来自博主卷毛迷你猪的授权,来自我们老师PPT,我只是写自己的操作过程
实验四 Hive实践介紹
- 1.实验目的
- 2.实验原理
- 3.实验准备
- 4.实验内容
时长:4次课(4周)
1.实验目的 - 熟悉Hive命令,通过编写HiveQL脚本初步掌握更高层次的ETL操作。
- 联合使用MapReduce+Hive,计算目标数据信息。
- (选做)初步掌握UDF/UDAF等自定义精细化数据计算操作,为后续学习SparkSQL和类似计算框架类SQL使用做好准备。
2.实验原理 - Hive是一种常用的数据仓库工具,帮助不熟悉Java编程的用户,依靠熟练的SQL操作实现MR程序的编写。
- Hive组件内置了解释器、编译器和优化器,能够通过预置的MR程序模板将用户编写的HiveSQL操作“翻译”成MR程序,并交给集群执行计算。
- Hive本身不存储和计算数据,它完全依赖于HDFS和MapReduce,它仅仅是一种纯逻辑操作;本质上看,Hive处理的就是HDFS上的数据,可以认为是map-reduce的一种包装。
- Hive也需要缓存元数据(Metastore ),且本次实验配合MySQL存储元数据;当然也可以直接使用Hive内嵌的Derby。
3.实验准备 - 完成实验一,搭建好伪分布式环境
- 完成实验二,确保HDFS可用
- 完成实验三,掌握MR程序的编写方法
4.实验内容
【实验项目】项目1、项目2、项目3必做;项目4,及后续项目选做;注意标红的思考题,并在实验报告中给出解答。
- 项目1:Hive安装配置
- 项目2:Hive操作实践——员工工资信息统计
- 项目3:MapReduce+Hive综合实践——搜狗日志查询分析
- 项目4:Hive Java API操作
- 项目5:UDF实践
- 项目6:视频数据统计实践(2023年)
【注】由于石老师的课程中已经介绍了HBase 的API编程,所以在2023年开始,本课程实验才会加入相关内容;本年度(2022)暂时不添加这部分。
项目1:Hive安装配置
【参考链接】(梁老师博客)
【准备工作】
-
安装好hadoop2.7.3(Linux环境);
-
安装好MySQL5.7(Windows系统下),推荐使用,或者 Xampp(Windows环境)参考 Navicat通过IP连接Xampp数据库;
-
【参考】命令安装MySQL(Windows系统下):
-
【参考】Navicat通过IP连接XAMPP数据库:https://blog.csdn.net/qq_42881421/article/details/84622058
-
用Navicat IP的方式连接到mysql数据库,如果通过IP连接失败,
【参考】通过IP连接mysql:https://blog.csdn.net/qq_42881421/article/details/84147689 -
也可以直接使用内嵌数据库或者在Linux安装MySQL,直接使用Localhost访问
- 并新建一个名为hive的数据库(可以自拟)
【注】
- mysql安装在windows时,需要用IP地址来连接数据库,确保navicat可以用IP连接到数据库;当网络环境变化时,windows IP会变化,这时要注意修改hive-site.xml中的mysql连接的IP地址。
- 为避免麻烦,可以将mysql安装在Ubuntu中,hive-site.xml配置为localhost
4.实验内容【大致步骤*】
- 项目1:Hive安装配置
【参考链接】https://blog.csdn.net/qq_42881421/article/details/84330906(梁老师博客)
【安装步骤】(大致)
- 官网下载hive安装文件,下载地址:Index of /dist/hive 或者 Index of /apache/hive
- 将hive安装文件上传到Linux系统中~/soft目录下,解压:
- 创建软连接:
- 配置环境变量
- 配置hive-site.xml(关键步骤) *发现没有直接自己写就行,*注意电脑IP
- 将MySQL驱动文件拷贝到hive安装目录的lib下*
- 初始化MySQL
- 启动Hive(先启动Hadoop:HDFS和YARN…)
- 执行hive启动客户端

【可能的坑】
-
hive/conf下没有hive-site.xml文件?*应该都会遇到
==> 自行创建一个hive-site.xml即可。 -
执行提示错误
==> com.mysql.jdbc.Driver“驱动已经被弃用了,要使用新的配置(因为我的MySQL是8.0.15版本):
修改hive-site.xml相关配置:”com.mysql.cj.jdbc.Driver“ -
项目1:Hive安装配置
【参考链接】https://blog.csdn.net/qq_42881421/article/details/84330906(梁老师博客)
【可能的坑】 -
执行提示错误:
==> 报错提示mate异常,参考以下信息修改url配置:
【注】
(1)useSSL=False (原来是小写,我的虚拟机提示要大写,根据提示
(2)添加配置allowPublicKeyRetrieval=true,且和前面一项配置之间要加上”&”和”;”间隔符
- 项目1:Hive安装配置
【参考链接】https://blog.csdn.net/qq_42881421/article/details/84330906(梁老师博客)
【可能的坑】 - 执行提示错误:
==> 报错提示timezone(时区)异常,设置完备的URL即可(添加时区设置):
【注】设置:serverTimezone=GMT,且和前面一项配置之间要加上”&”和”;”间隔符
-
项目1:Hive安装配置
【参考链接】https://blog.csdn.net/qq_42881421/article/details/84330906(梁老师博客)
【可能的坑】 -
执行hive提示错误:
==> 报错提示安全模式异常,关掉即可(启动Hadoop后太快启动Hive也可能出现类似情况,等等就好): -
项目1:Hive安装配置
【参考链接】https://blog.csdn.net/qq_42881421/article/details/84330906(梁老师博客)
【可能的坑】 -
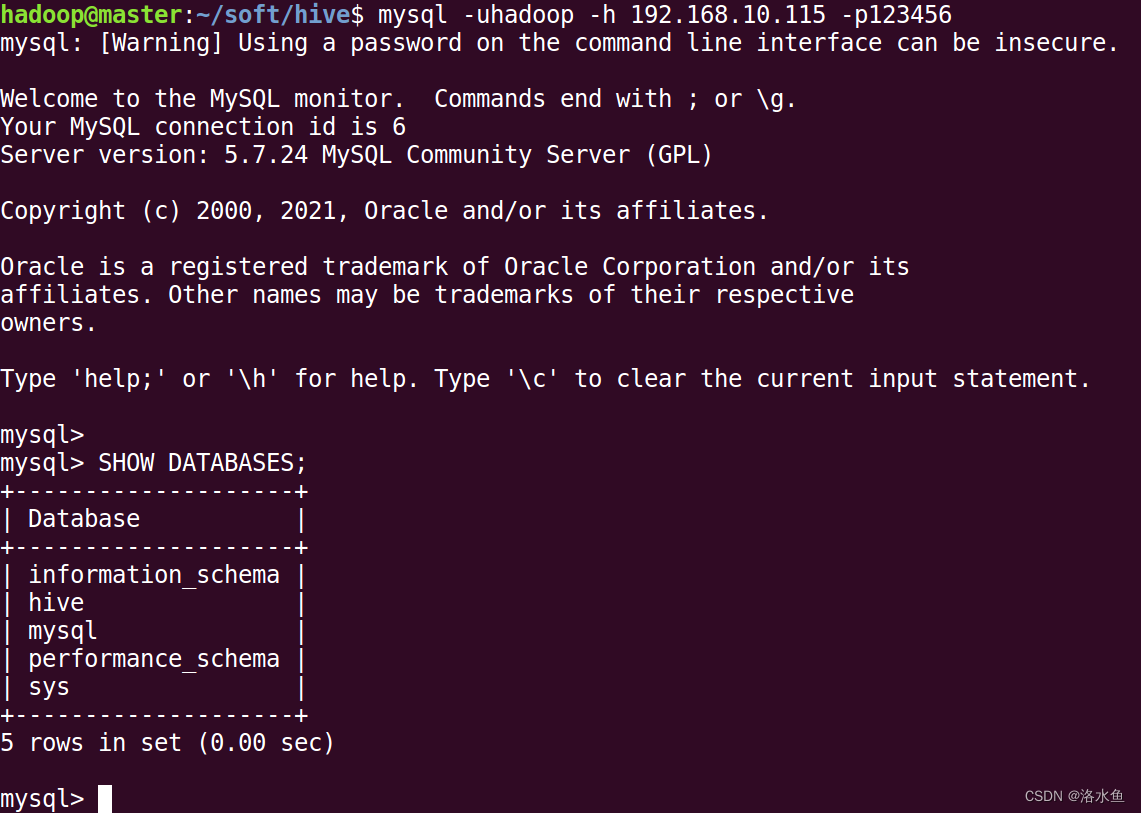
Linux无法访问MySQL的情况,需要在MySQL里添加远程登录账号,参考以下3个帖子(因为MySQL版本不同,可能存在第三个帖子的问题):
(1)虚拟机连接宿主机(外部本地主机)MySQL数据库
https://blog.csdn.net/qq_35151255/article/details/100046039
(2)linux虚拟机连接宿主机的mysql
https://blog.csdn.net/qq_35151255/article/details/100046039
mysql> GRANT ALL PRIVILEGES ON *.* TO 'hadoop'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
Query OK, 0 rows affected, 1 warning (0.01 sec)
linux登录前没有mysql要先安装
sudo apt-get install mysql-client-core-5.7
在用该命令
mysql -h <宿主机IP地址> -u <用户名> -p <密码>
(3)mysql版本:'for the right syntax to use near ‘identified by ‘password’ with grant option’
https://blog.csdn.net/Architect_CSDN/article/details/102488975
- 项目1:Hive安装配置
【参考链接】https://blog.csdn.net/qq_42881421/article/details/84330906(梁老师博客)
【可能的坑】 - 梁老师博客安装hive操作中,第6步无法下载MySQL驱动jar包
==> 参考https://www.cnblogs.com/it-mh/p/11205866.html,从官方网站下载压缩包,解压得到jar包! - 有的同学使用的是石老师提供的Linux镜像,若是那么请认真检查配置,问题往往都是配置参数需要修正。
项目2:Hive操作实践——员工工资信息统计
【参考链接】https://blog.csdn.net/qq_42881421/article/details/84618659(梁老师博客)
【准备工作】已经完成项目1 ==> 参考白书教材P193
【大致步骤】
-
启动Hadoop。
-
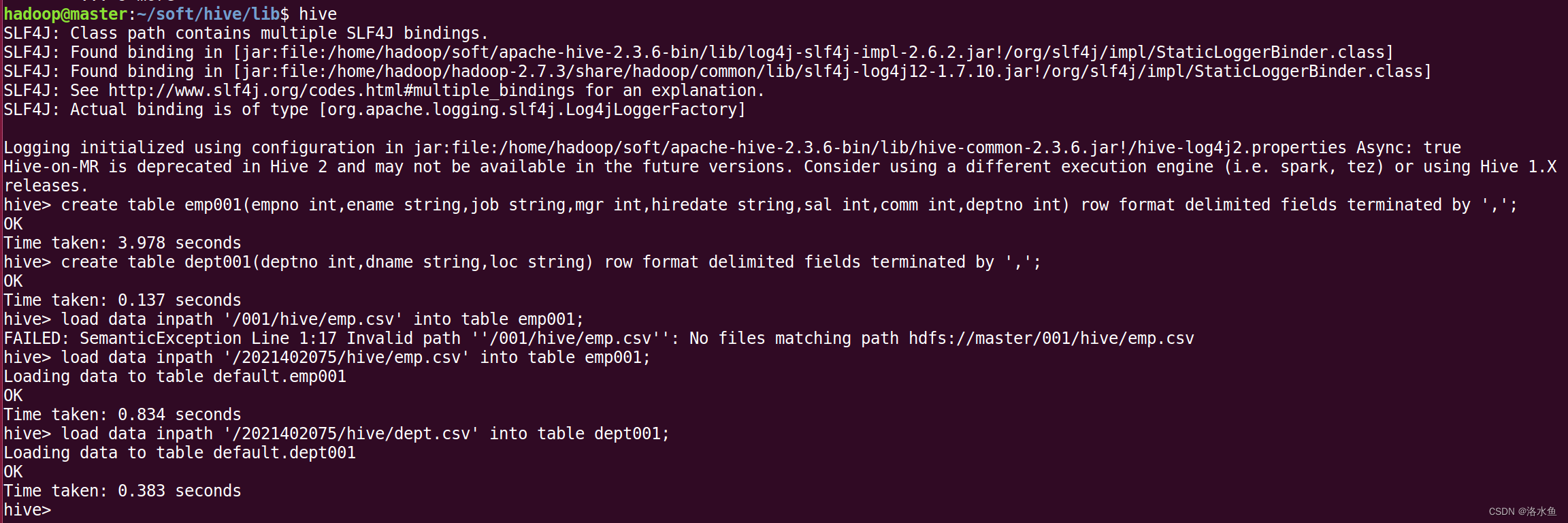
新建emp.csv和dept.csv两个数据文件,并上传到HDFS中。
-
启动Hive。
-
创建员工表(emp001)和部门表(dept001)。
-
将HDFS中的emp.csv和dept.csv分别导入emp001和dept001。
-
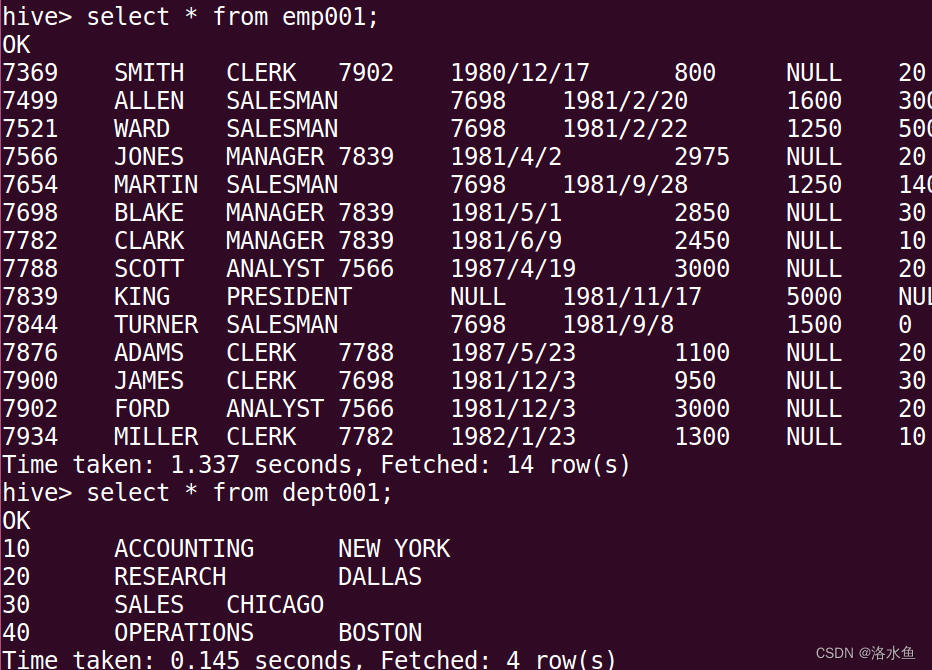
查询表数据。
-
根据员工的部门号创建分区,表名emp_part+学号,如:emp_part001,并查看分区数据。
-
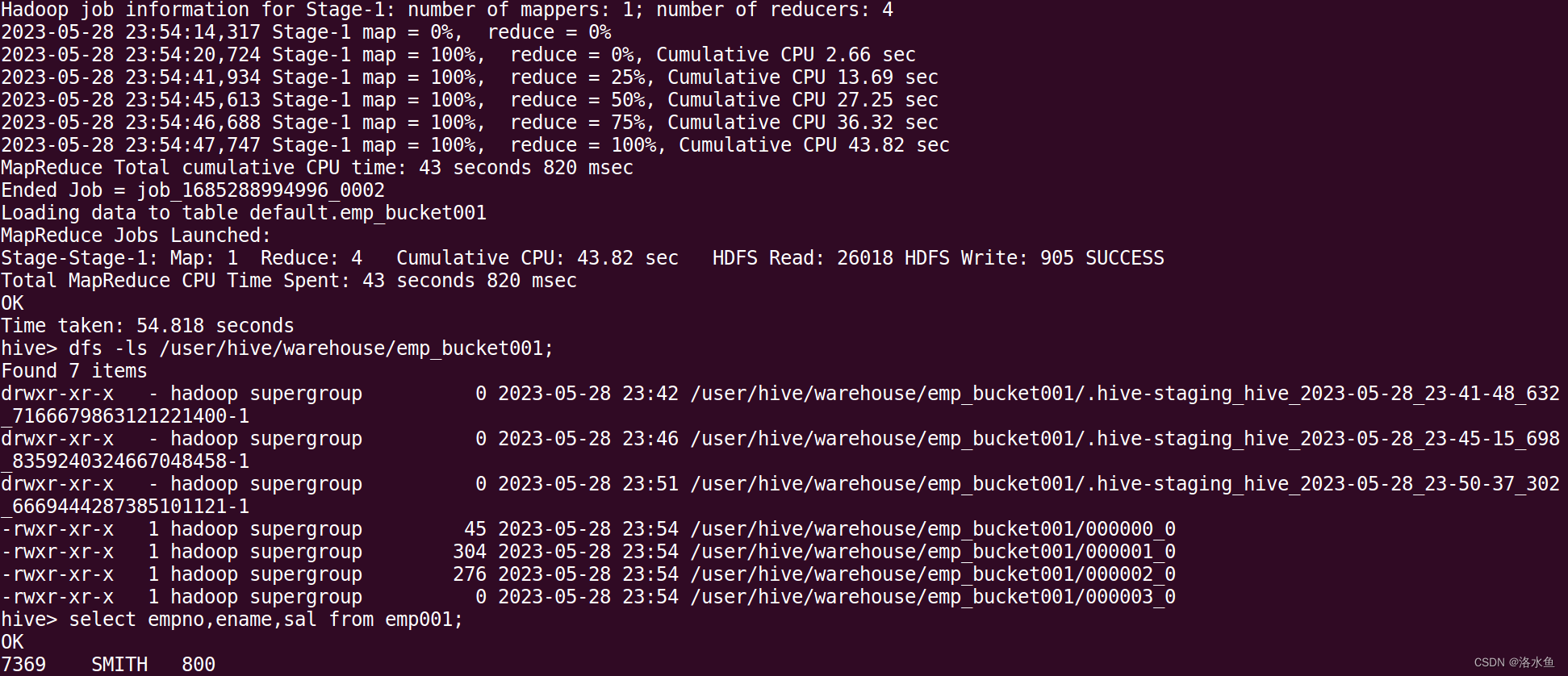
创建一个桶表,表名emp_bucket+学号,如:emp_bucket001,根据员工的职位(job)进行分桶。
-
查询员工信息:员工号 姓名 薪水。
-
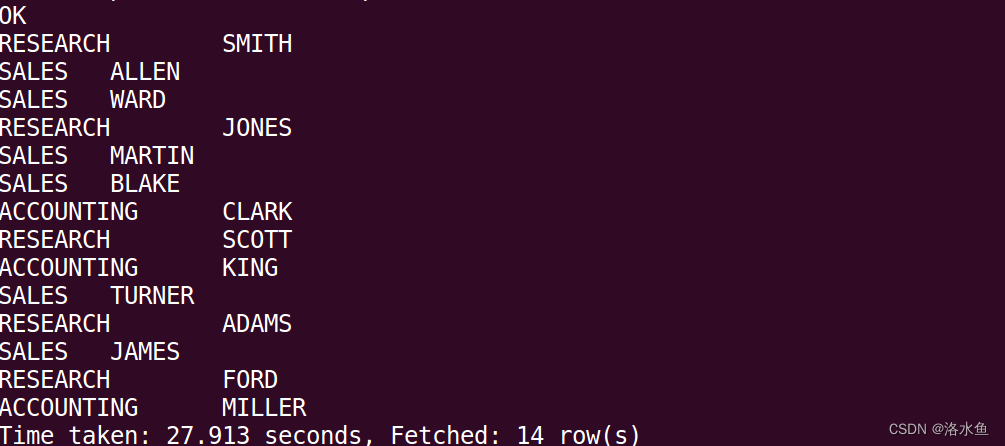
多表查询。
-
做报表,根据职位给员工涨工资,把涨前、涨后的薪水显示出来。
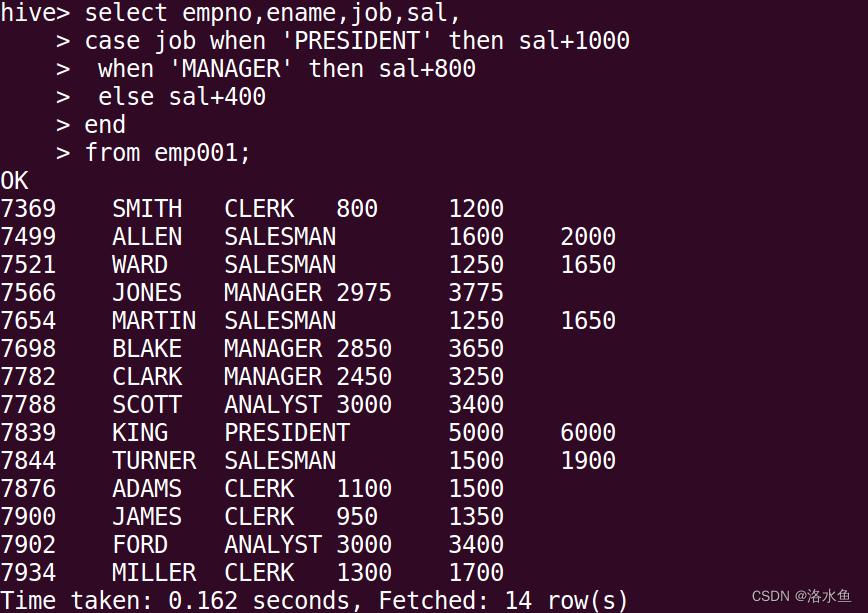
项目2:Hive操作实践——员工工资信息统计
【思考题】
【思考题1】对于Hive:什么是内部表?什么是托管表?什么是管理表?什么是外部表?这些概念有和区别和联系?
内部表和托管表是同一个概念,表示Hive完全管理和控制的表。Hive负责管理表的元数据和数据存储位置,包括在默认的数据存储位置中创建数据目录和存储数据文件。删除内部表将同时删除元数据和数据。
管理表是一个更通用的术语,用于描述由Hive管理的表,包括内部表和外部表。管理表的数据可以由Hive管理和控制,但数据文件存储位置可以是用户指定的位置或由Hive在默认位置中自动创建。删除管理表将删除元数据,并根据设置的参数决定是否删除数据文件。
外部表是独立于Hive的表,其数据文件不由Hive管理和控制。外部表的数据文件可以存储在任何位置,如HDFS或其他存储系统。删除外部表只会删除元数据,不会删除数据文件本身。
区别是:内部表和托管表是Hive完全管理和控制的表,外部表是独立于Hive的表,而管理表是一个更通用的术语,用于描述由Hive管理的表,包括内部表和外部表。
【思考题2】项目2中的load data操作后,数据和数据表被转移到那个目录下了?
在Hive中使用load data命令加载数据时,默认情况下,数据文件会被移动到Hive表所在的存储位置。具体来说,数据文件将被移动到Hive表的存储目录中的相应分区目录(如果适用)或表目录中。
Hive表的存储位置可以通过Hive的LOCATION属性指定,或者使用Hive默认的存储位置规则。如果没有显式指定存储位置,Hive默认将表存储在Hive Warehouse目录下的一个子目录中。
【思考题3】在最后一步操作中,我们对数据做了修改,为何再次查询数据却没有变化?
这个查询通过使用CASE表达式来计算一个新的薪水字段,并且不会对表中的数据进行实际修改。查询语句仅仅是基于已有的数据进行计算,并将计算结果作为新的字段返回。因此,这个查询不会对表中原有的内容进行任何改变。
【思考题4】Hive在MySQL中存放的元数据有哪些,能否根据自己MySQL中真实存放的Hive元数据逐一举例说明?
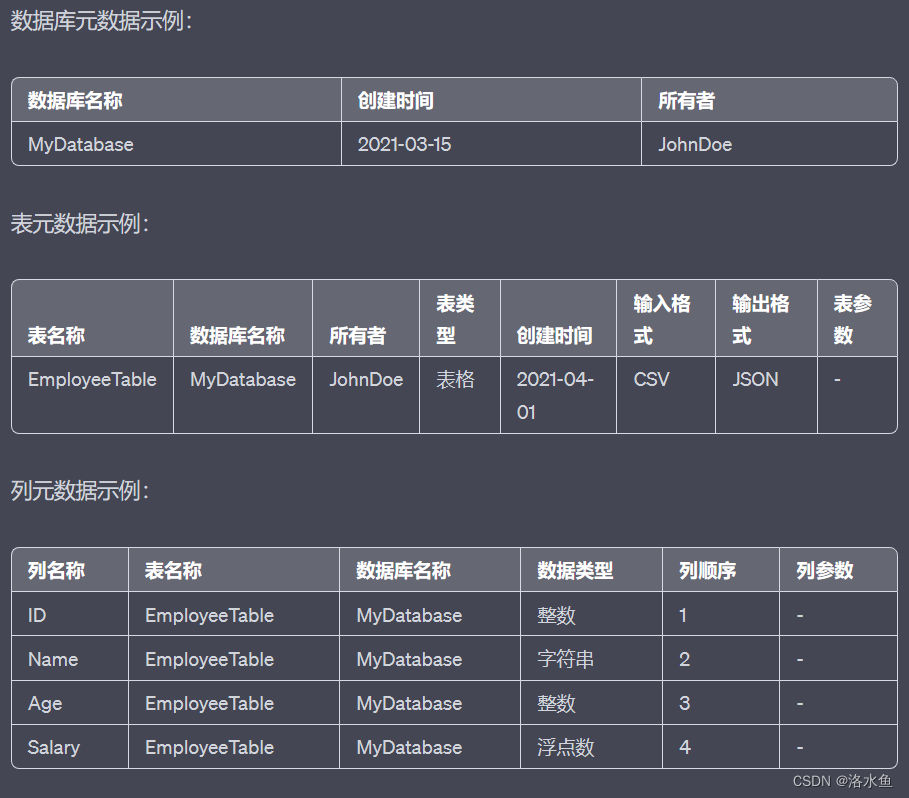
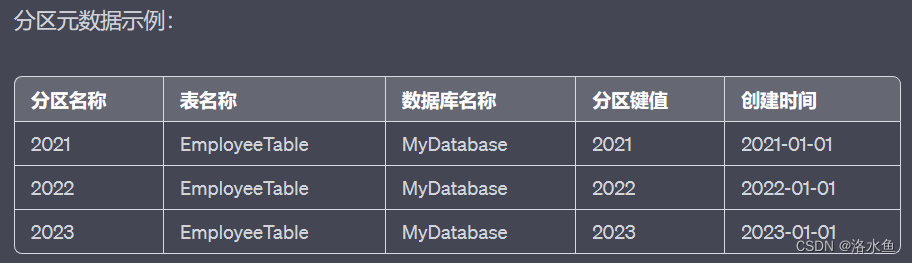
项目3:MapReduce+Hive综合实践——搜狗日志查询分析
【参考链接】https://blog.csdn.net/qq_42881421/article/details/84899795(梁老师博客)
【准备工作】已经完成项目1、2 ==> 参考白书教材P284
【模式实战场景】:从搜狗实验室下载搜索数据进行分析
下载的数据包含6个字段,数据格式说明如下:
访问时间 用户ID [查询词] 该URL在返回结果中的排名 用户点击的顺序号 用户点击的URL
【注意】
1.字段分隔符:字段分隔符是个数不等的空格;
2.字段个数:有些行有6个字段,有些达不到6个字段。
- 项目3:MapReduce+Hive综合实践——搜狗日志查询分析
【参考链接】https://blog.csdn.net/qq_42881421/article/details/84899795(梁老师博客)
【大致步骤】MR数据清洗可能多花费时间,实验内核是通过数据分析,找到隐含在数据中的规律/价值(数据挖掘)
1.下载数据源
- 上传下载文件至HDFS
2.1将下载的文件通过WinScp工具上传到Linux系统
2.2 解压SogouQ.reduced.tar.gz并上传到HDFS - 数据清洗
因为原始数据中有些行的字段数不为6,且原始数据的字段分隔符不是Hive表规定的逗号’,',所以需要对原始数据进行数据清洗。
通过编写MapReduce程序完成数据清洗:(打包运行)
(1)将不满足6个字段的行删除
(2)将字段分隔符由不等的空格变为逗号‘,’分隔符
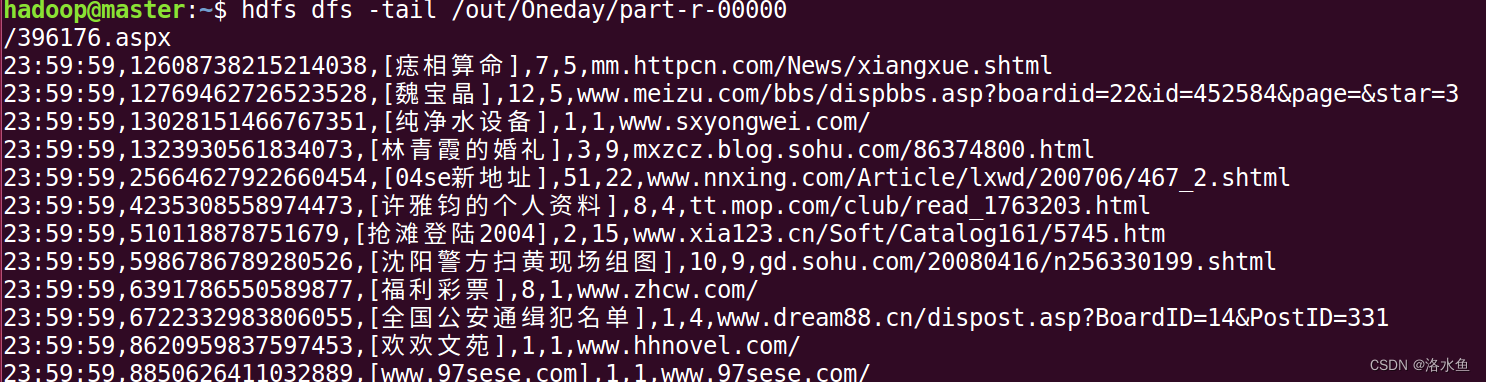
4.创建hive表
5.将MapReduce清洗后的数据导入Hive
4. 使用SQL查询满足条件的数据(只显示前10条)
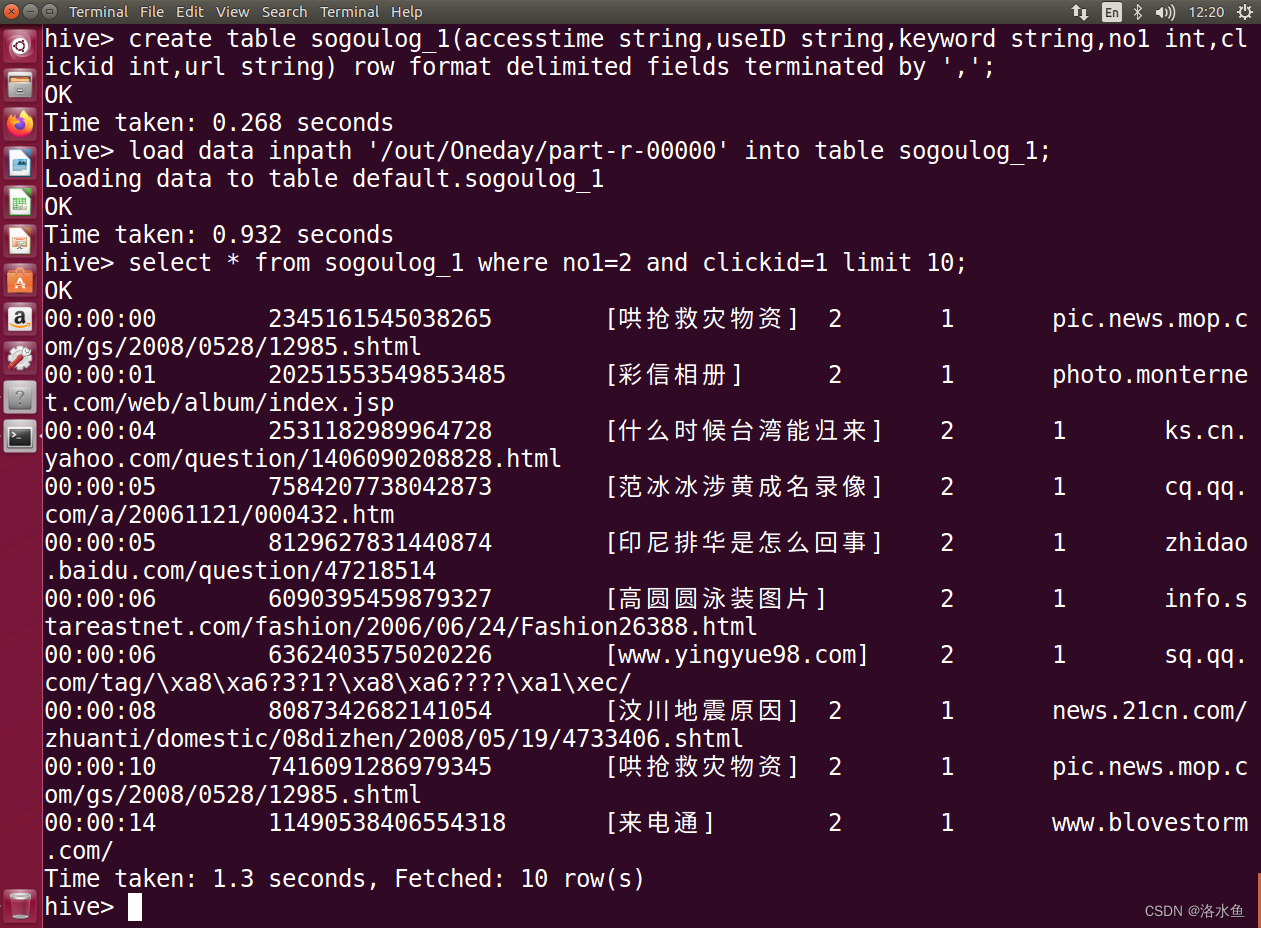
【注】有余力的同学可以考虑做分析结果的可视化
实验心得:
1:MySQL版本冲突的解决
2:不同的网络环境下Hive里面的配置IP需要更改,不然会出现命令运行不报错但一直等待的情况
3:运行时经常卡顿报错,建议提高虚拟机的内存