【运维工程师学习三】shell编程
Shell程序分类
Shell程序有很多, 如Korn shell(ksh)、Bourne Again shell(bash)、C shell(包括csh与tcsh)等等,
各主要操作系统下缺省的shell:
- AIX下是
Korn Shell - Solaris缺省的是
Bourne shell - FreeBSD缺省的是
C shell - HP-UX缺省的是
POSIX shell - Linux缺省的是
Bourne Again shell
1、系统中sh命令是bash的软链接
sh=bash
file /usr/bin/sh
sh --version
/usr/bin/bash --version
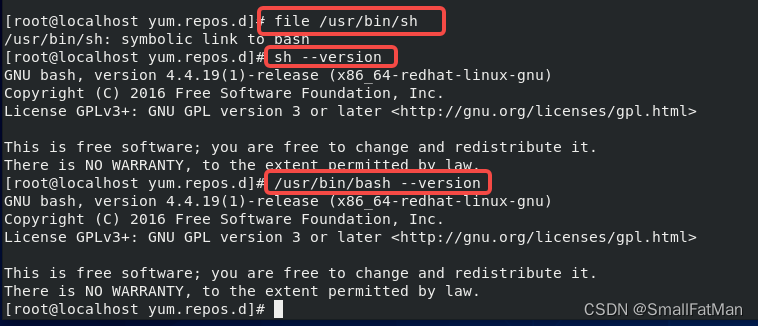
whereis sh

但这种在命令行中的命令是即时输出结果的,不能重复使用(重复输入可以重复使用,但如果是要多行输入的命令则极不方便),要想方便重复使用同一个功能就把多行的命令放到一个标准格式的文件中,这就是shell编程了。
所以所谓shell编程就是一行或多行不同功能的shell命令的集合!这个shell命令集合的文件叫shell script(shell脚本)。
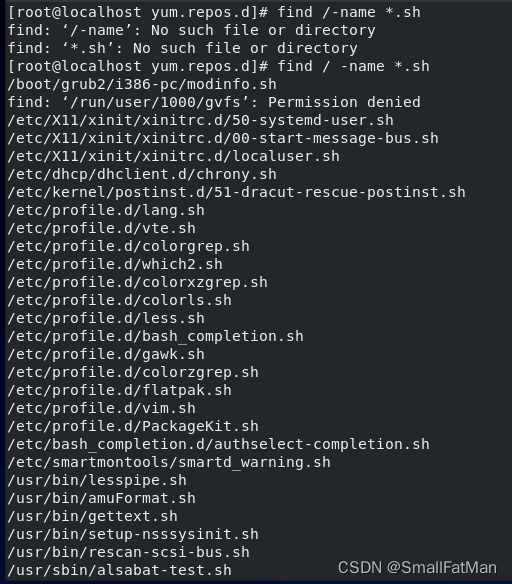
2、Shell脚本标准格式之文件后缀
Shell脚本文件一般是以.sh为后缀,如下图显示的文件fin是系统上默认存在的shell脚本文件
find /-name *.sh
3、Shell脚本标准格式之文件内容首行
首行通常是#!/bin/sh或#!/bin/bash或#!/usr/bin/sh或#!/usr/bin/bash开头(或者你还会看到其它的路径,或者全部有之)。该行的意思是,它告诉系统这个脚本需要什么解释器(即是什么shell,本系统是bash)来执行。
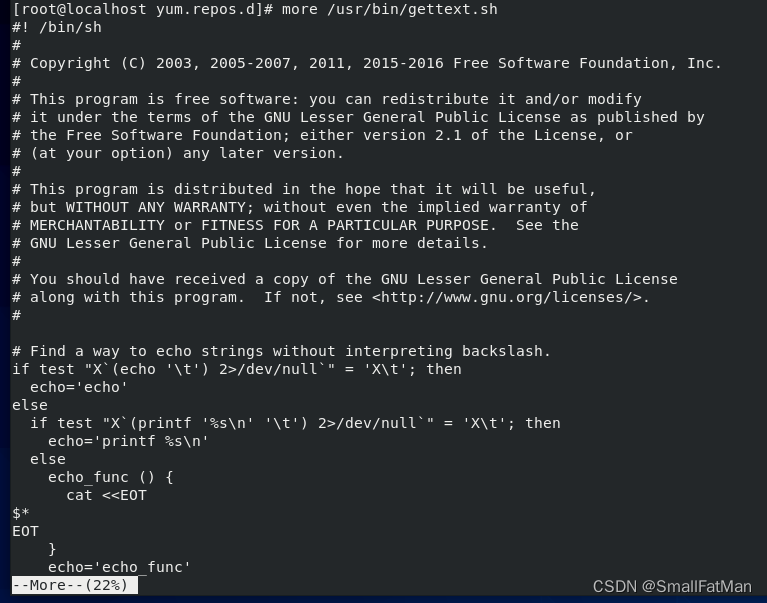
从第二行开始,凡是以#开头的行,说明该行均不会被执行,多用来作注释、说明。
注意:是以行为单位的。
到不是#开头的行开始,才是有效的命令、代码。
因篇幅原因,本截图省了后面很多内容,请自行在系统上查看该文件完整内容。
4、Shell脚本的运行方法
一、作为可执行程序
#!/bin/sh
ip addr | grep -v 127.0.0.1 | grep -v inet6 | grep inet | awk '{print $2}' | cut -d / -f 1
解释
这段Shell脚本的作用是获取本机的IPv4地址,并将其输出。
让我来一步一步解释这段脚本的具体内容:
-
#!/bin/sh:这是一个shebang(也称为hashbang),用于指定脚本使用哪个解释器来执行。在这里,#!/bin/sh表示脚本将使用默认的shell解释器来执行,通常是Bash或类似的shell。 -
ip addr:这个命令用于获取关于网络接口的信息,包括IP地址和其他网络配置。 -
grep -v 127.0.0.1:这个命令用于过滤掉IP地址中包含127.0.0.1的行,即过滤掉环回地址。 -
grep -v inet6:这个命令用于过滤掉IP地址中包含inet6的行,即过滤掉IPv6地址。 -
grep inet:这个命令用于筛选出包含inet(IPv4地址)的行。 -
awk '{print $2}':这个命令使用awk来提取每一行的第二个字段(IPv4地址),并进行打印输出。 -
cut -d / -f 1:这个命令使用cut来根据/进行分隔,提取分隔后的第一个字段(IPv4地址的主机部分),并进行打印输出。
综合起来,这个脚本的作用是获取本机的IPv4地址(除了本地回环地址和IPv6地址),并将其输出。
请注意,这段脚本在Linux环境下执行,可能需要确保你的系统中已经安装了所需的命令(如ip、grep、awk、cut)。
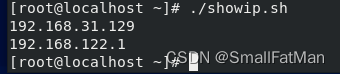
将上面内容保存了/root目录下的showip.sh文件中,并cd到/root目录下。
chmod +x ./showip.sh #使脚本具有执行权限
./showip.sh #执行脚本

二、作为解释器(bash)参数
本系统的解释器(shell)是bash,而我们知道sh是bash的软连接(类似于windows下的快捷方式),则最常用的方法就是“sh 脚本文件名”。
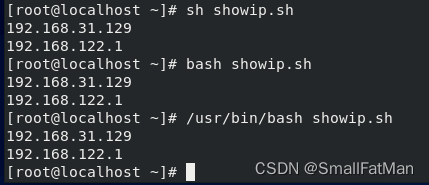
- 后面两种,只是故意演示出来而已。请使用上面的方法。理由是:输入少因而效率高。
- 我们知道sh是命令,而命令后面跟的就叫该命令参数。所以本方法叫“作为解释器的参数”运行脚本。
- 而该方法运行脚本,会无视脚本内的首行(即首行写与不写都没关系)。为什么?! 因为直接调用了解释器!
5、find、grep、xargs、sort、uniq、tr、cut、paste、wc、sed、awk的常用命令
当涉及到文本处理和数据操作时,下面是一些find、grep、xargs、sort、uniq、tr、cut、paste、wc、sed和awk的常用命令:
1. find:用于在文件系统中搜索文件或目录。
find /path/to/directory -name "filename":按照文件名在指定目录下搜索文件。find /path/to/directory -type f:找出指定目录下的所有文件。find /path/to/directory -type d:找出指定目录下的所有目录。

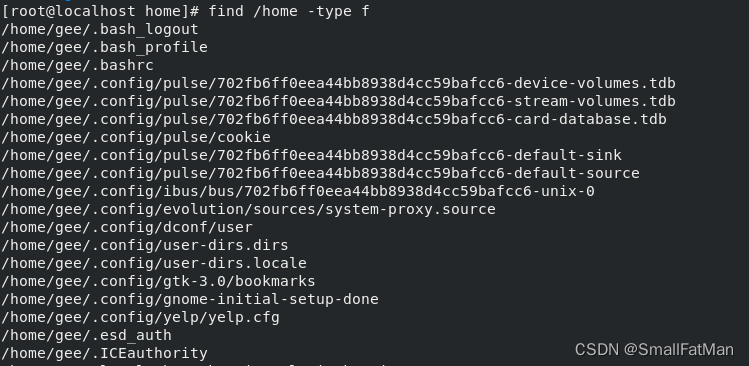
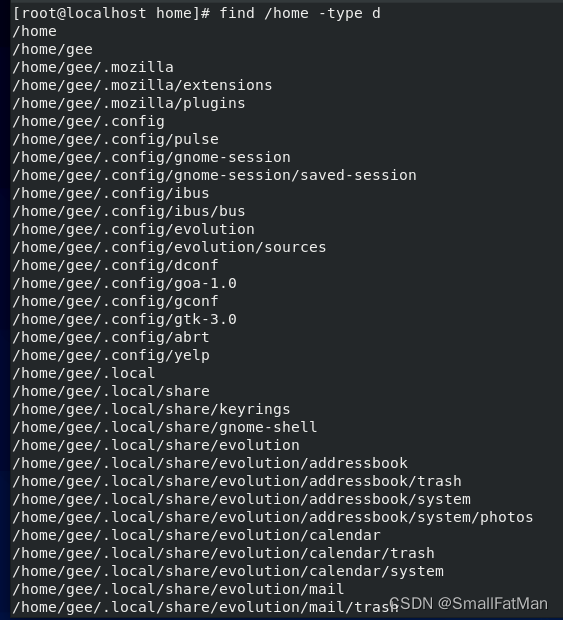
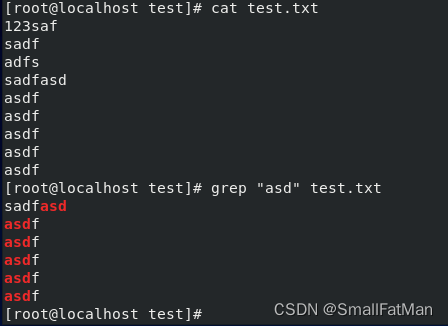
2. grep:用于在文件或输入中查找特定模式。
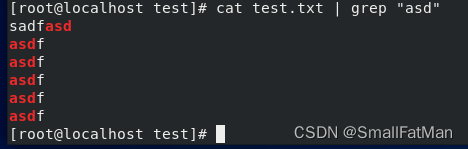
grep "pattern" file.txt:在文件中搜索包含指定模式的行。cat file.txt | grep "pattern":在输入流中搜索包含指定模式的行。
3. xargs:用于从标准输入中读取参数并将其传递给其他命令。
-
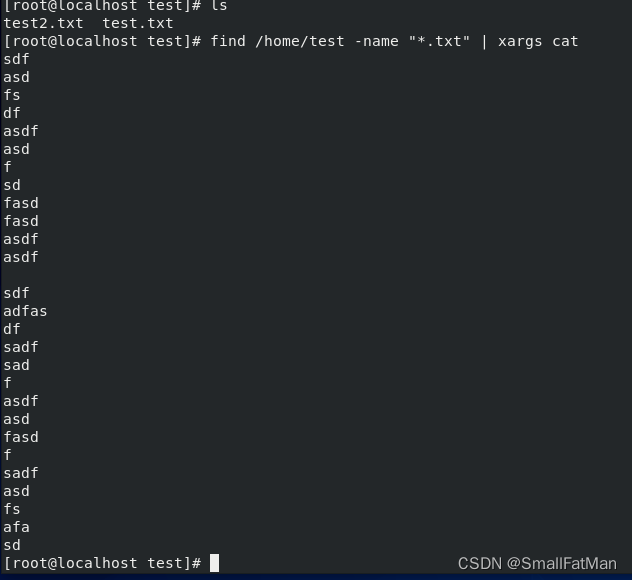
find /path/to/directory -name "*.txt" | xargs rm:找到所有以.txt结尾的文件并删除它们。 -
find /path/to/directory -name "*.txt" | xargs cat:找到所有以.txt结尾的文件并查看它们。

4. sort:用于对文本进行排序。
-
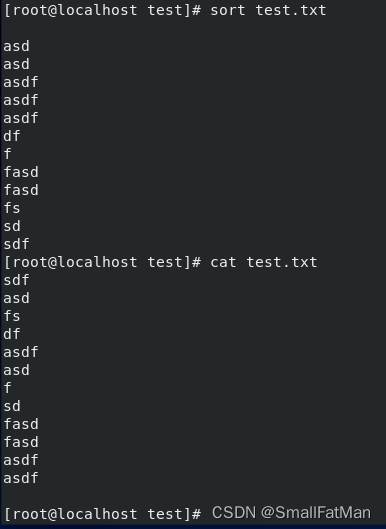
sort file.txt:对文件中的行按字母顺序进行排序。 -
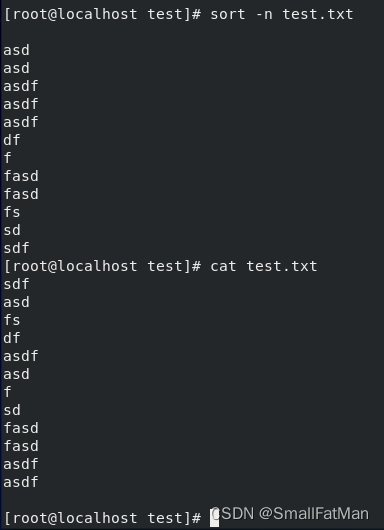
sort -n file.txt:对文件中的行按数值大小进行排序。
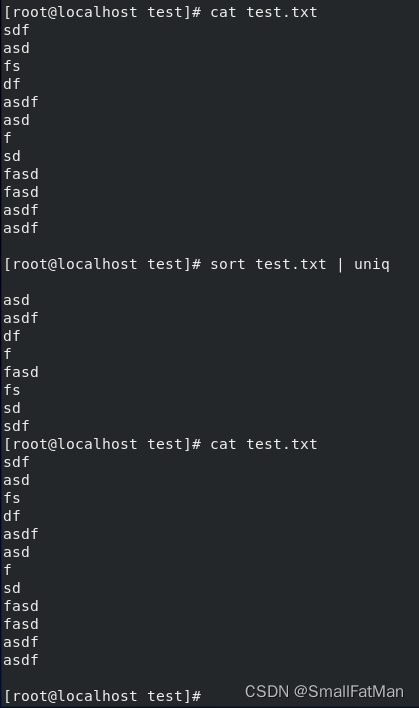
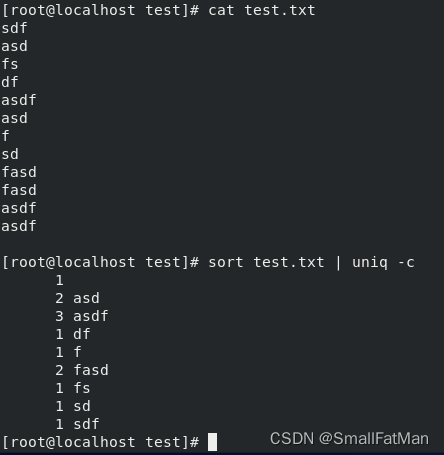
5. uniq:用于从排序后的输入中筛选出唯一的行。
-
sort file.txt | uniq:对文件中的行排序并消除重复行。 -
sort file.txt | uniq -c:计算每个唯一行的出现次数。
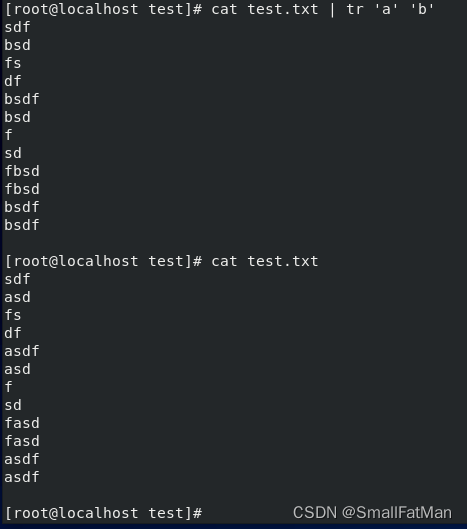
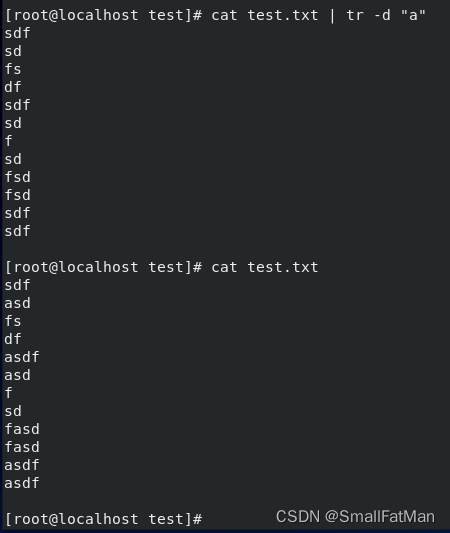
6. tr:用于字符替换和删除。
cat file.txt | tr 'a' 'b':将输入中的所有字母 ‘a’ 替换为 ‘b’。cat file.txt | tr -d 'a':删除输入中的所有字母 ‘a’。
7. cut:用于从文本中提取指定字段。
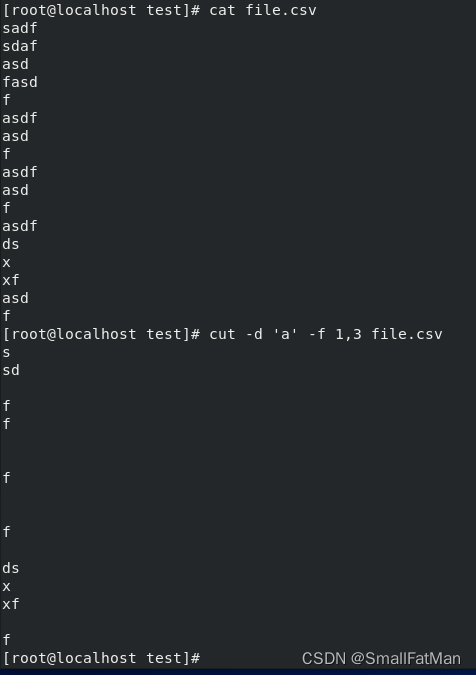
cut -d ',' -f 1,3 file.csv:以逗号为分隔符,提取CSV文件中的第1和第3个字段。
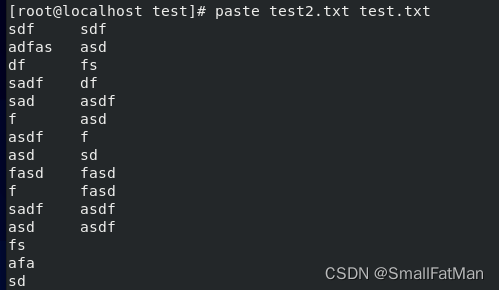
8. paste:用于将多个文件的内容合并为一行。
paste file1.txt file2.txt:将两个文件的内容并排合并。
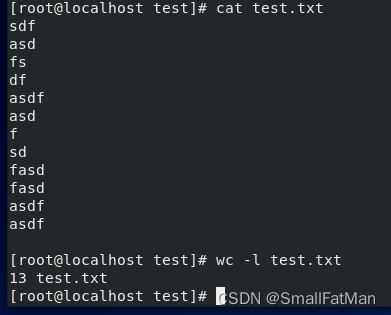
9. wc:用于计算文件或文本的行数、字数和字符数。
wc -l file.txt:计算文件中的行数。echo "Hello, World!" | wc -w:计算输入内容的字数。

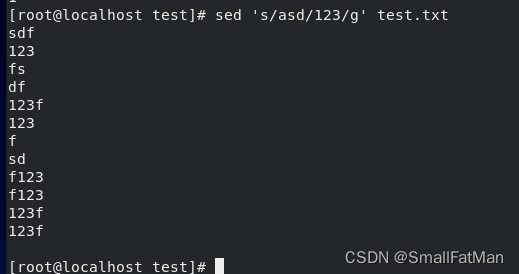
10. sed:用于流式文本编辑。
sed 's/pattern/replacement/g' file.txt:将文件中的所有匹配pattern的内容替换为replacement。sed '/pattern/d' file.txt:从文件中删除包含pattern的行。

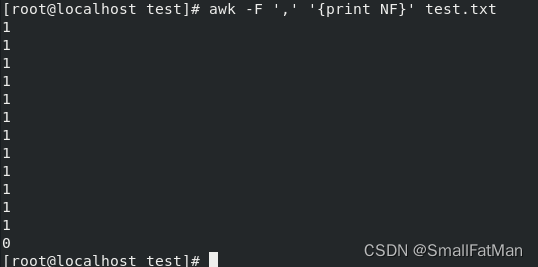
11. awk:用于处理结构化文本数据。
awk '{print $1}' file.txt:打印文件中每一行的第一个字段。awk -F ',' '{print NF}' file.csv:计算文件中每一行的字段数。
以上只是这些命令中的一些常见用法示例,它们具有更多强大和灵活的功能。你可以查阅命令的文档或在终端上运行 man <command> 来了解更多详细的用法和选项。