写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
- 对于文章中出现的任何错误请大家批评指出,一定及时修改。
- 有任何想要讨论和学习的问题可联系我:[email protected]。
- 发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。
一个例子带你了解Spark运算流程
本文关键字:大数据、Spark、算子、WordCount
文章目录
一、前期准备
1. 运行环境
对于Spark来说,WordCount程序同样是经典的Hello World案例。Spark本身的部署十分简单,因为是基于内存进行计算的,所以只要简单配置一下运行环境、端口、要分配的资源大小以及工作节点即可,如需搭建可以参考:Spark 3.x各模式部署 - Ubuntu。
如果只是快速的测试程序可以不需要搭建Spark环境,只需要在项目中构建需要的依赖,以本地模式运行即可。在这种模式下,可以将本地文件作为input,output也可以直接输出到控制台。
2. 项目新建
- 首先在IDEA中新建一个Maven项目:
- 修改pom.xml,添加Spark相关的依赖:
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.3.2</version>
</dependency>
</dependencies>
3. 输入数据准备
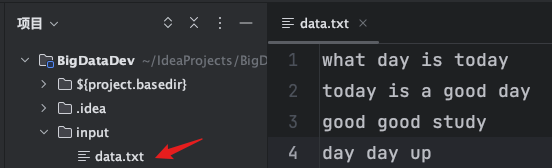
在项目下新建一个input文件夹,再新建一个data.txt文件,输入一些纯文本的单词作为样例数据:
二、从WordCount开始
程序的目标是计算出文本文件中每个单词各出现了多少次,目前先使用比较单一和简单的空格分隔符。
1. 完整程序实现
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
public class WordCount {
public static void main(String[] args) {
// 创建SparkConf对象,配置Spark运行参数,声明本地运行
SparkConf sparkConf = new SparkConf().setAppName("WordCount").setMaster("local[*]");
// 创建JavaSparkContext对象,是Spark应用的入口
JavaSparkContext context = new JavaSparkContext(sparkConf);
// 读取文件内容到JavaRDD,一个较为通用的分布式集合类型
JavaRDD<String> lines = context.textFile("input/data.txt");
System.err.println(lines.collect());
// 对每一行文本进行拆分,生成一个新的单词RDD
JavaRDD<String> words = lines.flatMap(
(FlatMapFunction<String, String>) line -> Arrays.asList(line.split(" ")).iterator());
System.err.println(words.collect());
// 将每个单词转换为(key, value)格式,生成新的JavaPairRDD
JavaPairRDD<String, Integer> wordOne = words.mapToPair(
(PairFunction<String, String, Integer>) word -> new Tuple2<>(word, 1));
System.err.println(wordOne.collect());
// 使用reduceByKey操作,计算每个单词的出现次数
JavaPairRDD<String, Integer> wordCounts = wordOne.reduceByKey(
(Function2<Integer, Integer, Integer>) Integer::sum);
System.err.println(wordCounts.collect());
// 使用collect操作,获取RDD中的所有元素
List<Tuple2<String, Integer>> output = wordCounts.collect();
// 在控制台打印出每个单词的出现次数
for (Tuple2<?, ?> tuple : output) {
System.err.println(tuple._1() + ": " + tuple._2());
}
// 关闭SparkContext,释放资源
context.stop();
}
}
2. 程序执行流程
- 从文件中读取数据
使用textFile方法时会逐行读取数据,构建出集合。
// 读取文件内容到JavaRDD,一个较为通用的分布式集合类型
JavaRDD<String> lines = context.textFile("input/data.txt");
System.err.println(lines.collect());
运行结果:【what day is today, today is a good day, good good study, day day up】
- 将文本拆分为单词
使用FlatMapFunction定义对每个集合元素的处理规则,泛型部分代表了输入和输出类型,处理完成后flatMap会将产生的列表连接到一起,形成一个新的列表,即不会出现嵌套结构。
flatMap前:【(what, day, is, today), (today, is, a, good, day)】。
flatMap后:【what, day, is, today, today, is, a, good, day】
// 对每一行文本进行拆分,生成一个新的单词RDD
JavaRDD<String> words = lines.flatMap(
(FlatMapFunction<String, String>) line -> Arrays.asList(line.split(" ")).iterator());
System.err.println(words.collect());
运行结果:【what, day, is, today, today, is, a, good, day, good, good, study, day, day, up】
- 对出现的单词标记
对得到的每个单词如何处理取决于我们的需求,由于现在要进行单词计数,所以按照MapReduce的思想先构建出Map结构,然后在Reduce阶段来实现计算逻辑。
在Java中需要使用JavaPairRDD,元素的结构都是键值对,因此额外提供了reduceByKey等方法,首先通过mapToPair进行一个类型转换,因此输入类型为String,输出类型为String,Integer。
// 将每个单词转换为(key, value)格式,生成新的JavaPairRDD
JavaPairRDD<String, Integer> wordOne = words.mapToPair(
(PairFunction<String, String, Integer>) word -> new Tuple2<>(word, 1));
System.err.println(wordOne.collect());
运行结果:【(what,1), (day,1), (is,1), (today,1), (today,1), (is,1), (a,1), (good,1), (day,1), (good,1), (good,1), (study,1), (day,1), (day,1), (up,1)】
- 执行按词累加计算
现在我们需要传入两个参数执行一个相加的逻辑Integer::sum,等价于(a,b) -> a + b,因此使用Function2,代表传入两个参数返回一个结果。
// 使用reduceByKey操作,计算每个单词的出现次数
JavaPairRDD<String, Integer> wordCounts = wordOne.reduceByKey(
(Function2<Integer, Integer, Integer>) Integer::sum);
System.err.println(wordCounts.collect());
运行结果:【(is,2), (day,4), (what,1), (up,1), (a,1), (today,2), (good,3), (study,1)】
3. 计算机制介绍
Spark的运算机制非常值得深入学习,这里只借助简单例子稍微的扩展一下。Spark的所有基于RDD的方法调用都可以看作一个个算子【小编习惯性的程序】,因为Spark是基于Scala开发的,当我们使用Scala语言进行程序开发时更能深刻到这一点。也就是我们基本上从一个集合开始,用一连串的方法调用就可以得到最终想要的结果,这也与Spark的延迟计算机制有关。
- 转换算子:Transformation
在Spark中,转换算子用于从一个数据集创建一个新的数据集。例如,map、filter和reduceByKey等操作都是转换算子。转换算子的结果是一个新的RDD,它通常是通过对输入RDD应用某种函数得到的。需要注意的是,转换操作是惰性的(lazy),也就是说,它们并不会立即计算结果,而是在行动操作调用时才真正执行。
- 行动算子:Action
行动算子是那些触发实际计算的操作。例如,count、collect、first、take等操作都是行动算子。当一个行动操作被调用时,Spark就会执行计算,并返回一个具体的值。
- 延迟计算:Lazy Evaluation
Spark使用延迟计算模型,也就是说,当转换操作被调用时,它们并不会立即执行,而是记录下这些操作。只有当一个行动操作被调用时,这些转换操作才会真正执行。这使得Spark可以优化整个计算过程,例如,通过合并多个转换操作,减少数据的读写等。
- 分布式计算:Distributed Evaluation
Spark通过分布式计算实现高效的大数据处理。数据被分割成多个分区(partition),每个分区可以在集群中的一个节点上单独处理。通过这种方式,Spark可以在多个节点上并行处理大量数据。另外,Spark还提供了弹性调度和容错机制,使其能够在节点失败时继续运行,并根据负载情况动态调整资源使用。
扫描下方二维码,加入CSDN官方粉丝微信群,可以与我直接交流,还有更多福利哦~
