如果对代码使用有困难的小伙伴可以直接使用WebUI版的LoRA模块进行训练操作。不管是训练人物,场景,风格,还是服装都是一套通用的模式,仅仅是使用不同的数据集得到的结果不同。
文章目录
lora-scripts WebUI的安装
使用 git clone --recurse-submodules https://github.com/Akegarasu/lora-scripts 进行源文件的下载,这个可以在你SD的拓展目录中进行。代码是基于 https://github.com/kohya-ss/sd-scripts 衍生出来的。
如果安装过程中出现Failed to clone 'sd-scripts' a second time, aborting的话需要手动执行git clone --recurse-submodules https://github.com/kohya-ss/sd-scripts.git安装。
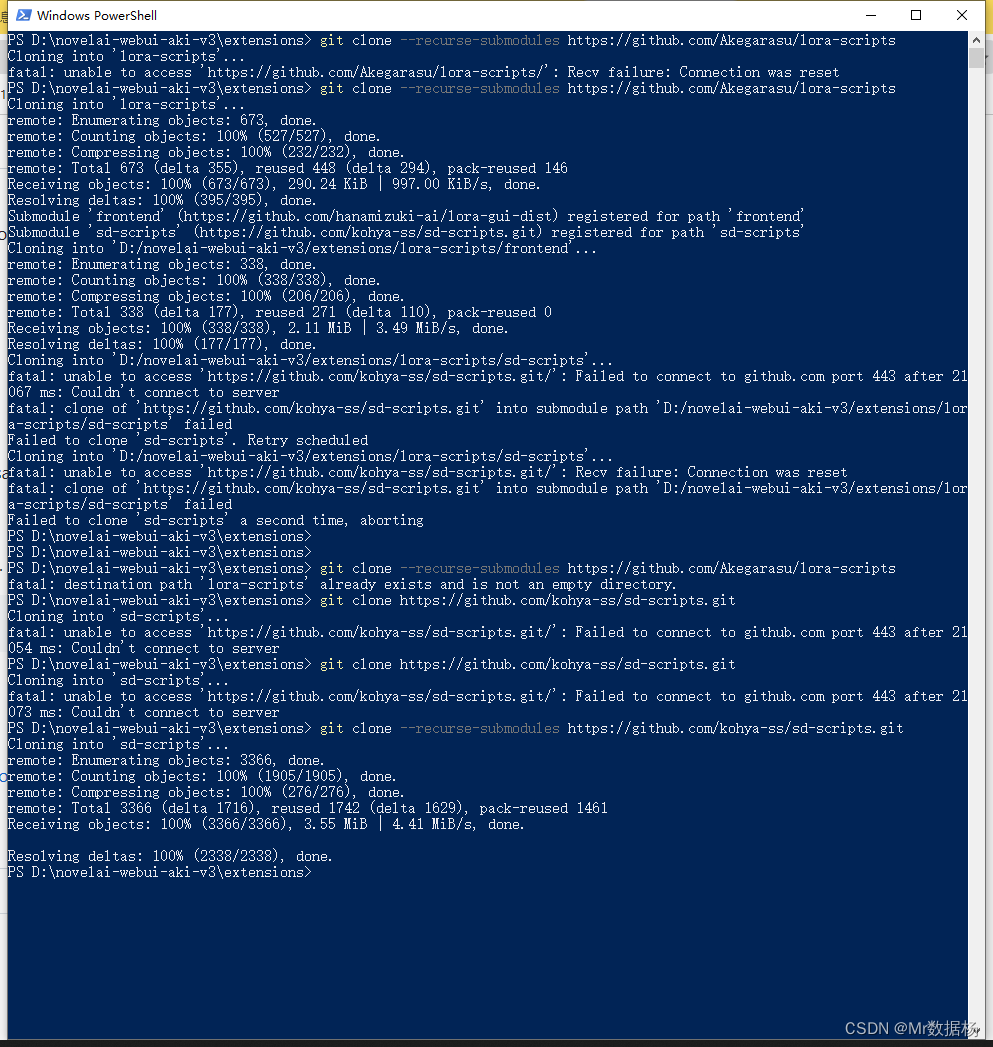
如果网络不好请多试几次,脚本克隆完成后是这样的。
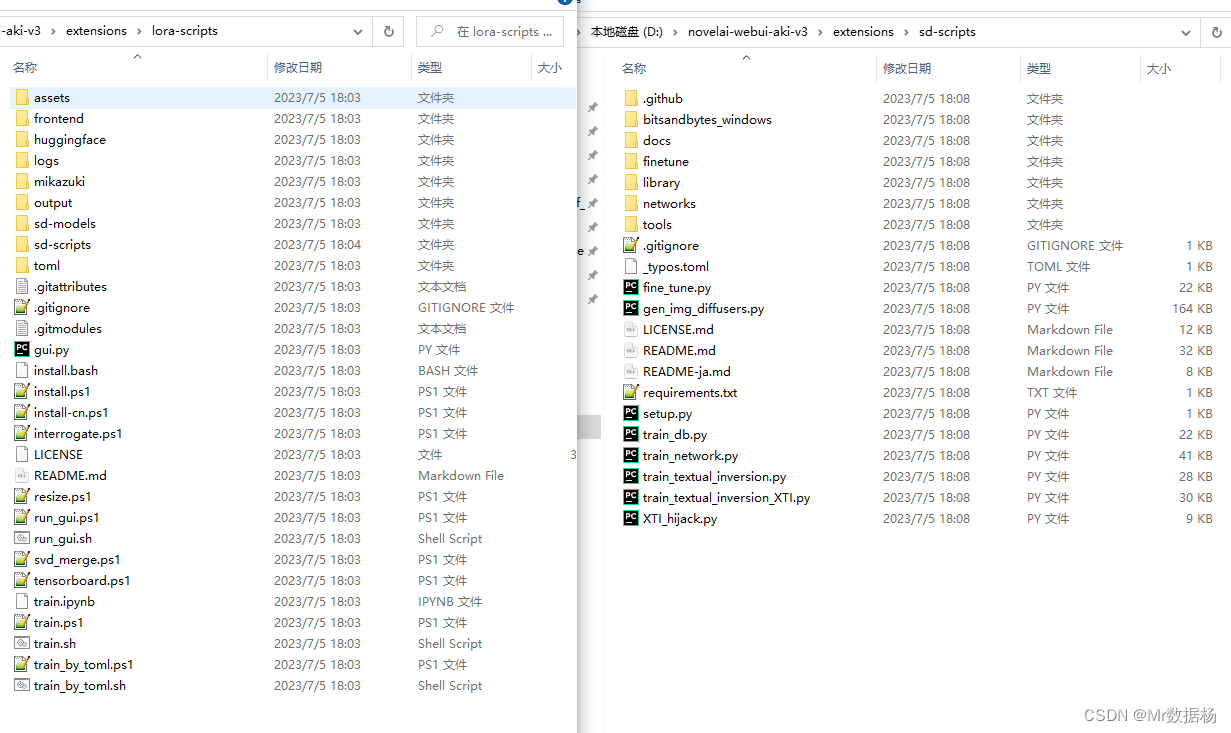
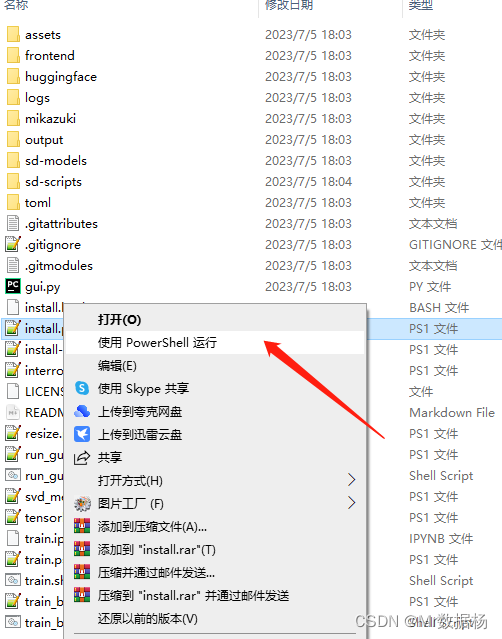
执行lora-scripts中的install.ps1进行开发环境的安装和配置。鼠标右键点击然后选择power shell执行即可。
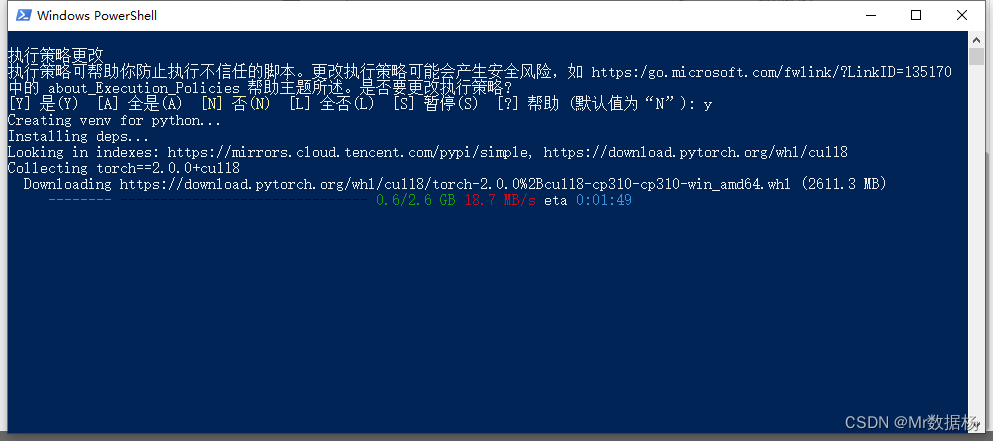
选择Y一路默认安装即可,这是在创建虚拟环境和进行配置cuda。
当显示Install completed的时候证明安装成功,窗口会自动关闭。
在当前目录下执行git clone --recurse-submodules https://github.com/kohya-ss/sd-scripts.git安装sd-scripts。或者将之前下载好的sd-scripts拖进来也行。
执行run_gui.ps1打开即可进入WebUI界面。如果出现窗口闪退的情况证明刚才安装没有完整,需要重新执行install-cn.ps1补全三方依赖包。
显示安装完毕即可。执行run_gui.ps1会在浏览器中弹出网址http://127.0.0.1:28000/lora/basic.html出现该页面。
LoRA训练过程
这里以《真·三国无双8》中吴国的人物立绘作为训练素材。
SD切分素材
打开SD点击图像预处理模块,输入图片防止文件夹的目录,记得这个路径中不要有中文。按照下图设置好,分别率自行设置一定要是64的倍数并且在512-1024之间。
切记关键词部分要二选一。
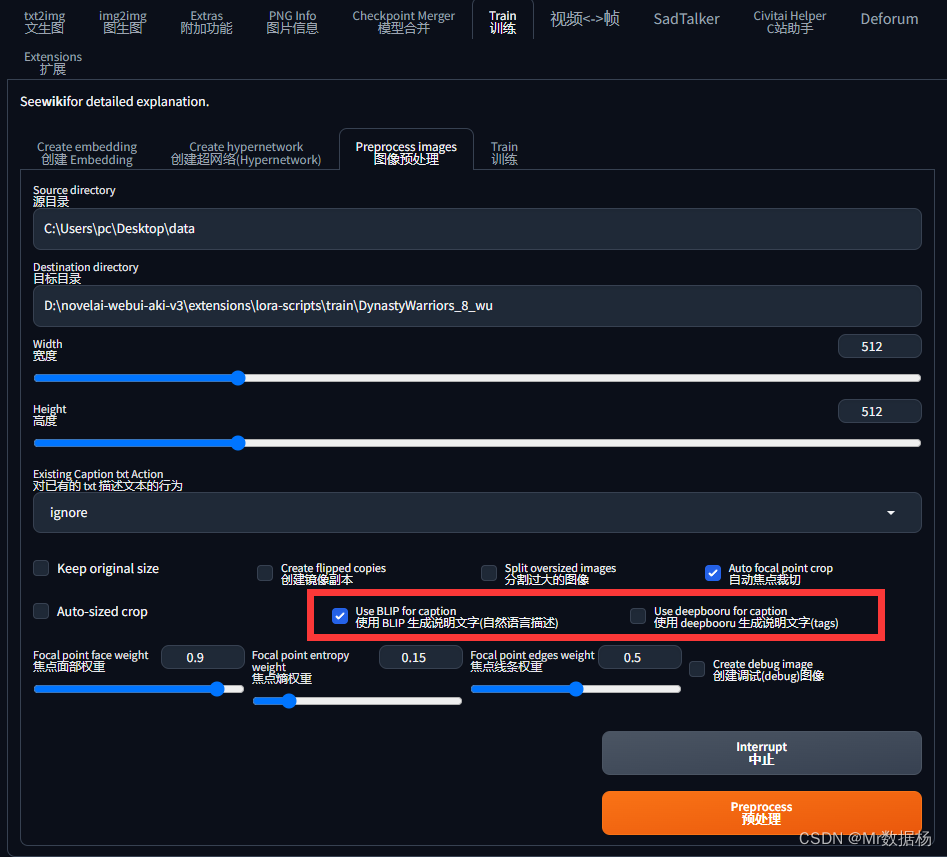
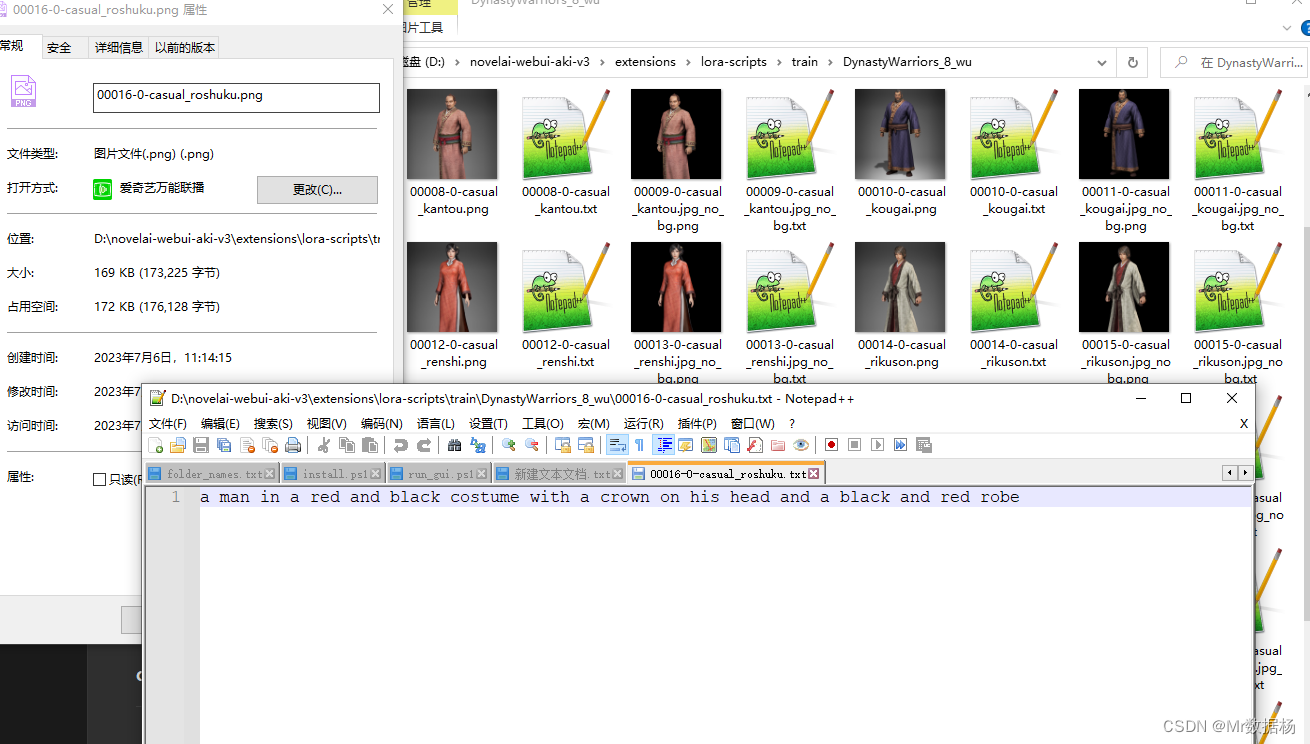
点击预处理会在data2的文件夹下生成对应聚焦切个好的图片以及关键词提示。
新手模式和专家模型
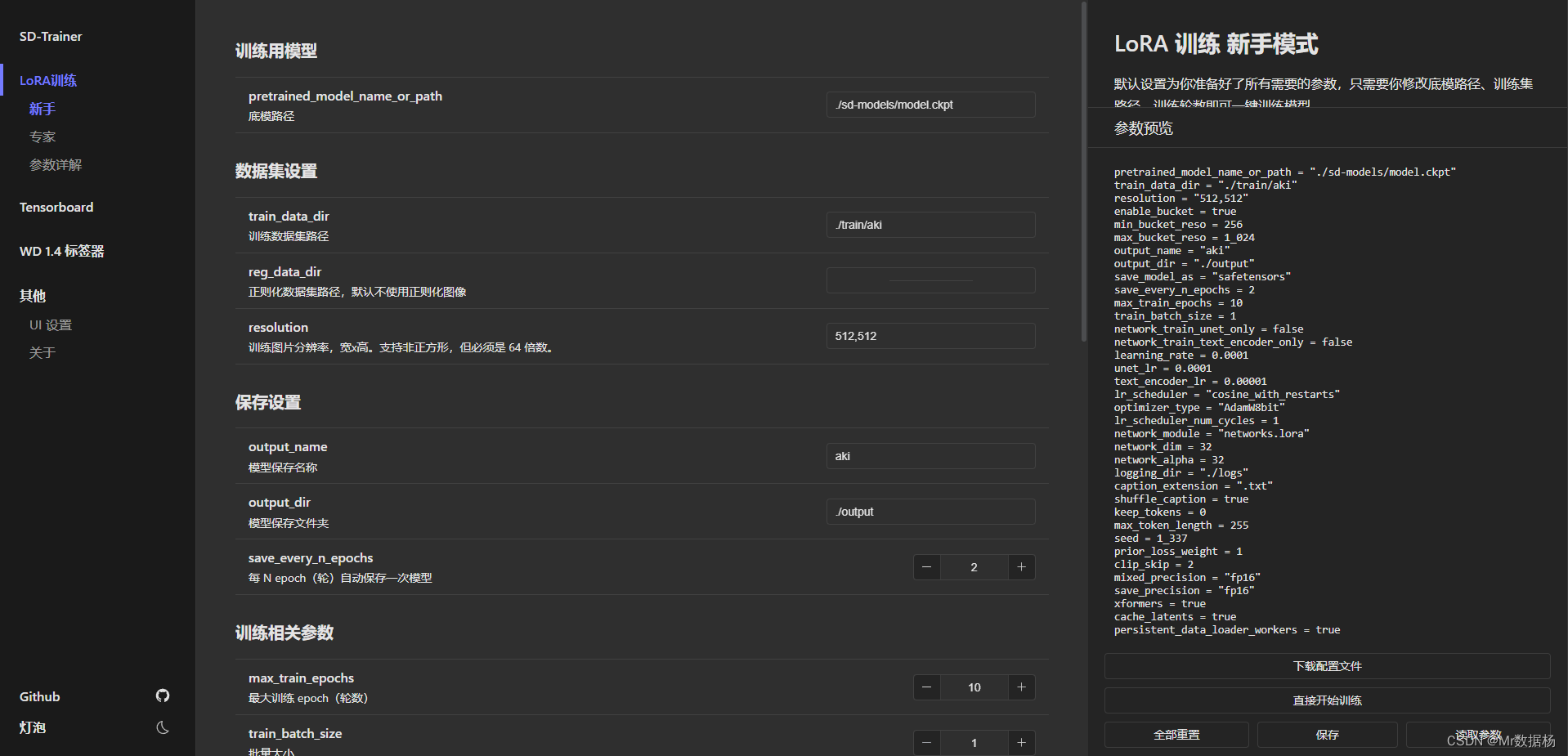
无论是专家模式还是新手模式,基础的配置是一样的,这里介绍新手模式,如果想使用专家模式的话可以根据后面的基本参数说明自行调配设置。
训练模型
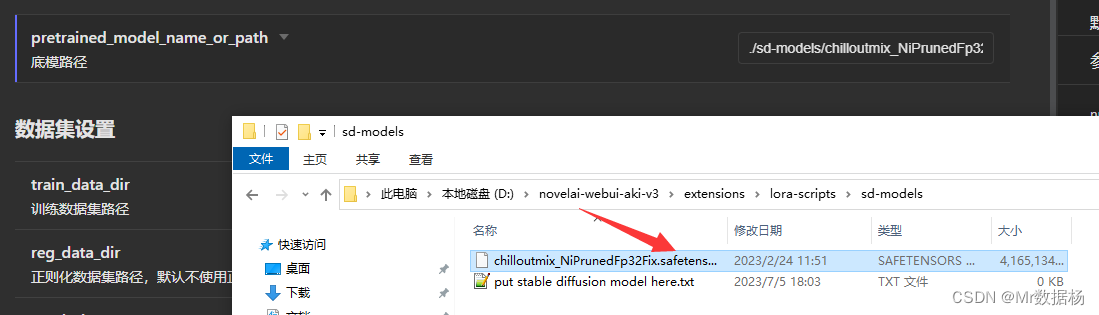
底模路径,选择你要训练的模型路径。默认是相对路径,因此需要把你训练的模型扔到对应的sd-models文件夹下。
数据集设置
训练数据集路径,需要在lora-scripts文件夹下创建train文件夹。然后将我们刚才预处理好的文件夹改名为DynastyWarriors_8_wu,然后需要在新建一个文件夹像我这样咱文件夹下加一个数字和下划线。文件夹中不要有中文和空格以及其他字符。
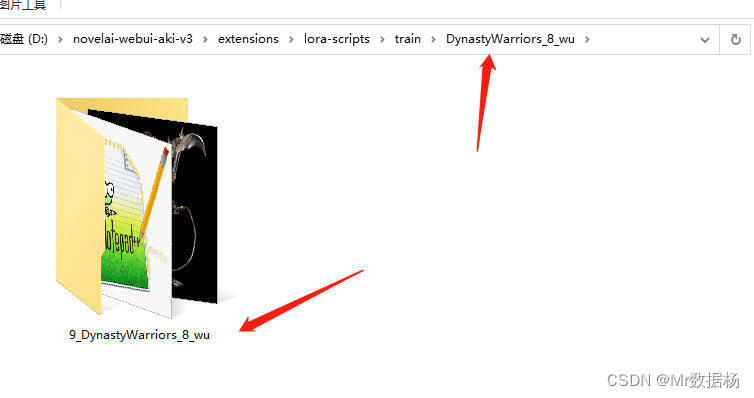
默认不使用正则化图像数据,分辨率设置刚才切分好的 512x512 即可。
保存设置
模型保存名称,这个是保存模型的文件名,可以用文件夹的名称命令便于管理。模型保存文件夹默认当前文件夹下的output文件夹,设置模型默认保存即每训练多少次保存一次模型,如果对模型要求高建议选择1,然后看参数去选择训练好的模型。
训练相关参数
最大训练epoch,表示训练多少次,也就是上面保存设置里对应的epoch,一般来说选择20-30即可。
批量大小,根据你的机器显存来设置,像我这RTX4090一般选择5,可以根据自己的情况选择。
学习率和优化器设置
这个要是不太懂的话就都选择默认即可,后面对于参数解释有介绍可以回过头来调整。
下面是我的配置供参考。

训练预览设置
这里可以开启也可以不开启,用于自己训练的时候每一步出一个样图而已,参数默认即可。每次预览的图会在toml文件夹下查看即可。机器性能不好不要开,直接看最后结果就好。
网络设置
这里支持继续训练的功能,需要自行设置之前的网络结构模型的地址,由于我这是第一次训练因此没有,其他dim和alpha选择默认即可。
captions 选项
是否打乱图片和保留token,也就是关键词,建议选择模型即可,如果每个图片的关键词需要固定统一的话建议选择你需要的数值即可。
参数设置完毕之后点击直接开始训练即可。然后就慢慢的等待吧。第一次启动会自动下载一些配置信息。
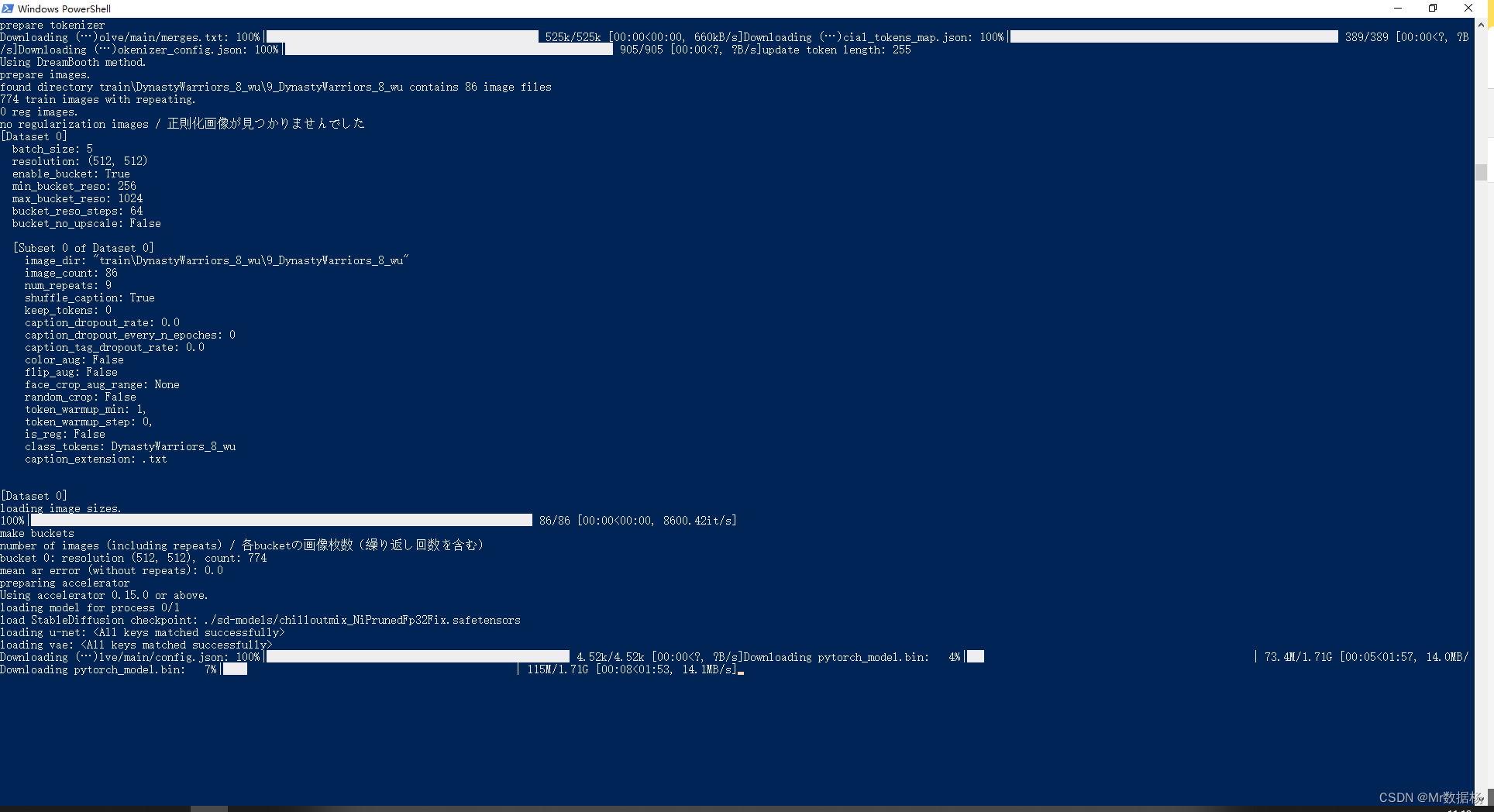
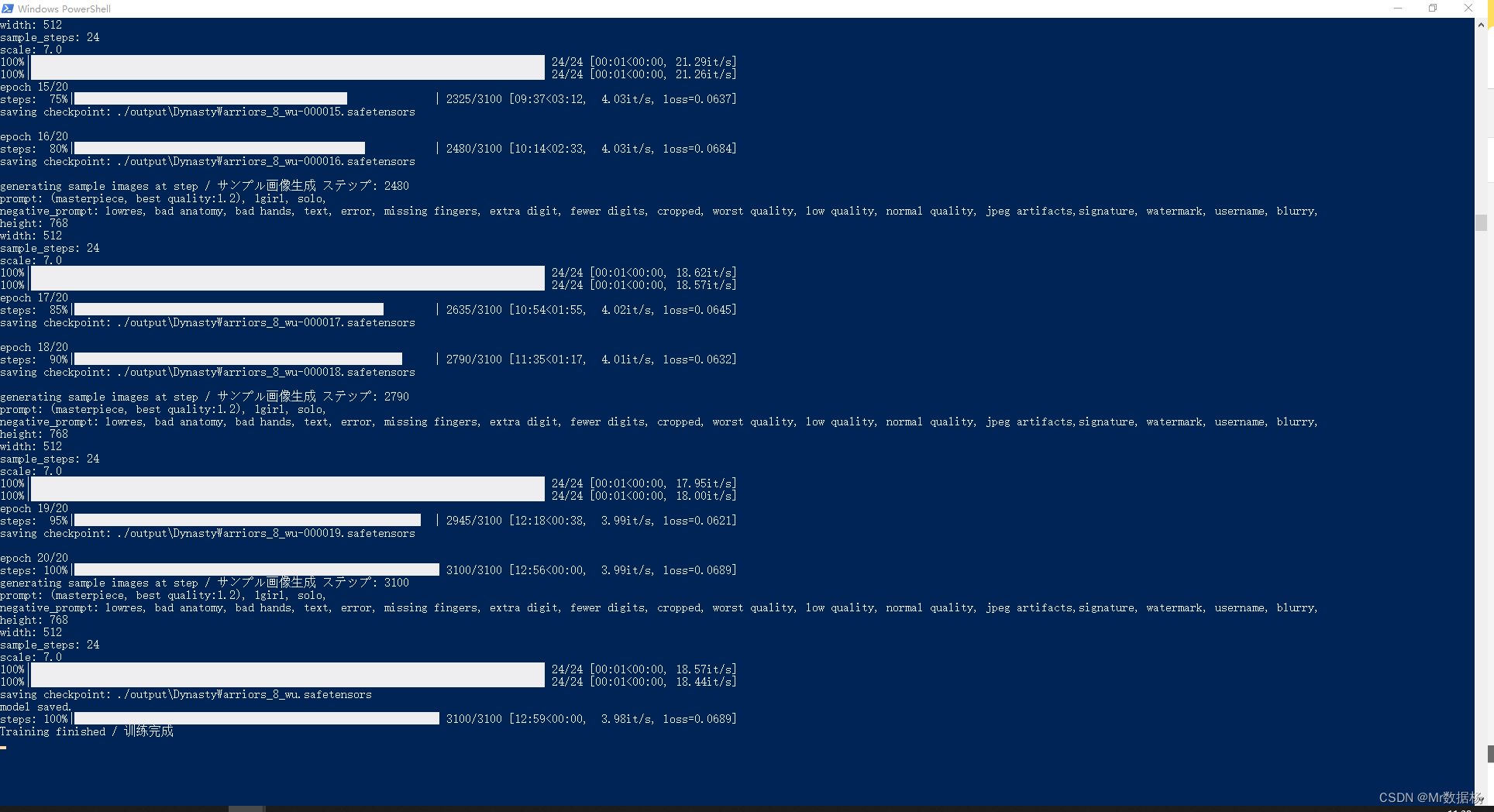
训练过程开始跑epoch。
根据设置每训练一个阶段会自动保存模型文件到output下。
预览图在output下的sample文件夹下,在预览图的过程中我们会发现有点像《真·三国无双》系列人物服装的进化,随着训练服装精细度越高。
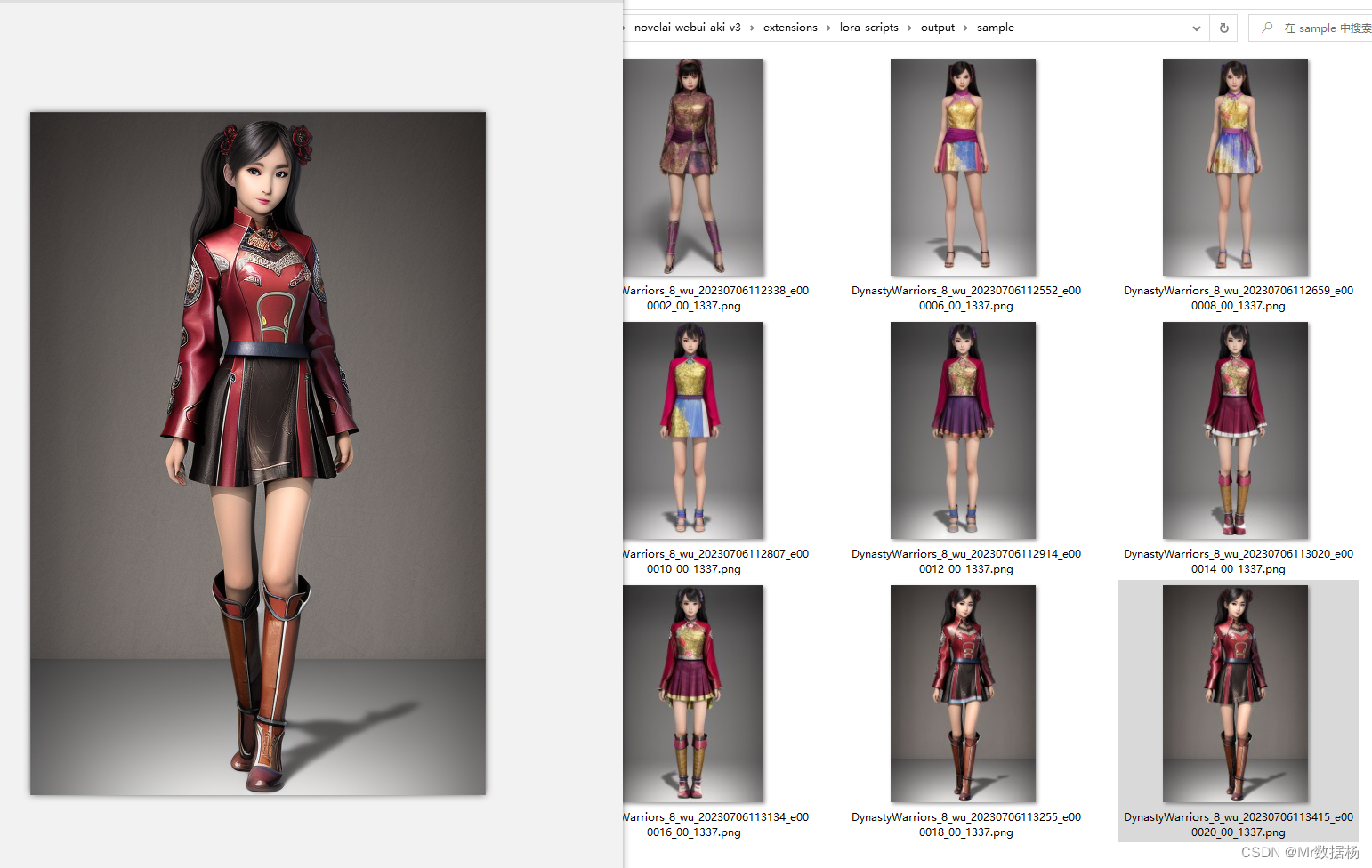
模型的选择和使用
默认选择最后一个模型也是可以的,或者开启专家模式打印日志会出现一个loss损失值,根据模型的鲁棒性,损失值越低的优先选择。
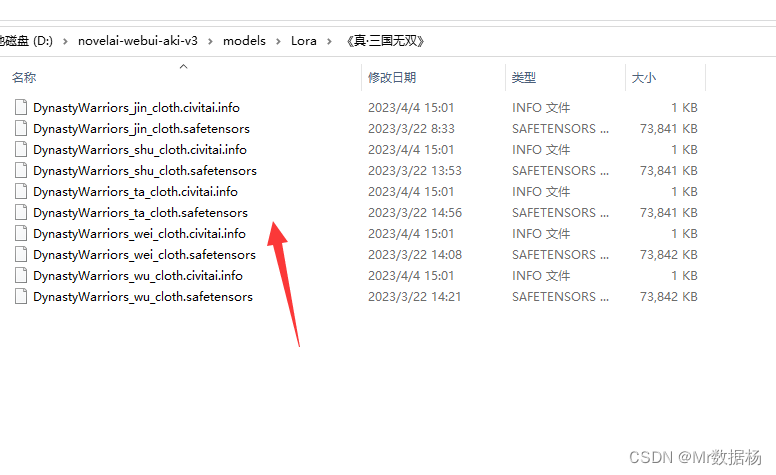
将训练好的LoRA模型放到你的SD目录下models的lora文件夹下就会看到了。
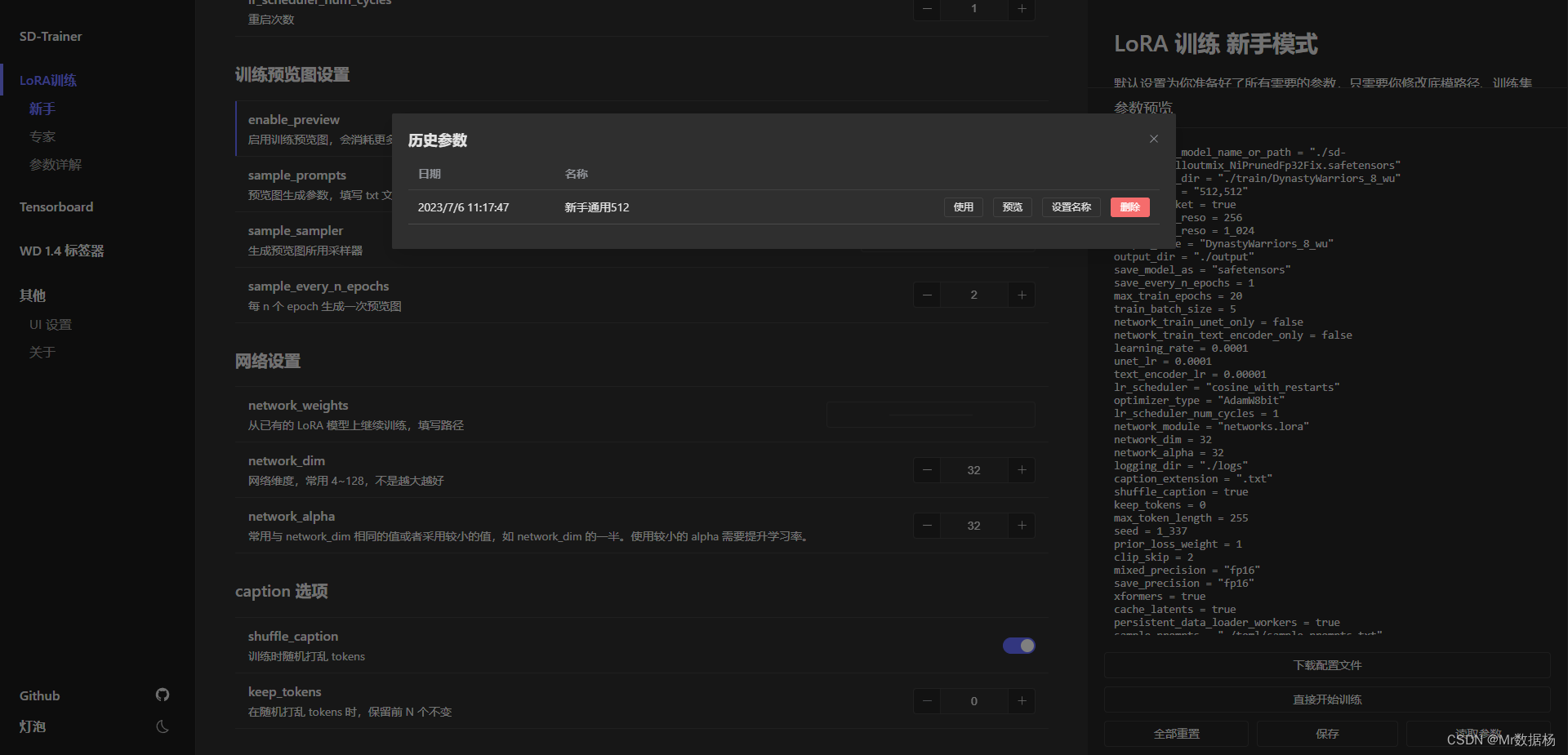
配置保存和读取
为了避免每次设置的麻烦可以将配置进行保存并设置名称,日后方便读取调用。
基本参数说明
在Stable Diffusion模型训练过程中,一个关键因素是正确选择和配置模型与数据集。在此博客中,我将概述如何做出最佳决策,并解释一些关键概念。不管是专家模式还是新手模式参数基本上是一致的,这里有个参数详解页面。直接换成大白话说一下。
模型和数据集
选择基础模型
当选择基础模型(或“底模”)时,建议尽可能选择“祖宗级别”的模型,因为用这些模型训练出来的LoRA(Latent Optimizer Re-Alignment)将会更通用。祖宗级别的模型包括如sd1.5,2.0以及novelai原版泄露模型等,他们是非融合模型。融合模型如anything系列和orangemix系列,这些模型融合了很多不同的元素。虽然在这些模型上进行训练可能在生成图片时会产生不错的效果,但这通常会损失模型的通用性,使得训练出来的模型在其他上下文中的性能较差。因此根据需求进行抉择是非常重要的。
训练分辨率
在训练过程中可以设定训练的分辨率,即图像的宽和高。虽然这可以是非正方形的,但必须为64的整数倍。通常推荐使用大于512x512且小于1024x1024的值。长宽比应根据训练集的特性来决定。一般来说正方形的分辨率可以兼容各种不同的图像分辨率。
但是如果训练集主要由纵向图片组成使用如512x768这样的分辨率。相反如果训练集中的横向图片较多使用768x512这样的分辨率。
ARB桶
ARB桶是一种训练技术,可以允许使用非固定宽高比的图像进行训练,这意味着不需要手动剪裁图像。但是会在一定程度上增加训练时间,并且其分辨率必须大于训练分辨率,因此会占用更多的显存。如果显存小于12G不建议开启ARB桶,请使用新手模式训练LoRA。
学习率与优化器
在深度学习中,有效的学习率设置与优化器选择是关键。
学习率设置
UNet和TE的学习率通常不同,因为它们的学习难度不一样。在常规设置中UNet的学习率会比TE高。这是因为如果UNet训练不足,生成的图像可能不够准确,而训练过度会导致面部扭曲或产生大量色块。相反TE训练不足会导致图像对Prompt的服从度低,过度训练则可能生成多余的内容。
为了精确计算学习步数计算公式如下:
学习步数 = (图片数量 ∗ 重复次数 ∗ e p o c h ) / 批次大小 学习步数 = (图片数量 * 重复次数 * epoch)/ 批次大小 学习步数=(图片数量∗重复次数∗epoch)/批次大小
一般来说效果比较好的初始值为UNet使用1e-4,TE使用5e-5。
以UNet学习率为1e-4为例,训练人物需要至少1000步,训练画风则需要至少2500步,训练概念则需要至少3000步。这是最低步数,如果有更多的图片,就需要更多的步数。
决定学习率和步数的最佳方法是通过迭代实验,先训练再测试如此反复。
学习率调整策略(lr_scheduler)
对于学习率调整策略,推荐使用余弦退火(Cosine Annealing)。如果启用预热,那么预热步数应该占总步数的5%-10%。如果选择使用带重启的余弦退火(Cosine Annealing with Restarts)那么重启次数不应该超过4次。
批次大小(Batch Size)
批次大小越大,梯度越稳定,也可以使用更大的学习率加速收敛。但是它也会消耗更多的机器资源占用更大的显存。一般设置batch size=2即两倍的UNet学习率。
优化器选择
三种最常用的优化器:
- AdamW8bit:这是一个启用int8优化的AdamW优化器,通常是默认选项。
- Lion:Google Brain发表的新优化器,在各个方面的表现都优于AdamW,占用显存更小,但需要更大的batch size以保持梯度更新稳定。
- D-Adaptation:Facebook发表的自适应学习率优化器,调参简单,无需手动控制学习率,但占用显存大(通常需要大于8G)。使用时设置学习率为1即可,同时学习率调整策略使用constant。需要添加
--optimizer_args decouple=True分离UNet和TE的学习率。
网络设置与网络结构
网络结构是构建任何模型的基础。LoRA、LyCORIS、LoCon、LoHa、LoKr 与 IA3 根据实际的训练集图片数量和使用的网络结构来选择合适的网络大小。
网络结构
不同网络结构对应不同的矩阵低秩分解方法。以下是几种结构说明:
- LoRA是一种网络结构,主要控制模型中的线性层和1x1卷积层。这是一种基本的结构,许多后续的网络结构都在 LoRA 的基础上进行改进。
- LyCORIS 是对 LoRA 的改进,它加入了几种不同的算法,包括 LoCon、LoHa、LoKr 与 IA3。
- LoCon:这种算法加入了对卷积层 (Conv) 的控制。
- LoHa 与 LoKr:这两种方法分别使用了哈达玛积(Hadamard product)和克罗内克积(Kronecker product)。
理论上 LyCORIS 会比 LoRA 拥有更强的微调效果,但也更容易过拟合。
网络大小
网络大小的选择应根据实际的训练集图片数量和使用的网络结构。这些推荐值并非对各个不同的数据集都是最优的,需要根据实际情况进行实验来得出最优解。此外对于卷积层 (Conv),最好不要超过8。
网络Alpha
网络Alpha(network_alpha)是一个参数,它在训练期间用来缩放网络的权重。Alpha越小学习越慢,关系可以认为是负线性相关的。一般设置为dim/2或者dim/4。如果选择1,则需要提高学习率或者使用D-Adapation优化器。
专家高级设置
在探索Stable Diffusion的深度应用时,我们会遇到一些高级设置,对于初学者来说这些设置可能会引发一些困惑。
Caption Dropout
Caption Dropout参数的文档和在线信息相对较少,即使在作者的文档中也没有对这些参数进行详细的说明,然而在某些情况下Caption Dropout可以提升模型的性能。
- caption_dropout_rate:这是丢弃全部标签的概率,这意味着图片可能不会使用caption或class token。
- caption_dropout_every_n_epochs:这个参数设置的是每N个epoch丢弃全部标签的频率。
- caption_tag_dropout_rate:这是按逗号分隔的标签来随机丢弃tag的概率。如果你使用DB+标签的训练方法训练画风,推荐使用这个参数,因为它能有效防止tag过拟合。一般来说,我们会选择0.2-0.5之间的值。对于人物训练,我们通常不需要开启这个选项。
Token
Token是由两个相关的参数组成,包括token_warmup_min和token_warmup_step。
- token_warmup_min:这是最小学习的token数量。
- token_warmup_step:这是在多少步后达到最大token数量。
Token热身可以被理解为另一种形式的caption dropout。然而如果不随机打乱token,那么模型只会学习前面N个token。
噪声相关
噪声相关的参数有两种,分别是噪声偏移(noise_offset)和多分辨率/金字塔噪声(multires_noise_iterations、multires_noise_discount)。
- 噪声偏移(noise_offset):在训练过程中加入全局的噪声,可以改善图片的亮度变化范围,使得模型能生成更黑或者更白的图片。如果需要开启这个选项,推荐设置值为0.1,同时需要增加学习步数作为网络收敛更慢的补偿。
- 多分辨率/金字塔噪声:相关参数包括multires_noise_iterations和multires_noise_discount。对于iterations,建议设置在6-8,再高提升不大。而对于discount,建议设置在0.3-0.8之间,更小的值需要更多的步数。
其他参数
- CLIP_SKIP 使用倒数第N层的CLIP模型输出的参数。这需要与我们使用的模型保持一致。如果使用的是基于NAI的二次元模型,那么应当使用2;而如果是使用的是像SD1.5这样的真实模型,那么我们应当使用1。
- Min-SNR-γ 用于加速扩散模型的收敛。由于不同样本批次的学习难度不同,导致梯度方向不一致,使得收敛过程变慢。为了解决这个问题,当这个参数设为5时效果最佳。当优化器使用D-Adaptation时,这种方法就不适用。
- 数据增强 是一种在训练时对图片进行实时变换的方法,用于防止模型过拟合。可以使用的数据增强方法包括:color_aug、flip_aug、face_crop_aug_range、random_crop。不推荐使用,会造成关键词和画面的差异。
- max_grad_norm 一般无用。这个参数用于限制模型更新梯度的大小,从而改善数值稳定性。如果梯度的范数超过这个值,它会被缩放到这个大小。
- gradient_accumulation_steps 这个参数是梯度累积的步数,用于在小显存上模拟大batch size的效果。如果显存足够使用4以上的batch size,例如24G显存的3090或者4090,那么就没有必要启用这个参数。
- log_with、wandb_api_key 用于选择logger类型,可以选择tensorboard或者wandb。
- prior_loss_weight 一般无用,默认选择1就可以了。用于控制在DB训练中先验部分的权重,可以用来控制图像的正则化强度。
- debug_dataset 用来检查我们的设置是否正确。
- vae_batch_size 使用2-4可以稍微加速cache latent的过程。由于VAE编码器本身参数量相对较小,所以即使在Linux机器上,使用8GB显存的显卡也能设为4。对于Windows系统,由于系统占用显存较多,如果显存小于10GB,不要开启这个参数。