前言
上一个博客里已经给出了mediapipe的环境配置,这个博客将分享一下基于mediapipe的人体图片关键点检测以及在三维中的场景
关键点检测实现
编译平台:jupyter notebook
代码如下
导入库,%matplotlib命令可以将matplotlib的图表直接嵌入到Notebook之中,model_complexity可以不设置,不设置时默认为1
import cv2
import mediapipe as mp
import matplotlib.pyplot as plt
%matplotlib inline
#定义查看图片函数
def look_img(img):
img_RGB=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
plt.imshow(img_RGB)
plt.show()
#导入模型
mp_pose=mp.solutions.pose
mp_drawing=mp.solutions.drawing_utils
pose=mp_pose.Pose(static_image_mode=True,#选择静态图片还是连续视频帧
model_complexity=2,#选择人体姿态关键点检测模型,0性能差但快,2性能好但慢,1介于之间
smooth_landmarks=True,#是否选择平滑关键点
min_detection_confidence=0.5,#置信度阈值
min_tracking_confidence=0.5)#追踪阈值
#
使用OpenCV中的cv2.imread()读入图像,在读入图像时不能使用单斜杠\,要使用双斜杠\\或者/。
img=cv2.imread('C:\\Users\\123\\Desktop\\2022-6-28.jpg')
#查看读入的图像
look_img(img)
图像输入模型,获取预测结果
#BGR转RGB
img_RGB=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
#输入模型,获取预测结果
results=pose.process(img_RGB)
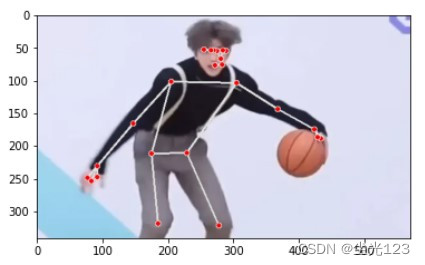
可视化检测结果
mp_drawing.draw_landmarks(img,results.pose_landmarks,mp_pose.POSE_CONNECTIONS)
look_img(img)
检测出的关键点结果如下图
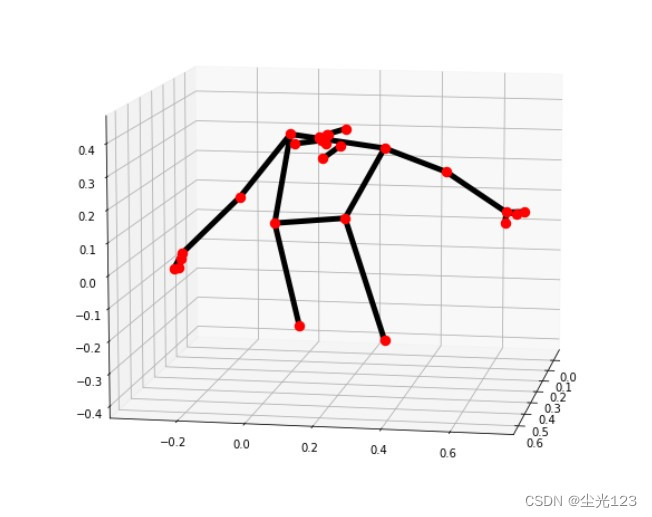
在三维场景中可视化
mp_drawing.plot_landmarks(results.pose_world_landmarks,mp_pose.POSE_CONNECTIONS)
效果如下图所示