
文章目录
一、导读

论文地址:
https://arxiv.org/abs/2306.12156
快速分段任意模型 (FastSAM) 是一种 CNN 分段任意模型,仅由 SAM 作者发布的 SA-1B 数据集的 2% 进行训练。 FastSAM 的性能与 SAM 方法相当,运行速度提高了 50 倍。

二、安装步骤
2.1 将存储库克隆到本地
git clone https://github.com/CASIA-IVA-Lab/FastSAM.git

2.2 创建 conda 环境
该代码需要 python>=3.7,以及 pytorch>=1.7 和 torchvision>=0.8。
请按照此处的说明安装 PyTorch 和 TorchVision 依赖项。 强烈建议安装支持 CUDA 的 PyTorch 和 TorchVision。
conda create -n FastSAM python=3.9
conda activate FastSAM
2.3 安装软件包
cd FastSAM
pip install -r requirements.txt


我们看到,下载速度太慢,我们需要引入镜像源!
以下是一些常用的Python镜像源地址,可用于加速Python软件包的安装和更新:
- 清华大学:
清华大学:https://pypi.tuna.tsinghua.edu.cn/simple

安装命令:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple [package_name]
- 阿里云:
主页:https://mirrors.aliyun.com/pypi/simple/
安装命令:
pip install -i https://mirrors.aliyun.com/pypi/simple/ [package_name]
- 豆瓣:
主页:https://pypi.doubanio.com/simple/
安装命令:
pip install -i https://pypi.doubanio.com/simple/ [package_name]
您可以将这些镜像源地址添加到您的pip配置文件或使用临时的安装命令中。将 [package_name] 替换为您要安装或更新的Python软件包名称。
请注意,镜像源的可用性和稳定性可能会有所变化,因此如果遇到下载问题,您可以尝试切换到其他可用的镜像源或与相关社区或支持渠道联系以获取进一步的帮助。
下载完成!
2.4 安装 CLIP
pip install git+https://github.com/openai/CLIP.git
2.5 下载权重文件
https://drive.google.com/file/d/1m1sjY4ihXBU1fZXdQ-Xdj-mDltW-2Rqv/view
2.6 开始使用
然后,您可以运行脚本来尝试一切模式和三种提示模式。
建立一个weights的文件夹,把刚刚下载的权重文件导进去:
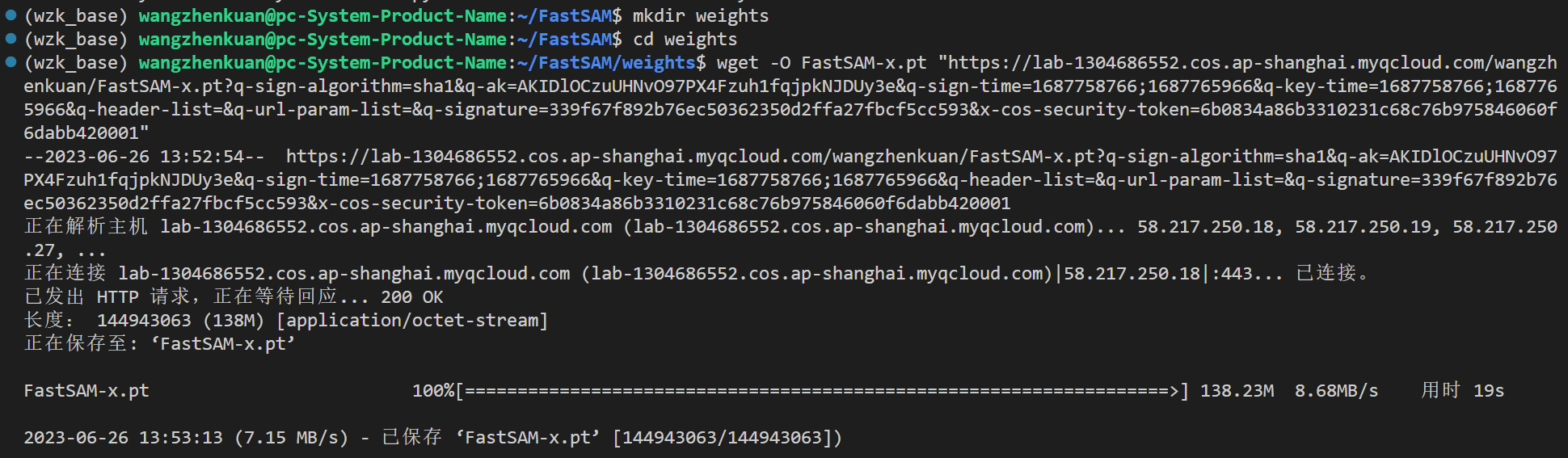
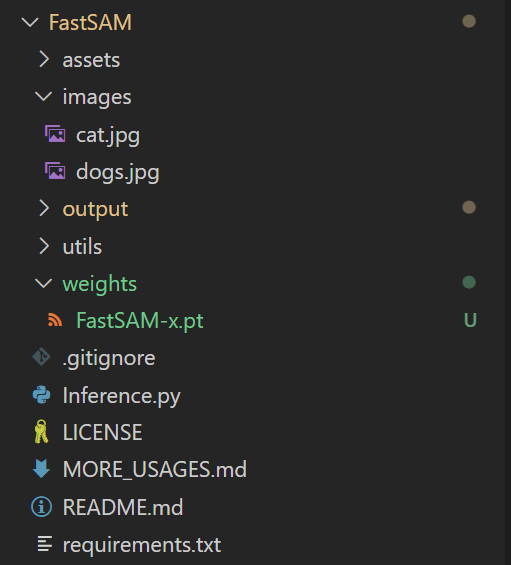
具体结果为:
2.6.1 Everything mode
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg
2.6.2 Text prompt
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --text_prompt "the yellow dog"
2.6.3 Box prompt (xywh)
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --box_prompt "[570,200,230,400]"
2.6.4 Points prompt
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --point_prompt "[[520,360],[620,300]]" --point_label "[1,0]"
三、示例代码
!git clone https://github.com/CASIA-IVA-Lab/FastSAM.git
下载权重文件:
!wget https://huggingface.co/spaces/An-619/FastSAM/resolve/main/checkpoints/FastSAM.pt

安装需要的包:
!pip install -r FastSAM/requirements.txt
!pip install git+https://github.com/openai/CLIP.git
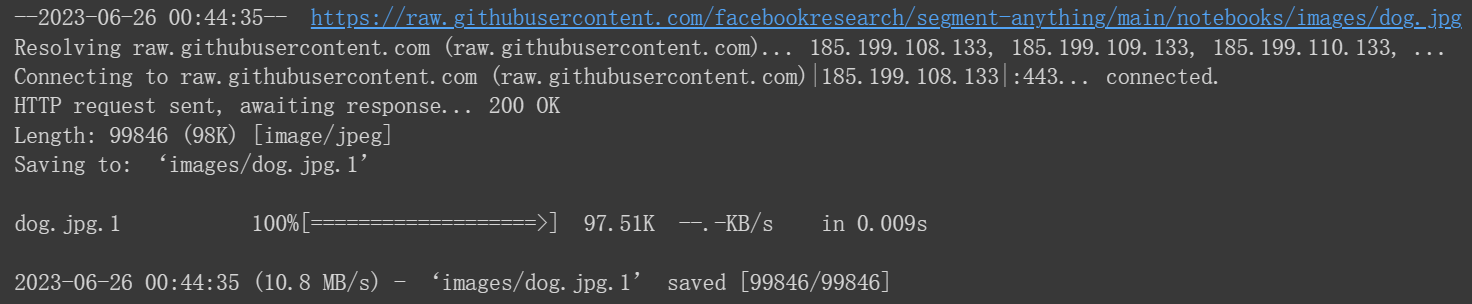
下载名为"dog.jpg"的文件并将其保存到名为"images"的目录中:
!wget -P images https://raw.githubusercontent.com/facebookresearch/segment-anything/main/notebooks/images/dog.jpg
import matplotlib.pyplot as plt
import cv2
cv2是一个流行的Python库,全称为OpenCV(Open Source Computer Vision Library)。它提供了丰富的计算机视觉和图像处理功能,可以用于处理图像、视频和摄像头输入。以下是cv2包的一些主要功能和用途:
- 图像读取和显示:cv2可以加载、读取和显示图像文件,支持多种常见图像格式(如JPEG、PNG等)。
- 图像处理和增强:cv2提供了各种图像处理和增强功能,例如调整大小、裁剪、旋转、翻转、缩放、滤波、边缘检测等。
- 颜色空间转换:cv2可以实现不同颜色空间之间的转换,如RGB、灰度、HSV等。
- 特征检测和描述:cv2提供了一些常见的特征检测和描述算法,如SIFT、SURF、ORB等,用于在图像中寻找关键点和描述符。
- 目标检测和识别:cv2可以用于目标检测和识别任务,包括人脸检测、物体识别等。
- 图像分割和轮廓检测:cv2提供了图像分割和轮廓检测算法,用于将图像分割成不同的区域并提取其边界。
- 视频处理和分析:cv2支持视频读取、处理和分析,可以从视频文件或实时摄像头获取视频流,并进行各种操作和分析。
- 图像绘制和标注:cv2可以在图像上绘制各种几何形状、文字和标注,用于可视化和分析结果展示。
image = cv2.imread('images/dog.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
使用cv2的imread函数加载’dog.jpg’图像文件,并将其存储在变量image中。函数imread接受图像文件的路径作为参数,并返回一个表示图像的多维数组(通常是一个NumPy数组)。注意,默认情况下,imread将图像以BGR颜色顺序加载。
使用cv2的cvtColor函数将图像从BGR颜色空间转换为RGB颜色空间。函数cvtColor接受两个参数,第一个参数是要转换的图像,第二个参数是转换的颜色空间代码。在这里,我们将BGR2RGB传递给第二个参数,表示将图像从BGR转换为RGB。
通过这两行代码,您可以加载图像文件并将其从BGR颜色空间转换为RGB颜色空间。这在处理和显示图像时很常见,因为大多数情况下,我们使用RGB颜色空间来表示图像。
original_h = image.shape[0]
original_w = image.shape[1]
print(original_w, original_h)
plt.figure(figsize=(10, 10))
plt.axis("off")
plt.imshow(image)
使用image的shape属性来获取图像的尺寸信息。shape属性返回一个包含图像高度、宽度和通道数的元组。元组的第一个元素是图像的高度,第二个元素是图像的宽度,第三个元素是图像的通道数。通过将shape的第一个元素赋值给original_h,将shape的第二个元素赋值给original_w,我们得到了图像的原始高度和宽度。
打印了图像的原始宽度和高度。
使用matplotlib库创建一个新的图像窗口,并在窗口中显示图像。plt.figure(figsize=(10, 10))指定了图像窗口的大小为10x10英寸。plt.axis(“off”)设置图像窗口的坐标轴为关闭状态,以便不显示坐标轴。plt.imshow(image)显示image变量中的图像数据。
通过这段代码,您可以获取图像的原始尺寸,并在一个新的图像窗口中显示图像。
输出的结果为:

–imgsz 1024"表示输入图像大小为1024。我们的模型是在1024的大小上训练的。您可以将其更改为您想要输入的任何大小。使用其他大小会产生不同的分割结果。
!python FastSAM/Inference.py --model_path FastSAM.pt --img_path ./images/dog.jpg --imgsz 1024

image = cv2.imread('output/dog.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
original_h = image.shape[0]
original_w = image.shape[1]
print(original_w, original_h)
plt.figure(figsize=(10, 10))
plt.axis("off")
plt.imshow(image)
输出结果为:
