这是一篇清华的团队发表于2020年四月CHI上面的论文,题为Enabling On-Face Interaction via Wireless Earbuds,也就是通过无线耳机实现的在脸部的交互,研究人员提出了Ear Buddy这种实时系统,利用商用无线耳机中的麦克风来检测脸部和耳朵附近的敲击和滑动手势。
这篇论文整体上来说,一共进行了三项研究,开发者建立了一个全面的设计空间,在人的脸部和耳朵的侧面设计了27个手势,由于用户无法真实地记住所有27个手势并且有的手势不容易被耳塞式麦克风检测到,因此开发人员进行了一项用户研究,针对用户偏好和麦克风的可检测性将设计的手势集缩小到8个手势。在第二次用户研究中,研究人员在安静的环境和有背景噪音的环境中收集包含这些手势的完整数据集,用这些数据来训练一个浅层神经网络二元分类器来检测手势,并使用了一个深度DenseNet来对手势进行分类。最后使用这些模型构建EarBuddy的实时实现,并进行第三次用户研究以评估EarBuddy的可用性。
1.系统设计EarBuddy
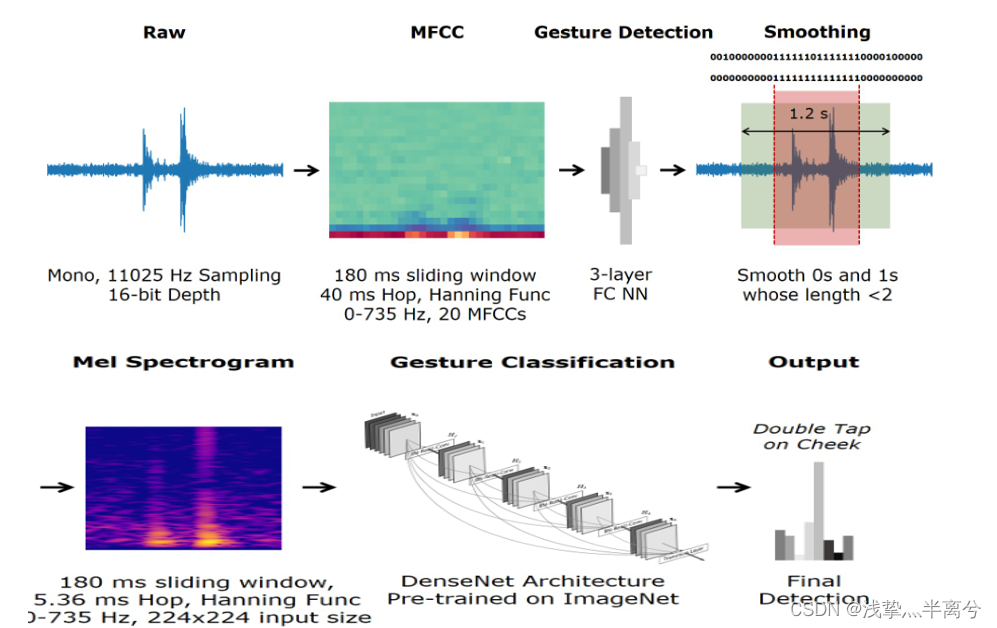
分两步识别⼿势。首先,⼿势检测器判断是否存在⼿势。如果检测到⼿势,则
分类器识别该⼿势。图 2 说明了系统的整体管道。
检测⼿势
检测使用 180 ms 滑动窗口开始,步⻓为 40 ms。在每⼀步从窗口中提取 20 个 MFCC,并输⼊到⼆元神经网络分类器。只要存在属于⼿势的音频内容,分类器就会输出 1,否则输出 0。
(FCNN网络,顾名思义,就是神经网络全部由卷积层构成。与经典CNN网络的区别在于,它将CNN网络中的全连接层全部用卷积层替换。
FCNN网络可以对图像进行像素级的分类,从而解决了语义级别的图像分割问题。FCNN网络可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样,使它恢复到与输入图像想通的尺寸,从而可以对每个像素都产生了一个预测,同时保留了原始输入图像的空间信息,最后在上采样的特征图上进行逐像素分类。)
(在语音识别和说话者识别方面,最常用到的语音特征就是梅尔倒谱系数(简称MFCC)。
将MFCC提取过程包括预处理、快速傅里叶变换、梅尔滤波器组、对数运算、离散余弦变换、动态特征提取等步骤。
预处理:对音频信号进行分帧加窗,因为音频信号本身是非平稳信号,主要是由于发声器官的运动不可预测带来的短时变,因此不能直接进行信号处理和分析。但发声器官的状态变化速度较声音振动的速度要缓慢的多,因此为了获得一段平稳的信号,就可以采取分帧的处理方法。假设在很短的时间内,信号是平稳的,通常取值在20-40ms之间作为一帧。
傅里叶变换:将信号从时域变换到频域的变换形式
梅尔滤波器组:将能量谱通过一组Mel尺度的三角形滤波器组
(1)三角形是低频密、高频疏的,这可以模仿人耳在低频处分辨率高的特性;
(2)对频谱进行平滑化,并消除谐波的作用,突显原先语音的共振峰;
(3)傅里叶变换得到的序列很长,把它变换成每个三角形下的能量,可以减少数据量;
对数运算:对数运算包括取绝对值和log运算。取绝对值是仅使用幅度值,忽略相位的影响,因为相位信息在语音识别中作用不大。
log运算是因为人的感知与频率的对数成正比,正好使用log模拟。
离散余弦变换:对每个滤波器的点的信号进行离散余弦变换,可以把基音信息和声道信息分离出来,由此可以获得12维的MFCC特征。
动态特征提取:标准的倒谱参数MFCC只反映了语音参数的静态特性,语音的动态特性可以用这些静态特征的差分谱来描述,比如MFCC随时间的轨迹,实际证明把MFCC的轨迹变化加入后会提高识别的效果。因此我们可以用当前帧前后几帧的信息来计算一阶和二阶差分,同时对帧的能量也进行一阶和二阶差分,这样最终可以得到39维的MFCC特征向量。
⼏乎所有⼿势都需要超过三个单步(> 120 ms),因此⼿势的存在应该导致分类器连续产生多个 1;然而,数据和噪声的时间变化会使分类器的串⾏输出噪声。 EarBuddy 通过使用多数投票⽅案解决了这个问题,如果相邻的连续 1 序列被⼀个或两个 0 分隔,它们将被合并。手势被定义为只要有 3 个或更多连续的 1 就存在,对应于 120 毫秒的最小手势持续时间。每当⼀个⼿势发生时,EarBuddy 都会获取以1 序列为中⼼的 1.2 秒原始音频片段(覆盖 99% 以上的⼿势) ,并将其输⼊⼿势分类器。
使用梅尔谱图处理音频数据以进⾏分类,梅尔谱图是通过应用具有 180 毫秒窗口和 5.36 毫秒步⻓的短时傅里叶变换生成的,从而产生⼀个 224 ⻓度的线性谱图,该谱图可以转换为 224 位梅尔谱图。当 EarBuddy 将音频信号转换为梅尔频谱图时,⼀维音频信号被转换为⼆维图像格式。
梅尔谱图:频谱图基于梅尔刻度得到的图,频谱表示了信号在不同频率上的分布,然通过实际的主观实验,科学家发现人耳对低频信号的区别更加敏感,而对高频信号的区别则不那么敏感。也就是说低频段上的两个频度和高频段上的两个频度,人们会更容易区分前者。因此频域上相等距离的两对频度,对于人耳来说他们的距离不一定相等。
因此就想到通过调整频域的刻度,使得这个新的刻度上相等距离的两对频度,对于人耳来说也相等,这也就是所谓的梅尔刻度。
梅尔刻度是在1930年左右被提出的,至今仍被广泛使用。
研究人员分别探究了VGG16 [58]、ResNet [22]和DenseNet [25]等预训练视觉模型进⾏迁移学习,根据观察发现预训练的 DenseNet更具有优势:它是深度密集网络且参数数量相对较少,能够为数据产生最佳精度。


论文中的DenseNet是具有⼀个卷积层、四个密集块和中间过渡层的网络。
然后我查了一下这个DenseNet(它是基于这么一种想法,如果卷积网络在靠近输入的层和靠近输出的层之间包含较短的连接,则它们可以更深、更准确和更有效地训练。由此提出了密集卷积网络(DenseNet),它是由康威尔大学、清华大学和 Facebook AI Research (FAIR) 联合发明它是2017 年 CVPR获得最佳论文奖的论文。以前馈方式将每一层连接到其他每一层。对于每一层,所有前面层的特征图都被用作输入,它自己的特征图被用作所有后续层的输入。DenseNets 有几个引人注目的优势:它们缓解了梯度消失问题,加强了特征传播,鼓励特征重用,并大幅减少参数数量。)
如图,密集块中,每一层都从所有前面的层接收特征图,其中,上面的H l (⋅)函数代表是非线性转化函数,(它是一个组合操作,包括一系列的BN(Batch Normalization),ReLU,Pooling及Conv操作。
1×1 Conv 和 2×2 平均池化用作两个连续密集块之间的过渡层,它主要是连接两个相邻的DenseBlock,并且降低特征图大小。。
密集块内的特征图大小相同,可以在channel维度上连接。。
(BN原因:随着网络的深度增加,每层特征值分布会逐渐的向激活函数的输出区间的上下两端(激活函数饱和区间)靠近,这样继续下去就会导致梯度消失。BN就是通过方法将该层特征值分布重新拉回标准正态分布,特征值将落在激活函数对于输入较为敏感的区间,输入的小变化可导致损失函数较大的变化,使得梯度变大,避免梯度消失,同时也可加快收敛。)
在预训练后修改这个架构,用两个全连接层替换最后⼀个全连接层,在中间使用⼀个 dropout 层 和 ReLU 激活函数。需要修改输出层,因为 DenseNet为 数据集 产生了1000 个可能的输出类,但EarBuddy需要的输出类要少得多(每个⼿势 1 个)。最后,在数据集上训练修改后的预训练网络,以生成EarBuddy 使用的最终分类模型。
( dropout作用:在每次训练的时候,随机让一定数量的卷积停止工作,这样可以提高网络的泛化能力,减少过拟合)
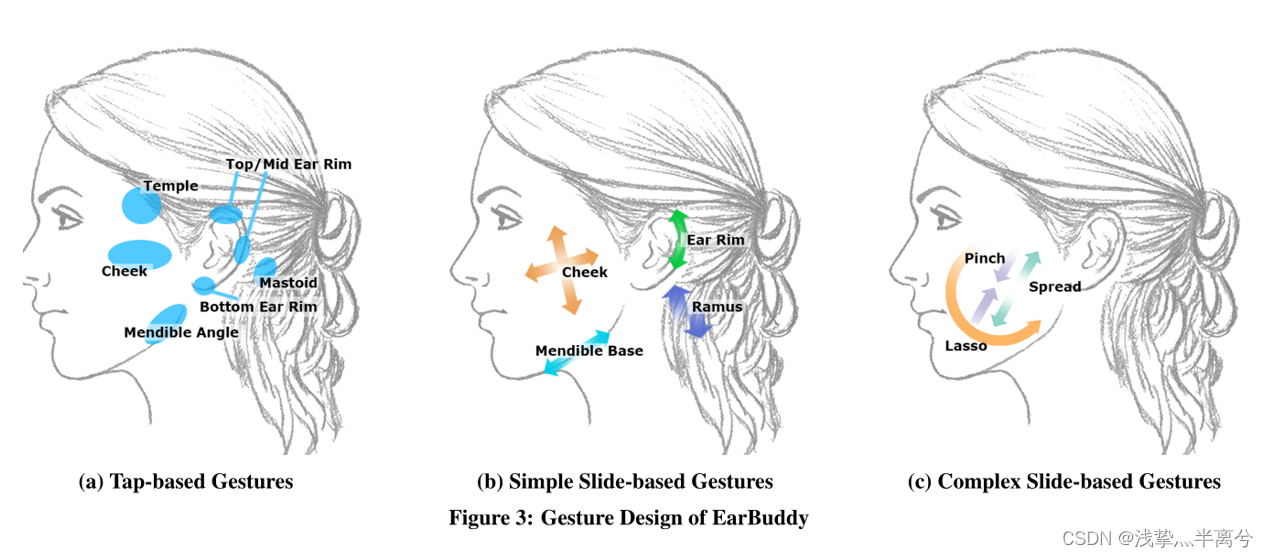
在交互设计中,一共确定了图中这七个可用于交互的区域,⼿势在脸上的位置和⼿指的动作是定义研究者设计空间的两个维度,如图所示,使用这两个维度上所有可⾏的选项对,一共生成了 27 个⼿势,其中14个是基于点击的手势,13个则是基于滑动的手势。

研究人员希望把27个手势集缩小到可以自然执行、快速记忆和轻松分类的子集,因此进行了一项研究以确定一个具有最优手势的集合。
招募了 16 名参与者(8 名男性,8 名女性,年龄 = 21.3 ±0.9)该研究在环境噪音约为 35‑40 分贝的安静房间中进⾏。每位参与者用右⼿完成所有 27 个⼿势 3 次。
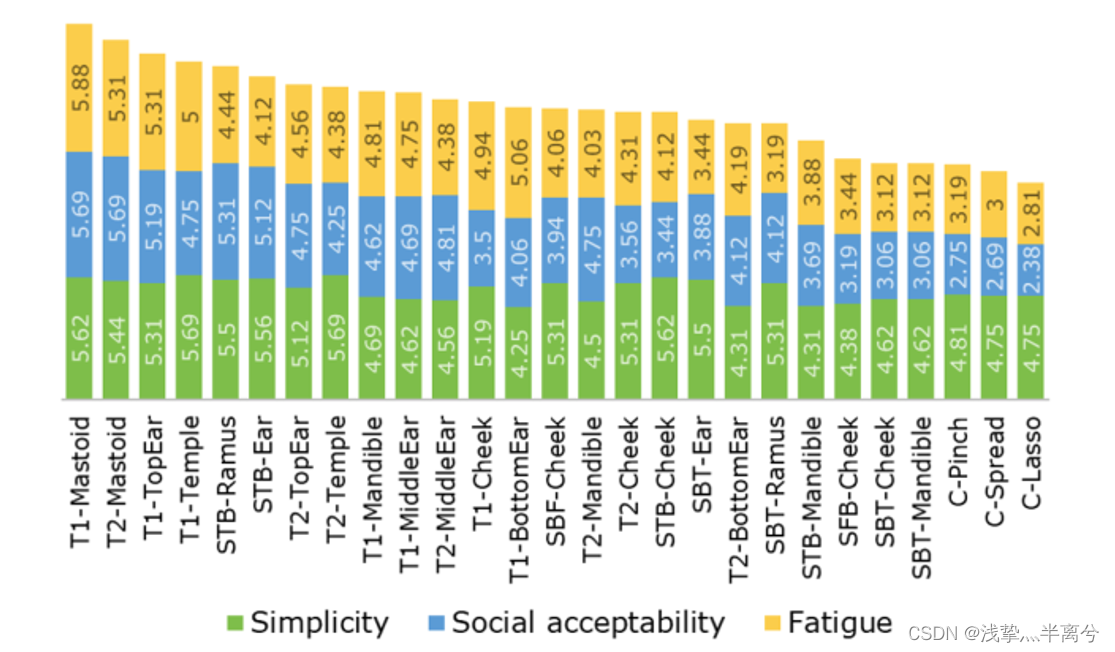
完成该⼿势 3 次后,参与者被要求根据 7 点李克特量表
(1:非常不同意到 7:非常同意)的三个标准对⼿势进⾏评分:
• 简单:“⼿势易于精确执⾏。”
•社会可接受性:“可以在没有社会关注的情况下执⾏该⼿势。”(也就是说符合行为学,操作不会显得很突兀)
•疲劳:“这个姿势让我感到疲倦。” (注:李克特分数被颠倒进⾏分析)
他们使用以下方面来选择最佳手势:
- 信噪⽐。我们计算了每个样本的信噪⽐ (SNR),并移除了平均SNR 低于5 dB 的⼿势。这删除了八个⼿势,其中许多是基于滑动的⼿势,它们要么是从下到上,要么是复杂的滑动⼿势
- 信号相似度。我们在原始数据上使用动态时间扭曲 (DTW) [54] 来计算⼿势对之间的信号相似度。总距离低于25 % 的⼿势被移除,因为它们在分类过程中最有可能被混淆。
- 设计⼀致性。先前的⼯作表明,单击⼿势和双击⼿势通常⼀起出现在设计空间中,即,如果界⾯⽀持单击⼿势,它通常也⽀持双击⼿势。因此,对于在此点之前消除的每个单击⼿势,相应的双击⼿势被删除,反之亦然。
- 偏好。使用用户的主观评分来决定剩余的⼿势。
最终剩下了8种手势,包括6种点击手势和2种滑动手势。
接下来又进行第二次研究来评估EarBuddy的检测和分类准确性,这项研究分两个阶段进行:⼀个是在安静的环境中,另⼀个是在嘈杂的环境中。
在数据收集期间,要求参与者在两个会话中在 5 轮中执⾏每个⼿势 10 次,
从而为每个参与者生成 100 个每个⼿势的示例(10 个示例/轮× 5 轮/会话× 2 个会话)。为了验证 EarBuddy 的检测准确性,参与者被要求执行手势的时间与笔记本电脑屏幕上的倒计时保持一致。也就是说计时器倒计时 2 秒,然后参与者再有 2 秒时间完成⼿势。在这 4 秒内录制了音频,以捕获带有和不带有⼿势的音频。
为了测试 EarBuddy 的可⾏性,研究人员使用本研究中收集的数据训练了两个模型,⼀个用于分割音频(即⼿势检测),另⼀个用于识别片段中的⼿势(即⼿势分类)。
他们使用 SGD(随机梯度下降) 作为训练的优化器,动量参数为 0.9以加速收敛,权重衰减正则化参数为 0.0001 [30] 以防⽌过度拟合。我们结合了梯度预热⽅法 [17] 和余弦退⽕技术来更新学习率。
余弦退火:使用梯度下降算法优化目标函数时,当接近损失函数的全局最小值时,学习率应该变得更小以使得模型尽可能接近这一点,所以需要对学习率进行衰减。余弦函数的特点是,随着自变量 x 的增大,余弦函数值先缓慢下降,然后加速下降,再减速下降,所以常用余弦函数来降低学习率
梯度预热⽅法:由于刚开始训练时,模型的权重是随机初始化的,此时若选择一个较大的学习率,模型可能会出现振荡现象。利用训练预热(Warmup)学习率的方法,使得前几个周期内的学习率较小,在较小的学习率的预热下模型将逐步趋于稳定,当模型较为稳定后便使用预先设置的学习率进行训练,这有利于加快模型的收敛速度,模型效果更佳。)
学习率从 0.01 开始,然后在 20 个 epoch 中攀升至 0.1 ,然后在接下来的 400 个 epoch 中以余弦曲线衰减。
这样的学习率调度具有收敛速度快(开始时学习率⼤)和稳健(结束时学习率小)收敛的优点。
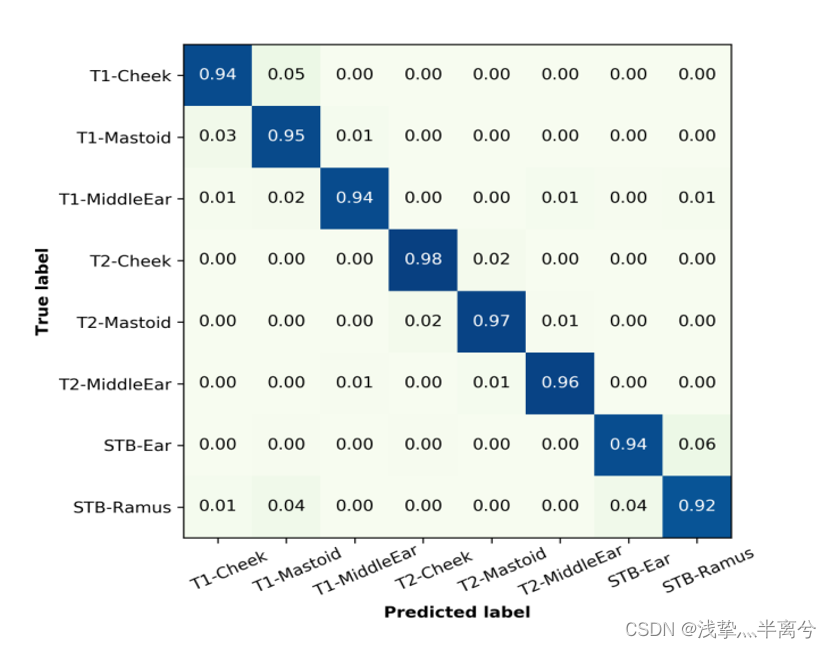
上图 显示了基于表 2 中最佳模型的八个⼿势的混淆矩阵。三个双击⼿势的准确度最⾼(97.3%),其次是三个单击⼿势(94.4%)和两个滑动⼿势⼿势(93.1%)。
图 :评估研究的结果。顶部)完成任务的时间。底部)三种设置的主观评分

总得来说,EarBuddy 可以作为⼀种便捷的输⼊⽅式。但是,EarBuddy 不适合重复、
持续的交互,例如文本输⼊和界⾯滚动。
。用⼾通常更喜欢轻敲⼿势而不是滑动⼿势。与滑动⼿势相⽐,轻敲⼿势的平均简单性评分相似,但社交接受度更⾼(4.6 对 3.9)和疲劳评分(4.8 对 3.7)。此外,简单的滑动⼿势⽐复杂的滑动⼿势更受欢迎,因为后者被认为不适合社交(2.6)和而且更劳累(3.0)。