核心数据类型:
-
数字:int, long(python3.5已经没有), float, complex, bool
-
字符:str, unicode
-
列表:list
-
字典:dict
-
元组:tuple
-
集合:set(可变集合),frozenset(不可变集合)
-
文件:file
虽然说我们是在学习数据类型,但其实只是在学习每一个类型所提供的API而已,你所需要的大部分功能,Python都已经帮我们封装好了,不需要担心任何效率的问题,当你熟悉了这些API之后,灵活的组合应用,因为这在开发的过程中是必不可少的,那么接下来就让我们开始漫长的数据类型API学习之旅吧。
在Python3中,整型、长整型、浮点数、负数、布尔值等都可以称之为数字类型。

2.1、创建数据类型
创建数字类型类型的对象int类型通常都是数字,创建数字类型的方式有两种,且在创建的时候值两边不需要加双引号或单引号。
第一种创建整型的方式
>>> number = 9 >>> type(number) <class 'int'>
第二种创建整型的方式
>>> number = int(9) >>> type(number) <class 'int'>
以上两种创建整型对象的方式都可以创建的,但是他们也是有本质上的区别,第一种方式实际上会转换成第二种方式,然后第二种方式会把括号内的数据交给__init__这个构造方法,构造方法是int类的,然后构造方法会在内存中开辟一块空间用来存放数据,但实际上我们在用时候是没有任何区别的。
2.2、数字类型的长度限制
数字类型在python2.7里面是分整型和长整型这个区别的,也就是说如果你的数字大到一定的范围,那么python会把它转换为长整形,一个数字类型包含32位,可以存储从-2147483648到214483647的整数。
一个长整(long)型会占用更多的空间,64位的可以存储-922372036854775808到922372036854775808的整数。
python3里long型已经不存在了,而int型可以存储到任意大小的整型,甚至超过64为。
Python内部对整数的处理分为普通整数和长整数,普通整数长度为机器位长,通常都是32位,超过这个范围的整数就自动当长整数处理,而长整数的范围几乎完全没限制,如下:
-
Python2.7.x
>>> var=123456 >>> var 123456 >>> var=10**20 >>> var 100000000000000000000L >>> type(var) # long就是长整型 <type 'long'>
-
Python3.5.x
>>> var=123456789 >>> var 123456789 >>> var=10**20 >>> var 100000000000000000000 >>> type(var) <class 'int'>
2.3、数字类型所具备的方法
-
bit_length返回表示该数字时占用的最少位数
>>> num=20
>>> num.bit_length()
5
-
conjugate返回该复数的共轭复数,复数,比如0+2j,其中num.real,num.imag分别返回其实部和虚部,num.conjugate(),返回其共扼复数对象
>>> num =-20 >>> num.conjugate() -20 >>> num=0+2j >>> num.real 0.0 >>> num.imag 2.0 >>> num.conjugate() -2j
-
imag返回复数的虚数
>>> number = 10 >>> number.imag 0 >>> number = 3.1415926 >>> number.imag 0.0
内置的方法还有denominator、from_bytes、numerator、real、to_bytes,实在搞不懂这有什么用,也不太理解,就不做介绍了,你可以通过help(int.numerator)查看该方法的帮助信息等。
2.4、布尔类型(bool)
布尔类型其实就是数字0和1的变种而来,即真(True/0)或假(False/1),实际上就是内置的数字类型的子类而已。
# 如果0不是真,那么就输出'0 is False.' >>> if not 0: print('0 is False.') ... 0 is False. # 如果1是真,那么就输出'1 is True.' >>> if 1: print('1 is True.') ... 1 is True.
你还可以使用布尔值进行加减法,虽然从来没在任何代码中见过这种形式:
>>> True + 1 # 1 + 1 = 2 2 >>> False + 1 # 0 + 1 = 1 1
集合的元素是不允许重复、不可变且无序的集合,集合就像是字典舍弃了值一样,集合中的元素只能够出现一次且不能重复。
3.1、创建集合的方法
创建set集合
>>> s = set([11,22,33]) >>> s {33, 11, 22} >>> type(s) <class 'set'>
第二种不常用创建set集合的方式
# 这种的创建方式,集合中的元素相当于字典中的key >>> s = {11,22,33} >>> type(s) <class 'set'> >>> s {33, 11, 22}
把其它可迭代的数据类型转换为set集合
>>> li = ["a","b","c"] >>> seting = set(li) >>> seting {'b', 'a', 'c'} >>> type(seting) <class 'set'>
集合同样支持表达式操作符
# 首先创建两个集合 >>> x = set('abcde') >>> y = set('bdxyz') >>> x {'a', 'd', 'b', 'c', 'e'} >>> y {'y', 'd', 'b', 'x', 'z'} # 使用in进行成员检测 >>> 'a' in x True # 差集 >>> x - y {'a', 'e', 'c'} # 并集 >>> x | y {'b', 'y', 'z', 'a', 'd', 'e', 'c', 'x'} # 交集 >>> x & y {'d', 'b'} # 对称差 >>> x ^ y {'y', 'z', 'a', 'e', 'c', 'x'} # 比较 >>> x > y, x < y (False, False)
集合解析
>>> {x for x in 'abc'}
{'a', 'b', 'c'}
>>> {x+'b' for x in 'abc'}
{'bb', 'cb', 'ab'}
3.2、集合运算符
s | t s和t的并集 s & t s和t的交集 s - t 求差集 s ^ t 求对称差集 len(s) 集合中项数 max(s) 最大值 min(s) 最小值
3.3、变集合常用方法:
s.add(item) 将item添加到s中。如果item已经在s中,则无任何效果
s.remove(item) 从s中删除item。如果item不是s的成员,则引发KeyError异常
s.discard(item) 从s中删除item.如果item不是s的成员,则无任何效果
s.pop() 随机删除一个任意集合元素,并将其从s删除,如果有变量接收则会接收到删除到的那个元素
s.clear() 删除s中的所有元素
s.copy() 浅复制
s.update(t) 将t中的所有元素添加到s中。t可以是另一个集合、一个序列或者支持迭代的任意对象
s.union(t) 求并集。返回所有在s和t中的元素
s.intersection(t) 求交集。返回所有同时在s和t中的都有的元素
s.intersection_update(t) 计算s与t的交集,并将结果放入s
s.difference(t) 求差集。返回所有在set中,但不在t中的元素
s.difference_update(t) 从s中删除同时也在t中的所有元素
s.symmetric_difference(t) 求对称差集。返回所有s中没有t中的元素和t中没有s中的元素组成的集合
s.sysmmetric_difference_update(t) 计算s与t的对称差集,并将结果放入s
s.isdisjoint(t) 如果s和t没有相同项,则返回True
s.issubset(t) 如果s是t的一个子集,则返回True
s.issuperset(t) 如果s是t的一个超集,则返回True
字符串类型是python的序列类型,他的本质就是字符序列,而且python的字符串类型是不可以改变的,你无法将原字符串进行修改,但是可以将字符串的一部分复制到新的字符串中,来达到相同的修改效果。
4.1、创建字符串类型
创建字符串类型可以使用单引号或者双引号又或者三引号来创建,实例如下
单引号
>>> string = 'ansheng' # type是查看一个变量的数据类型 >>> type(string) <class 'str'>
双引号
>>> string = "ansheng" # type是查看一个变量的数据类型 >>> type(string) <class 'str'>
三引号
>>> string = """ansheng""" >>> type(string) <class 'str'>
还可以指定类型
>>> var=str("string") >>> var 'string' >>> type(var) <class 'str'>
4.2、适用于字符串常用方法
str.capitalize() 将字符串的首字母变大写
str.title() 将字符串中的每个单词的首字母大写
str.upper() 将字符串变成大写
str.lower() 将字符串变成小写
str.index() 找出索引对应的字符串
str.find() 同上
str.count() 找出字符串中元素出现的次数
str.format() 也是格式化的一种
str.center() 以什么字符从字符串两边填充
str.join() 以str为分隔符连接字符串
str.split() 以什么为分隔符分隔字符串
str.strip() 将字符串两边中的空格去掉
str.replace() 查找替换
str.isupper() 判断是否为大写
str.islower() 判断是否为小写
str.isalnum() 判断是否是字母数字
str.isalpha() 判断是否是字母下划线
str.isdigit() 判断是否是数字
str.isspace() 判断是否为空
str.startswith() 找出以什么为开头的字符元素
str.endswith() 找出以什么为结尾的字符元素
4.3、案例
#!/usr/bin/env python # ~*~ coding: utf-8 ~*~ __auchor__ = "Zhang.H" name = "zhang.h" print(name.capitalize()) # 首字符大写 name = "my name is zhang.h" print(name.count("m")) # 统计字符出现的次数 print(name.center(50,"*")) # 打印50个字符,如果变量里面不够,用*代替 email = "[email protected]" print(email.endswith("linux-python.com")) # 判断后面以什么结尾 print(email[email.find("linux"):20]) # 利用查找进行切片 print(email.isalpha()) #判断是否纯英文字符 我的里面有@所以不是 print("zhanghe".isalpha()) # 这样判断就是纯英文字符了 print("zhanghe".isidentifier()) # 判断是不是一个合法的标识符{变量名} print("1zhanghe".isidentifier()) #因为数字开头所以这个不是一个合法的标识符,所以False print('---'.join(["1","2","3","4"])) #定义打印 print(name.ljust(50,"-")) # 和center的用处差不多,这个是如果字符不够定义的数量,用-补充 print(name.rjust(50,"-")) # 和ljust的用处一样,一个行位,这个行头 print(email.replace('com','COM',1)) # 把指定的字符换成指定的字符 print(email.rfind('@')) # 查找到指定数字的下标 print(email.split('@')) print('1+2+3+4'.split('+')) # 可以把有规律的取出成list print("ZhangHe".swapcase()) # 大写变小写,小写变大写 print(email.title()) # 所有的单词首写大写
列表(list)同字符串一样都是有序的,因为他们都可以通过切片和索引进行数据访问,且列表是可变的。
5.1、创建列表的几种方法
第一种
name_list = ['Python', 'PHP', 'JAVA']
第二种
name_list = list(['Python', 'PHP', 'JAVA'])
创建一个空列表
>>> li = list() >>> type(li) <class 'list'>
把一个字符串转换成一个列表
>>> var="abc" >>> li = list(var) >>> li ['a', 'b', 'c']
list在把字符串转换成列表的时候,会把字符串用for循环迭代一下,然后把每个值当作list的一个元素。
把一个元组转换成列表
>>> tup=("a","b","c") >>> li=list(tup) >>> type(li) <class 'list'> >>> li ['a', 'b', 'c']
把字典转换成列表
>>> dic={"k1":"a","k2":"b","k3":"c"}
>>> li=list(dic)
>>> type(li)
<class 'list'>
>>> li
['k3', 'k1', 'k2']
字典默认循环的时候就是key,所以会把key当作列表的元素
>>> dic={"k1":"a","k2":"b","k3":"c"}
>>> li=list(dic.values())
>>> li
['c', 'a', 'b']
如果指定循环的是values,那么就会把values当作列表的元素
5.2、列表所提供的方法
list.insert() 在列表中指定索引位置前插入元素 list.append() 在列表尾部插入 list.remove() 删除指定的元素 list.pop() 没有指定索引,则弹出最后一个元素,返回的结果是弹出的索引对应的元素 list.copy() 浅复制,只会复制第一层,如果有嵌套序列则不会复制,如果需要复制则要导入copy模块 list.extend() 把另外一个列表合并,并不是追加 list.index() 列表中元素出现的索引位置 list.count() 统计列表中元素的次数 list.reverse() 进行逆序 list.sort() 进行排序,python3无法把数字和字符串一起排序 l1 + l2 : 合并两个列表,返回一个新的列表,不会修改原列表 l1 * N : 把l1重复N次,返回一个新列表
5.3、案例
通过索引来修改元素
>>> print(l2) [1, 2, 3, 4, 5] >>> l2[1] = 32 >>> print(l2) [1, 32, 3, 4, 5] >>> l2[3] = 'xyz' >>> print(l2) [1, 32, 3, 'xyz', 5] >>> print(l1) [1, 2, 3] >>> l1[1:] = ['m','n','r'] >>> print(l1) [1,'m','n','r']
通过分片进行删除
>>> l2[1:3] [32, 3] >>> l2[1:3] = [] >>> print(l2) [1, 'xyz', 5]
通过内置的函数进行删除
>>> del(l2[1:]) >>> print(l2) [1]
通过列表类中的方法进行增删改
>>> l3 = [1,2,3,4,5,6] >>> l3.append(77) >>> print(l3) [1, 2, 3, 4, 5, 6, 77] >>> l4 = ['x','y','z'] >>> l3.append(l4) >>> print(l3) [1, 2, 3, 4, 5, 6, 77, ['x', 'y', 'z']]
变量解包
>>> l1,l2 = [[1,'x','y'],[2,'z','r']] >>> print(l1) [1, 'x', 'y'] >>> type(l1) >>> print(l2) [2, 'z', 'r']
找到列表中的元素并修改
tomcat@node:~/scripts$ cat b.py name = [1,2,3,4,5,1,5,6] if 1 in name: num_of_ele = name.count(1) position_of_ele = name.index(1) name[position_of_ele] = 888 print(name) tomcat@node:~/scripts$ python b.py [888, 2, 3, 4, 5, 1, 5, 6]
找到列表中的元素并批量修改
tomcat@node:~/scripts$ cat b.py name = [1,2,3,4,5,1,5,6] for i in range(name.count(1)): ele_index = name.index(1) name[ele_index] = 8888888 print(name) tomcat@node:~/scripts$ python b.py [8888888, 2, 3, 4, 5, 8888888, 5, 6]
元组(tuple)和列表的唯一区别就是列表可以更改,元组不可以更改,其他功能与列表一样
6.1、创建元组类型
创建元组的两种方法
第一种
ages = (11, 22, 33, 44, 55)
第二种
ages = tuple((11, 22, 33, 44, 55))
如果元祖内只有一个元素,那么需要加上一个逗号,否则就变成字符串了。
In [1]: t = (1) In [2]: t Out[2]: 1 In [3]: type(t) Out[3]: int In [4]: t = (1,) In [5]: t Out[5]: (1,) In [6]: type(t) Out[6]: tuple
6.2、元组常用方法
tuple.count() 统计元组中元素的个数
tuple.index() 找出元组中元素的索引位置
6.3、补充
在没有嵌套的情况,元组是不可变对象,但是在嵌套了列表,列表是可变的
>>> t5 = ('x',[1,2,3,4]) >>> print t5 ('x', [1, 2, 3, 4]) >>> t5[1].pop() 4 >>> print(t5) ('x', [1, 2, 3])
元组解包
>>> t1,t2 = ((1,2,3,4,5,'xy'),('s','y','w')) >>> print(t1) (1, 2, 3, 4, 5, 'xy') >>> type(t1) tuple >>> print(t2) ('s', 'y', 'w')
字典(dict)在基本的数据类型中使用频率也是相当高的,而且它的访问方式是通过键来获取到对应的值,当然存储的方式也是键值对了,属于可变类型。
其中字典的Key必须是不可变类型,比如字符串、数字、元组都可以作为字典的Key。
7.1、创建字典类型
创建字典的两种方式
第一种
>>> dic = {"k1":"123","k2":"456"}
>>> dic
{'k1': '123', 'k2': '456'}
>>> type(dic)
<class 'dict'>
第二种
>>> dic = dict({"k1":"123","k2":"456"})
>>> dic
{'k1': '123', 'k2': '456'}
>>> type(dic)
<class 'dict'>
在创建字典的时候,__init__初始化的时候还可以接受一个可迭代的变量作为值
>>> li = ["a","b","c"] >>> dic = dict(enumerate(li)) >>> dic {0: 'a', 1: 'b', 2: 'c'}
默认dict在添加元素的时候会把li列表中的元素for循环一遍,添加的时候列表中的内容是字典的值,而键默认是没有的,可以通过enumerate方法给他加一个序列,也就是键。
与其变量不同的是,字典的键不仅仅支持字符串,而且还支持其他数据类型,譬如:
# 数字 >>> D = {1:3} >>> D[1] 3 # 元组 >>> D = {(1,2,3):3} >>> D[(1,2,3)] 3
字典解析
>>> D = {x: x*2 for x in range(10)}
>>> D
{0: 0, 1: 2, 2: 4, 3: 6, 4: 8, 5: 10, 6: 12, 7: 14, 8: 16, 9: 18}
# 可以使用zip
>>> D = {k:v for (k, v) in zip(['a','b','c'],[1,2,3])}
>>> D
{'a': 1, 'c': 3, 'b': 2}
两种遍历字典方法
第一种: for k,v in dict.items(): print(k,v) 第二种:高效 for key in dict: print(key,dict[key])
7.2、字典常用方法
dict.get(key) 取得某个key的value dict.has_key(key) 判断字典是否有这个key,在python3中已经废除,使用in 判断 dict.keys() 返回所有的key为一个列表 dict.values() 返回所有的value为一个列表 dict.items() 将字典的键值拆成元组,全部元组组成一个列表 dict.pop(key) 弹出某个key-value dict.popitem() 随机弹出key-value dict.clear() 清除字典中所有元素 dict.copy() 字典复制,d2 = d1.copy(),是浅复制,如果深复制需要copy模块 dict.fromkeys(S) 生成一个新字典 dict.update(key) 将一个字典合并到当前字典中 dict.iteritems() 生成key-value迭代器,可以用next()取下个key-value dict.iterkeys() 生成key迭代器 dict.itervalues() 生成values迭代器
拷贝意味着对数据重新复制一份,对于拷贝有两种深拷贝,浅拷贝两种拷贝,不同的拷贝有不同的效果。拷贝操作对于基本数据结构需要分两类进行考虑,一类是字符串和数字,另一类是列表、字典等。如果要进行拷贝的操作话,要import copy。
8.1、数字和字符串
对于数字和字符串而言,深拷贝,浅拷贝没有什么区别,因为对于数字数字和字符串一旦创建便不能被修改,假如对于字符串进行替代操作,只会在内存中重新生产一个字符串,而对于原字符串,并没有改变,基于这点,深拷贝和浅拷贝对于数字和字符串没有什么区别,下面从代码里面说明这一点。
import copy s='abc' print(s.replace('c','222')) # 打印出 ab222 print(s) # s='abc' s并没有被修改 s1=copy.deepcopy(s) s2=copy.copy(s) #可以看出下面的值和地址都一样,所以对于字符串和数字,深浅拷贝不一样,数字和字符串一样就不演示了,大家可以去试一下 print(s,id(s2)) # abc 1995006649768 print(s1,id(s2)) # abc 1995006649768 print(s2,id(s2)) # abc 1995006649768
8.2、字典、列表等数据结构
对于字典、列表等数据结构,深拷贝和浅拷贝有区别,从字面上来说,可以看出深拷贝可以完全拷贝,浅拷贝则没有完全拷贝,下面先从内存地址分别来说明,假设 n1 = {"k1": "wu", "k2": 123, "k3": ["alex", 456]}。
8.2.1、创建一个字典var1
var1 = {"k1": "1", "k2": 2, "k3": ["abc", 456]}
8.2.2、赋值
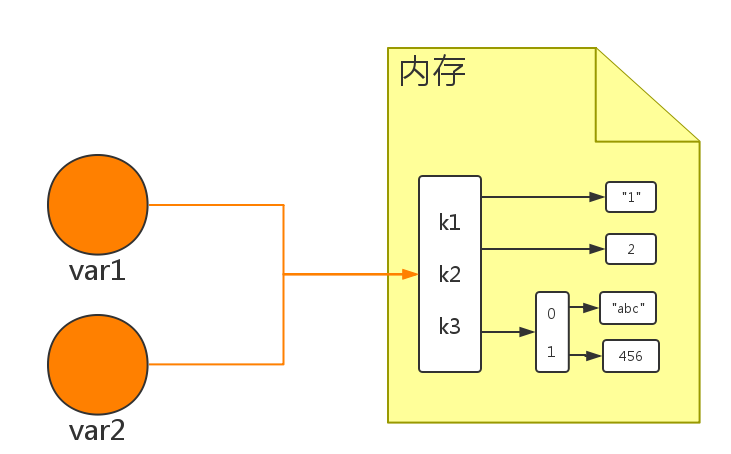
赋值,只是创建一个变量,该变量指向原来内存地址,如:
>>> var1 = {"k1": "1", "k2": 2, "k3": ["abc", 456]}
>>> var2 = var1
>>> id(var1)
1937003361288
>>> id(var2)
1937003361288
如图所示:
3.2.3、浅拷贝
浅拷贝,在内存中只额外创建第一层数据
# 导入拷贝模块 >>> import copy >>> var1 = {"k1": "1", "k2": 2, "k3": ["abc", 456]} # 使用浅拷贝的方式 >>> var2 = copy.copy(var1) # 两个变量的内存地址是不一样的 >>> id(var1) 2084726354952 >>> id(var2) 2084730248008 # 但是他们的元素内存地址是一样的 >>> id(var1["k1"]) 2084726207464 >>> id(var2["k1"]) 2084726207464
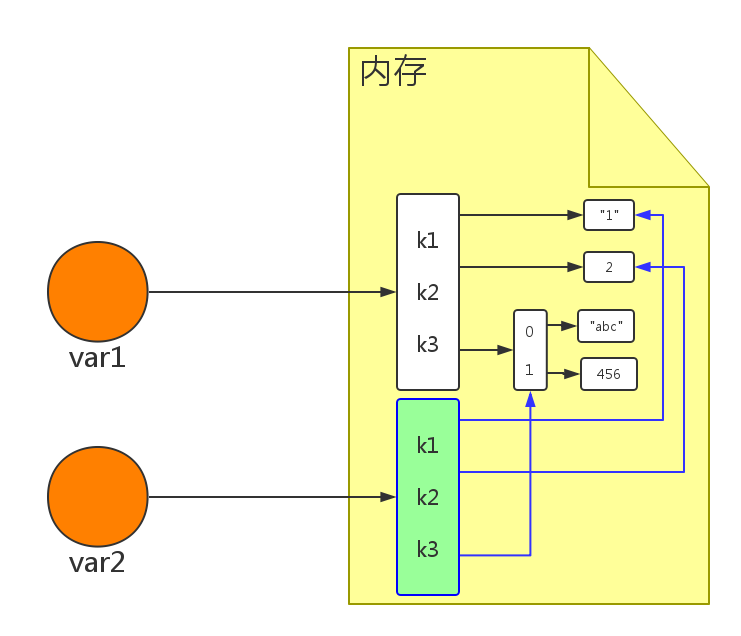
8.2.4、深拷贝
深拷贝,在内存中将所有的数据重新创建一份(排除最后一层,即:python内部对字符串和数字的优化)
# 导入拷贝模块 >>> import copy >>> var1 = {"k1": "1", "k2": 2, "k3": ["abc", 456]} # 使用深拷贝的方式把var1的内容拷贝给var2 >>> var2 = copy.deepcopy(var1) # var1和var2的内存地址是不相同的 >>> id(var1) 1706383946760 >>> id(var2) 1706389852744 # var1和var2的元素"k3"内存地址是不相同的 >>> id(var1["k3"]) 1706389853576 >>> id(var2["k3"]) 1706389740744 # var1和var2的"k3"元素的内存地址是相同的 >>> id(var1["k3"][1]) 1706383265744 >>> id(var2["k3"][1]) 1706383265744
如图所示:
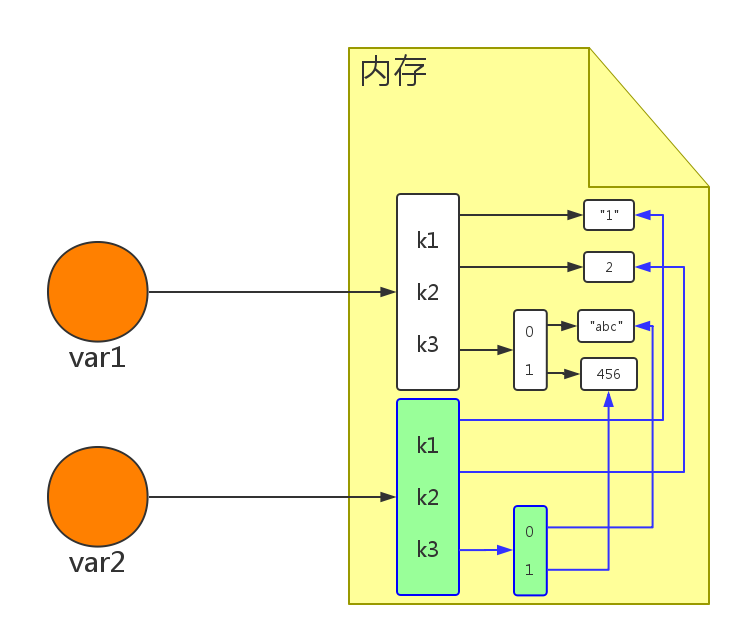
9.1、enumrate
为一个可迭代的对象添加序号,可迭代的对象你可以理解成能用for循环的就是可迭代的。默认是编号是从0开始,可以设置从1开始
li = ["手机", "电脑", '鼠标垫', '游艇'] for k, i in enumerate(li,1): print(k,i) 1 手机 2 电脑 3 鼠标垫 4 游艇
9.2、range和xrange
在python2中有xrange和range,其中range会一次在内存中开辟出了所需的所有资源,而xrange则是在for循环中循环一次则开辟一次所需的内存,而在Python3中没有xrange,只有range ,但是python3的range代表的就是xrange。range用来指定范围,生成指定的数字。
for i in range(10): #循环输出所生成的 0-9 print(i) for i in range(1,10,2): #输出所生成的 1 3 5 7 9 print(i)