2.3 Standalone模式
Standalone模式是Spark自带的资源调度引擎,构建一个由Master + Worker构成的Spark集群,Spark运行在集群中。
这个Standalone区别于Hadoop的。这里的Standalone是指只用Spark来搭建一个集群,不需要借助其他框架。
2.3.1集群角色之资源管理
Master和Worker集群资源管理
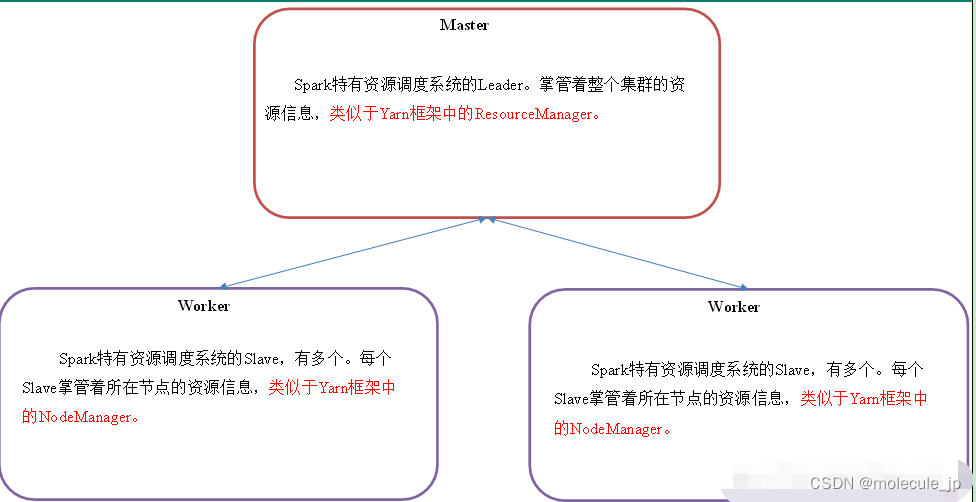
Master和Worker是Spark的守护进程(常驻后台进程)、集群资源管理者,即Spark在特定模式(Standalone)下正常运行必须要有的后台常驻进程。
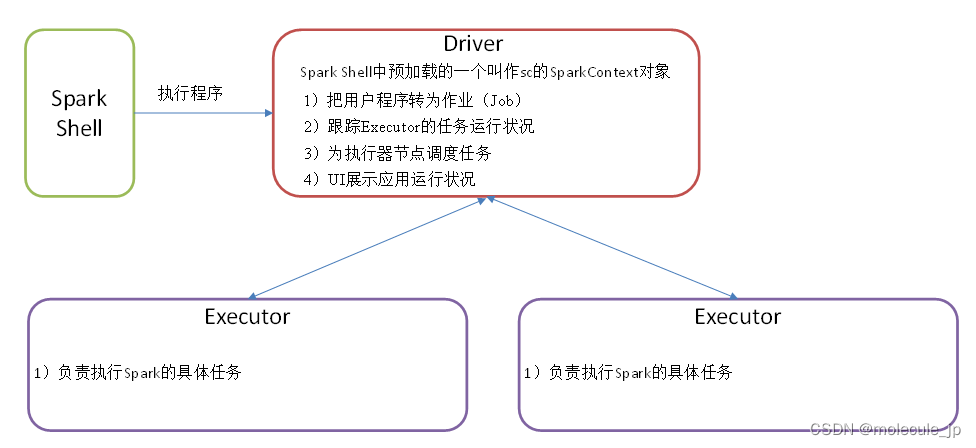
Driver和Executor是临时程序,当有具体任务提交到Spark集群才会开启的程序。
Standalone是Spark自带的资源调度引擎,构建一个由Master + Worker构成的Spark集群,Spark运行在集群中。
2.3.2 安装使用
1)集群规划

2)再解压一份Spark安装包,并修改解压后的文件夹名称为spark-standalone
[aa@hadoop102 sorfware]$ tar -zxvf spark-3.1.3-bin-hadoop3.2.tgz -C /opt/module/
[aa@hadoop102 module]$ mv spark-3.1.3-bin-hadoop3.2 spark-standalone
3)进入Spark的配置目录/opt/module/spark-standalone/conf
[aa@hadoop102 spark-standalone]$ cd conf
4)重命名conf/workers.template文件为conf/workers,并修改works文件内容,添加work节点:
[aa@hadoop102 conf]$ mv workers.template workers
[aa@hadoop102 conf]$ vim workers
```dart
hadoop102
hadoop103
hadoop104
5)修改重命名文件conf/spark-env.sh.template为conf/spark-env.sh文件,添加master节点
```dart
[aa@hadoop102 conf]$ mv spark-env.sh.template spark-env.sh
[aa@hadoop102 conf]$ vim spark-env.sh
SPARK_MASTER_HOST=hadoop102
SPARK_MASTER_PORT=7077
6)分发spark-standalone包
[aa module]$ xsync spark-standalone/
7)启动spark集群
[aa spark-standalone]$ sbin/start-all.sh
查看三台服务器运行进程(xcall.sh是以前采集项目里面讲的脚本)。
[aa spark-standalone]$ xcall.sh
=============== hadoop102 ===============
10341 Worker
11061 Jps
10231 Master
=============== hadoop103 ===============
7800 Worker
8266 Jps
=============== hadoop104 ===============
13601 Jps
13293 Worker
注意:如果遇到 “JAVA_HOME not set” 异常,可以在sbin目录下的spark-config.sh 文件中加入如下配置。
export JAVA_HOME=XXXX
8)网页查看:hadoop102:8080(master web的端口,相当于yarn的8088端口)
目前还看不到任何任务的执行信息。
9)官方求PI案例
[aa spark-standalone]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10
参数:–master spark://hadoop102:7077指定要连接的集群的master(配置文件中所配置的信息一致)。
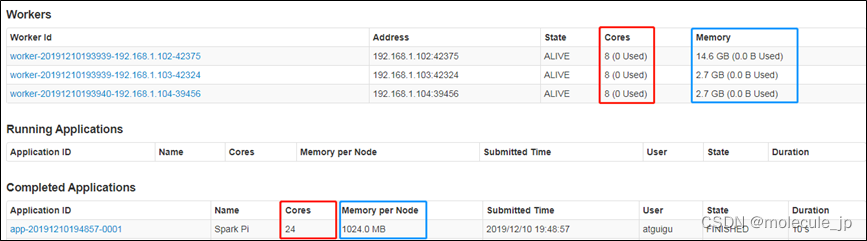
10)页面查看http://hadoop102:8080/
默认采用三台服务器节点的总核数24核,每个节点内存1024M
·8080:master的webUI
·4040:application的webUI的端口号

2.3.3 参数说明
我们当然也可以根据实际任务需求指定使用资源
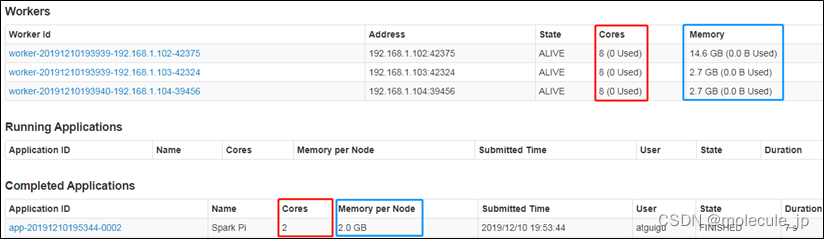
1)配置Executor可用内存为2G,使用CPU核数为2个
[aa spark-standalone]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--executor-memory 2G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10
2)页面查看http://hadoop102:8080/
3)基本语法
bin/spark-submit
–class
–master
… # other options
[application-arguments]
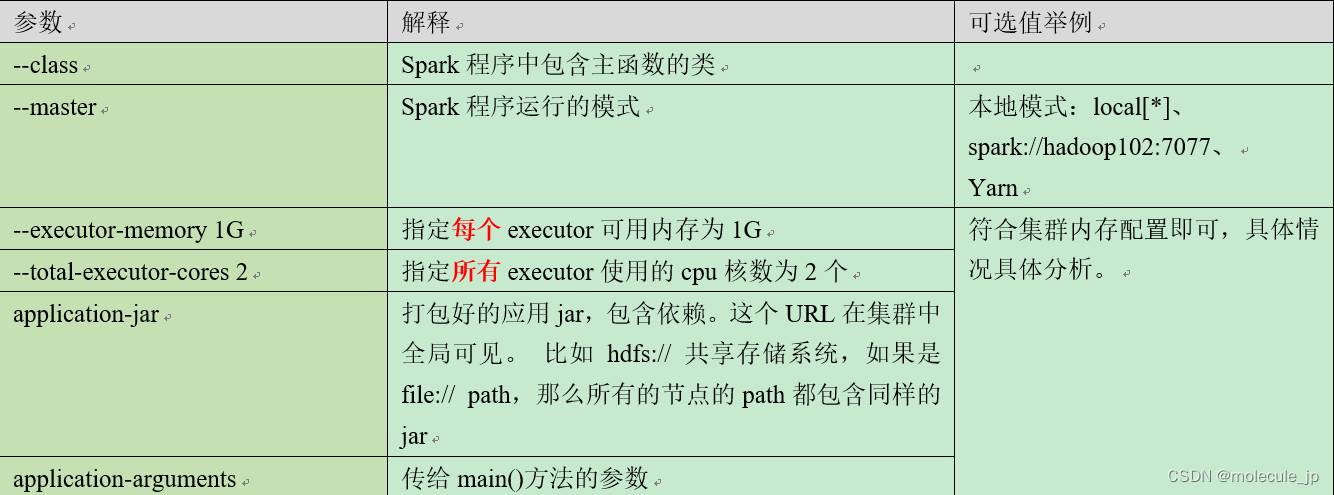
4)参数说明
2.3.4 配置历史服务
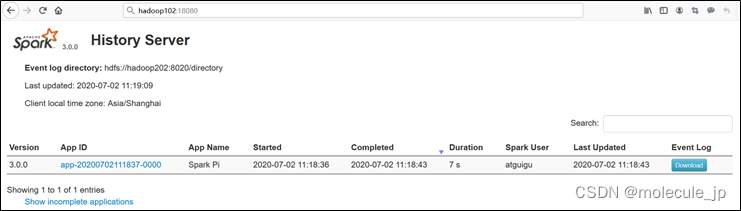
由于spark-shell停止掉后,hadoop102:4040页面就看不到历史任务的运行情况,所以我们需要历史服务器任务日志。
1)修改spark-default.conf.template名称
[aa conf]$ mv spark-defaults.conf.template spark-defaults.conf
2)修改spark-default.conf文件,配置日志存储路径(写)
[aa conf]$ vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/directory
注意:需要启动Hadoop集群,HDFS上的目录需要提前存在(因为历史任务日志数据存储在HDFS上)。
[aa hadoop-3.1.3]$ hadoop.sh start
[aa hadoop-3.1.3]$ hadoop fs -mkdir /directory
3)修改spark-env.sh文件,添加如下配置:
[aa conf]$ vim spark-env.sh
export SPARK_HISTORY_OPTS="
-Dspark.history.ui.port=18080
-Dspark.history.fs.logDirectory=hdfs://hadoop102:8020/directory
-Dspark.history.retainedApplications=30"
参数1含义:WEBUI访问的端口号为18080
参数2含义:指定历史服务器日志存储路径(读)
参数3含义:指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
4)分发配置文件
[aa conf]$ xsync spark-defaults.conf
[aa conf]$ xsync spark-env.sh
5)启动历史服务
[aa spark-standalone]$ sbin/start-history-server.sh
6)再次执行任务
[aa spark-standalone]$ bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop102:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.12-3.1.3.jar \
10
7)查看Spark历史服务地址:hadoop102:18080