译者:飞龙
本文来自【OpenDocCN 饱和式翻译计划】,采用译后编辑(MTPE)流程来尽可能提升效率。
真相一旦入眼,你就再也无法视而不见。——《黑客帝国》
九、并发实践
本章涵盖
- 防止 goroutines 和通道的常见错误
- 了解使用标准数据结构和并发代码的影响
- 使用标准库和一些扩展
- 避免数据竞争和死锁
在前一章中,我们讨论了并发的基础。现在是时候看看 Go 开发人员在使用并发原语时所犯的实际错误了。
9.1 #61:传播不适当的上下文
在 Go 中处理并发时,上下文无处不在,在许多情况下,可能建议传播它们。然而,上下文传播有时会导致细微的错误,阻止子函数的正确执行。
让我们考虑下面的例子。我们公开一个 HTTP 处理器,它执行一些任务并返回一个响应。但是就在返回响应之前,我们还想把它发送到一个kafka主题。我们不想降低 HTTP 消费者的延迟,所以我们希望在新的 goroutine 中异步处理发布操作。我们假设我们有一个接受上下文的publish函数,例如,如果上下文被取消,发布消息的操作就会被中断。下面是一个可能的实现:
func handler(w http.ResponseWriter, r *http.Request) {
response, err := doSomeTask(r.Context(), r) // ❶
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
go func() {
// ❷
err := publish(r.Context(), response)
// Do something with err
}()
writeResponse(response) // ❸
}
❶ 执行一些任务来 HTTP 响应
❷ 创建了一个goroutine来向kafka发送响应
❸ 编写 HTTP 响应
首先我们调用一个doSomeTask函数来获得一个response变量。它在调用publish的 goroutine 中使用,并格式化 HTTP 响应。此外,当调用publish时,我们传播附加到 HTTP 请求的上下文。你能猜出这段代码有什么问题吗?
我们必须知道附加到 HTTP 请求的上下文可以在不同的情况下取消:
-
当客户端连接关闭时
-
在 HTTP/2 请求的情况下,当请求被取消时
-
当响应被写回客户端时
在前两种情况下,我们可能会正确处理事情。例如,如果我们从doSomeTask得到一个响应,但是客户端已经关闭了连接,那么调用publish时可能已经取消了一个上下文,所以消息不会被发布。但是最后一种情况呢?
当响应被写入客户端时,与请求相关联的上下文将被取消。因此,我们面临着一种竞争状态:
-
如果响应是在 Kafka 发布之后写的,我们都返回响应并成功发布消息。
-
然而,如果响应是在kafka发表之前或发表期间写的,则该消息不应被发表。
在后一种情况下,调用publish将返回一个错误,因为我们快速返回了 HTTP 响应。
我们如何解决这个问题?一种想法是不传播父上下文。相反,我们会用一个空的上下文调用publish:
err := publish(context.Background(), response) // ❶
❶ 使用空上下文代替 HTTP 请求上下文
在这里,这将工作。不管写回 HTTP 响应需要多长时间,我们都可以调用publish。
但是如果上下文包含有用的值呢?例如,如果上下文包含用于分布式跟踪的关联 ID,我们可以将 HTTP 请求和 Kafka 发布关联起来。理想情况下,我们希望有一个新的上下文,它与潜在的父取消无关,但仍然传达值。
标准包没有提供这个问题的直接解决方案。因此,一个可能的解决方案是实现我们自己的 Go 上下文,类似于所提供的上下文,只是它不携带取消信号。
一个context.Context是一个接口,包含四个方法:
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{
}
Err() error
Value(key any) any
}
通过Deadline方法管理上下文的截止时间,通过Done和Err方法管理取消信号。当截止时间已过或上下文已被取消时,Done应该返回一个关闭的通道,而Err应该返回一个错误。最后,通过Value方法传送这些值。
让我们创建一个自定义上下文,将取消信号从父上下文中分离出来:
type detach struct {
// ❶
ctx context.Context
}
func (d detach) Deadline() (time.Time, bool) {
return time.Time{
}, false
}
func (d detach) Done() <-chan struct{
} {
return nil
}
func (d detach) Err() error {
return nil
}
func (d detach) Value(key any) any {
return d.ctx.Value(key) // ❷
}
❶ 自定义结构充当初始上下文顶部的包装
❷ 将获取值的调用委托给父上下文
除了调用父上下文获取值的Value方法之外,其他方法都返回默认值,因此上下文永远不会被视为过期或取消。
由于我们的自定义上下文,我们现在可以调用publish并分离取消信号:
err := publish(detach{
ctx: r.Context()}, response) // ❶
❶ 在 HTTP 上下文上使用detach
现在传递给publish的上下文将永远不会过期或被取消,但是它将携带父上下文的值。
总之,传播一个上下文要谨慎。在本节中,我们用一个基于与 HTTP 请求相关联的上下文处理异步操作的例子来说明这一点。因为一旦我们返回响应,上下文就会被取消,所以异步操作也可能会意外停止。让我们记住传播给定上下文的影响,如果有必要,总是可以为特定的操作创建自定义上下文。
下一节讨论一个常见的并发错误:启动一个 goroutine 而没有计划停止它。
9.2 #62:启动一个 goroutine 而不知道何时停止它
启动 goroutine 既容易又便宜——如此容易又便宜,以至于我们可能没有必要计划何时停止新的 goroutine,这可能会导致泄漏。不知道何时停止 goroutine 是一个设计问题,也是 Go 中常见的并发错误。我们来了解一下为什么以及如何预防。
首先,让我们量化一下 goroutine 泄漏意味着什么。在内存方面,一个 goroutine 的最小栈大小为 2 KB,可以根据需要增加和减少(最大栈大小在 64 位上是 1 GB,在 32 位上是 250 MB)。在内存方面,goroutine 还可以保存分配给堆的变量引用。与此同时,goroutine 可以保存 HTTP 或数据库连接、打开的文件和网络套接字等资源,这些资源最终应该被正常关闭。如果一个 goroutine 被泄露,这些类型的资源也会被泄露。
让我们看一个例子,其中 goroutine 停止的点不清楚。这里,父 goroutine 调用一个返回通道的函数,然后创建一个新的 goroutine,它将继续从该通道接收消息:
ch := foo()
go func() {
for v := range ch {
// ...
}
}()
当ch关闭时,创建的 goroutine 将退出。但是我们知道这个通道什么时候会关闭吗?这可能不明显,因为ch是由foo函数创建的。如果通道从未关闭,那就是泄漏。因此,我们应该始终保持警惕,确保最终到达一个目标。
我们来讨论一个具体的例子。我们将设计一个需要观察一些外部配置的应用(例如,使用数据库连接)。这是第一个实现:
func main() {
newWatcher()
// Run the application
}
type watcher struct {
/* Some resources */ }
func newWatcher() {
w := watcher{
}
go w.watch() // ❶
}
❶ 创建了一个监视外部配置的 goroutine
我们调用newWatcher,它创建一个watcher结构,并启动一个负责监视配置的 goroutine。这段代码的问题是,当主 goroutine 退出时(可能是因为 OS 信号或者因为它的工作负载有限),应用就会停止。因此,由watcher创建的资源没有被优雅地关闭。如何才能防止这种情况发生?
一种选择是传递给newWatcher一个当main返回时将被取消的上下文:
func main() {
ctx, cancel := context.WithCancel(context.Background())
defer cancel()
newWatcher(ctx) // ❶
// Run the application
}
func newWatcher(ctx context.Context) {
w := watcher{
}
go w.watch(ctx) // ❷
}
❶ 传递给newWatcher一个最终会取消的上下文
❷ 传播这一上下文
我们将创建的上下文传播给watch方法。当上下文被取消时,watcher结构应该关闭它的资源。然而,我们能保证watch有时间这样做吗?绝对不是——这是一个设计缺陷。
问题是,我们使用信号来传达必须停止 goroutine。直到资源关闭后,我们才阻塞父 goroutine。让我们确保做到:
func main() {
w := newWatcher()
defer w.close() // ❶
// Run the application
}
func newWatcher() watcher {
w := watcher{
}
go w.watch()
return w
}
func (w watcher) close() {
// Close the resources
}
❶ 延迟调用close方法
watcher有了新方法:close。我们现在调用这个close方法,使用defer来保证在应用退出之前关闭资源,而不是用信号通知watcher该关闭它的资源了。
总之,我们要注意的是,goroutine 和任何其他资源一样,最终都必须被关闭以释放内存或其他资源。启动 goroutine 而不知道何时停止是一个设计问题。无论什么时候开始,我们都应该有一个明确的计划,知道它什么时候会停止。最后但同样重要的是,如果一个 goroutine 创建资源,并且它的生命周期与应用的生命周期绑定在一起,那么在退出应用之前等待这个 goroutine 完成可能更安全。这样,我们可以确保释放资源。
现在让我们讨论在 Go 中工作时最常见的错误之一:错误处理 goroutines 和循环变量。
9.3 #63:对 goroutines 和循环变量不够小心
错误处理 goroutines 和循环变量可能是 Go 开发者在编写并发应用时最常犯的错误之一。我们来看一个具体的例子;然后我们将定义这种 bug 的条件以及如何防止它。
在下面的例子中,我们初始化一个切片。然后,在作为新的 goroutine 执行的闭包中,我们访问这个元素:
s := []int{
1, 2, 3}
for _, i := range s {
// ❶
go func() {
fmt.Print(i) // ❷
}()
}
❶ 迭代每个元素
❷ 访问循环变量
我们可能希望这段代码不按特定的顺序打印123(因为不能保证创建的第一个 goroutine 会首先完成)。然而,这段代码的输出是不确定的。比如有时候打印233有时候打印333。原因是什么?
在这个例子中,我们从一个闭包创建新的 goroutines。提醒一下,闭包是一个从其正文外部引用变量的函数值:这里是i变量。我们必须知道,当执行闭包 goroutine 时,它不会捕获创建 goroutine 时的值。相反,所有的 goroutines 都引用完全相同的变量。当一个 goroutine 运行时,它在执行fmt.Print时打印出i的值。因此,i可能在 goroutine 上市后被修改过。
图 9.1 显示了代码打印233时可能的执行情况。随着时间的推移,i的值会发生变化:1、2,然后是3。在每次迭代中,我们都会旋转出一个新的 goroutine。因为不能保证每个 goroutine 什么时候开始和完成,所以结果也会不同。在这个例子中,第一个 goroutine 在i等于2时打印它。然后,当值已经等于3时,其他 goroutines 打印i。因此,本例打印233。这段代码的行为是不确定的。

图 9.1 goroutines 访问一个不固定但随时间变化的i变量。
如果我们想让每个闭包在创建 goroutine 时访问i的值,有什么解决方案?如果我们想继续使用闭包,第一个选项包括创建一个新变量:
for _, i := range s {
val := i // ❶
go func() {
fmt.Print(val)
}()
}
❶ 为每次迭代创建一个局部变量
为什么这段代码会起作用?在每次迭代中,我们创建一个新的局部变量val。该变量在创建 goroutine 之前捕获i的当前值。因此,当每个闭包 goroutine 执行 print 语句时,它会使用预期的值。这段代码打印123(同样,没有特别的顺序)。
第二个选项不再依赖于闭包,而是使用一个实际的函数:
for _, i := range s {
go func(val int) {
// ❶
fmt.Print(val)
}(i) // ❷
}
❶ 执行一个以整数为参数的函数
❷ 调用这个函数并传递i的当前值
我们仍然在新的 goroutine 中执行匿名函数(例如,我们不运行go f(i)),但这一次它不是闭包。该函数没有从其正文外部引用val作为变量;val现在是函数输入的一部分。通过这样做,我们在每次迭代中修正了i,并使我们的应用按预期工作。
我们必须小心 goroutines 和循环变量。如果 goroutine 是一个访问从其正文外部声明的迭代变量的闭包,那就有问题了。我们可以通过创建一个局部变量(例如,我们已经看到在执行 goroutine 之前使用val := i)或者使函数不再是一个闭包来修复它。两种选择都可行,我们不应该偏向其中一种。一些开发人员可能会发现闭包方法更方便,而其他人可能会发现函数方法更具表现力。
在多个通道上使用select语句会发生什么?让我们找出答案。
9.4 #64:使用select和通道预期确定性行为
Go 开发人员在使用通道时犯的一个常见错误是对select如何使用多个通道做出错误的假设。错误的假设会导致难以识别和重现的细微错误。
假设我们想要实现一个需要从两个通道接收数据的 goroutine:
-
messageCh为待处理的新消息。 -
disconnectCh接收传达断线的通知。在这种情况下,我们希望从父函数返回。
这两个通道,我们要优先考虑messageCh。例如,如果发生断开连接,我们希望在返回之前确保我们已经收到了所有的消息。
我们可以决定这样处理优先级:
for {
select {
// ❶
case v := <-messageCh: // ❷
fmt.Println(v)
case <-disconnectCh: // ❸
fmt.Println("disconnection, return")
return
}
}
❶ 使用select语句从多个通道接收
❷ 接收新消息
❸ 断开连接
我们使用select从多个通道接收。因为我们想要区分messageCh的优先级,我们可以假设我们应该首先编写messageCh案例,然后是disconnectCh案例。但是这些代码真的有用吗?让我们通过编写一个发送 10 条消息然后发送一个断开通知的伪生产者 goroutine 来尝试一下:
for i := 0; i < 10; i++ {
messageCh <- i
}
disconnectCh <- struct{
}{
}
如果我们运行这个例子,如果messageCh被缓冲,这里是一个可能的输出:
0
1
2
3
4
disconnection, return
我们没有收到这 10 条信息,而是收到了其中的 5 条。原因是什么?它在于规范的多通道的select语句(go.dev/ref/spec):
如果一个或多个通信可以进行,则通过统一的伪随机选择来选择可以进行的单个通信。
与switch语句不同,在语句中,第一个匹配的案例获胜,如果有多个选项,则select语句随机选择。
这种行为乍一看可能很奇怪,但有一个很好的理由:防止可能的饥饿。假设选择的第一个可能的通信是基于源顺序的。在这种情况下,我们可能会陷入这样一种情况,例如,由于发送者速度快,我们只能从一个通道接收。为了防止这种情况,语言设计者决定使用随机选择。
回到我们的例子,即使case v := <-messageCh在源代码顺序中排在第一位,如果messageCh和disconnectCh中都有消息,也不能保证哪种情况会被选中。因此,这个例子的行为是不确定的。我们可能会收到 0 条、5 条或 10 条消息。
如何才能克服这种情况?如果我们想在断线情况下返回之前接收所有消息,有不同的可能性。
如果只有一个制片人,我们有两个选择:
-
使
messageCh成为非缓冲通道,而不是缓冲通道。因为发送方 goroutine 阻塞,直到接收方 goroutine 准备好,所以这种方法保证了在从disconnectCh断开连接之前,接收到来自messageCh的所有消息。 -
用单通道代替双通道。例如,我们可以定义一个
struct来传递一个新消息或者一个断开。通道保证发送消息的顺序与接收消息的顺序相同,因此我们可以确保最后接收到断开连接。
如果我们遇到有多个生产者 goroutines 的情况,可能无法保证哪一个先写。因此,无论我们有一个无缓冲的messageCh通道还是一个单一的通道,都会导致生产者之间的竞争。在这种情况下,我们可以实现以下解决方案:
-
从
messageCh或disconnectCh接收。 -
如果接收到断开连接
- 阅读
messageCh中所有已有的信息,如果有的话。 - 然后返回。
- 阅读
以下是解决方案:
for {
select {
case v := <-messageCh:
fmt.Println(v)
case <-disconnectCh:
for {
// ❶
select {
case v := <-messageCh: // ❷
fmt.Println(v)
default: // ❸
fmt.Println("disconnection, return")
return
}
}
}
}
❶ 内部for/select
❷ 读取剩下的信息
❸ 然后返回
该解决方案使用带有两个外壳的内部for/select:一个在messageCh上,一个在default外壳上。在中使用default,只有当其他情况都不匹配时,才选择select语句。在这种情况下,这意味着我们只有在收到了messageCh中所有剩余的消息后才会返回。
让我们来看一个代码如何工作的例子。我们将考虑这样的情况,在messageCh中有两个消息,在disconnectCh中有一个断开,如图 9.2 所示。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BUYOlQ0J-1684395591001)(https://gitcode.net/OpenDocCN/100-go-mistakes-zh/-/raw/master/docs/img/CH09_F02_Harsanyi.png)]
图 9.2 初始状态
在这种情况下,正如我们已经说过的,select随机选择一种情况或另一种情况。假设select选择第二种情况;参见图 9.3。

图 9.3 接收断开连接
因此,我们接收到断开连接并进入内部select(图 9.4)。这里,只要消息还在messageCh中,select将总是优先于default(图 9.5)。

图 9.4 内部select
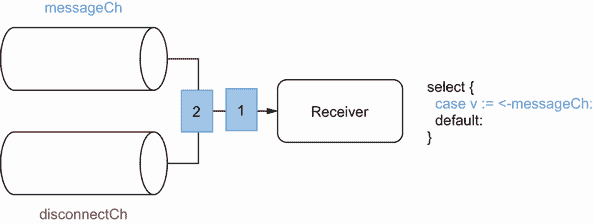
图 9.5 接收剩余消息
一旦我们收到来自messageCh的所有消息,select不会阻塞并选择default的情况(图 9.6)。因此,我们返回并阻止 goroutine。

图 9.6 默认情况
这是一种确保我们通过多个通道上的接收器从一个通道接收所有剩余消息的方法。当然,如果在 goroutine 返回后发送了一个messageCh(例如,如果我们有多个生产者 goroutine),我们将错过这个消息。
当使用多通道的select时,我们必须记住,如果有多个选项,源顺序中的第一种情况不会自动胜出。相反,Go 随机选择,所以不能保证哪个选项会被选中。为了克服这种行为,在单个生产者 goroutine 的情况下,我们可以使用无缓冲通道或单个通道。在多个生产者 goroutines 的情况下,我们可以使用内部选择和default来处理优先级。
下一节讨论一种常见的通道类型:通知通道。
9.5 #65:不使用通知通道
通道是一种通过信号进行跨例程通信的机制。信号可以有数据,也可以没有数据。但是对于 Go 程序员来说,如何处理后一种情况并不总是那么简单。
我们来看一个具体的例子。我们将创建一个通道,当某个连接断开时,它会通知我们。一种想法是将它作为一个chan bool来处理:
disconnectCh := make(chan bool)
现在,假设我们与一个为我们提供这样一个通道的 API 进行交互。因为这是一个布尔通道,我们可以接收true或false消息。大概很清楚true传达的是什么。但是false是什么意思呢?是不是说明我们没有断线?在这种情况下,我们收到这种信号的频率有多高?是不是意味着我们又重新联系上了?
我们应该期待收到false吗?也许我们应该只期待收到true消息。如果是这样的话,意味着我们不需要特定的值来传达一些信息,我们需要一个没有数据的通道。惯用的处理方式是一个空的结构的通道:chan struct{}。
在 Go 中,空结构是没有任何字段的结构。无论架构如何,它都不占用任何字节的存储空间,我们可以使用unsafe.Sizeof来验证这一点:
var s struct{
}
fmt.Println(unsafe.Sizeof(s))
0
注意为什么不用空接口(var i interface{})?因为空接口不是免费的;它在 32 位架构上占用 8 个字节,在 64 位架构上占用 16 个字节。
一个空的结构是一个事实上的标准来表达没有意义。例如,如果我们需要一个散列集合结构(唯一元素的集合),我们应该使用一个空结构作为值:map[K]struct{}。
应用于通道,如果我们想要创建一个通道来发送没有数据的通知,在 Go 中这样做的合适方法是一个chan struct{}。空结构通道的一个最著名的应用是 Go 上下文,我们将在本章中讨论。
通道可以有数据,也可以没有数据。如果我们想设计一个关于 Go 标准的惯用 API,让我们记住没有数据的通道应该用achan类型来表示。这样,它向接收者阐明了他们不应该从信息的内容中期待任何意义——仅仅是他们已经收到信息的事实。在 Go 中,这样的通道称为通知通道。
下一节将讨论 Go 如何处理nil通道以及使用它们的基本原理。
9.6 #66:不使用nil通道
在使用 Go 和通道时,一个常见的错误是忘记了nil通道有时是有帮助的。那么什么是nil通道,我们为什么要关心它们呢?这是本节的范围。
让我们从创建一个nil通道并等待接收消息的 goroutine 开始。这段代码应该做什么?
var ch chan int // ❶
<-ch
❶ nil通道
ch是chan int型。通道的零值为零,ch为nil。goroutine 不会惊慌;但是,会永远屏蔽。
如果我们向nil通道发送消息,原理是相同的。这条路永远不通:
var ch chan int
ch <- 0
那么 Go 允许从nil通道接收消息或者向nil通道发送消息的目的是什么呢?我们将用一个具体的例子来讨论这个问题。
我们将实现一个func merge(ch1, ch2 <-chan int) <-chan int函数来将两个通道合并成一个通道。通过合并它们(参见图 9.7),我们的意思是在ch1或ch2中接收的每个消息都将被发送到返回的通道。

图 9.7 将两个通道合并为一个
在GO中如何做到这一点?让我们首先编写一个简单的实现,它启动一个 goroutine 并从两个通道接收数据(得到的通道将是一个包含一个元素的缓冲通道):
func merge(ch1, ch2 <-chan int) <-chan int {
ch := make(chan int, 1)
go func() {
for v := range ch1 {
// ❶
ch <- v
}
for v := range ch2 {
// ❷
ch <- v
}
close(ch)
}()
return ch
}
❶ 从ch1接收并发布到合并的通道
❷ 从ch2接收并发布到合并的通道
在另一个 goroutine 中,我们从两个通道接收信息,每条信息最终都在ch中发布。
这个第一个版本的主要问题是我们从ch1接收,然后从ch2接收。这意味着在ch1关闭之前,我们不会收到来自ch2的信息。这不符合我们的用例,因为ch1可能会永远打开,所以我们希望同时从两个通道接收。
让我们使用select编写一个带有并发接收者的改进版本:
func merge(ch1, ch2 <-chan int) <-chan int {
ch := make(chan int, 1)
go func() {
for {
select {
// ❶
case v := <-ch1:
ch <- v
case v := <-ch2:
ch <- v
}
}
close(ch)
}()
return ch
}
❶ 同时接收ch1和ch2
select语句让一个 goroutine 同时等待多个操作。因为我们将它包装在一个for循环中,所以我们应该重复地从一个或另一个通道接收消息,对吗?但是这些代码真的有用吗?
一个问题是close(ch)语句是不可达的。当通道关闭时,使用range操作符在通道上循环中断。然而,当ch1或ch2关闭时,我们实现for / select的方式并不适用。更糟糕的是,如果在某个点ch1或ch2关闭,当记录值时,合并通道的接收器将接收到以下内容:
received: 0
received: 0
received: 0
received: 0
received: 0
...
所以接收器会重复接收一个等于零的整数。为什么?从封闭通道接收是一种非阻塞操作:
ch1 := make(chan int)
close(ch1)
fmt.Print(<-ch1, <-ch1)
尽管我们可能认为这段代码会恐慌或阻塞,但是它会运行并打印出0 0。我们在这里捕获的是闭包事件,而不是实际的消息。要检查我们是否收到消息或结束信号,我们必须这样做:
ch1 := make(chan int)
close(ch1)
v, open := <-ch1 // ❶
fmt.Print(v, open)
无论通道是否打开,❶都会指定打开
使用open布尔值,我们现在可以看到ch1是否仍然打开:
0 false
同时,我们也将0赋给v,因为它是一个整数的零值。
让我们回到我们的第二个解决方案。我们说ch1关了不太好用;例如,因为select案例是case v := <-ch1,所以我们会一直输入这个案例,并向合并后的通道发布一个零整数。
让我们后退一步,看看处理这个问题的最佳方法是什么(见图 9.8)。我们必须从两个通道接收。那么,要么
-
的
ch1是先关闭的,所以我们要从ch2开始接收,直到它关闭。 -
ch2先关闭,所以我们要从ch1接收,直到它关闭。

图 9.8 根据先关闭ch1还是先关闭ch2来处理不同情况
如何在 Go 中实现这一点?让我们编写一个版本,就像我们可能使用状态机方法和布尔函数所做的那样:
func merge(ch1, ch2 <-chan int) <-chan int {
ch := make(chan int, 1)
ch1Closed := false
ch2Closed := false
go func() {
for {
select {
case v, open := <-ch1:
if !open {
// ❶
ch1Closed = true
break
}
ch <- v
case v, open := <-ch2:
if !open {
// ❷
ch2Closed = true
break
}
ch <- v
}
if ch1Closed && ch2Closed {
// ❸
close(ch)
return
}
}
}()
return ch
}
❶ 处理ch1是否关闭
❷ 处理ch2是否关闭
❸ 如果两个通道都关闭,将关闭ch并返回
我们定义了两个布尔值ch1Closed和ch2Closed。一旦我们从一个通道接收到一个消息,我们就检查它是否是一个关闭信号。如果是,我们通过将通道标记为关闭来处理(例如,ch1Closed = true)。两个通道都关闭后,我们关闭合并的通道并停止 goroutine。
这段代码除了开始变得复杂之外,还有什么问题呢?有一个主要问题:当两个通道中的一个关闭时,for循环将充当一个忙等待循环,这意味着即使在另一个通道中没有接收到新消息,它也将继续循环。在我们的例子中,我们必须记住语句的行为。假设ch1关闭(所以我们在这里不会收到任何新消息);当我们再次到达select时,它将等待以下三个条件之一发生:
-
ch1关闭。 -
ch2有新消息。 -
ch2关闭。
第一个条件ch1是关闭的,将永远有效。因此,只要我们在ch2中没有收到消息,并且这个通道没有关闭,我们将继续循环第一个案例。这将导致浪费 CPU 周期,必须避免。因此,我们的解决方案不可行。
我们可以尝试增强状态机部分,并在每种情况下实现子for/select循环。但是这将使我们的代码更加复杂和难以理解。
是时候回到nil通道了。正如我们提到的,从nil通道接收将永远阻塞。在我们的解决方案中使用这个想法怎么样?我们将把这个通道赋值为nil,而不是在一个通道关闭后设置一个布尔值。让我们写出最终版本:
func merge(ch1, ch2 <-chan int) <-chan int {
ch := make(chan int, 1)
go func() {
for ch1 != nil || ch2 != nil {
// ❶
select {
case v, open := <-ch1:
if !open {
ch1 = nil // ❷
break
}
ch <- v
case v, open := <-ch2:
if !open {
ch2 = nil // ❸
break
}
ch <- v
}
}
close(ch)
}()
return ch
}
❶ 如果至少有一个通道不为nil,将继续
❷一旦关闭,将nil通道分配给ch1
❷一旦关闭,将nil通道分配给ch2
首先,只要至少一个通道仍然打开,我们就循环。然后,例如,如果ch1关闭,我们将ch1赋值为零。因此,在下一次循环迭代期间,select语句将只等待两个条件:
-
ch2有新消息。 -
ch2关闭。
ch1不再是等式的一部分,因为它是一个nil通道。同时,我们为ch2保留相同的逻辑,并在它关闭后将其赋值为nil。最后,当两个通道都关闭时,我们关闭合并的通道并返回。图 9.9 显示了这种实现的模型。

图 9.9 从两个通道接收。如果一个是关闭的,我们把它赋值为 0,这样我们只从一个通道接收。
这是我们一直在等待的实现。我们涵盖了所有不同的情况,并且不需要会浪费 CPU 周期的繁忙循环。
总之,我们已经看到,等待或发送到一个nil通道是一个阻塞行为,这种行为是有用的。正如我们在合并两个通道的例子中所看到的,我们可以使用nil通道来实现一个优雅的状态机,该状态机将从一个select语句中移除一个case。让我们记住这个想法:nil通道在某些情况下是有用的,在处理并发代码时应该成为 Go 开发者工具集的一部分。
在下一节中,我们将讨论创建通道时应设置的大小。
9.7 #67:对通道大小感到困惑
当我们使用make内置函数创建通道时,通道可以是无缓冲的,也可以是缓冲的。与这个话题相关,有两个错误经常发生:不知道什么时候使用这个或那个;如果我们使用缓冲通道,应该使用多大的缓冲通道。让我们检查一下这几点。
首先,让我们记住核心概念。无缓冲通道是没有任何容量的通道*。它可以通过省略尺寸或提供一个0尺寸来创建:*
ch1 := make(chan int)
ch2 := make(chan int, 0)
使用无缓冲通道(有时称为同步通道),发送方将阻塞,直到接收方从该通道接收到数据。
相反,缓冲通道有容量,必须创建大于或等于1的大小:
ch3 := make(chan int, 1)
使用缓冲通道,发送方可以在通道未满时发送消息。一旦通道满了,它就会阻塞,直到接收者或路由器收到消息。例如:
ch3 := make(chan int, 1)
ch3 <-1 // ❶
ch3 <-2 // ❷
❶ 无阻塞
❷ 阻塞
第一个发送没有阻塞,而第二个阻塞了,因为这个阶段通道已满。
让我们后退一步,讨论这两种通道类型之间的根本区别。通道是一种并发抽象,用于支持 goroutines 之间的通信。但是同步呢?在并发中,同步意味着我们可以保证多个 goroutines 在某个时刻处于已知状态。例如,互斥锁提供同步,因为它确保同一时间只有一个 goroutine 在临界区。关于通道:
-
无缓冲通道支持同步。我们保证两个 goroutines 将处于已知状态:一个接收消息,另一个发送消息。
-
缓冲通道不提供任何强同步。事实上,如果通道未满,生产者 goroutine 可以发送消息,然后继续执行。唯一的保证是 goroutine 在消息发送之前不会收到消息。但这只是一个保证,因为因果关系(你不喝你的咖啡之前,你准备好了)。
牢记这一基本区别至关重要。两种通道类型都支持通信,但只有一种提供同步。如果我们需要同步,我们必须使用无缓冲通道。无缓冲通道也可能更容易推理:缓冲通道可能会导致不明显的死锁,而无缓冲通道会立即显现出来。
在其他情况下,无缓冲通道更可取:例如,在通知通道的情况下,通知是通过通道关闭(close(ch))来处理的。这里,使用缓冲通道不会带来任何好处。
但是如果我们需要一个缓冲通道呢?我们应该提供多大的尺寸?我们应该为缓冲通道使用的默认值是它的最小值:1。因此,我们可以从这个角度来处理这个问题:有什么好的理由不使用1的值吗?这里列出了我们应该使用另一种尺寸的可能情况:
-
使用类似工作器池的模式,意味着旋转固定数量的 goroutines,这些 goroutines 需要将数据发送到共享通道。在这种情况下,我们可以将通道大小与创建的 goroutines 的数量联系起来。
-
使用通道进行限速问题时。例如,如果我们需要通过限制请求数量来加强资源利用率,我们应该根据限制来设置通道大小。
如果我们在这些情况之外,使用不同的通道尺寸应该谨慎。使用幻数设置通道大小的代码库非常常见:
ch := make(chan int, 40)
为什么是40?有什么道理?为什么不是50甚至1000?设置这样的值应该有充分的理由。也许这是在基准测试或性能测试之后决定的。在许多情况下,对这样一个值的基本原理进行注释可能是一个好主意。
让我们记住,决定一个准确的队列大小并不是一个简单的问题。首先,这是 CPU 和内存之间的平衡。值越小,我们面临的 CPU 争用就越多。但是值越大,需要分配的内存就越多。
另一个需要考虑的问题是 2011 年关于 LMAX Disruptor 的白皮书中提到的问题(马丁·汤普森等人; lmax-exchange.github.io/disruptor/files/Disruptor-1.0.pdf ):
由于消费者和生产者之间的速度差异,队列通常总是接近满或接近空。他们很少在一个平衡的中间地带运作,在那里生产和消费的比率是势均力敌的。
因此,很难找到一个稳定准确的通道大小,这意味着一个不会导致太多争用或内存分配浪费的准确值。
这就是为什么,除了所描述的情况,通常最好从默认的通道大小1开始。例如,当不确定时,我们仍然可以使用基准来度量它。
与编程中的几乎任何主题一样,可以发现异常。因此,这一节的目标不是详尽无遗,而是给出创建通道时应该使用什么尺寸的指导。同步是无缓冲通道而非缓冲通道的保证。此外,如果我们需要一个缓冲通道,我们应该记住使用一个作为通道大小的默认值。我们应该通过精确的过程谨慎地决定使用另一个值,并且应该对基本原理进行注释。最后但并非最不重要的一点是,我们要记住,选择缓冲通道也可能导致不明显的死锁,而使用无缓冲通道更容易发现这种死锁。
在下一节中,我们将讨论处理字符串格式时可能出现的副作用。
9.8 #68:忘记字符串格式化可能带来的副作用
格式化字符串是开发者的常用操作,无论是返回错误还是记录消息。然而,在并发应用中工作时,很容易忘记字符串格式的潜在副作用。本节将看到两个具体的例子:一个来自 etcd 存储库,导致数据竞争,另一个导致死锁情况。
9.8.1 etcd 数据竞争
etcd 是在 Go 中实现的分布式键值存储。它被用于许多项目,包括 Kubernetes,来存储所有的集群数据。它提供了与集群交互的 API。例如,Watcher接口用于接收数据变更通知:
type Watcher interface {
// Watch watches on a key or prefix. The watched events will be returned
// through the returned channel.
// ...
Watch(ctx context.Context, key string, opts ...OpOption) WatchChan
Close() error
}
API 依赖于 gRPC 流。如果你不熟悉它,它是一种在客户机和服务器之间不断交换数据的技术。服务器必须维护使用该函数的所有客户端的列表。因此,Watcher接口由包含所有活动流的watcher结构实现:
type watcher struct {
// ...
// streams hold all the active gRPC streams keyed by ctx value.
streams map[string]*watchGrpcStream
}
该映射的键基于调用Watch方法时提供的上下文:
func (w *watcher) Watch(ctx context.Context, key string,
opts ...OpOption) WatchChan {
// ...
ctxKey := fmt.Sprintf("%v", ctx) // ❶
// ...
wgs := w.streams[ctxKey]
// ...
❶ 根据提供的上下文格式化映射键
ctxKey是映射的键,由客户端提供的上下文格式化。当格式化由值(context.WithValue)创建的上下文中的字符串时,Go 将读取该上下文中的所有值。在这种情况下,etcd 开发人员发现提供给Watch的上下文在某些条件下是包含可变值(例如,指向结构的指针)的上下文。他们发现了一种情况,其中一个 goroutine 正在更新一个上下文值,而另一个正在执行Watch,因此读取这个上下文中的所有值。这导致了一场数据竞争。
修复(github.com/etcd-io/etcd/pull/7816)是不依赖fmt.Sprintf来格式化映射的键,以防止遍历和读取上下文中的包装值链。相反,解决方案是实现一个定制的streamKeyFromCtx函数,从特定的不可变的上下文值中提取键。
注意:上下文中潜在的可变值会引入额外的复杂性,以防止数据竞争。这可能是一个需要仔细考虑的设计决策。
这个例子说明了我们必须小心并发应用中字符串格式化的副作用——在这个例子中,是数据竞争。在下面的例子中,我们将看到导致死锁情况的副作用。
9.8.2 死锁
假设我们必须处理一个可以并发访问的Customer结构。我们将使用sync.RWMutex来保护访问,无论是读还是写。我们将实现一个UpdateAge方法来更新客户的年龄,并检查年龄是否为正数。同时,我们将实现和Stringer接口。
你能看出这段代码中的问题是什么吗?一个Customer结构公开了一个UpdateAge方法,而实现了fmt.Stringer接口。
type Customer struct {
mutex sync.RWMutex // ❶
id string
age int
}
func (c *Customer) UpdateAge(age int) error {
c.mutex.Lock() // ❷
defer c.mutex.Unlock()
if age < 0 {
// ❸
return fmt.Errorf("age should be positive for customer %v", c)
}
c.age = age
return nil
}
func (c *Customer) String() string {
c.mutex.RLock() // ❹
defer c.mutex.RUnlock()
return fmt.Sprintf("id %s, age %d", c.id, c.age)
}
❶ 使用sync.RWMutex保护并发访问
❷ 锁定并延迟解锁,因为我们更新客户
❸ 如果年龄为负,将返回错误
❹ 锁定和延迟解锁,因为我们读取客户
这里的问题可能并不简单。如果提供的age是负的,我们返回一个错误。因为错误被格式化了,使用接收者上的%s指令,它将调用String方法来格式化Customer。但是因为UpdateAge已经获得了互斥锁,所以String方法将无法获得互斥锁(见图 9.10)。

图 9.10 如果age为负,执行UpdateAge
因此,这会导致死锁情况。如果所有的 goroutines 也睡着了,就会导致恐慌:
fatal error: all goroutines are asleep - deadlock!
goroutine 1 [semacquire]:
sync.runtime_SemacquireMutex(0xc00009818c, 0x10b7d00, 0x0)
...
这种情况应该怎么处理?首先,它说明了单元测试的重要性。在这种情况下,我们可能会认为创建一个负年龄的测试是不值得的,因为逻辑非常简单。然而,没有适当的测试覆盖,我们可能会错过这个问题。
这里可以改进的一点是限制互斥锁的范围。在UpdateAge中,我们首先获取锁并检查输入是否有效。我们应该反其道而行之:首先检查输入,如果输入有效,就获取锁。这有利于减少潜在的副作用,但也会对性能产生影响——仅在需要时才获取锁,而不是在此之前:
func (c *Customer) UpdateAge(age int) error {
if age < 0 {
return fmt.Errorf("age should be positive for customer %v", c)
}
c.mutex.Lock() // ❶
defer c.mutex.Unlock()
c.age = age
return nil
}
只有当输入被验证后,❶才会锁定互斥体
在我们的例子中,只有在检查了年龄之后才锁定互斥体可以避免死锁情况。如果年龄为负,则调用String而不事先锁定互斥体。
但是,在某些情况下,限制互斥锁的范围并不简单,也不可能。在这种情况下,我们必须非常小心字符串格式。也许我们想调用另一个不试图获取互斥体的函数,或者我们只想改变我们格式化错误的方式,这样它就不会调用的String方法。例如,下面的代码不会导致死锁,因为我们只在直接访问id字段时记录客户 ID:
func (c *Customer) UpdateAge(age int) error {
c.mutex.Lock()
defer c.mutex.Unlock()
if age < 0 {
return fmt.Errorf("age should be positive for customer id %s", c.id)
}
c.age = age
return nil
}
我们已经看到了两个具体的例子,一个格式化上下文中的键,另一个返回格式化结构的错误。在这两种情况下,格式化字符串都会导致一个问题:数据竞争和死锁情况。因此,在并发应用中,我们应该对字符串格式化可能产生的副作用保持谨慎。
下一节讨论并发调用append时的行为。
9.9 #69:使用append创建数据竞争
我们之前提到过什么是数据竞争,有哪些影响。现在,让我们看看片,以及使用append向片添加元素是否是无数据竞争的。剧透?看情况。
在下面的例子中,我们将初始化一个切片并创建两个 goroutines,这两个 goroutines 将使用append创建一个带有附加元素的新切片:
s := make([]int, 1)
go func() {
// ❶
s1 := append(s, 1)
fmt.Println(s1)
}()
go func() {
// ❷
s2 := append(s, 1)
fmt.Println(s2)
}()
❶ 在一个新的 goroutine 中,在s上追加了一个新元素
❷ 相同
你相信这个例子有数据竞争吗?答案是否定的。
我们必须回忆一下第 3 章中描述的一些切片基础知识。切片由数组支持,有两个属性:长度和容量。长度是切片中可用元素的数量,而容量是后备数组中元素的总数。当我们使用append时,行为取决于切片是否已满(长度==容量)。如果是,Go 运行时创建一个新的后备数组来添加新元素;否则,运行库会将其添加到现有的后备数组中。
在这个例子中,我们用make([]int, 1)创建一个切片。该代码创建一个长度为一、容量为一的切片。因此,因为切片已满,所以在每个 goroutine 中使用append会返回一个由新数组支持的切片。它不会改变现有的数组;因此,它不会导致数据竞争。
现在,让我们运行同一个例子,只是在初始化s的方式上稍作改变。我们不是创建长度为1的切片,而是创建长度为0但容量为1的切片:
s := make([]int, 0, 1) // ❶
// Same
❶ 改变了切片初始化的方式
这个新例子怎么样?是否包含数据竞争?答案是肯定的:
==================
WARNING: DATA RACE
Write at 0x00c00009e080 by goroutine 10:
...
Previous write at 0x00c00009e080 by goroutine 9:
...
==================
我们用make([]int, 0, 1)创建一个切片。因此,数组没有满。两个 goroutines 都试图更新后备数组的同一个索引(索引 1),这是一种数据竞争。
如果我们希望两个 goroutines 都在一个包含初始元素s和一个额外元素的片上工作,我们如何防止数据竞争?一种解决方案是创建s的副本:
s := make([]int, 0, 1)
go func() {
sCopy := make([]int, len(s), cap(s))
copy(sCopy, s) // ❶
s1 := append(sCopy, 1)
fmt.Println(s1)
}()
go func() {
sCopy := make([]int, len(s), cap(s))
copy(sCopy, s) // ❷
s2 := append(sCopy, 1)
fmt.Println(s2)
}()
❶ 制作了一个副本,并在拷贝的切片上使用了append
❷ 相同
两个 goroutines 都会制作切片的副本。然后他们在切片副本上使用append,而不是原始切片。这防止了数据竞争,因为两个 goroutines 都处理孤立的数据。
切片和映射的数据竞争
数据竞争对切片和映射的影响有多大?当我们有多个 goroutines 时,以下为真:
-
用至少一个 goroutine 更新值来访问同一个片索引是一种数据竞争。goroutines 访问相同的内存位置。
-
不管操作如何,访问不同的片索引不是数据竞争;不同的索引意味着不同的内存位置。
-
用至少一个 goroutine 更新来访问同一个映射(不管它是相同的还是不同的键)是一种数据竞争。为什么这与切片数据结构不同?正如我们在第 3 章中提到的,映射是一个桶数组,每个桶是一个指向键值对数组的指针。哈希算法用于确定桶的数组索引。因为该算法在映射初始化期间包含一些随机性,所以一次执行可能导致相同的数组索引,而另一次执行可能不会。竞争检测器通过发出警告来处理这种情况,而不管实际的数据竞争是否发生。
当在并发上下文中使用片时,我们必须记住在片上使用append并不总是无竞争的。根据切片以及切片是否已满,行为会发生变化。如果切片已满,append是无竞争的。否则,多个 goroutines 可能会竞争更新同一个数组索引,从而导致数据竞争。
一般来说,我们不应该根据片是否已满而有不同的实现。我们应该考虑到在并发应用中的共享片上使用append会导致数据竞争。因此,应该避免使用它。
现在,让我们讨论一个切片和映射上不精确互斥锁的常见错误。
9.10 #70:对切片和映射不正确地使用互斥
在数据可变和共享的并发环境中工作时,我们经常需要使用互斥体来实现对数据结构的保护访问。一个常见的错误是在处理切片和贴图时不准确地使用互斥。让我们看一个具体的例子,了解潜在的问题。
我们将实现一个用于处理客户余额缓存的Cache结构。该结构将包含每个客户 ID 的余额映射和一个互斥体,以保护并发访问:
type Cache struct {
mu sync.RWMutex
balances map[string]float64
}
注意这个解决方案使用一个sync.RWMutex来允许多个读者,只要没有作者。
接下来,我们添加一个AddBalance方法来改变balances图。改变是在一个临界区中完成的(在互斥锁和互斥解锁内):
func (c *Cache) AddBalance(id string, balance float64) {
c.mu.Lock()
c.balances[id] = balance
c.mu.Unlock()
}
同时,我们必须实现一个方法来计算所有客户的平均余额。一种想法是这样处理最小临界区:
func (c *Cache) AverageBalance() float64 {
c.mu.RLock()
balances := c.balances // ❶
c.mu.RUnlock()
sum := 0.
for _, balance := range balances {
// ❷
sum += balance
}
return sum / float64(len(balances))
}
❶ 创建了balances的副本
❷ 在临界区之外迭代副本
首先,我们创建一个映射到本地balances变量的副本。仅在临界区中进行复制,以迭代每个余额,并计算临界区之外的平均值。这个解决方案有效吗?
如果我们使用带有两个并发 goroutines 的-race标志运行测试,一个调用AddBalance(因此改变balances),另一个调用AverageBalance,就会发生数据竞争。这里有什么问题?
在内部,映射是一个runtime.hmap结构,主要包含元数据(例如,计数器)和引用数据桶的指针。所以,balances := c.balances不会复制实际的数据。切片也是同样的原理:
s1 := []int{
1, 2, 3}
s2 := s1
s2[0] = 42
fmt.Println(s1)
即使我们修改了s2,打印s1也会返回[42 2 3]。原因是s2 := s1创建了一个新的切片:s2与s1有相同的长度和相同的容量,并由相同的数组支持。
回到我们的例子,我们给balances分配一个新的映射,引用与c.balances相同的数据桶。同时,两个 goroutines 对同一个数据集执行操作,其中一个对它进行了改变。因此,这是一场数据竞争。我们如何解决数据竞争?我们有两个选择。
如果迭代操作并不繁重(这里就是这种情况,因为我们执行增量操作),我们应该保护整个函数:
func (c *Cache) AverageBalance() float64 {
c.mu.RLock()
defer c.mu.RUnlock() // ❶
sum := 0.
for _, balance := range c.balances {
sum += balance
}
return sum / float64(len(c.balances))
}
函数返回时,❶解锁
临界区现在包含了整个函数,包括迭代。这可以防止数据竞争。
如果迭代操作不是轻量级的,另一个选择是处理数据的实际副本,并且只保护副本:
func (c *Cache) AverageBalance() float64 {
c.mu.RLock()
m := make(map[string]float64, len(c.balances)) // ❶
for k, v := range c.balances {
m[k] = v
}
c.mu.RUnlock()
sum := 0.
for _, balance := range m {
sum += balance
}
return sum / float64(len(m))
}
❶ 复制了这个映射
一旦我们完成了深层拷贝,我们就释放互斥体。迭代是在临界区之外的副本上完成的。
让我们考虑一下这个解决方案。我们必须在映射值上迭代两次:一次是复制,一次是执行操作(这里是增量)。但关键部分只是映射副本。因此,当且仅当操作不是快速时,这种解决方案可能是一个很好的选择。例如,如果一个操作需要调用外部数据库,这个解决方案可能会更有效。在选择一个解决方案或另一个解决方案时,不可能定义一个阈值,因为选择取决于元素数量和结构的平均大小等因素。
总之,我们必须小心互斥锁的边界。在本节中,我们已经看到了为什么将一个现有的映射(或一个现有的片)分配给一个映射不足以防止数据竞争。无论是映射还是切片,新变量都由相同的数据集支持。有两种主要的解决方案可以防止这种情况:保护整个函数,或者处理实际数据的副本。在所有情况下,让我们在设计临界截面时保持谨慎,并确保准确定义边界。
现在让我们讨论一下使用sync.WaitGroup时的一个常见错误。
9.11 #71:误用sync.WaitGroup
sync.WaitGroup是一种等待n操作完成的机制;通常,我们使用它来等待ngoroutines 完成。我们先回忆一下公开的 API 然后,我们将看到一个导致非确定性行为的常见错误。
可以用零值sync.WaitGroup创建一个等待组:
wg := sync.WaitGroup{
}
在内部,sync.WaitGroup保存默认初始化为0的内部计数器。我们可以使用Add(int)方法递增这个计数器,使用带有负值的Done()或Add递减它。如果我们想等待计数器等于0,我们必须使用阻塞的Wait()方法。
注意计数器不能为负,否则 goroutine 将会恐慌。
在下面的例子中,我们将初始化一个等待组,启动三个自动更新计数器的 goroutines,然后等待它们完成。我们希望等待这三个 goroutines 打印计数器的值(应该是3)。你能猜出这段代码是否有问题吗?
wg := sync.WaitGroup{
}
var v uint64
for i := 0; i < 3; i++ {
go func() {
// ❶
wg.Add(1) // ❷
atomic.AddUint64(&v, 1) // ❸
wg.Done() // ❹
}()
}
wg.Wait() // ❺
fmt.Println(v)
❶ 创建了一个 goroutine
❷ 递增等待组计数器
❸ 原子地递增v
❹ 递减等待组计数器
❺ 一直等到所有的 goroutines 都递增了v才打印它
如果我们运行这个例子,我们会得到一个不确定的值:代码可以打印从0到3的任何值。同样,如果我们启用了-race标志,Go 甚至会发生数据竞争。考虑到我们正在使用sync/atomic包来更新v,这怎么可能呢?这个代码有什么问题?
问题是wg.Add(1)是在新创建的 goroutine 中调用的,而不是在父 goroutine 中。因此,不能保证我们已经向等待组表明我们想在调用wg.Wait()之前等待三次 goroutines。
图 9.11 显示了代码打印2时的可能场景。在这个场景中,主 goroutine 旋转了三个 goroutine。但是最后一个 goroutine 是在前两个 goroutine 已经调用了wg.Done()之后执行的,所以父 goroutine 已经解锁。因此,在这种情况下,当主 goroutine 读取v时,它等于2。竞争检测器还可以检测对v的不安全访问。
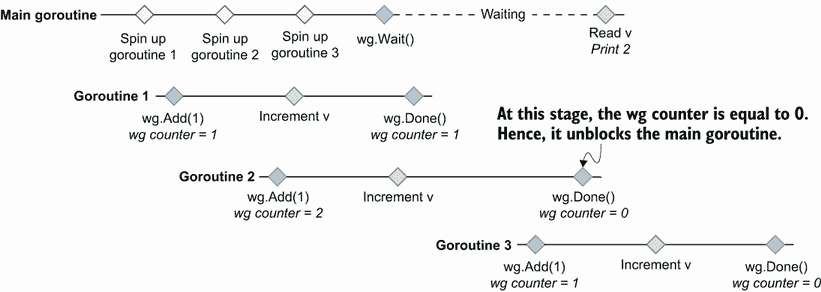
图 9.11 主 goroutine 已经解封后,最后一个 goroutine 调用wg.Add(1)。
在处理 goroutines 时,关键是要记住,没有同步,执行是不确定的。例如,以下代码可以打印ab或ba:
go func() {
fmt.Print("a")
}()
go func() {
fmt.Print("b")
}()
两个 goroutines 都可以分配给不同的线程,不能保证哪个线程会先被执行。
CPU 有来使用内存屏障(也称为内存屏障)来确保顺序。Go 为实现内存栅栏提供了不同的同步技术:例如,sync.WaitGroup支持wg.Add和wg.Wait之间的先发生关系。
回到我们的例子,有两个选项来解决我们的问题。首先,我们可以用 3:
wg := sync.WaitGroup{
}
var v uint64
wg.Add(3)
for i := 0; i < 3; i++ {
go func() {
// ...
}()
}
// ...
或者,第二,我们可以在每次循环迭代中调用wg.Add,然后旋转子 goroutines:
wg := sync.WaitGroup{
}
var v uint64
for i := 0; i < 3; i++ {
wg.Add(1)
go func() {
// ...
}()
}
// ...
两种解决方案都可以。如果我们想要最终设置给等待组计数器的值是预先知道的,那么第一个解决方案可以避免我们不得不多次调用wg.Add。然而,它需要确保在任何地方都使用相同的计数,以避免细微的错误。
让我们小心不要重现这种GO开发者常犯的错误。使用sync.WaitGroup时,Add操作必须在父 goroutine 中启动 goroutine 之前完成,而Done操作必须在 goroutine 中完成。
下面讨论的另一个原语sync包:sync.Cond。
9.12 #72:忘记sync.Cond
在sync包中的同步原语中,sync.Cond可能是使用和理解最少的。但是,它提供了我们用通道无法实现的功能。本节通过一个具体的例子来说明sync.Cond何时有用以及如何使用。
本节中的示例实现了一个捐赠目标机制:一个每当达到特定目标时就会发出警报的应用。我们将有一个 goroutine 负责增加余额(一个更新器 goroutine)。相反,其他 goroutines 将接收更新,并在达到特定目标时打印一条消息(监听 goroutines)。例如,一个 goroutine 正在等待 10 美元的捐赠目标,而另一个正在等待 15 美元的捐赠目标。
第一个简单的解决方案是使用互斥。更新程序 goroutine 每秒增加一次余额。另一方面,监听 goroutines 循环,直到达到它们的捐赠目标:
type Donation struct {
// ❶
mu sync.RWMutex
balance int
}
donation := &Donation{
}
// Listener goroutines
f := func(goal int) {
// ❷
donation.mu.RLock()
for donation.balance < goal {
// ❸
donation.mu.RUnlock()
donation.mu.RLock()
}
fmt.Printf("$%d goal reached\n", donation.balance)
donation.mu.RUnlock()
}
go f(10)
go f(15)
// Updater goroutine
go func() {
for {
// ❹
time.Sleep(time.Second)
donation.mu.Lock()
donation.balance++
donation.mu.Unlock()
}
}()
❶ 创建并实例化包含当前余额和互斥体的Donation结构
❷ 创建了一个目标
❸ 检查目标是否达到
❹ 不断增加余额
我们使用互斥来保护对共享的donation.balance变量的访问。如果我们运行这个示例,它会像预期的那样工作:
$10 goal reached
$15 goal reached
主要问题——也是使这种实现变得糟糕的原因——是繁忙循环。每个监听 goroutine 一直循环,直到达到它的捐赠目标,这浪费了大量的 CPU 周期,并使 CPU 的使用量巨大。我们需要找到一个更好的解决方案。
让我们后退一步。每当平衡被更新时,我们必须找到一种方法从更新程序发出信号。如果我们考虑GO中的信令,就要考虑通道。因此,让我们尝试使用通道原语的另一个版本:
type Donation struct {
balance int
ch chan int // ❶
}
donation := &Donation{
ch: make(chan int)}
// Listener goroutines
f := func(goal int) {
for balance := range donation.ch {
// ❷
if balance >= goal {
fmt.Printf("$%d goal reached\n", balance)
return
}
}
}
go f(10)
go f(15)
// Updater goroutine
for {
time.Sleep(time.Second)
donation.balance++
donation.ch <- donation.balance // ❸
}
❶ 更新Donation,所以它包含一个通道
❷ 从通道接收更新
❸ 每当余额更新时,都会发送一条消息
每个监听程序从一个共享的通道接收。与此同时,每当余额更新时,更新程序 goroutine 就会发送消息。但是,如果我们尝试一下这个解决方案,下面是一个可能的输出:
$11 goal reached
$15 goal reached
当余额为 10 美元而不是 11 美元时,应该通知第一个 goroutine。发生了什么事?
发送到通道的消息只能由一个 goroutine 接收。在我们的例子中,如果第一个 goroutine 在第二个之前从通道接收,图 9.12 显示了可能发生的情况。

图 9.12 第一个 goroutine 接收$1 消息,然后第二个 goroutine 接收$2 消息,然后第一个 goroutine 接收$3 消息,依此类推。
从共享通道接收多个 goroutines 的默认分发模式是循环调度。如果一个 goroutine 没有准备好接收消息(没有在通道上处于等待状态),它可能会改变;在这种情况下,Go 将消息分发到下一个可用的 goroutine。
每条消息都由一个单独的 goroutine 接收。因此,在这个例子中,第一个 goroutine 没有收到 10 美元消息,但是第二个收到了。只有一个通道关闭事件可以广播到多个 goroutines。但是这里我们不想关闭通道,因为那样的话更新程序 goroutine 就不能发送消息了。
在这种情况下使用通道还有另一个问题。只要达到了捐赠目标,监听器就会回来。因此,更新程序 goroutine 必须知道所有监听器何时停止接收到该通道的消息。否则,通道最终会变满,阻塞发送方。一个可能的解决方案是在组合中添加一个sync.WaitGroup,但是这样做会使解决方案更加复杂。
理想情况下,我们需要找到一种方法,每当余额更新到多个 goroutines 时,重复广播通知。好在 Go 有解:sync.Cond。我们先讨论理论;然后我们将看到如何使用这个原语解决我们的问题。
根据官方文档(pkg.go.dev/sync),
Cond 实现了一个条件变量,即等待或宣布事件发生的 goroutines 的集合点。
条件变量是等待特定条件的线程(这里是 goroutines)的容器。在我们的例子中,条件是余额更新。每当余额更新时,更新程序 gorroutine 就会广播一个通知,监听程序 gorroutine 会一直等到更新。此外,sync.Cond依靠一个sync.Locker(一个*sync .Mutex或*sync.RWMutex)来防止数据竞争。下面是一个可能的实现:
type Donation struct {
cond *sync.Cond // ❶
balance int
}
donation := &Donation{
cond: sync.NewCond(&sync.Mutex{
}), // ❷
}
// Listener goroutines
f := func(goal int) {
donation.cond.L.Lock()
for donation.balance < goal {
donation.cond.Wait() // ❸
}
fmt.Printf("%d$ goal reached\n", donation.balance)
donation.cond.L.Unlock()
}
go f(10)
go f(15)
// Updater goroutine
for {
time.Sleep(time.Second)
donation.cond.L.Lock()
donation.balance++ // ❹
donation.cond.L.Unlock()
donation.cond.Broadcast() // ❺
}
❶ 添加一个*sync.Cond
❷ *sync.Cond依赖于互斥体。
❸ 在锁定/解锁状态下等待条件(余额更新)
❹ 在锁定/解锁范围内增加余额
❺ 广播满足条件的事实(余额更新)
首先,我们使用sync.NewCond创建一个*sync.Cond,并提供一个*sync.Mutex。监听器和更新程序 goroutines 呢?
监听 goroutines 循环,直到达到捐赠余额。在循环中,我们使用Wait方法,该方法一直阻塞到满足条件。
注意,让我们确保术语条件在这里得到理解。在这种情况下,我们讨论的是更新余额,而不是捐赠目标条件。所以,这是两个监听器共享的一个条件变量。
对Wait的调用必须发生在临界区内,这听起来可能有些奇怪。锁不会阻止其他 goroutines 等待相同的条件吗?实际上,Wait的实现是这样的:
-
解锁互斥体。
-
暂停 goroutine,并等待通知。
-
通知到达时锁定互斥体。
因此,监听 goroutines 有两个关键部分:
-
访问
for donation.balance < goal中的donation.balance时 -
访问
fmt.Printf中的donation.balance时
这样,对共享donation.balance变量的所有访问都受到保护。
现在,更新程序 goroutine 怎么样了?平衡更新在临界区内完成,以防止数据竞争。然后我们调用Broadcast方法,它在每次余额更新时唤醒所有等待条件的 goroutines。
因此,如果我们运行这个示例,它会打印出我们期望的结果:
10$ goal reached
15$ goal reached
在我们的实现中,条件变量基于正在更新的余额。因此,监听器变量在每次进行新的捐赠时都会被唤醒,以检查它们的捐赠目标是否达到。这种解决方案可以防止我们在重复检查中出现消耗 CPU 周期的繁忙循环。
让我们也注意一下使用sync.Cond时的一个可能的缺点。当我们发送一个通知时——例如,发送给一个chan struct——即使没有活动的接收者,消息也会被缓冲,这保证了这个通知最终会被接收到。使用sync.Cond和Broadcast方法唤醒当前等待该条件的所有 goroutines 如果没有,通知将被错过。这也是我们必须牢记的基本原则。
信号()与广播()
我们可以使用Signal()而不是Broadcast()来唤醒单个 goroutine。就语义而言,它与以非阻塞方式在chan struct中发送消息是一样的:
ch := make(chan struct{
})
select {
case ch <- struct{
}{
}:
default:
}
GO中的信令可以用通道来实现。多个 goroutines 可以捕获的唯一事件是通道关闭,但这只能发生一次。因此,如果我们重复向多个 goroutines 发送通知,sync.Cond是一个解决方案。这个原语基于条件变量,这些变量设置了等待特定条件的线程容器。使用sync.Cond,我们可以广播信号来唤醒所有等待某个条件的 goroutines。
让我们使用golang.org/x和errgroup包来扩展我们关于并发原语的知识。
9.13 #73:不使用errgroup
不管什么编程语言,多此一举很少是个好主意。代码库重新实现如何旋转多个 goroutines 并聚合错误也很常见。但是 Go 生态系统中的一个包就是为了支持这种频繁的用例而设计的。让我们看看它,并理解为什么它应该成为 Go 开发者工具集的一部分。
是一个为标准库提供扩展的库。sync子库包含一个便利的包:errgroup。
假设我们必须处理一个函数,我们接收一些数据作为参数,我们希望用这些数据来调用外部服务。由于条件限制,我们不能打一个电话;我们每次都用不同的子集打多个电话。此外,这些调用是并行进行的(参见图 9.13)。
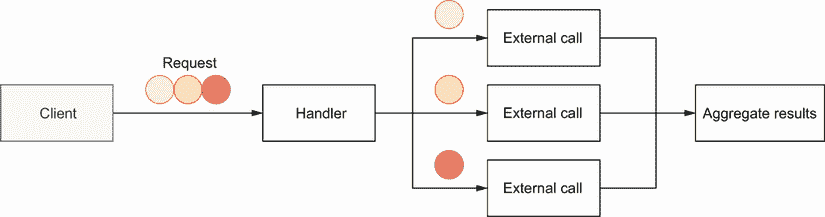
图 9.13 每个圆圈导致一个并行调用。
万一通话过程中出现错误,我们希望返回。如果有多个错误,我们只想返回其中一个。让我们只使用标准的并发原语来编写实现的框架:
func handler(ctx context.Context, circles []Circle) ([]Result, error) {
results := make([]Result, len(circles))
wg := sync.WaitGroup{
} // ❶
wg.Add(len(results))
for i, circle := range circles {
i := i // ❷
circle := circle // ❸
go func() {
// ❹
defer wg.Done() // ❺
result, err := foo(ctx, circle)
if err != nil {
// ?
}
results[i] = result // ❻
}()
}
wg.Wait()
// ...
}
❶ 创建了一个等待组来等待我们旋转的所有 goroutines
❷ 在 goroutine 中创建了一个新的i变量(参见错误#63,“不小心使用 goroutine 和循环变量”)
❸ 同样适用于circle
❹ 每个循环触发一次 goroutine
❺ 指示 goroutine 何时完成
❻ 汇总了结果
我们决定使用一个sync.WaitGroup来等待所有的 goroutines 完成,并在一个片上处理聚合。这是做这件事的一种方法;另一种方法是将每个部分结果发送到一个通道,并在另一个 goroutine 中聚合它们。如果需要排序,主要的挑战将是重新排序传入的消息。因此,我们决定采用最简单的方法和共享切片。
注意因为每个 goroutine 都写入一个特定的索引,所以这个实现是无数据竞争的。
然而,有一个关键案例我们还没有解决。如果foo(在新的 goroutine 中进行的调用)返回一个错误怎么办?应该怎么处理?有各种选项,包括:
-
就像
results切片一样,我们可以在 goroutines 之间共享一个错误切片。每个 goroutine 都会在出错时写入这个片。我们必须在父 goroutine 中迭代这个切片,以确定是否发生了错误(O(n)时间复杂度)。 -
我们可以通过一个共享互斥体让 goroutines 访问一个错误变量。
-
我们可以考虑共享一个错误通道,父 goroutine 将接收并处理这些错误。
不管选择哪个选项,它都会使解决方案变得非常复杂。出于这个原因,errgroup包是设计和开发的。
它导出一个函数WithContext,这个函数返回一个给定上下文的*Group结构。该结构为一组 goroutines 提供同步、错误传播和上下文取消,并且只导出两种方法:
-
Go在新的 goroutine 中触发调用。 -
Wait阻塞,直到所有程序完成。它返回第一个非零错误(如果有)。
让我们使用errgroup重写解决方案。首先我们需要导入errgroup包:
$ go get golang.org/x/sync/errgroup
实现如下:
func handler(ctx context.Context, circles []Circle) ([]Result, error) {
results := make([]Result, len(circles))
g, ctx := errgroup.WithContext(ctx) // ❶
for i, circle := range circles {
i := i
circle := circle
g.Go(func() error {
// ❷
result, err := foo(ctx, circle)
if err != nil {
return err
}
results[i] = result
return nil
})
}
if err := g.Wait(); err != nil {
// ❸
return nil, err
}
return results, nil
}
❶ 创建了一个errgroup。给定父上下文的组
❷ 调用 Go 来提升处理错误的逻辑,并将结果聚合到一个新的 goroutine 中
❸ 调用Wait来等待所有的 goroutines
首先,我们通过提供父上下文来创建和*errgroup.Group。在每次迭代中,我们使用g.Go在新的 goroutine 中触发一个调用。这个方法将一个func() error作为输入,用一个闭包包装对foo的调用,并处理结果和错误。与我们第一个实现的主要区别是,如果我们得到一个错误,我们从这个闭包返回它。然后,g.Wait允许我们等待所有的 goroutines 完成。
这个解决方案本质上比第一个更简单(第一个是部分的,因为我们没有处理错误)。我们不必依赖额外的并发原语,并且errgroup.Group足以处理我们的用例。
我们还没有解决的另一个好处是共享环境。假设我们必须触发三个并行调用:
-
第一个在 1 毫秒内返回一个错误。
-
第二次和第三次调用在 5 秒内返回结果或错误。
我们想要返回一个错误,如果有的话。因此,没有必要等到第二次和第三次通话结束。使用errgroup.WithContext创建一个在所有并行调用中使用的共享上下文。因为第一个调用在 1 毫秒内返回一个错误,所以它将取消上下文,从而取消其他 goroutines。所以,我们不必等 5 秒钟就返回一个错误。这是使用errgroup的另一个好处。
注意由g.Go调用的流程必须是上下文感知的。否则,取消上下文不会有任何效果。
总之,当我们必须触发多个 goroutines 并处理错误和上下文传播时,可能值得考虑errgroup是否是一个解决方案。正如我们所看到的,这个包支持一组 goroutines 的同步,并提供了处理错误和共享上下文的答案。
本章的最后一节讨论了 Go 开发者在复制sync 类型时的一个常见错误。
9.14 #74:复制同步类型
sync包提供了基本的同步原语,比如互斥、条件变量和等待组。对于所有这些类型,有一个硬性规则要遵循:它们永远不应该被复制。让我们了解一下基本原理和可能出现的问题。
我们将创建一个线程安全的数据结构来存储计数器。它将包含一个代表每个计数器当前值的map[string]int。我们还将使用一个sync.Mutex,因为访问必须受到保护。让我们添加一个increment方法来递增给定的计数器名称:
type Counter struct {
mu sync.Mutex
counters map[string]int
}
func NewCounter() Counter {
// ❶
return Counter{
counters: map[string]int{
}}
}
func (c Counter) Increment(name string) {
c.mu.Lock() // ❷
defer c.mu.Unlock()
c.counters[name]++
}
❶ 工厂函数
❷ 在临界区增加计数器
增量逻辑在一个临界区完成:在c.mu.Lock()和c.mu .Unlock()之间。让我们通过使用和-race选项运行下面的例子来尝试我们的方法,该例子加速两个 goroutines 并递增它们各自的计数器:
counter := NewCounter()
go func() {
counter.Increment("foo")
}()
go func() {
counter.Increment("bar")
}()
如果我们运行这个例子,它会引发一场数据竞争:
==================
WARNING: DATA RACE
...
我们的Counter实现中的问题是互斥体被复制了。因为Increment的接收者是一个值,所以每当我们调用Increment时,它执行Counter结构的复制,这也复制了互斥体。因此,增量不是在共享的临界区中完成的。
sync不应复制类型。此规则适用于以下类型:
-
sync.Cond -
sync.Map -
sync.Mutex -
sync.RWMutex -
sync.Once -
sync.Pool -
sync.WaitGroup
因此,互斥体不应该被复制。有哪些替代方案?
首先是修改Increment方法的接收器类型:
func (c *Counter) Increment(name string) {
// Same code
}
改变接收器类型可避免调用Increment时复制Counter。因此,内部互斥体不会被复制。
如果我们想保留一个值接收器,第二个选项是将Counter中的mu字段的类型改为指针:
type Counter struct {
mu *sync.Mutex // ❶
counters map[string]int
}
func NewCounter() Counter {
return Counter{
mu: &sync.Mutex{
}, // ❷
counters: map[string]int{
},
}
}
❶ 改变了mu的类型
❷ 改变了Mutex的初始化方式
如果Increment有一个值接收器,它仍然复制Counter结构。然而,由于mu现在是一个指针,它将只执行指针复制,而不是sync.Mutex的实际复制。因此,这种解决方案也防止了数据竞争。
注意我们也改变了mu的初始化方式。因为mu是一个指针,如果我们在创建Counter的时候省略了它,那么它会被初始化为一个指针的零值:nil。这将导致调用c.mu.Lock()时 goroutine 恐慌。
在以下情况下,我们可能会面临无意中复制sync字段的问题:
-
调用带有值接收器的方法(如我们所见)
-
调用带有
sync参数的函数 -
调用带有包含
sync字段的参数的函数
在每一种情况下,我们都应该非常谨慎。另外,让我们注意一些 linters 可以捕捉到这个问题——例如,使用go vet:
$ go vet .
./main.go:19:9: Increment passes lock by value: Counter contains sync.Mutex
根据经验,每当多个 goroutines 必须访问一个公共的sync元素时,我们必须确保它们都依赖于同一个实例。这个规则适用于包sync中定义的所有类型。使用指针是解决这个问题的一种方法:我们可以有一个指向sync元素的指针,或者一个指向包含sync元素的结构的指针。
总结
-
在传播上下文时,理解可以取消上下文的条件应该很重要:例如,当响应已经发送时,HTTP 处理器取消上下文。
-
避免泄露意味着无论何时启动 goroutine,你都应该有一个最终阻止它的计划。
-
为了避免 goroutines 和循环变量的错误,创建局部变量或调用函数,而不是闭包。
-
了解拥有多个通道的
select在多个选项可能的情况下随机选择案例,可以防止做出错误的假设,从而导致微妙的并发错误。 -
使用
chan struct{}类型发送通知。 -
使用
nil通道应该是你的并发工具集的一部分,因为它允许你从select语句中移除用例。 -
给定一个问题,仔细决定要使用的正确通道类型。只有无缓冲通道才能提供强同步保证。
-
除了为缓冲通道指定通道尺寸之外,您应该有一个很好的理由来指定通道尺寸。
-
意识到字符串格式化可能会导致调用现有函数意味着要小心可能的死锁和其他数据竞争。
-
调用
append并不总是无数据竞争的;因此,它不应该在共享片上并发使用。 -
记住切片和图是指针可以防止常见的数据竞争。
-
为了准确地使用
sync.WaitGroup,在旋转 goroutines 之前调用Add方法。 -
您可以使用
sync.Cond向多个 goroutines 发送重复通知。 -
你可以同步一组 goroutines,并用
errgroup包处理错误和上下文。 -
sync不该复制的类型。
十、标准库
本章涵盖
- 提供正确的持续时间
- 使用
time.After时了解潜在的内存泄漏 - 避免 JSON 处理和 SQL 中的常见错误
- 关闭暂态资源
- 记住 HTTP 处理器中的
return语句 - 为什么生产级应用不应该使用默认的 HTTP 客户端和服务器
Go 标准库是一组增强和扩展该语言的核心包。例如,Go 开发人员可以编写 HTTP 客户端或服务器,处理 JSON 数据,或者与 SQL 数据库进行交互。所有这些特性都由标准库提供。然而,误用标准库是很容易的,或者我们可能对它的行为了解有限,这可能导致错误和编写不应该被认为是生产级的应用。让我们看看使用标准库时最常见的一些错误。
10.1 #75:提供了错误的持续时间
标准库提供了接受time.Duration的通用函数和方法。然而,因为time.Duration是int64类型的别名,对这种语言的新来者可能会感到困惑,并提供错误的持续时间。例如,具有 Java 或 JavaScript 背景的开发人员习惯于传递数值类型。
为了说明这个常见的错误,让我们创建一个新的time.Ticker,它将提供每秒钟的时钟滴答声:
ticker := time.NewTicker(1000)
for {
select {
case <-ticker.C:
// Do something
}
}
如果我们运行这段代码,我们会注意到分笔成交点不是每秒都有;它们每微秒传送一次。
因为time.Duration基于int64类型,所以之前的代码是正确的,因为1000是有效的int64。但是time.Duration代表两个瞬间之间经过的时间,单位为纳秒。所以我们给NewTicker提供了 1000 纳秒= 1 微秒的持续时间。
这种错误经常发生。事实上,Java 和 JavaScript 等语言的标准库有时会要求开发人员以毫秒为单位提供持续时间。
此外,如果我们想有目的地创建一个间隔为 1 微秒的time.Ticker,我们不应该直接传递一个int64。相反,我们应该始终使用time.Duration API 来避免可能的混淆:
ticker = time.NewTicker(time.Microsecond)
// Or
ticker = time.NewTicker(1000 * time.Nanosecond)
这并不是本书中最复杂的错误,但是具有其他语言背景的开发人员很容易陷入这样一个陷阱,认为time包中的函数和方法应该是毫秒级的。我们必须记住使用time.Duration API 和提供一个int64和一个时间单位。
现在,让我们讨论一下在使用time.After和包时的一个常见错误。
10.2 #76:time.After和内存泄漏
time.After(time.Duration)是一个方便的函数,它返回一个通道,并在向该通道发送消息之前等待一段规定的时间。通常,它用在并发代码中;否则,如果我们想要睡眠给定的持续时间,我们可以使用time.Sleep(time.Duration)。time.After的优势在于它可以用于实现这样的场景,比如“如果我在这个通道中 5 秒钟没有收到任何消息,我会…"但是代码库经常在循环中包含对time.After的调用,正如我们在本节中所描述的,这可能是内存泄漏的根本原因。
让我们考虑下面的例子。我们将实现一个函数,该函数重复使用来自通道的消息。如果我们超过 1 小时没有收到任何消息,我们也希望记录一个警告。下面是一个可能的实现:
func consumer(ch <-chan Event) {
for {
select {
case event := <-ch: // ❶
handle(event)
case <-time.After(time.Hour): // ❷
log.Println("warning: no messages received")
}
}
}
❶ 处理事件
❷ 递增空闲计数器
这里,我们在两种情况下使用select:从ch接收消息和 1 小时后没有消息(time.After在每次迭代中被求值,因此超时每次被重置)。乍一看,这段代码还不错。但是,这可能会导致内存使用问题。
我们说过,time.After返回一个通道。我们可能期望这个通道在每次循环迭代中都是关闭的,但事实并非如此。一旦超时,由time.After创建的资源(包括通道)将被释放,并使用内存直到超时结束。多少内存?在 Go 1.15 中,每次调用time.After大约使用 200 字节的内存。如果我们收到大量的消息,比如每小时 500 万条,我们的应用将消耗 1 GB 的内存来存储和time.After资源。
我们可以通过在每次迭代中以编程方式关闭通道来解决这个问题吗?不会。返回的通道是一个<-chan time.Time,意味着它是一个只能接收的通道,不能关闭。
我们有几个选择来修正我们的例子。第一种是使用上下文来代替time.After:
func consumer(ch <-chan Event) {
for {
// ❶
ctx, cancel := context.WithTimeout(context.Background(), time.Hour) // ❷
select {
case event := <-ch:
cancel() // ❸
handle(event)
case <-ctx.Done(): // ❹
log.Println("warning: no messages received")
}
}
}
❶ 主循环
❷ 创建了一个超时的上下文
❸ 如果我们收到消息,取消上下文
❹ 上下文取消
这种方法的缺点是,我们必须在每次循环迭代中重新创建一个上下文。创建上下文并不是 Go 中最轻量级的操作:例如,它需要创建一个通道。我们能做得更好吗?
第二个选项来自time包:time.NewTimer。这个函数创建了一个结构,该结构导出了以下内容:
-
一个
C字段,它是内部计时器通道 -
一种
Reset(time.Duration)方法来重置持续时间 -
一个
Stop()方法来停止计时器
时间。内部构件后
我们要注意的是time.After也依赖于time.Timer。但是,它只返回C字段,所以我们无法访问Reset方法:
package time
func After(d Duration) <-chan Time {
return NewTimer(d).C // ❶
}
❶ 创建了一个新计时器并返回通道字段
让我们使用time.NewTimer实现一个新版本:
func consumer(ch <-chan Event) {
timerDuration := 1 * time.Hour
timer := time.NewTimer(timerDuration) // ❶
for {
// ❷
timer.Reset(timerDuration) // ❸
select {
case event := <-ch:
handle(event)
case <-timer.C: // ❹
log.Println("warning: no messages received")
}
}
}
❶ 创建了一个新的计时器
❷ 主循环
❸ 重置持续时间
❹ 计时器到期
在这个实现中,我们在每次循环迭代中保持一个循环动作:调用Reset方法。然而,调用Reset比每次都创建一个新的上下文要简单得多。它速度更快,对垃圾收集器的压力更小,因为它不需要任何新的堆分配。因此,使用time.Timer是我们最初问题的最佳解决方案。
注意为了简单起见,在这个例子中,前面的 goroutine 没有停止。正如我们在错误#62 中提到的,“启动一个 goroutine 却不知道何时停止”,这不是一个最佳实践。在生产级代码中,我们应该找到一个退出条件,比如可以取消的上下文。在这种情况下,我们还应该记得使用defer timer.Stop()停止time.Timer,例如,在timer创建之后。
在循环中使用time.After并不是导致内存消耗高峰的唯一情况。该问题与重复调用的代码有关。循环是一种情况,但是在 HTTP 处理函数中使用time.After会导致同样的问题,因为该函数会被多次调用。
一般情况下,使用time.After时要谨慎。请记住,创建的资源只有在计时器到期时才会被释放。当重复调用time.After时(例如,在一个循环中,一个 Kafka 消费函数,或者一个 HTTP 处理器),可能会导致内存消耗的高峰。在这种情况下,我们应该倾向于time.NewTimer。
下一节讨论 JSON 处理过程中最常见的错误。
10.3 #77:常见的 JSON 处理错误
Go 用encoding/json包对 JSON 有极好的支持。本节涵盖了与编码(编组)和解码(解组)JSON 数据相关的三个常见错误。
10.3.1 类型嵌入导致的意外行为
在错误#10“没有意识到类型嵌入可能存在的问题”中,我们讨论了与类型嵌入相关的问题。在 JSON 处理的上下文中,让我们讨论类型嵌入的另一个潜在影响,它会导致意想不到的封送/解封结果。
在下面的例子中,我们创建了一个包含 ID 和嵌入时间戳的Event结构:
type Event struct {
ID int
time.Time // ❶
}
❶ 嵌入字段
因为time.Time是嵌入式的,以我们之前描述的方式,我们可以在Event级别直接访问和time.Time方法:例如,event .Second()。
JSON 封送处理对嵌入式字段有哪些可能的影响?让我们在下面的例子中找出答案。我们将实例化一个Event,并将其封送到 JSON 中。这段代码的输出应该是什么?
event := Event{
ID: 1234,
Time: time.Now(), // ❶
}
b, err := json.Marshal(event)
if err != nil {
return err
}
fmt.Println(string(b))
❶ 结构实例化期间匿名字段的名称是结构的名称(时间)。
我们可能期望这段代码打印出如下内容:
{
"ID":1234,"Time":"2021-05-18T21:15:08.381652+02:00"}
相反,它会打印以下内容:
"2021-05-18T21:15:08.381652+02:00"
我们如何解释这个输出?ID字段和1234值怎么了?因为此字段是导出的,所以它应该已被封送。要理解这个问题,我们必须强调两点。
首先,正如错误#10 中所讨论的,如果一个嵌入字段类型实现了一个接口,那么包含该嵌入字段的结构也将实现这个接口。其次,我们可以通过让一个类型实现json.Marshaler接口来改变默认的封送处理行为。该接口包含单个MarshalJSON函数:
type Marshaler interface {
MarshalJSON() ([]byte, error)
}
下面是一个自定义封送处理的示例:
type foo struct{
} // ❶
func (foo) MarshalJSON() ([]byte, error) {
// ❷
return []byte(`"foo"`), nil // ❸
}
func main() {
b, err := json.Marshal(foo{
}) // ❹
if err != nil {
panic(err)
}
fmt.Println(string(b))
}
❶ 定义了这个结构
❷ 实现了MarshalJSON方法
❸ 响应了一个静态响应
❹ 然后,json.Marshal依赖于自定义MarshalJSON实现。
因为我们通过实现和Marshaler接口改变了默认的 JSON 封送行为,所以这段代码打印出了"foo"。
澄清了这两点之后,让我们回到最初关于Event结构的问题:
type Event struct {
ID int
time.Time
}
我们必须知道time.Time实现了json.Marshaler接口。因为time.Time是Event的嵌入字段,所以编译器会提升它的方法。因此,Event也实现了json.Marshaler。
因此,向json.Marshal传递一个Event会使用time.Time提供的封送处理行为,而不是默认行为。这就是为什么封送一个Event会导致忽略ID字段。
注意,如果我们使用json.Unmarshal解组一个Event,我们也会面临相反的问题。
要解决这个问题,有两种主要的可能性。首先,我们可以添加一个名称,这样time.Time字段就不再被嵌入:
type Event struct {
ID int
Time time.Time // ❶
}
❶ time.Time不再是嵌入的。
这样,如果我们封送这个Event结构的一个版本,它将打印如下内容:
{
"ID":1234,"Time":"2021-05-18T21:15:08.381652+02:00"}
如果我们希望或者必须保留嵌入的time.Time字段,另一个选择是让Event实现的json.Marshaler接口:
func (e Event) MarshalJSON() ([]byte, error) {
return json.Marshal(
struct {
// ❶
ID int
Time time.Time
}{
ID: e.ID,
Time: e.Time,
},
)
}
❶ 创建了一个匿名结构
在这个解决方案中,我们实现了一个定制的MarshalJSON方法,而定义了一个反映Event结构的匿名结构。但是这种解决方案更麻烦,并且要求我们确保MarshalJSON方法和Event结构总是最新的。
我们应该小心嵌入字段。虽然提升嵌入字段类型的字段和方法有时会很方便,但它也会导致微妙的错误,因为它会使父结构在没有明确信号的情况下实现接口。还是那句话,在使用嵌入字段的时候,要清楚的了解可能产生的副作用。
在下一节中,我们将看到另一个与使用time.Time相关的常见 JSON 错误。
10.3.2 JSON 和单调时钟
当封送或解封一个包含time.Time类型的结构时,我们有时会面临意想不到的比较错误。检查time.Time有助于完善我们的假设并防止可能的错误。
一个操作系统处理两种不同的时钟类型:墙时钟和单调时钟。本节首先看这些时钟类型,然后看使用 JSON 和time.Time时可能产生的影响。
挂钟用来确定一天中的当前时间。这个钟可能会有变化。例如,如果使用网络时间协议(NTP)同步时钟,它可以在时间上向后或向前跳转。我们不应该使用挂钟来测量持续时间,因为我们可能会面临奇怪的行为,例如负持续时间。这就是操作系统提供第二种时钟类型原因:单调时钟。单调时钟保证时间总是向前移动,不受时间跳跃的影响。它会受到频率调整的影响(例如,如果服务器检测到本地石英钟的移动速度与 NTP 服务器不同),但不会受到时间跳跃的影响。
在下面的例子中,我们考虑一个包含单个time.Time字段(非嵌入式)的Event结构:
type Event struct {
Time time.Time
}
我们实例化一个Event,将它封送到 JSON 中,并将其解包到另一个结构中。然后我们比较这两种结构。让我们看看编组/解组过程是否总是对称的:
t := time.Now() // ❶
event1 := Event{
// ❷
Time: t,
}
b, err := json.Marshal(event1) // ❸
if err != nil {
return err
}
var event2 Event
err = json.Unmarshal(b, &event2) // ❹
if err != nil {
return err
}
fmt.Println(event1 == event2)
❶ 得到当前的当地时间
❷ 实例化一个Event结构
❸ 编组 JSON
❹ 解组 JSON
这段代码的输出应该是什么?它打印的是false,不是true。我们如何解释这一点?
首先,让我们打印出event1和event2的内容:
fmt.Println(event1.Time)
fmt.Println(event2.Time)
2021-01-10 17:13:08.852061 +0100 CET m=+0.000338660
2021-01-10 17:13:08.852061 +0100 CET
代码为event1和event2打印不同的内容。除了m=+0.000338660部分,它们是一样的。这是什么意思?
在 Go 中,time.Time可能包含一个挂钟和一个单调时间,而不是将两个时钟分成两个不同的 API。当我们使用time.Now()获得本地时间时,它返回一个time.Time和两个时间:
2021-01-10 17:13:08.852061 +0100 CET m=+0.000338660
------------------------------------ --------------
Wall time Monotonic time
相反,当我们解组 JSON 时,time.Time字段不包含单调时间——只包含墙时间。因此,当我们比较这些结构时,由于单调的时间差,结果是false;这也是为什么我们在打印两个结构时会看到差异。我们如何解决这个问题?有两个主要选项。
当我们使用==操作符来比较两个time.Time字段时,它会比较所有的结构字段,包括单调部分。为了避免这种情况,我们可以使用Equal方法来代替:
fmt.Println(event1.Time.Equal(event2.Time))
true
Equal方法没有考虑单调时间;因此,这段代码打印了true。但是在这种情况下,我们只比较了time.Time字段,而不是父Event结构。
第二个选项是保留==来比较两个结构,但是使用和Truncate方法去除单调时间。该方法返回将time.Time值向下舍入到给定持续时间的倍数的结果。我们可以通过提供零持续时间来使用它,如下所示:
t := time.Now()
event1 := Event{
Time: t.Truncate(0), // ❶
}
b, err := json.Marshal(event1)
if err != nil {
return err
}
var event2 Event
err = json.Unmarshal(b, &event2)
if err != nil {
return err
}
fmt.Println(event1 == event2) // ❷
❶ 剥离了单调的时间
❷ 使用==运算符执行比较
在这个版本中,两个time.Time字段是相等的。因此,这段代码打印了true。
时间。时间和地点
我们还要注意,每个time.Time都与一个代表时区的time.Location相关联。例如:
t := time.Now() // 2021-01-10 17:13:08.852061 +0100 CET
这里,位置被设置为 CET,因为我使用了time.Now(),它返回我当前的本地时间。JSON 封送结果取决于位置。为了防止这种情况,我们可以坚持一个特定的位置:
location, err := time.LoadLocation("America/New_York") // ❶
if err != nil {
return err
}
t := time.Now().In(location) // 2021-05-18 22:47:04.155755 -0500 EST
❶ 获得"America/New_York"的当前位置
或者,我们可以获得 UTC 的当前时间:
t := time.Now().UTC() // 2021-05-18 22:47:04.155755 +0000 UTC
总之,编组/解组过程并不总是对称的,我们面对的这种情况是一个包含time.Time的结构。我们应该记住这个原则,这样我们就不会写错误的测试。
10.3.3 任何的映射
在解组数据的时候,我们可以提供一个映射来代替结构。基本原理是,当键和值不确定时,传递映射比传递静态结构更灵活。然而,有一个规则要记住,以避免错误的假设和可能的恐慌。
让我们编写一个将消息解组到映射中的示例:
b := getMessage()
var m map[string]any
err := json.Unmarshal(b, &m) // ❶
if err != nil {
return err
}
❶ 提供了映射指针
让我们为前面的代码提供以下 JSON:
{
"id": 32,
"name": "foo"
}
因为我们使用了一个通用的map[string]any,它会自动解析所有不同的字段:
map[id:32 name:foo]
然而,如果我们使用any的映射,有一个重要的问题需要记住:任何数值,不管它是否包含小数,都被转换为float64类型。我们可以通过打印m["id"]的类型来观察这一点:
fmt.Printf("%T\n", m["id"])
float64
我们应该确保我们没有做出错误的假设,并期望默认情况下没有小数的数值被转换为整数。例如,对类型转换做出不正确的假设可能会导致 goroutine 崩溃。
下一节讨论编写与 SQL 数据库交互的应用时最常见的错误。
10.4 #78:常见的 SQL 错误
database/sql包为 SQL(或类似 SQL 的)数据库提供了一个通用接口。在使用这个包时,看到一些模式或错误也是相当常见的。让我们深入探讨五个常见错误。
10.4.1 忘记了sql.Open不一定要建立到数据库的连接
使用sql.Open时,一个常见的误解是期望该函数建立到数据库的连接:
db, err := sql.Open("mysql", dsn)
if err != nil {
return err
}
但这不一定是事实。据文献记载(pkg.go.dev/database/sql),
Open 可能只是验证它的参数,而不创建到数据库的连接。
实际上,行为取决于所使用的 SQL 驱动程序。对于某些驱动程序来说,sql.Open并不建立连接:这只是为以后使用做准备(例如,与db.Query)。因此,到数据库的第一个连接可能是延迟建立的。
为什么我们需要了解这种行为?例如,在某些情况下,我们希望只有在我们知道所有的依赖项都已正确设置并且可以访问之后,才准备好服务。如果我们不知道这一点,服务可能会接受流量,尽管配置是错误的。
如果我们想确保使用sql.Open的函数也保证底层数据库是可访问的,我们应该使用Ping方法:
db, err := sql.Open("mysql", dsn)
if err != nil {
return err
}
if err := db.Ping(); err != nil {
// ❶
return err
}
❶ 在sql.Open之后调用Ping方法
Ping强制代码建立一个连接,确保数据源名称有效并且数据库可访问。注意,Ping的另一种选择是PingContext,它要求一个额外的上下文来传达 ping 何时应该被取消或超时。
尽管可能违反直觉,但让我们记住sql.Open不一定建立连接,第一个连接可以被延迟打开。如果我们想测试我们的配置并确保数据库是可达的,我们应该在sql.Open之后调用Ping或PingContext方法。
10.4.2 忘记连接池
正如默认的 HTTP 客户端和服务器提供了在生产中可能无效的默认行为一样(参见错误#81,“使用默认的 HTTP 客户端和服务器”),理解 Go 中如何处理数据库连接是至关重要的。sql.Open返回一个*sql.DB结构。此结构不代表单个数据库连接;相反,它代表一个连接池。这是值得注意的,所以我们不会尝试手动实现它。池中的连接可以有两种状态:
-
已被使用(例如,被另一个触发查询的 goroutine 使用)
-
闲置(已经创建但暂时没有使用)
同样重要的是要记住,创建池会导致四个可用的配置参数,我们可能想要覆盖它们。这些参数中的每一个都是*sql.DB的导出方法:
-
SetMaxOpenConns——数据库的最大打开连接数(默认值:unlimited) -
SetMaxIdleConns——最大空闲连接数(默认值:2) -
SetConnMaxIdleTime——连接关闭前可以空闲的最长时间(默认值:unlimited) -
SetConnMaxLifetime——连接关闭前可以保持打开的最长时间(默认值:unlimited)
图 10.1 显示了一个最多有五个连接的例子。它有四个正在进行的连接:三个空闲,一个在使用中。因此,仍有一个插槽可用于额外的连接。如果有新的查询进来,它将选择一个空闲连接(如果仍然可用)。如果没有更多的空闲连接,如果有额外的时隙可用,池将创建一个新的连接;否则,它将一直等到连接可用。

图 10.1 具有五个连接的连接池
那么,我们为什么要调整这些配置参数呢?
-
设置
SetMaxOpenConns对于生产级应用非常重要。因为默认值是无限制的,所以我们应该设置它以确保它适合底层数据库可以处理的内容。 -
如果我们的应用生成大量并发请求,那么
SetMaxIdleConns(默认:2)的值应该增加。否则,应用可能会经历频繁的重新连接。 -
如果我们的应用可能面临突发的请求,设置
SetConnMaxIdleTime是很重要的。当应用返回到一个更和平的状态时,我们希望确保创建的连接最终被释放。 -
例如,如果我们连接到一个负载平衡的数据库服务器,设置
SetConnMaxLifetime会很有帮助。在这种情况下,我们希望确保我们的应用不会长时间使用连接。
对于生产级应用,我们必须考虑这四个参数。如果一个应用面临不同的用例,我们也可以使用多个连接池。
10.4.3 不使用预准备语句
预准备语句是很多 SQL 数据库为了执行重复的 SQL 语句而实现的功能。在内部,SQL 语句被预编译并与提供的数据分离。有两个主要好处:
-
效率——语句不用重新编译(编译就是解析+优化+翻译)。
-
安全——这种方法降低了 SQL 注入攻击的风险。
因此,如果一个语句是重复的,我们应该使用预准备语句。我们还应该在不受信任的上下文中使用预准备语句(比如在互联网上公开一个端点,其中请求被映射到一个 SQL 语句)。
为了使用预准备语句,我们不调用*sql.DB的Query方法,而是调用Prepare:
stmt, err := db.Prepare("SELECT * FROM ORDER WHERE ID = ?") // ❶
if err != nil {
return err
}
rows, err := stmt.Query(id) // ❷
// ...
❶ 预准备语句
❷ 执行准备好的查询
我们准备语句,然后在提供参数的同时执行它。Prepare方法的第一个输出是一个*sql.Stmt,它可以被重用和并发运行。当不再需要该语句时,必须使用和Close()方法将其关闭。
注意,Prepare和Query方法提供了另外一个上下文:PrepareContext和QueryContext。
为了效率和安全,我们需要记住在有意义的时候使用预准备语句。
10.4.4 错误处理空值
下一个错误是用查询错误处理空值。让我们写一个例子,其中我们检索雇员的部门和年龄:
rows, err := db.Query("SELECT DEP, AGE FROM EMP WHERE ID = ?", id) // ❶
if err != nil {
return err
}
// Defer closing rows
var (
department string
age int
)
for rows.Next() {
err := rows.Scan(&department, &age) // ❷
if err != nil {
return err
}
// ...
}
❶ 执行查询
❷ 扫描每一行
我们使用Query来执行一个查询。然后,我们对行进行迭代,并使用Scan将列复制到由department和age指针指向的值中。如果我们运行这个例子,我们可能会在调用Scan时得到以下错误:
2021/10/29 17:58:05 sql: Scan error on column index 0, name "DEPARTMENT":
converting NULL to string is unsupported
这里,SQL 驱动程序引发了一个错误,因为部门值等于NULL。如果一个列可以为空,有两个选项可以防止Scan返回错误。
第一种方法是将department声明为字符串指针:
var (
department *string // ❶
age int
)
for rows.Next() {
err := rows.Scan(&department, &age)
// ...
}
❶ 将类型从字符串更改为*string
我们给scan提供的是指针的地址,而不是直接字符串类型的地址。通过这样做,如果值为NULL,department将为nil。
另一种方法是使用sql.NullXXX类型中的,如sql.NullString:
var (
department sql.NullString // ❶
age int
)
for rows.Next() {
err := rows.Scan(&department, &age)
// ...
}
❶ 将类型更改为sql.NullString
sql.NullString是字符串顶部的包装。它包含两个导出字段:String包含字符串值,Valid表示字符串是否不是NULL。可以访问以下包装器:
-
sql.NullString -
sql.NullBool -
sql.NullInt32 -
sql.NullFloat64 -
sql.NullTime
两个都采用的工作方式,用sql.NullXXX更清晰地表达的意图,正如核心GO维护者 Russ Cox(mng.bz/rJNX)所说:
没有有效的区别。我们认为人们可能想要使用NullString,因为它太常见了,并且可能比*string更清楚地表达了意图。但是这两种方法都可以。
因此,可空列的最佳实践是要么将其作为指针处理,要么使用和sql.NullXXX类型。
10.4.5 不处理行迭代错误
另一个常见的错误是在迭代行时漏掉可能的错误。让我们看一个错误处理被误用的函数:
func get(ctx context.Context, db *sql.DB, id string) (string, int, error) {
rows, err := db.QueryContext(ctx,
"SELECT DEP, AGE FROM EMP WHERE ID = ?", id)
if err != nil {
// ❶
return "", 0, err
}
defer func() {
err := rows.Close() // ❷
if err != nil {
log.Printf("failed to close rows: %v\n", err)
}
}()
var (
department string
age int
)
for rows.Next() {
err := rows.Scan(&department, &age) // ❸
if err != nil {
return "", 0, err
}
}
return department, age, nil
}
❶ 在执行查询时处理错误
❷ 在关闭行时处理错误
❸ 在扫描行时处理错误
在这个函数中,我们处理三个错误:执行查询时,关闭行,扫描行。但这还不够。我们必须知道for rows .Next() {}循环可以中断,无论是当没有更多的行时,还是当准备下一行时发生错误时。在行迭代之后,我们应该调用rows.Err来区分两种情况:
func get(ctx context.Context, db *sql.DB, id string) (string, int, error) {
// ...
for rows.Next() {
// ...
}
if err := rows.Err(); err != nil {
// ❶
return "", 0, err
}
return department, age, nil
}
❶ 检查rows.Err确定上一个循环是否因为错误而停止
这是要记住的最佳实践:因为rows.Next可能在我们迭代完所有行时停止,或者在准备下一行时发生错误时停止,所以我们应该在迭代后检查rows.Err。
现在让我们讨论一个常见的错误:忘记关闭瞬态资源。
10.5 #79:不关闭瞬态资源
开发人员经常使用必须在代码中的某个点关闭的瞬态(临时)资源:例如,为了避免磁盘或内存中的泄漏。结构通常可以实现io.Closer接口来传达必须关闭瞬态资源。让我们来看三个常见的例子,看看当资源没有正确关闭时会发生什么,以及如何正确地处理它们。
10.5.1 HTTP 正文
首先,我们在 HTTP 的背景下讨论一下这个问题。我们将编写一个getBody方法,发出 HTTP GET 请求并返回 HTTP 正文响应。这是第一个实现:
type handler struct {
client http.Client
url string
}
func (h handler) getBody() (string, error) {
resp, err := h.client.Get(h.url) // ❶
if err != nil {
return "", err
}
body, err := io.ReadAll(resp.Body) // ❷
if err != nil {
return "", err
}
return string(body), nil
}
❶ 发出一个 HTTP GET 请求
❷ 读取resp.Body,并以[]byte的形式获取正文
我们使用http.Get并使用io.ReadAll解析响应。这个方法看起来不错,它正确地返回了 HTTP 响应体。然而,有一个资源泄漏。我们来了解一下在哪里。
resp是一个*http.Response型。它包含一个Body io.ReadCloser字段(io.ReadCloser实现了io.Reader和io.Closer)。如果http.Get没有返回错误,这个正文必须关闭;否则就是资源泄露。在这种情况下,我们的应用将保留一些不再需要但不能被 GC 回收的内存,在最坏的情况下,可能会阻止客户端重用 TCP 连接。
处理体闭包最方便的方法是像这样处理defer语句:
defer func() {
err := resp.Body.Close()
if err != nil {
log.Printf("failed to close response: %v\n", err)
}
}()
在这个实现中,我们将正文资源闭包作为一个defer函数来处理,一旦getBody返回,就会执行。
注意在服务器端,在实现 HTTP 处理器时,我们不需要关闭请求正文,因为服务器会自动关闭请求正文。
我们还应该理解,无论我们是否读取响应体,它都必须是封闭的。例如,如果我们只对 HTTP 状态代码感兴趣,而对正文不感兴趣,那么无论如何都必须关闭它,以避免泄漏:
func (h handler) getStatusCode(body io.Reader) (int, error) {
resp, err := h.client.Post(h.url, "application/json", body)
if err != nil {
return 0, err
}
defer func() {
// ❶
err := resp.Body.Close()
if err != nil {
log.Printf("failed to close response: %v\n", err)
}
}()
return resp.StatusCode, nil
}
即使我们不读,❶也会关闭响应正文
这个函数关闭了正文,即使我们没有读它。
另一件需要记住的重要事情是,当我们关闭身体时,行为是不同的,这取决于我们是否已经阅读了它:
-
如果我们在没有读取的情况下关闭正文,默认的 HTTP 传输可能会关闭连接。
-
如果我们在读取之后关闭正文,默认的 HTTP 传输不会关闭连接;因此,它可以重复使用。
因此,如果getStatusCode被重复调用并且我们想要使用保持活动的连接,我们应该读取正文,即使我们对它不感兴趣:
func (h handler) getStatusCode(body io.Reader) (int, error) {
resp, err := h.client.Post(h.url, "application/json", body)
if err != nil {
return 0, err
}
// Close response body
_, _ = io.Copy(io.Discard, resp.Body) // ❶
return resp.StatusCode, nil
}
❶ 阅读响应正文
在本例中,我们读取正文以保持连接的活力。注意,我们没有使用io.ReadAll,而是使用了io.Copy到io.Discard,一个io.Writer实现。这段代码读取正文,但丢弃它,不进行任何复制,这比io.ReadAll更有效。
何时关闭响应体
通常,如果响应不为空,实现会关闭正文,而不是如果错误为nil:
resp, err := http.Get(url)
if resp != nil {
// ❶
defer resp.Body.Close() // ❷
}
if err != nil {
return "", err
}
如果答案不是零,❶…
❷ …作为延迟函数关闭响应正文。
这个实现不是必需的。这是基于这样一个事实:在某些情况下(比如重定向失败),无论是resp还是err都不会是nil。但是根据官方GO文档(pkg.go.dev/net/http),
出错时,任何响应都可以忽略。只有当CheckRedirect失败时,才会出现带有非零错误的非零响应,即使在这种情况下,返回的响应也是如此。身体已经关闭。
因此,没有必要进行if resp != nil {}检查。我们应该坚持最初的解决方案,只有在没有错误的情况下,才在defer函数中关闭正文。
关闭资源以避免泄漏不仅仅与 HTTP 正文管理相关。一般来说,所有实现io.Closer接口的结构都应该在某个时候关闭。该接口包含单个Close方法:
type Closer interface {
Close() error
}
现在让我们看看sql.Rows的影响。
10.5.2 sql.Rows
sql.Rows是作为 SQL 查询结果使用的结构。因为这个结构实现了io.Closer,所以它必须被关闭。以下示例省略了行的关闭:
db, err := sql.Open("postgres", dataSourceName)
if err != nil {
return err
}
rows, err := db.Query("SELECT * FROM CUSTOMERS") // ❶
if err != nil {
return err
}
// Use rows
return nil
❶ 执行 SQL 查询
忘记关闭行意味着连接泄漏,这会阻止数据库连接被放回连接池中。
我们可以将闭包作为跟在if err != nil块后面的defer函数来处理:
// Open connection
rows, err := db.Query("SELECT * FROM CUSTOMERS") // ❶
if err != nil {
return err
}
defer func() {
// ❷
if err := rows.Close(); err != nil {
log.Printf("failed to close rows: %v\n", err)
}
}()
// Use rows
❶ 执行 SQL 查询
❷ 关闭一行
在Query调用之后,如果没有返回错误,我们应该最终关闭rows来防止连接泄漏。
注如前一节所述,db变量(*sql.DB类型)代表一个连接池。它还实现了io.Closer接口。但是正如文档所示,很少关闭一个sql.DB,因为它应该是长期存在的,并且由许多 goroutines 共享。
接下来,让我们讨论在处理文件时关闭资源。
10.5.3 os.File
os.File代表一个打开的文件描述符。和sql.Rows一样,最终必须关闭:
f, err := os.OpenFile(filename, os.O_APPEND|os.O_WRONLY, os.ModeAppend) // ❶
if err != nil {
return err
}
defer func() {
if err := f.Close(); err != nil {
// ❷
log.Printf("failed to close file: %v\n", err)
}
}()
❶ 打开文件
❷ 关闭文件描述符
在这个例子中,我们使用defer来延迟对Close方法的调用。如果我们最终没有关闭一个os.File,它本身不会导致泄漏:当os.File被垃圾收集时,文件会自动关闭。但是,最好显式调用Close,因为我们不知道下一个 GC 将在何时被触发(除非我们手动运行它)。
显式调用Close还有另一个好处:主动监控返回的错误。例如,可写文件应该是这种情况。
写入文件描述符不是同步操作。出于性能考虑,数据被缓冲。close(2)的 BSD 手册页提到,一个闭包会导致在 I/O 错误期间遇到的先前未提交的写操作(仍在缓冲区中)出错。因此,如果我们想要写入文件,我们应该传播关闭文件时发生的任何错误:
func writeToFile(filename string, content []byte) (err error) {
// Open file
defer func() {
// ❶
closeErr := f.Close()
if err == nil {
err = closeErr
}
}()
_, err = f.Write(content)
return
}
如果写入成功,❶将返回关闭错误
在本例中,我们使用命名参数,并在写入成功时将错误设置为f.Close的响应。通过这种方式,客户将会意识到这个函数是否出了问题,并做出相应的反应。
此外,成功关闭可写的os.File并不能保证文件将被写入磁盘。写操作仍然可以驻留在文件系统的缓冲区中,而不会刷新到磁盘上。如果持久性是一个关键因素,我们可以使用Sync()方法来提交变更。在这种情况下,来自Close的错误可以被安全地忽略:
func writeToFile(filename string, content []byte) error {
// Open file
defer func() {
_ = f.Close() // ❶
}()
_, err = f.Write(content)
if err != nil {
return err
}
return f.Sync() // ❷
}
❶ 忽略了可能的错误
❷ 将写入提交到磁盘
这个例子是一个同步写函数。它确保内容在返回之前被写入磁盘。但是它的缺点是会影响性能。
总结这一节,我们已经看到关闭短暂的资源从而避免泄漏是多么重要。短暂的资源必须在正确的时间和特定的情况下关闭。事先并不总是清楚什么必须结束。我们只能通过仔细阅读 API 文档和/或通过经验来获取这些信息。但是我们应该记住,如果一个结构实现了io.Closer接口,我们最终必须调用Close方法。最后但并非最不重要的一点是,必须理解如果闭包失败了该怎么做:记录一条消息就够了吗,或者我们还应该传播它吗?适当的操作取决于实现,如本节中的三个示例所示。
现在让我们切换到与 HTTP 处理相关的常见错误:忘记return语句。
10.6 #80:响应 HTTP 请求后忘记返回语句
在编写 HTTP 处理器时,很容易忘记响应 HTTP 请求后的语句。这可能会导致一种奇怪的情况,我们应该在出错后停止处理器,但是我们没有。
我们可以在下面的例子中观察到这种情况:
func handler(w http.ResponseWriter, req *http.Request) {
err := foo(req)
if err != nil {
http.Error(w, "foo", http.StatusInternalServerError) // ❶
}
// ...
}
❶ 处理错误
如果foo返回一个错误,我们使用http.Error来处理它,它用foo错误消息和一个 500 内部服务器错误来响应请求。这段代码的问题是,如果我们进入if err != nil分支,应用将继续执行,因为http.Error不会停止处理器的执行。
这种错误的真正影响是什么?首先我们从 HTTP 层面来讨论一下。例如,假设我们通过添加一个步骤来编写成功的 HTTP 响应正文和状态代码,从而完成了前面的 HTTP 处理器:
func handler(w http.ResponseWriter, req *http.Request) {
err := foo(req)
if err != nil {
http.Error(w, "foo", http.StatusInternalServerError)
}
_, _ = w.Write([]byte("all good"))
w.WriteHeader(http.StatusCreated)
}
在err != nil的情况下,HTTP 响应如下:
foo
all good
响应包含错误和成功消息。
我们将只返回第一个 HTTP 状态代码:在前面的例子中是 500。但是,Go 也会记录一个警告:
2021/10/29 16:45:33 http: superfluous response.WriteHeader call
from main.handler (main.go:20)
这个警告意味着我们试图多次写入状态代码,这样做是多余的。
就执行而言,主要影响是继续执行本应停止的函数。例如,如果foo在返回错误的同时还返回了一个指针,那么继续执行将意味着使用这个指针,这可能会导致一个空指针解引用(并因此导致一个 goroutine 崩溃)。
纠正这个错误的方法是继续考虑在http.Error之后添加return语句的:
func handler(w http.ResponseWriter, req *http.Request) {
err := foo(req)
if err != nil {
http.Error(w, "foo", http.StatusInternalServerError)
return // ❶
}
// ...
}
❶ 补充了返回语句
由于的return语句,如果我们在if err != nil分支结束,函数将停止执行。
这个错误可能不是这本书最复杂的。然而,很容易忘记这一点,这种错误经常发生。我们总是需要记住http.Error不会停止一个处理器的执行,必须手动添加。如果我们有足够的覆盖率,这样的问题可以而且应该在测试中被发现。
本章的最后一节继续我们对 HTTP 的讨论。我们明白了为什么生产级应用不应该依赖默认的 HTTP 客户端和服务器实现。
10.7 #81:使用默认的 HTTP 客户端和服务器
http包提供了 HTTP 客户端和服务器实现。然而,开发人员很容易犯一个常见的错误:在最终部署到生产环境中的应用的上下文中依赖默认实现。让我们看看问题和如何克服它们。
10.7.1 HTTP 客户端
我们来定义一下默认客户端是什么意思。我们将使用一个 GET 请求作为例子。我们可以像这样使用http.Client结构的零值:
client := &http.Client{
}
resp, err := client.Get("https://golang.org/")
或者我们可以使用http.Get函数:
resp, err := http.Get("https://golang.org/")
最后,两种方法都是一样的。http.Get函数使用http .DefaultClient,其也是基于http.Client的零值:
// DefaultClient is the default Client and is used by Get, Head, and Post.
var DefaultClient = &Client{
}
那么,使用默认的 HTTP 客户端有什么问题呢?
首先,默认客户端没有指定任何超时。这种没有超时的情况并不是我们想要的生产级系统:它会导致许多问题,比如永无止境的请求会耗尽系统资源。
在深入研究发出请求时的可用超时之前,让我们回顾一下 HTTP 请求中涉及的五个步骤:
-
建立 TCP 连接。
-
TLS 握手(如果启用)。
-
发送请求。
-
读取响应标题。
-
读取响应正文。
图 10.2 显示了这些步骤与主客户端超时的关系。

图 10.2 HTTP 请求期间的五个步骤,以及相关的超时
四种主要超时如下:
-
net.Dialer.Timeout——指定拨号等待连接完成的最长时间。 -
http.Transport.TLSHandshakeTimeout——指定等待 TLS 握手的最长时间。 -
http.Transport.ResponseHeaderTimeout——指定等待服务器响应头的时间。 -
http.Client.Timeout——指定请求的时限。它包括从步骤 1(拨号)到步骤 5(读取响应正文)的所有步骤。
HTTP 客户端超时
在指定http.Client .Timeout时,您可能会遇到以下错误:
net/http: request canceled (Client.Timeout exceeded while awaiting
headers)
此错误意味着端点未能及时响应。我们得到这个关于头的错误是因为读取它们是等待响应的第一步。
下面是一个覆盖这些超时的 HTTP 客户端示例:
client := &http.Client{
Timeout: 5 * time.Second, // ❶
Transport: &http.Transport{
DialContext: (&net.Dialer{
Timeout: time.Second, // ❷
}).DialContext,
TLSHandshakeTimeout: time.Second, // ❸
ResponseHeaderTimeout: time.Second, // ❹
},
}
❶ 全局请求超时
❷ 拨号超时
❸ TLS 握手超时
❹ 响应标头超时
我们创建一个客户端,拨号、TLS 握手和读取响应头的超时时间为 1 秒。同时,每个请求都有一个 5 秒的全局超时。
关于默认 HTTP 客户端,要记住的第二个方面是如何处理连接。默认情况下,HTTP 客户端使用连接池。默认客户端重用连接(可以通过将http.Transport.DisableKeepAlives设置为true来禁用)。有一个额外的超时来指定空闲连接在池中保持多长时间:http.Transport.IdleConnTimeout。默认值是 90 秒,这意味着在此期间,连接可以被其他请求重用。之后,如果连接没有被重用,它将被关闭。
要配置池中的连接数,我们必须覆盖http.Transport.MaxIdleConns。该值默认设置为100。但是有一些重要的事情需要注意:每台主机的http.Transport.MaxIdleConnsPerHost限制,默认设置为 2。例如,如果我们向同一个主机触发100请求,那么在此之后,只有 2 个连接会保留在连接池中。因此,如果我们再次触发 100 个请求,我们将不得不重新打开至少 98 个连接。如果我们必须处理对同一台主机的大量并行请求,这种配置也会影响平均延迟。
对于生产级系统,我们可能希望覆盖默认超时。调整与连接池相关的参数也会对延迟产生重大影响。
10.7.2 HTTP 服务器
在实现 HTTP 服务器时,我们也应该小心。同样,可以使用零值http.Server创建默认服务器:
server := &http.Server{
}
server.Serve(listener)
或者我们可以使用一个函数,比如http.Serve、http.ListenAndServe或http .ListenAndServeTLS,它们也依赖于默认的http.Server。
一旦连接被接受,HTTP 响应就分为五个步骤:
-
等待客户端发送请求。
-
TLS 握手(如果启用)。
-
读取请求标题。
-
读取请求正文。
-
写入响应。
注意,对于已经建立的连接,不必重复 TLS 握手。
图 10.3 显示了这些步骤与主服务器超时的关系。三种主要超时如下:
-
http.Server.ReadHeaderTimeout——字段,指定读取请求头的最大时间量 -
http.Server.ReadTimeout——指定读取整个请求的最长时间的字段 -
http.TimeoutHandler——一个包装器函数,指定处理器完成的最大时间

图 10.3 HTTP 响应的五个步骤,以及相关的超时
最后一个参数不是服务器参数,而是一个位于处理器之上的包装器,用于限制其持续时间。如果处理器未能及时响应,服务器将通过特定消息响应 503 服务不可用,传递给处理器的上下文将被取消。
注意我们故意省略了http.Server.WriteTimeout,因为http.TimeoutHandler已经发布(Go 1.8),所以没有必要。http.Server.WriteTimeout有一些问题。首先,它的行为取决于是否启用了 TLS,这使得理解和使用它变得更加复杂。如果超时,它还会关闭 TCP 连接,而不返回正确的 HTTP 代码。它不会将取消传播到处理器上下文,所以处理器可能会继续执行,而不知道 TCP 连接已经关闭。
当向不受信任的客户端公开我们的端点时,最佳实践是至少设置http.Server.ReadHeaderTimeout字段,并且使用http.TimeoutHandler包装函数。否则,客户端可能会利用此缺陷,例如,创建永无止境的连接,这可能会导致系统资源耗尽。
以下是如何设置具有这些超时的服务器:
s := &http.Server{
Addr: ":8080",
ReadHeaderTimeout: 500 * time.Millisecond,
ReadTimeout: 500 * time.Millisecond,
Handler: http.TimeoutHandler(handler, time.Second, "foo"), // ❶
}
❶ 包装了 HTTP 处理器
http.TimeoutHandler包装提供的处理器。这里,如果handler在 1 秒内没有响应,服务器返回一个 503 状态码,用foo作为 HTTP 响应。
正如我们所描述的 HTTP 客户端一样,在服务器端,我们可以在激活 keep-alive 时为下一个请求配置最长时间。我们使用http.Server.IdleTimeout来完成:
s := &http.Server{
// ...
IdleTimeout: time.Second,
}
注意,如果没有设置http.Server.IdleTimeout,则http.Server .ReadTimeout的值用于空闲超时。如果两者都没有设置,则不会有任何超时,连接将保持打开状态,直到被客户端关闭。
对于生产级应用,我们需要确保不使用默认的 HTTP 客户端和服务器。否则,请求可能会因为没有超时而永远停滞不前,甚至恶意客户端会利用我们的服务器没有任何超时这一事实。
总结
-
对接受
time.Duration的函数保持谨慎。尽管传递整数是允许的,但还是要努力使用 time API 来防止任何可能的混淆。 -
避免在重复的函数(比如循环或者 HTTP 处理器)中调用
time.After可以避免内存消耗高峰。由time.After创建的资源只有在计时器到期时才会被释放。 -
在 Go 结构中使用嵌入字段时要小心。这样做可能会导致偷偷摸摸的错误,比如实现
json .Marshaler接口的嵌入式time.Time字段,因此会覆盖默认的封送处理行为。 -
当比较两个
time.Time结构时,回想一下time.Time包含一个挂钟和一个单调时钟,使用==操作符的比较是在两个时钟上进行的。 -
为了避免在解组 JSON 数据时提供映射时的错误假设,请记住默认情况下 numerics 被转换为
float64。 -
如果您需要测试您的配置并确保数据库可访问,请调用
Ping或PingContext方法。 -
为生产级应用配置数据库连接参数。
-
使用 SQL 预准备语句使查询更高效、更安全。
-
使用指针或
sql.NullXXX类型处理表中可空的列。 -
在行迭代后调用
*sql.Rows的Err方法,以确保在准备下一行时没有遗漏错误。 -
最终关闭所有实现
io.Closer的结构以避免可能的泄漏。 -
为了避免 HTTP 处理器实现中的意外行为,如果您希望处理器在
http.Error之后停止,请确保不要错过return语句。 -
对于生产级应用,不要使用默认的 HTTP 客户端和服务器实现。这些实现缺少生产中应该强制的超时和行为。
十一、测试
本章涵盖
- 对测试进行分类,使它们更加健壮
- 使 Go 测试具有确定性
- 使用实用工具包,如
httptest和iotest - 避免常见的基准错误
- 改进测试流程
测试是项目生命周期的一个重要方面。它提供了无数的好处,比如建立对应用的信心,充当代码文档,以及使重构更容易。与其他一些语言相比,Go 拥有强大的编写测试的原语。在这一章中,我们将关注那些使测试过程变得脆弱、低效和不准确的常见错误。
11.1 #82:没有对测试进行分类
测试金字塔是一个将测试分成不同类别的模型(见图 11.1)。单元测试占据了金字塔的底部。大多数测试应该是单元测试:它们编写成本低,执行速度快,并且具有很高的确定性。通常,当我们走的时候
在金字塔的更高层,测试变得越来越复杂,运行越来越慢,并且更难保证它们的确定性。

图 11.1 测试金字塔的一个例子
一种常见的技术是明确要运行哪种测试。例如,根据项目生命周期的阶段,我们可能希望只运行单元测试或者运行项目中的所有测试。不对测试进行分类意味着潜在的浪费时间和精力,并且失去了测试范围的准确性。本节讨论了在 Go 中对测试进行分类的三种主要方法。
11.1.1 构建标签
分类测试最常见的方法是使用构建标签。构建标签是 Go 文件开头的特殊注释,后面跟一个空行。
例如,看看这个bar.go文件:
//go:build foo
package bar
这个文件包含了foo标签。请注意,一个包可能包含多个带有不同构建标记的文件。
注从 Go 1.17 开始,语法// +build foo被//go:build foo取代。目前(Go 1.18),gofmt同步这两种形式来帮助迁移。
构建标签主要用于两种情况。首先,我们可以使用build标签作为构建应用的条件选项:例如,如果我们希望只有在启用了cgo的情况下才包含源文件(cgo是一种让包调用 C 代码的方法),我们可以添加//go:build cgo``build标签。第二,如果我们想要将一个测试归类为集成测试,我们可以添加一个特定的构建标志,比如integration。
下面是一个db_test.go文件示例:
//go:build integration
package db
import (
"testing"
)
func TestInsert(t *testing.T) {
// ...
}
这里我们添加了integration``build标签来分类这个文件包含集成测试。使用构建标签的好处是我们可以选择执行哪种测试。例如,让我们假设一个包包含两个测试文件:
-
我们刚刚创建的文件:
db_test.go -
另一个不包含构建标签的文件:
contract_test.go
如果我们在这个包中运行go test而没有任何选项,它将只运行没有构建标签的测试文件(contract_test.go):
$ go test -v .
=== RUN TestContract
--- PASS: TestContract (0.01s)
PASS
然而,如果我们提供了integration标签,运行go test也将包括db_test.go:
$ go test --tags=integration -v .
=== RUN TestInsert
--- PASS: TestInsert (0.01s)
=== RUN TestContract
--- PASS: TestContract (2.89s)
PASS
因此,运行带有特定标签的测试包括没有标签的文件和匹配这个标签的文件。如果我们只想运行集成测试呢?一种可能的方法是在单元测试文件上添加一个否定标记。例如,使用!integration意味着只有当integration标志不启用时,我们才想要包含测试文件(contract_test.go):
//go:build !integration
package db
import (
"testing"
)
func TestContract(t *testing.T) {
// ...
}
使用这种方法,
-
带
integration标志运行go test仅运行集成测试。 -
在没有
integration标志的情况下运行go test只会运行单元测试。
让我们讨论一个在单个测试层次上工作的选项,而不是一个文件。
11.1.2 环境变量
正如 Go 社区的成员 Peter Bourgon 所提到的,build标签有一个主要的缺点:缺少一个测试被忽略的信号(参见 mng.bz/qYlr )。在第一个例子中,当我们在没有构建标志的情况下执行go test时,它只显示了被执行的测试:
$ go test -v .
=== RUN TestUnit
--- PASS: TestUnit (0.01s)
PASS
ok db 0.319s
如果我们不小心处理标签的方式,我们可能会忘记现有的测试。出于这个原因,一些项目喜欢使用环境变量来检查测试类别的方法。
例如,我们可以通过检查一个特定的环境变量并可能跳过测试来实现TestInsert集成测试:
func TestInsert(t *testing.T) {
if os.Getenv("INTEGRATION") != "true" {
t.Skip("skipping integration test")
}
// ...
}
如果INTEGRATION环境变量没有设置为true,测试将被跳过,并显示一条消息:
$ go test -v .
=== RUN TestInsert
db_integration_test.go:12: skipping integration test // ❶
--- SKIP: TestInsert (0.00s)
=== RUN TestUnit
--- PASS: TestUnit (0.00s)
PASS
ok db 0.319s
❶ 显示跳过测试的消息
使用这种方法的一个好处是明确哪些测试被跳过以及为什么。这种技术可能没有build标签使用得广泛,但是它值得了解,因为正如我们所讨论的,它提供了一些优势。
接下来,让我们看看另一种分类测试的方法:短模式。
11.1.3 短模式
另一种对测试进行分类的方法与它们的速度有关。我们可能必须将短期运行的测试与长期运行的测试分离开来。
作为一个例子,假设我们有一组单元测试,其中一个非常慢。我们希望对慢速测试进行分类,这样我们就不必每次都运行它(特别是当触发器是在保存一个文件之后)。短模式允许我们进行这种区分:
func TestLongRunning(t *testing.T) {
if testing.Short() {
// ❶
t.Skip("skipping long-running test")
}
// ...
}
❶ 将测试标记为长期运行
使用testing.Short,我们可以在运行测试时检索是否启用了短模式。然后我们使用Skip来跳过测试。要使用短模式运行测试,我们必须通过-short:
% go test -short -v .
=== RUN TestLongRunning
foo_test.go:9: skipping long-running test
--- SKIP: TestLongRunning (0.00s)
PASS
ok foo 0.174s
执行测试时,明确跳过TestLongRunning。请注意,与构建标签不同,该选项适用于每个测试,而不是每个文件。
总之,对测试进行分类是成功测试策略的最佳实践。在本节中,我们已经看到了三种对测试进行分类的方法:
-
在测试文件级别使用构建标签
-
使用环境变量来标记特定的测试
-
基于使用短模式的测试步速
我们还可以组合方法:例如,如果我们的项目包含长时间运行的单元测试,使用构建标签或环境变量来分类测试(例如,作为单元或集成测试)和短模式。
在下一节中,我们将讨论为什么启用-race标志很重要。
11.2 #83:不启用竞争标志
在错误#58“不理解竞争问题”中,我们将数据竞争定义为当两个 goroutines 同时访问同一个变量时发生,至少有一个变量被写入。我们还应该知道,Go 有一个标准的竞争检测工具来帮助检测数据竞争。一个常见的错误是忘记了这个工具的重要性,没有启用它。这一节讨论竞争检测器捕捉什么,如何使用它,以及它的局限性。
在 Go 中,竞争检测器不是编译期间使用的静态分析工具;相反,它是一个发现运行时发生的数据竞争的工具。要启用它,我们必须在编译或运行测试时启用-race标志。例如:
$ go test -race ./...
一旦启用了竞争检测器,编译器就会检测代码来检测数据竞争。插装指的是编译器添加额外的指令:在这里,跟踪所有的内存访问并记录它们何时以及如何发生。在运行时,竞争检测器监视数据竞争。但是,我们应该记住启用竞争检测器的运行时开销:
-
内存使用量可能会增加 5 到 10 倍。
-
执行时间可能增加 2 到 20 倍。
由于这种开销,通常建议只在本地测试或持续集成(CI)期间启用竞争检测器。在生产中,我们应该避免使用它(或者只在金丝雀释放的情况下使用它)。
如果检测到竞争,Go 会发出警告。例如,这个例子包含了一个数据争用,因为i可以同时被读取和写入:
package main
import (
"fmt"
)
func main() {
i := 0
go func() {
i++ }()
fmt.Println(i)
}
使用-race标志运行该应用会记录以下数据竞争警告:
==================
WARNING: DATA RACE
Write at 0x00c000026078 by goroutine 7: // ❶
main.main.func1()
/tmp/app/main.go:9 +0x4e
Previous read at 0x00c000026078 by main goroutine: // ❷
main.main()
/tmp/app/main.go:10 +0x88
Goroutine 7 (running) created at: // ❸
main.main()
/tmp/app/main.go:9 +0x7a
==================
❶ 指出由 goroutine 7 写入
❷ 指出由主 goroutine读取
❸ 指出了 goroutine 7 的创建时间
让我们确保阅读这些信息时感到舒适。Go 总是记录以下内容:
-
被牵连的并发 goroutine:这里是主 goroutine 和 goroutine 7。
-
代码中出现访问的地方:在本例中,是第 9 行和第 10 行。
-
创建这些 goroutine 的时间:goroutine 7 是在
main()中创建的。
注意在内部,竞争检测器使用向量时钟,这是一种用于确定事件部分顺序的数据结构(也用于分布式系统,如数据库)。每一个 goroutine 的创建都会导致一个向量时钟的产生。该工具在每次存储器访问和同步事件时更新向量时钟。然后,它比较向量时钟以检测潜在的数据竞争。
竞争检测器不能捕捉假阳性(一个明显的数据竞争,而不是真正的数据竞争)。因此,如果我们得到警告,我们知道我们的代码包含数据竞争。相反,它有时会导致假阴性(遗漏实际的数据竞争)。
关于测试,我们需要注意两件事。首先,竞争检测器只能和我们的测试一样好。因此,我们应该确保针对数据竞争对并发代码进行彻底的测试。其次,考虑到可能的假阴性,如果我们有一个测试来检查数据竞争,我们可以将这个逻辑放在一个循环中。这样做增加了捕获可能的数据竞争的机会:
func TestDataRace(t *testing.T) {
for i := 0; i < 100; i++ {
// Actual logic
}
}
此外,如果一个特定的文件包含导致数据竞争的测试,我们可以使用!race``build标签将其从竞争检测中排除:
//go:build !race
package main
import (
"testing"
)
func TestFoo(t *testing.T) {
// ...
}
func TestBar(t *testing.T) {
// ...
}
只有在禁用竞争检测器的情况下,才会构建该文件。否则,整个文件不会被构建,所以测试不会被执行。
总之,我们应该记住,如果不是强制性的,强烈推荐使用并发性为应用运行带有-race标志的测试。这种方法允许我们启用竞争检测器,它检测我们的代码来捕捉潜在的数据竞争。启用时,它会对内存和性能产生重大影响,因此必须在特定条件下使用,如本地测试或 CI。
下面讨论与和执行模式相关的两个标志:parallel和shuffle。
11.3 #84:不使用测试执行模式
在运行测试时,go命令可以接受一组标志来影响测试的执行方式。一个常见的错误是没有意识到这些标志,错过了可能导致更快执行或更好地发现可能的 bug 的机会。让我们来看看其中的两个标志:parallel和shuffle。
11.3.1 并行标志
并行执行模式允许我们并行运行特定的测试,这可能非常有用:例如,加速长时间运行的测试。我们可以通过调用t.Parallel来标记测试必须并行运行:
func TestFoo(t *testing.T) {
t.Parallel()
// ...
}
当我们使用t.Parallel标记一个测试时,它与所有其他并行测试一起并行执行。然而,在执行方面,Go 首先一个接一个地运行所有的顺序测试。一旦顺序测试完成,它就执行并行测试。
例如,以下代码包含三个测试,但其中只有两个被标记为并行运行:
func TestA(t *testing.T) {
t.Parallel()
// ...
}
func TestB(t *testing.T) {
t.Parallel()
// ...
}
func TestC(t *testing.T) {
// ...
}
运行该文件的测试会产生以下日志:
=== RUN TestA
=== PAUSE TestA // ❶
=== RUN TestB
=== PAUSE TestB // ❷
=== RUN TestC // ❸
--- PASS: TestC (0.00s)
=== CONT TestA // ❹
--- PASS: TestA (0.00s)
=== CONT TestB
--- PASS: TestB (0.00s)
PASS
❶ 暂停TestA
❷ 暂停TestB
❸ 运行TestC
❹ 恢复TestA和TestB
TestC第一个被处决。TestA和TestB首先被记录,但是它们被暂停,等待TestC完成。然后两者都被恢复并并行执行。
默认情况下,可以同时运行的最大测试数量等于GOMAXPROCS值。为了序列化测试,或者,例如,在进行大量 I/O 的长时间运行的测试环境中增加这个数字,我们可以使用的-parallel标志来改变这个值:
$ go test -parallel 16 .
这里,并行测试的最大数量被设置为 16。
现在让我们看看运行 Go 测试的另一种模式:shuffle。
11.3.2 混洗标志
从 Go 1.17 开始,可以随机化测试和基准的执行顺序。有什么道理?编写测试的最佳实践是将它们隔离开来。例如,它们不应该依赖于执行顺序或共享变量。这些隐藏的依赖关系可能意味着一个可能的测试错误,或者更糟糕的是,一个在测试过程中不会被发现的错误。为了防止这种情况,我们可以使用和-shuffle标志来随机化测试。我们可以将其设置为on或off来启用或禁用测试混洗(默认情况下禁用):
$ go test -shuffle=on -v .
然而,在某些情况下,我们希望以相同的顺序重新运行测试。例如,如果在 CI 期间测试失败,我们可能希望在本地重现错误。为此,我们可以传递用于随机化测试的种子,而不是将on传递给-shuffle标志。我们可以通过启用详细模式(-v)在运行混洗测试时访问这个种子值:
$ go test -shuffle=on -v .
-test.shuffle 1636399552801504000 // ❶
=== RUN TestBar
--- PASS: TestBar (0.00s)
=== RUN TestFoo
--- PASS: TestFoo (0.00s)
PASS
ok teivah 0.129s
❶ 种子值
我们随机执行测试,但是go test打印种子值:1636399552801504000。为了强制测试以相同的顺序运行,我们将这个种子值提供给shuffle:
$ go test -shuffle=1636399552801504000 -v .
-test.shuffle 1636399552801504000
=== RUN TestBar
--- PASS: TestBar (0.00s)
=== RUN TestFoo
--- PASS: TestFoo (0.00s)
PASS
ok teivah 0.129s
测试以相同的顺序执行:TestBar然后是TestFoo。
一般来说,我们应该对现有的测试标志保持谨慎,并随时了解最近 Go 版本的新特性。并行运行测试是减少运行所有测试的总执行时间的一个很好的方法。并且shuffle模式可以帮助我们发现隐藏的依赖关系,这可能意味着在以相同的顺序运行测试时的测试错误,甚至是看不见的 bug。
11.4 #85:不使用表驱动测试
表驱动测试是一种有效的技术,用于编写精简的测试,从而减少样板代码,帮助我们关注重要的东西:测试逻辑。本节通过一个具体的例子来说明为什么在使用 Go 时表驱动测试是值得了解的。
让我们考虑下面的函数,它从字符串中删除所有的新行后缀(\n或\r\n):
func removeNewLineSuffixes(s string) string {
if s == "" {
return s
}
if strings.HasSuffix(s, "\r\n") {
return removeNewLineSuffixes(s[:len(s)-2])
}
if strings.HasSuffix(s, "\n") {
return removeNewLineSuffixes(s[:len(s)-1])
}
return s
}
这个函数递归地删除所有前导的\r\n和\n后缀。现在,假设我们想要广泛地测试这个函数。我们至少应该涵盖以下情况:
-
输入为空。
-
输入以
\n结束。 -
输入以
\r\n结束。 -
输入以多个
\n结束。 -
输入结束时没有换行符。
以下方法为每个案例创建一个单元测试:
func TestRemoveNewLineSuffix_Empty(t *testing.T) {
got := removeNewLineSuffixes("")
expected := ""
if got != expected {
t.Errorf("got: %s", got)
}
}
func TestRemoveNewLineSuffix_EndingWithCarriageReturnNewLine(t *testing.T) {
got := removeNewLineSuffixes("a\r\n")
expected := "a"
if got != expected {
t.Errorf("got: %s", got)
}
}
func TestRemoveNewLineSuffix_EndingWithNewLine(t *testing.T) {
got := removeNewLineSuffixes("a\n")
expected := "a"
if got != expected {
t.Errorf("got: %s", got)
}
}
func TestRemoveNewLineSuffix_EndingWithMultipleNewLines(t *testing.T) {
got := removeNewLineSuffixes("a\n\n\n")
expected := "a"
if got != expected {
t.Errorf("got: %s", got)
}
}
func TestRemoveNewLineSuffix_EndingWithoutNewLine(t *testing.T) {
got := removeNewLineSuffixes("a\n")
expected := "a"
if got != expected {
t.Errorf("got: %s", got)
}
}
每个函数都代表了我们想要涵盖的一个特定案例。然而,有两个主要缺点。首先,函数名更复杂(TestRemoveNewLineSuffix_EndingWithCarriageReturnNewLine有 55 个字符长),这很快会影响函数测试内容的清晰度。第二个缺点是这些函数之间的重复量,因为结构总是相同的:
-
谓
removeNewLineSuffixes。 -
定义期望值。
-
比较数值。
-
记录错误信息。
如果我们想要改变这些步骤中的一个——例如,将期望值作为错误消息的一部分包含进来——我们将不得不在所有的测试中重复它。我们写的测试越多,代码就越难维护。
相反,我们可以使用表驱动测试,这样我们只需编写一次逻辑。表驱动测试依赖于子测试,一个测试函数可以包含多个子测试。例如,以下测试包含两个子测试:
func TestFoo(t *testing.T) {
t.Run("subtest 1", func(t *testing.T) {
// ❶
if false {
t.Error()
}
})
t.Run("subtest 2", func(t *testing.T) {
// ❷
if 2 != 2 {
t.Error()
}
})
}
❶ 进行第一个子测试,称为子测试 1
❷ 进行第二个子测试,称为子测试 2
TestFoo函数包括两个子测试。如果我们运行这个测试,它显示了subtest 1和subtest 2的结果:
--- PASS: TestFoo (0.00s)
--- PASS: TestFoo/subtest_1 (0.00s)
--- PASS: TestFoo/subtest_2 (0.00s)
PASS
我们还可以使用和-run标志运行一个单独的测试,并将父测试名与子测试连接起来。例如,我们可以只运行subtest 1:
$ go test -run=TestFoo/subtest_1 -v // ❶
=== RUN TestFoo
=== RUN TestFoo/subtest_1
--- PASS: TestFoo (0.00s)
--- PASS: TestFoo/subtest_1 (0.00s)
❶ 使用-run标志只运行子测试 1
让我们回到我们的例子,看看如何使用子测试来防止重复测试逻辑。主要想法是为每个案例创建一个子测试。变化是存在的,但是我们将讨论一个映射数据结构,其中键代表测试名称,值代表测试数据(输入,预期)。
表驱动测试通过使用包含测试数据和子测试的数据结构来避免样板代码。下面是一个使用映射的可能实现:
func TestRemoveNewLineSuffix(t *testing.T) {
tests := map[string]struct {
// ❶
input string
expected string
}{
`empty`: {
// ❷
input: "",
expected: "",
},
`ending with \r\n`: {
input: "a\r\n",
expected: "a",
},
`ending with \n`: {
input: "a\n",
expected: "a",
},
`ending with multiple \n`: {
input: "a\n\n\n",
expected: "a",
},
`ending without newline`: {
input: "a",
expected: "a",
},
}
for name, tt := range tests {
// ❸
t.Run(name, func(t *testing.T) {
// ❹
got := removeNewLineSuffixes(tt.input)
if got != tt.expected {
t.Errorf("got: %s, expected: %s", got, tt.expected)
}
})
}
}
❶ 定义了测试数据
❷ :映射中的每个条目代表一个子测试。
❸ 在映射上迭代
❹ 为每个映射条目运行一个新的子测试
tests变量是一个映射。关键是测试名称,值代表测试数据:在我们的例子中,输入和预期的字符串。每个映射条目都是我们想要覆盖的一个新的测试用例。我们为每个映射条目运行一个新的子测试。
这个测试解决了我们讨论的两个缺点:
-
每个测试名现在是一个字符串,而不是 Pascal 大小写函数名,这使得它更容易阅读。
-
该逻辑只编写一次,并在所有不同的情况下共享。修改测试结构或者增加一个新的测试需要最小的努力。
关于表驱动测试,我们需要提到最后一件事,它也可能是错误的来源:正如我们前面提到的,我们可以通过调用t.Parallel来标记一个并行运行的测试。我们也可以在提供给t.Run的闭包内的子测试中这样做:
for name, tt := range tests {
t.Run(name, func(t *testing.T) {
t.Parallel() // ❶
// Use tt
})
}
❶ 标记了并行运行的子测试
然而,这个闭包使用了一个循环变量。为了防止类似于错误#63 中讨论的问题,“不小心使用 goroutines 和循环变量”,这可能导致闭包使用错误的tt变量的值,我们应该创建另一个变量或影子tt:
for name, tt := range tests {
tt := tt // ❶
t.Run(name, func(t *testing.T) {
t.Parallel()
// Use tt
})
}
❶ 跟踪tt,使其位于循环迭代的局部
这样,每个闭包都会访问它自己的tt变量。
总之,如果多个单元测试有相似的结构,我们可以使用表驱动测试来共同化它们。因为这种技术防止了重复,它使得改变测试逻辑变得简单,并且更容易添加新的用例。
接下来,我们来讨论如何在 Go 中防止片状测试。
11.5 #86:在单元测试中睡眠
古怪的测试是一个不需要任何代码改变就可以通过和失败的测试。古怪的测试是测试中最大的障碍之一,因为它们调试起来很昂贵,并且削弱了我们对测试准确性的信心。在 Go 中,在测试中调用time.Sleep可能是可能出现问题的信号。例如,并发代码经常使用睡眠进行测试。这一部分介绍了从测试中移除睡眠的具体技术,从而防止我们编写出易变的测试。
我们将用一个函数来说明这一部分,该函数返回值并启动一个在后台执行任务的 goroutine。我们将调用一个函数来获取一片Foo结构,并返回最佳元素(第一个)。与此同时,另一个 goroutine 将负责调用带有第n个Foo元素的Publish方法:
type Handler struct {
n int
publisher publisher
}
type publisher interface {
Publish([]Foo)
}
func (h Handler) getBestFoo(someInputs int) Foo {
foos := getFoos(someInputs) // ❶
best := foos[0] // ❷
go func() {
if len(foos) > h.n {
// ❸
foos = foos[:h.n]
}
h.publisher.Publish(foos) // ❹
}()
return best
}
❶ 得到Foo切片
❷ 保留第一个元素(为了简单起见,省略了检查foos的长度)
❸ 只保留前n个Foo结构
❹ 调用Publish方法
Handler结构包含两个字段:一个n字段和一个用于发布第一个n Foo结构的publisher依赖项。首先我们得到一片Foo;但是在返回第一个元素之前,我们旋转一个新的 goroutine,过滤foos片,并调用Publish。
我们如何测试这个函数?编写声明响应的部分非常简单。但是,如果我们还想检查传递给Publish的是什么呢?
我们可以模仿publisher接口来记录调用Publish方法时传递的参数。然后,我们可以在检查记录的参数之前睡眠几毫秒:
type publisherMock struct {
mu sync.RWMutex
got []Foo
}
func (p *publisherMock) Publish(got []Foo) {
p.mu.Lock()
defer p.mu.Unlock()
p.got = got
}
func (p *publisherMock) Get() []Foo {
p.mu.RLock()
defer p.mu.RUnlock()
return p.got
}
func TestGetBestFoo(t *testing.T) {
mock := publisherMock{
}
h := Handler{
publisher: &mock,
n: 2,
}
foo := h.getBestFoo(42)
// Check foo
time.Sleep(10 * time.Millisecond) // ❶
published := mock.Get()
// Check published
}
❶ 在检查传递给Publish的参数之前,睡眠了 10 毫秒
我们编写了一个对publisher的模拟,它依赖于一个互斥体来保护对published字段的访问。在我们的单元测试中,我们调用time.Sleep在检查传递给Publish的参数之前留出一些时间。
这种测试本来就不可靠。不能严格保证 10 毫秒就足够了(在本例中,有可能但不能保证)。
那么,有哪些选项可以改进这个单元测试呢?首先,我们可以使用重试来周期性地断言给定的条件。例如,我们可以编写一个函数,将一个断言作为参数,最大重试次数加上等待时间,定期调用该函数以避免繁忙循环:
func assert(t *testing.T, assertion func() bool,
maxRetry int, waitTime time.Duration) {
for i := 0; i < maxRetry; i++ {
if assertion() {
// ❶
return
}
time.Sleep(waitTime) // ❷
}
t.Fail() // ❸
}
❶ 检查断言
❷ 在重试前睡眠
❸ 经过多次尝试后,最终失败了
该函数检查提供的断言,并在一定次数的重试后失败。我们也使用time.Sleep,但是我们可以用这段代码来缩短睡眠时间。
举个例子,让我们回到TestGetBestFoo:
assert(t, func() bool {
return len(mock.Get()) == 2
}, 30, time.Millisecond)
我们不是睡眠 10 毫秒,而是每毫秒睡眠一次,并配置最大重试次数。如果测试成功,这种方法可以减少执行时间,因为我们减少了等待时间。因此,实现重试策略是比使用被动睡眠更好的方法。
注意一些测试库,如testify,提供重试功能。例如,在testify中,我们可以使用Eventually函数,它实现了最终应该成功的断言和其他特性,比如配置错误消息。
另一个策略是使用通道来同步发布Foo结构的 goroutine 和测试 goroutine。例如,在模拟实现中,我们可以将这个值发送到一个通道,而不是将接收到的切片复制到一个字段中:
type publisherMock struct {
ch chan []Foo
}
func (p *publisherMock) Publish(got []Foo) {
p.ch <- got // ❶
}
func TestGetBestFoo(t *testing.T) {
mock := publisherMock{
ch: make(chan []Foo),
}
defer close(mock.ch)
h := Handler{
publisher: &mock,
n: 2,
}
foo := h.getBestFoo(42)
// Check foo
if v := len(<-mock.ch); v != 2 {
// ❷
t.Fatalf("expected 2, got %d", v)
}
}
❶ 发送收到的参数
❷ 比较了这些参数
发布者将接收到的参数发送到通道。同时,测试 goroutine 设置模拟并基于接收到的值创建断言。我们还可以实现一个超时策略,以确保如果出现问题,我们不会永远等待mock.ch。例如,我们可以将select与time.After一起使用。
我们应该支持哪个选项:重试还是同步?事实上,同步将等待时间减少到最低限度,如果设计得好的话,可以使测试完全确定。
如果我们不能应用同步,我们也许应该重新考虑我们的设计,因为我们可能有一个问题。如果同步确实不可能,我们应该使用重试选项,这是比使用被动睡眠来消除测试中的不确定性更好的选择。
让我们继续讨论如何在测试中防止剥落,这次是在使用时间 API 的时候。
11.6 #87:没有有效地处理时间 API
一些函数必须依赖于时间 API:例如,检索当前时间。在这种情况下,编写脆弱的单元测试可能会很容易失败。在本节中,我们将通过一个具体的例子来讨论选项。我们的目标并不是涵盖所有的用例及技术,而是给出关于使用时间 API 编写更健壮的函数测试的指导。
假设一个应用接收到我们希望存储在内存缓存中的事件。我们将实现一个Cache结构来保存最近的事件。此结构将公开三个方法,这些方法执行以下操作:
-
追加事件
-
获取所有事件
-
在给定的持续时间内修剪事件(我们将重点介绍这种方法)
这些方法中的每一个都需要访问当前时间。让我们使用time.Now()编写第三种方法的第一个实现(我们将假设所有事件都按时间排序):
type Cache struct {
mu sync.RWMutex
events []Event
}
type Event struct {
Timestamp time.Time
Data string
}
func (c *Cache) TrimOlderThan(since time.Duration) {
c.mu.RLock()
defer c.mu.RUnlock()
t := time.Now().Add(-since) // ❶
for i := 0; i < len(c.events); i++ {
if c.events[i].Timestamp.After(t) {
c.events = c.events[i:] // ❷
return
}
}
}
❶ 从当前时间中减去给定的持续时间
❷ 负责整理这些事件
我们计算一个t变量,它是当前时间减去提供的持续时间。然后,因为事件是按时间排序的,所以一旦到达时间在t之后的事件,我们就更新内部的events片。
我们如何测试这种方法?我们可以依靠当前时间使用time.Now来创建事件:
func TestCache_TrimOlderThan(t *testing.T) {
events := []Event{
// ❶
{
Timestamp: time.Now().Add(-20 * time.Millisecond)},
{
Timestamp: time.Now().Add(-10 * time.Millisecond)},
{
Timestamp: time.Now().Add(10 * time.Millisecond)},
}
cache := &Cache{
}
cache.Add(events) // ❷
cache.TrimOlderThan(15 * time.Millisecond) // ❸
got := cache.GetAll() // ❹
expected := 2
if len(got) != expected {
t.Fatalf("expected %d, got %d", expected, len(got))
}
}
❶ 利用time.Now()创建事件。
❷ 将这些事件添加到缓存中
❸ 整理了 15 毫秒前的事件
❹ 检索所有事件
我们使用time.Now()将一部分事件添加到缓存中,并增加或减少一些小的持续时间。然后,我们将这些事件调整 15 毫秒,并执行断言。
这种方法有一个主要缺点:如果执行测试的机器突然很忙,我们可能会修剪比预期更少的事件。我们也许能够增加提供的持续时间,以减少测试失败的机会,但这样做并不总是可能的。例如,如果时间戳字段是在添加事件时生成的未导出字段,该怎么办?在这种情况下,不可能传递特定的时间戳,最终可能会在单元测试中添加睡眠。
问题和TrimOlderThan的实现有关。因为它调用了time.Now(),所以实现健壮的单元测试更加困难。让我们讨论两种使我们的测试不那么脆弱的方法。
第一种方法是使检索当前时间的方法成为对Cache结构的依赖。在生产中,我们会注入真正的实现,而在单元测试中,我们会传递一个存根。
有多种技术可以处理这种依赖性,比如接口或函数类型。在我们的例子中,因为我们只依赖一个方法(time.Now()),我们可以定义一个函数类型:
type now func() time.Time
type Cache struct {
mu sync.RWMutex
events []Event
now now
}
now类型是一个返回time.Time的函数。在工厂函数中,我们可以这样传递实际的time.Now函数:
func NewCache() *Cache {
return &Cache{
events: make([]Event, 0),
now: time.Now,
}
}
因为now依赖项仍未导出,所以外部客户端无法访问它。此外,在我们的单元测试中,我们可以通过基于预定义的时间注入func() time.Time的假实现来创建一个Cache结构:
func TestCache_TrimOlderThan(t *testing.T) {
events := []Event{
// ❶
{
Timestamp: parseTime(t, "2020-01-01T12:00:00.04Z")},
{
Timestamp: parseTime(t, "2020-01-01T12:00:00.05Z")},
{
Timestamp: parseTime(t, "2020-01-01T12:00:00.06Z")},
}
cache := &Cache{
now: func() time.Time {
// ❷
return parseTime(t, "2020-01-01T12:00:00.06Z")
}}
cache.Add(events)
cache.TrimOlderThan(15 * time.Millisecond)
// ...
}
func parseTime(t *testing.T, timestamp string) time.Time {
// ...
}
❶ 基于特定的时间戳创建事件
❷ 注入一个静态函数来固定时间
在创建新的Cache结构时,我们根据给定的时间注入now依赖。由于这种方法,测试是健壮的。即使在最坏的情况下,这个测试的结果也是确定的。
使用全局变量
我们可以通过一个全局变量来检索时间,而不是使用字段:
var now = time.Now // ❶
❶ 定义了全局变量now
一般来说,我们应该尽量避免这种易变的共享状态。在我们的例子中,这将导致至少一个具体的问题:测试将不再是孤立的,因为它们都依赖于一个共享的变量。因此,举例来说,测试不能并行运行。如果可能的话,我们应该将这些情况作为结构依赖的一部分来处理,促进测试隔离。
这个解决方案也是可扩展的。比如函数调用time.After怎么办?我们可以添加另一个after依赖项,或者创建一个将两个方法Now和After组合在一起的接口。然而,这种方法有一个主要的缺点:例如,如果我们从一个外部包中创建一个单元测试,那么now依赖就不可用(我们在错误 90“没有探索所有的 Go 测试特性”中探讨了这一点)。
在这种情况下,我们可以使用另一种技术。我们可以要求客户端提供当前时间,而不是将时间作为未报告的依赖项来处理:
func (c *Cache) TrimOlderThan(now time.Time, since time.Duration) {
// ...
}
为了更进一步,我们可以将两个函数参数合并到一个单独的time.Time中,该参数代表一个特定的时间点,直到我们想要调整事件:
func (c *Cache) TrimOlderThan(t time.Time) {
// ...
}
由调用者来计算这个时间点:
cache.TrimOlderThan(time.Now().Add(time.Second))
而在测试中,我们也必须通过相应的时间:
func TestCache_TrimOlderThan(t *testing.T) {
// ...
cache.TrimOlderThan(parseTime(t, "2020-01-01T12:00:00.06Z").
Add(-15 * time.Millisecond))
// ...
}
这种方法是最简单的,因为它不需要创建另一种类型和存根。
一般来说,我们应该谨慎测试使用time API 的代码。这可能是一扇为古怪的测试敞开的大门。在本节中,我们看到了两种处理方法。我们可以将time交互作为依赖的一部分,通过使用我们自己的实现或依赖外部库,我们可以在单元测试中伪造这种依赖;或者我们可以修改我们的 API,要求客户提供我们需要的信息,比如当前时间(这种技术更简单,但是更有限)。
现在让我们讨论两个与测试相关的有用的 Go 包:httptest和iotest。
11.7 #88:不使用测试实用工具包
标准库提供了用于测试的实用工具包。一个常见的错误是没有意识到这些包,并试图重新发明轮子或依赖其他不方便的解决方案。本节研究其中的两个包:一个在使用 HTTP 时帮助我们,另一个在进行 I/O 和使用读取器和写入器时使用。
11.7.1 httptest包
httptest包(pkg.go.dev/net/http/httptest)为客户端和服务器端的 HTTP 测试提供了工具。让我们看看这两个用例。
首先,让我们看看httptest如何在编写 HTTP 服务器时帮助我们。我们将实现一个处理器,它执行一些基本的操作:编写标题和正文,并返回一个特定的状态代码。为了清楚起见,我们将省略错误处理:
func Handler(w http.ResponseWriter, r *http.Request) {
w.Header().Add("X-API-VERSION", "1.0")
b, _ := io.ReadAll(r.Body)
_, _ = w.Write(append([]byte("hello "), b...)) // ❶
w.WriteHeader(http.StatusCreated)
}
❶ 将hello与请求正文连接起来
HTTP 处理器接受两个参数:请求和编写响应的方式。httptest包为两者提供了实用工具。对于请求,我们可以使用 HTTP 方法、URL 和正文使用httptest.NewRequest构建一个*http.Request。对于响应,我们可以使用httptest.NewRecorder来记录处理器中的变化。让我们编写这个处理器的单元测试:
func TestHandler(t *testing.T) {
req := httptest.NewRequest(http.MethodGet, "http://localhost", // ❶
strings.NewReader("foo"))
w := httptest.NewRecorder() // ❷
Handler(w, req) // ❸
if got := w.Result().Header.Get("X-API-VERSION"); got != "1.0" {
// ❹
t.Errorf("api version: expected 1.0, got %s", got)
}
body, _ := ioutil.ReadAll(wordy) // ❺
if got := string(body); got != "hello foo" {
t.Errorf("body: expected hello foo, got %s", got)
}
if http.StatusOK != w.Result().StatusCode {
// ❻
t.FailNow()
}
}
❶ 构建请求
❷ 创建了响应记录器
❸ 调用Handler
❹ 验证 HTTP 报头
❺ 验证 HTTP 正文
❻ 验证 HTTP 状态代码
使用httptest测试处理器并不测试传输(HTTP 部分)。测试的重点是用请求和记录响应的方法直接调用处理器。然后,使用响应记录器,我们编写断言来验证 HTTP 头、正文和状态代码。
让我们看看硬币的另一面:测试 HTTP 客户端。我们将编写一个负责查询 HTTP 端点的客户机,该端点计算从一个坐标开车到另一个坐标需要多长时间。客户端看起来像这样:
func (c DurationClient) GetDuration(url string,
lat1, lng1, lat2, lng2 float64) (
time.Duration, error) {
resp, err := c.client.Post(
url, "application/json",
buildRequestBody(lat1, lng1, lat2, lng2),
)
if err != nil {
return 0, err
}
return parseResponseBody(resp.Body)
}
这段代码对提供的 URL 执行 HTTP POST 请求,并返回解析后的响应(比如说,一些 JSON)。
如果我们想测试这个客户呢?一种选择是使用 Docker 并启动一个模拟服务器来返回一些预先注册的响应。然而,这种方法使得测试执行缓慢。另一个选择是使用httptest.NewServer来创建一个基于我们将提供的处理器的本地 HTTP 服务器。一旦服务器启动并运行,我们可以将它的 URL 传递给GetDuration:
func TestDurationClientGet(t *testing.T) {
srv := httptest.NewServer( // ❶
http.HandlerFunc(
func(w http.ResponseWriter, r *http.Request) {
_, _ = w.Write([]byte(`{"duration": 314}`)) // ❷
},
),
)
defer srv.Close() // ❸
client := NewDurationClient()
duration, err :=
client.GetDuration(srv.URL, 51.551261, -0.1221146, 51.57, -0.13) // ❹
if err != nil {
t.Fatal(err)
}
if duration != 314*time.Second {
// ❺
t.Errorf("expected 314 seconds, got %v", duration)
}
}
❶ 启动 HTTP 服务器
❷ 注册处理器来服务响应
❸ 关闭了服务器
❹ 提供了服务器 URL
❺ 验证了响应
在这个测试中,我们创建了一个带有返回314秒的静态处理器的服务器。我们还可以根据发送的请求做出断言。此外,当我们调用GetDuration时,我们提供启动的服务器的 URL。与测试处理器相比,这个测试执行一个实际的 HTTP 调用,但是它的执行只需要几毫秒。
我们还可以使用 TLS 和httptest.NewTLSServer启动一个新的服务器,并使用httptest.NewUnstartedServer创建一个未启动的服务器,这样我们就可以延迟启动它。
让我们记住在 HTTP 应用的上下文中工作时httptest是多么有用。无论我们是编写服务器还是客户端,httptest都可以帮助我们创建高效的测试。
11.7.2 iotest包
iotest包(pkg.go.dev/testing/iotest)实现了测试读者和作者的实用工具。这是一个很方便的包,但 Go 开发者经常会忘记。
当实现一个自定义的io.Reader时,我们应该记得使用iotest.TestReader来测试它。这个实用函数测试读取器的行为是否正确:它准确地返回读取的字节数,填充提供的片,等等。如果提供的阅读器实现了像io.ReaderAt这样的接口,它还会测试不同的行为。
假设我们有一个自定义的LowerCaseReader,它从给定的输入io.Reader中流出小写字母。下面是如何测试这个读者没有行为不端:
func TestLowerCaseReader(t *testing.T) {
err := iotest.TestReader(
&LowerCaseReader{
reader: strings.NewReader("aBcDeFgHiJ")}, // ❶
[]byte("acegi"), // ❷
)
if err != nil {
t.Fatal(err)
}
}
❶ 提供了一个io.Reader
❷ 期望
我们通过提供自定义的LowerCaseReader和一个期望来调用iotest.TestReader:小写字母acegi。
iotest包的另一个用例是,以确保使用读取器和写入器的应用能够容忍错误:
-
iotest.ErrReader创建一个io.Reader返回一个提供的错误。 -
iotest.HalfReader创建一个io.Reader,它只读取从io.Reader请求的一半字节。 -
iotest.OneByteReader创建一个io.Reader,用于从io.Reader中读取每个非空字节。 -
iotest.TimeoutReader创建一个io.Reader,在第二次读取时返回一个没有数据的错误。后续调用将会成功。 -
iotest.TruncateWriter创建一个io.Writer写入一个io.Writer,但在n字节后静默停止。
例如,假设我们实现了以下函数,该函数从读取器读取所有字节开始:
func foo(r io.Reader) error {
b, err := io.ReadAll(r)
if err != nil {
return err
}
// ...
}
我们希望确保我们的函数具有弹性,例如,如果提供的读取器在读取期间失败(例如模拟网络错误):
func TestFoo(t *testing.T) {
err := foo(iotest.TimeoutReader( // ❶
strings.NewReader(randomString(1024)),
))
if err != nil {
t.Fatal(err)
}
}
❶ 使用iotest.TimeoutReader包装提供的io.Reader。
我们用io.TimeoutReader包装一个io.Reader。正如我们提到的,二读会失败。如果我们运行这个测试来确保我们的函数能够容忍错误,我们会得到一个测试失败。实际上,io.ReadAll会返回它发现的任何错误。
知道了这一点,我们就可以实现我们的自定义readAll函数,它可以容忍多达n个错误:
func readAll(r io.Reader, retries int) ([]byte, error) {
b := make([]byte, 0, 512)
for {
if len(b) == cap(b) {
b = append(b, 0)[:len(b)]
}
n, err := r.Read(b[len(b):cap(b)])
b = b[:len(b)+n]
if err != nil {
if err == io.EOF {
return b, nil
}
retries--
if retries < 0 {
// ❶
return b, err
}
}
}
}
❶ 容忍重试
这个实现类似于io.ReadAll,但是它也处理可配置的重试。如果我们改变初始函数的实现,使用自定义的readAll而不是io.ReadAll,测试将不再失败:
func foo(r io.Reader) error {
b, err := readAll(r, 3) // ❶
if err != nil {
return err
}
// ...
}
❶ 表示最多可重试三次
我们已经看到了一个例子,在从io.Reader中读取数据时,如何检查一个函数是否能够容忍错误。我们依靠的iotest包进行了测试。
当使用io.Reader和io.Writer进行 I/O 和工作时,让我们记住iotest包有多方便。正如我们所看到的,它提供了测试自定义io.Reader行为的实用工具,并针对读写数据时出现的错误测试我们的应用。
下一节讨论一些可能导致编写不准确基准的常见陷阱。
11.8 #89:编写不准确的基准
一般来说,我们永远不要去猜测性能。当编写优化时,许多因素可能会发挥作用,即使我们对结果有强烈的意见,测试它们也不是一个坏主意。然而,编写基准并不简单。编写不准确的基准并基于它们做出错误的假设可能非常简单。本节的目标是检查导致不准确的常见和具体的陷阱。
在讨论这些陷阱之前,让我们简单回顾一下基准在 Go 中是如何工作的。基准的框架如下:
func BenchmarkFoo(b *testing.B) {
for i := 0; i < b.N; i++ {
foo()
}
}
函数名以前缀Benchmark开头。被测函数(foo)在循环for中被调用。b.N代表可变的迭代次数。当运行一个基准时,Go 试图使它与请求的基准时间相匹配。基准时间默认设置为 1 秒,可通过-benchtime标志进行更改。b.N从 1 开始;如果基准在 1 秒内完成,b.N增加,基准再次运行,直到b.N与benchtime大致匹配:
$ go test -bench=.
cpu: Intel(R) Core(TM) i5-7360U CPU @ 2.30GHz
BenchmarkFoo-4 73 16511228 ns/op
在这里,基准测试花费了大约 1 秒钟,foo被执行了 73 次,平均执行时间为 16511228 纳秒。我们可以使用-benchtime改变基准时间:
$ go test -bench=. -benchtime=2s
BenchmarkFoo-4 150 15832169 ns/op
foo被执行死刑的人数大约是前一次基准期间的两倍。
接下来,我们来看看一些常见的陷阱。
11.8.1 不重置或暂停计时器
在某些情况下,我们需要在基准循环之前执行操作。这些操作可能需要相当长的时间(例如,生成大量数据),并且可能会显著影响基准测试结果:
func BenchmarkFoo(b *testing.B) {
expensiveSetup()
for i := 0; i < b.N; i++ {
functionUnderTest()
}
}
在这种情况下,我们可以在进入循环之前使用ResetTimer方法:
func BenchmarkFoo(b *testing.B) {
expensiveSetup()
b.ResetTimer() // ❶
for i := 0; i < b.N; i++ {
functionUnderTest()
}
}
❶ 重置基准计时器
调用ResetTimer将测试开始以来运行的基准时间和内存分配计数器清零。这样,可以从测试结果中丢弃昂贵的设置。
如果我们必须不止一次而是在每次循环迭代中执行昂贵的设置,那该怎么办?
func BenchmarkFoo(b *testing.B) {
for i := 0; i < b.N; i++ {
expensiveSetup()
functionUnderTest()
}
}
我们不能重置计时器,因为这将在每次循环迭代中执行。但是我们可以停止并恢复基准计时器,围绕对expensiveSetup的调用:
func BenchmarkFoo(b *testing.B) {
for i := 0; i < b.N; i++ {
b.StopTimer() // ❶
expensiveSetup()
b.StartTimer() // ❷
functionUnderTest()
}
}
❶ 暂停基准计时器
❷ 恢复基准计时器
这里,我们暂停基准计时器来执行昂贵的设置,然后恢复计时器。
注意,这种方法有一个问题需要记住:如果被测函数与设置函数相比执行速度太快,基准测试可能需要太长时间才能完成。原因是到达benchtime需要比 1 秒长得多的时间。基准时间的计算完全基于functionUnderTest的执行时间。因此,如果我们在每次循环迭代中等待很长时间,基准测试将会比 1 秒慢得多。如果我们想保持基准,一个可能的缓解措施是减少benchtime。
我们必须确保使用计时器方法来保持基准的准确性。
11.8.2 对微观基准做出错误的假设
微基准测试测量一个微小的计算单元,并且很容易对它做出错误的假设。比方说,我们不确定是使用atomic.StoreInt32还是atomic.StoreInt64(假设我们处理的值总是适合 32 位)。我们希望编写一个基准来比较这两种函数:
func BenchmarkAtomicStoreInt32(b *testing.B) {
var v int32
for i := 0; i < b.N; i++ {
atomic.StoreInt32(&v, 1)
}
}
func BenchmarkAtomicStoreInt64(b *testing.B) {
var v int64
for i := 0; i < b.N; i++ {
atomic.StoreInt64(&v, 1)
}
}
如果我们运行该基准测试,下面是一些示例输出:
cpu: Intel(R) Core(TM) i5-7360U CPU @ 2.30GHz
BenchmarkAtomicStoreInt32
BenchmarkAtomicStoreInt32-4 197107742 5.682 ns/op
BenchmarkAtomicStoreInt64
BenchmarkAtomicStoreInt64-4 213917528 5.134 ns/op
我们很容易认为这个基准是理所当然的,并决定使用atomic.StoreInt64,因为它似乎更快。现在,为了做一个公平的基准测试,我们颠倒一下顺序,先测试atomic.StoreInt64,再测试atomic.StoreInt32。以下是一些输出示例:
BenchmarkAtomicStoreInt64
BenchmarkAtomicStoreInt64-4 224900722 5.434 ns/op
BenchmarkAtomicStoreInt32
BenchmarkAtomicStoreInt32-4 230253900 5.159 ns/op
这一次,atomic.StoreInt32效果更好。发生了什么事?
在微基准的情况下,许多因素都会影响结果,例如运行基准时的机器活动、电源管理、散热以及指令序列的更好的高速缓存对齐。我们必须记住,许多因素,即使在我们的 Go 项目范围之外,也会影响结果。
注意,我们应该确保执行基准测试的机器是空闲的。但是,外部流程可能在后台运行,这可能会影响基准测试结果。出于这个原因,像perflock这样的工具可以限制基准测试消耗多少 CPU。例如,我们可以用总可用 CPU 的 70%来运行基准测试,将 30%分配给操作系统和其他进程,并减少机器活动因素对结果的影响。
一种选择是使用-benchtime选项增加基准时间。类似于概率论中的大数定律,如果我们运行基准测试很多次,它应该倾向于接近它的期望值(假设我们忽略了指令缓存和类似机制的好处)。
另一种选择是在经典的基准工具之上使用外部工具。例如,benchstat工具,是golang.org/x库的的一部分,它允许我们计算和比较关于基准执行的统计数据。
让我们使用和-count选项运行基准测试 10 次,并将输出传输到一个特定的文件:
$ go test -bench=. -count=10 | tee stats.txt
cpu: Intel(R) Core(TM) i5-7360U CPU @ 2.30GHz
BenchmarkAtomicStoreInt32-4 234935682 5.124 ns/op
BenchmarkAtomicStoreInt32-4 235307204 5.112 ns/op
// ...
BenchmarkAtomicStoreInt64-4 235548591 5.107 ns/op
BenchmarkAtomicStoreInt64-4 235210292 5.090 ns/op
// ...
然后我们可以对这个文件运行benchstat:
$ benchstat stats.txt
name time/op
AtomicStoreInt32-4 5.10ns ± 1%
AtomicStoreInt64-4 5.10ns ± 1%
结果是一样的:两个函数平均需要 5.10 纳秒来完成。我们还可以看到给定基准的执行之间的百分比变化:1%。这个指标告诉我们,两个基准都是稳定的,让我们对计算出的平均结果更有信心。因此,对于我们测试的使用情况(在特定机器上的特定 Go 版本中),我们可以得出其执行时间与atomic .StoreInt64相似的结论,而不是得出atomic.StoreInt32更快或更慢的结论。
总的来说,我们应该对微基准保持谨慎。许多因素会显著影响结果,并可能导致错误的假设。增加基准测试时间或使用benchstat等工具重复执行基准测试并计算统计数据,可以有效地限制外部因素并获得更准确的结果,从而得出更好的结论。
我们还要强调的是,如果另一个系统最终运行了该应用,那么在使用在给定机器上执行的微基准测试的结果时,我们应该小心。生产系统的行为可能与我们运行微基准测试的系统大相径庭。
11.8.3 不注意编译器优化
另一个与编写基准相关的常见错误是被编译器优化所愚弄,这也可能导致错误的基准假设。在这一节中,我们来看看 Go issue 14813 ( github.com/golang/go/issues/14813 ,也是 Go 项目成员戴夫·切尼讨论过的)的人口计数函数(计算设置为1的位数的函数):
const m1 = 0x5555555555555555
const m2 = 0x3333333333333333
const m4 = 0x0f0f0f0f0f0f0f0f
const h01 = 0x0101010101010101
func popcnt(x uint64) uint64 {
x -= (x >> 1) & m1
x = (x & m2) + ((x >> 2) & m2)
x = (x + (x >> 4)) & m4
return (x * h01) >> 56
}
这个函数接受并返回一个uint64。为了对这个函数进行基准测试,我们可以编写以下代码:
func BenchmarkPopcnt1(b *testing.B) {
for i := 0; i < b.N; i++ {
popcnt(uint64(i))
}
}
然而,如果我们执行这个基准测试,我们得到的结果低得惊人:
cpu: Intel(R) Core(TM) i5-7360U CPU @ 2.30GHz
BenchmarkPopcnt1-4 1000000000 0.2858 ns/op
0.28 纳秒的持续时间大约是一个时钟周期,所以这个数字低得不合理。问题是开发人员对编译器优化不够仔细。在这种情况下,测试中的函数足够简单,可以作为内联的候选函数:这是一种用被调用函数的正文替换函数调用的优化,让我们可以避免函数调用,它占用的内存很小。一旦函数被内联,编译器会注意到该调用没有副作用,并将其替换为以下基准:
func BenchmarkPopcnt1(b *testing.B) {
for i := 0; i < b.N; i++ {
// Empty
}
}
基准现在是空的——这就是为什么我们得到了接近一个时钟周期的结果。为了防止这种情况发生,最佳实践是遵循以下模式:
-
在每次循环迭代中,将结果赋给一个局部变量(基准函数上下文中的局部变量)。
-
将最新结果赋给一个全局变量。
在我们的例子中,我们编写了以下基准:
var global uint64 // ❶
func BenchmarkPopcnt2(b *testing.B) {
var v uint64 // ❷
for i := 0; i < b.N; i++ {
v = popcnt(uint64(i)) // ❸
}
global = v // ❹
}
❶ 定义了一个全局变量
❷ 定义了一个局部变量
❸ 将结果赋给局部变量
❹ 将结果赋给全局变量
global是全局变量,而v是局部变量,其作用域是基准函数。在每次循环迭代中,我们将popcnt的结果赋给局部变量。然后我们将最新的结果赋给全局变量。
注意为什么不把popcnt调用的结果直接分配给global来简化测试呢?写入一个全局变量比写入一个局部变量要慢(我们在错误#95“不理解栈和堆”中讨论了这些概念)。因此,我们应该将每个结果写入一个局部变量,以限制每次循环迭代期间的内存占用。
如果我们运行这两个基准测试,我们现在会得到显著不同的结果:
cpu: Intel(R) Core(TM) i5-7360U CPU @ 2.30GHz
BenchmarkPopcnt1-4 1000000000 0.2858 ns/op
BenchmarkPopcnt2-4 606402058 1.993 ns/op
BenchmarkPopcnt2是基准的准确版本。它保证我们避免了内联优化,内联优化会人为地降低执行时间,甚至会删除对被测函数的调用。依赖BenchmarkPopcnt1的结果可能会导致错误的假设。
让我们记住避免编译器优化愚弄基准测试结果的模式:将被测函数的结果赋给一个局部变量,然后将最新的结果赋给一个全局变量。这种最佳实践还可以防止我们做出不正确的假设。
11.8.4 被观察者效应所迷惑
在物理学中,观察者效应是观察行为对被观察系统的扰动。这种影响也可以在基准测试中看到,并可能导致对结果的错误假设。让我们看一个具体的例子,然后尝试减轻它。
我们想要实现一个函数来接收一个由int64元素组成的矩阵。这个矩阵有固定的 512 列,我们想计算前八列的总和,如图 11.2 所示。

图 11.2 计算前八列的总和
为了优化,我们还想确定改变列数是否有影响,所以我们还实现了第二个函数,有 513 列。实现如下:
func calculateSum512(s [][512]int64) int64 {
var sum int64
for i := 0; i < len(s); i++ {
// ❶
for j := 0; j < 8; j++ {
// ❷
sum += s[i][j] // ❸
}
}
return sum
}
func calculateSum513(s [][513]int64) int64 {
// Same implementation as calculateSum512
}
❶ 遍历每一行
❷ 遍历前八列
❸ 增加sum
我们遍历每一行,然后遍历前八列,并增加一个返回的sum变量。calculateSum513中的实现保持不变。
我们希望对这些函数进行基准测试,以确定在给定固定行数的情况下哪一个函数的性能最高:
const rows = 1000
var res int64
func BenchmarkCalculateSum512(b *testing.B) {
var sum int64
s := createMatrix512(rows) // ❶
b.ResetTimer()
for i := 0; i < b.N; i++ {
sum = calculateSum512(s) // ❷
}
res = sum
}
func BenchmarkCalculateSum513(b *testing.B) {
var sum int64
s := createMatrix513(rows) // ❸
b.ResetTimer()
for i := 0; i < b.N; i++ {
sum = calculateSum513(s) // ❹
}
res = sum
}
❶ 创建了一个 512 列的矩阵
❷ 计算总数
❸ 创建了一个 513 列的矩阵
❹ 计算总数
我们希望只创建一次矩阵,以限制结果的影响。因此,我们在循环外调用createMatrix512和createMatrix513。我们可能期望结果是相似的,因为我们只希望迭代前八列,但实际情况并非如此(在我的机器上):
cpu: Intel(R) Core(TM) i5-7360U CPU @ 2.30GHz
BenchmarkCalculateSum512-4 81854 15073 ns/op
BenchmarkCalculateSum513-4 161479 7358 ns/op
具有 513 列的第二个基准测试快了大约 50%。同样,因为我们只迭代了前八列,所以这个结果相当令人惊讶。
为了理解这种差异,我们需要理解 CPU 缓存的基础知识。简而言之,CPU 由不同的缓存组成(通常是 L1、L2 和 L3)。这些高速缓存降低了从主存储器访问数据的平均成本。在某些情况下,CPU 可以从主存储器中取出数据,并将其复制到 L1。在这种情况下,CPU 试图将calculateSum感兴趣的矩阵子集(每行的前八列)读入 L1。但是,在一种情况下(513 列),矩阵适合内存,而在另一种情况下(512 列),则不适合。
注意解释原因不在本章的范围内,但是我们在错误#91“不理解 CPU 缓存”中来看这个问题
回到基准测试,主要问题是我们在两种情况下都重复使用相同的矩阵。因为函数重复了成千上万次,所以当它接收一个普通的新矩阵时,我们不测量函数的执行。相反,我们测量一个函数,该函数获取一个矩阵,该矩阵已经包含缓存中存在的单元的子集。因此,因为calculateSum513导致缓存未命中更少,所以它有更好的执行时间。
这是观察者效应的一个例子。因为我们一直在观察一个被反复调用的 CPU 绑定函数,所以 CPU 缓存可能会发挥作用并显著影响结果。在这个例子中,为了防止这种影响,我们应该在每个测试期间创建一个矩阵,而不是重用一个:
func BenchmarkCalculateSum512(b *testing.B) {
var sum int64
for i := 0; i < b.N; i++ {
b.StopTimer()
s := createMatrix512(rows) // ❶
b.StartTimer()
sum = calculateSum512(s)
}
res = sum
}
❶ 在每次循环迭代中都会创建一个新矩阵
现在,在每次循环迭代中都会创建一个新矩阵。如果我们再次运行基准测试(并调整benchtime——否则执行时间太长),结果会更接近:
cpu: Intel(R) Core(TM) i5-7360U CPU @ 2.30GHz
BenchmarkCalculateSum512-4 1116 33547 ns/op
BenchmarkCalculateSum513-4 998 35507 ns/op
我们没有做出calculateSum513更快的错误假设,而是看到两个基准测试在接收新矩阵时会产生相似的结果。
正如我们在本节中看到的,因为我们重用了相同的矩阵,CPU 缓存显著影响了结果。为了防止这种情况,我们必须在每次循环迭代中创建一个新的矩阵。一般来说,我们应该记住,观察测试中的函数可能会导致结果的显著差异,特别是在低级别优化很重要的 CPU 绑定函数的微基准环境中。强制基准在每次迭代期间重新创建数据是防止这种影响的好方法。
在本章的最后一节,让我们看看一些关于GO测试的常见技巧。
11.9 #90:没有探索所有的 Go 测试功能
在编写测试时,开发人员应该了解 Go 的特定测试特性和选项。否则,测试过程可能不太准确,甚至效率更低。这一节讨论的主题可以让我们在编写 Go 测试时更加舒适。
11.9.1 代码覆盖率
在开发过程中,直观地看到测试覆盖了代码的哪些部分是很方便的。我们可以使用的-coverprofile标志来访问这些信息:
$ go test -coverprofile=coverage.out ./...
这个命令创建一个coverage.out文件,然后我们可以使用go tool cover打开它:
$ go tool cover -html=coverage.out
该命令打开 web 浏览器并显示每行代码的覆盖率。
默认情况下,只对当前被测试的包进行代码覆盖率分析。例如,假设我们有以下结构:
/myapp
|_ foo
|_ foo.go
|_ foo_test.go
|_ bar
|_ bar.go
|_ bar_test.go
如果foo.go的某个部分只在bar_test.go中测试,默认情况下,它不会显示在覆盖率报告中。要包含它,我们必须在myapp文件夹中,并且使用-coverpkg标志:
go test -coverpkg=./... -coverprofile=coverage.out ./...
我们需要记住这个特性来查看当前的代码覆盖率,并决定哪些部分值得更多的测试。
注意在跟踪代码覆盖率时要保持谨慎。拥有 100%的测试覆盖率并不意味着一个没有 bug 的应用。正确地推理我们的测试覆盖的内容比任何静态的阈值更重要。
11.9.2 不同包的测试
当编写单元测试时,一种方法是关注行为而不是内部。假设我们向客户端公开一个 API。我们可能希望我们的测试关注于从外部可见的东西,而不是实现细节。这样,如果实现发生变化(例如,如果我们将一个函数重构为两个),测试将保持不变。它们也更容易理解,因为它们展示了我们的 API 是如何使用的。如果我们想强制执行这种做法,我们可以使用不同的包。
在 Go 中,一个文件夹中的所有文件应该属于同一个包,只有一个例外:一个测试文件可以属于一个_test包。例如,假设下面的counter.go源文件属于counter包:
package counter
import "sync/atomic"
var count uint64
func Inc() uint64 {
atomic.AddUint64(&count, 1)
return count
}
测试文件可以存在于同一个包中,并访问内部文件,比如count变量。或者它可以存在于一个counter_test包中,比如这个counter_test.go文件:
package counter_test
import (
"testing"
"myapp/counter"
)
func TestCount(t *testing.T) {
if counter.Inc() != 1 {
t.Errorf("expected 1")
}
}
在这种情况下,测试是在一个外部包中实现的,不能访问内部包,比如count变量。使用这种实践,我们可以保证测试不会使用任何未导出的元素;因此,它将着重于测试公开的行为。
11.9.3 实用函数
在编写测试时,我们可以用不同于生产代码的方式处理错误。例如,假设我们想要测试一个函数,它将一个Customer结构作为参数。因为Customer的创建将被重用,为了测试,我们决定创建一个特定的createCustomer函数。该函数将返回一个可能的错误,并附带一个Customer:
func TestCustomer(t *testing.T) {
customer, err := createCustomer("foo") // ❶
if err != nil {
t.Fatal(err)
}
// ...
}
func createCustomer(someArg string) (Customer, error) {
// Create customer
if err != nil {
return Customer{
}, err
}
return customer, nil
}
❶ 创建一个Customer并检查错误
我们使用createCustomer实用函数创建一个客户,然后我们执行剩下的测试。然而,在测试函数的上下文中,我们可以通过将*testing.T变量传递给实用函数来简化错误管理:
func TestCustomer(t *testing.T) {
customer := createCustomer(t, "foo") // ❶
// ...
}
func createCustomer(t *testing.T, someArg string) Customer {
// Create customer
if err != nil {
t.Fatal(err) // ❷
}
return customer
}
❶ 调用效用函数并提供t
❷ 如果我们不能创建一个客户,就直接失败了
如果不能创建一个Customer,那么createCustomer会直接测试失败,而不是返回一个错误。这使得TestCustomer写起来更小,读起来更容易。
让我们记住这个关于错误管理和测试的实践来改进我们的测试。
11.9.4 安装和拆卸
在某些情况下,我们可能需要准备一个测试环境。例如,在集成测试中,我们启动一个特定的 Docker 容器,然后停止它。我们可以为每个测试或每个包调用安装和拆卸函数。幸运的是,在GO中,两者都有可能。
为了每次测试都这样做,我们可以使用defer调用安装函数和拆卸函数作为预操作:
func TestMySQLIntegration(t *testing.T) {
setupMySQL()
defer teardownMySQL()
// ...
}
也可以注册一个在测试结束时执行的函数。例如,让我们假设TestMySQLIntegration需要调用createConnection来创建数据库连接。如果我们希望这个函数也包含拆卸部分,我们可以使用t.Cleanup来注册一个清理函数:
func TestMySQLIntegration(t *testing.T) {
// ...
db := createConnection(t, "tcp(localhost:3306)/db")
// ...
}
func createConnection(t *testing.T, dsn string) *sql.DB {
db, err := sql.Open("mysql", dsn)
if err != nil {
t.FailNow()
}
t.Cleanup( // ❶
func() {
_ = db.Close()
})
return db
}
❶ 注册了一个要在测试结束时执行的函数
测试结束时,执行提供给t.Cleanup的关闭。这使得未来的单元测试更容易编写,因为它们不会负责关闭db变量。
注意,我们可以注册多个清理函数。在这种情况下,它们将被执行,就像我们使用defer一样:后进先出。
为了处理每个包的安装和拆卸,我们必须使用TestMain函数。下面是TestMain的一个简单实现:
func TestMain(m *testing.M) {
os.Exit(m.Run())
}
这个特定的函数接受一个*testing.M参数,该参数公开了一个运行所有测试的Run方法。因此,我们可以用安装和拆卸数围绕这个调用:
func TestMain(m *testing.M) {
setupMySQL() // ❶
code := m.Run() // ❷
teardownMySQL() // ❸
os.Exit(code)
}
❶ 安装 MySQL
❷ 负责测试
❸ 拆卸 MySQL
这段代码在所有测试之前启动 MySQL 一次,然后将其关闭。
使用这些实践来添加安装和拆卸函数,我们可以为我们的测试配置一个复杂的环境。
总结
-
使用构建标志、环境变量或者短模式对测试进行分类使得测试过程更加有效。您可以使用构建标志或环境变量来创建测试类别(例如,单元测试与集成测试),并区分短期和长期运行的测试,以决定执行哪种测试。
-
在编写并发应用时,强烈建议启用
-race标志。这样做可以让您捕捉到可能导致软件错误的潜在数据竞争。 -
使用
-parallel标志是加速测试的有效方法,尤其是长时间运行的测试。 -
使用
-shuffle标志来帮助确保测试套件不依赖于可能隐藏 bug 的错误假设。 -
表驱动测试是一种有效的方法,可以将一组相似的测试分组,以防止代码重复,并使未来的更新更容易处理。
-
使用同步来避免睡眠,以使测试不那么不稳定,更健壮。如果同步是不可能的,考虑重试的方法。
-
理解如何使用时间 API 处理函数是使测试不那么容易出错的另一种方法。您可以使用标准技术,比如将时间作为隐藏依赖项的一部分来处理,或者要求客户端提供时间。
-
httptest包有助于处理 HTTP 应用。它提供了一组测试客户机和服务器的实用工具。 -
iotest包帮助编写io.Reader并测试应用是否能够容忍错误。 -
关于基准:
- 使用时间方法保持基准的准确性。
- 增加
benchtime或使用benchstat等工具在处理微基准时会有所帮助。 - 如果最终运行应用的系统与运行微基准测试的系统不同,请小心微基准测试的结果。
- 确保被测函数会导致副作用,防止编译器优化在基准测试结果上欺骗你。
- 为了防止观察者效应,强制基准重新创建 CPU 绑定函数使用的数据。
-
使用带有
-coverprofile标志的代码覆盖率来快速查看哪部分代码需要更多的关注。 -
将单元测试放在一个不同的包中,以强制编写关注于公开行为而不是内部的测试。
-
使用
*testing.T变量而不是经典的iferr !=nil来处理错误使得代码更短,更容易阅读。 -
你可以使用安装和拆卸函数来配置一个复杂的环境,比如在集成测试的情况下。
十二、优化
本章涵盖
- 研究机械同情心的概念
- 了解堆与栈并减少分配
- 使用标准 Go 诊断工具
- 了解垃圾收集器的工作原理
- 跑GO里面的 Docker 和 Kubernetes
在我们开始这一章之前,一个免责声明:在大多数情况下,编写可读、清晰的代码比编写优化但更复杂、更难理解的代码要好。优化通常是有代价的,我们建议您遵循软件工程师 Wes Dyer 的这句名言:
使其正确,使其清晰,使其简洁,使其快速,按此顺序。
这并不意味着禁止优化应用的速度和效率。例如,我们可以尝试识别需要优化的代码路径,因为有必要这样做,比如让我们的客户满意或者降低我们的成本。在本章中,我们将讨论常见的优化技术;有些是特定要去的,有些不是。我们还讨论了识别瓶颈的方法,这样我们就不会盲目工作。
12.1 #91:不了解 CPU 缓存
当赛车手不一定要当工程师,但一定要有机械同情心。
——三届 F1 世界冠军杰基·斯图瓦特创建的一个术语
简而言之,当我们了解一个系统是如何被设计使用的,无论是 F1 赛车、飞机还是计算机,我们都可以与设计保持一致,以获得最佳性能。在本节中,我们将讨论一些具体的例子,在这些例子中,对 CPU 缓存如何工作的机械同情可以帮助我们优化 Go 应用。
12.1.1 CPU 架构
首先让我们了解一下 CPU 架构的基础知识,以及为什么 CPU 缓存很重要。我们将以英特尔酷睿 i5-7300 为例。
现代 CPU 依靠缓存来加速内存访问,大多数情况下通过三个缓存级别:L1、L2 和 L3。在 i5-7300 上,这些高速缓存的大小如下:
-
L1: 64 KB
-
L2: 256 KB
-
三级:4 MB
i5-7300 有两个物理内核,但有四个逻辑内核(也称为虚拟内核或线程)。在英特尔家族中,将一个物理内核划分为多个逻辑内核称为超线程。
图 12.1 给出了英特尔酷睿 i5-7300 的概述(Tn代表线程n)。每个物理核心(核心 0 和核心 1)被分成两个逻辑核心(线程 0 和线程 1)。L1 缓存分为两个子缓存:L1D 用于数据,L1I 用于指令(每个 32 KB)。缓存不仅仅与数据相关,当 CPU 执行一个应用时,它也可以缓存一些指令,理由相同:加速整体执行。

图 12.1 i5-7300 具有三级高速缓存、两个物理内核和四个逻辑内核。
存储器位置越靠近逻辑核心,访问速度越快(参见 mng.bz/o29v ):
-
L1:大约 1 纳秒
-
L2:大约比 L1 慢 4 倍
-
L3:大约比 L1 慢 10 倍
CPU 缓存的物理位置也可以解释这些差异。L1 和 L2被称为片上,这意味着它们与处理器的其余部分属于同一块硅片。相反,L3 是片外,这部分解释了与 L1 和 L2 相比的延迟差异。
对于主内存(或 RAM),平均访问速度比 L1 慢 50 到 100 倍。我们可以访问存储在 L1 上的多达 100 个变量,只需支付一次访问主存储器的费用。因此,作为 Go 开发人员,一个改进的途径是确保我们的应用使用 CPU 缓存。
12.1.2 高速缓存行
理解高速缓存行的概念至关重要。但是在介绍它们是什么之前,让我们了解一下为什么我们需要它们。
当访问特定的内存位置时(例如,通过读取变量),在不久的将来可能会发生以下情况之一:
-
相同的位置将被再次引用。
-
将引用附近的存储位置。
前者指时间局部性,后者指空间局部性。两者都是称为引用位置的原则的一部分。
例如,让我们看看下面这个计算一个int64切片之和的函数:
func sum(s []int64) int64 {
var total int64
length := len(s)
for i := 0; i < length; i++ {
total += s[i]
}
return total
}
在这个例子中,时间局部性适用于多个变量:i、length和total。在整个迭代过程中,我们不断地访问这些变量。空间局部性适用于代码指令和切片s。因为一个片是由内存中连续分配的数组支持的,在这种情况下,访问s[0]也意味着访问s[1]、s[2]等等。
时间局部性是我们需要 CPU 缓存的部分原因:加速对相同变量的重复访问。然而,由于空间局部性,CPU 复制我们称之为缓存行,而不是将单个变量从主内存复制到缓存。
高速缓存行是固定大小的连续内存段,通常为 64 字节(8 个int64变量)。每当 CPU 决定从 RAM 缓存内存块时,它会将内存块复制到缓存行。因为内存是一个层次结构,当 CPU 想要访问一个特定的内存位置时,它首先检查 L1,然后是 L2,然后是 L3,最后,如果该位置不在这些缓存中,则检查主内存。
让我们用一个具体的例子来说明获取内存块。我们第一次用 16 个int64元素的切片调用sum函数。当sum访问s[0]时,这个内存地址还不在缓存中。如果 CPU 决定缓存这个变量(我们在本章后面也会讨论这个决定),它会复制整个内存块;参见图 12.2。

图 12.2 访问s[0]使 CPU 复制 0x000 内存块。
首先,访问s[0]会导致缓存未命中,因为地址不在缓存中。这种错过被称为一种强制错过。但是,如果 CPU 获取 0x000 存储块,访问从 1 到 7 的元素会导致缓存命中。当sum访问s[8]时,同样的逻辑也适用(见图 12.3)。

图 12.3 访问s[8]使 CPU 复制 0x100 内存块。
同样,访问s8会导致强制未命中。但是如果将0x100内存块复制到高速缓存行中,也会加快对元素 9 到 15 的访问。最后,迭代 16 个元素导致 2 次强制缓存未命中和 14 次缓存命中。
CPU 缓存策略
你可能想知道当 CPU 复制一个内存块时的确切策略。例如,它会将一个块复制到所有级别吗?只去 L1?在这种情况下,L2 和 L3 怎么办?
我们必须知道存在不同的策略。有时缓存是包含性的(例如,L2 数据也存在于 L3 中),有时缓存是排他性的(例如,L3 被称为牺牲缓存,因为它只包含从 L2 逐出的数据)。
一般来说,这些策略都是 CPU 厂商隐藏的,知道了不一定有用。所以,这些问题我们就不深究了。
让我们看一个具体的例子来说明 CPU 缓存有多快。我们将实现两个函数,它们在迭代一片int64元素时计算总数。在一种情况下,我们将迭代每两个元素,在另一种情况下,迭代每八个元素:
func sum2(s []int64) int64 {
var total int64
for i := 0; i < len(s); i+=2 {
// ❶
total += s[i]
}
return total
}
func sum8(s []int64) int64 {
var total int64
for i := 0; i < len(s); i += 8 {
// ❷
total += s[i]
}
return total
}
❶ 迭代每两个元素
❷ 迭代每八个元素
除了迭代之外,这两个函数是相同的。如果我们对这两个函数进行基准测试,我们的直觉可能是第二个版本会快四倍,因为我们需要增加的元素少了四倍。然而,运行基准测试表明sum8在我的机器上只快了 10%:仍然更快,但是只快了 10%。
原因与缓存行有关。我们看到一个缓存行通常是 64 字节,包含多达 8 个int64变量。这里,这些循环的运行时间是由内存访问控制的,而不是增量指令。在第一种情况下,四分之三的访问导致缓存命中。因此,这两个函数的执行时间差异并不明显。这个例子展示了为什么缓存行很重要,以及如果我们缺乏机械的同情心,我们很容易被我们的直觉所欺骗——在这个例子中,是关于 CPU 如何缓存数据的。
让我们继续讨论引用的局部性,看一个使用空间局部性的具体例子。
12.1.3 结构切片与切片结构
本节看一个比较两个函数执行时间的例子。第一个将一部分结构作为参数,并对所有的a字段求和:
type Foo struct {
a int64
b int64
}
func sumFoo(foos []Foo) int64 {
// ❶
var total int64
for i := 0; i < len(foos); i++ {
// ❷
total += foos[i].a
}
return total
}
❶ 获取Foo切片
❷ 对每个Foo进行迭代,并对每个字段求和
sumFoo接收Foo的一部分,并通过读取每个a域来增加total。
第二个函数也计算总和。但是这一次,参数是一个包含片的结构:
type Bar struct {
a []int64 // ❶
b []int64
}
func sumBar(bar Bar) int64 {
// ❷
var total int64
for i := 0; i < len(bar.a); i++ {
// ❸
total += bar.a[i] // ❹
}
return total
}
❶ a和b现在是切片。
❷ 接收单个结构
❸ 遍历bar
❹ 增加了total
sumBar接收一个包含两个切片的Bar结构:a和b。它遍历a的每个元素来增加total。
我们期望这两个函数在速度上有什么不同吗?在运行基准测试之前,让我们在图 12.4 中直观地看看内存的差异。两种情况的数据量相同:切片中有 16 个Foo元素,切片中有 16 个Bar元素。每个黑条代表一个被读取以计算总和的int64,而每个灰条代表一个被跳过的int64。

图 12.4 切片结构更紧凑,因此需要迭代的缓存行更少。
在sumFoo的情况下,我们收到一个包含两个字段a和b的结构片。因此,我们在内存中有一连串的a和b。相反,在sumBar的情况下,我们收到一个包含两个片的结构,a和b。因此,a的所有元素都是连续分配的。
这种差异不会导致任何内存压缩优化。但是这两个函数的目标都是迭代每个a,这样做在一种情况下需要四个缓存行,在另一种情况下只需要两个缓存行。
如果对这两个函数进行基准测试,sumBar更快(在我的机器上大约快 20%)。主要原因是更好的空间局部性,这使得 CPU 从内存中获取更少的缓存行。
这个例子演示了空间局部性如何对性能产生重大影响。为了优化应用,我们应该组织数据,以从每个单独的缓存行中获得最大的价值。
但是,使用空间局部性就足以帮助 CPU 了吗?我们仍然缺少一个关键特征:可预测性。
12.1.4 可预测性
可预测性是指 CPU 预测应用将如何加速其执行的能力。让我们看一个具体的例子,缺乏可预测性会对应用性能产生负面影响。
再一次,让我们看两个对元素列表求和的函数。第一个循环遍历一个链表并对所有值求和:
type node struct {
// ❶
value int64
next *node
}
func linkedList(n *node) int64 {
var total int64
for n != nil {
// ❷
total += n.value // ❸
n = n.next
}
return total
}
❶ 链表数据结构
❷ 迭代每个节点
❸ 增加total
这个函数接收一个链表,遍历它,并增加一个总数。
另一方面,让我们再来看一下sum2函数,它迭代一个片,两个元素中的一个:
func sum2(s []int64) int64 {
var total int64
for i := 0; i < len(s); i+=2 {
// ❶
total += s[i]
}
return total
}
❶ 迭代每两个元素
让我们假设链表是连续分配的:例如,由单个函数分配。在 64 位架构中,一个字的长度是 64 位。图 12.5 比较了函数接收的两种数据结构(链表或切片);深色的条代表
我们用来增加总数的int64元素。

图 12.5 在内存中,链表和切片以类似的方式压缩。
在这两个例子中,我们面临类似的压缩。因为链表是由一连串的值和 64 位指针元素组成的,所以我们使用两个元素中的一个来增加总和。同时,sum2的例子只读取了两个元素中的一个。
这两个数据结构具有相同的空间局部性,因此我们可以预期这两个函数的执行时间相似。但是在片上迭代的函数要快得多(在我的机器上大约快 70%)。原因是什么?
要理解这一点,我们得讨论一下大步走的概念。跨越与 CPU 如何处理数据有关。有三种不同类型的步幅(见图 12.6):
-
单位步幅——我们要访问的所有值都是连续分配的:比如一片
int64元素。这一步对于 CPU 来说是可预测的,也是最有效的,因为它需要最少数量的缓存行来遍历元素。 -
恒定步幅——对于 CPU 来说仍然是可预测的:例如,每两个元素迭代一次的切片。这个步幅需要更多的缓存行来遍历数据,因此它的效率比单位步幅低。
-
非单位步幅——CPU 无法预测的一个步幅:比如一个链表或者一片指针。因为 CPU 不知道数据是否是连续分配的,所以它不会获取任何缓存行。

图 12.6 三种类型的步幅
对于sum2,我们面对的是一个不变的大步。但是,对于链表来说,我们面临的是非单位跨步。即使我们知道数据是连续分配的,CPU 也不知道。因此,它无法预测如何遍历链表。
由于不同的步距和相似的空间局部性,遍历一个链表比遍历一个值要慢得多。由于更好的空间局部性,我们通常更喜欢单位步幅而不是常数步幅。但是,无论数据如何分配,CPU 都无法预测非单位步幅,从而导致负面的性能影响。
到目前为止,我们已经讨论了 CPU 缓存速度很快,但明显小于主内存。因此,CPU 需要一种策略来将内存块提取到缓存行。这种策略称为缓存放置策略和会显著影响性能。
12.1.5 缓存放置策略
在错误#89“编写不准确的基准测试”中,我们讨论了一个矩阵示例,其中我们必须计算前八列的总和。在这一点上,我们没有解释为什么改变列的总数会影响基准测试的结果。这听起来可能违反直觉:因为我们只需要读取前八列,为什么改变总列数会影响执行时间?让我们来看看这一部分。
提醒一下,实现如下:
func calculateSum512(s [][512]int64) int64 {
// ❶
var sum int64
for i := 0; i < len(s); i++ {
for j := 0; j < 8; j++ {
sum += s[i][j]
}
}
return sum
}
func calculateSum513(s [][513]int64) int64 {
// ❷
// Same implementation as calculateSum512
}
❶ 接收 512 列的矩阵
❷ 接收 513 列的矩阵
我们迭代每一行,每次对前八列求和。当这两个函数每次都用一个新矩阵作为基准时,我们没有观察到任何差异。然而,如果我们继续重用相同的矩阵,calculateSum513在我的机器上大约快 50%。原因在于 CPU 缓存以及如何将内存块复制到缓存行。让我们对此进行检查,以了解这种差异。
当 CPU 决定复制一个内存块并将其放入缓存时,它必须遵循特定的策略。假设 L1D 缓存为 32 KB,缓存行为 64 字节,如果将一个块随机放入 L1D,CPU 在最坏的情况下将不得不迭代 512 个缓存行来读取一个变量。这种缓存叫做全关联。
为了提高从 CPU 缓存中访问地址的速度,设计人员在缓存放置方面制定了不同的策略。让我们跳过历史,讨论一下今天使用最广泛的选项:组关联缓存,其中依赖于缓存分区。
为了使下图更清晰,我们将简化问题:
-
我们假设 L1D 缓存为 512 字节(8 条缓存线)。
-
矩阵由 4 行 32 列组成,我们将只读取前 8 列。
图 12.7 显示了这个矩阵如何存储在内存中。我们将使用内存块地址的二进制表示。同样,灰色块代表我们想要迭代的前 8 个int64元素。剩余的块在迭代过程中被跳过。

图 12.7 存储在内存中的矩阵,以及用于执行的空缓存
每个存储块包含 64 个字节,因此有 8 个int64元素。第一个内存块从 0x000000000000 开始,第二个从 0001000000000(二进制 512)开始,依此类推。我们还展示了可以容纳 8 行的缓存。
请注意,我们将在错误#94“不知道数据对齐”中看到,切片不一定从块的开头开始。
使用组关联高速缓存策略,高速缓存被划分为多个组。我们假设高速缓存是双向组关联的,这意味着每个组包含两行。一个内存块只能属于一个集合,其位置由内存地址决定。为了理解这一点,我们必须将内存块地址分成三个部分:
-
块偏移是基于块大小的。这里块的大小是 512 字节,512 等于
2^9。因此,地址的前 9 位代表块偏移(BO)。 -
集合索引表示一个地址所属的集合。因为高速缓存是双向组关联的,并且包含 8 行,所以我们有
8 / 2 = 4个组。此外,4 等于2^2,因此接下来的两位表示集合索引(SI)。 -
地址的其余部分由标签位(TB)组成。在图 12.7 中,为了简单起见,我们用 13 位来表示一个地址。为了计算 TB,我们使用
13 - BO - SI。这意味着剩余的两位代表标签位。
假设该函数启动并试图读取属于地址 000000000000 的s[0][0]。因为这个地址还不在高速缓存中,所以 CPU 计算它的集合索引并将其复制到相应的高速缓存集合中(图 12.8)。

图 12.8 内存地址 000000000000 被复制到集合 0。
如前所述,9 位代表块偏移量:这是每个内存块地址的最小公共前缀。然后,2 位表示集合索引。地址为 0000000000000 时,SI 等于 00。因此,该存储块被复制到结合 0。
当函数从s[0][1]读取到s[0][7]时,数据已经在缓存中。CPU 是怎么知道的?CPU 计算存储块的起始地址,计算集合索引和标记位,然后检查集合 0 中是否存在 00。
接下来函数读取s[0][8],这个地址还没有被缓存。所以同样的操作发生在复制内存块 0100000000000(图 12.9)。

图 12.9 内存地址 010000000000 被复制到集合 0。
该存储器的集合索引等于 00,因此它也属于集合 0。高速缓存线被复制到组 0 中的下一个可用线。然后,再一次,从s[1][1]到s[1][7]的读取导致缓存命中。
现在事情越来越有趣了。该函数读取s[2][0],该地址不在缓存中。执行相同的操作(图 12.10)。

图 12.10 内存地址 1000000000000 替换集合 0 中的现有缓存行。
设置的索引再次等于 00。但是,set 0 已满 CPU 做什么?将内存块复制到另一组?不会。CPU 会替换现有缓存线之一来复制内存块 1000000000000。
缓存替换策略依赖于 CPU,但它通常是一个伪 LRU 策略(真正的 LRU(最久未使用)会太复杂而难以处理)。在这种情况下,假设它替换了我们的第一个缓存行:000000000000。当迭代第 3 行时,这种情况重复出现:内存地址 1100000000000 也有一个等于 00 的集合索引,导致替换现有的缓存行。
现在,让我们假设基准程序用一个从地址 000000000000 开始指向同一个矩阵的片来执行函数。当函数读取s[0][0]时,地址不在缓存中。该块已被替换。
基准测试将导致更多的缓存未命中,而不是从一次执行到另一次执行都使用 CPU 缓存。这种类型的缓存未命中被称为冲突未命中:如果缓存没有分区,这种未命中就不会发生。我们迭代的所有变量都属于一个集合索引为 00 的内存块。因此,我们只使用一个缓存集,而不是分布在整个缓存中。
之前我们讨论了跨越的概念,我们将其定义为 CPU 如何遍历我们的数据。在这个例子中,这个步距被称为临界步距:它导致访问具有相同组索引的存储器地址,这些地址因此被存储到相同的高速缓存组。
让我们回到现实世界的例子,用两个函数calculateSum512和calculateSum513。基准测试是在一个 32 KB 的八路组关联 L1D 缓存上执行的:总共 64 组。因为高速缓存行是 64 字节,所以关键步距等于64 × 64B = 4 KB。四 KB 的int64类型代表 512 个元素。因此,我们用 512 列的矩阵达到了一个临界步长,所以我们有一个差的缓存分布。同时,如果矩阵包含 513 列,它不会导致关键的一步。这就是为什么我们在两个基准测试中观察到如此巨大的差异。
总之,我们必须意识到现代缓存是分区的。根据步距的不同,在某些情况下只使用一组,这可能会损害应用性能并导致冲突未命中。这种跨步叫做临界跨步。对于性能密集型应用,我们应该避免关键步骤,以充分利用 CPU 缓存。
请注意,我们的示例还强调了为什么我们应该注意在生产系统之外的系统上执行微基准测试的结果。如果生产系统具有不同的缓存架构,性能可能会有很大不同。
让我们继续讨论 CPU 缓存的影响。这一次,我们在编写并发代码时看到了具体的效果。
12.2 #92:编写导致错误共享的并发代码
到目前为止,我们已经讨论了 CPU 缓存的基本概念。我们已经看到,一些特定的缓存(通常是 L1 和 L2)并不在所有逻辑内核之间共享,而是特定于一个物理内核。这种特殊性会产生一些具体的影响,比如并发性和错误共享的概念,这会导致性能显著下降。让我们通过一个例子来看看什么是虚假分享,然后看看如何防止它。
在这个例子中,我们使用了两个结构,Input和Result:
type Input struct {
a int64
b int64
}
type Result struct {
sumA int64
sumB int64
}
目标是实现一个count函数,该函数接收Input的一部分并计算以下内容:
-
所有
Input.a字段的总和变成Result.sumA -
所有
Input.b字段的总和变成Result.sumB
为了举例,我们实现了一个并发解决方案,其中一个 goroutine 计算sumA,另一个计算sumB:
func count(inputs []Input) Result {
wg := sync.WaitGroup{
}
wg.Add(2)
result := Result{
} // ❶
go func() {
for i := 0; i < len(inputs); i++ {
result.sumA += inputs[i].a // ❷
}
wg.Done()
}()
go func() {
for i := 0; i < len(inputs); i++ {
result.sumB += inputs[i].b // ❸
}
wg.Done()
}()
wg.Wait()
return result
}
❶ 初始化Result结构
❷ 计算sumA
❸ 计算sumB
我们旋转了两个 goroutines:一个迭代每个a字段,另一个迭代每个b字段。从并发的角度来看,这个例子很好。例如,它不会导致数据竞争,因为每个 goroutine 都会增加自己的数据
可变。但是这个例子说明了降低预期性能的错误共享概念。
让我们看看主内存(见图 12.11)。因为sumA和sumB是连续分配的,所以在大多数情况下(八分之七),两个变量都被分配到同一个内存块。

图 12.11 在这个例子中,sumA和sumB是同一个内存块的一部分。
现在,让我们假设机器包含两个内核。在大多数情况下,我们最终应该在不同的内核上调度两个线程。因此,如果 CPU 决定将这个内存块复制到一个缓存行,它将被复制两次(图 12.12)。

图 12.12 每个块都被复制到核心 0 和核心 1 上的缓存行。
因为 L1D (L1 数据)是针对每个内核的,所以两条缓存线都是复制的。回想一下,在我们的例子中,每个 goroutine 更新它自己的变量:一边是sumA,另一边是sumB(图 12.13)。

图 12.13 每个 goroutine 更新它自己的变量。
因为这些缓存行是复制的,所以 CPU 的目标之一是保证缓存一致性。例如,如果一个 goroutine 更新sumA而另一个读取sumA(在一些同步之后),我们期望我们的应用获得最新的值。
然而,我们的例子并没有做到这一点。两个 goroutines 都访问它们自己的变量,而不是共享的变量。我们可能希望 CPU 知道这一点,并理解这不是冲突,但事实并非如此。当我们写缓存中的变量时,CPU 跟踪的粒度不是变量:而是缓存行。
当一个缓存行在多个内核之间共享,并且至少有一个 goroutine 是写线程时,整个缓存行都会失效。即使更新在逻辑上是独立的,也会发生这种情况(例如,sumA和sumB)。这就是错误共享的问题,它降低了性能。
注意在内部,CPU 使用 MESI 协议来保证缓存一致性。它跟踪每个高速缓存行,标记它已修改、独占、共享或无效(MESI)。
关于内存和缓存,需要理解的最重要的一个方面是,跨内核共享内存是不真实的——这是一种错觉。这种理解来自于我们并不认为机器是黑匣子;相反,我们试图对潜在的层次产生机械的同情。
那么我们如何解决虚假分享呢?有两种主要的解决方案。
第一个解决方案是使用我们已经展示过的相同方法,但是确保sumA和sumB不属于同一个缓存行。例如,我们可以更新Result结构,在字段之间添加填充。填充是一种分配额外内存的技术。因为int64需要 8 字节的分配和 64 字节长的缓存行,所以我们需要64–8 = 56字节的填充:
type Result struct {
sumA int64
_ [56]byte // ❶
sumB int64
}
❶ 填充
图 12.14 显示了一种可能的内存分配。使用填充,sumA和sumB将总是不同存储块的一部分,因此是不同的高速缓存行。

图 12.14 sumA和sumB是不同内存块的一部分。
如果我们对两种解决方案进行基准测试(有和没有填充),我们会发现填充解决方案明显更快(在我的机器上大约快 40%)。这是一个重要的改进,因为在两个字段之间添加了填充以防止错误的共享。
第二个解决方案是重新设计算法的结构。例如,不是让两个 goroutines 共享同一个结构,我们可以让它们通过通道交流它们的本地结果。结果基准与填充大致相同。
总之,我们必须记住,跨 goroutines 共享内存是最低内存级别的一种错觉。当至少有一个 goroutine 是写线程时,如果缓存行在两个内核之间共享,则会发生假共享。如果我们需要优化一个依赖于并发的应用,我们应该检查假共享是否适用,因为这种模式会降低应用的性能。我们可以通过填充或通信来防止错误共享。
下一节讨论 CPU 如何并行执行指令,以及如何利用这种能力。
12.3 #93:不考虑指令级并行性
指令级并行是另一个可以显著影响性能的因素。在定义这个概念之前,我们先讨论一个具体的例子,以及如何优化。
我们将编写一个接收两个int64元素的数组的函数。这个函数将迭代一定次数(一个常数)。在每次迭代期间,它将执行以下操作:
-
递增数组的第一个元素。
-
如果第一个元素是偶数,则递增数组的第二个元素。
这是 Go 版本:
const n = 1_000_000
func add(s [2]int64) [2]int64 {
for i := 0; i < n; i++ {
// ❶
s[0]++ // ❷
if s[0]%2 == 0 {
// ❸
s[1]++
}
}
return s
}
❶ 迭代n次
❷ 递增s[0]
❸ 如果s[0]是偶数,递增s[1]
循环中执行的指令如图 12.15 所示(一个增量需要一个读操作和一个写操作)。指令的顺序是连续的:首先我们递增s[0];然后,在递增s[1]之前,我们需要再次读取s[0]。

图 12.15 三个主要步骤:增量、检查、增量
注意这个指令序列与汇编指令的粒度不匹配。但是为了清楚起见,我们使用一个简化的视图。
让我们花点时间来讨论指令级并行(ILP)背后的理论。几十年前,CPU 设计师不再仅仅关注时钟速度来提高 CPU 性能。他们开发了多种优化,包括 ILP,它允许开发人员并行执行一系列指令。在单个虚拟内核中实现 ILP 的处理器称为超标量处理器。例如,图 12.16 显示了一个 CPU 执行一个由三条指令组成的应用,I1、I2和I3。
*执行一系列指令需要不同的阶段。简而言之,CPU 需要解码指令并执行它们。执行由执行单元处理,执行单元执行各种操作和计算。

图 12.16 尽管是按顺序写的,但这三条指令是并行执行的。
在图 12.16 中,CPU 决定并行执行这三条指令。注意,并非所有指令都必须在单个时钟周期内完成。例如,读取已经存在于寄存器中的值的指令将在一个时钟周期内完成,但是读取必须从主存储器获取的地址的指令可能需要几十个时钟周期才能完成。
如果顺序执行,该指令序列将花费以下时间(函数t(x)表示 CPU 执行指令x所花费的时间):
total time = t(I1) + t(I2) + t(I3)
由于 ILP,总时间如下:
total time = max(t(I1), t(I2), t(I3))
理论上,ILP 看起来很神奇。但是这也带来了一些挑战叫做冒险。
举个例子,如果I3将一个变量设置为 42,而I2是条件指令(例如if foo == 1)怎么办?理论上,这个场景应该防止并行执行I2和I3。此称为 a 控制冒险或分支冒险。在实践中,CPU 设计者使用分支预测来解决控制冒险。
例如,CPU 可以计算出在过去的 100 次中有 99 次条件为真;因此,它将并行执行I2和I3。在错误预测(I2恰好为假)的情况下,CPU 将刷新其当前执行流水线,确保没有不一致。这种刷新会导致 10 到 20 个时钟周期的性能损失。
其他类型的冒险会阻止并行执行指令。作为软件工程师,我们应该意识到这一点。例如,让我们考虑下面两条更新寄存器(用于执行操作的临时存储区)的指令:
-
I1将寄存器 A 和 B 中的数字加到 C 中。 -
I2将寄存器 C 和 D 中的数字加到 D 中。
因为I2取决于关于寄存器 C 的值的I1的结果,所以两条指令不能同时执行。I1必须在I2前完成。这被称为一数据冒险。为了处理数据冒险,CPU 设计者想出了一个叫做转发的技巧,即基本上绕过了对寄存器的写入。这种技术不能解决问题,而是试图减轻影响。
请注意,当流水线中至少有两条指令需要相同的资源时,还有和结构冒险。作为 Go 开发人员,我们不能真正影响这些种类的冒险,所以我们不在本节讨论它们。
现在我们对 ILP 理论有了一个不错的理解,让我们回到我们最初的问题,把注意力集中在循环的内容上:
s[0]++
if s[0]%2 == 0 {
s[1]++
}
正如我们所讨论的,数据冒险会阻止指令同时执行。让我们看看图 12.17 中的指令序列;这次我们强调说明之间的冒险。

图 12.17 说明之间的冒险类型
由于的if语句,该序列包含一个控制冒险。然而,正如所讨论的,优化执行和预测应该采取什么分支是 CPU 的范围。还有多重数据危害。正如我们所讨论的,数据冒险阻止 ILP 并行执行指令。图 12.18 从 ILP 的角度显示了指令序列:唯一独立的指令是s[0]检查和s[1]增量,因此这两个指令集可以并行执行,这要归功于分支预测。

图 12.18 两个增量都是顺序执行的。
增量呢?我们能改进代码以减少数据冒险吗?
让我们编写另一个版本(add2)来引入一个临时变量:
func add(s [2]int64) [2]int64 {
// ❶
for i := 0; i < n; i++ {
s[0]++
if s[0]%2 == 0 {
s[1]++
}
}
return s
}
func add2(s [2]int64) [2]int64 {
// ❷
for i := 0; i < n; i++ {
v := s[0] // ❸
s[0] = v + 1
if v%2 != 0 {
s[1]++
}
}
return s
}
❶ 第一版
❷ 第二版
❸ 引入了一个新的变量来固定s[0]值
在这个新版本中,我们将s[0]的值固定为一个新变量v。之前我们增加了s[0],并检查它是否是偶数。为了复制这种行为,因为v是基于s[0],为了增加s[1],我们现在检查v是否是奇数。
图 12.19 比较了两个版本的危害。步骤的数量是相同的。最大的区别是关于数据冒险:s[0]增量步骤和检查v步骤现在依赖于相同的指令(read s[0] into v)。

图 12.19 一个显著的区别:检查步骤v的数据冒险
为什么这很重要?因为它允许 CPU 提高并行度(图 12.20)。

图 12.20 在第二个版本中,两个增量步骤可以并行执行。
尽管有相同数量的步骤,第二个版本增加了可以并行执行的步骤数量:三个并行路径而不是两个。同时,应该优化执行时间,因为最长路径已经减少。如果我们对这两个函数进行基准测试,我们会看到第二个版本的速度有了显著的提高(在我的机器上大约提高了 20%),这主要是因为 ILP。
让我们后退一步来结束这一节。我们讨论了现代 CPU 如何使用并行性来优化一组指令的执行时间。我们还研究了数据冒险,它会阻止并行执行指令。我们还优化了一个 Go 示例,减少了数据冒险的数量,从而增加了可以并行执行的指令数量。
理解 Go 如何将我们的代码编译成汇编,以及如何使用 ILP 等 CPU 优化是另一个改进的途径。在这里,引入一个临时变量可以显著提高性能。这个例子演示了机械共鸣如何帮助我们优化 Go 应用。
让我们也记住对这种微优化保持谨慎。因为 Go 编译器一直在发展,所以当 Go 版本发生变化时,应用生成的程序集也可能发生变化。
下一节讨论数据对齐的效果。
12.4 #94:不知道数据对齐
数据对齐是一种安排如何分配数据的方式,以加速 CPU 的内存访问。不了解这个概念会导致额外的内存消耗,甚至降低性能。本节讨论这个概念,它适用的地方,以及防止代码优化不足的技术。
为了理解数据对齐是如何工作的,让我们首先讨论一下没有它会发生什么。假设我们分配了两个变量,一个int32 (32 字节)和一个int64 (64 字节):
var i int32
var j int64
在没有数据对齐的情况下,在 64 位架构上,这两个变量的分配如图 12.21 所示。j变量分配可以用两个词来概括。如果 CPU 想要读取j,它将需要两次内存访问,而不是一次。

图 12.21 j两个字上的分配
为了避免这种情况,变量的内存地址应该是其自身大小的倍数。这就是数据对齐的概念。在 Go 中,对齐保证如下:
-
byte、uint8、int8: 1 字节 -
uint16,int16: 2 字节 -
uint32、int32、float32: 4 字节 -
uint64、int64、float64、complex64: 8 字节 -
complex128: 16 字节
所有这些类型都保证是对齐的:它们的地址是它们大小的倍数。例如,任何int32变量的地址都是 4 的倍数。
让我们回到现实世界。图 12.22 显示了i和j在内存中分配的两种不同情况。

图 12.22 在这两种情况下,j都与自己的尺寸对齐。
在第一种情况下,就在i之前分配了一个 32 位变量。因此,i和j被连续分配。第二种情况,32 位变量在i之前没有分配(例如,它是一个 64 位变量);所以,i是一个字的开头。考虑到数据对齐(地址是 64 的倍数),不能将j与i一起分配,而是分配给下一个 64 的倍数。灰色框表示 32 位填充。
接下来,让我们看看填充何时会成为问题。我们将考虑以下包含三个字段的结构:
type Foo struct {
b1 byte
i int64
b2 byte
}
我们有一个byte类型(1 字节),一个int64 (8 字节),还有另一个byte类型(1 字节)。在 64 位架构上,该结构被分配在内存中,如图 12.23 所示。b1先分配。因为i是一个int64,所以它的地址必须是 8 的倍数。所以不可能在 0x01 和b1一起分配。下一个是 8 的倍数的地址是什么?0x08。b2分配给下一个可用地址,该地址是 1: 0x10 的倍数。

图 12.23 该结构总共占用 24 个字节。
因为结构的大小必须是字长的倍数(8 字节),所以它的地址不是 17 字节,而是总共 24 字节。在编译期间,Go 编译器添加填充以保证数据对齐:
type Foo struct {
b1 byte
_ [7]byte // ❶
i int64
b2 byte
_ [7]byte // ❶
}
❶ 由编译器添加
每次创建一个Foo结构,它都需要 24 个字节的内存,但是只有 10 个字节包含数据——剩下的 14 个字节是填充。因为结构是一个原子单元,所以它永远不会被重组,即使在垃圾收集(GC)之后;它将总是占用 24 个字节的内存。请注意,编译器不会重新排列字段;它只添加填充以保证数据对齐。
如何减少分配的内存量?经验法则是重新组织结构,使其字段按类型大小降序排列。在我们的例子中,int64类型首先是,然后是两个byte类型:
type Foo struct {
i int64
b1 byte
b2 byte
}
图 12.24 显示了这个新版本的Foo是如何在内存中分配的。i先分配,占据一个完整的字。主要的区别是现在b1和b2可以在同一个单词中共存。
图 12.24 该结构现在占用了 16 个字节的内存。
同样,结构必须是字长的倍数;但是它只占用了 16 个字节,而不是 24 个字节。我们仅仅通过移动i到第一个位置就节省了 33%的内存。
如果我们使用第一个版本的Foo结构(24 字节)而不是压缩的,会有什么具体的影响?如果保留了Foo结构(例如,内存中的Foo缓存),我们的应用将消耗额外的内存。但是,即使没有保留Foo结构,也会有其他影响。例如,如果我们频繁地创建Foo变量并将它们分配给堆(我们将在下一节讨论这个概念),结果将是更频繁的 GC,影响整体应用性能。
说到性能,空间局部性还有另一个影响。例如,让我们考虑下面的sum函数,它将一部分Foo结构作为参数。该函数对切片进行迭代,并对所有的i字段(int64)求和:
func sum(foos []Foo) int64 {
var s int64
for i := 0; i < len(foos); i++ {
s += foos[i].i // ❶
}
return s
}
❶ 对所有i字段求和
因为一个片由一个数组支持,这意味着一个Foo结构的连续分配。
让我们讨论一下两个版本的Foo的后备数组,并检查两个缓存行的数据(128 字节)。在图 12.25 中,每个灰色条代表 8 个字节的数据,较暗的条是i变量(我们要求和的字段)。
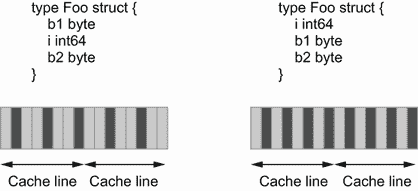
图 12.25 因为每个缓存行包含更多的i变量,迭代Foo的一个片需要更少的缓存行。
正如我们所见,在最新版本的Foo中,每条缓存线都更加有用,因为它平均包含 33%以上的i变量。因此,迭代一个Foo片来对所有的int64元素求和会更有效。
我们可以用一个基准来证实这一观察。如果我们使用 10,000 个元素的切片运行两个基准测试,使用最新的Foo结构的版本在我的机器上大约快 15%。与改变结构中单个字段的位置相比,速度提高了 15%。
让我们注意数据对齐。正如我们在本节中所看到的,重新组织 Go 结构的字段以按大小降序排列可以防止填充。防止填充意味着分配更紧凑的结构,这可能会导致优化,如减少 GC 的频率和更好的空间局部性。
下一节讨论栈和堆之间的根本区别以及它们为什么重要。
12.5 #95:不了解栈与堆
在 Go 中,一个变量既可以分配在栈上,也可以分配在堆上。这两种类型的内存有着根本的不同,会对数据密集型应用产生重大影响。让我们来看看这些概念和编译器在决定变量应该分配到哪里时所遵循的规则。
12.5.1 栈与堆
首先,让我们讨论一下栈和堆的区别。栈是默认内存;它是一种后进先出(LIFO)的数据结构,存储特定 goroutine 的所有局部变量。当一个 goroutine 启动时,它会获得 2 KB 的连续内存作为其栈空间(这个大小会随着时间的推移而变化,并且可能会再次改变)。但是,这个大小在运行时不是固定的,可以根据需要增加或减少(但是它在内存中始终保持连续,从而保持数据局部性)。
当 Go 进入一个函数时,会创建一个栈帧,表示内存中只有当前函数可以访问的区间。让我们看一个具体的例子来理解这个概念。这里,main函数将打印一个sumValue函数的结果:
func main() {
a := 3
b := 2
c := sumValue(a, b) // ❶
println(c) // ❷
}
//go:noinline // ❸
func sumValue(x, y int) int {
z := x + y
return z
}
❶ 调用sumValue函数
❷ 打印了结果
❸ 禁用内联
这里有两点需要注意。首先,我们使用println内置函数代替fmt.Println,这将强制在堆上分配c变量。其次,我们在sumValue函数上禁用内联;否则,函数调用不会发生(我们在错误#97“不依赖内联”中讨论了内联)。
图 12.26 显示了a和b分配后的栈。因为我们执行了main,所以为这个函数创建了一个栈框架。在这个栈帧中,两个变量a和b被分配给栈。所有存储的变量都是有效的地址,这意味着它们可以被引用和访问。

图 12.26 a和b分配在栈上。
图 12.27 显示了如果我们进入函数到语句会发生什么。Go 运行时创建一个新的栈框架,作为当前 goroutine 栈的一部分。x和y被分配在当前栈帧的z旁边。

图 12.27 调用sumValue创建一个新的栈框架。
前一个栈帧(main)包含仍被视为有效的地址。我们不能直接访问a和b;但是如果我们有一个指针在a上,例如,它将是有效的。我们不久将讨论指针。
让我们转到main函数的最后一条语句:println。我们退出了sumValue函数,那么它的栈框架会发生什么变化呢?参见图 12.28。

图 12.28 删除了sumValue栈框架,并用main中的变量代替。在本例中,x已被c擦除,而y和z仍在内存中分配,但无法访问。
栈帧没有完全从内存中删除。当一个函数返回时,Go 不需要花时间去释放变量来回收空闲空间。但是这些先前的变量不能再被访问,当来自父函数的新变量被分配到栈时,它们替换了先前的分配。从某种意义上说,栈是自清洁的;它不需要额外的机制,比如 GC。
现在,让我们做一点小小的改变来理解栈的局限性。该函数将返回一个指针,而不是返回一个int:
func main() {
a := 3
b := 2
c := sumPtr(a, b)
println(*c)
}
//go:noinline
func sumPtr(x, y int) *int {
// ❶
z := x + y
return &z
}
❶ 返回了一个指针
main中的c变量现在是一个*int类型。在调用sumPtr之后,让我们直接转到最后一个println语句。如果z在栈上保持分配状态会发生什么(这不可能)?参见图 12.29。

图 12.29c变量引用一个不再有效的地址。
如果c引用的是z变量的地址,而z是在栈上分配的,我们就会遇到一个大问题。该地址将不再有效,加上main的栈帧将继续增长并擦除z变量。出于这个原因,栈是不够的,我们需要另一种类型的内存:堆。
内存堆是由所有 goroutines 共享的内存池。在图 12.30 中,三个 goroutineG1、G2和G3都有自己的栈。它们都共享同一个堆。

图 12.30 三个 goroutines 有自己的栈,但共享堆
在前面的例子中,我们看到z变量不能在栈上生存;因此,是逃逸到堆里。如果在函数返回后,编译器不能证明变量没有被引用,那么该变量将被分配到堆中。
我们为什么要关心?理解栈和堆的区别有什么意义?因为这对性能有很大的影响。
正如我们所说的,栈是自清洁的,由一个单独的 goroutine 访问。相反,堆必须由外部系统清理:GC。分配的堆越多,我们给 GC 的压力就越大。当 GC 运行时,它使用 25%的可用 CPU 容量,并可能产生毫秒级的“停止世界”延迟(应用暂停的阶段)。
我们还必须理解,在栈上分配对于 Go 运行时来说更快,因为它很简单:一个指针引用下面的可用内存地址。相反,在堆上分配需要更多的努力来找到正确的位置,因此需要更多的时间。
为了说明这些差异,让我们对sumValue和sumPtr进行基准测试:
var globalValue int
var globalPtr *int
func BenchmarkSumValue(b *testing.B) {
b.ReportAllocs() // ❶
var local int
for i := 0; i < b.N; i++ {
local = sumValue(i, i) // ❷
}
globalValue = local
}
func BenchmarkSumPtr(b *testing.B) {
b.ReportAllocs() // ❸
var local *int
for i := 0; i < b.N; i++ {
local = sumPtr(i, i) // ❹
}
globalValue = *local
}
❶ 报告堆分配
❷ 按值求和
❸ 报告堆分配
❹ 用指针求和
如果我们运行这些基准测试(并且仍然禁用内联),我们会得到以下结果:
BenchmarkSumValue-4 992800992 1.261 ns/op 0 B/op 0 allocs/op
BenchmarkSumPtr-4 82829653 14.84 ns/op 8 B/op 1 allocs/op
sumPtr比sumValue大约慢一个数量级,这是用堆代替栈的直接后果。
注意这个例子表明使用指针来避免复制并不一定更快;这要看上下文。到目前为止,在本书中,我们只通过语义的棱镜讨论了值和指针:当值必须被共享时使用指针。在大多数情况下,这应该是遵循的规则。还要记住,现代 CPU 复制数据的效率非常高,尤其是在同一个缓存行中。让我们避免过早的优化,首先关注可读性和语义。
我们还应该注意,在之前的基准测试中,我们调用了b.ReportAllocs(),它强调了堆分配(栈分配不计算在内):
-
B/op:每次操作分配多少字节 -
allocs/op:每次操作分配多少
接下来,我们来讨论变量逃逸到堆的条件。
12.5.2 逃逸分析
冒险分析是指编译器执行的决定一个变量应该分配在栈上还是堆上的工作。让我们看看主要的规则。
当一个分配不能在栈上完成时,它在堆上完成。尽管这听起来像是一个简单的规则,但记住这一点很重要。例如,如果编译器不能证明函数返回后变量没有被引用,那么这个变量就被分配到堆上。在上一节中,sumPtr函数返回了一个指向在函数作用域中创建的变量的指针。一般来说,向上共享会将冒险到堆中。
但是相反的情况呢?如果我们接受一个指针,如下例所示,会怎么样?
func main() {
a := 3
b := 2
c := sum(&a, &b)
println(c)
}
//go:noinline
func sum(x, y *int) int {
// ❶
return *x + *y
}
❶ 接受指针
sum接受两个指针指向父级中创建的变量。如果我们移到sum函数中的return语句,图 12.31 显示了当前栈。

图 12.31x和y变量引用有效地址。
尽管是另一个栈帧的一部分,x和y变量引用有效地址。所以,a和b就不用逃了;它们可以留在栈中。一般来说,向下共享停留在栈上。
以下是变量可以冒险到堆的其他情况:
-
全局变量,因为多个 goroutines 可以访问它们。
-
发送到通道的指针:
type Foo struct{ s string } ch := make(chan *Foo, 1) foo := &Foo{ s: "x"} ch <- foo在这里,
foo逃到了垃圾堆里。 -
发送到通道的值所引用的变量:
type Foo struct{ s *string } ch := make(chan Foo, 1) s := "x" bar := Foo{ s: &s} ch <- bar因为
s通过它的地址被Foo引用,所以在这些情况下它会冒险到堆中。 -
如果局部变量太大,无法放入栈。
-
如果一个局部变量的大小未知。例如,
s:=make([]int,10)可能不会冒险到堆中,但s:=make([]int,n)会,因为它的大小是基于变量的。 -
如果使用
append重新分配切片的后备数组。
尽管这个列表为我们理解编译器的决定提供了思路,但它并不详尽,在未来的 Go 版本中可能会有所改变。为了确认一个假设,我们可以使用-gcflags来访问编译器的决定:
$ go build -gcflags "-m=2"
...
./main.go:12:2: z escapes to heap:
在这里,编译器通知我们z变量将逃逸到堆中。
理解堆和栈之间的根本区别对于优化 Go 应用至关重要。正如我们已经看到的,堆分配对于 Go 运行时来说更加复杂,需要一个带有 GC 的外部系统来释放数据。在一些数据密集型应用中,堆管理会占用高达 20%或 30%的总 CPU 时间。另一方面,栈是自清洁的,并且对于单个 goroutine 来说是本地的,这使得分配更快。因此,优化内存分配可以有很大的投资回报。
理解逸出分析的规则对于编写更高效的代码也是必不可少的。一般来说,向下共享停留在栈上,而向上共享则转移到堆上。这应该可以防止常见的错误,比如我们想要返回指针的过早优化,例如,“为了避免复制”让我们首先关注可读性和语义,然后根据需要优化分配。
下一节讨论如何减少分配。
12.6 不知道如何减少分配
减少分配是加速 Go 应用的常用优化技术。本书已经介绍了一些减少堆分配数量的方法:
-
优化不足的字符串连接(错误#39):使用
strings.Builder而不是+操作符来连接字符串。 -
无用的字符串转换(错误#40):尽可能避免将
[]byte转换成字符串。 -
切片和图初始化效率低(错误#21 和#27):如果长度已知,则预分配切片和图。
-
更好的数据结构对齐以减少结构大小(错误#94)。
作为本节的一部分,我们将讨论三种减少分配的常用方法:
-
改变我们的 API
-
依赖编译器优化
-
使用
sync.Pool等工具
12.6.1 API 的变化
第一个选择是在我们提供的 API 上认真工作。让我们举一个具体的例子io.Reader接口:
type Reader interface {
Read(p []byte) (n int, err error)
}
Read方法接受一个片并返回读取的字节数。现在,想象一下如果io.Reader接口被反过来设计:传递一个表示需要读取多少字节的int并返回一个片:
type Reader interface {
Read(n int) (p []byte, err error)
}
语义上,这没有错。但是在这种情况下,返回的片会自动逃逸到堆中。我们将处于上一节描述的共享情况。
Go 设计者使用向下共享的方法来防止自动将切片逃逸到堆中。因此,由调用者来提供切片。这并不一定意味着这个片不会被逃逸:编译器可能已经决定这个片不能留在栈上。然而,由调用者来处理它,而不是由调用的Read方法引起的约束。
有时,即使是 API 中的微小变化也会对分配产生积极的影响。当设计一个 API 时,让我们注意上一节描述的逃逸分析规则,如果需要,使用-gcflags来理解编译器的决定。
12.6.2 编译器优化
Go 编译器的目标之一就是尽可能优化我们的代码。这里有一个关于映射的具体例子。
在 Go 中,我们不能使用切片作为键类型来定义映射。在某些情况下,特别是在做 I/O 的应用中,我们可能会收到我们想用作关键字的[]byte数据。我们必须先将它转换成一个字符串,这样我们就可以编写下面的代码:
type cache struct {
m map[string]int // ❶
}
func (c *cache) get(bytes []byte) (v int, contains bool) {
key := string(bytes) // ❷
v, contains = c.m[key] // ❸
return
}
❶ 包含字符串的映射
❷ 将[]byte转换为字符串
❸ 使用字符串值查询映射
因为get函数接收一个[]byte切片,所以我们将其转换成一个key字符串来查询映射。
然而,如果我们使用string(bytes)查询映射,Go 编译器会实现一个特定的优化:
func (c *cache) get(bytes []byte) (v int, contains bool) {
v, contains = c.m[string(bytes)] // ❶
return
}
❶ 使用string(bytes)直接查询映射
尽管这是几乎相同的代码(我们直接调用string(bytes)而不是传递变量),编译器将避免进行这种字节到字符串的转换。因此,第二个版本比第一个快。
这个例子说明了看起来相似的函数的两个版本可能导致遵循 Go 编译器工作的不同汇编代码。我们还应该了解优化应用的可能的编译器优化。我们需要关注未来的 Go 版本,以检查是否有新的优化添加到语言中。
12.6.3 sync.Pool
如果我们想解决分配数量的问题,另一个改进的途径是使用sync.Pool。我们应该明白sync.Pool不是一个缓存:没有我们可以设置的固定大小或最大容量。相反,它是一个重用公共对象的池。
假设我们想要实现一个write函数,它接收一个io.Writer,调用一个函数来获取一个[]byte片,然后将它写入io.Writer。我们的代码如下所示(为了清楚起见,我们省略了错误处理):
func write(w io.Writer) {
b := getResponse() // ❶
_, _ = w.Write(b) // ❷
}
❶ 收到一个[]byte的响应
❷ 写入io.Writer
这里,getResponse在每次调用时返回一个新的[]byte片。如果我们想通过重用这个片来减少分配的次数呢?我们假设所有响应的最大大小为 1,024 字节。这种情况,我们可以用sync.Pool。
创建一个sync.Pool需要一个func() any工厂函数;参见图 12.32。sync.Pool暴露两种方法:
-
Get() any——从池中获取一个对象 -
Put(any)——将对象返回到池中

图 12.32 定义了一个工厂函数,它在每次调用时创建一个新对象。
如果池是空的,使用Get创建一个新对象,否则重用一个对象。然后,在使用该对象之后,我们可以使用Put将它放回池中。图 12.33 显示了先前定义的工厂的一个例子,当池为空时有一个Get,当池不为空时有一个Put和一个Get。

图 12.33 Get创建一个新对象或从池中返回一个对象。Put将对象返回到池中。
什么时候从水池中排出物体?没有特定的方法可以做到这一点:它依赖于 GC。每次 GC 之后,池中的对象都被销毁。
回到我们的例子,假设我们可以更新getResponse函数,将数据写入给定的片,而不是创建一个片,我们可以实现另一个版本的依赖于池的write方法:
var pool = sync.Pool{
New: func() any {
// ❶
return make([]byte, 1024)
},
}
func write(w io.Writer) {
buffer := pool.Get().([]byte) // ❷
buffer = buffer[:0] // ❸
defer pool.Put(buffer) // ❹
getResponse(buffer) // ❺
_, _ = w.Write(buffer)
}
❶ 创建了一个池并设置了工厂函数
❷ 从池中获取或创建[]byte
❸ 重置了缓冲区
❹ 把缓冲区放回池
❺ 将响应写入提供的缓冲区
我们使用sync.Pool结构定义一个新的池,并设置工厂函数来创建一个长度为 1024 个元素的新的[]byte。在write函数中,我们试图从池中检索一个缓冲区。如果池是空的,该函数创建一个新的缓冲区;否则,它从缓冲池中选择一个任意的缓冲区并返回它。关键的一步是使用buffer[:0]重置缓冲区,因为该片可能已经被使用。然后我们将调用Put将切片放回池中。
在这个新版本中,调用write不会导致为每个调用创建一个新的[]byte片。相反,我们可以重用现有的已分配片。在最坏的情况下——例如,在 GC 之后——该函数将创建一个新的缓冲区;但是,摊余分配成本会减少。
综上所述,如果我们频繁分配很多同类型的对象,可以考虑使用sync.Pool。它是一组临时对象,可以帮助我们避免重复重新分配同类数据。并且sync.Pool可供多个 goroutines 同时安全使用。
接下来,让我们讨论内联的概念,以了解这种计算机优化是值得了解的。
12.7 #97:不依赖内联
内联是指用函数体替换函数调用。现在,内联是由编译器自动完成的。理解内联的基本原理也是优化应用特定代码路径的一种方式。
让我们来看一个内联的具体例子,它使用一个简单的sum函数将两种int类型相加:
func main() {
a := 3
b := 2
s := sum(a, b)
println(s)
}
func sum(a int, b int) int {
// ❶
return a + b
}
❶ 内联了这个函数
如果我们使用-gcflags运行go build,我们将访问编译器对sum函数做出的决定:
$ go build -gcflags "-m=2"
./main.go:10:6: can inline sum with cost 4 as:
func(int, int) int {
return a + b }
...
./main.go:6:10: inlining call to sum func(int, int) int {
return a + b }
编译器决定将调用内联到sum。因此,前面的代码被替换为以下代码:
func main() {
a := 3
b := 2
s := a + b // ❶
println(s)
}
❶ 用它的正文代替了对sum的调用
内联只对具有一定复杂性的函数有效,也称为内联预算。否则,编译器会通知我们该函数太复杂,无法内联:
./main.go:10:6: cannot inline foo: function too complex:
cost 84 exceeds budget 80
内联有两个主要好处。首先,它消除了函数调用的开销(尽管自 Go 1.17 和基于寄存器的调用约定以来,开销已经有所减少)。其次,它允许编译器进行进一步的优化。例如,在内联一个函数后,编译器可以决定最初应该在堆上逃逸的变量可以留在栈上。
问题是,如果这种优化是由编译器自动应用的,那么作为 Go 开发者,我们为什么要关心它呢?答案在于中间栈内联的概念。
栈中内联是关于调用其他函数的内联函数。在 Go 1.9 之前,内联只考虑叶函数。现在,由于栈中内联,下面的foo函数也可以被内联:
func main() {
foo()
}
func foo() {
x := 1
bar(x)
}
因为foo函数不太复杂,编译器可以内联它的调用:
func main() {
x := 1 // ❶
bar(x)
}
❶ 用正文代替
多亏了中间栈内联,作为 Go 开发者,我们现在可以使用快速路径内联的概念来区分快速和慢速路径,从而优化应用。让我们看一个在sync.Mutex实现中发布的具体例子来理解这是如何工作的。
在中间栈内联之前,Lock方法的实现如下:
func (m *Mutex) Lock() {
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
// Mutex isn't locked
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
// Mutex is already locked
var waitStartTime int64
starving := false
awoke := false
iter := 0
old := m.state
for {
// ... // ❶
}
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
}
❶ 复杂逻辑
我们可以区分两条主要路径:
-
如果互斥没有被锁定(
atomic.CompareAndSwapInt32为真),快速路径 -
如果互斥体已经锁定(
atomic.CompareAndSwapInt32为假),慢速路径
然而,无论采用哪种方法,由于函数的复杂性,它都不能内联。为了使用中间栈内联,Lock方法被重构,因此慢速路径位于一个特定的函数中:
func (m *Mutex) Lock() {
if atomic.CompareAndSwapInt32(&m.state, 0, mutexLocked) {
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
return
}
m.lockSlow() // ❶
}
func (m *Mutex) lockSlow() {
var waitStartTime int64
starving := false
awoke := false
iter := 0
old := m.state
for {
// ...
}
if race.Enabled {
race.Acquire(unsafe.Pointer(m))
}
}
互斥体已经锁定的❶路径
由于这一改变,Lock方法可以被内联。好处是没有被锁定的互斥体现在被锁定了,而不需要支付调用函数的开销(速度提高了 5%左右)。当互斥体已经被锁定时,慢速路径不会改变。以前它需要一个函数调用来执行这个逻辑;它仍然是一个函数调用,这次是对lockSlow的调用。
这种优化技术是关于区分快速和慢速路径。如果快速路径可以内联,而慢速路径不能内联,我们可以在专用函数中提取慢速路径。因此,如果没有超出内联预算,我们的函数是内联的候选函数。
内联不仅仅是我们不应该关心的不可见的编译器优化。正如在本节中所看到的,理解内联是如何工作的以及如何访问编译器的决定是使用快速路径内联技术进行优化的一条途径。如果执行快速路径,在专用函数中提取慢速路径可以防止函数调用。
下一节将讨论常见的诊断工具,这些工具可以帮助我们理解在我们的 Go 应用中应该优化什么。
12.8 #98:不使用 Go 诊断工具
Go 提供了一些优秀的诊断工具,帮助我们深入了解应用的执行情况。这一节主要关注最重要的部分:概要分析和执行跟踪器。这两个工具都非常重要,应该成为任何对优化感兴趣的 Go 开发者的核心工具集的一部分。我们先讨论侧写。
12.8.1 概要分析
评测提供了对应用执行的深入了解。它允许我们解决性能问题、检测竞争、定位内存泄漏等等。这些见解可以通过以下几个方面收集:
-
CPU——决定应用的时间花在哪里 -
Goroutine——报告正在进行的 goroutines 的栈跟踪 -
Heap——报告堆内存分配,以监控当前内存使用情况并检查可能的内存泄漏 -
Mutex——报告锁争用,以查看我们代码中使用的互斥体的行为,以及应用是否在锁定调用上花费了太多时间 -
Block——显示 goroutines 阻塞等待同步原语的位置
剖析是通过使用一个叫做剖析器的工具来实现的。先来了解一下如何以及何时启用pprof;然后,我们讨论最重要的概要文件类型。
启用pprof
启用pprof有几种方法。例如,我们可以使用net/http/pprof包通过 HTTP:
package main
import (
"fmt"
"log"
"net/http"
_ "net/http/pprof" // ❶
)
func main() {
http.HandleFunc("/", func(w http.ResponseWriter, r *http.Request) {
// ❷
fmt.Fprintf(w, "")
})
log.Fatal(http.ListenAndServe(":80", nil))
}
❶ 空白导入pprof
❷ 公开了一个 HTTP 端点
导入net/http/pprof会导致一个副作用,即允许我们到达pprof URL,http://host/debug/pprof。注意启用pprof即使在生产中也是安全的(go.dev/doc/diagnostics#profiling)。影响性能的配置文件,如 CPU 配置文件,默认情况下不会启用,也不会连续运行:它们只在特定的时间段内激活。
既然我们已经看到了如何公开一个pprof端点,让我们讨论一下最常见的概要文件。
CPU 分析
CPU 性能分析器依赖于 OS 和信令。当它被激活时,默认情况下,应用通过SIGPROF信号要求操作系统每隔 10 ms 中断一次。当应用接收到一个SIGPROF时,它会挂起当前的活动,并将执行转移到分析器。分析器收集数据,例如当前的 goroutine 活动,并聚合我们可以检索的执行统计信息。然后停止,继续执行,直到下一个SIGPROF。
我们可以访问/debug/pprof/profile端点来激活 CPU 分析。默认情况下,访问此端点会执行 30 秒的 CPU 分析。在 30 秒内,我们的应用每 10 毫秒中断一次。注意,我们可以更改这两个默认值:我们可以使用seconds参数向端点传递分析应该持续多长时间(例如,/debug/pprof/profile?seconds=15),并且我们可以改变中断率(甚至到小于 10 ms)。但是在大多数情况下,10 ms 应该足够了,在减小这个值(意味着增加速率)时,我们应该小心不要损害性能。30 秒钟后,我们下载了 CPU 分析器的结果。
基准测试期间的 CPU 性能分析
我们还可以使用的-cpuprofile标志来启用 CPU 分析器,比如在运行基准测试时:
$ go test -bench=. -cpuprofile profile.out
该命令生成的文件类型与可以通过/debug/pprof/profile 下载的文件类型相同。
从这个文件中,我们可以使用go tool导航到结果:
$ go tool pprof -http=:8080 <file>
该命令打开一个显示调用图的 web UI。图 12.34 显示了一个来自应用的例子。箭头越大,说明这条路越热。然后,我们可以浏览该图表,获得执行洞察。

图 12.34 30 秒内应用的调用图
例如,图 12.35 中的图表告诉我们,在 30 秒内,decode方法(*FetchResponse接收器)花费了 0.06 秒。在这 0.06 秒中,RecordBatch.decode用了 0.02 秒,makemap(创建映射)用了 0.01 秒。

图 12.35 示例调用图
我们还可以通过不同的表示从 web 用户界面访问这类信息。例如,顶视图按执行时间对函数进行排序,而火焰图可视化了执行时间层次结构。UI 甚至可以逐行显示源代码中昂贵的部分。
注意,我们还可以通过命令行深入分析数据。然而,在这一节中,我们将重点放在 web UI 上。
借助这些数据,我们可以大致了解应用的行为方式:
-
太多对
runtime.mallogc的调用意味着过多的小堆分配,我们可以尽量减少。 -
花在通道操作或互斥锁上的时间太多,可能表明存在过多的争用,这会损害应用的性能。
-
在
syscall.Read或syscall.Write上花费太多时间意味着应用在内核模式下花费大量时间。致力于 I/O 缓冲可能是一条改进的途径。
这些是我们可以从 CPU 性能分析器中获得的洞察。理解最热门的代码路径并识别瓶颈是很有价值的。但是它不会确定超过配置的速率,因为 CPU 性能分析器是以固定的速度执行的(默认为 10 毫秒)。为了获得更细粒度的洞察力,我们应该使用跟踪,我们将在本章后面讨论。
注:我们还可以给不同的函数贴上标签。例如,想象一个从不同客户端调用的公共函数。为了跟踪两个客户端花费的时间,我们可以使用pprof.Labels。
堆分析
堆分析允许我们获得关于当前堆使用情况的统计数据。与 CPU 分析一样,堆分析也是基于样本的。我们可以改变这个速率,但是我们不应该太细,因为我们降低的速率越多,堆分析收集数据的工作量就越大。默认情况下,对于每 512 KB 的堆分配,对样本进行一次分析。
如果我们到达/debug/pprof/heap/但是,我们可以使用debug/pprof/heap/?debug=0,然后用go tool(与上一节相同的命令)打开它,使用 web UI 导航到数据。

图 12.36 堆积图
图 12.36 显示了一个堆图的例子。调用MetadataResponse .decode方法导致分配 1536 KB 的堆数据(占总堆的 6.32%)。然而,这 1536 KB 中有 0 个是由这个函数直接分配的,所以我们需要检查第二个调用。TopicMetadata.decode方法分配了 1536 KB 中的 512 KB 其余的 1024 KB 用另一种方法分配。
这就是我们如何浏览调用链,以了解应用的哪个部分负责大部分堆分配。我们还可以看看不同的样本类型:
-
alloc_objects——分配的对象总数 -
alloc_space——分配的内存总量 -
inuse_objects——已分配未释放的对象数量 -
inuse_space——已分配但尚未释放的内存量
堆分析的另一个非常有用的功能是跟踪内存泄漏。对于基于 GC 的语言,通常的过程如下:
-
触发 GC。
-
下载堆数据。
-
等待几秒钟/几分钟。
-
触发另一个 GC。
-
下载另一个堆数据。
-
比较。
在下载数据之前强制执行 GC 是防止错误假设的一种方法。例如,如果我们在没有首先运行 GC 的情况下看到保留对象的峰值,我们就不能确定这是一个泄漏还是下一个 GC 将收集的对象。
使用pprof,我们可以下载一个堆概要文件,同时强制执行 GC。Go 中的过程如下:
-
转到
/debug/pprof/heap?gc=1(触发 GC 并下载堆配置文件)。 -
等待几秒钟/几分钟。
-
再次转到
/debug/pprof/heap?gc=1。 -
使用
go tool比较两个堆配置文件:
$ go tool pprof -http=:8080 -diff_base <file2> <file1>
图 12.37 显示了我们可以访问的数据类型。例如,newTopicProducer方法(左上)持有的堆内存量已经减少了(–513 KB)。相比之下,updateMetadata(右下角)持有的数量增加了(+512 KB)。缓慢增加是正常的。例如,第二个堆配置文件可能是在服务调用过程中计算出来的。我们可以重复这个过程或等待更长时间;重要的部分是跟踪特定对象分配的稳定增长。

图 12.37 两种堆配置文件的区别
注意,与堆相关的另一种类型的分析是allocs,它报告分配情况。堆分析显示了堆内存的当前状态。为了深入了解应用启动以来的内存分配情况,我们可以使用分配分析。如前所述,因为栈分配的成本很低,所以它们不是这种分析的一部分,这种分析只关注堆。
Goroutines 剖析
goroutine配置文件报告应用中所有当前 goroutines 的栈跟踪。我们可以用debug/pprof/goroutine/?debug=0,再次使用go tool。图 12.38 显示了我们能得到的信息种类。

图 12.38 Goroutine 图
我们可以看到应用的当前状态以及每个函数创建了多少个 goroutines。在这种情况下,withRecover创建了 296 个正在进行的 goroutine(63%),其中 29 个与对responseFeeder的调用相关。
如果我们怀疑 goroutine 泄密,这种信息也是有益的。我们可以查看 goroutine 性能分析器数据,了解系统的哪个部分是可疑的。
块剖析
block配置文件报告正在进行的 goroutines 阻塞等待同步原语的位置。可能性包括
-
在无缓冲通道上发送或接收
-
发送到完整通道
-
从空通道接收
-
互斥竞争
-
网络或文件系统等待
块分析还记录了一个 goroutine 等待的时间,可以通过debug/pprof/block访问。如果我们怀疑阻塞调用损害了性能,这个配置文件会非常有用。
默认情况下,block配置文件是不启用的:我们必须调用runtime.SetBlockProfileRate来启用它。此函数控制报告的 goroutine 阻塞事件的比例。一旦启用,分析器将继续在后台收集数据,即使我们不调用debug/pprof/block端点。如果我们想设置一个较高的比率,我们就要谨慎,以免影响性能。
完整的 goroutine 栈转储
如果我们面临死锁或者怀疑 goroutine 处于阻塞状态,那么完整的 goroutine 栈转储(debug/pprof/goroutine/?debug=2)创建所有当前 goroutine 栈跟踪的转储。作为第一个分析步骤,这可能很有帮助。例如,以下转储显示 Sarama goroutine 在通道接收操作中被阻塞了 1,420 分钟:
goroutine 2494290 [chan receive, 1420 minutes]:
github.com/Shopify/sarama.(*syncProducer).SendMessages(0xc00071a090,
➥{
0xc0009bb800, 0xfb, 0xfb})
/app/vendor/github.com/Shopify/sarama/sync_producer.go:117 +0x149
互斥剖析
最后一种配置文件类型与阻塞有关,但仅与互斥有关。如果我们怀疑我们的应用花费大量时间等待锁定互斥体,从而损害执行,我们可以使用互斥体分析。可以通过/debug/pprof/mutex 访问它。
该配置文件的工作方式类似于阻塞。默认情况下它是禁用的:我们必须使用runtime.SetMutexProfileFraction来启用它,它控制所报告的互斥争用事件的比例。
以下是关于概要分析的一些附加说明:
-
我们没有提到
threadcreate剖面,因为从 2013 年开始就坏了(github.com/golang/go/issues/6104)。 -
确保一次只启用一个分析器:例如,不要同时启用 CPU 和堆分析。这样做会导致错误的观察。
-
pprof是可扩展的,我们可以使用pprof.Profile创建自己的自定义概要文件。
我们已经看到了最重要的配置文件,它们可以帮助我们了解应用的性能以及可能的优化途径。一般来说,建议启用pprof,即使是在生产环境中,因为在大多数情况下,它在它的占用空间和我们可以从中获得的洞察力之间提供了一个极好的平衡。一些配置文件,比如 CPU 配置文件,会导致性能下降,但只在它们被启用的时候。
现在让我们看看执行跟踪器。
12.8.2 执行跟踪器
执行跟踪器是一个工具,它用go tool捕捉广泛的运行时事件,使它们可用于可视化。这有助于:
-
了解运行时事件,例如 GC 如何执行
-
了解 goroutines 如何执行
-
识别并行性差的执行
让我们用错误#56 中给出的一个例子来试试,“思考并发总是更快。”我们讨论了归并排序算法的两个并行版本。第一个版本的问题是并行性差,导致创建了太多的 goroutines。让我们看看跟踪器如何帮助我们验证这一陈述。
我们将为第一个版本编写一个基准,并使用-trace标志来执行它,以启用执行跟踪器:
$ go test -bench=. -v -trace=trace.out
注意我们还可以使用/debug/pprof/trace?debug=0的pprof端点下载远程跟踪文件。 。
这个命令创建一个trace.out文件,我们可以使用go tool打开它:
$ go tool trace trace.out
2021/11/26 21:36:03 Parsing trace...
2021/11/26 21:36:31 Splitting trace...
2021/11/26 21:37:00 Opening browser. Trace viewer is listening on
http://127.0.0.1:54518
web 浏览器打开,我们可以单击 View Trace 查看特定时间段内的所有跟踪,如图 12.39 所示。这个数字代表大约 150 毫秒,我们可以看到多个有用的指标,比如 goroutine 计数和堆大小。堆大小稳定增长,直到触发 GC。我们还可以观察每个 CPU 内核的 Go 应用的活动。时间范围从用户级代码开始;然后执行“停止世界”,占用四个 CPU 内核大约 40 毫秒。

图 12.39 显示了 goroutine 活动和运行时事件,如 GC 阶段
关于并发,我们可以看到这个版本使用了机器上所有可用的 CPU 内核。然而,图 12.40 放大了 1 毫秒的一部分,每个条形对应于一次 goroutine 执行。拥有太多的小竖条看起来不太好:这意味着执行的并行性很差。

图 12.40 太多的小横条意味着并行执行效果不佳。
图 12.41 放大到更近,以查看这些 goroutines 是如何编排的。大约 50%的 CPU 时间没有用于执行应用代码。空白表示 Go 运行时启动和编排新的 goroutines 所需的时间。

图 12.41 大约 50%的 CPU 时间用于处理 goroutine 开关。
让我们将其与第二种并行实现进行比较,后者大约快一个数量级。图 12.42 再次放大到 1 毫秒的时间范围。

图 12.42 空格数量明显减少,证明 CPU 被更充分的占用。
每个 goroutine 都需要更多的时间来执行,并且空格的数量已经显著减少。因此,与第一个版本相比,CPU 执行应用代码的时间要多得多。每一毫秒的 CPU 时间都得到了更有效的利用,这解释了基准测试的差异。
请注意,跟踪的粒度是每个例程,而不是像 CPU 分析那样的每个函数。然而,可以使用包来定义用户级任务,以获得每个函数或函数组的洞察力。
例如,假设一个函数计算一个斐波那契数,然后使用atomic将其写入一个全局变量。我们可以定义两种不同的任务:
var v int64
ctx, fibTask := trace.NewTask(context.Background(), "fibonacci") // ❶
trace.WithRegion(ctx, "main", func() {
v = fibonacci(10)
})
fibTask.End()
ctx, fibStore := trace.NewTask(ctx, "store") // ❷
trace.WithRegion(ctx, "main", func() {
atomic.StoreInt64(&result, v)
})
fibStore.End()
❶ 创建了一个斐波那契任务
❷ 创建一个存储任务
使用go tool,我们可以获得关于这两个任务如何执行的更精确的信息。在前面的 trace UI 中(图 12.42),我们可以看到每个 goroutine 中每个任务的边界。在用户定义的任务中,我们可以遵循持续时间分布(见图 12.43)。

图 12.43 用户级任务的分布
我们看到,在大多数情况下,fibonacci任务的执行时间不到 15 微秒,而store任务的执行时间不到 6309 纳秒。
在上一节中,我们讨论了我们可以从 CPU 概要分析中获得的各种信息。与我们可以从用户级跟踪中获得的数据相比,主要的区别是什么?
-
CPU 性能分析:
- 以样本为基础。
- 每个函数。
- 不会低于速率(默认为 10 毫秒)。
-
用户级跟踪:
- 不基于样本。
- 逐例程执行(除非我们使用
runtime/trace包)。 - 时间执行不受任何速率的约束。
总之,执行跟踪器是理解应用如何执行的强大工具。正如我们在归并排序示例中看到的,我们可以识别出并行性差的执行。然而,跟踪器的粒度仍然是每一个例程,除非我们手动使用runtime/trace与 CPU 配置文件进行比较。在优化应用时,我们可以同时使用概要分析和执行跟踪器来充分利用标准的 Go 诊断工具。
下一节讨论 GC 如何工作以及如何调优。
12.9 #99:不了解 GC 如何工作
垃圾收集器(GC)是简化开发人员生活的 Go 语言的关键部分。它允许我们跟踪和释放不再需要的堆分配。因为我们不能用栈分配来代替每个堆分配,所以理解 GC 如何工作应该是 Go 开发人员优化应用的工具集的一部分。
12.9.1 概念
GC 保存了一个对象引用树。Go GC 基于标记-清除算法,该算法依赖于两个阶段:
-
标记阶段——遍历堆中的所有对象,并标记它们是否仍在使用
-
清除阶段——从根开始遍历引用树,并释放不再被引用的对象块
当 GC 运行时,它首先执行一组动作,导致停止世界(准确地说,每个 GC 两次停止世界)。也就是说,所有可用的 CPU 时间都用于执行 GC,从而暂停了我们的应用代码。按照这些步骤,它再次启动这个世界,恢复我们的应用,同时运行一个并发阶段。出于这个原因,Go GC 被称为并发标记和清除:它的目标是减少每个 GC 周期的停止世界操作的数量,并且主要与我们的应用并发运行。
清理器
Go GC 还包括一种在消耗高峰后释放内存的方法。假设我们的应用基于两个阶段:
-
导致频繁分配和大量堆的初始化阶段
-
具有适度分配和小堆的运行时阶段
如何处理大堆只在应用启动时有用,而在那之后没有用的事实呢?这是作为 GC 的一部分使用所谓的定期清理器来处理的。一段时间后,GC 检测到不再需要这么大的堆,所以它释放一些内存并将其返回给操作系统。
注意如果清理器不够快,我们可以使用debug.FreeOSMemory()手动强制将内存返回给操作系统。
重要的问题是,GC 周期什么时候运行?与 Java 等其他语言相比,Go 配置仍然相当简单。它依赖于单个环境变量:GOGC。该变量定义了在触发另一个 GC 之前,自上次 GC 以来堆增长的百分比;默认值为 100%。
让我们看一个具体的例子,以确保我们理解。让我们假设刚刚触发了一个 GC,当前的堆大小是 128 MB。如果GOGC=100,当堆大小达到 256 MB 时,触发下一次垃圾收集。默认情况下,每当堆大小加倍时,就会执行一次 GC。此外,如果在最后 2 分钟内没有执行 GC,Go 将强制运行一个 GC。
如果我们用生产负载分析我们的应用,我们可以微调GOGC:
-
减少它会导致堆增长更慢,增加 GC 的压力。
-
相反,碰撞它会导致堆增长得更快,从而减轻 GC 的压力。
GC 痕迹
我们可以通过设置GODEBUG环境变量来打印 GC 轨迹,比如在运行基准测试时:
$ GODEBUG=gctrace=1 go test -bench=. -v
启用gctrace会在每次 GC 运行时向stderr写入跟踪。
让我们通过一些具体的例子来理解 GC 在负载增加时的行为。
12.9.2 示例
假设我们向用户公开一些公共服务。在中午 12:00 的高峰时段,有 100 万用户连接。然而,联网用户在稳步增长。图 12.44 表示平均堆大小,以及当我们将GOGC设置为100时何时触发 GC。

图 12.44 联网用户的稳步增长
因为GOGC被设置为100,所以每当堆大小加倍时,GC 都会被触发。在这种情况下,由于用户数量稳步增长,我们应该全天面对可接受数量的 GC(图 12.45)。

图 12.45 GC 频率从未达到大于中等的状态。
在一天开始的时候,我们应该有适度数量的 GC 周期。当我们到达中午 12:00 时,当用户数量开始减少时,GC 周期的数量也应该稳步减少。在这种情况下,保持GOGC到100应该没问题。
现在,让我们考虑第二个场景,100 万用户中的大多数在不到一个小时内连接;参见图 12.46。上午 8:00,平均堆大小迅速增长,大约一小时后达到峰值。

图 12.46 用户突然增加
在这一小时内,GC 周期的频率受到严重影响,如图 12.47 所示。由于堆的显著和突然的增加,我们在短时间内面临频繁的 GC 循环。即使 Go GC 是并发的,这种情况也会导致大量的停顿期,并会造成一些影响,例如增加用户看到的平均延迟。

图 12.47 在一个小时内,我们观察到高频率的 GCs。
在这种情况下,我们应该考虑将GOGC提高到一个更高的值,以减轻 GC 的压力。注意,增加GOGC并不会带来线性的好处:堆越大,清理的时间就越长。因此,使用生产负载时,我们在配置GOGC时应该小心。
在颠簸更加严重的特殊情况下,调整GOGC可能还不够。例如,我们不是在一个小时内从 0 到 100 万用户,而是在几秒钟内完成。在这几秒钟内,GC 的数量可能会达到临界状态,导致应用的性能非常差。
如果我们知道堆的峰值,我们可以使用一个技巧,强制分配大量内存来提高堆的稳定性。例如,我们可以在main.go中使用一个全局变量强制分配 1 GB:
var min = make([]byte, 1_000_000_000) // 1 GB
这样的分配有什么意义?如果GOGC保持在100,而不是每次堆翻倍时触发一次 GC(同样,这在这几秒钟内发生得非常频繁),那么 Go 只会在堆达到 2 GB 时触发一次 GC。这应该会减少所有用户连接时触发的 GC 周期数,从而减少对平均延迟的影响。
我们可以说,当堆大小减小时,这个技巧会浪费大量内存。但事实并非如此。在大多数操作系统上,分配这个min变量不会让我们的应用消耗 1 GB 的内存。调用make会导致对mmap()的系统调用,从而导致惰性分配。例如,在 Linux 上,内存是通过页表虚拟寻址和映射的。使用mmap()在虚拟地址空间分配 1 GB 内存,而不是物理空间。只有读取或写入会导致页面错误,从而导致实际的物理内存分配。因此,即使应用在没有任何连接的客户端的情况下启动,它也不会消耗 1 GB 的物理内存。
注意,我们可以使用ps这样的工具来验证这种行为。
为了优化 GC,理解它的行为是很重要的。作为 Go 开发者,我们可以使用GOGC来配置何时触发下一个 GC 周期。大多数情况下,保持在100应该就够了。但是,如果我们的应用可能面临导致频繁 GC 和延迟影响的请求高峰,我们可以增加这个值。最后,在出现异常请求高峰时,我们可以考虑使用将虚拟堆大小保持在最小的技巧。
本章最后一节讨论了在 Docker 和 Kubernetes 中运行 Go 的影响。
12.10 #100:不了解在 Docker 和 Kubernetes 中运行GO的影响
根据 2021 年 Go 开发者调查(go.dev/blog/survey2021-results),用 Go 编写服务是最常见的用法。同时,Kubernetes 是部署这些服务最广泛使用的平台。理解在 Docker 和 Kubernetes 中运行 Go 的含义是很重要的,这样可以防止常见的情况,比如 CPU 节流。
我们在错误#56“思考并发总是更快”中提到,GOMAXPROCS变量定义了负责同时执行用户级代码的操作系统线程的限制。默认情况下,它被设置为操作系统可见的逻辑 CPU 内核的数量。这在 Docker 和 Kubernetes 的上下文中意味着什么?
假设我们的 Kubernetes 集群由八核节点组成。当在 Kubernetes 中部署一个容器时,我们可以定义一个 CPU 限制来确保应用不会消耗所有的主机资源。例如,以下配置将 cpu 的使用限制为 4,000 个毫 CPU(或毫核心),因此有四个 CPU 核心:
spec:
containers:
- name: myapp
image: myapp
resources:
limits:
cpu: 4000m
我们可以假设,当部署我们的应用时,GOMAXPROCS将基于这些限制,因此将具有值4。但事实并非如此;它被设置为主机上逻辑核心的数量:8。那么,有什么影响呢?
Kubernetes 使用完全公平调度器(CFS)作为进程调度器。CFS 还用于强制执行 Pod 资源的 CPU 限制。在管理 Kubernetes 集群时,管理员可以配置这两个参数:
-
cpu.cfs_period_us(全局设置) -
cpu.cfs_quota_us(设定每 Pod)
前者规定了一个期限,后者规定了一个配额。默认情况下,周期设置为 100 毫秒。同时,默认配额值是应用在 100 毫秒内可以消耗的 CPU 时间。限制设置为四个内核,这意味着 400 毫秒(4 × 100毫秒)。因此,CFS 将确保我们的应用在 100 毫秒内不会消耗超过 400 毫秒的 CPU 时间。
让我们想象一个场景,其中多个 goroutines 当前正在四个不同的线程上执行。每个线程被调度到不同的内核(1、3、4 和 8);参见图 12.48。

图 12.48 每 100 毫秒,应用消耗的时间不到 400 毫秒
在第一个 100 毫秒期间,有四个线程处于忙碌状态,因此我们消耗了 400 毫秒中的 400 毫秒:100%的配额。在第二阶段,我们消耗 400 毫秒中的 360 毫秒,以此类推。一切都很好,因为应用消耗的资源少于配额。
但是,我们要记住GOMAXPROCS是设置为8的。因此,在最坏的情况下,我们可以有八个线程,每个线程被安排在不同的内核上(图 12.49)。
图 12.49 在每 100 毫秒期间,CPU 在 50 毫秒后被节流。
每隔 100 毫秒,配额设置为 400 毫秒,如果 8 个线程忙于执行 goroutines,50 毫秒后,我们达到 400 毫秒的配额(8 × 50 毫秒 = 400 毫秒)。会有什么后果?CFS 将限制 CPU 资源。因此,在下一个周期开始之前,不会再分配 CPU 资源。换句话说,我们的应用将被搁置 50 毫秒。
例如,平均延迟为 50 毫秒的服务可能需要 150 毫秒才能完成。这可能会对延迟造成 300%的损失。
那么,有什么解决办法呢?先关注 Go 第 33803 期(github.com/golang/go/issues/33803)。也许在 Go 的未来版本中,GOMAXPROCS将会支持 CFS。
今天的一个解决方案是依靠由github.com/uber-go/automaxprocs制作的名为automaxprocs的库。我们可以通过向main.go中的go.uber.org/automaxprocs添加一个空白导入来使用这个库;它会自动设置GOMAXPROCS来匹配 Linux 容器的 CPU 配额。在前面的例子中,GOMAXPROCS将被设置为4而不是8,因此我们将无法达到 CPU 被抑制的状态。
总之,让我们记住,目前,Go 并不支持 CFS。GOMAXPROCS基于主机,而不是基于定义的 CPU 限制。因此,我们可能会达到 CPU 被抑制的状态,从而导致长时间的暂停和重大影响,例如显著的延迟增加。在 Go 能够感知 CFS 之前,一种解决方案是依靠automaxprocs自动将GOMAXPROCS设置为定义的配额。
总结
-
了解如何使用 CPU 缓存对于优化 CPU 密集型应用非常重要,因为 L1 缓存比主内存快 50 到 100 倍。
-
了解缓存线概念对于理解如何在数据密集型应用中组织数据至关重要。CPU 不会一个字一个字地获取内存;相反,它通常将内存块复制到 64 字节的缓存行。要充分利用每个单独的缓存行,请实现空间局部性。
-
使代码对 CPU 可预测也是优化某些函数的有效方法。例如,CPU 的单位步幅或常量步幅是可预测的,但是非单位步幅(例如,一个链表)是不可预测的。
-
为了避免关键的一步,因此只利用缓存的一小部分,请注意缓存是分区的。
-
知道较低级别的 CPU 缓存不会在所有内核之间共享有助于避免性能下降的模式,例如在编写并发代码时的错误共享。分享内存是一种错觉。
-
使用指令级并行(ILP)来优化代码的特定部分,以允许 CPU 执行尽可能多的并行指令。识别数据冒险是主要步骤之一。
-
记住在GO中,基本类型是根据它们自己的大小排列的,这样可以避免常见的错误。例如,请记住,按大小降序重新组织结构的字段可以产生更紧凑的结构(更少的内存分配和潜在的更好的空间局部性)。
-
在优化 Go 应用时,理解堆和栈之间的根本区别也应该是您核心知识的一部分。栈分配几乎是免费的,而堆分配速度较慢,并且依赖 GC 来清理内存。
-
减少分配也是优化 Go 应用的一个重要方面。这可以通过不同的方式来实现,比如仔细设计 API 以防止共享,理解常见的 Go 编译器优化,以及使用
sync.Pool。 -
使用快速路径内联技术有效减少调用函数的分摊时间。
-
依靠分析和执行跟踪器来了解应用的执行情况以及需要优化的部分。
-
了解如何调优 GC 可以带来多种好处,比如更有效地处理突然增加的负载。
-
为了帮助避免部署在 Docker 和 Kubernetes 中时的 CPU 节流,请记住 Go 不支持 CFS。
最后的话
恭喜你完成了《100 个 Go 错误以及如何避免它们》。我真诚地希望你喜欢读这本书,它将对你的个人和/或专业项目有所帮助。
记住,犯错是学习过程的一部分,正如我在序言中强调的,它也是本书灵感的重要来源。归根结底,重要的是我们从中学习的能力。
如果你想继续讨论,可以在推特上关注我:@teivah。***