感谢阅读
不完全原创声明
本人使用了多个第三方软件,并修改了一部分代码使得其可以在PC上训练,如有侵权请联系作者删除。
环境部署
下载工具包
安装人声背景音分离工具
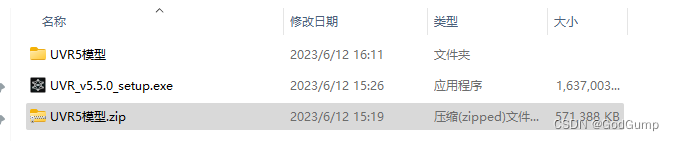
安装完后将模型文件解压,然后粘贴到安装目录的这里
如果提示替换,就替换不要怕
在同一个目录下新建3个文件,在第一个文件中放原唱歌曲,第二个文件夹放输出的歌曲,注意不要出现中文名并且不要改变格式,源文件是MP3目标文件就MP3
分离
按照下图的配置就行操作
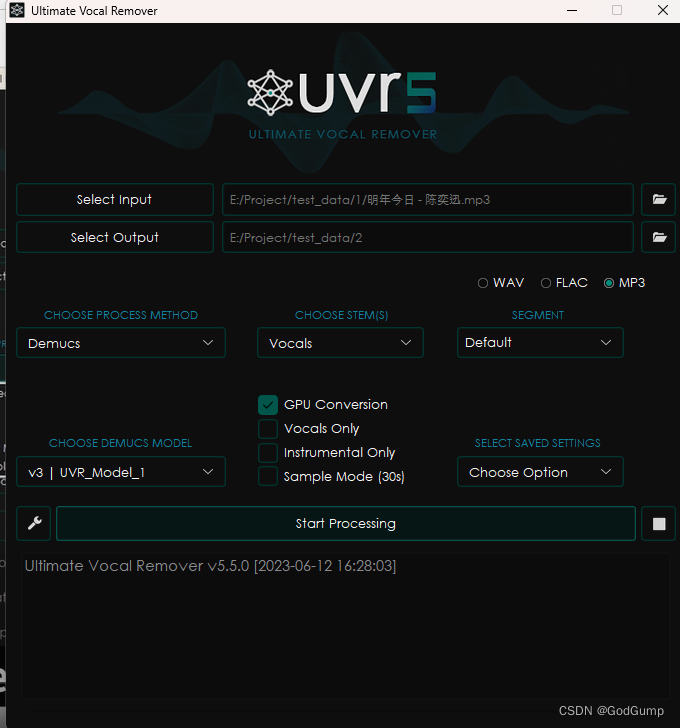
消除脏数据(比如杂音)
选择刚才分离出来的声音,按照以下方式配置

准备自己的声音
这个要求干净安静,而且时间越长越好,人工智能这种东西,数据决定了上限,算法本身只是起到辅助作用。这些音频文件要注意名字不要五花八门要统一。
然后将这些文件放在第三个文件夹,为了保证训练效果,每个时间段控制在15到20S,分割工具用audio sicer然后把目录放在dataraw目录下
预处理
点击svs程序的webui然后按照如图所示操作
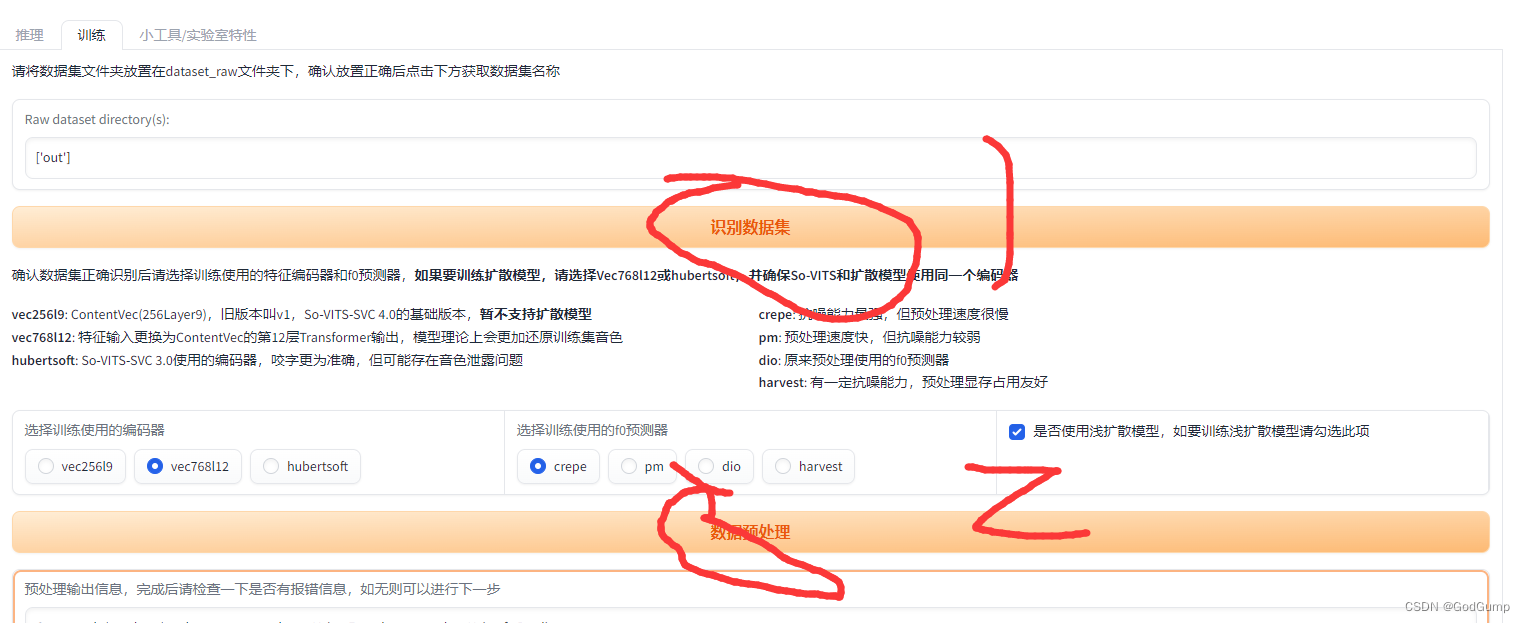
完工
然后依次点击写入配置、从头开始训练(训练时间长,可以ctrl+c中断,然后下次开启程序继续训练即可)
然后切换推理
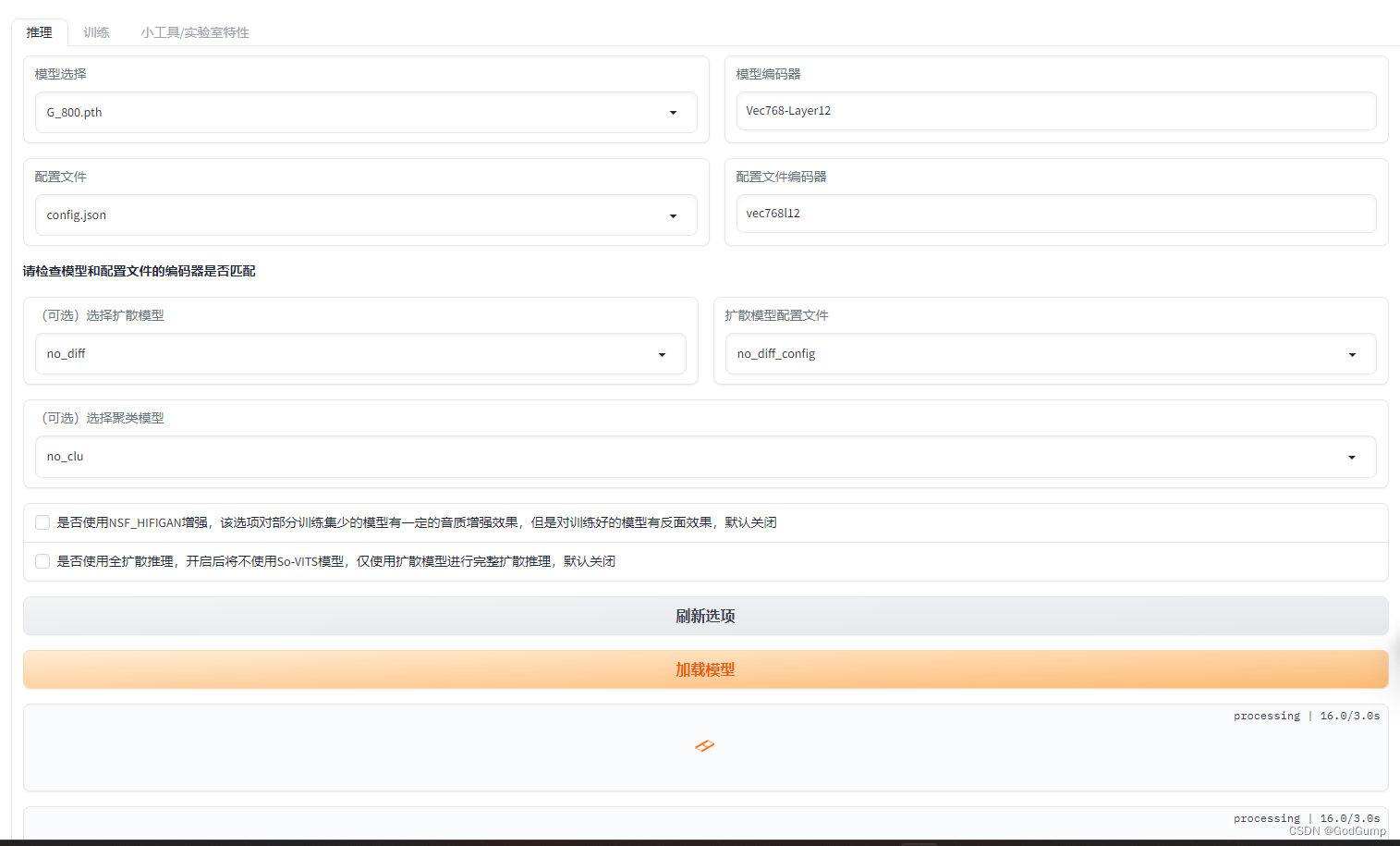
然后把声音文件下载下来
用Adobe Audition把伴奏加进去即可。
效果参考
因为只训练了800步,效果就那样(许嵩的声音,如有侵权请联系作者删除视频),有机器声勿喷,至少要1W步才会没有,我的960显卡真的做不了,至少要20显卡。
点我看效果