目录
一、介绍
当读操作远远高于写操作时,这时候使用读写锁让读-读可以并发,提高性能
类似于数据库中的共享锁 select...from...lock in share mode
提供一个数据容器类内部分别使用读锁保护数据的read()方法,写锁保护数据的write()方法
两个线程读读不是互斥的,读写和写写是互斥的
注意事项:
- 读锁不支持条件变量
- 重入时升级不支持:持有读锁的情况获取写锁,会导致获取写锁永久等待,必须要先释放读锁才能获取写锁
- 重入时降级支持:持有写锁可以获取读锁
二、应用
我们更新缓存有两种操作
先删除缓存:我们在实现缓存和数据库的时候就要考虑这种问题,比如现在有a线程去查询数据库然后准备把数据库的数据更新到缓存的时候,b线程把数据库的时候就改了,这个时候如果更新成功缓存就和数据库已经改了的数据不一致的,然后后面就一直拿缓存中的旧数据。
先更新数据库:先更新数据库的话好一点,缓存数据库不一致的情况会少一些,但是要保证强一致性,还是要加锁。因为先改库还没来得及删除缓存的时候,这个时候去查询都是旧数据,不一致的
这里加锁是可以用读写锁来优化的
- 读锁:如果缓存中有数据,查询缓存,这里要记得释放读锁(因为如果缓存没有要查询需要写锁,持有读锁拿不了写锁)
- 写锁:缓存中没有数据,从数据库中查询,写入缓存(如果很多个线程去抢锁可能会进队列很多个,但是这个只需要一个,所以要加双重检查)
- 写锁:更新,先更新数据库然后删除缓存
这种优化主要体现在了读多写少的场景中读读可以共享的情况,但是如果还想更加提高并发,可以更细粒度划分。而且这种情况只适合单机场景
三、原理
读写锁用的是同一个sycn同步器因此等待队列、state等也是同一个
但是也有区别,他的state变了,因为要记录读锁和写锁两个锁的状态,高16位记录读锁,低16位记录写锁。其他流程都跟reentrantlock差不多
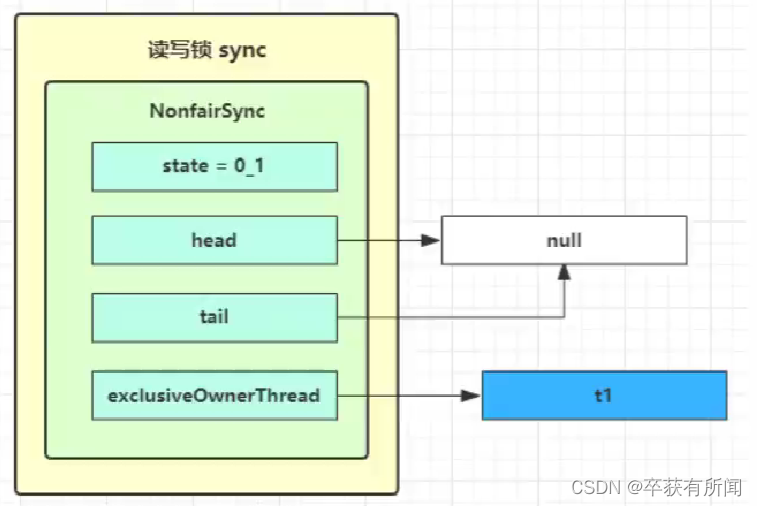
加写锁
加写锁和之前没有什么区别,先去检查state状态,如果状态等于0说明读和写锁都没有加,就再判断一个方法(非公平直接返回false,公平锁就去检查队列是否有,有就得排队进去,没有也返回),然后cas来加锁,成功就设置当前持锁线程到exclusiveOwnerThread。如果前面判断state不为0,那么可能读锁加了还是写锁加了,如果加了读锁,就互斥了直接return false,如果加的是写锁,看是不是自己加的,自己加的就是重入写锁状态+1,如果是别人的也return false,当然如果重入次数超过一定的次数65535也会抛出异常
加读锁
首先判断状态,然后看写锁的部分是不是0,如果不是0&&加写锁的是不是他自己,如果不是自己加的写锁,就返回-1(写锁是可以升级加读锁的,但是读锁不能加写锁)。如果为-1他就会再判断一遍能不能拿到读锁,还是不行就循环进入堵塞队列堵塞等待。
注意:
他们堵塞的线程虽然都在一个堵塞队列里,但是他们因为申请的锁不同他们的状态是不同的,等待读锁的是shared状态,等待写锁的是ex状态,然后前面的节点状态都是-1有责任区唤醒后面的节点,但是最后一个节点的状态是0,后面没他需要唤醒的
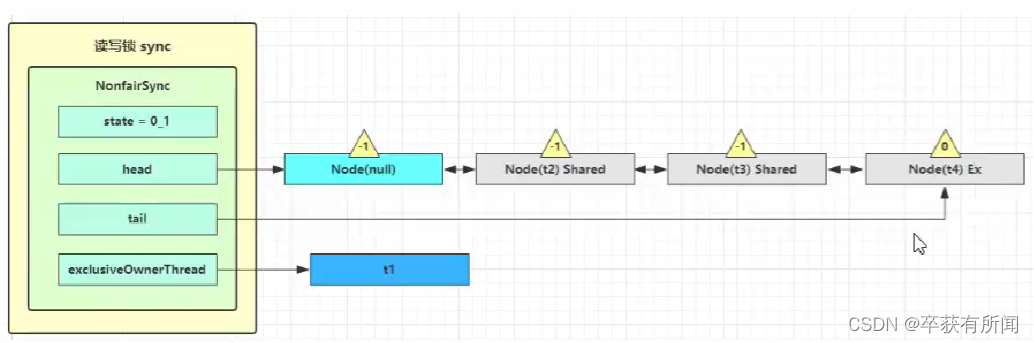
写锁释放
直接把状态数量-1,减一后查看是不是0,如果不是0就是锁重入减一了,返回false;如果减小后是0了,就返回true。返回真的话就把当前持锁线程设为null,然后就去检查堵塞队列的头节点,如果有气切状态不等于0,就唤醒他。唤醒了就继续循环去竞争锁,发现没人拿锁,就cas加写锁,高位加锁,然后return 1表示加锁成功了。然后就要取堵塞队列里面唤醒,如果是读锁,就唤醒。
换完阻塞队列的节点之后,拿到当前节点的下一个,如果下个节点是想要加读锁的shared,就把会当前节点的-1变为0,然后对后面的节点唤醒,然后让读锁的状态+1(多个线程都读锁可以让计数增加)然后把这个节点在堵塞队列删掉改为下一个,然后继续判断下一个是不是读节点,如果是重复。
读锁释放
拿到state状态,然后把读锁状态-1,然后用cas去设置state,看看能不能成功,成功后判断是不是0,如果是true,不是0就是false。如果是0就去看堵塞队列的头结点,如果头结点的状态是-1就唤醒那个节点,不是-1就重试。