目录
1. 介绍
LeNet 网络的结构如图:
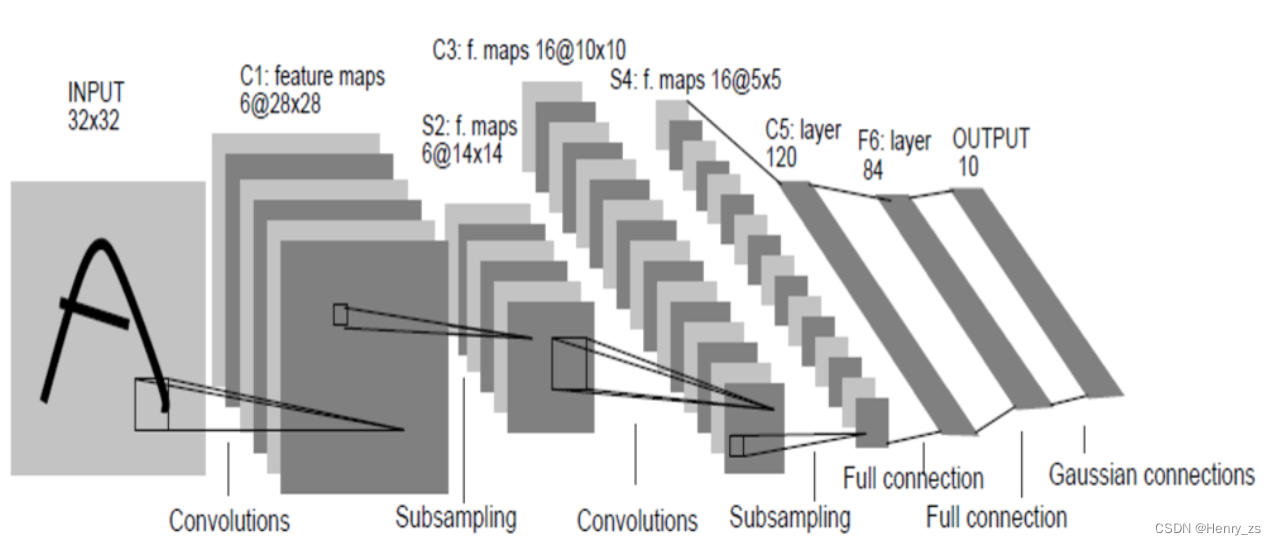
网络流通的顺序为:
输入->卷积层1->激活函数->池化层->卷积层2->激活函数->池化层2->全连接层1->激活函数->全连接层2->激活函数->全连接层3->激活函数->softmax->输出10个类别的概率
再看一下网络的维度:
卷积层的计算公式为:
- src 代表输入图像,dst代表输出图像,也可以计算对应的Height , Width
- f 代表卷积核的size
- p 代表填充的个数
- s 代表卷积核的步幅
池化层计算公式较为简单,这里用的是(2,2)大小的Max池化。通常池化层核的size 核stride一样,所以图像输出的维度是输入图像的一半
池化层的作用类似于选取代表,缩小图片的size,可以有效提高特征的鲁棒性能,所以不需要激活函数
鲁棒性倒不如说健壮性好理解,当图像发生微小偏差的时候,Max池化返回的结果不变。
这里我们采用模块化的方式:
- model 存放LeNet 网络
- train 用于训练我们的模型
- predict 把训练好的权重数据取出,预测网上找的dog、plane图片
- LeNet.pth 是保存训练好的权重参数
2. 搭建LeNet 网络
首先是需要的库文件

然后搭建LeNet 网络结构:
CIFAR - 10 数据集是一个彩色图像,因此有三个通道
它包含十个类别,每张图片的维度都是(3 *32*32)
'plane','car','bird','cat','deer','dog','frog','horse','ship','truck'

需要注意的是,torch.nn 只支持mini-batches 输入,对应的通道顺序是:
nSamples * Channels * Height * Width
nn.Conv2d(3,6,5) # 3代表输入的通道数,6代表卷积核的个数=输出图片个数,5 kernel 的size
这里的的5是根据
得来的,这里src = 32,dst = 28,默认s = 1,pad = 0 ----------> f = 5
而激活函数(这里用的是relu)不会改变维度,Max池化层会降低一半图像的Height和Width,所以第一个 输入->卷积层1->激活函数->池化层 里面维度的传播过程为:(3,32,32)-> (6,28,28)-> (6,28,28)->(6,14,14)。第二个卷积、池化同样计算
卷积神经网络分类里面
- 卷积层 处理的都是图片,所以卷积的目的是特征提取,因此有时候将卷积层的输入输出数据也叫特征图(feature map)
- 而全连接层处理的已经不是图片,类似于一维矩阵的形式,因此主要的任务是分类
到图像流出到全连接层1,这时候维度是(16,5,5),具体的应该说是(n,16,5,5)n是处理的mini-batches 的个数。通过view将它变为输入是(n,16*5*5)的维度,我们期望他的输出维度是(n,120)(改变的只是对应的数据,而非样本的个数),根据矩阵乘法,所以第一个全连接层应该是(16*5*5,120)的形式,剩下的同理
最后输出的是(n,10)也就是n个样本,然后按照十个类别预测的概率值(要记住这个维度,后面计算accuracy的时候需要)
这里输出没有经过softmax 层的原因,是多分类常用交叉熵损失函数,而nn里面的交叉熵损失函数包括了softmax层

定义好模型后,可以测试一下维度是否匹配:

可以发现输出是我们期望的n = 5,10个预测类别的shape

3. 训练网络
需要的头文件如图:

3.1 数据预处理
载入数据集:
- root 代表数据集的目录
- train 为 True 的时候,代表是训练样本
- download 为True 的时候,会从root里面读取,否则,会从网上下载到root路径
- transforms 图像的预处理操作
- batch_size 代表每次拿出来的数据个数,也就是之前定义网络的 n 样本个数
- shuffle 代表是否打乱数据集,train 时候打乱,测试的时候是为了准确率,没必要打乱
- num_workers 代表线程数,windows 要设置为 0

其中,transform的处理为:

- ToTensor 改变通道顺序,一般图像通道顺序为(H,W,C),这里改变为(C,H,W),并且将灰度值归一化到 0-1之间
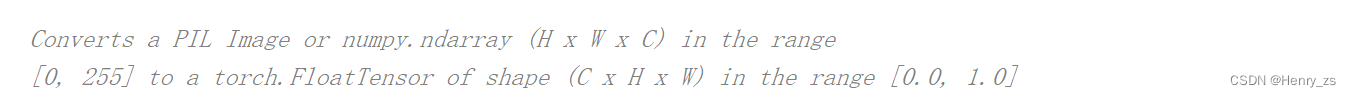
- Normalize 标准化过程如图,这里三个通道,所以mean需要三个数字

3.2 显示图像
这里,通过前两行代码拿到图像的data和图像的label
imshow函数内部,因为取到的图像,已经normalize了,所以需要反变换一下。
这里normalize的时候是:out = (in - 0.5) / 2 ---> in = 2 *out + 0.5
因为图像的正确通道顺序是(H,W,C)所以需要改变一下
注:这里我们是从testloader里面拿的,所以要把batch_size 改到4,要不然10000 太多了,显示不出来

显示结果为:
图像的label 为:![]()
图像为:

3.3 实例化网络+构建优化器
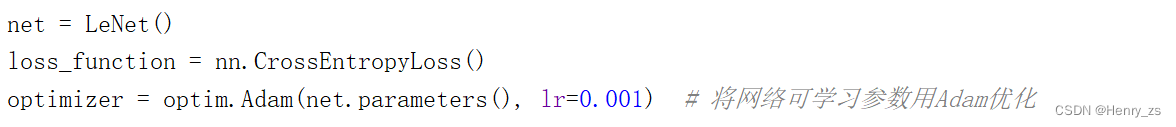
这里采用交叉熵损失函数。
net.parameters() 是 网络可学习的所以参数
3.4 训练网络
因为网络太大,这里我们只让所有的训练集重复5次
enumerate 会返回每一批的data 和 index ,这里index 从0开始,并赋值给step。而trainloader是里面包含了数据和标签,将它赋值给inputs和labels
将第一个value 赋值给inputs(每一个样本的32*32) ,第二个value 赋值给 labels(10个分类)
然后就是梯度清零->网络前向传播->计算损失->反向传播->参数更新

接下来开始打印loss和accuracy,每500步的时候打印一次loss:

再测试集上计算网络的accuracy的时候,不需要计算梯度。然后将test的图像送进我们的网络,得到一个outputs
这里的outputs维度特别重要,之前我们测试网络的时候,输入是5个样本,最后的输出是5*10。而这里test_image是从testloader里面取出的,而testloader里面的batch_size是10000------之前显示图像的时候改为4,这里要改成10000
所以outputs 的输出是 (10000,10)维度的,也就是10000个样本,10个分类类别

维度弄明白的话,后面的实现就简单了。
torch.max 会返回value和index,这里dim = 1,代表横着取最大值

3.5 保存网络参数
保存到LeNet.pth 文件就可以了

4. 预测图片
这里因为网上随机的图片不满足32*32的size,所以需要更改一下尺寸
然后就是加载网络已经训练好的参数,因为我们下载的图片是3通道的,需要增加一个维度,调用unsqueeze,最后预测就行了

5. Code
model模块
import torch.nn as nn # 神经网络库
import torch.nn.functional as F # 函数功能库,如relu、sigmoid等等
import torch
class LeNet(nn.Module): # 继承父类
def __init__(self):
super(LeNet,self).__init__() #涉及到多继承需要,这个记住就行
self.conv1 = nn.Conv2d(3,6,5) # 输入(3,32,32) 输出(6,28,28)
self.conv2 = nn.Conv2d(6,16,5) # 输入(6,14,14) 输出(16,10,10)
self.fc1 = nn.Linear(16*5*5,120) # 输入16*5*5,输出120
self.fc2 = nn.Linear(120,84)
self.fc3 = nn.Linear(84,10)
# 定义前向传播过程
def forward(self,x): # 输入x == 【batch,channel,height,width】
# conv -> 激活函数 -> 池化
x = F.max_pool2d(F.relu(self.conv1(x)),2) # 输入(3,32,32)-> (6,28,28)-> 输出(6,14,14)
x = F.max_pool2d(F.relu(self.conv2(x)),2) # 输入(6,14,14)-> (16,10,10)-> 输出(16,5,5)
x = x.view(x.shape[0],-1) # -->output (1,16*5*5) * (16*5*5,120) = (1,120)
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x) # 不需要softmax,交叉熵损失函数里面有
return x
'''
# 测试一下网络
input = torch.randn((5,3,32,32)) # n 个 3 通道的32*32分辨率的图像
net = LeNet() # 实例化网络
output = net(input)
print(input.shape)
print(output.shape)
print(net)
'''
train 模块
import torch
import torchvision # 提供数据集
import torch.nn as nn # 神经网络库
import torchvision.transforms as transforms # 图像处理包
from model import LeNet # 导入模型
import torch.optim as optim # 导入优化器包
import numpy as np
import matplotlib.pyplot as plt
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
# 5w 张训练图片
trainset = torchvision.datasets.CIFAR10(root='./data', train=True, download=False, transform=transform)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=36, shuffle=True, num_workers=0)
# 1w 张测试图片
testset = torchvision.datasets.CIFAR10(root='./data', train=False, download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=10000, shuffle=False, num_workers=0)
test_data_iter = iter(testloader) # 生成一个可以迭代的迭代器
test_image, test_label = test_data_iter.next() # 通过next获取图像的data和label
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck') # 十个分类的label
'''
# 定义show 函数
def imshow(img):
img = img / 2 + 0.5 # 去normalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0))) # 改变图像通道顺序(C,H,W) -> (H,W,C)
plt.show()
# 打印 label
print(' '.join('%5s' % classes[test_label[j]] for j in range(4)))
# show 图片
imshow(torchvision.utils.make_grid(test_image))
'''
net = LeNet()
loss_function = nn.CrossEntropyLoss()
optimizer = optim.Adam(net.parameters(), lr=0.001) # 将网络可学习参数用Adam优化
for epoch in range(5): # 将所有的训练集重复 5次
running_loss = 0.0
for step, data in enumerate(trainloader, start=0):
inputs, labels = data
optimizer.zero_grad() # 梯度清零
outputs = net(inputs) # 前向传播
loss = loss_function(outputs, labels) # 计算损失函数
loss.backward() # 反向传播
optimizer.step() # 参数更新
running_loss += loss.item()
if step % 500 == 499: # 每隔 500 步打印一次信息
with torch.no_grad(): # 打印的时候不需要计算梯度
outputs = net(test_image) # 一次拿出所有的测试图片,前向传播,要将batch_size 改成1w
predict_y = torch.max(outputs, dim=1)[1] # 返回值为(值,索引) [1]代表取索引,dim = 1代表横着取最大值
accuracy = (predict_y == test_label).sum().item() / test_label.size(0) # test_label.size(0)==batch_size
print('[%d,%5d] train_loss: %.3f test_accuracy:%.3f'
% (epoch + 1, step + 1, running_loss / 500, accuracy))
running_loss = 0.0 # 清零,为下一次打印做准备
print('Finished Training')
save_path = './LeNet.pth'
torch.save(net.state_dict(), save_path)
训练结果为:

predict 模块:
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
transforms = transforms.Compose([transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))])
classes = ('plane','car','bird','cat','deer','dog','frog','horse','ship','truck')
net = LeNet()
net.load_state_dict(torch.load('LeNet.pth')) # 加载网络训练的参数
im = Image.open('dog.png')
im = transforms(im) # 图像维度 (C,H,W)
im = torch.unsqueeze(im,dim = 0) # 增加维度,第0维增加1 ,维度(1,C,H,W)
with torch.no_grad():
outputs = net(im)
predict = torch.max(outputs,dim = 1)[1].data.numpy()
print(classes[int(predict)])
预测图像:
1. dog
预测结果:

2. plane
预测结果:
