(强推)李宏毅2021/2022春机器学习课程_哔哩哔哩_bilibili
目录
3.1 Function with unknown parameters
3.2 Define loss fun from training data(定义loss函数)
3.3 Optimization(优化的方法为Gradient decent)
1.机器学习是什么?
机器学习,就是让机器帮人类找出一个人类写不出来的复杂函数。

2.机器学习任务
机器学习的三个任务,regression回归问题、classification分类问题、structured learning结构学习。
2.1 regression回归问题
resgression,输出是一个数值(scalar)。例如,让机器做的事预测未来某一天的PM2.5的值,机器的输入是今天PM2.5的值,温度和臭氧的浓度,中间的是要找的函数,输出的是明天的PM2.5的值,找中间函数的任务就是resgression。

2.2 classification分类问题
classification,输出为离散数值。先准好一些选项(类别),要找的函数的输出就是在设定好的这些类别中选择一个输出。例如,让函数判断传来的邮件是不是垃圾邮件,函数的输入是一封邮件,函数要先准好选项,是或者不是,这封邮件经过函数的判断,输出是或者不是。

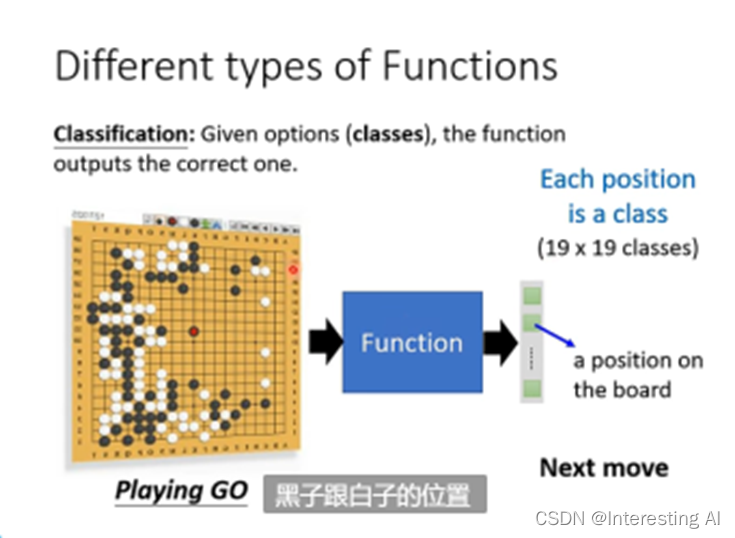
但classification不只是只有两个选项,也可以有多个选项。比如,阿尔法go,让机器下围棋,机器的输入就是19×19的选项(就是棋盘上棋盘格的个数),输出就是让函式找到正确的落子位置。
2.3 structured learning结构学习
structured learning,输出为一个有结构的内容,如一张图画、一段文字。
3.机器学习步骤
3.1 Function with unknown parameters
Function with unknown parameters(写出一个带有未知参数的函数),例如,Linear Model y=wx+b,这里y即是一个model,w、b为待训练的参数。定义函数类型。

目前有 GPT-3、GPT-2、T5、BERT、ELMo等大模型。

3.2 Define loss fun from training data(定义loss函数)
定义一个loss,这个函数的输入就是model的未知参数。函数输出的值代表,将未知函数值设定为一组固定的数值时,来判断这组数值的好坏。计算差值e的方法有两种,根据自己的需求来选择合适的方法计算e。cross-entropy交叉熵。

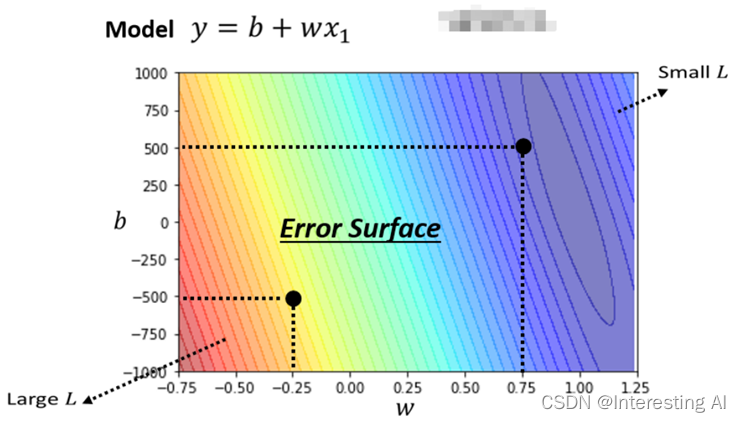
不同的w跟b的组合,都去计算它的Loss,然后就可以画出以下这一个等高线图。在这个等高线图上面,越偏红色系,代表计算出来的Loss越大,就代表这一组w跟b越差,如果越偏蓝色系,就代表Loss越小,就代表这一组w跟b越好。通常一个模型的修改来自你对这个问题的理解,即Domain Knowledge。
3.3 Optimization(优化的方法为Gradient decent)
解最优化问题,找一个w和b使L最小,使用到的方法,Gradient Descent。
(1)假设只有一个参数w
当w取不同的数的时候就会得到一个L曲线,这个曲线叫做 error surface。
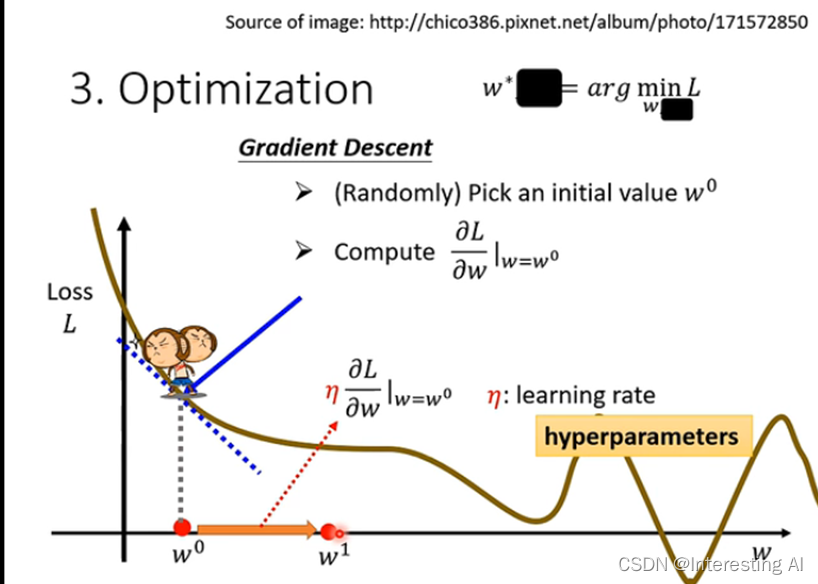
和前面的系数相关,叫做学习速率。学习速率是自己设定的,如果设置的学习速率的值大一点,那么参数的更新就会快一点,如果设置的值小一点的话,参数的更新就会慢一点。

但是这种反复操作的程序不会一直进行下去,也会有在某一个地方停止的时候,那什么时候停下来呢?会有两种状况:
一种是设置最大迭代次数,另一种就是计算到某一个wT时正好在这一点的微分是0,此时 参数的未知就不会在发生变化。但是,应用Dradient Descent 这种方法通常找不到最好的w解使得L 的值时最小的。会遇到局部最优情况。

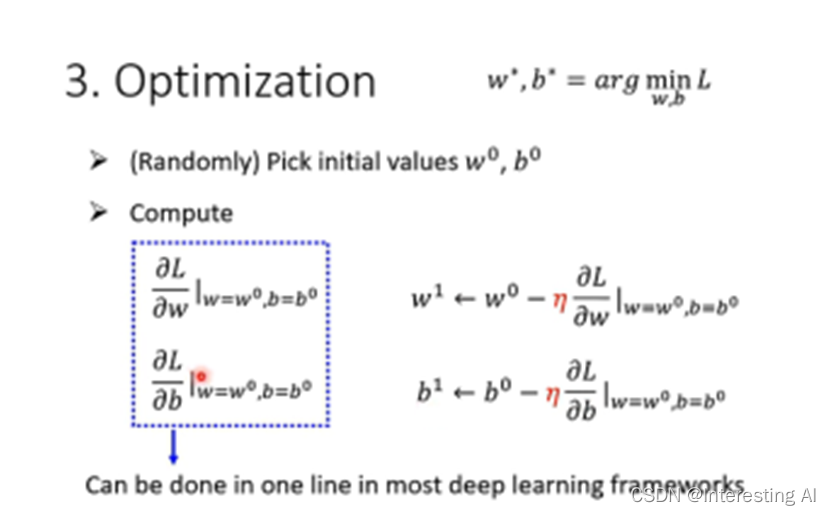
(2)两个参数w,b情况
步骤:
1)现在有两个参数,给他随即的数值w0和b0;
2)接下来分别计算w0和b0对loss的微分(微分的值是根据程式自动算出来的);
3)计算完上述的微分之后就去更新w和b(和只有一个参数的做法是一样的);
4)反复进行同样的步骤,更新w和b的值;
5)最后就得到最好的w和b。

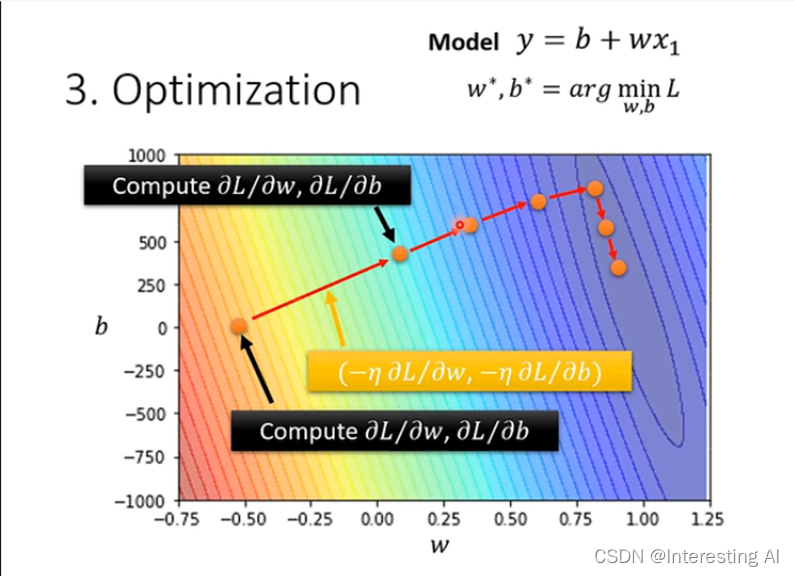
举例说明:
1.选择一个初始值(任意的),计算在该点的微分;
2.更新w和b,更新的方向就是;
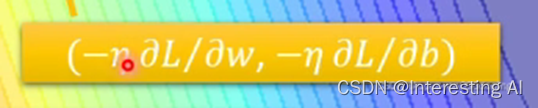
3.在更新之后的点处再对该点计算微分;
4.反复进行上面的操作,最后找到合适的w和b,计算出L。
函数的价值在于做预测。
