MySQL索引
当我们用数据库查询数据的时候,如果它只有很小的数据量时,可能查询不同数据的时候所消耗的时间并没有太大区别,但如果是一个有着几百万甚至几千万的数据库呢?此时你就会发现你查询一条数据的时间甚至要消耗十几秒,对于人来说可能这十几秒并不算什么,可是对于计算机来说这是坚决不被允许的,可是为什么会造成这样的情况呢?
当我们查询的使用的该字段没有索引的时候,它是会从第一条数据依次查询到最后一条,尽管它找到了唯一符合条件的数据的时候,它也会接着找到最后一条,会消耗大量的时间
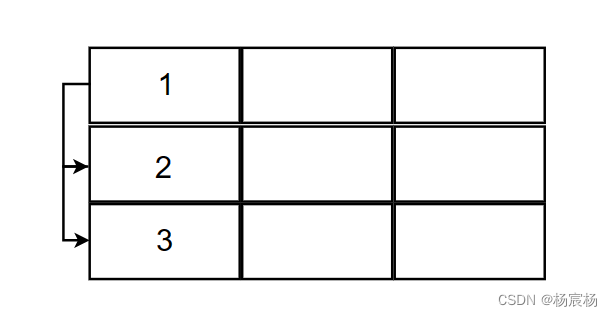
当你给某列加索引的时候,该列就会形成二叉树,将中间值作为该二叉树根节点,此后找寻数据,只需要根据大小进行比较就可以快速锁定数据位置
添加索引
添加唯一索引

添加普通索引

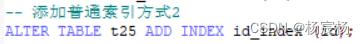
添加主键索引
方法一:

方法二:

如何选择
如果某列的值,是不会重复的,则优先考虑使用unique索引,否则使用普通索引
删除索引
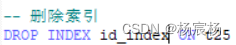
删除主键索引

查询索引
方式一:
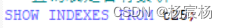
方式二:
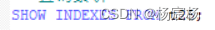
方式三:

哪些列上适合使用索引
1.较频繁的作为查询条件字段应该创建索引
2.唯一性太差的字段不适合单独创建索引,即使频繁的作为条件查询条件
3.更新非常频繁的字段不适合创建索引
4.不会出现在where子句中字段不该创建索引
MySQL事务
什么是事务?
事务用于保证数据的一致性,它由一组相关的dml(增 删 改)语句组成,该组的dml语句要么全部成功,要么全部失败回滚
将一个账号的钱转到另一个账户上
需求:
1.将转账账户减去100
2.将接收账户加上100
问题:第1条语句执行成功,但是第2条语句失败

提交事务(一旦提交之后不可以回退,会自动删除所有保存点,会确认事务的变化,结束事务、删除保存点、释放锁、数据生效,其它会话可以查看到事物变化后的新数据)其产生这种现象和隔离级别有关系

细节
1.如果不开始事务,默认情况下,dml操作是自动提交的,不能回滚
2.如果开始了一个事务,你没有创建保存点,你可以执行 rollback,默认就是回退到你事务开始的状态
3.可以在事务中(还没有提交的时候),创建多个保存点
4.可以在事务没有提交前,选择回退到哪个保存点
5.InnoDB存储引擎支持事务,MyISAM不支持
6.开启一个事务 start transaction,set autocommit=off
mysql事务隔离级别
多个连接开启各自事务操作事务来操作数据库中的数据时,数据库系统来负责隔离操作,从而以保证各个连接在获取数据时的准确性
否则会出现脏读、幻读、不可重复读
脏读:当一个数据读取到另一个事务未提交的修改
就好比两个人操作同一个账户,一个人存钱,一个人查询,刚存进去100还没有提交,可是查询的人已经查到了这个数据,但发生异常之后,存钱发生回滚,导致读取脏数据
不可重复读:同一查询在同一事务中多从进行,由于其他提交事务所做的修改或删除,每次返回不同的结果集
就好比你想知道你账户有多钱,当你读取之后,还没有提交,突然你妈妈存了400,并且提交了事务,再次读取后就没有读取到原来的结果了
幻读:同一次查询在事务中多次进行,由于其他提交事务所作的插入操作,每次返回不同放入结果集
