知乎极速版,应该不少人用过,界面简洁无广告,体积小巧,我一开始用知乎App就是用的极速版,所以一开始也收藏了不少内容,不过在2021年前后知乎极速版就不能使用了,不能使用也可以理解,下载了新版知乎app之后,竟然发现极速版收藏夹的内容竟然看不了了。只能新建收藏夹,重新收藏内容。
为此我打了知乎的客服电话,但是客服只是拖延时间,并不给解决问题,答复是无法恢复极速版收藏夹内容,也不能提供极速版收藏夹的内容。
不过我找了一些旧版本的知乎App,收藏内容时,底部弹窗可以显示出极速版收藏夹,也可以收藏进去,只是无法进如极速版收藏夹。那么猜测极速版收藏夹大概率还在,只是关闭了入口。是否可以通过接口的形式访问。毕竟内容无价。
这里我是用的知乎版本是 6.27.0 (安卓),找不到资源的可以在此处下载 ,下载后安装知乎app,并登录,然后手机安装抓包工具,我这里使用的是HttpCanary 选择知乎app开始抓包。
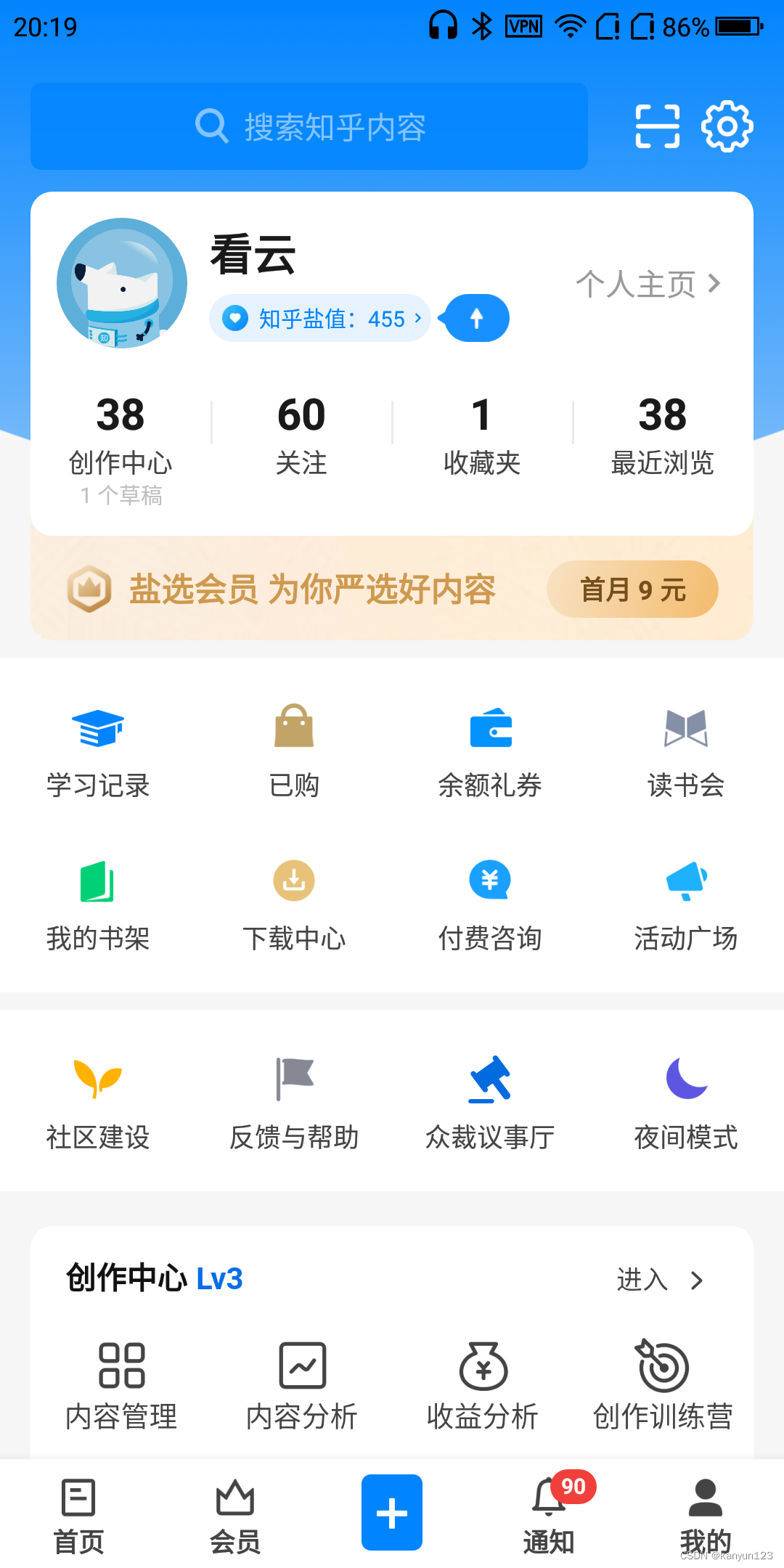
首先点击知乎app的个人-收藏 可以看到目前只有一个收藏夹。
打开HttpCanary,随便找一篇文章,然后点击收藏
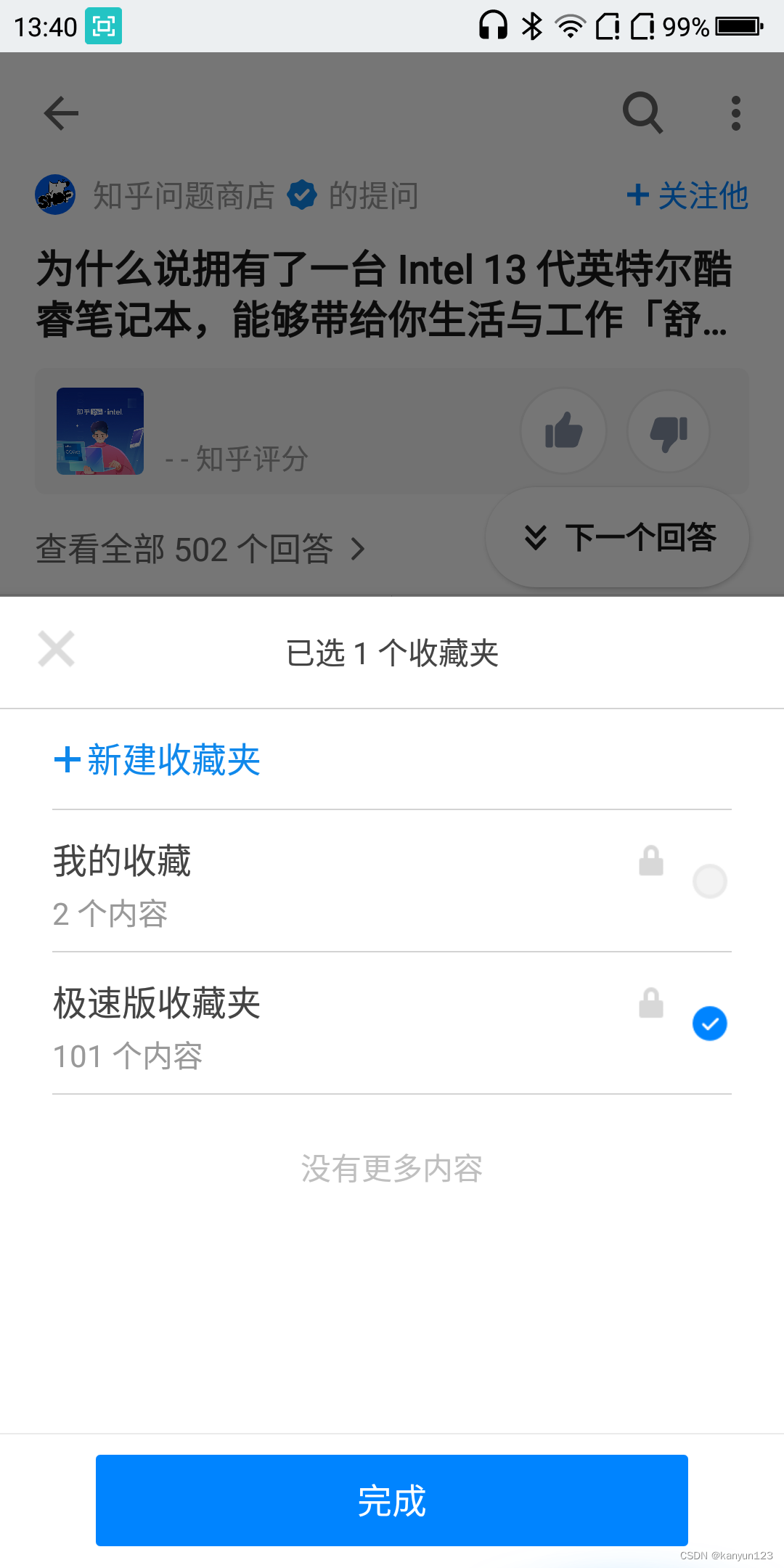
可以看到当前可用的收藏夹,此时发现极速版收藏夹已经显示出来了
由于我们此时已经打开了抓包工具,此时回到抓包工具,搜索关键字 collection 并点击进去
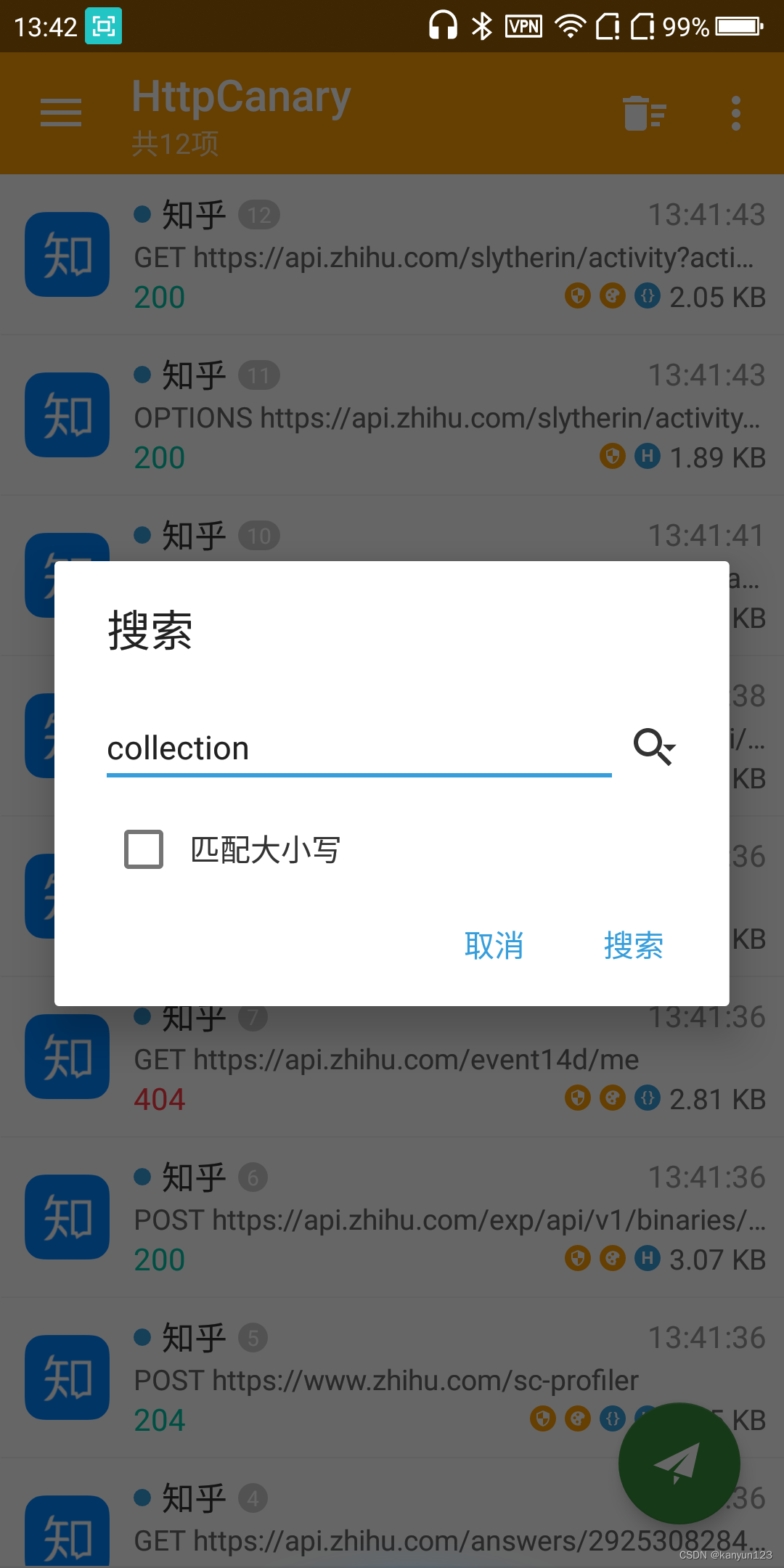
选择响应tab,选择底部text。可以看到服务端的响应内容。

可以看到服务端返回的内容是json格式,这里我们只关注返回报文中的data属性,它是一个数组。这里我把data中的内容展示出来
[
{
"title": "\u6211\u7684\u6536\u85cf",
"url": "http://api.zhihu.com/collections/850401696",
"answer_count": 2,
"is_favorited": false,
"follower_count": 0,
"is_public": false,
"type": "collection",
"id": 850401696
},
{
"title": "\u6781\u901f\u7248\u6536\u85cf\u5939",
"url": "http://api.zhihu.com/collections/420224098",
"answer_count": 101,
"is_favorited": false,
"follower_count": 0,
"is_public": false,
"type": "collection",
"id": 420224098
}
]data属性里包含两个子项,其中的title是 unicode编码,一种文字编码标准
这是计算机科学领域里的一项业界标准,在这种语言环境下,不会再有语言的编码冲突,在同屏下,可以显示任何语言的内容,这就是Unicode的最大好处。 就是将世界上所有的文字用2个字节统一进行编码。那样,像这样统一编码,2个字节就已经足够容纳世界上所有的语言的大部分文字了。
此时我们只需要找一个转换工具,把Unicode编码转换一下就知道title的内容了。
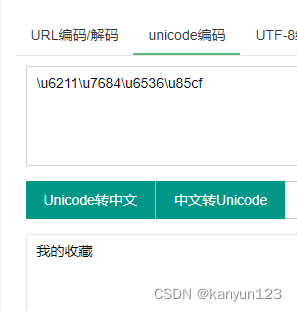
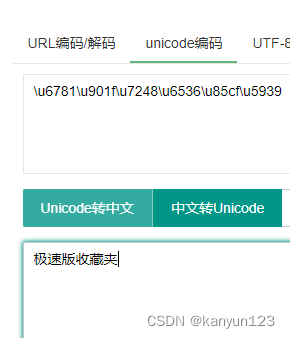
通过在线的转换工具,我们很快就知道了data属性中的内容是什么了,此时知道了title的内容,那么对应的url/id 的属性值就是收藏夹的 地址 和 id。
有了收藏夹的url和id,那么现在就差得到收藏夹内容列表的api了。
回到知乎app首页,点击个人-收藏夹-点击我的收藏
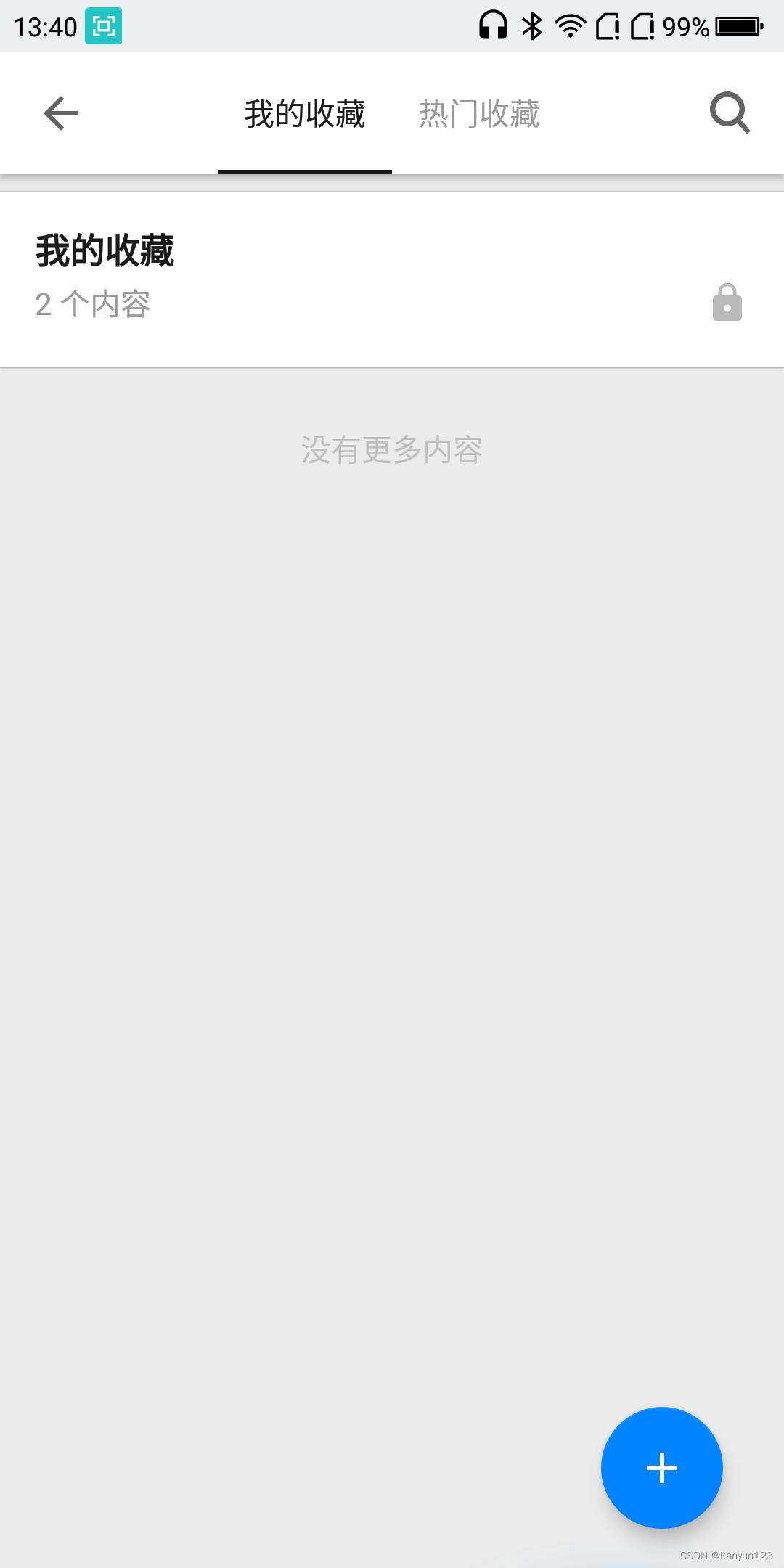
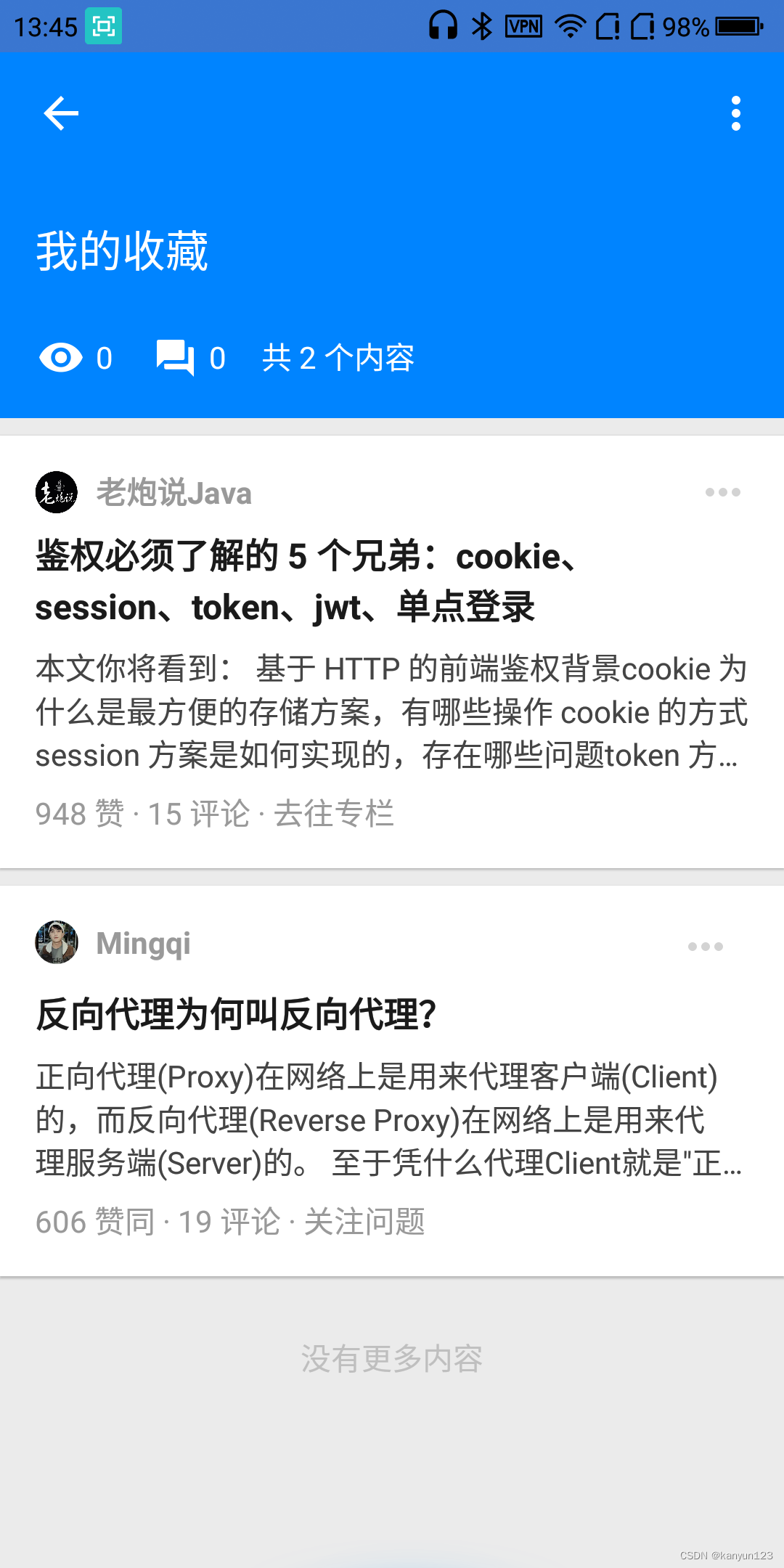
打开HttpCancry,搜索你看到的关键字,比如我收藏的内容中的 反向代理
然后找到了对应的请求,然后查看请求,和内容


发现此时抓取的报文内容与app上显示的内容一致!
此时我们就找到了获取收藏夹内容的api。因此这里我们只需要将url中的id替换为极速版收藏夹的id即可。我们可以直接httpCancy中编辑这个请求,并点击发送,并发现可以返回内容,同时注意到,url中还有limit/offset的参数,这两个参数就是用来分页的,可以控制每次展示多少条收藏的内容
最后打开电脑浏览器,先登录知乎,开启新的标签页,并在地址栏输入地址
https://api.zhihu.com/collections/{你的极速版收藏夹ID}/contents?limit={你的极速版收藏夹内容数量}&offset=0
输入完毕后,就会返回一大串的json。
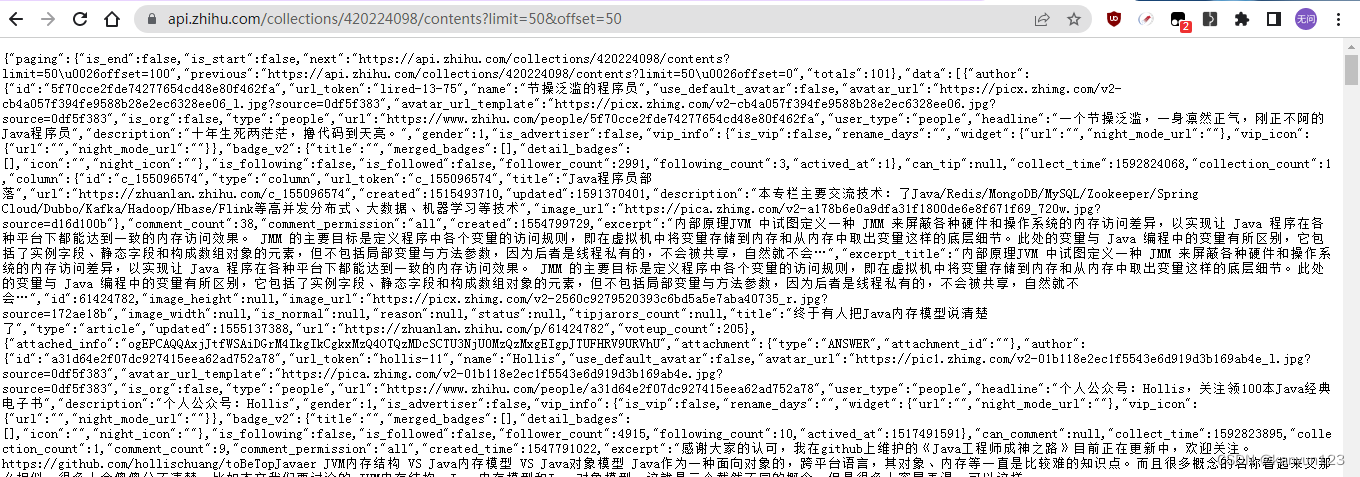
需要注意的是即使你选择了获取全部的收藏内容,得到的收藏内容数量可能跟app显示的total不一致,这个可能是知乎服务端统计收藏数存在bug!
使用格式化工具进行格式化,可以发现data下是一个数组类型,数组中的每一个对象里的url的内容,即为你极速版收藏夹中收藏的内容。
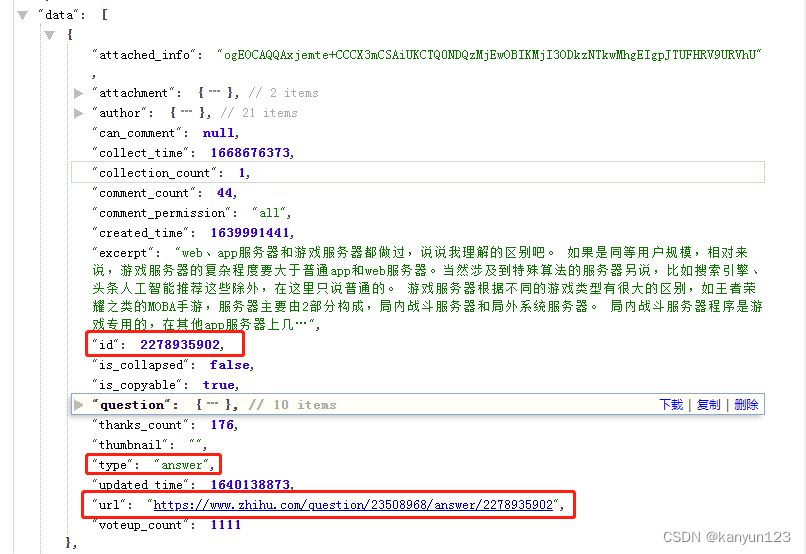
现在已经得到了极速版收藏夹的所有内容,你可以把浏览器的内容复制出来,粘贴到文件中,如果要重新收藏他们,可以新建一个收藏夹,并复制url打开浏览器,收藏内容。
新收藏夹的ID,比较容易获取,在电脑端打开知乎进入个人中心-收藏,即可在浏览器控制台看到新收藏夹的ID了!
如果收藏内容比较多,也可以批量收藏。
收藏api是 https://www.zhihu.com/api/v4/collections/{收藏夹id}/contents?content_id={内容id}&content_type={内容类型}
url中的content_id、content_type参数值,即为上图所标注出来的content_id/content_type。
这里上一段代码,解析极速版收藏夹的内容,并批量收藏到新的收藏夹。
package com.kanyun;
import com.google.gson.JsonArray;
import com.google.gson.JsonElement;
import com.google.gson.JsonObject;
import com.google.gson.JsonParser;
import okhttp3.*;
import java.io.File;
import java.nio.file.Files;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.TimeUnit;
public class ZhiHu {
public static void main(String[] args) throws Exception {
String domain = "https://www.zhihu.com";
//要恢复到哪个收藏夹的id(创建好新的收藏夹后,点击进去可以在浏览器地址栏看到)
String collectionId = "867907103";
String uri = "/api/v4/collections/"+collectionId+"/contents";
//极速版收藏夹的内容
byte[] bytes = Files.readAllBytes(new File("C:\\Users\\KANYUN\\Desktop\\untitled\\src\\main\\resources\\zhihu.json").toPath());
String collections = new String(bytes, "UTF-8");
JsonObject zhihuCollection = JsonParser.parseString(collections).getAsJsonObject();
JsonArray data = zhihuCollection.get("data").getAsJsonArray();
for (JsonElement datum : data) {
long id = datum.getAsJsonObject().get("id").getAsLong();
String type = datum.getAsJsonObject().get("type").getAsString();
String contentUrl = datum.getAsJsonObject().get("url").getAsString();
OkHttpClient httpClient = new OkHttpClient.Builder().connectTimeout(13, TimeUnit.SECONDS).build();
Map<String, String> header = new HashMap<>();
// 打开浏览器的控制台,复制如下的请求头的key的值
header.put("cookie", "_zap= KLBRSID=ed2ad9934af8a1f80db52dcb08d13344|1679576820|1679576725");
header.put("x-requested-with", "fetch");
MediaType mediaType = MediaType.parse("application/x-www-form-urlencoded");
System.out.println("准备收藏内容:[content_id:" + id + ",content_type:" + type + "]");
String tpl = "content_id=%s&content_type=%s";
String body = String.format(tpl, id, type);
Request request = new Request.Builder()
.url(domain + uri)
.headers(Headers.of(header))
.post(RequestBody.create(body, mediaType))
.build();
Response response = httpClient.newCall(request).execute();
if (response.isSuccessful()) {
System.out.println("服务端响应结果: " + response.body().string());
// 不要执行太快,会被检测到,限制操作
TimeUnit.SECONDS.sleep(10);
} else {
System.err.println(response);
System.exit(1);
}
}
}
}