本文仅供学习参考!
Java是一种类型化语言,这本质上意味着声明的每个变量都有与之关联的特定类型。此类型确定它可以存储的值。例如,整数类型可以存储非小数。也称为数据类型,这可以大致分为两类:基元和引用。基元类型是最常见的,它们构成了类型声明的基础,引用类型是那些不是基元类型的类型。稍后将在本文中详细介绍这些引用类型;但首先,稍微绕道而行。
Java 中的静态和动态类型是什么?
如果在编译代码之前已知声明的变量的类型,则认为语言是静态类型的。对于某些语言,这通常意味着程序员在使用变量之前需要在代码中指定变量的类型(例如 - Java,C,C++)。其他人提供了一种类型推断形式,能够推断变量的类型(例如 – Kotlin,Scala,Haskell)。显式类型声明的优点是,在早期阶段可以快速捕获琐碎的错误。
另一方面,动态类型意味着程序员不需要声明任何类型的变量,只需开始使用它们即可。类型是根据它存储的值动态确定的。这是一种更快的编码方式,因为变量可以存储不同类型的值 - 例如,数字和字符串 - 而不必为它们的类型声明而烦恼(例如 - Perl,Ruby,Python,PHP,JavaScript)。类型是在旅途中决定的。大多数脚本语言都具有此功能,主要是因为在任何情况下都没有编译器来执行静态类型检查。但是,这使得查找错误有点困难,特别是如果它是一个大程序,尽管这种类型的脚本通常具有较小的代码,因此错误隐藏的地方较少。
有些语言(如流氓)采用两种方法(静态和动态)。有趣的是,Java 10引入了var关键字。声明为 var 的变量根据其存储的值自动检测其类型。但是,请注意,一旦分配了值,编译器就会在编译期间指定其类型。以后,它们不能与代码行中的另一种类型重用。下面是如何在 Java 中使用 var 关键字的示例:
var iVar = 12;
var dVar = 4.678;
var cVar = 'A';
var sVar = "Java";
var bVar = true;
Java 中的基元类型和引用类型有什么区别?
在 Java 中,由于所有非基元类型都是引用类型,因此将对象指定为类实例的类也被视为引用类型。为了进行比较,以下是基元类型相对于引用类型的典型特征:
- 它可以存储其声明类型的值。
- 分配另一个值时,将替换其初始值。
- 对于所有基元类型,其内存占用都有特定的限制。
- 默认情况下,它们是初始化的(值为 0 的数字,具有假值的布尔值)
- 它们可以在声明期间显式初始化(*int tot=10;*)
- 声明的本地基元类型变量永远不会初始化,因此在 Java 中不允许在初始化之前尝试使用它们。
引用类型的一些特征如下:
- 除基元之外的所有其他变量都是引用类型。
- 引用类型在计算机内存中存储对象的引用或位置。此类变量引用程序中的对象。
- 类的对象或具体实例是使用构造函数调用后面的 new 关键字创建的。构造函数是类的特殊成员函数,用于通过使用各自的默认值或作为构造函数参数接收的值初始化类中声明的所有变量来创建对象。
- 类实例是通过调用类构造函数创建的,可以有多个。
- 尽管无法实例化接口引用,但可以将扩展接口的类的实例分配给接口类型的引用。
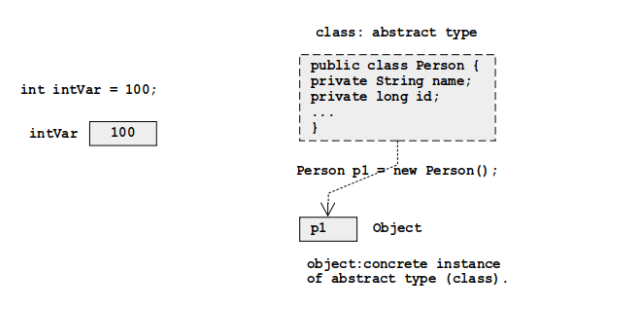
Java 中变量和引用类型的地址
与 C/C++ 不同,我们可以通过指针仔细查看变量的内存地址和引用,Java 在这里完全沉默。Java 语言中没有任何元素可以获取变量的地址。这就是为什么语言结构中没有地址或类似的运算符的原因;该语言从头开始设计为无需它即可工作。这完全关闭了 Java 中指针的大门。
但是,如果我们如此热衷于接近内存 - 或者更确切地说,接近Java中的内存抽象 - 请使用引用类型。引用类型实际上不是内存地址,但可以紧密转换为内存地址。无论如何,它们与指针具有相似的氛围,并且可以像任何其他变量一样对待它们。
Java 中的接口参考
在 Java 中,接口不能实例化。因此,不能直接引用它。但是,扩展接口的类类型的对象可用于分配该接口类型的引用。在下面的示例中,教授不仅派生自 Person 类,还派生自两个接口:教师和研究人员。
因此,根据该语句,以下层次结构是有效的:
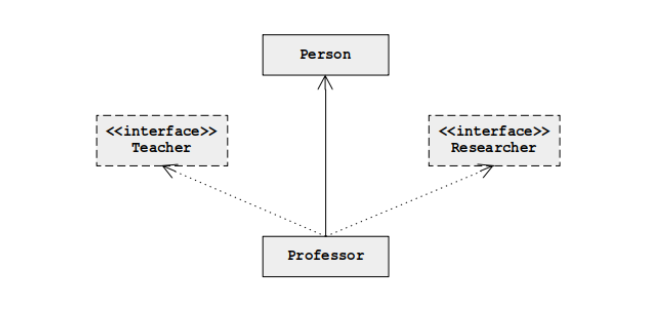
因此,以下 Java 代码示例可以很好地编译:
public class Main{
public static void main(String[] args){
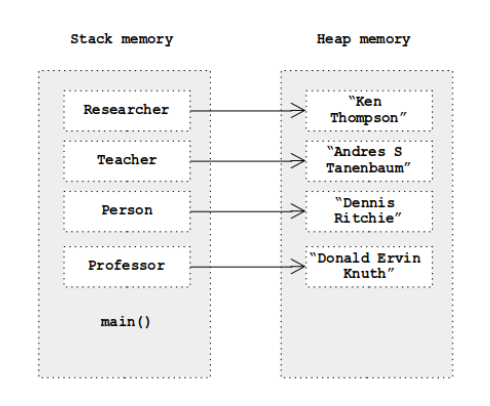
Professor professor = new Professor("112233", "Donald Ervin Knuth", Date.valueOf(LocalDate.of(1938,1,10)), 9.8f);
Person person = new Professor("223344", "Dennis Ritchie", Date.valueOf(LocalDate.of(1941,9,9)),9.7f);
Teacher teacher = new Professor("223344", "Andrew S Tanenbaum", Date.valueOf(LocalDate.of(1944,3,16)),9.6f);
Researcher researcher = new Professor("223344", "Ken Thompson", Date.valueOf(LocalDate.of(1943,2,4)),9.5f);
}
}
在这里,教授类型的四个对象被分配给不同的引用类型,这些类型还包括两个接口引用类型。假设引用类型的堆栈和堆内容如下所示:
以下参考也同样可行:
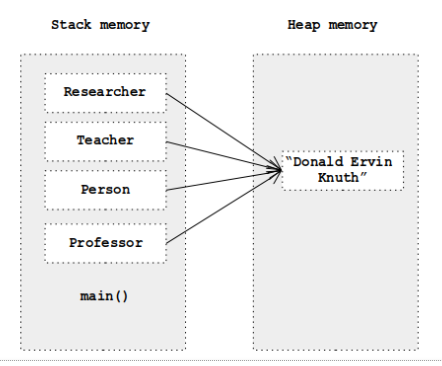
Professor professor = new Professor("112233", "Donald Ervin Knuth", Date.valueOf(LocalDate.of(1938,1,10)), 9.8f);
Person person = professor;
Teacher teacher = professor;
Researcher researcher = professor;
在这种情况下,堆栈和堆内存将如下所示,其中一个对象具有多个引用:
但是,请注意,引用必须是已分配对象的超类型。这意味着以下赋值无效(并且不会编译):
person = professor; //valid
professor = person; //invalid
这样做的原因是引用用于调用在类中声明的公共方法。因此,引用指向的对象必须能够访问这些方法。在这里,参考教授无法访问一个人的财产。结果,Java 编译器抱怨分配。一些智能代码编辑器和 IDE 也能够在编译之前识别无效性并标记消息并警告程序员。
但是,可以使用显式转换来说服编译器一切正常:
professor = (Professor)person; //valid
END
默认情况下,引用类型实例初始化为值 null。null 是 Java 中的保留关键字,这意味着引用类型指向内存中的任何内容。在 Java 中没有指针的一个方面是,在大多数情况下,引用类型几乎可以像对待任何其他变量一样处理。指针有一个奇怪的外观,许多程序员不喜欢这个原因(但有些人还是喜欢它)。放下程序员的手,仍然有一个指向内存中的对象的引用 - 你会得到Java引用类型。