一个以内容服务为主的软件,它的推荐系统在数据侧对软件产生着举足轻重的作用。数据的三个方面决定了这个内容软件的档次。
- 数据的质量好坏
- 数据和用户需求的相关性好坏
- 数据的层次体系好坏
通常,我们说的推荐,包含了两类不同的推荐
- 内容详情页下的相关推荐
- 软件主视图的各种推荐等信息流,属于【个性化推荐】部分
本文介绍的是我们在CSDN的软件主视图的各种推荐等信息流部分的持续改进工作。这部分在各种不同的技术浪潮下,容易发生这些问题
- 优先级不高,整个系统处于年久失修状态
- 推荐系统依赖的数据链路不通,数据处于不健康状态
- 研发人员的多次转换,后面新增的代码和前人加的代码之间有矛盾和冲突的地方
- 最可怕的是,一些策略事实上已经出错,但是也无人知晓和改进
- 缺乏最新的构架和全局链路信息地图
本文侧重在个性化推荐系统治理中的4种重要的工程保证:
- 梳理大地图:有持续维护的最新构架和全局链路信息地图
- 工具构建:支持必要的数据解析和非常规的调试工具
- 数据治理:持续梳理和简化数据侧的工作
- 保持发布:坚决执行SMART原则,拆和推进的能上线的任务
- 重视测试:深入细节的测试
大地图
首先我的同事介绍了在《CSDN个性化推荐系统的设计和演化》,介绍了许多在服务代码层面做的持续的重构工作。这部分工作基本上需要持续有耐心地将系统的每个部分都梳理、重构、迭代、上线。
从系统治理的角度来说,服务代码的直接重构是系统中的一个最重要的环节,但不是全部。这是因为这样的系统包含对多个部分的理解:
- 服务接口部分:下游如何使用系统的接口,下游对推荐服务的接口做了哪些进一步的加工工作后,才能和应用层对接上。
- 服务策略部分:也就是推荐服务本身(如上文章)
- 服务数据部分:在上述文章里构架图里的Habse的数据来自哪里?
所以,从系统治理的角度,大概构架图这样的:
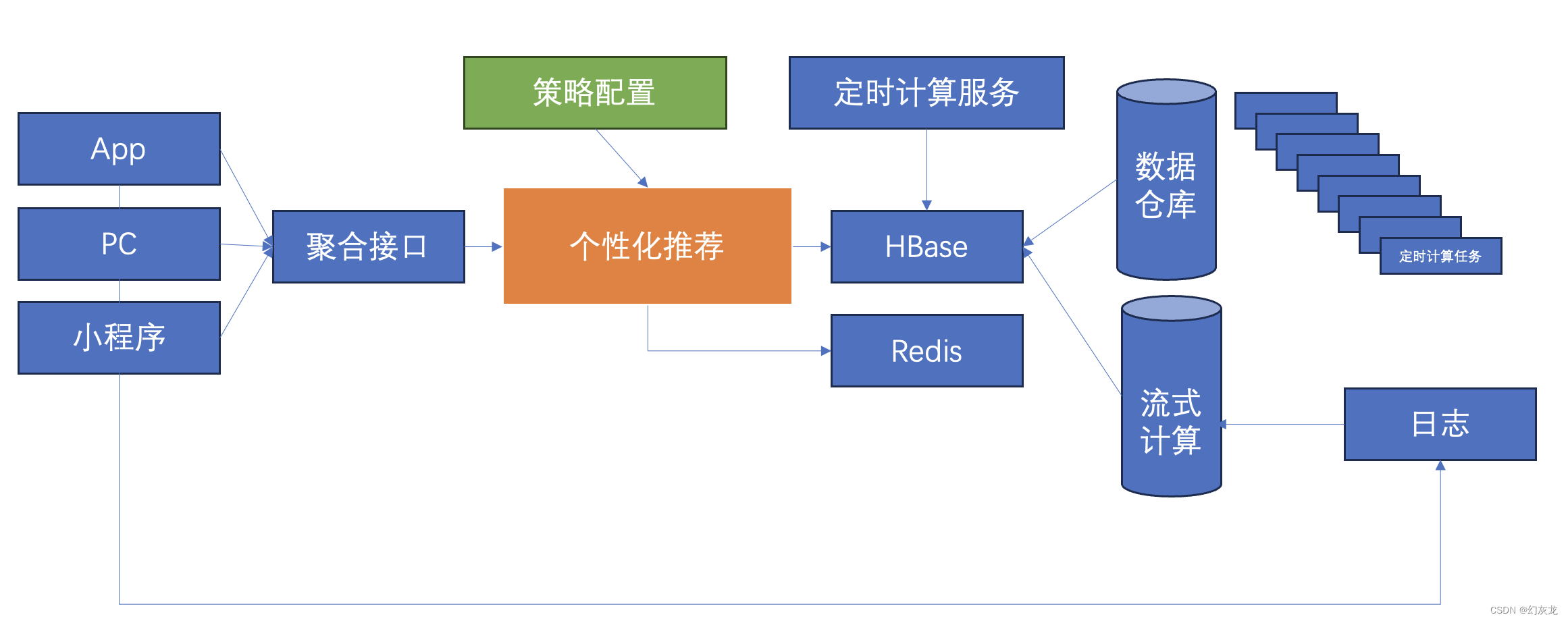
在系统治理的过程中,需要完整的梳理3个环节是如何工作的:
- 聚合接口部分如何工作
- 个性化推荐和策略配置部分如何工作
- 数据源部分如何工作,和配置之间的关系(包括:定时计算服务、数据仓库的几十个计算任务、以及流式计算部分)
没有全链路信息,我们就是在盲人摸象,这是系统工程,需要严肃的工程和数据质量。
在整个系统治理期间,工程上的做法是:
- 从头到位维护一份持续更新的个推数据管道流向的文档
- 使用分层、表格梳理的方式梳理全链路的数据流向
- 以数据流动和朔源为驱动
- 服务研发、测试、数据研发联合持续更新
- 以数据流动和朔源为驱动
- 使用分层、表格梳理的方式梳理全链路的数据流向
工具构建
我们都知道,在工程上,维持开发/测试/正式三件套的完整分离的环境对于健康项目的迭代是非常重要的。但是我们也经常遇到一些系统由于历史的各种原因,并不完整的具有开发/测试/正式三件套环境。这给开发、测试和验证功能带来了很大的麻烦。
但是作为工程师,我们必须解决问题,有时候不能等着理想环境的出现(这是一个代价的问题)。因此,我们支持研发花时间构建在线上系统诊断工具。这个系统原有一些简单的线上接口调试信息获取能力。但是对于初期诊断那些疑难问题还是信息不够。这部分也是通常所的「可观测性」。
我的同事付出努力,构建了一套相对完备的易于使用的线上系统诊断 inspect 接口,这位后续的诸多问题定位解决带来了极大的便利。
其次,该推荐系统的策略配置一堆json定义的组合配置,代码中需要解析这些组合配置动态构建出策略树,本质上是一个有向无环图的数据结构。这里的问题是配置的和代码之间的映射,如果单靠看配置是很难定位和诊断问题的。旧的工程师也开发了一个可视化的工具来呈现这个有向无环图,但是
- 一方面这些工具久无维护就失去了时效性
- 另一方面策略多了之后,可视化工具也并不方便查看
- 最后在节点和源代码之间的映射信息不够完全,难以直接映射
这个问题一度是研发中的瓶颈问题。这个和前一节是一样的:在系统治理中,如果没有好的工具支持对全局信息或者局部重要信息的快速定位,它就会成为解决问题的瓶颈。
于是,我们写了一个策略配置的解析工具,将线性的配置,解析成符合实际代码嵌套的管道紧凑json,将有向无环图的骨架快速展示出来,便于定位和诊断,包含多种中间格式的数据。实际上这是一种复合利用文本解决问题的Unix风格做法。
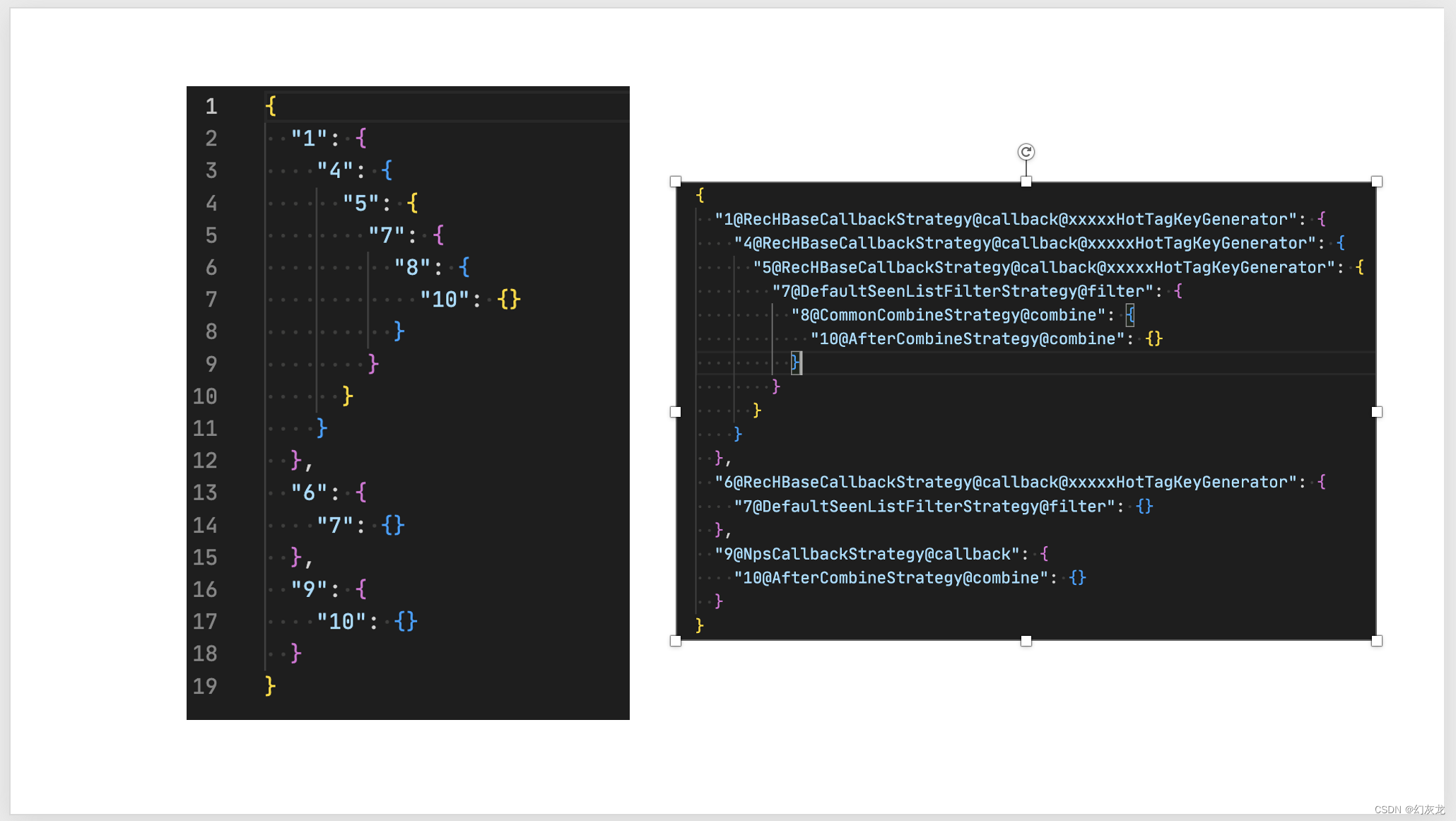
图示是一个小的策略配置例子,具体信息对于系统研发来说有着具体的含义,这样的组合链路,如果繁杂起来但是没有便利的展示,用以快速定位到源代码中具体的类和配置,会十分费劲。
这部分,我们的经验是:投资工具,使得系统问题诊断能快速而直接,从而让研发循环周期更小。
数据治理
我们在系统治理过程中,遵循一些原则使得系统逐渐更加简单可依赖:
- 尽可能简化服务代码层的工作,服务代码层做有技术含量的策略配置和反馈机制
- 尽可能在数据层解决问题,因为数据层的工作在可维护上研发周期更短,小到按小时就可以解决。
这部分的工作。我们数据层的研发同事会有专门的技术博客分析:《CSDN 个性化推荐的数据治理》
但是我们在这个过程中,坚持持续的梳理所有的数据计算任务:
- 清理旧的实效的数据
- 合并冗余的策略
- 减少特异性规则
- 使用上AI层的新的结构化数据特征
- 构建完备的控制api
这层工作,核心是要体现:数据驱动。
保持发布
大的系统治理,有一个麻烦的地方在于如何保持迭代周期。在工程上,有一个重要的原则是:“保持发布是硬道理”。如果某个工作,想的太多,想要改造的步伐太大,常常会导致系统在工程上不收敛,这是绝大部分研发都会遇到的问题。
不过我们通过一些策略,比较合适的规避了这样的问题。大概有这些方式:
- 有了大地图,使得我们能比较清晰地判断:
- “这是一个适合在数据层解决的问题”
- “这是一个适合在策略层解决的问题”
- “这是一个适合在聚合层解决的问题”
- …
- 有了工具,使得我们能在DAG部分的配置快速定位问题
- “根据这个链路骨架,出问题的应该是这个环节”
- “根据这个链路骨架,可以在这层加入特性解决问题”
- “根据这个链路骨架,这两层做的事情是冲突的,应该合并到一起”
- …
- 有了数据层的梳理,使得我们可以快速确认
- “快速找到数据的源头,检查数据源头是否有问题,如果能通过源头解决,中间就不要动”
- “数据层可以做更多的事情,提供更完备信息后,策略层就可以去掉一大块原来很绕的逻辑…”
- …
对于需要多环节配合的任务,一般的方式是:
- 数据侧先准备数据
- 数据层的数据ready后,策略层再跟进改进
- 测试验证策略层接口没有问题后,先通过api发布的方式迭代上线
- 策略层api已经ready后,再推进聚合层接口的改造…
- …
通过多阶段的发布,避免端到端研发带来的各种弊端。
重视测试
关键的一部分,我们的测试熟悉系统每个环节的工作原理。使得测试能在每个环节的迭代中,深入细节的做白盒测试。这对于这样的系统治理来说非常关键。这部分的工作,我们的测试也会有相关的技术博客:《CSDN个性化推荐系统-负反馈测试》
小结
良构的数据系统,才能带来良构的生态,从而上层目标的搭建才不会建立在一堆已经不正确工作的系统产生的数据指标之上。
引用
[1] 《CSDN个性化推荐系统的设计和演化》
[2] 《CSDN 个性化推荐的数据治理》
[3] 《CSDN个性化推荐系统-负反馈测试》
–end–