使用背景:
在SQL中我们经常遇到一种需求:分组排序,分组求和等各种需求。像这样的需求,如果在Oracle、SQLserver、postgresql等数据库中很容易实现,一个开窗函数row_nubmer() over(partition by xxx,yyy order by zzz)就可以解决。
但是在MySQL8.0版本之前,是没有这样的开窗函数的。好在8.0之后的版本已经内置了开窗函数。不必自己写实现逻辑了。但是我们目前还有很多人在使用5.7版本。那么在5.7版本中,如何实现开窗函数的功能呢?
准备实验环境
准备建表语句
CREATE TABLE `emp` (
`id` int(11) NOT NULL,
`emp_name` varchar(255) DEFAULT NULL,
`dept_no` varchar(255) DEFAULT NULL,
`emp_salary` int(10) DEFAULT NULL,
`emp_hire_date` date DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
初始化数据
INSERT INTO `mysql_db`.`emp`(`id`, `emp_name`, `dept_no`, `emp_salary`, `emp_hire_date`) VALUES (1, '张三', '0001', 5000, '2017-01-11');
INSERT INTO `mysql_db`.`emp`(`id`, `emp_name`, `dept_no`, `emp_salary`, `emp_hire_date`) VALUES (2, '李四', '0002', 1000, '2018-10-10');
INSERT INTO `mysql_db`.`emp`(`id`, `emp_name`, `dept_no`, `emp_salary`, `emp_hire_date`) VALUES (3, '王五', '0003', 2000, '2018-12-19');
INSERT INTO `mysql_db`.`emp`(`id`, `emp_name`, `dept_no`, `emp_salary`, `emp_hire_date`) VALUES (4, '赵六', '0002', 4000, '2019-09-11');
INSERT INTO `mysql_db`.`emp`(`id`, `emp_name`, `dept_no`, `emp_salary`, `emp_hire_date`) VALUES (5, '王强强', '0001', 3000, '2019-03-14');
INSERT INTO `mysql_db`.`emp`(`id`, `emp_name`, `dept_no`, `emp_salary`, `emp_hire_date`) VALUES (6, '刘阳', '0002', 6000, '2019-08-08');
INSERT INTO `mysql_db`.`emp`(`id`, `emp_name`, `dept_no`, `emp_salary`, `emp_hire_date`) VALUES (7, '周心怡', '0003', 500, '2015-06-10');
INSERT INTO `mysql_db`.`emp`(`id`, `emp_name`, `dept_no`, `emp_salary`, `emp_hire_date`) VALUES (8, '毛志宇', '0004', 4500, '2016-09-20');
INSERT INTO `mysql_db`.`emp`(`id`, `emp_name`, `dept_no`, `emp_salary`, `emp_hire_date`) VALUES (9, '刘德仁', '0002', 3500, '2016-02-25');
INSERT INTO `mysql_db`.`emp`(`id`, `emp_name`, `dept_no`, `emp_salary`, `emp_hire_date`) VALUES (10, '范德武', '0001', 3000, '2020-02-12');
INSERT INTO `mysql_db`.`emp`(`id`, `emp_name`, `dept_no`, `emp_salary`, `emp_hire_date`) VALUES (11, '梅婷婷', '0005', 8000, '2013-07-07');
INSERT INTO `mysql_db`.`emp`(`id`, `emp_name`, `dept_no`, `emp_salary`, `emp_hire_date`) VALUES (12, '郑冰', '0005', 1000, '2014-11-17');
最后的环境如下:
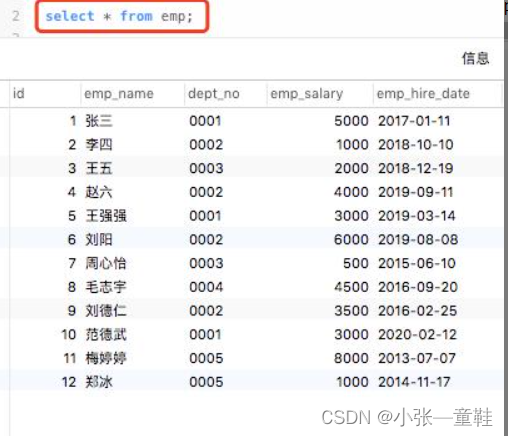
分组排序
需求描述:获取每一个部门薪水最高的员工的信息。
需求分析:
-
按照部门分组,每一部门的员工放在一组,然后基于这个组中的数据,按照工资降序排列。
-
然后再根据排序后的结果集,获取排序为1的数据行即为结果。
-
步骤1的SQL如下:
定义两个变量,
row_num_t用于存储每一个组中的排序结果。dept_no_t用于存储判断数据行是否是同一组。同事给他们分别初始化数据。然后再查询的字段当中,先判断一下当前是否和上一行的部门编号是同一个部门编号。如果是同一个部门编号,则将排序结果字段加1;如果不是同个部门编号,表示要切换为新的组了,这个时候,把排序结果字段重置为1。 -
select case when @dept_no_t != x.dept_no then @row_num_t := 1 else @row_num_t := @row_num_t + 1 end as sort_result, x.id, x.emp_name, -- x.dept_no, @dept_no_t := x.dept_no as dept_no, x.emp_salary, x.emp_hire_date from emp as x, (select @dept_no_t := '') as t1, (select @row_num_t := 0) as t2 order by dept_no, emp_salary desc; -
步骤1的示例结果如下:
-

-
步骤2的SQL语句如下:
-
在步骤1的SQL基础之上,在外出包裹一层查询,然后时候用where条件获取上面内层查询结果中排序为1的数据行。
-
select * from ( select case when @dept_no_t != x.dept_no then @row_num_t := 1 else @row_num_t := @row_num_t + 1 end as sort_result, x.id, x.emp_name, -- x.dept_no, @dept_no_t := x.dept_no as dept_no, x.emp_salary, x.emp_hire_date from emp as x, (select @dept_no_t := '') as t1, (select @row_num_t := 0) as t2 order by dept_no, emp_salary desc ) as y where y.sort_result = 1; -
步骤2的示例结果如下
-

分组求和
需求描述:累计统计每一个部门下所有员工的工资之和。
分析:按照部门分组,每一部门的员工放在一组,然后基于这个组中的数据,逐行累加该部门下所有员工的工资。
-
SQL如下:
定义一个用于存储最后每组员工工资之和的变量
emp_salary_sum_t,然后再每一行数据是否为同一组数据,如果是同一组数据,则将这行数据的工资,累加到工资之和的变量中;如果不是同一组数据,把当前行的工资赋值给每组工资之和的变量。 -
select case when @dept_no_t != x.dept_no then @row_num_t := 1 else @row_num_t := @row_num_t + 1 end as sort_result, case when @dept_no_t != x.dept_no then @emp_salary_sum_t := x.emp_salary when @dept_no_t = x.dept_no then @emp_salary_sum_t := @emp_salary_sum_t + x.emp_salary end as emp_salary_sum, x.id, x.emp_name, -- x.dept_no, @dept_no_t := x.dept_no as dept_no, x.emp_salary, x.emp_hire_date from emp as x, (select @dept_no_t := '') as t1, (select @row_num_t := 0) as t2, (select @emp_salary_sum_t := 0) as t3 order by dept_no, emp_salary desc; -
最后示例结果如下:
-

分组求最大值
需求描述:计算每个员工和部门中工资最高员工的工资差。
需求分析:
- 根据员工的部门分组,然后判断得到每组数据中,工资最高的员工的工资。把这个作为一个新列查询出出来。
- 基于步骤1的结果集中的新列,和员工的工资列做减法得到差值。
-
步骤1SQL语句如下:
select case when @dept_no_t != x.dept_no then @emp_salary_max_t := x.emp_salary when @dept_no_t = x.dept_no and x.emp_salary > @emp_salary_max_t then @emp_salary_max_t := x.emp_salary else @emp_salary_max_t end as emp_salary_max, x.id, x.emp_name, @dept_no_t := x.dept_no as dept_no, x.emp_salary, x.emp_hire_date from emp as x, (select @dept_no_t := '') as t1, (select @emp_salary_max_t := 0) as t4 order by dept_no, emp_salary desc -
步骤1实验结果如下:
-

-
步骤2SQL语句如下:
select y.emp_salary_max, y.emp_salary_max - y.emp_salary as cha, y.id, y.emp_name, y.dept_no, y.emp_salary, y.emp_hire_date from ( select case when @dept_no_t != x.dept_no then @emp_salary_max_t := x.emp_salary when @dept_no_t = x.dept_no and x.emp_salary > @emp_salary_max_t then @emp_salary_max_t := x.emp_salary else @emp_salary_max_t end as emp_salary_max, x.id, x.emp_name, @dept_no_t := x.dept_no as dept_no, x.emp_salary, x.emp_hire_date from emp as x, (select @dept_no_t := '') as t1, (select @emp_salary_max_t := 0) as t4 order by dept_no, emp_salary desc ) as y; -
步骤2实验结果如下:
-

以上就是MySQL5.7版本中,如何使用开窗函数的示例,希望能这篇文章能够帮到你。