目录

前言:
本篇模拟实现了STL中的list容器,其中的难点不在于其数据结构——链表,而在于对于类与类之间的联系和互相调用,关系十分巧妙,并且还有对于模板类的牛逼写法,相信大家认真阅读之后一定会有一些收获的。
学习类的方式:
如果大家学过string或者vector等其它类后一定会养成一个好习惯——了解一个类必须先了解它的成员变量,然后就是它的默认函数,再然后就是迭代器、最后才是它的其它函数功能。
1 类成员变量
1.1 list成员变量
首先看到list类的成员变量,没错,你没有看错只有一个_head,但是它的类型是Node*,通过我们typedef出来的类型,看到这个有没有联想到以前在哪里见到过吗?Linux中的string类当中就是通过这样的方式,用一个指针将一个结构类型封装起来,而不是像我上篇vector中使用的哪种方式,将一个结构用拆分成为一个个的变量作为list类的成员,虽然实际底层上没有任何的区别,但是对于代码的独有性就变得不在健全,还有很多功能是不好实现的,这一点我之后迭代器讲解。
template<class T>
class list{
public:
typedef struct node<T> Node;
typedef struct __list_iterator<T, T&, T*> iterator;
typedef struct __list_iterator<T,const T&, const T*> const_iterator;private:
Node* _head;
}
1.2 结点结构体变量
如果大家有链表的基础的话,我想应该是能够反应过来这个链表的形式是一个双向的,因为他保留了前后结点的指针,所以能够前移或者后移,不过因为我们想要一个非常高效的链表,单纯的双向还不够,我们还需要添加上循环属性,成为链表中最牛逼的带头双向循环链表。
其中的T类型是模板类型,不单纯指代一个类型,也就是我们可以构造出存储能够任意类型的链表,包括自定义类型。
template<class T>
struct node
{struct node<T>* next;
struct node<T>* prev;
T data;};
1.3 迭代器成员变量
要说STL容器当中的什么设计最牛逼,我只会给出一个答案,那就是迭代器思想的构建,要问为什么?只能说通过对数据结构封装成为的迭代器,让外部接口在不知道这个结构是如何的也能够通过相同的接口访问起来,极大的节省了初学者的精力。
举一个例子:(看下方的代码)
void test1()
{
std::vector<int> vv = { 1, 2, 3, 4, 5 };
std::list<int> ll = { 1, 2, 3, 4, 5 };
std::vector<int>::iterator itv = vv.begin();
while (itv != vv.end())
{
std::cout << (*itv *= 2) << " ";
itv++;
}
std::cout << std::endl;
std::list<int>::iterator itl = ll.begin();
while (itl != ll.end())
{
std::cout << (*itl *= 3) << " ";
itl++;
}
std::cout << std::endl;
}相信学过数据结构的大伙一定是明白vector和list的实现底层是完全不一样的,但是呢,大家发现了没有,这两个底层结构完全不同的数据结构被迭代器组织,将两个数据结构的使用变成了统一结构。是不是感觉很牛逼?只能说祖师爷和大佬们的世界太大了,要是本博主能够想出这种结构,估计这辈子的牛都够吹了。哈哈。如下是访问结果。
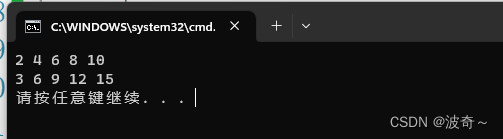
看到下方的迭代器结构体,其中也是只有一个变量,并且与我们的list类的变量类型完全一致,不过大家不用感到惊奇,因为迭代器类的出现本身就是为了辅助list访问结点的类的成员,所以类型相等是必然的,并且提前告诉你们,它们不只是类型相等,而且变量指向的空间也是同一份。那么这样做不会导致空间重复释放吗?
答案是,一定不会,除非咱们脑子突然被狗啃了,要在迭代器结构体当中写一个析构函数与给这片空间释放了。那么这也就表示了,迭代器是不需要拷贝构造和赋值重载的,我们要的就是浅拷贝。
迭代器表示:我只是摸摸,看看,动动,但是绝对不会给你顺了,放一百个心。
template<class T, class Ref, class Ptr>
struct __list_iterator
{typedef struct node<T> Node;
typedef struct __list_iterator<T, Ref, Ptr> self;Node* Pos;
};
至于迭代器模板中的Ref和Ptr大家现在不用理会,等到之后我会为大家解释。
2 默认函数——构造
2.1 结点结构体构造函数
构造当中,我使用了T()作为缺省参数,毕竟咱还是得考虑类型是自定义类型的情况,又或者是有帅小伙懒得都不想传参数了,比如博主本人。
因为这个结点只是结点,所以他还没有与链表构建联系,所以他不指向任何其他节点,指向空,数据直接赋值就行。
node(const T& val = T())
:next(nullptr)
, prev(nullptr)
, data(val)
{}
我突然想到,大家会不会在构造node结点时,在里面开一个空间?应该不会吧,毕竟只要我们调用了这个函数,那么空间必然是已经存在了,无论是在堆当中开辟还是在栈上,我们只是将这个空间当中的变量赋值,所以是不需要开空间的。
2.2 list构造函数
因为我们写的链表是带头的,所以说就算是无参构造也不是直接给_head置一个nullptr就行,也是需要开辟一个结点空间的,并且该节点的前后指针都指向自己。
并且看到我开空间的地方了吗?是因为_head需要指向一个这样的空间,并且不能因为函数退出就失效,那么必定就需要去堆上开空间,这里就会去调用Node的构造函数,那么就有地方承载Node变量的空间了,自然是不需要到Node里再去开空间。
void Init_head()
{
_head = new Node;
_head->next = _head;
_head->prev = _head;
}
//无参
list()
{
Init_head();
}2.3 迭代器构造函数
迭代器的构造函数就简单了,只需要传入一个Node*类型的指针过来,然后进行浅拷贝赋值给Pos就行,相信大家也不会在这里难住。
struct __list_iterator(Node* node)
:Pos(node)
{}
3 迭代器实现
3.1 list部分
对于迭代器来说,最基础的就是需要提供begin和end函数,这样我们的范围for才能被编辑器实现出来。
而且大家有注意到吗?以往我们写迭代器都是直接返回一个指针,但是对于list还是这样吗?很明显不是,我们是通过拿到头结点、尾结点的指针,然后通过这个指针去调用迭代器的构造函数,再将这个结构体返回拿到。
iterator begin()
{
//进入迭代器类当中去,然后传入起始值的数据初始化
return iterator(_head->next);
}
iterator end()
{
//_head相当于循环里的迭代器最后一个数据的下一个
//所以初始化就用_head去初始化
return iterator(_head);
}
const_iterator begin() const
{
return const_iterator(_head->next);
}
const_iterator end() const
{
return const_iterator(_head);
}3.2 迭代器结构体部分
3.2.1 operator*
我们平时在使用迭代器获取数据的时候是怎么样的?是不是直接*iterator就能得到了?但是对于我们的list迭代器呢?直接*iterator能得到数据吗?很明显不行的,并且我们的iterator可不是指针哦,而是一个完整的结构,那么它本身*是没有任何意义的。所以正因如此,我们需要对迭代器重载一个*运算符,当我们用*iterator时能够得到它里面结点内的数据。
那么这个时候我提一个问题,如果list类不封装迭代器,他还能像这样这样重载*吗?
答案是不能,因为如果我们不封装迭代器,那么这个迭代器必然只能是一个指针,但是这个指针是我们node结点里数据的指针么?不是!它是这个结点的指针,用*解引用之后只能得到node结点这个结构体,而不是结构体里面的数据。
那么有人又要问了,难道我得到了结点,我还不能访问数据了?
可以,但是我问,我们通过迭代器拿到了结点,然后通过这个结点再去访问数据还是我们想要的结果吗?换句话说就是,迭代器的行为不再统一,我要他有什么用?如下:
//希望的结果
yf::list<int>::iterator it = head.begin();
*it = 数据
//不希望的结果
yf::list<int>::iterator it = head.begin();
*it = 结点
结点.data = 数据
由此来看,list的迭代器封装起来并不只是为了实现功能分离,而是为了将行为统一,与其他容器的迭代器构成一个整体。
3.2.2 operator++/operator--
我们得知到迭代器++/--表示是什么意思,迭代器++/--指我们要将迭代器的结点走向想下个结点位置或者前一个结点位置,而不是走到连续空间的下一个位置。如果是vector这种形式的迭代器本身就是连续空间,那么它走到下一个位置自然是没有任何问题,但是关键是list不是,它的list被封装了,那么也就表示,迭代器只能重载++/--。根据前置后置需求不同,返回不同位置的结点。
3.2.3 operator->
大家在使用一个结构体指针的时候会先解引用,然后再用这个结构体去访问里面的数据吗?这样说大家可能大家不是很理解,那么请看下方代码:
struct AA
{
int a;
int b;
}struct AA val;
struct AA* ptr = &val;
//使用1
(*ptr).a = 2;
//使用2
ptr->a = 2;
我不用脑子我都能知道大家使用结构体指针的时候必定是用第二种方式,用第一种不纯粹恶心自己吗,所以说迭代器也出现了这个东西->。当然这个->箭头运算符重载的不是我们的Node结点,而是Node结点里的变量data,如果它的类型是类、结构体,那么就能够使用。
list<struct AA> ll;
list<struct AA>::iterator it = ll.begin();
it->a = 2;
也就是说,如果T类型本身就不支持使用->这个运算符,那么重载了->也是没有任何效果的。
list<int> ll;
list<struct AA>::iterator it = ll.begin();
it-> //错误,都不知道你要指什么
//如果你要指数据直接*it就行哈
还有大家有没有觉得这个重载少了点什么?
机智的小伙估计已经看出来了,没错就是少了一个->符号,本来是:
list<struct AA> ll;
list<struct AA>::iterator it = ll.begin();
it->->a = 2;
这样看不直观,但是展开就能知道了:
it.operator->()->a = 2;
看出来了吗?本来应该有一个重载运算符的,但是这里上面的访问却没有了,为什么?
编辑器省略了,为了代码的可读性。大佬们肯定是知道这里我们到底想要干嘛的,所以他们就对这种重定义做了处理,只用一个->就行。
3.2.4 operator==/!=
这两个重载很容易理解,你不是要比较这两个结点是不是相同吗?我又正好知道这两个结点的地址,那么只要地址不相同那就不相同,反之就相同。
3.2.5 Ref和Ptr
看到这里大家应该也能知道为什么要有Ref和Ptr这两个模板参数的出现了吧,Ref为了区分const T& 和 T&,Ptr为了区分const T* 和 T*。
为什么要区分呢?因为如果不区分的话我们就必须写两个内容功能基本相同的模板写两遍,那这个模板好垃圾哦,就出现了Ref,在模板里面又要考虑返回值是const T* 和 T* 这种类型,又要将函数写两边,这不纯恶心人吗,就有了Ptr。
代码:
//*迭代器返回结点内部的数据
Ref operator*()
{
return Pos->data;
}
//到下一个结点,而不是结点指针的下一个位置
self& operator++()
{
Pos = Pos->next;
return *this;
}
self operator++(int)
{
self temp = *this;
Pos = Pos->next;
return temp;
}
self& operator--()
{
Pos = Pos->prev;
return *this;
}
self operator--(int)
{
self temp = *this;
Pos = Pos->prev;
return temp;
}
//返回节点数据的地址
Ptr operator->()
{
//Pos已经是结点了,但是如果需要访问的数据也是一个结构体
//那么获取到了它的地址,就能用->去访问了
return &Pos->data;
}
bool operator==(const self& val)
{
return Pos == val.Pos;
}
bool operator!=(const self& val)
{
return Pos != val.Pos;
}4 区间构造、拷贝、赋值、析构
4.1 迭代器区间构造
迭代器区间可是一个好东西,它实现的可不仅仅是我们的同类型的迭代器去构造,他还能直接将其他类型的迭代器拿来拷贝,但是它本身的逻辑却很简单,如下。
//迭代器区间构造
template<class InputIterator>
list(InputIterator first, InputIterator last)
{
Init_head();
while (first != last)
{
push_back(*first);
++first;
}
}
4.2 拷贝构造
我写的拷贝是现代写法,不是传统的每一个数据都要直接去拷贝,然后连接,那样太麻烦了,非常不符合我喜欢偷懒的习惯,所以代码如下:
//拷贝
list(const list<T>& val)
{
Init_head();
list<T> temp(val.begin(), val.end());
std::swap(_head, temp._head);
}光看代码大家可能很疑惑,那么我就为大家解惑,首先看到Init_head(),这里是需要写的,不然之后交换函数时,_head是没有空间的,会使用野指针。我们的temp(val.begin(),val.end())这一句话直接通过原数据val拷贝出来了一个备份,而且不是指向同一个空间。
也就表示了我们现在有三个头了,_head,temp._head,val._head,这个时候我们只需要将_head和temp._head交换一下,那么我们的类就有数据了,temp就没了。为什么能这么做?因为这些空间是在堆上的,不用担心除了函数作用域就消失了,消失的只是temp这个栈上的变量。这叫什么,窃取劳动法,十分牛逼,建议大家学习,哈哈。
4.3 赋值重载
赋值重载和拷贝构造使用了同样的逻辑,都是偷,但是偷的方式不太一样,因为赋值重载的函数参数没有使用引用,那么传参过来回去调用拷贝构造,也就表示了已经有了新的空间,所以咱们直接去偷就可以。
//赋值重载
list<T>& operator=(list<T> val)
{
std::swap(_head, val._head);
return *this;
}4.4 析构函数
析构函数是清理所有结点,clear函数是清理这个对象里除了头结点以外的所有结点,清理方式很简单,把节点delete掉就行,我的clear复用了我的erase函数,等下为大家分享。
//清空除头结点之外的所有结点
void clear()
{
iterator it = begin();
while (it != end())
{
erase(it++);
}
}
//析构
~list()
{
clear();
delete _head;
}5 插入删除函数
该代码完全与数据结构链表的实现逻辑相同,也太简单,所以博主不想讲解。
//插入
void insert(iterator pos, const T& val)
{
Node* cur = pos.Pos;
Node* NewNode = new Node(val);
cur->prev->next = NewNode;
NewNode->prev = cur->prev;
NewNode->next = cur;
cur->prev = NewNode;
}
//尾插
void push_back(const T& val)
{
iterator it = end();
insert(it,val);
}
//头插
void push_front(const T& val)
{
iterator it = begin();
insert(it,val);
}
//删除
void erase(iterator pos)
{
assert(pos != end());
Node* cur = pos.Pos;
cur->prev->next = cur->next;
cur->next->prev = cur->prev;
delete cur;
}
//尾删
void pop_back()
{
iterator it = end();
erase(--it);
}
//头删
void pop_front()
{
iterator it = begin();
erase(it);
}
//判空
bool empty()
{
return _head->next == _head;
}