论文:Object detection at 200 Frames Per Second
论文链接:https://arxiv.org/abs/1805.06361
一开始是被这篇文章的名称所吸引,毕竟object detection算法能达到200FPS的确实很少见,读完这篇文章后发现这篇文章确实有很多细节优化非常有意思,值得借鉴,特来分享。主要的优化点包括:特征融合、网络结构改进、引入network distillation、引入FM-NMS等。
首先来看看算法在效果和速度上的整体情况,如Figure1所示,还是比较亮眼的。

特征融合(dense feature map with stacking)
特征融合已经是公认的可以提高算法效果的方法(比如SSD和DenseNet都利用了这个思想),因此这篇文章也采用了这个策略。有个细节是在融合过程中,并不是对大size的feature map做max pooling然后与小size的feature map做融合,而是采用将大size的feature map进行resize然后和小size的feature map融合的方式。论文中提到SSD算法中对不同维度的特征融合是采用max pooling,但是据我所知SSD是直接对不同size的feature map做reshape,然后concate,所以这一点描述有点疑惑。
网络更深而且更窄(deep but narrow)
首先,网络越深且越宽一般而言效果也会越好,但同时计算量和参数量也会随之增加,这样就导致算法速度变慢,因此需要做一个平衡。这篇文章的baseline算法是Tiny-Yolo,Tiny-Yolo是Yolo v2的加速版。
首先是更窄:在Tiny-Yolo算法中,最后的几个卷积层都比较宽(比如卷积核数量是1024),在前面引入特征融合后就不大需要这么多的卷积核了,于是作者对这些层的卷积核数量做了缩减,也就是达到了narrow。如图Figure2最后一个3*3卷积层的卷积核数量只有125个,倒数第5个3*3卷积层的卷积核数量只有512个(该卷积层原来是Yolo算法的最后某个卷积层,原卷积核数量是1024个)。
其次是更深:怎样才能增加网络的深度,同时又避免引入过多的计算量?作者的想法是采用叠加一系列1*1卷积的方式,因为1*1卷积的计算量要远远小于3*3卷积。如图Figure2最后3个1*1卷积层。
Figure2的网络作者取名叫F-Yolo,不得不说这两个设计细节还是比较有意思的。

蒸馏损失函数(distillation loss for training)
首先,什么是网络蒸馏(network distillation)呢?原文的这段表述非常到位:The idea of the network distillation is to train a light-weight (student) network using knowledge of a large accurate network (teacher). The knowledge is transferred in form of soft labels of the teacher network. 换句话说就是用一个复杂网络(teacher network)学到的东西去辅助训练一个简单网络(student network)。文章中也给出了network distillation的示意图(Figure3)。network distillation算法是模型加速压缩领域的一个分支,作者在这篇文章中引入network distillation的目的也是为了提升小网络的效果。

但是直接在Yolo算法中引入distillation loss会有一些问题,因为目前的network distillation算法主要是针对RCNN系列的object detection算法(或者叫two stage系列)。对于two stage的object detection算法而言,其最后送给检测网络的ROI数量是很少的(默认是128个),而且大部分都是包含object的bbox,因此针对这些bbox引入distillation loss不会有太大问题。但是对于Yolo这类one stage算法而言,假设feature map大小是13*13,每个grid cell预测5个bbox,那么一共就会生成13*13*5=845个bbox,而且大部分都是背景(background)。如果将大量的背景区域传递给student network,就会导致网络不断去回归这些背景区域的坐标以及对这些背景区域做分类,这样训练起来模型很难收敛。因此,作者利用Yolo网络输出的objectness对distillation loss做一定限定,换句话说,只有teacher network的输出objectness较高的bbox才会对student network的最终损失函数产生贡献,这就是objectness scaled distillation。
因此先来看看原来Yolo算法的损失函数,包含3个部分(公式1):1、objectness loss,表示一个bbox是否包含object的损失;2、classification loss,表示一个bbox的分类损失;3、regression loss,表示一个bbox的坐标回归损失。

那么针对这三个部分该如何引入objectness scaled distillation?
objectness loss部分并不采用objectness scaling。首先公式主要由两部分组成,第一部分是detection loss,这和Yolo算法中的objectness loss一致;第二部分是distillation loss,这部分和第一部分最大的差别在于输入之一不是ground truth,而是oiT,也就是teacher network的objectness输出(参考Figure3)。λD是用来平衡两个loss,文中默认采用1。

classification loss部分采用objectness scaling。该公式也是由两部分组成,可以看出最大的不同点在于第二部分多了oi^T,这是teacher network的objectness输出,表示每个bbox包含object的概率,因此如果一个bbox是background,那么该概率值会很低,那么distillation loss就基本上没有,这样就防止student network去误学习这些background信息。

regression loss部分采用objectness scaling,和公式3类似。

因此最后的损失函数如下:

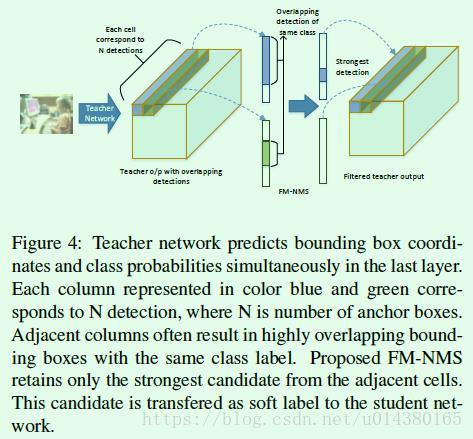
基于特征的NMS算法(feature map NMS或者简写成FM-NMS)
NMS是object detection算法中常用的后处理算法,用来去除重复预测框,传统的NMS算法和网络结构的训练是独立的。如果不做NMS,直接将teacher network的预测框输出给student network,则会导致student network接收到的object相关的loss会非常大,这样训练几轮以后就会对这些object过拟合了。因此这里采取了类似NMS算法的feature map NMS进行重复框进行去除。
首先在Yolo算法中,最后的输出层中每个grid cell的维度是1*1*(N*(K + 5)),也就是图中的蓝色或绿色三维矩形条,矩形条的长度就是N*(K + 5),其中N表示bbox的数量,K表示分类的类别数,5表示4个坐标值和1个objectness score。grid cell的数量就是输出层的feature map的宽高乘积。FM-NMS算法的假设是假如几个相邻的grid cell所预测bbox的类别一样,那么这些bbox极有可能预测的是同一个object。基于这样的假设或者说是观察到的现象,FM-NMS算法的做法是:每次取3*3个相邻的grid cell,对这9个grid cell中预测类别相同的bbox的得分(objectness value)进行排序,最后只选择得分最高的那个bbox传给后续的student network。Figure4是对2个grid cell做FM-NMS的示意图。
实验结果:
首先是关于特征融合的效果对比,如Table1所示,可以看出随着融合的层数增加,效果也越来越好。另外一点是高层特征的融合效果要优于低层特征。前面提到过作者不采用max pooling的方式对不同维度的feature map做融合,而是采用对feature map做resize然后融合,在Table1中也对比了二者的效果。

其次是更深且更窄的网络在速度上的对比。可以看出特征融合后的速度是184FPS,将最后某个3*3卷积层的卷积核数量从1024降到512就可以将速度提到234FPS,最后增加几个1*1卷积层速度也只降到221FPS,可以看出这种又深又窄的网络设计在速度上做的还是很到位的。

最后是关于引入network distillation和FM-NMS的效果对比。可以看出如果在引入network distillation的时候没有采用FM-NMS对teacher network的预测框输出做处理,效果下降是比较明显的(平均下来降2到3个点)。另外,数据集从VOC到VOC+COCO,baseline的效果提升比较明显,说明增加数据的有效性。
