2022年数学建模美赛B题数据爬取
背景
2022年的美赛刚刚落下帷幕,该题的一个主要难点在于数据的获取。很多人无法找到有效的数据,或者是无法获取数据。
比如找到了如下米德湖的水文数据,但是发现并没有提供直接下载数据的功能
Lake Mead Water Database (water-data.com)
这种情况就需要实现一个简单爬虫去获取数据
准备
Python可以实现多种爬虫方法,如selenium,关于这种方法可以参照我之前的一个例子,但是这次获取的数据是表格数据,所以选择了非常简单好用的scrapy爬虫。
运行环境
- Python 3.7
- scrapy
- pandas
分析
首先需要对于网站进行分析,明确爬取的目标为每天的数据
注意到网站的网址后有个as_of=2022-1-1,此外显示的也是2022年1月1日的数据,说明网址后的as_of就是请求的具体日期
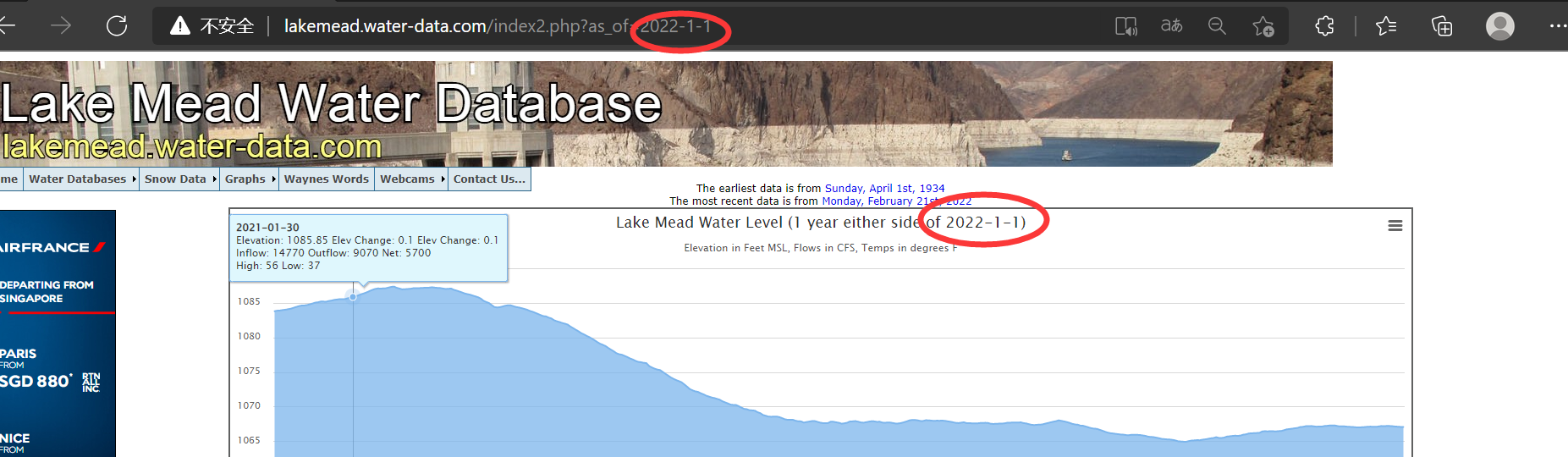
所以生成的url列表应该为20xx-x-x——20xx-x-x的形式
实现这种时间序列,我们一般使用pandas提供的库date_range
date=pd.date_range('1/1/2021','1/2/2022')
注意到此时的date类型为<class 'pandas.core.indexes.datetimes.DatetimeIndex'>
但是scrapy需求的url必须为list格式,所以还需要转化一下,随后使用append创建url列表
date_list = [x.strftime('%F') for x in date]
for d in date_list:
a.append("http://lakemead.water-data.com/index2.php?as_of="+d)
下一步就是分析网站元素,寻找元素的xpath表达式
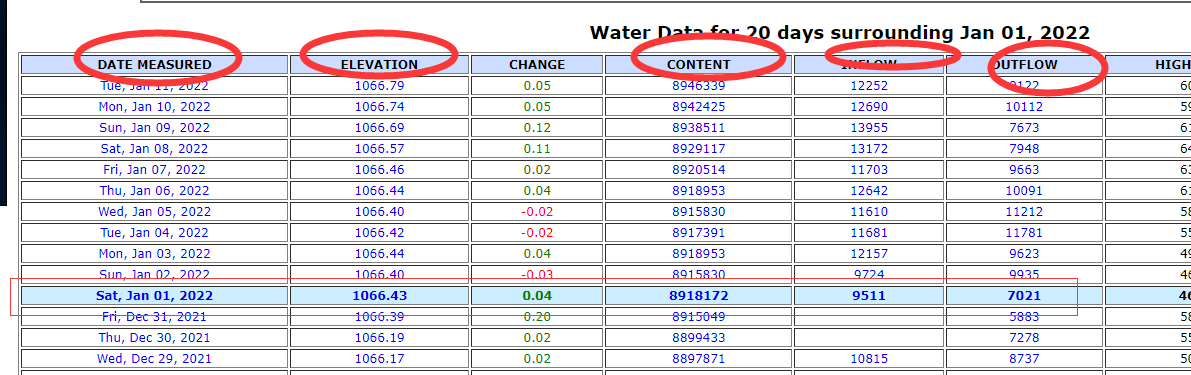
这个是爬虫的重点,我们想要爬取的数据是日期,水平面海拔,流入和流出,水量这五项,想要爬取的是每一天的数据
F12查看源码
首先确定这行数据的位置

一个很容易想到的思路是根据tr的位置来获取,该网页显示的都是前后十天的数据,那只要找到tr的序号似乎就可以了,但是有一种特殊情况需要考虑,当爬取的这天到现在的时间还不够十天时,原来的tr自然是不正确的位置,为了解决这个问题,有一种思路是判断天数,计算和当前日期的相差,不足十天的按照相差计算。
我这里采取的办法是寻找特异性
可以看到,显示的天数与其他行有个区别,即底色的不同,在源码这里可以看到,这里给了底色,但是其他天数是没有给出的

所以根据此即可构造爬虫,但是有时候会出现这种情况,在网页上使用xpath是可以定位的,但是爬取却是空值
例如
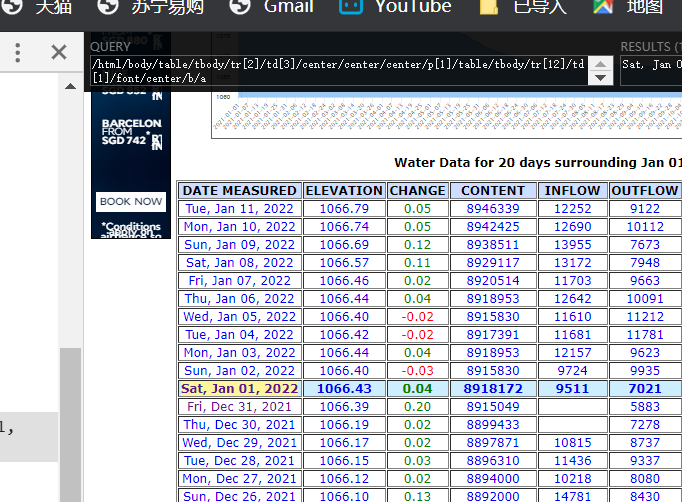
这个xpath可以试试,肯定爬取不到数据的,因为网页显示的内容和网页的源码并不相同,网页的显示,是经过了前端的渲染的,例如tbody这种标签是不可以识别的,所以我们写xpath路径的时候,一定要根据response的具体内容去写
写的时候可以将response的内容先保存下来看看
datas=response.xpath('//tr//td[@bgcolor="#cceeff"][5]').extract()
item=LakemeadItem()
print(datas[1])
open("test.html", 'wb').write(response.body)
然后再根据获取的信息写下级的xpath,或者右键查看网页源码
写好xpath语句后,设置请求头,items等即可正常运行
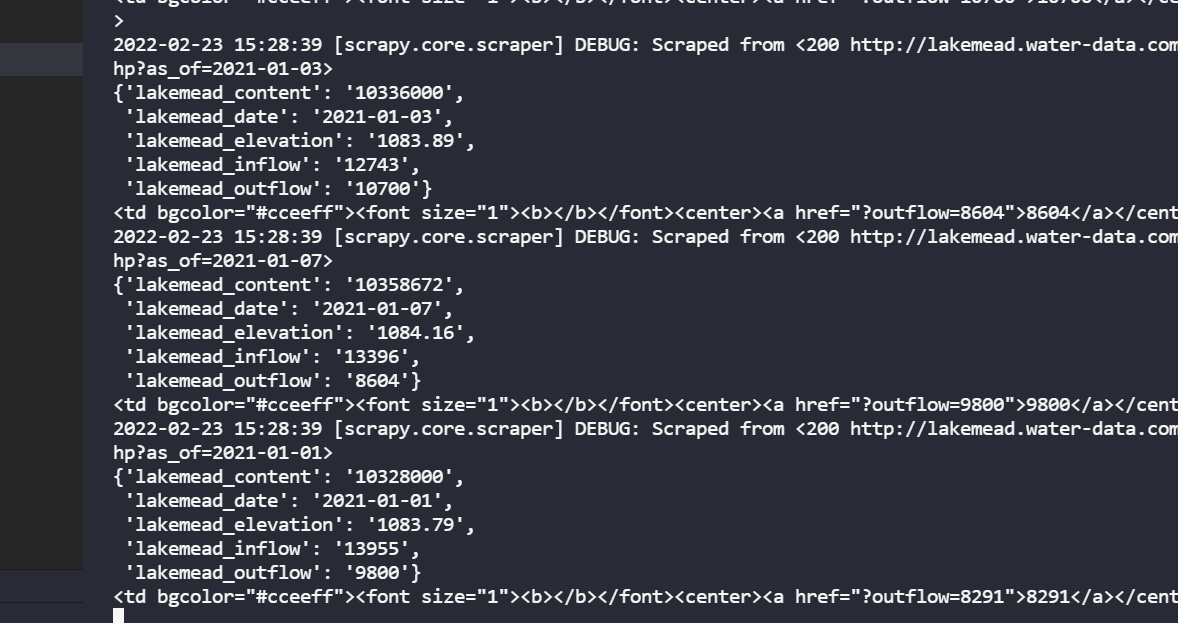
实现
完整代码如下
lakemead_scrapy.py
import scrapy
import sys
import pandas as pd
import datetime
sys.path.append('D:\MyStudy\junior_2\mcm\mySpider\lakemead\lakemead')
# sys.path.append('D:\MyStudy\junior_2\mcm\mySpider\mySpider\mySpider')
# import items
from items import LakemeadItem
a=[]
date=pd.date_range('1/1/2021','1/2/2022')
print(type(date))
date_list = [x.strftime('%F') for x in date]
# for x in date_list:
# print(x)
print(a)
for d in date_list:
a.append("http://lakemead.water-data.com/index2.php?as_of="+d)
class LakemeadScrapySpider(scrapy.Spider):
name = 'lakemead_scrapy'
allowed_domains = ['lakemead.water-data.com']
start_urls =a
def parse(self, response):
datas=response.xpath('//tr//td[@bgcolor="#cceeff"][5]').extract()
item=LakemeadItem()
print(datas[1])
open("test.html", 'wb').write(response.body)
# open("test.txt",'wb').writelines((datas.extract()))
date=response.xpath('//tr//td[@bgcolor="#cceeff"][1]//a/@href').extract()[0]
item['lakemead_date']=date[7: ]
item['lakemead_elevation']=response.xpath('//tr//td[@bgcolor="#cceeff"][2]//a//text()').extract()[0]
item['lakemead_content']=response.xpath('//tr//td[@bgcolor="#cceeff"][3]//a//text()').extract()[0]
item['lakemead_inflow']=response.xpath('//tr//td[@bgcolor="#cceeff"][5]//a//text()').extract()[0]
# item['lakemead_inflow']=""
item['lakemead_outflow']=response.xpath('//tr//td[@bgcolor="#cceeff"][5]//a//text()').extract()[1]
yield item
pass
if __name__ == '__main__':
from scrapy import cmdline
args="scrapy crawl lakemead_scrapy -o lakemead.csv".split()
cmdline.execute(args)
items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class LakemeadItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
lakemead_date = scrapy.Field()
lakemead_elevation=scrapy.Field()
lakemead_content =scrapy.Field()
lakemead_inflow=scrapy.Field()
lakemead_outflow=scrapy.Field()
# pass