Elastic MySQL 连接器是 MySQL 数据源的连接器。它可以帮我们把 MySQL 里的数据同步到 Elasticsearch 中去。在今天的文章里,我来详细地描述如何一步一步地实现。

在下面的展示中,我将使用 Elastic Stack 8.8.2 来进行展示。
无缝集成:将 Elasticsearch 连接到 MongoDB
可用性和先决条件
此连接器在 Elastic 版本 8.5.0 及更高版本中作为本机连接器提供。 要将此连接器用作本机连接器,请满足所有本机连接器 (Native Connector)要求。
此连接器也可用作 Python 连接器框架的连接器客户端。 要将此连接器用作连接器客户端,请满足所有连接器客户端要求。
除了上面链接的共享要求之外,此连接器没有其他先决条件。
用法
要将此连接器用作本机连接器,请使用连接器工作流程。 请参阅本机连接器。
要将此连接器用作连接器客户端,请参阅连接器客户端和框架。
在如下的展示中,我将使用连接器客户端来进行使用。

安装
Elasticsearch
我们可参考我之前的文章 “如何在 Linux,MacOS 及 Windows 上进行安装 Elasticsearch” 来安装 Elasticsearch。特别地,我们需要按照 Elastic Stack 8.x 的安装指南来进行安装。
在 Elasticsearch 终端输出中,找到 elastic 用户的密码和 Kibana 的注册令牌。 这些是在 Elasticsearch 第一次启动时打印的。

我们记下这个密码,并在下面的配置中进行使用。同时它也会生成相应的证书文件:
$ pwd
/Users/liuxg/elastic/elasticsearch-8.8.2/config/certs
$ ls
http.p12 http_ca.crt transport.p12为了方便下面的配置,我们把 http_ca.crt 证书拷贝到如下的一个目录中:
mkdir -p ~/connectors-python-config
cp http_ca.crt ~/connectors-python-config
保存密码、注册令牌和证书路径名。 你将在后面的步骤中需要它们。如果你对这些操作还不是很熟的话,请参考我之前的文章 “Elastic Stack 8.0 安装 - 保护你的 Elastic Stack 现在比以往任何时候都简单”。
安装 Kibana
我们接下来安装 Kibana。我们可以参考我之前的文章 “如何在 Linux,MacOS 及 Windows 上安装 Elastic 栈中的 Kibana” 来进行我们的安装。特别地,我们需要安装 Kibana 8.2 版本。如果你还不清楚如何安装 Kibana 8.2,那么请阅读我之前的文章 “Elastic Stack 8.0 安装 - 保护你的 Elastic Stack 现在比以往任何时候都简单”。在启动 Kibana 之前,我们可以修改 Kibana 的配置文件如下。添加如下的句子到 config/kibana.yml 中去:
config/kibana.yml
enterpriseSearch.host: http://localhost:3002然后,我们使用如下的命令来启动 Kibana:
bin/kibana我们在浏览器中输入上面输出的地址然后输入相应的 enrollment token 就可以把 Kibana 启动起来。
Java安装
你需要安装 Java。版本在 Java 8 或者 Java 11。我们可以参考链接来查找需要的 Java 版本。
Enterprise search 安装
我们在地址 Download Elastic Enterprise Search | Elastic 找到我们需要的版本进行下载。并按照页面上相应的指令来进行按照。如果你想针对你以前的版本进行安装的话,请参阅地址 https://www.elastic.co/downloads/past-releases#app-search。
等我们下载完 Enterprise Search 的安装包,我们可以使用如下的命令来进行解压缩:
$ pwd
/Users/liuxg/elastic
$ ls
elasticsearch-8.8.2 kibana-8.8.2
elasticsearch-8.8.2-darwin-aarch64.tar.gz kibana-8.8.2-darwin-aarch64.tar.gz
enterprise-search-8.8.2.tar.gz
$ tar xzf enterprise-search-8.8.2.tar.gz
$ cd enterprise-search-8.8.2
$ ls
LICENSE NOTICE.txt README.md bin config lib metricbeat如上所示,它含有一个叫做 config 的目录。我们在启动 Enterprise Search 之前,必须做一些相应的配置。我们需要修改 config/enterprise-search.yml 文件。在这个文件中添加如下的内容:
config/enterprise-search.yml
allow_es_settings_modification: true
secret_management.encryption_keys: ['q3t6w9z$C&F)J@McQfTjWnZr4u7x!A%D']
elasticsearch.username: elastic
elasticsearch.password: "JUYrx8L3WOeG6zysQY2D"
elasticsearch.host: https://127.0.0.1:9200
elasticsearch.ssl.enabled: true
elasticsearch.ssl.certificate_authority: /Users/liuxg/elastic/elasticsearch-8.8.2/config/certs/http_ca.crt
kibana.external_url: http://localhost:5601
在上面,请注意 elasticsearch.password 是我们在 Elasticsearch 安装过程中生成的密码。elasticsearch.ssl.certificate_authority 必须根据自己的 Elasticsearch 安装路径中生成的证书进行配置。在上面的配资中,我们还没有配置 secret_management.encryption_keys。我们可以使用上面的配置先运行,然后让系统帮我们生成。在配置上面的密码时,我们需要添加上引号。我发现在密码中含有 * 字符会有错误的信息。我们使用如下的命令来启动:
bin/enterprise-search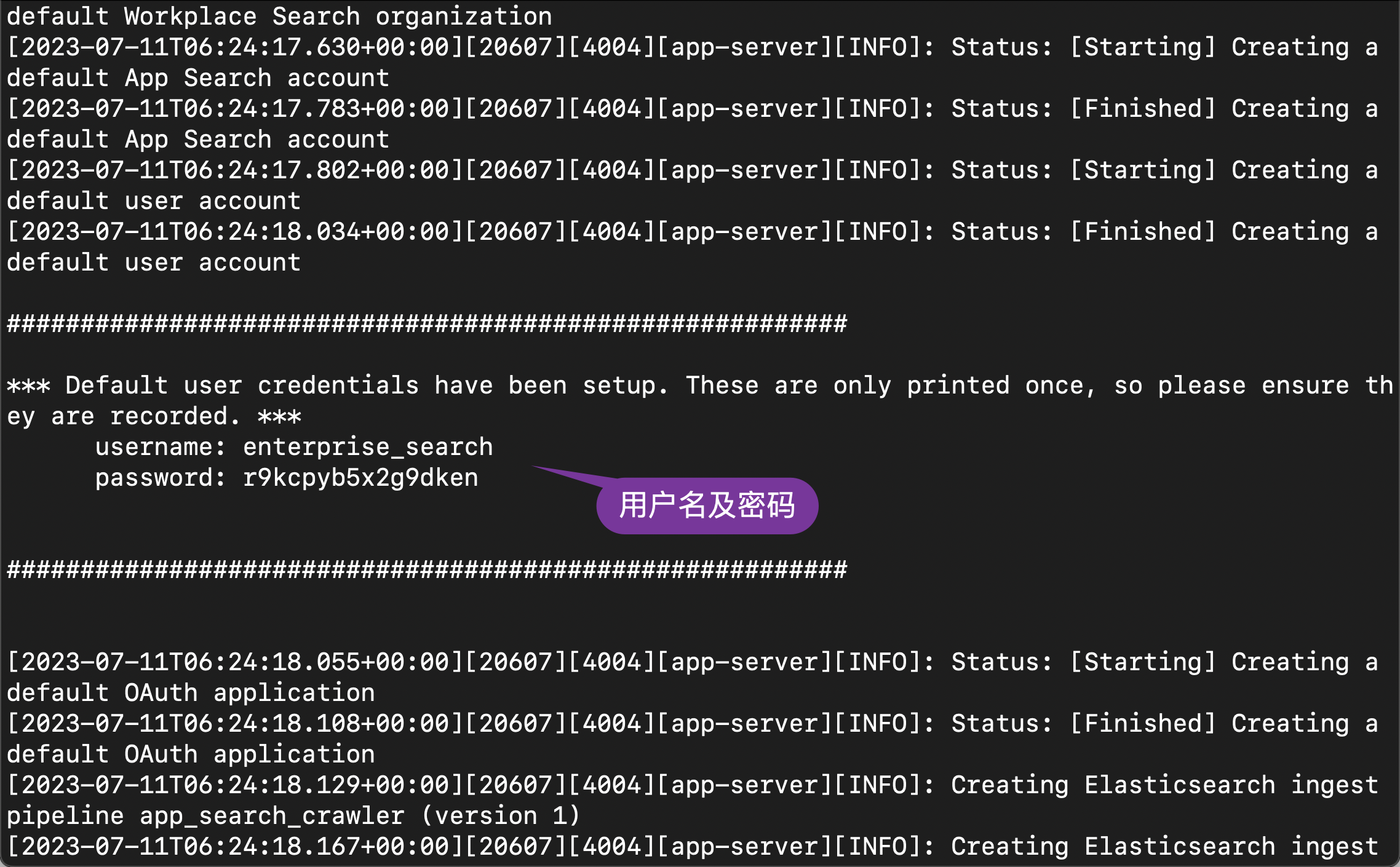
在启动的过程中,我们可以看到生成的用户名及密码信息:
username: enterprise_search
password: r9kcpyb5x2g9dken我们记下这个用户名及密码。在启动的过程中,我们还可以看到一个生成的 secret_session_key:

我们也把它拷贝下来,并添加到配置文件中去:
allow_es_settings_modification: true
secret_management.encryption_keys: ['q3t6w9z$C&F)J@McQfTjWnZr4u7x!A%D']
elasticsearch.username: elastic
elasticsearch.password: "JUYrx8L3WOeG6zysQY2D"
elasticsearch.host: https://127.0.0.1:9200
elasticsearch.ssl.enabled: true
elasticsearch.ssl.certificate_authority: /Users/liuxg/elastic/elasticsearch-8.8.2/config/certs/http_ca.crt
kibana.external_url: http://localhost:5601
secret_session_key: 3a6d8ab8993a9818728eabd6513fd1c448263be6f5497c8d286bc8be05b87edffd95073582e3277f1e8fb8f753a3ab07a5749ce4394a16f69bdc4acb3d2826ae
feature_flag.elasticsearch_search_api: true为了能够使得我们能够在 App Search 中使用 Elasticsearch 搜索,我们必须设置
feature_flag.elasticsearch_search_api: true。 我们再次重新启动 enterprise search:
./bin/enterprise-search 这次启动后,我们再也不会看到任何的配置输出了。这样我们的 enterprise search 就配置好了。
MySQL
对于本教程,你需要一个供 Logstash 读取的源 MySQL 实例。 MySQL Community Downloads 站点的 MySQL Community Server 部分提供了免费版本的 MySQL。我们可以通过如下的命令来登录 MySQL:
mysql -u root -p
在上面,我们使用 root 的密码来进行登录。针对我的情况,密码为 1234。等我们登录后,我们运行如下的命令:
CREATE DATABASE sample_db;
USE sample_db;
CREATE TABLE person (
person_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
age INT
);
CREATE TABLE address (
address_id INT AUTO_INCREMENT PRIMARY KEY,
address VARCHAR(255)
);
INSERT INTO person (name, age) VALUES ('Alice', 30);
INSERT INTO person (name, age) VALUES ('Bob', 25);
INSERT INTO person (name, age) VALUES ('Carol', 35);
INSERT INTO address (address) VALUES ('123 Elm St');
INSERT INTO address (address) VALUES ('456 Oak St');
INSERT INTO address (address) VALUES ('789 Pine St');在上面,我们创建了数据库 sample_db,也同时创建了两个表格 address 及 person。

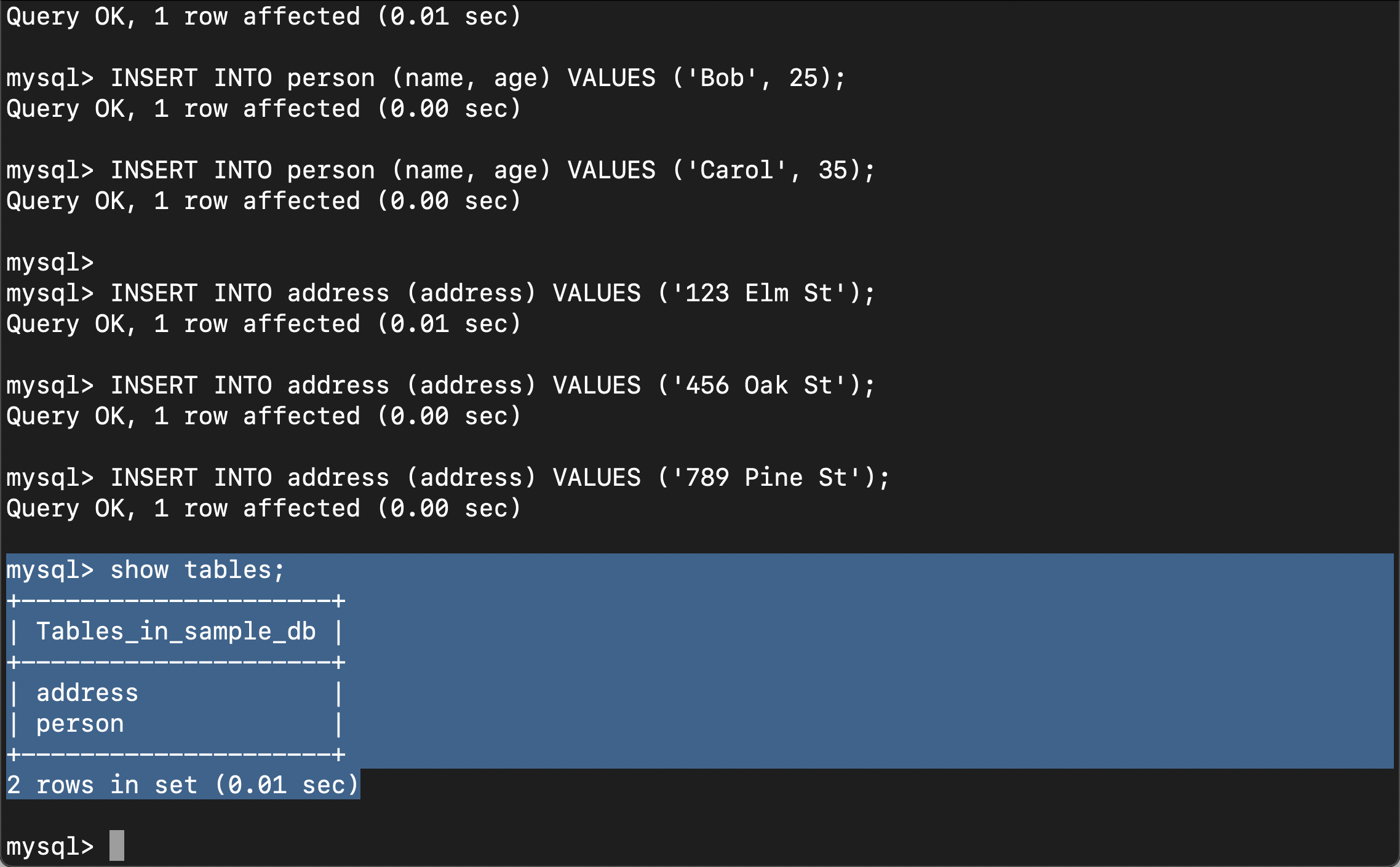
同步数据到 Elasticsearch
步骤一:下载示例配置文件
下载示例配置文件。 你可以手动下载或运行以下命令:
curl https://raw.githubusercontent.com/elastic/connectors-python/main/config.yml --output ~/connectors-python-config/config.yml我们可以查看文件:
$ pwd
/Users/liuxg/connectors-python-config
$ ls
config.yml http_ca.crt如果你的目录名称不同,或者你想使用不同的配置文件名,请记住更新 --output 参数值。
步骤二:更新自管理连接器的配置文件
使用以下设置更新配置文件以匹配你的环境:
elasticsearch.hostelasticsearch.passwordconnector_idservice_type
使用 mysql 作为 service_type 值。 不要忘记取消 yaml 文件源部分中 mysql 的注释。
如果你针对 Elasticsearch 和 Kibana 的 Docker 化版本运行连接器服务,你的配置文件将如下所示:
elasticsearch:
host: http://host.docker.internal:9200
username: elastic
password: <YOUR_PASSWORD>
connector_id: <CONNECTOR_ID_FROM_KIBANA>
service_type: mysql
sources:
# UNCOMMENT "mysql" below to enable the MySQL connector
#mongodb: connectors.sources.mongo:MongoDataSource
#s3: connectors.sources.s3:S3DataSource
#dir: connectors.sources.directory:DirectoryDataSource
#mysql: connectors.sources.mysql:MySqlDataSource
#network_drive: connectors.sources.network_drive:NASDataSource
#google_cloud_storage: connectors.sources.google_cloud_storage:GoogleCloudStorageDataSource
#azure_blob_storage: connectors.sources.azure_blob_storage:AzureBlobStorageDataSource
#postgresql: connectors.sources.postgresql:PostgreSQLDataSource
#oracle: connectors.sources.oracle:OracleDataSource
#mssql: connectors.sources.mssql:MSSQLDataSource请注意,你下载的配置文件可能包含更多条目,因此你需要手动复制/更改适用于您的设置。 通常,你只需要更新 elasticsearch.host、elasticsearch.password、connector_id 和 service_type 即可运行连接器服务。
我们来从 Kibana 界面得到这些配置:





~/connectors-python-config/config.yml
elasticsearch:
host: https://192.168.0.3:9200
api_key: "OUkyM1E0a0JrWktfLVd2OTRPZkE6TmkxbUNuN3dROGlrT2cwWlNVaEZKQQ=="
ca_certs: "/usr/share/certs/http_ca.crt"
ssl: true
bulk:
queue_max_size: 1024
queue_max_mem_size: 25
display_every: 100
chunk_size: 1000
max_concurrency: 5
chunk_max_mem_size: 5
concurrent_downloads: 10
request_timeout: 120
max_wait_duration: 120
initial_backoff_duration: 1
backoff_multiplier: 2
log_level: info
service:
idling: 30
heartbeat: 300
max_errors: 20
max_errors_span: 600
max_concurrent_content_syncs: 1
max_concurrent_access_control_syncs: 1
job_cleanup_interval: 300
log_level: INFO
connector_id: '8423Q4kBkZK_-Wv9z-en'
service_type: 'mysql'
sources:
# mongodb: connectors.sources.mongo:MongoDataSource
# s3: connectors.sources.s3:S3DataSource
# dir: connectors.sources.directory:DirectoryDataSource
mysql: connectors.sources.mysql:MySqlDataSource
# network_drive: connectors.sources.network_drive:NASDataSource
# google_cloud_storage: connectors.sources.google_cloud_storage:GoogleCloudStorageDataSource
# google_drive: connectors.sources.google_drive:GoogleDriveDataSource
# azure_blob_storage: connectors.sources.azure_blob_storage:AzureBlobStorageDataSource
# postgresql: connectors.sources.postgresql:PostgreSQLDataSource
# oracle: connectors.sources.oracle:OracleDataSource
# sharepoint_server: connectors.sources.sharepoint_server:SharepointServerDataSource
# mssql: connectors.sources.mssql:MSSQLDataSource
# jira: connectors.sources.jira:JiraDataSource
# confluence: connectors.sources.confluence:ConfluenceDataSource
# dropbox: connectors.sources.dropbox:DropboxDataSource
# servicenow: connectors.sources.servicenow:ServiceNowDataSource
# sharepoint_online: connectors.sources.sharepoint_online:SharepointOnlineDataSource
# github: connectors.sources.github:GitHubDataSource在上面,请注意:
-
host 是 Elasticsearch 的访问地址
-
api_key 是用来访问 Elasticsearch 的 API key。如果你使用用户名和密码组合,这个就不需要了
-
ca_certs 是用来访问 Elasticsearch 的证书。这个是针对 self-managed 的 Elasticsearch 集群而言的
-
sevice_type 必须是 mysql
-
connector_id 是在上面的配置中生成的。用来标识该连接器
步骤三:运行 Docker 镜像
docker run \
-v ~/connectors-python-config:/config \
--volume="$PWD/http_ca.crt:/usr/share/certs/http_ca.crt:ro" \
--network "elastic" \
--tty \
--rm \
docker.elastic.co/enterprise-search/elastic-connectors:8.8.2.0-SNAPSHOT \
/app/bin/elastic-ingest \
-c /config/config.yml
当运行完上面的命令后,我们再次回到 Kibana 的界面:

接下来我们来配置 MySQL。由于我们的连接器客户端是在 docker 容器里运行的,二我们的 MySQL 只能在 localhost:3306 进行访问。容器里的代码是没有办法访问到外面的 localhost 地址的。为此,我参照之前的文章 “Kibana:创建一个 webhook alert - Elastic Stack 8.2”。运行如下的命令:
bore local 3306 --to bore.pub
这样 MySQL 就可以被一个公网地址 bore.pub:3332 所访问。我们接下来使用这个地址来进行配置:



我们定于每天的 UTC 零点时间来进行同步。当然,我们也可以选择不定时同步。点击 Save:
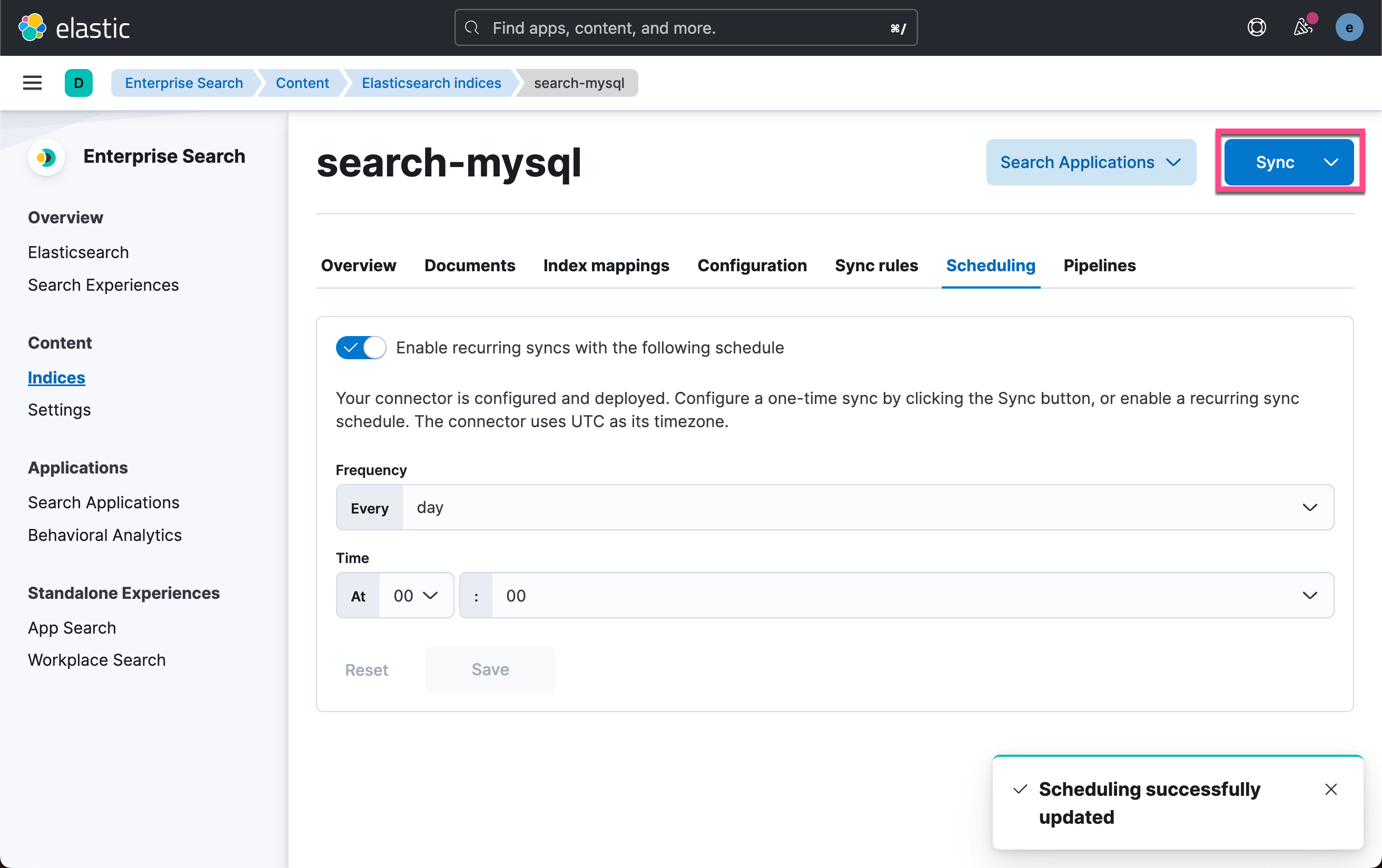
我们点击上面的 Sync:

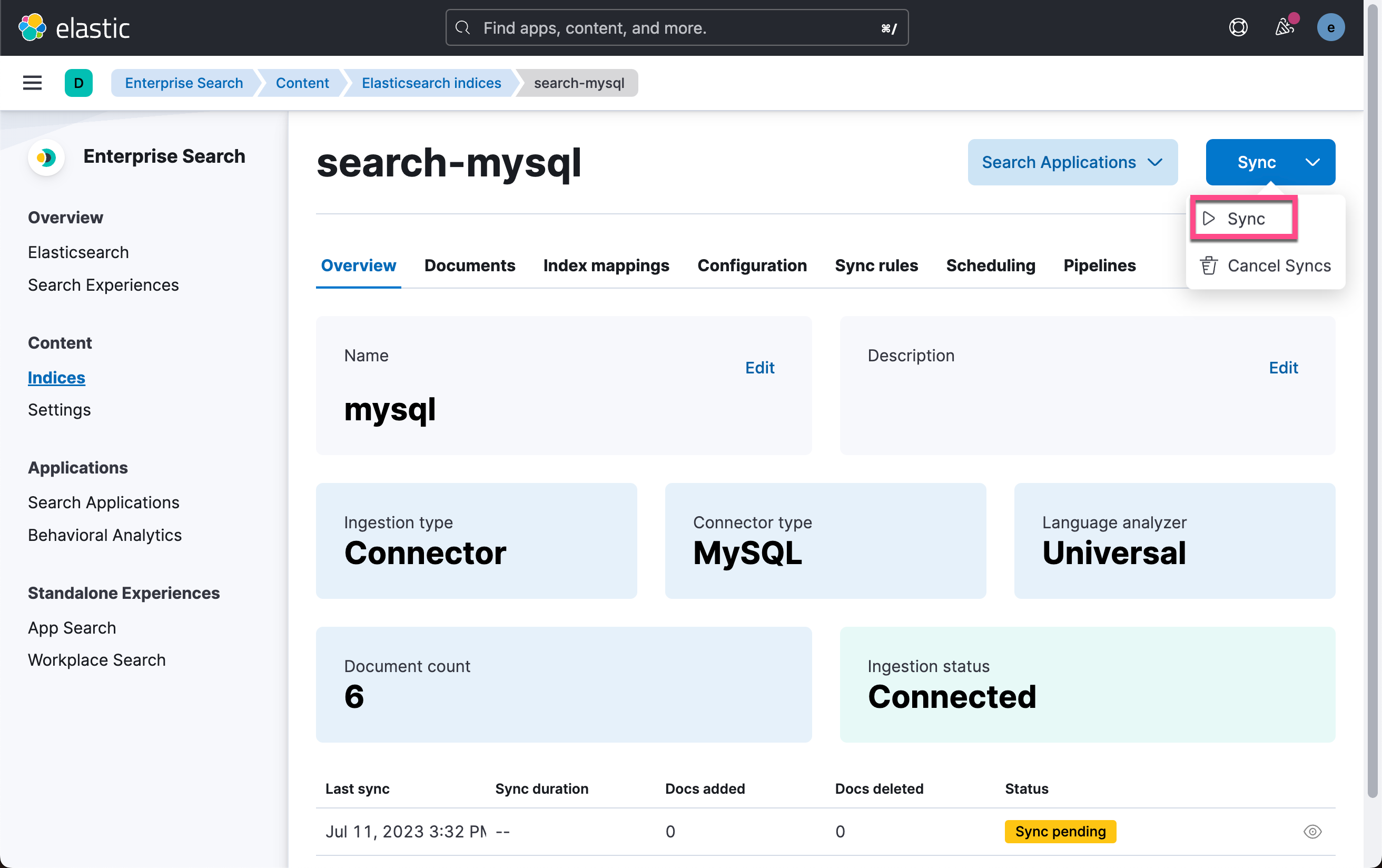


为了验证它是否能够正确地同步新的文档,我们在 MySQL 中添加一个新的文档:

我们在 Kibana 中再次手动 Sync:
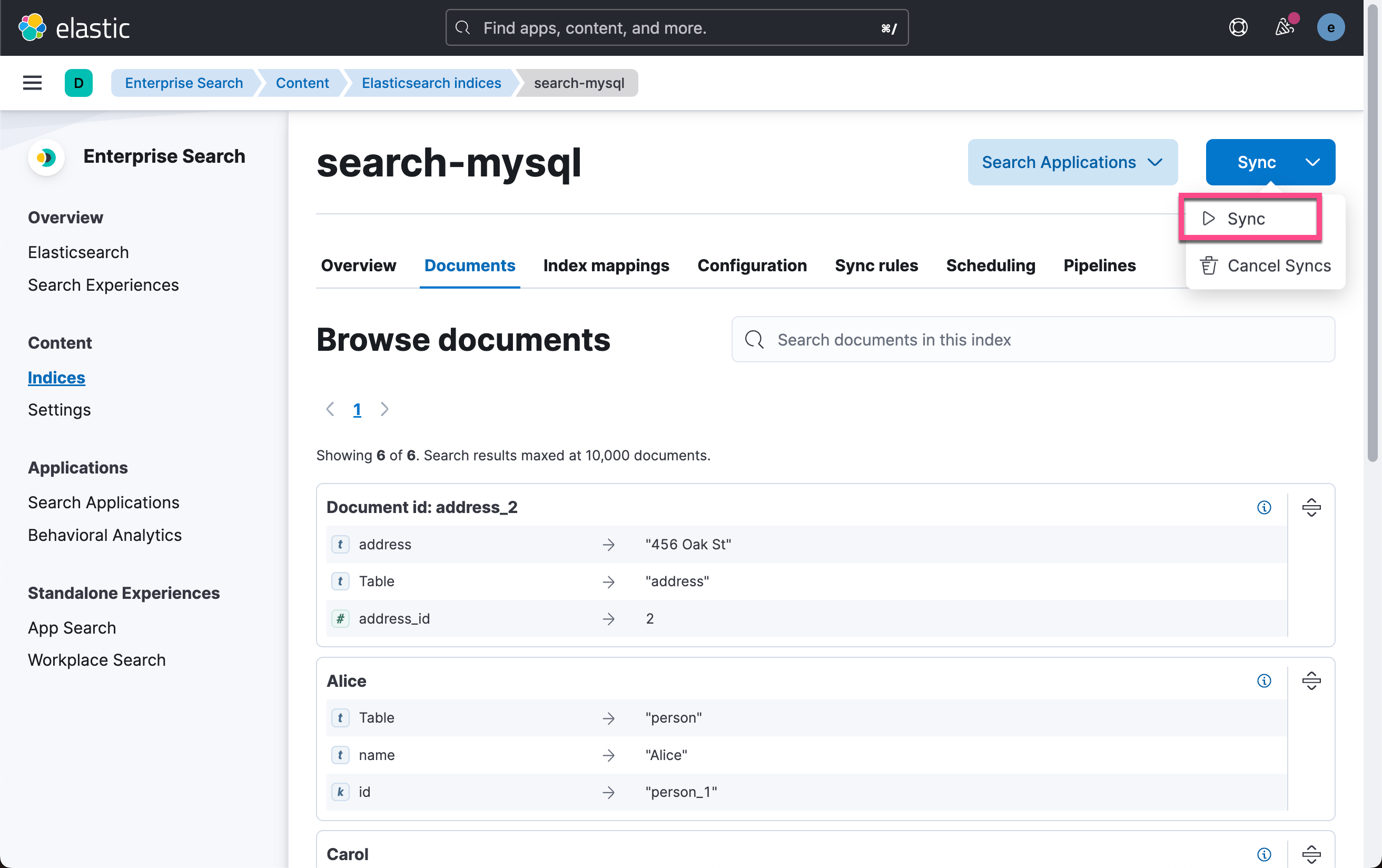

由于一些原因,在测试中,我发现在最新的 connector 发布中,它含有 Sync rules,而在我运行的版本中是没有的。它需要在最新的发布版中才有,但是 snapshot 的运行中有一个错误。
我们可以通过 Sync rule 来同步我们需要的数据,比如:
[
{
"tables": [
"person"
],
"query": "SELECT * FROM sample_db.person LIMIT 1;"
},
{
"tables": [
"address"
],
"query": "SELECT * FROM sample_db.address LIMIT 1;"
}
] 
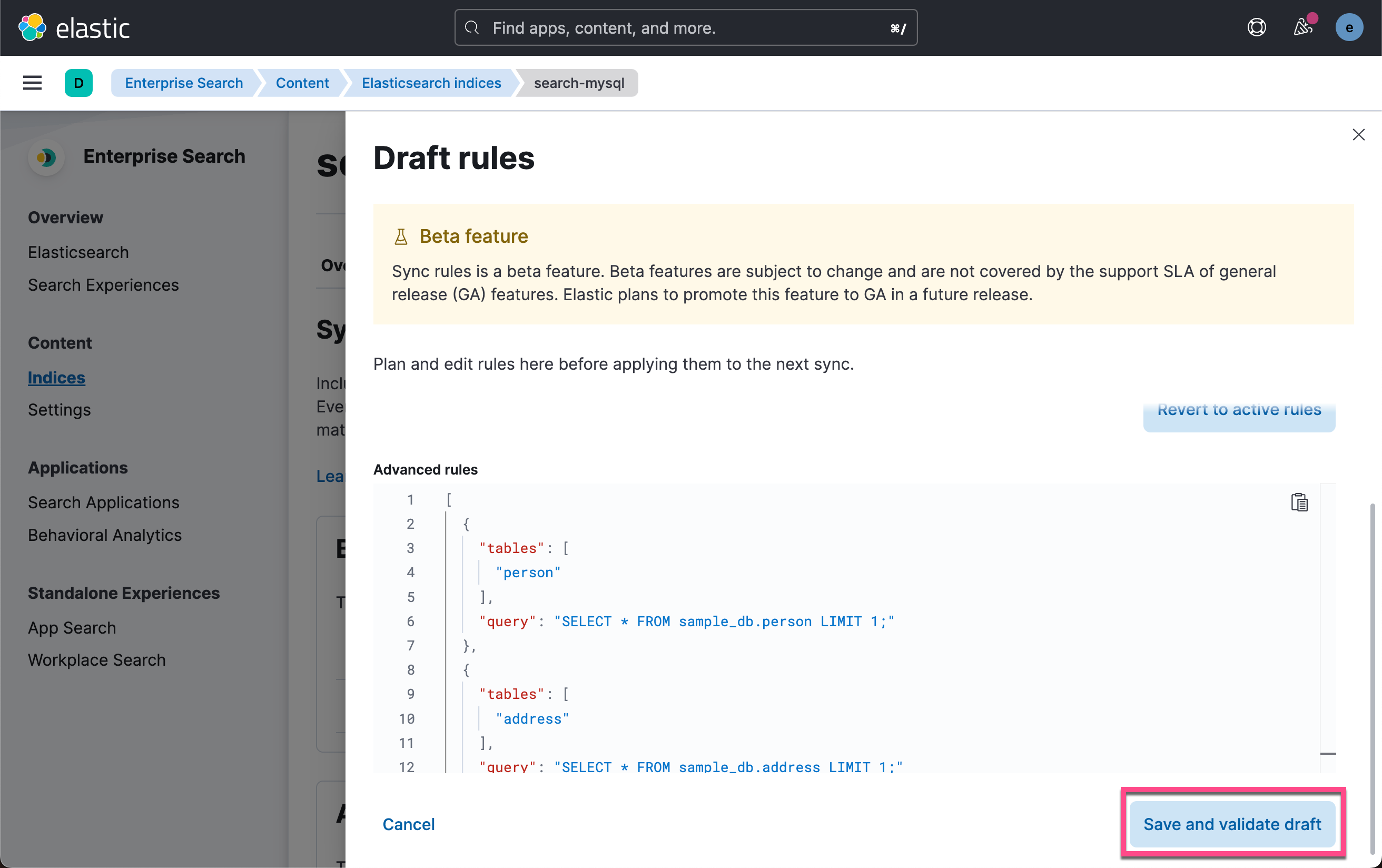
这样,当同步的时候,它只会同步 address 及 person 里的一条数据。

同样,我们可以定义如下的 WHERE query:
[
{
"tables": ["person"],
"query": "SELECT * FROM sample_db.person WHERE sample_db.person.age > 25;"
}
]它只会同步年龄大于 25 岁的 person 里的文档。
在 Kibana 中查看同步的过来的文档
我们可以通过如下的方法来查找索引:
GET _cat/indices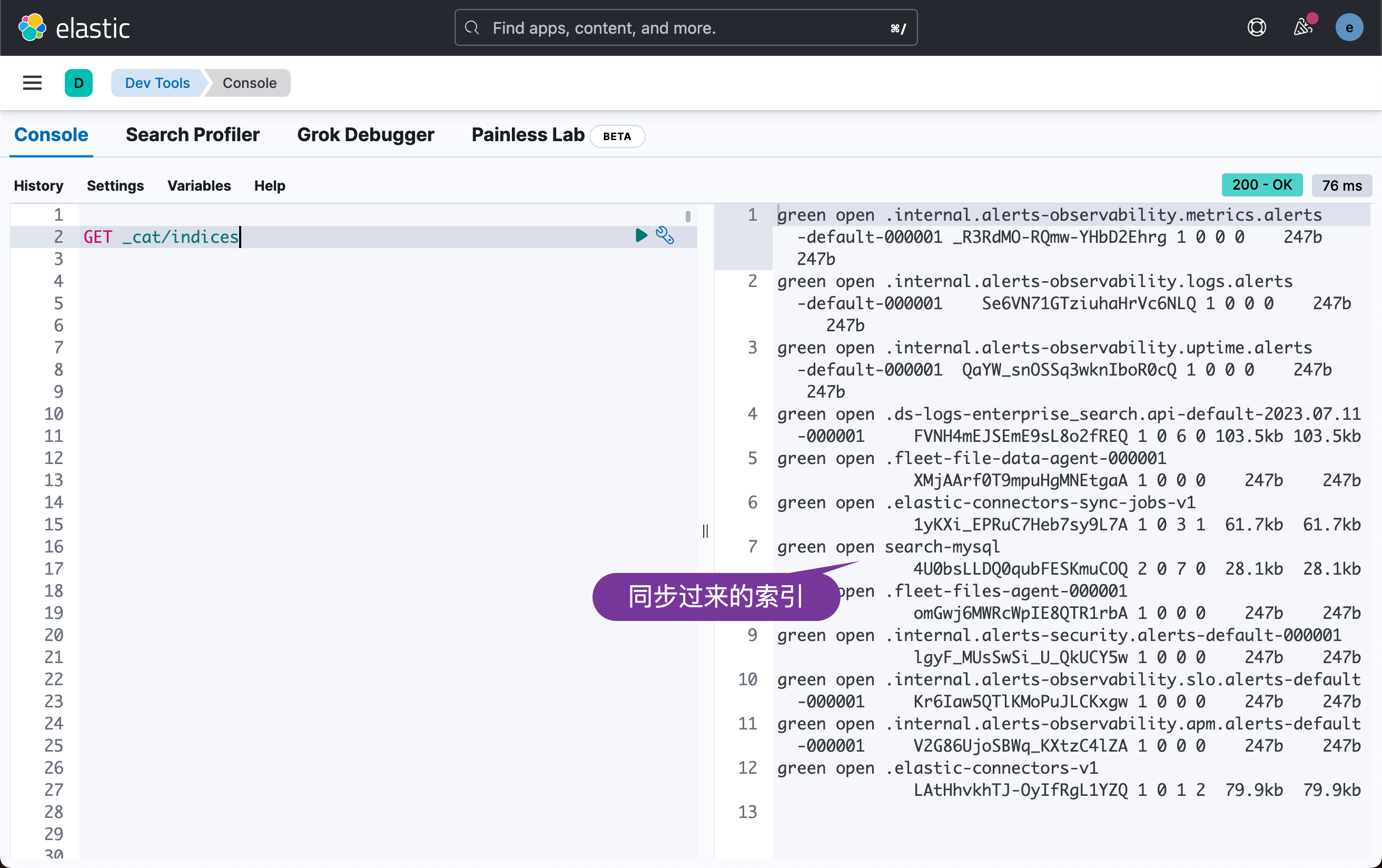
我们可以通过如下的命令来查看它的文档:
GET search-mysql/_search
使用 Docker 来安装 MySQL
在上面,我们使用本机来安装 MySQL。在实际的测试中,我们可以使用 Docker 更为方便地安装 MySQL:
docker run --name mysql_container -p 3306:3306 -e MYSQL_ROOT_PASSWORD=changeme -e MYSQL_USER=elastic -e MYSQL_PASSWORD=changeme -d mysql:latest授予用户权限:
docker exec -it mysql_container mysql -u root -pGRANT ALL PRIVILEGES ON sample_db.* TO 'elastic'@'%';
FLUSH PRIVILEGES;创建数据库及表格:
CREATE DATABASE sample_db;
USE sample_db;
CREATE TABLE person (
person_id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(255),
age INT
);
CREATE TABLE address (
address_id INT AUTO_INCREMENT PRIMARY KEY,
address VARCHAR(255)
);
INSERT INTO person (name, age) VALUES ('Alice', 30);
INSERT INTO person (name, age) VALUES ('Bob', 25);
INSERT INTO person (name, age) VALUES ('Carol', 35);
INSERT INTO address (address) VALUES ('123 Elm St');
INSERT INTO address (address) VALUES ('456 Oak St');
INSERT INTO address (address) VALUES ('789 Pine St');在配置的时候,我们可以参考如下的内容来进行配置:
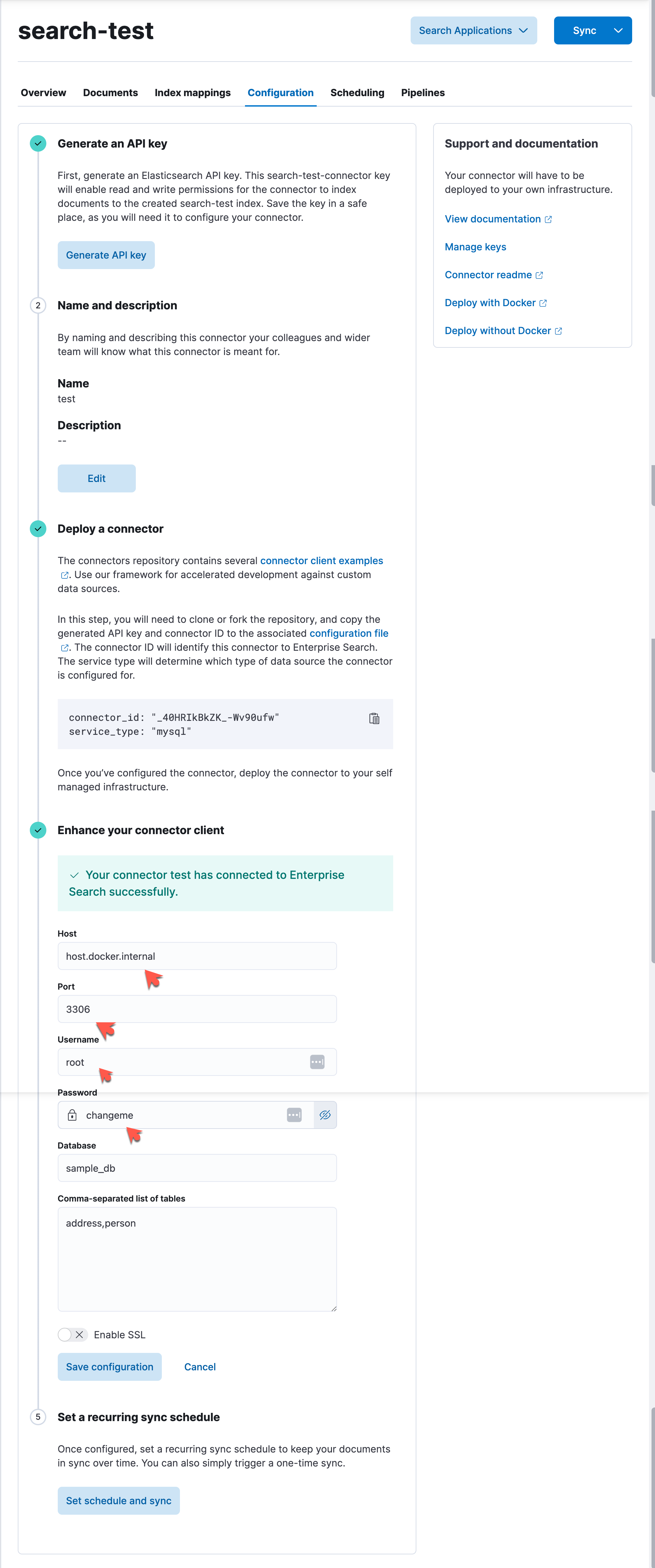
总结
在本文中,我们非常详细地描述如何使用 MySQL connector 来同步 MySQL 和 Elasticsearch 的索引。它使用起来非常方便。如果大家对 Logstash 很熟悉的话,请参阅我之前的文章 “Elastic:开发者上手指南” 中的 “数据库数据同步” 章节。我们还可以使用 Pipeline 对数据进行清洗。这个就不做展示了。