目录
项目数据及源码
可在github下载:
https://github.com/chenshunpeng/Stock-forecast-based-on-RNN
1.数据处理
1.1.导入数据
设置GPU环境
import tensorflow as tf
# 探测是否有GPU设备
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
# 指定哪些PhysicalDevice 对象对运行时可见。
# TensorFlow 只会在可见的物理设备上分配内存和放置操作,否则不会在它们上创建 LogicalDevice。
# 默认情况下,所有发现的设备都标记为可见
tf.config.set_visible_devices([gpus[0]], "GPU")
# 打印显卡信息,确认GPU可用
print(gpus)
显卡信息如下
[PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')]
引入头文件
import os, math
from tensorflow.keras.layers import Dropout, Dense, SimpleRNN
from sklearn.preprocessing import MinMaxScaler
from sklearn import metrics
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
加载数据
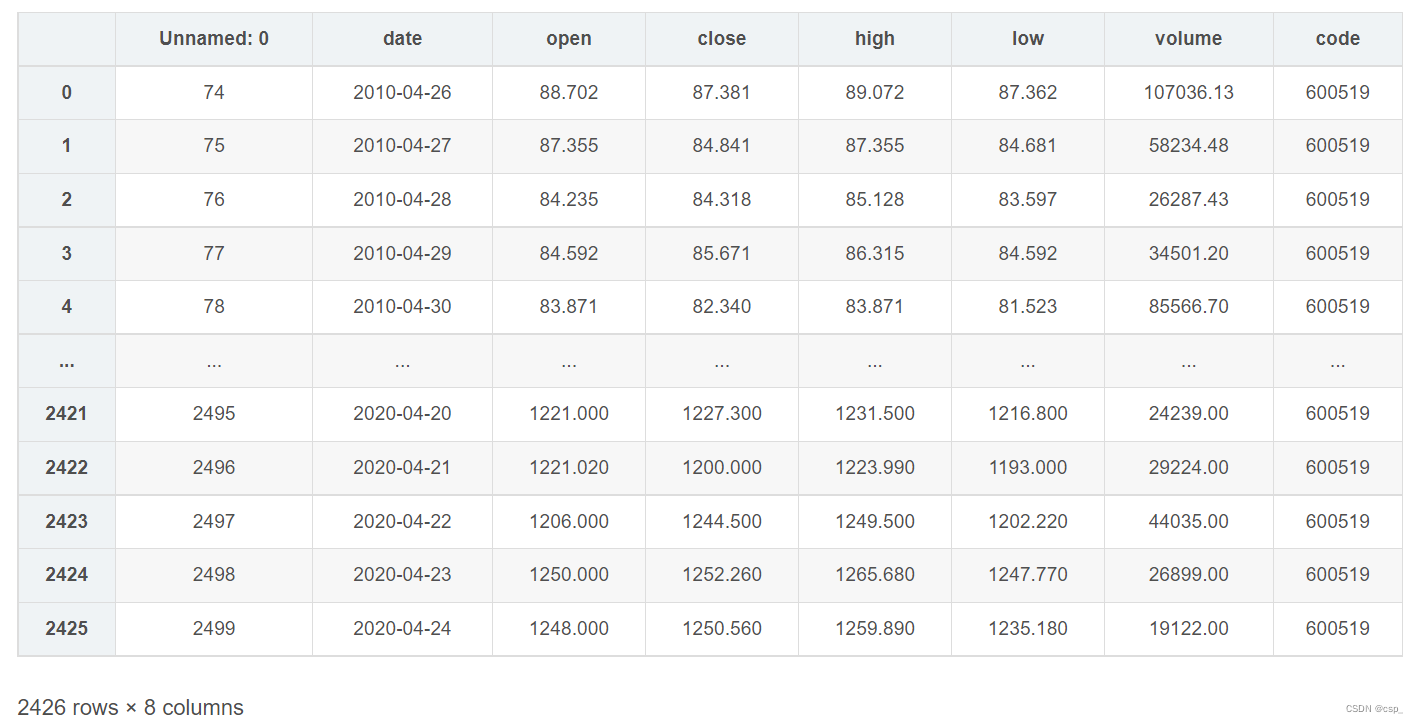
data = pd.read_csv('./datasets/data.csv') # 读取股票文件
# 粗略显示文件信息
data
文件信息显示如下:
取出C列开盘价(open列):
"""
前(2426-300=2126)天的开盘价作为训练集
后300天的开盘价作为测试集
表格从0开始计数,2:3 是提取[2:3)列,前闭后开,故提取出C列开盘价(open列)
"""
training_set = data.iloc[0:2426 - 300, 2:3].values
test_set = data.iloc[2426 - 300:, 2:3].values
# https://blog.csdn.net/weixin_43135178/article/details/124320736
# Pandas中loc和iloc函数(提取某几列或者行的数据)
查看training_set:
array([[ 88.702],
[ 87.355],
[ 84.235],
...,
[670.3 ],
[675.88 ],
[684. ]])
1.2.数据预处理
归一化
# https://blog.csdn.net/Fwuyi/article/details/123137074
# MinMaxScaler(feature_range=(0,1))(sklearn库)
sc = MinMaxScaler(feature_range=(0, 1))
training_set = sc.fit_transform(training_set)
test_set = sc.transform(test_set)
查看training_set:
array([[0.011711 ],
[0.00980951],
[0.00540518],
...,
[0.83272021],
[0.84059718],
[0.85205973]])
设置测试集训练集,这里使用前60天的开盘价作为输入特征x_train,第61天的开盘价作为输入标签y_train
for循环共构建2426-300-60=2066组训练数据,共构建300-60=260组测试数据
x_train = []
y_train = []
x_test = []
y_test = []
for i in range(60, len(training_set)):
x_train.append(training_set[i - 60:i, 0])
y_train.append(training_set[i, 0])
for i in range(60, len(test_set)):
x_test.append(test_set[i - 60:i, 0])
y_test.append(test_set[i, 0])
# 对训练集进行打乱
# 要对数据集乱序,输入特征是第1组数据,标签是第2组数据,要对输入特征和标签都做乱序,为了一一对应,就需要随机种子确定
# https://blog.csdn.net/qq_36201400/article/details/108512368
# tf.random.set_seed用法
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
将训练数据(list)调整为符合输入格式的数组(array)
最终目的:
x_train:(2066, 60, 1)
y_train:(2066,)
x_test :(240, 60, 1)
y_test :(240,)
x_train, y_train = np.array(x_train), np.array(y_train) # x_train形状为:(2066, 60, 1)
x_test, y_test = np.array(x_test), np.array(y_test)
查看x_train.shape:
(2066, 60)
查看x_test.shape:
(240, 60)
RNN网络输入要求:[送入样本数, 循环核时间展开步数, 每个时间步输入特征个数]
x_train = np.reshape(x_train, (x_train.shape[0], 60, 1))
x_test = np.reshape(x_test, (x_test.shape[0], 60, 1))
查看x_train.shape:
(2066, 60, 1)
查看x_test.shape:
(240, 60, 1)
2.网络设计
2.1.RNN介绍
RNN的介绍借鉴自:Recurrent Neural Network (RNN) Tutorial: Types, Examples, LSTM and More
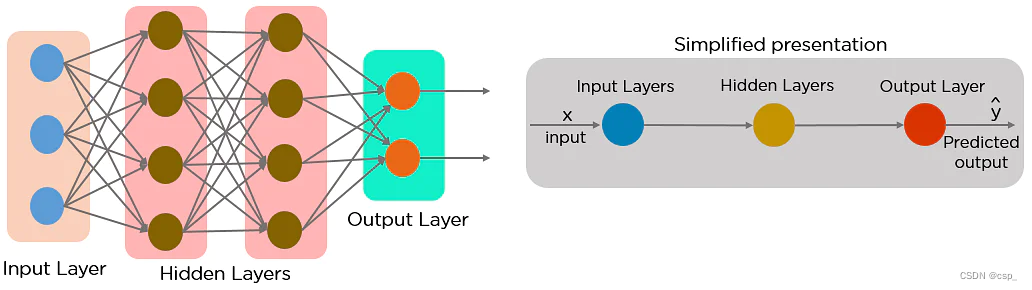
什么是神经网络?
神经网络由彼此连接的不同层组成,研究人脑的结构和功能。它从大量数据中学习,并使用复杂的算法来训练神经网络
这是神经网络(neural networks)如何根据其特征识别狗的品种的示例:
- 两种不同品种的狗的图像像素被馈送到神经网络的输入层
- 然后在隐藏层中处理图像像素以进行特征提取
- 输出层生成结果以识别它是德国牧羊犬还是拉布拉多犬
- 这样的网络不需要记住过去的输出
几个神经网络可以帮助解决不同的业务问题。让我们来看看其中的几个
- 前馈神经网络:用于一般回归和分类问题
- 卷积神经网络:用于对象检测和图像分类
- 深度信念网络:用于医疗保健领域的癌症检测
- 递归神经网络:用于语音识别、语音识别、时间序列预测和自然语言处理
什么是递归神经网络 (RNN)?
RNN的工作原理是保存特定层的输出并将其反馈给输入,以预测这一层的输出
前馈神经网络的简化表示方式:
以下是如何将前馈神经网络转换为递归神经网络:
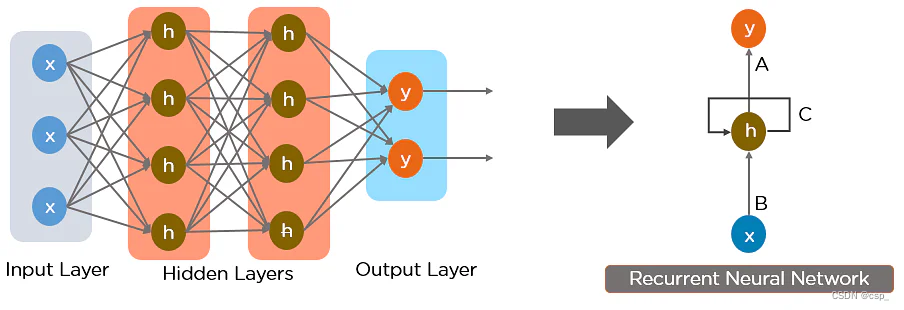
神经网络不同层中的节点被压缩形成单层递归神经网络:

这里, x x x 是输入层, h h h 是隐藏层, y y y 是输出层。 A A A、 B B B 和 C C C 是用于改进模型输出的网络参数。在任何给定时间 t t t,当前输入是 x ( t ) x(t) x(t) 和 x ( t − 1 ) x(t-1) x(t−1) 处输入的组合,任何给定时间的输出都会被提取回网络以改进输出
全连接递归神经网络图示:
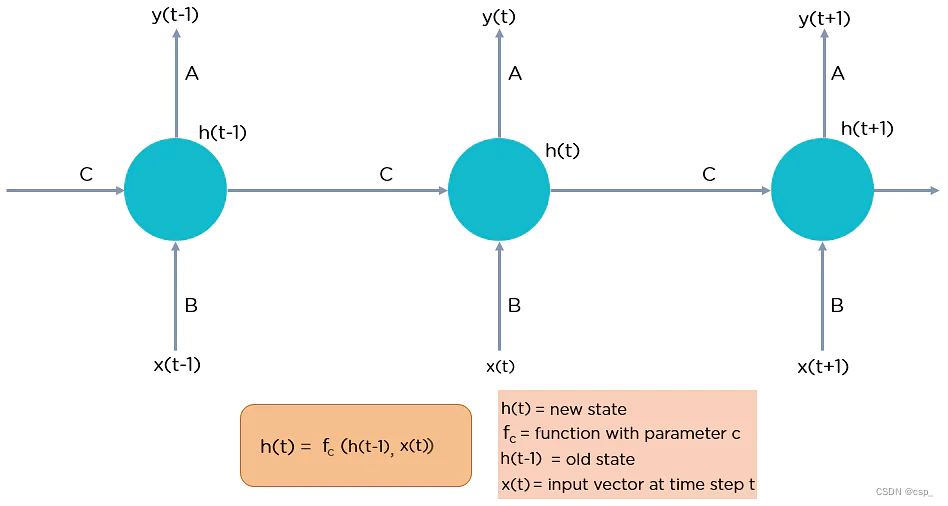
为什么选择递归神经网络?
创建RNN是因为前馈神经网络中存在一些问题:
- 无法处理顺序数据
- 仅考虑当前输入
- 无法记住以前的输入
RNN 可以处理顺序数据、接受当前输入数据和以前接收的输入
递归神经网络的工作原理:

输入层 x x x 接收神经网络的输入并对其进行处理并将其传递到中间层。
递归神经网络将标准化不同的激活函数以及权重和偏差,以便每个隐藏层具有相同的参数。然后,它不会创建多个隐藏层,而是创建一个隐藏层,并根据需要多次循环访问它
2.2.构建网络并训练
构建模型
这部分可看tensorflow官网:tf.keras.Sequential
首先通过model = tf.keras.Sequential()创建模型,之后通过model.add()方法搭建网络
model = tf.keras.Sequential([
SimpleRNN(100, return_sequences=True), #布尔值。是返回输出序列中的最后一个输出,还是全部序列。
Dropout(0.1), #防止过拟合
SimpleRNN(100),
Dropout(0.1),
Dense(1)
])
网络结构:
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn (SimpleRNN) (None, 60, 100) 10200
dropout (Dropout) (None, 60, 100) 0
simple_rnn_1 (SimpleRNN) (None, 100) 20100
dropout_1 (Dropout) (None, 100) 0
dense (Dense) (None, 1) 101
之后需要激活模型,官方激活模型的实例:
compile(
optimizer='rmsprop',
loss=None,
metrics=None,
loss_weights=None,
weighted_metrics=None,
run_eagerly=None,
steps_per_execution=None,
jit_compile=None,
**kwargs
)
我们这里是:
# 该应用只观测loss数值,不观测准确率,所以删去metrics选项,一会在每个epoch迭代显示时只显示loss值
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error') # 损失函数用均方误差
训练模型,官方给出的模块是:
fit(
x=None,
y=None,
batch_size=None,
epochs=1,
verbose='auto',
callbacks=None,
validation_split=0.0,
validation_data=None,
shuffle=True,
class_weight=None,
sample_weight=None,
initial_epoch=0,
steps_per_epoch=None,
validation_steps=None,
validation_batch_size=None,
validation_freq=1,
max_queue_size=10,
workers=1,
use_multiprocessing=False
)
我们这里是:
history = model.fit(x_train,
y_train,
batch_size=64,
epochs=50,
validation_data=(x_test, y_test),
validation_freq=1) #测试的epoch间隔数
model.summary()
2.3.训练结果(R2达到58.1%)
Epoch 1/50
33/33 [==============================] - 12s 302ms/step - loss: 0.1262 - val_loss: 0.0670
Epoch 2/50
33/33 [==============================] - 12s 363ms/step - loss: 0.0172 - val_loss: 0.0786
Epoch 3/50
33/33 [==============================] - 13s 377ms/step - loss: 0.0126 - val_loss: 0.0037
Epoch 4/50
33/33 [==============================] - 10s 300ms/step - loss: 0.0089 - val_loss: 0.0160
Epoch 5/50
33/33 [==============================] - 9s 285ms/step - loss: 0.0064 - val_loss: 0.0352
Epoch 6/50
33/33 [==============================] - 12s 371ms/step - loss: 0.0052 - val_loss: 0.0207
Epoch 7/50
33/33 [==============================] - 10s 303ms/step - loss: 0.0048 - val_loss: 0.0307
Epoch 8/50
33/33 [==============================] - 12s 355ms/step - loss: 0.0046 - val_loss: 0.0255
Epoch 9/50
33/33 [==============================] - 11s 326ms/step - loss: 0.0037 - val_loss: 0.0246
Epoch 10/50
33/33 [==============================] - 11s 336ms/step - loss: 0.0031 - val_loss: 0.0069
Epoch 11/50
33/33 [==============================] - 12s 362ms/step - loss: 0.0029 - val_loss: 0.0077
Epoch 12/50
33/33 [==============================] - 15s 466ms/step - loss: 0.0027 - val_loss: 0.0097
Epoch 13/50
33/33 [==============================] - 17s 519ms/step - loss: 0.0023 - val_loss: 0.0091
Epoch 14/50
33/33 [==============================] - 16s 491ms/step - loss: 0.0024 - val_loss: 0.0084
Epoch 15/50
33/33 [==============================] - 16s 493ms/step - loss: 0.0020 - val_loss: 0.0092
Epoch 16/50
33/33 [==============================] - 16s 480ms/step - loss: 0.0019 - val_loss: 0.0084
Epoch 17/50
33/33 [==============================] - 16s 481ms/step - loss: 0.0020 - val_loss: 0.0057
Epoch 18/50
33/33 [==============================] - 16s 490ms/step - loss: 0.0018 - val_loss: 0.0064
Epoch 19/50
33/33 [==============================] - 15s 467ms/step - loss: 0.0018 - val_loss: 0.0071
Epoch 20/50
33/33 [==============================] - 11s 319ms/step - loss: 0.0016 - val_loss: 0.0056
Epoch 21/50
33/33 [==============================] - 11s 324ms/step - loss: 0.0017 - val_loss: 0.0152
Epoch 22/50
33/33 [==============================] - 11s 328ms/step - loss: 0.0016 - val_loss: 0.0062
Epoch 23/50
33/33 [==============================] - 10s 310ms/step - loss: 0.0015 - val_loss: 0.0016
Epoch 24/50
33/33 [==============================] - 11s 335ms/step - loss: 0.0014 - val_loss: 0.0045
Epoch 25/50
33/33 [==============================] - 11s 346ms/step - loss: 0.0013 - val_loss: 0.0069
Epoch 26/50
33/33 [==============================] - 10s 308ms/step - loss: 0.0012 - val_loss: 0.0053
Epoch 27/50
33/33 [==============================] - 12s 352ms/step - loss: 0.0012 - val_loss: 0.0073
Epoch 28/50
33/33 [==============================] - 11s 325ms/step - loss: 0.0013 - val_loss: 0.0085
Epoch 29/50
33/33 [==============================] - 11s 335ms/step - loss: 0.0012 - val_loss: 0.0063
Epoch 30/50
33/33 [==============================] - 11s 340ms/step - loss: 0.0012 - val_loss: 0.0070
Epoch 31/50
33/33 [==============================] - 12s 353ms/step - loss: 0.0012 - val_loss: 0.0030
Epoch 32/50
33/33 [==============================] - 12s 361ms/step - loss: 0.0011 - val_loss: 0.0040
Epoch 33/50
33/33 [==============================] - 13s 390ms/step - loss: 9.9787e-04 - val_loss: 0.0047
Epoch 34/50
33/33 [==============================] - 11s 333ms/step - loss: 0.0010 - val_loss: 0.0062
Epoch 35/50
33/33 [==============================] - 12s 349ms/step - loss: 0.0011 - val_loss: 0.0059
Epoch 36/50
33/33 [==============================] - 15s 461ms/step - loss: 0.0011 - val_loss: 0.0090
Epoch 37/50
33/33 [==============================] - 11s 326ms/step - loss: 9.8275e-04 - val_loss: 0.0050
Epoch 38/50
33/33 [==============================] - 11s 321ms/step - loss: 0.0011 - val_loss: 0.0015
Epoch 39/50
33/33 [==============================] - 11s 326ms/step - loss: 9.5900e-04 - val_loss: 0.0018
Epoch 40/50
33/33 [==============================] - 11s 347ms/step - loss: 9.5788e-04 - val_loss: 0.0024
Epoch 41/50
33/33 [==============================] - 12s 352ms/step - loss: 8.9445e-04 - val_loss: 0.0114
Epoch 42/50
33/33 [==============================] - 12s 374ms/step - loss: 9.5272e-04 - val_loss: 0.0042
Epoch 43/50
33/33 [==============================] - 11s 328ms/step - loss: 8.0571e-04 - val_loss: 0.0035
Epoch 44/50
33/33 [==============================] - 10s 312ms/step - loss: 8.2984e-04 - val_loss: 0.0030
Epoch 45/50
33/33 [==============================] - 11s 338ms/step - loss: 7.7699e-04 - val_loss: 0.0035
Epoch 46/50
33/33 [==============================] - 11s 321ms/step - loss: 9.4940e-04 - val_loss: 0.0058
Epoch 47/50
33/33 [==============================] - 13s 393ms/step - loss: 7.7500e-04 - val_loss: 0.0065
Epoch 48/50
33/33 [==============================] - 15s 450ms/step - loss: 9.6614e-04 - val_loss: 0.0023
Epoch 49/50
33/33 [==============================] - 11s 323ms/step - loss: 7.4114e-04 - val_loss: 0.0028
Epoch 50/50
33/33 [==============================] - 11s 322ms/step - loss: 8.5990e-04 - val_loss: 0.0068
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn (SimpleRNN) (None, 60, 100) 10200
dropout (Dropout) (None, 60, 100) 0
simple_rnn_1 (SimpleRNN) (None, 100) 20100
dropout_1 (Dropout) (None, 100) 0
dense (Dense) (None, 1) 101
=================================================================
Total params: 30,401
Trainable params: 30,401
Non-trainable params: 0
_________________________________________________________________
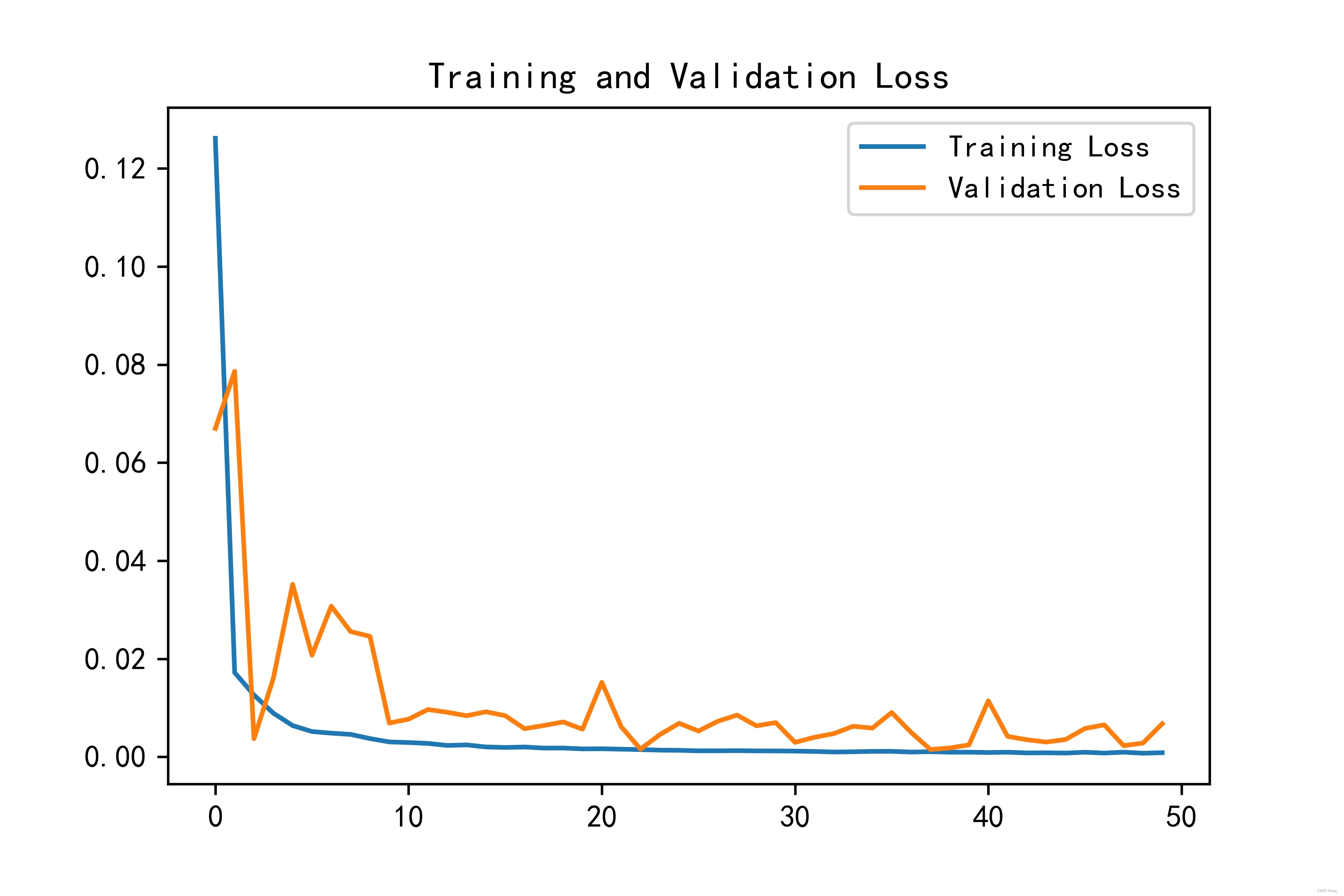
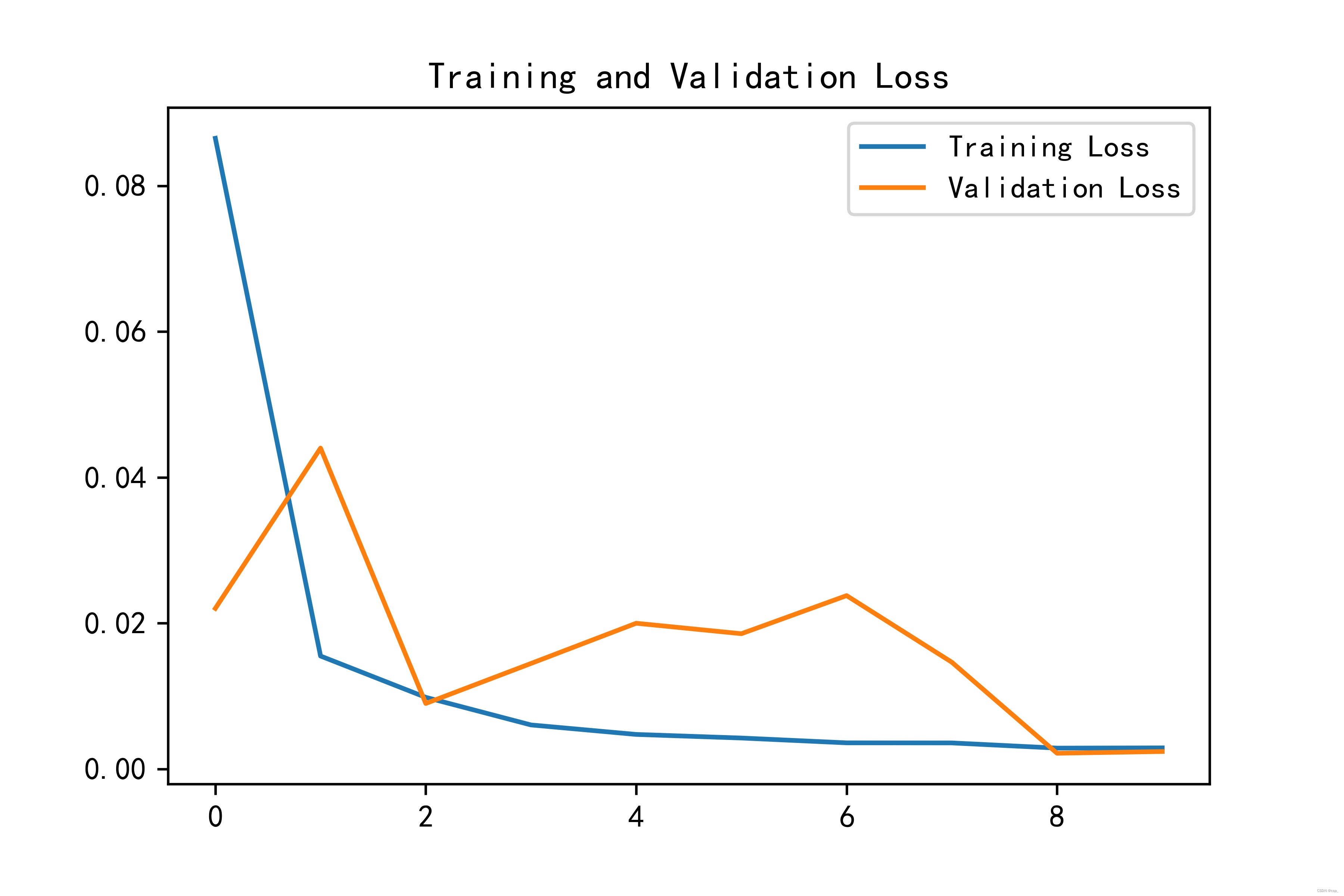
绘制loss图
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Training and Validation Loss')
plt.legend()
plt.savefig('pic1.jpg', dpi=600) #指定分辨率保存
plt.show()
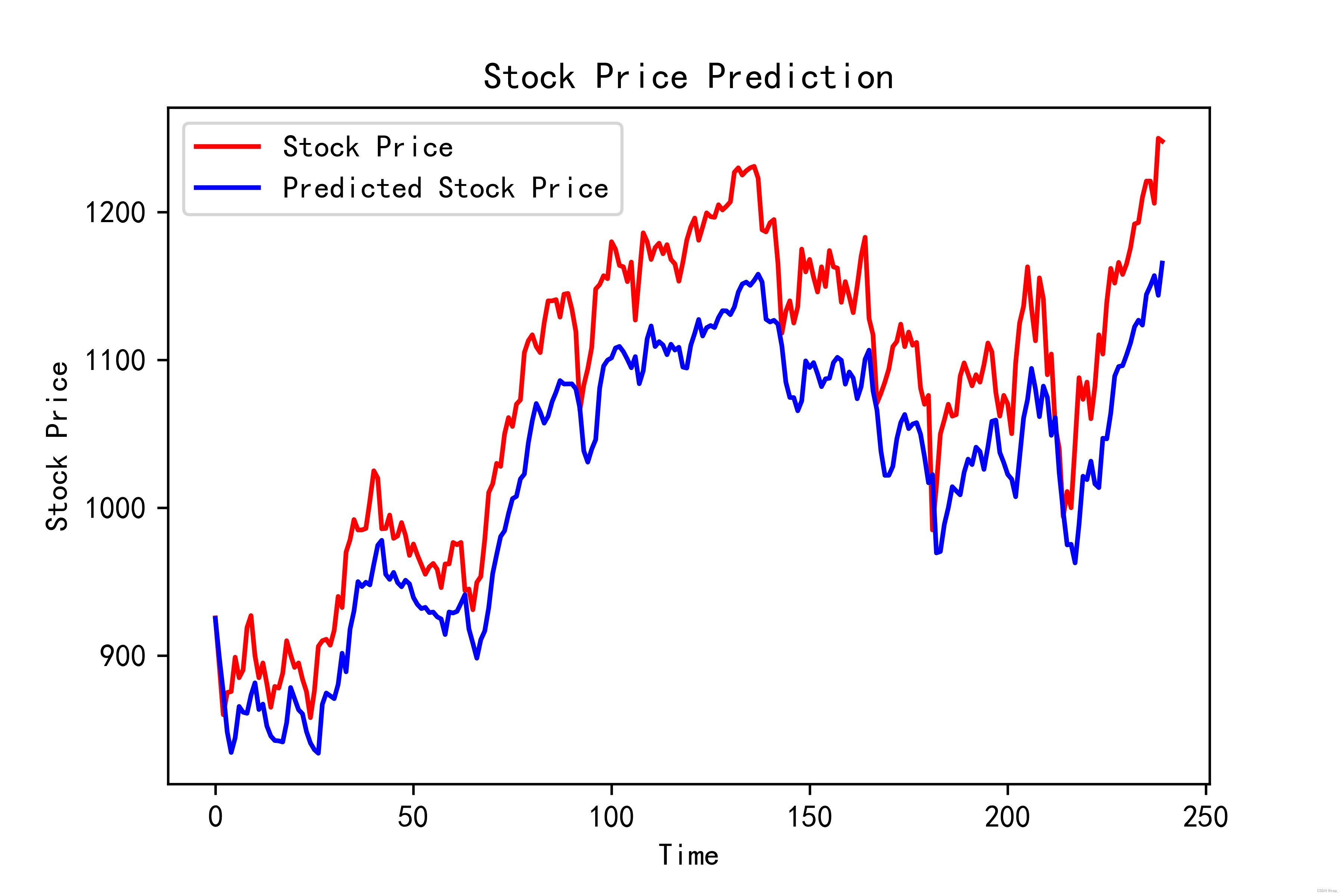
2.4.进行预测
predicted_stock_price = model.predict(x_test) # 测试集输入模型进行预测
predicted_stock_price = sc.inverse_transform(
predicted_stock_price) # 对预测数据还原---从(0,1)反归一化到原始范围
real_stock_price = sc.inverse_transform(
test_set[60:]) # 对真实数据还原---从(0,1)反归一化到原始范围
# 画出真实数据和预测数据的对比曲线
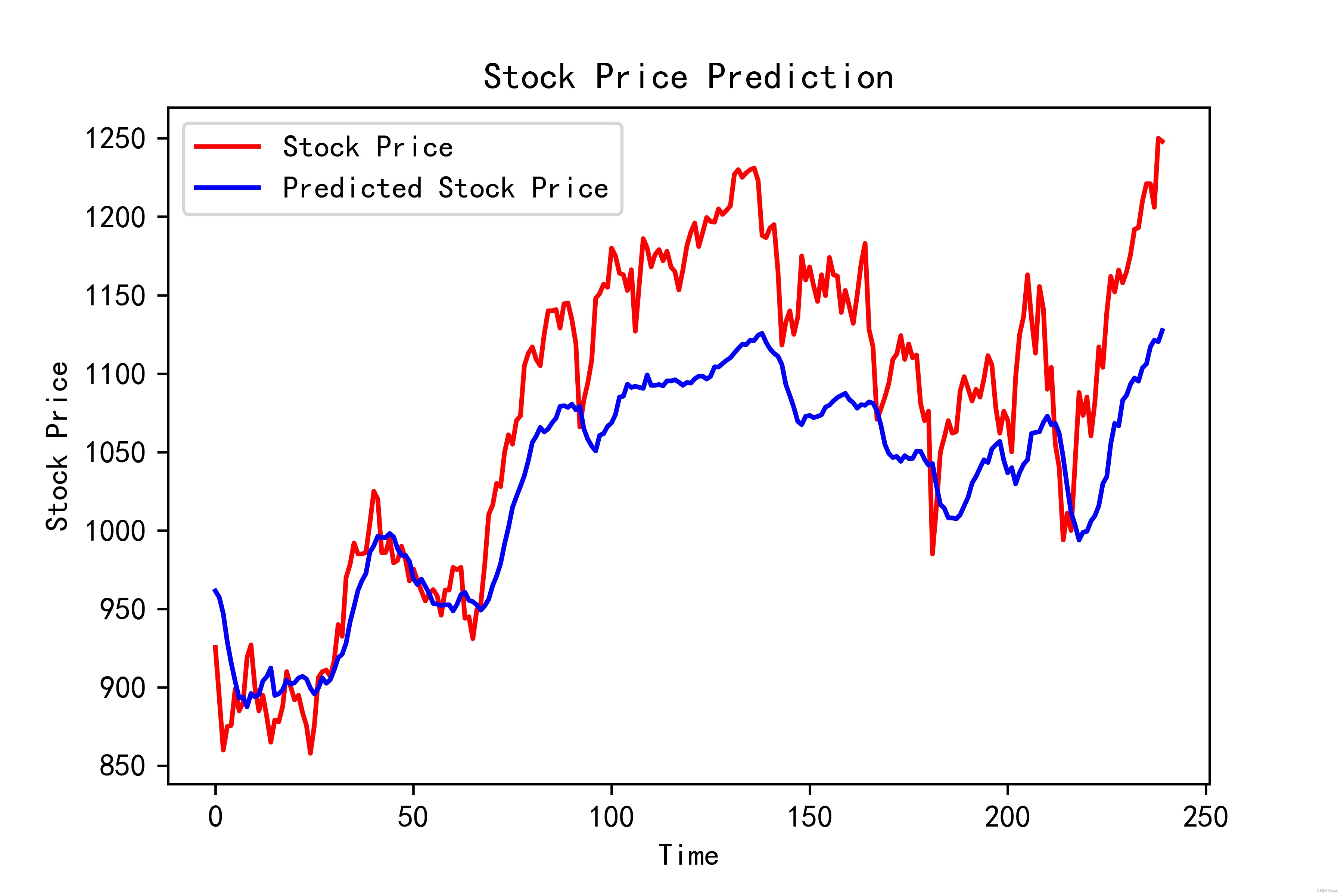
plt.plot(real_stock_price, color='red', label='Stock Price')
plt.plot(predicted_stock_price, color='blue', label='Predicted Stock Price')
plt.title('Stock Price Prediction')
plt.xlabel('Time')
plt.ylabel('Stock Price')
plt.legend()
plt.savefig('pic2.jpg', dpi=600) #指定分辨率保存
plt.show()
评估:
MSE :均方误差 -----> 预测值减真实值求平方后求均值
RMSE :均方根误差 -----> 对均方误差开方
MAE :平均绝对误差-----> 预测值减真实值求绝对值后求均值
R2 :决定系数,可以简单理解为反映模型拟合优度的重要的统计量
这些误差的介绍可以参考文章:传送门
MSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)
RMSE = metrics.mean_squared_error(predicted_stock_price, real_stock_price)**0.5
MAE = metrics.mean_absolute_error(predicted_stock_price, real_stock_price)
R2 = metrics.r2_score(predicted_stock_price, real_stock_price)
print('均方误差: %.5f' % MSE)
print('均方根误差: %.5f' % RMSE)
print('平均绝对误差: %.5f' % MAE)
print('R2: %.5f' % R2)
输出:
均方误差: 3395.28758
均方根误差: 58.26910
平均绝对误差: 53.76161
R2: 0.58054
3.网络优化
我们可以看到训练至20次的时候,train loss 不断下降,test loss趋于不变,说明网络过拟合
我们在设计网络结构的时候有SimpleRNN(100, return_sequences=True)这样一行代码,这个参数默认为False
其概念定义(传送门):
return_sequences: Boolean. Whether to return the last output. in the output sequence, or the full sequence. Default:False.
设置为True:输出为 (样本数,输出维度) 的 2D 张量
设置为False:输出为 (样本数,中间每步的神经元计算输出timesteps,输出维度) 的 3D 张量
根据不同的情况,可以选择只输出结论,或者全部中间过程都保留,通常在需要将各个隐层的结果作为下一层的输入时,选择设置return_sequences=True
3.1.修改网络的RNN个数
SimpleRNN部分可看tensorflow官网:传送门
我们再加一层RNN,迭代10次效果如下:
Epoch 1/10
33/33 [==============================] - 12s 309ms/step - loss: 0.2287 - val_loss: 0.0179
Epoch 2/10
33/33 [==============================] - 10s 319ms/step - loss: 0.1363 - val_loss: 0.0912
Epoch 3/10
33/33 [==============================] - 11s 326ms/step - loss: 0.0967 - val_loss: 0.0519
Epoch 4/10
33/33 [==============================] - 11s 324ms/step - loss: 0.0569 - val_loss: 0.0235
Epoch 5/10
33/33 [==============================] - 11s 324ms/step - loss: 0.0370 - val_loss: 0.0499
Epoch 6/10
33/33 [==============================] - 11s 318ms/step - loss: 0.0242 - val_loss: 0.0431
Epoch 7/10
33/33 [==============================] - 12s 377ms/step - loss: 0.0155 - val_loss: 0.0260
Epoch 8/10
33/33 [==============================] - 14s 438ms/step - loss: 0.0152 - val_loss: 0.0341
Epoch 9/10
33/33 [==============================] - 14s 416ms/step - loss: 0.0115 - val_loss: 0.0351
Epoch 10/10
33/33 [==============================] - 13s 398ms/step - loss: 0.0097 - val_loss: 0.0080
Model: "sequential_8"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn_20 (SimpleRNN) (None, 60, 100) 10200
dropout_20 (Dropout) (None, 60, 100) 0
simple_rnn_21 (SimpleRNN) (None, 60, 100) 20100
dropout_21 (Dropout) (None, 60, 100) 0
simple_rnn_22 (SimpleRNN) (None, 100) 20100
dropout_22 (Dropout) (None, 100) 0
dense_8 (Dense) (None, 1) 101
=================================================================
Total params: 50,501
Trainable params: 50,501
Non-trainable params: 0
_________________________________________________________________
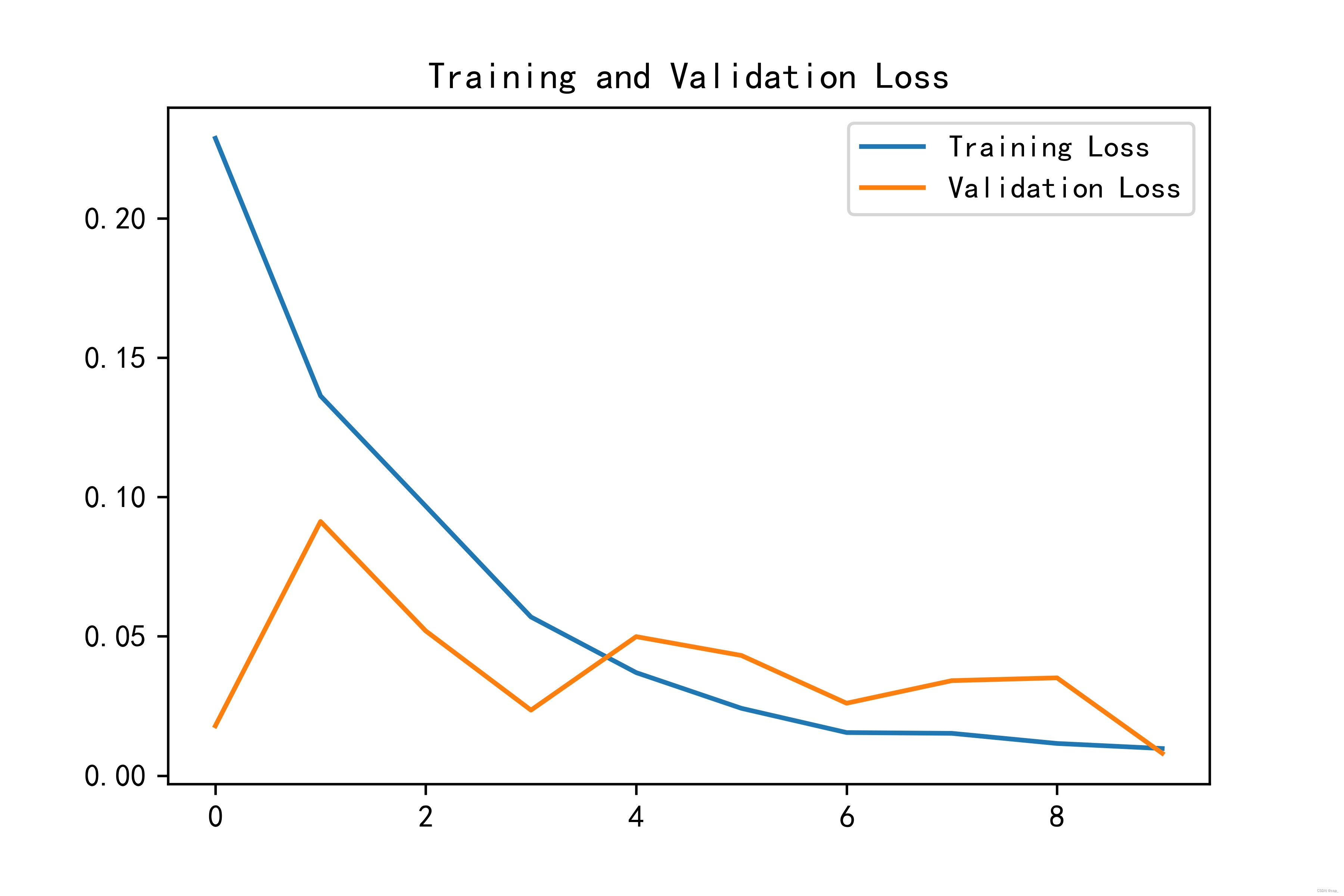
均方误差: 4034.04490
均方根误差: 63.51413
平均绝对误差: 53.89802
R2: 0.10803
可以看出来还是过拟合了
3.2.修改RNN网络的参数量
如果加大参数量:
model = tf.keras.Sequential([
SimpleRNN(200, return_sequences=True), #布尔值。是返回输出序列中的最后一个输出,还是全部序列。
Dropout(0.1), #防止过拟合
SimpleRNN(100),
Dropout(0.1),
Dense(1)
])
结果:
Epoch 1/10
33/33 [==============================] - 8s 198ms/step - loss: 0.1811 - val_loss: 0.1024
Epoch 2/10
33/33 [==============================] - 6s 190ms/step - loss: 0.0120 - val_loss: 0.0645
Epoch 3/10
33/33 [==============================] - 6s 194ms/step - loss: 0.0086 - val_loss: 0.0405
Epoch 4/10
33/33 [==============================] - 6s 193ms/step - loss: 0.0067 - val_loss: 0.0526
Epoch 5/10
33/33 [==============================] - 6s 190ms/step - loss: 0.0053 - val_loss: 0.0492
Epoch 6/10
33/33 [==============================] - 7s 206ms/step - loss: 0.0041 - val_loss: 0.0236
Epoch 7/10
33/33 [==============================] - 6s 186ms/step - loss: 0.0031 - val_loss: 0.0235
Epoch 8/10
33/33 [==============================] - 6s 193ms/step - loss: 0.0032 - val_loss: 0.0245
Epoch 9/10
33/33 [==============================] - 7s 205ms/step - loss: 0.0027 - val_loss: 0.0372
Epoch 10/10
33/33 [==============================] - 7s 211ms/step - loss: 0.0030 - val_loss: 0.0233
Model: "sequential_10"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn_26 (SimpleRNN) (None, 60, 200) 40400
dropout_26 (Dropout) (None, 60, 200) 0
simple_rnn_27 (SimpleRNN) (None, 100) 30100
dropout_27 (Dropout) (None, 100) 0
dense_10 (Dense) (None, 1) 101
=================================================================
Total params: 70,601
Trainable params: 70,601
Non-trainable params: 0
_________________________________________________________________
3.3.修改Dropout(R2达到81.6%)
通俗易懂的说,dropout的作用就是随机的裁减掉一部分神经元,以防止神经元之间的相互影响造成结果的不稳定和模型的过拟合,提高模型的泛化能力
函数原型:
tf.keras.layers.Dropout(
rate, noise_shape=None, seed=None, **kwargs
)
dropout部分介绍可看tensorflow官网:传送门
既然效果还不如第一次好,我们不如提高Dropout,然后训练10次:
model = tf.keras.Sequential([
SimpleRNN(110, return_sequences=True), #布尔值。是返回输出序列中的最后一个输出,还是全部序列。
Dropout(0.2), #防止过拟合
SimpleRNN(110),
Dropout(0.1),
Dense(1)
])
结果:
Epoch 1/10
33/33 [==============================] - 8s 213ms/step - loss: 0.0865 - val_loss: 0.0220 ETA: 1s - los
Epoch 2/10
33/33 [==============================] - 7s 206ms/step - loss: 0.0155 - val_loss: 0.0440
Epoch 3/10
33/33 [==============================] - 7s 208ms/step - loss: 0.0098 - val_loss: 0.0090
Epoch 4/10
33/33 [==============================] - 7s 215ms/step - loss: 0.0060 - val_loss: 0.0145
Epoch 5/10
33/33 [==============================] - 7s 209ms/step - loss: 0.0047 - val_loss: 0.0200
Epoch 6/10
33/33 [==============================] - 7s 201ms/step - loss: 0.0042 - val_loss: 0.0185
Epoch 7/10
33/33 [==============================] - 7s 204ms/step - loss: 0.0036 - val_loss: 0.0238
Epoch 8/10
33/33 [==============================] - 7s 202ms/step - loss: 0.0036 - val_loss: 0.0146
Epoch 9/10
33/33 [==============================] - 7s 199ms/step - loss: 0.0029 - val_loss: 0.0021
Epoch 10/10
33/33 [==============================] - 7s 202ms/step - loss: 0.0029 - val_loss: 0.0024 1s - los
Model: "sequential_17"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn_40 (SimpleRNN) (None, 60, 110) 12320
dropout_40 (Dropout) (None, 60, 110) 0
simple_rnn_41 (SimpleRNN) (None, 110) 24310
dropout_41 (Dropout) (None, 110) 0
dense_17 (Dense) (None, 1) 111
=================================================================
Total params: 36,741
Trainable params: 36,741
Non-trainable params: 0
_________________________________________________________________
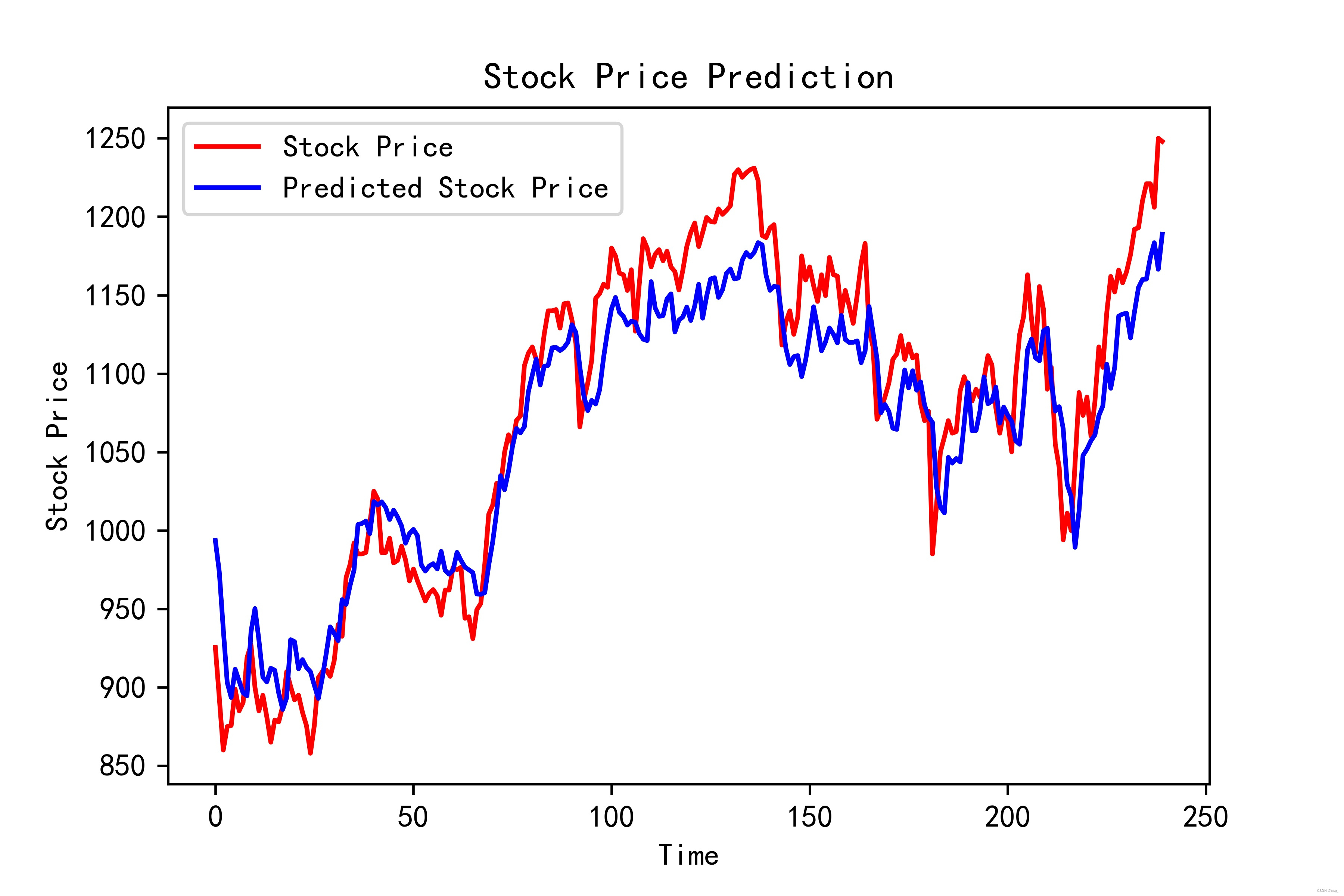
R2达到了81.6%,还是很不错的
均方误差: 1195.69426
均方根误差: 34.57881
平均绝对误差: 28.94272
R2: 0.81633
最后保存模型即可:
# 保存模型
model.save('model_81.6%')
4.tensorboard可视化
配置gpu:
import tensorflow as tf
gpus = tf.config.list_physical_devices("GPU")
if gpus:
tf.config.experimental.set_memory_growth(gpus[0], True) #设置GPU显存用量按需使用
tf.config.set_visible_devices([gpus[0]], "GPU")
配置网络:
import os, math
from tensorflow.keras.layers import Dropout, Dense, SimpleRNN
from sklearn.preprocessing import MinMaxScaler
from sklearn import metrics
import numpy as np
import pandas as pd
import tensorflow as tf
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
data = pd.read_csv('./datasets/data.csv') # 读取股票文件
training_set = data.iloc[0:2426 - 300, 2:3].values
test_set = data.iloc[2426 - 300:, 2:3].values
sc = MinMaxScaler(feature_range=(0, 1))
training_set = sc.fit_transform(training_set)
test_set = sc.transform(test_set)
x_train = []
y_train = []
x_test = []
y_test = []
"""
使用前60天的开盘价作为输入特征x_train
第61天的开盘价作为输入标签y_train
for循环共构建2426-300-60=2066组训练数据。
共构建300-60=260组测试数据
"""
for i in range(60, len(training_set)):
x_train.append(training_set[i - 60:i, 0])
y_train.append(training_set[i, 0])
for i in range(60, len(test_set)):
x_test.append(test_set[i - 60:i, 0])
y_test.append(test_set[i, 0])
# 对训练集进行打乱
# 要对数据集乱序,输入特征是第1组数据,标签是第2组数据,要对输入特征和标签都做乱序,为了一一对应,就需要随机种子确定
# https://blog.csdn.net/qq_36201400/article/details/108512368
# tf.random.set_seed用法
np.random.seed(7)
np.random.shuffle(x_train)
np.random.seed(7)
np.random.shuffle(y_train)
tf.random.set_seed(7)
x_train, y_train = np.array(x_train), np.array(y_train) # x_train形状为:(2066, 60, 1)
x_test, y_test = np.array(x_test), np.array(y_test)
x_train = np.reshape(x_train, (x_train.shape[0], 60, 1))
x_test = np.reshape(x_test, (x_test.shape[0], 60, 1))
model = tf.keras.Sequential([
SimpleRNN(110, return_sequences=True), #布尔值。是返回输出序列中的最后一个输出,还是全部序列。
Dropout(0.2), #防止过拟合
SimpleRNN(110),
Dropout(0.1),
Dense(1)
])
# 该应用只观测loss数值,不观测准确率,所以删去metrics选项,一会在每个epoch迭代显示时只显示loss值
model.compile(optimizer=tf.keras.optimizers.Adam(0.001),
loss='mean_squared_error') # 损失函数用均方误差
进行训练并可视化
##定义回调函数
log_dir = os.path.join(r'E:\demo_study\jupyter\Jupyter_notebook\Stock-forecast-based-on-RNN\tensorboard')
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir,histogram_freq=1)
history = model.fit(x_train,
y_train,
batch_size=64,
epochs=10,
validation_data=(x_test, y_test),
validation_freq=1, #测试的epoch间隔数
callbacks=[tensorboard_callback])
model.summary()
输出:
Train on 2066 samples, validate on 240 samples
Epoch 1/10
C:\Users\HP ZBook15\AppData\Roaming\Python\Python37\site-packages\keras\engine\training_v1.py:2045: UserWarning: `Model.state_updates` will be removed in a future version. This property should not be used in TensorFlow 2.0, as `updates` are applied automatically.
updates = self.state_updates
2066/2066 [==============================] - 8s 4ms/sample - loss: 0.0547 - val_loss: 0.0090
Epoch 2/10
2066/2066 [==============================] - 5s 2ms/sample - loss: 0.0112 - val_loss: 0.0404
Epoch 3/10
2066/2066 [==============================] - 5s 2ms/sample - loss: 0.0071 - val_loss: 0.0451
Epoch 4/10
2066/2066 [==============================] - 6s 3ms/sample - loss: 0.0052 - val_loss: 0.0254
Epoch 5/10
2066/2066 [==============================] - 6s 3ms/sample - loss: 0.0041 - val_loss: 0.0162
Epoch 6/10
2066/2066 [==============================] - 5s 3ms/sample - loss: 0.0032 - val_loss: 0.0362
Epoch 7/10
2066/2066 [==============================] - 5s 2ms/sample - loss: 0.0031 - val_loss: 0.0402
Epoch 8/10
2066/2066 [==============================] - 5s 2ms/sample - loss: 0.0026 - val_loss: 0.0173
Epoch 9/10
2066/2066 [==============================] - 6s 3ms/sample - loss: 0.0024 - val_loss: 0.0068
Epoch 10/10
2066/2066 [==============================] - 6s 3ms/sample - loss: 0.0023 - val_loss: 0.0072
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
simple_rnn (SimpleRNN) multiple 12320
dropout (Dropout) multiple 0
simple_rnn_1 (SimpleRNN) multiple 24310
dropout_1 (Dropout) multiple 0
dense (Dense) multiple 111
=================================================================
Total params: 36,741
Trainable params: 36,741
Non-trainable params: 0
_________________________________________________________________
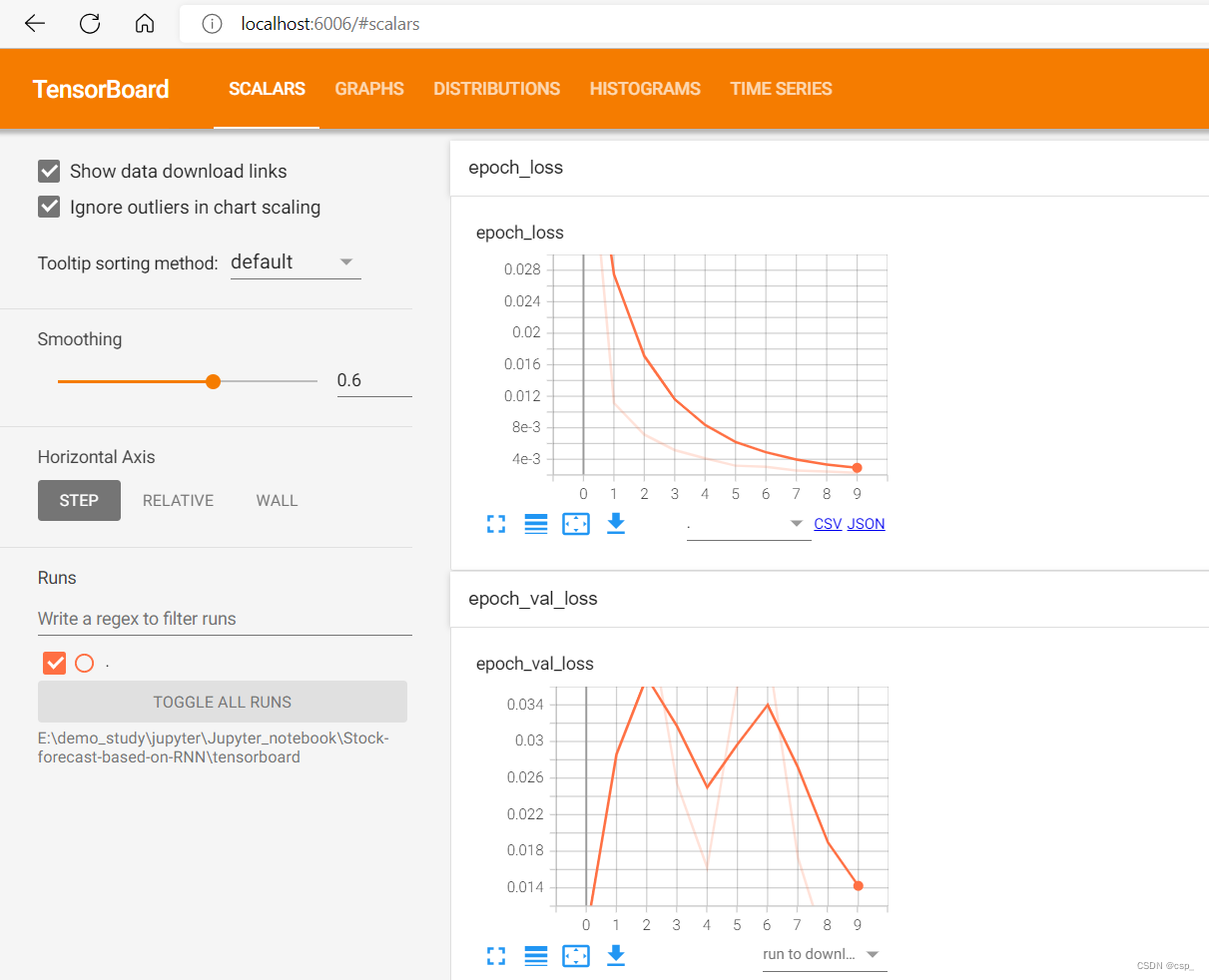
在我这里输入如下命令即可看到 tensorboard 的可视化:
tensorboard --logdir="E:\demo_study\jupyter\Jupyter_notebook\Stock-forecast-based-on-RNN\tensorboard"
之后在 http://localhost:6006/ 打开 tensorboard 即可: