参考Redis学习笔记 https://bcdh.yuque.com/staff-wpxfif/resource/gl5cic#LYwz2(可能有权限限制无法访问)
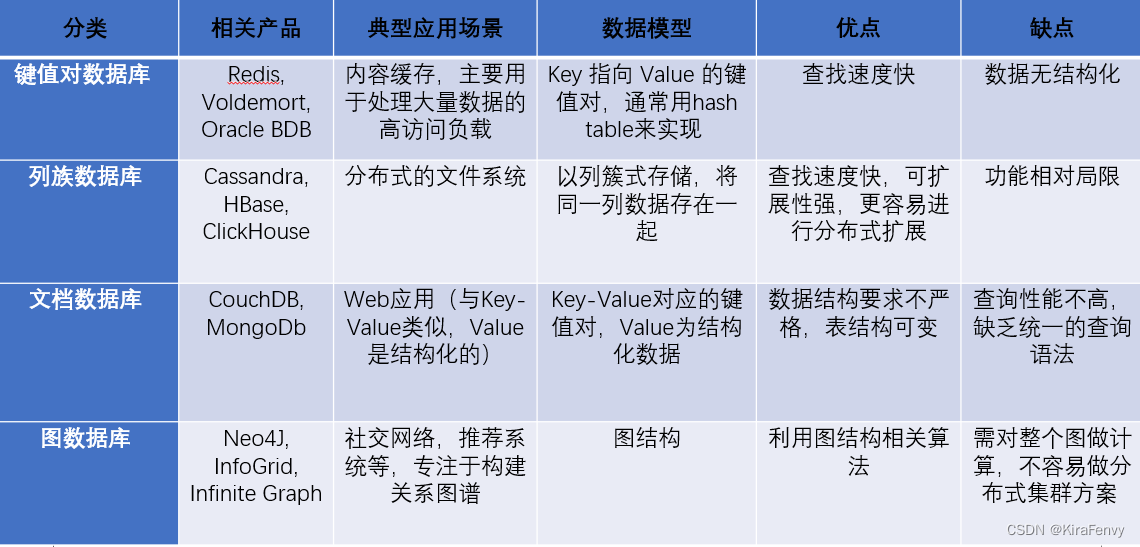
Redis介绍
Redis是Remote Dictionary Server
背景
业务中会遇到的问题:
- 数据量巨大
- 数据模式的不确定性
- 数据的频繁读
- 数据的频繁更改
- 大量数据的统计分析
集中数据库的特点
简介
- Redis(Remote Dictionary Server)是一个使用ANSI C语言编写的开源数据库
- 高性能的 key-value数据库
- 内存数据库,支持数据持久化
- 提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端
Redis数据类型
Keys:非二进制安全的字符类型
Values:
string:最基本的数据类型,二进制安全的字符串,最大512M。
list:按照添加顺序保持顺序的字符串列表。
set:无序的字符串集合,不存在重复的元素。
sorted set:已排序的字符串集合。
hash:key-value对的一种集合。
bitmap:更细化的一种操作,以bit为单位。
hyperloglog:基于概率的数据结构。 # 2.8.9新增
Geo:地理位置信息储存起来, 并对这些信息进行操作 # 3.2新增
流(Stream):# 5.0新增
Redis特点
1.支持多种数据结构
2.单线程,每个命令的执行具备原子性,中途不会执行其他命令(指命令处理始终是单线程的,自6X起改为多
线程接受风络请求)
3.高性能、低延时(基于内存、O多路复用、良好编码)
4.支持数据持久化
5.支持主从、分片集群
6.支持多语言客户端
Redis的优点
- 操作简单。相比关系数据库在安装以及CRUD方面便捷。
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 strings, lists, hashes, sets 及 sorted sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,同时Redis还支持对几个操作合并后的原子性执行。
丰富的特性 – Redis还支持 publish/subscribe, 通知, 主从复制等特性。
Redis持久化操作
RDB(Redis DataBase):快照持久化,存储数据结果,关注点在数据
AOF(Append Only File):存储操作过程,关注点在数据的操作过程
CAP定理
一致性(C):在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
可用性(A):保证每个请求不管成功或者失败都有响应。
分区容忍性(P):系统中任意信息的丢失或失败不会影响系统的继续运作。
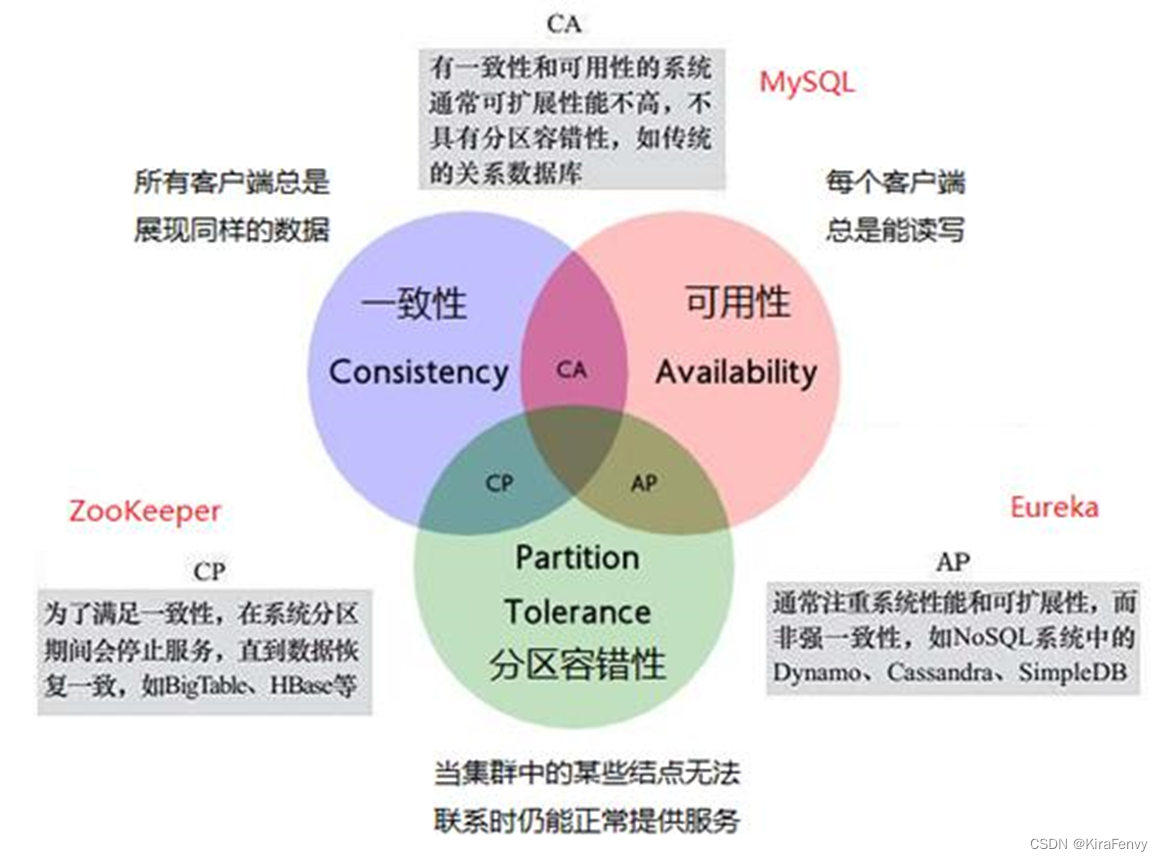
数据一致性
- 强一致性(线性一致性):复制是同步的
- 弱一致性:复制是异步的。数据更新后,如果能容忍后续的访问只能访问到部分或者全部访问不到,则是弱一致性
- 最终一致性:不保证在任意时刻任意节点上的同一份数据都是相同的,但是随着时间的迁移,不同节点上的同一份数据总是在向趋同的方向变化。属于弱一致性
Redis实战
共享Session(实现单点登录)
简介
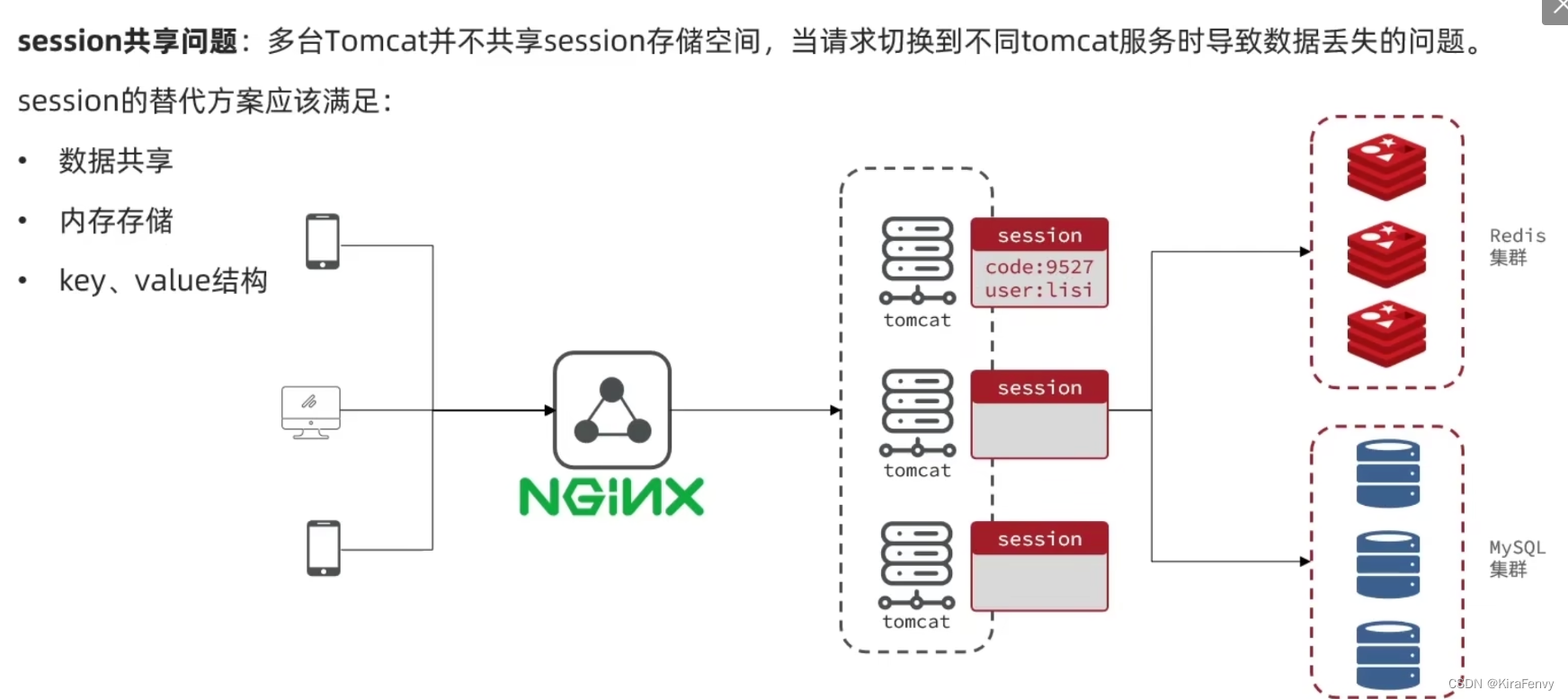
为什么需要共享Session?
防止多个后端服务器的数据存储不一致,导致用户访问时出现未登录的情况。
如何实现共享Session?
使用独立的内存存储来存放Session。
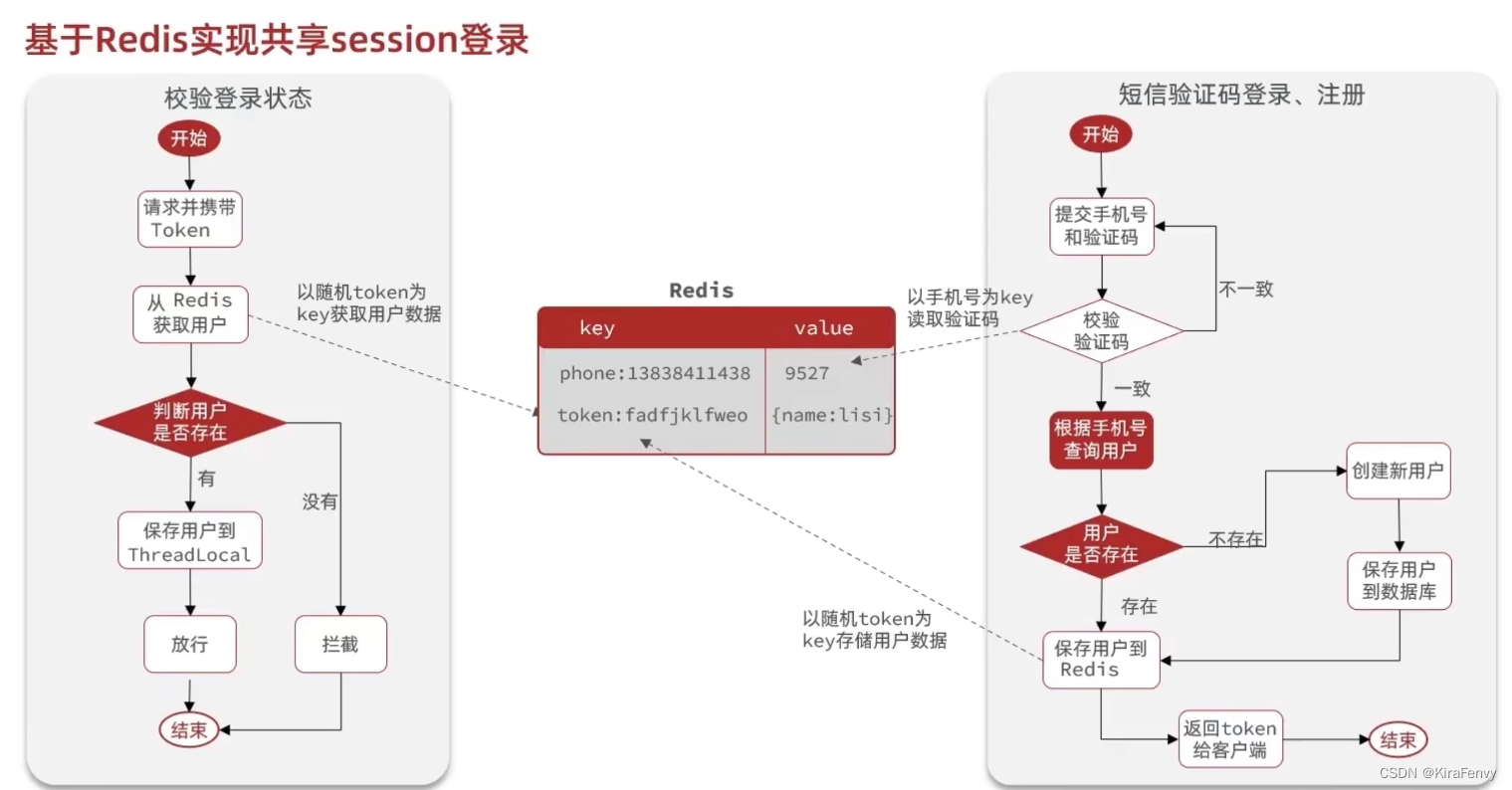
具体实现
key如何设计?
为了安全性,随机生成token,而不是拼接用户信息,防止恶意伪造或爆破。
选用何种value数据结构存放用户信息?
string还是hash?有以下两种方案:
1.先在程序中将对象进行JSON序列化,再以string类型写入
2.直接以hash数据结构写入
因为用户信息是对象,建议选择hash数据结构,占用内存更少、且支特对单个字段的增删改查。
具体流程如下:
注意事项
1.存入Redis的数据一定要设置过期时间!
2.存入Redis的数据尽量保证精简和安全,比如存入用户信息时可以移除密码等敏感数据
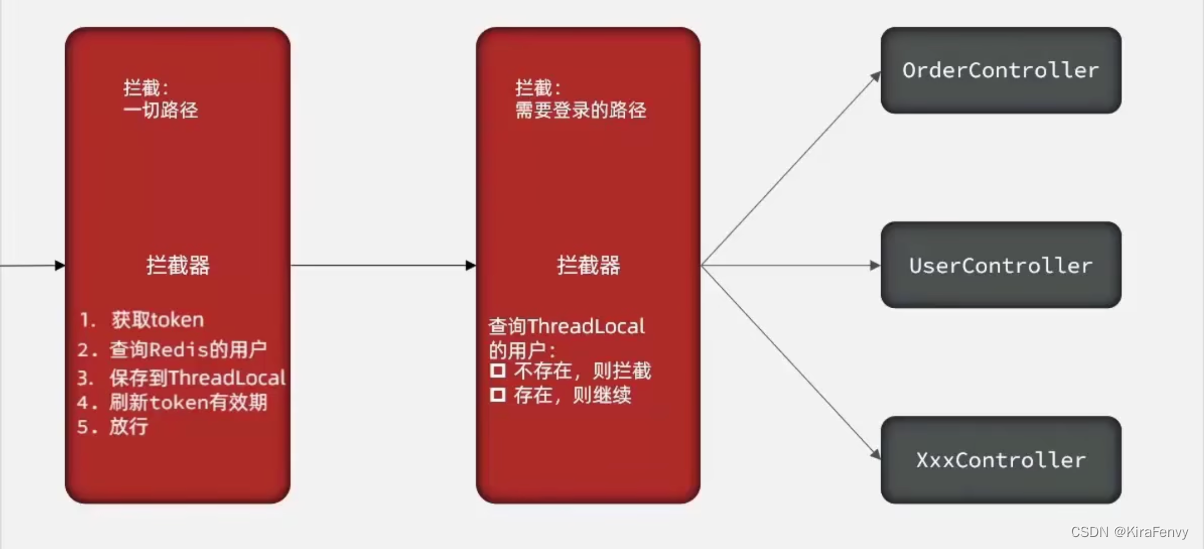
3.已登录用户访问系统后,记得刷新token过期时间(续期)。并且访问任何路径时都要刷新tokn,而不仅
是需要登录的路径。可以新增1层独立的拦截器来实现token刷新,如下图:
缓存
优点:
·降低后瑞节点负载
·提升数据读写性能
缺点:
·额的外引入中间件,增大运维成本
·额外开发和解决缓存带来的问题,增大开发成本
需要保证数据一致性
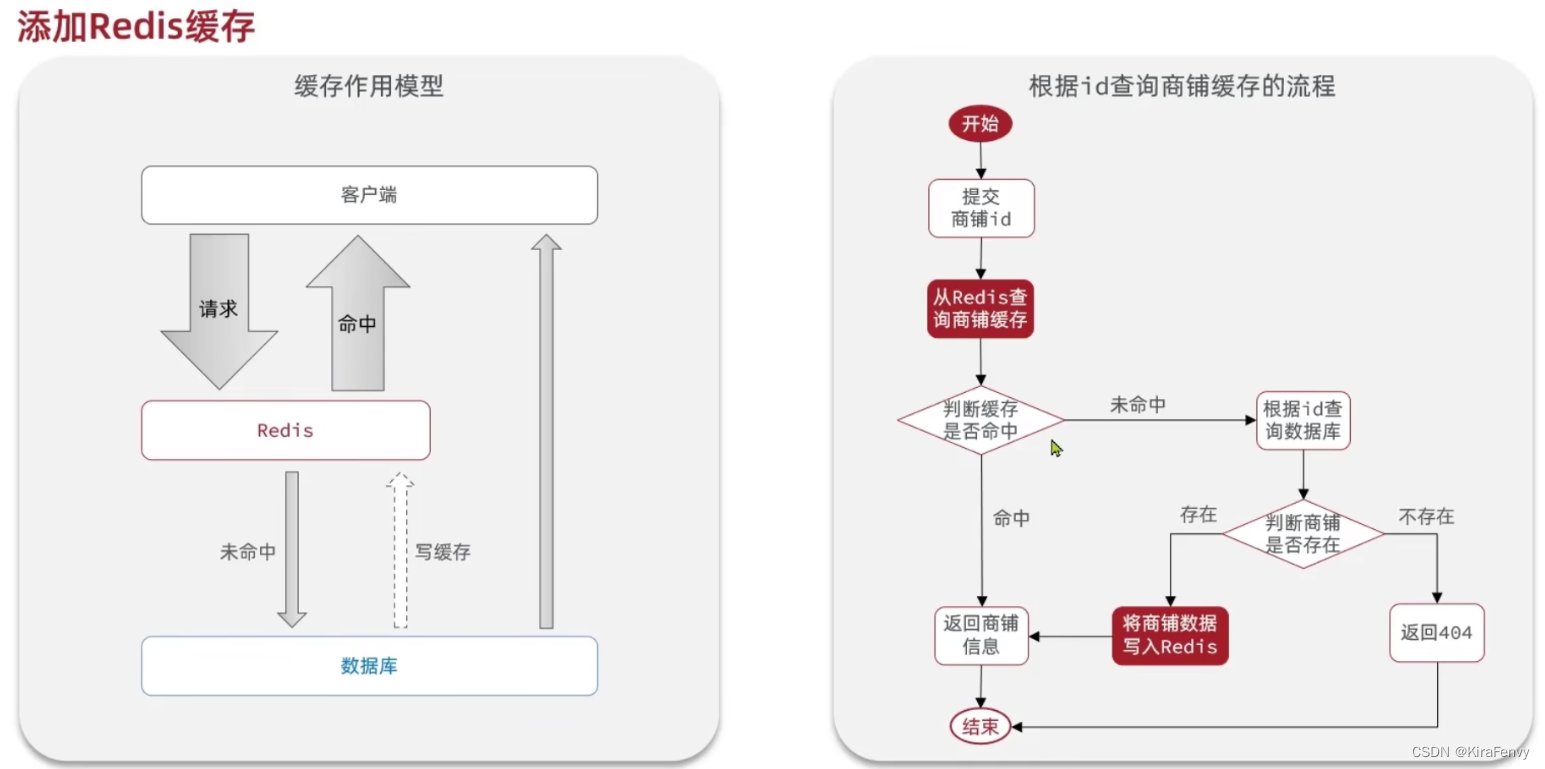
缓存的添加和查询
1.暂无缓存,从数据库读,然后设置(更新)缓存
2.已有缓存,直接读缓存
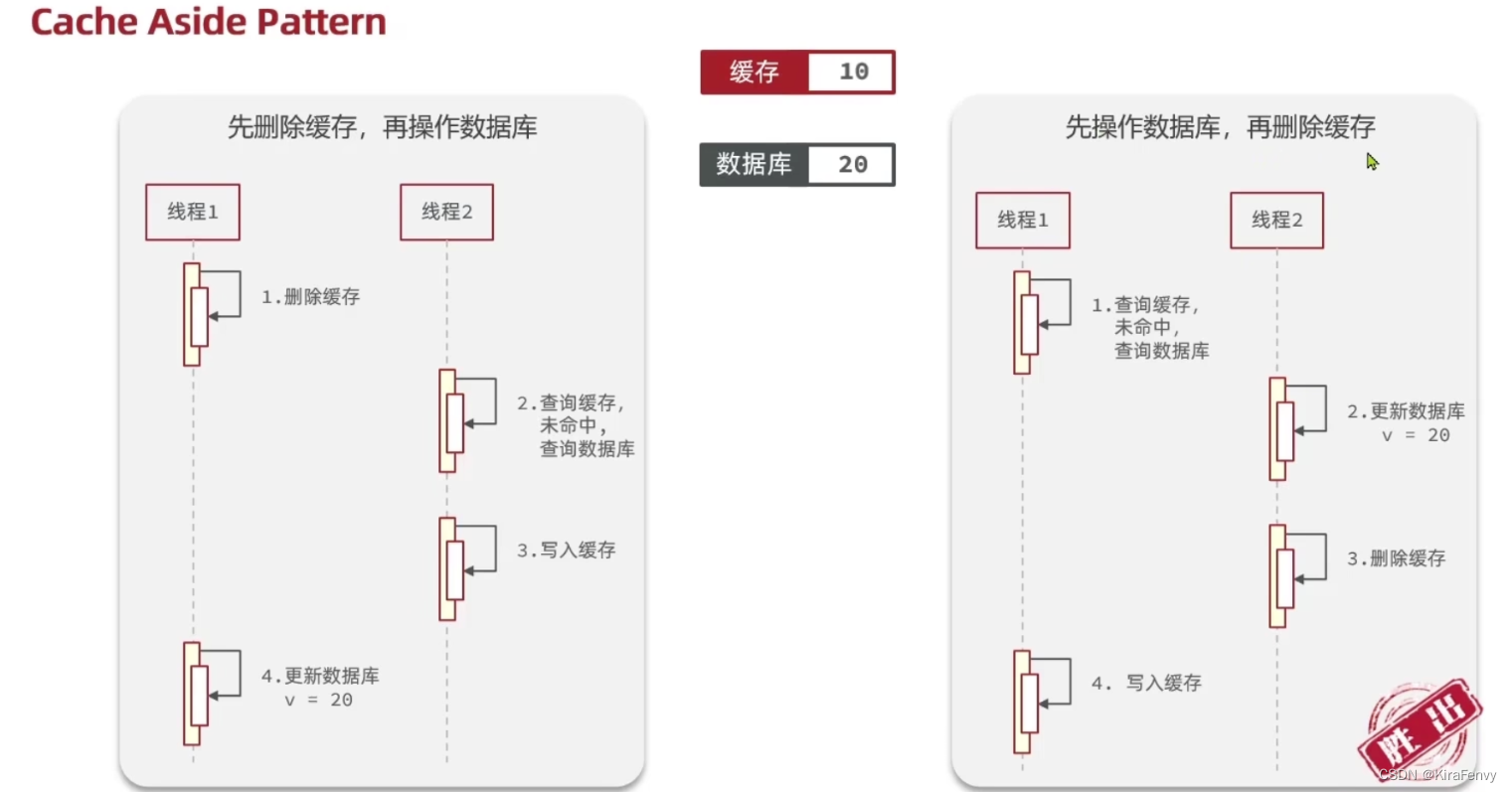
缓存的更新

多线程状态下缓存
多线程情况下,如何保证缓存和数据库的一致性?
1.单机:使用本地事务
2.分布式:使用TCC等分布式事务
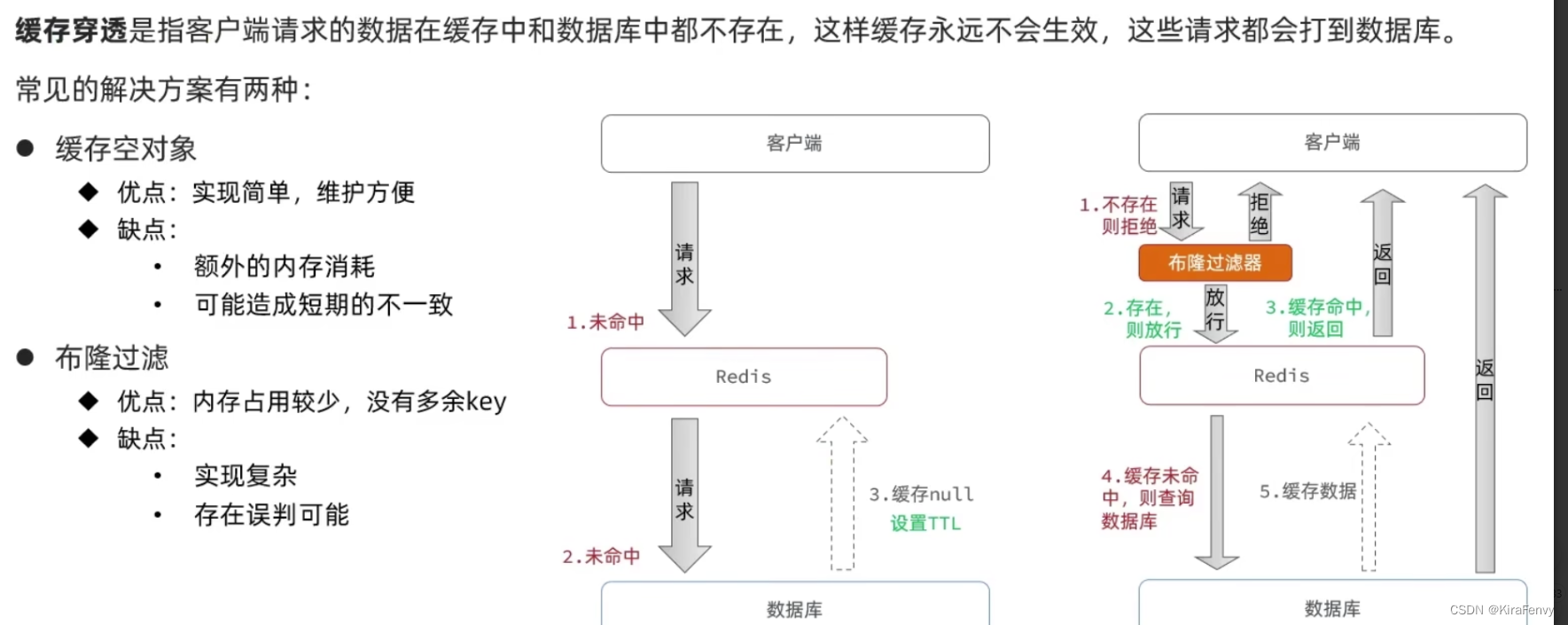
缓存穿透
攻击者可以恶意请求数据库中不存在的数据,从而使得每次查询都要绕过缓存查数据库,增大数据库的压力。
解决方案:
1.缓存空值:比如塞一个空字符串。注意可以给空对象的键过期时间设置短一些,或者在新增数据时强制清除下
对应缓存(防止查出来还是u)
2.布隆过滤器
预防做法:
1.增强对请求数据的校验,比如id>0
2.增强对数据格式的控制,比如id设置为10位,不为10位的请求直接拒绝
3.增强用户权限校验
4.通过限流来保护数据库
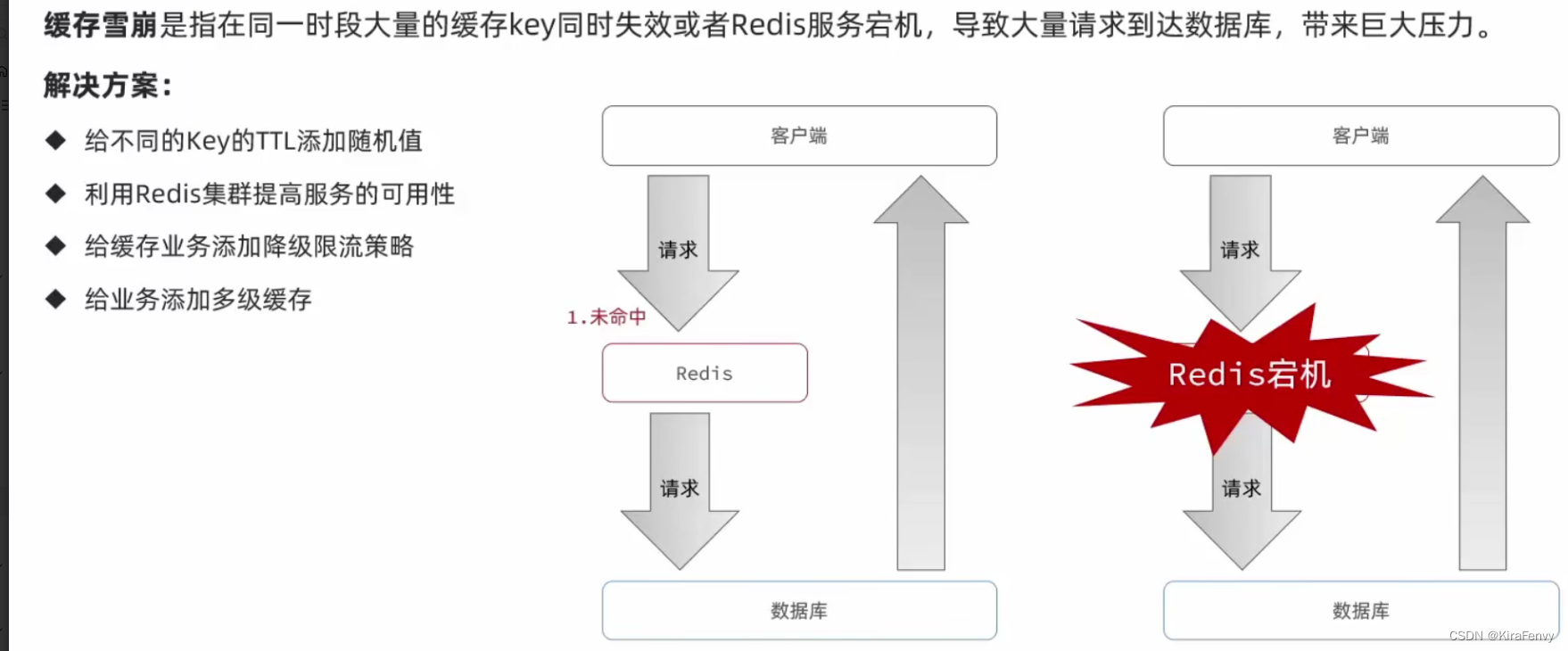
缓存雪崩
问题:大量key同时失效或Redis宕机导致大量请求访问数据库,带来巨大压力
解决思路:
1.不让key同时失效
2.尽量不让Redis宕机
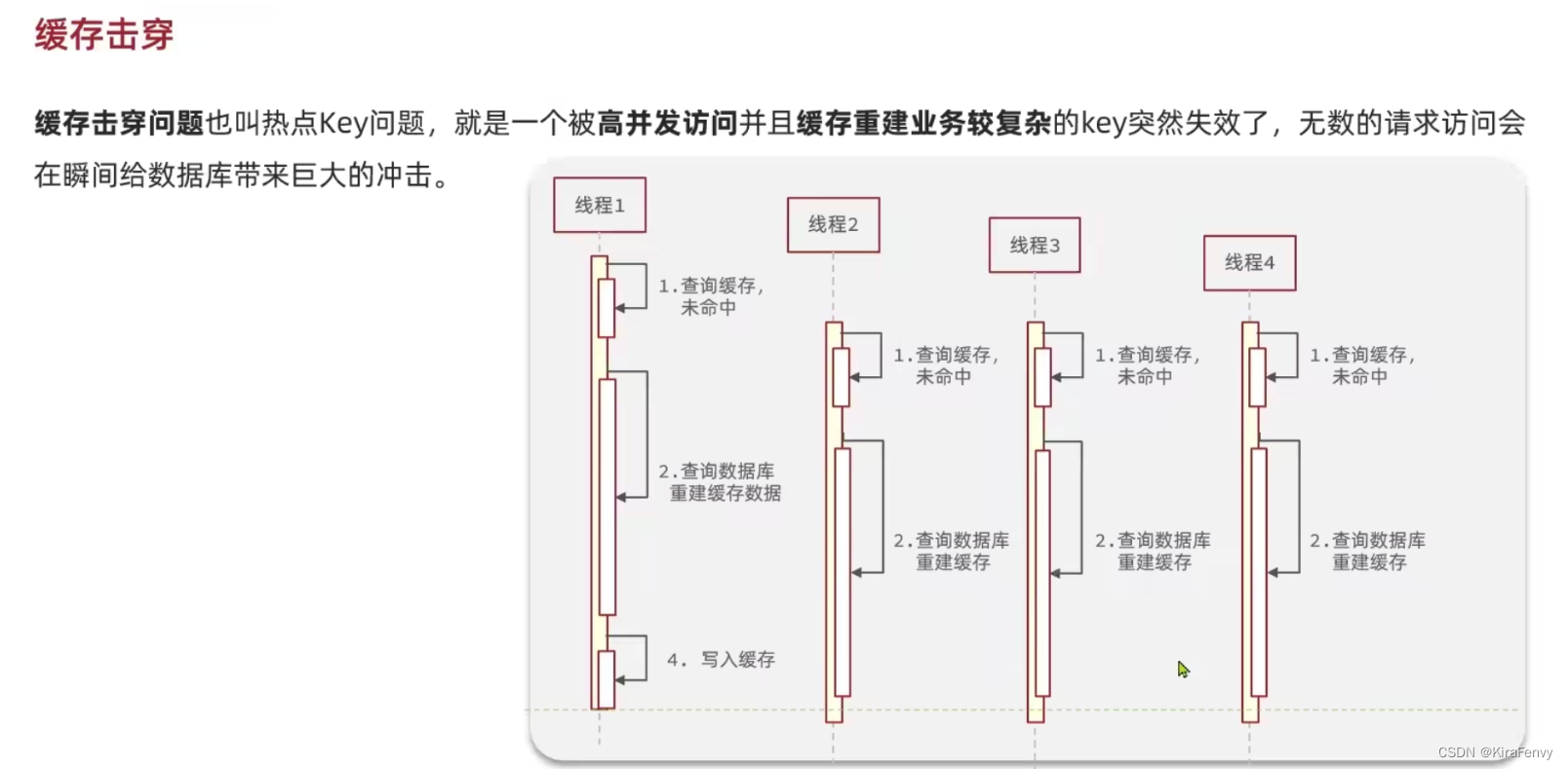
缓存击穿(热点key失效)
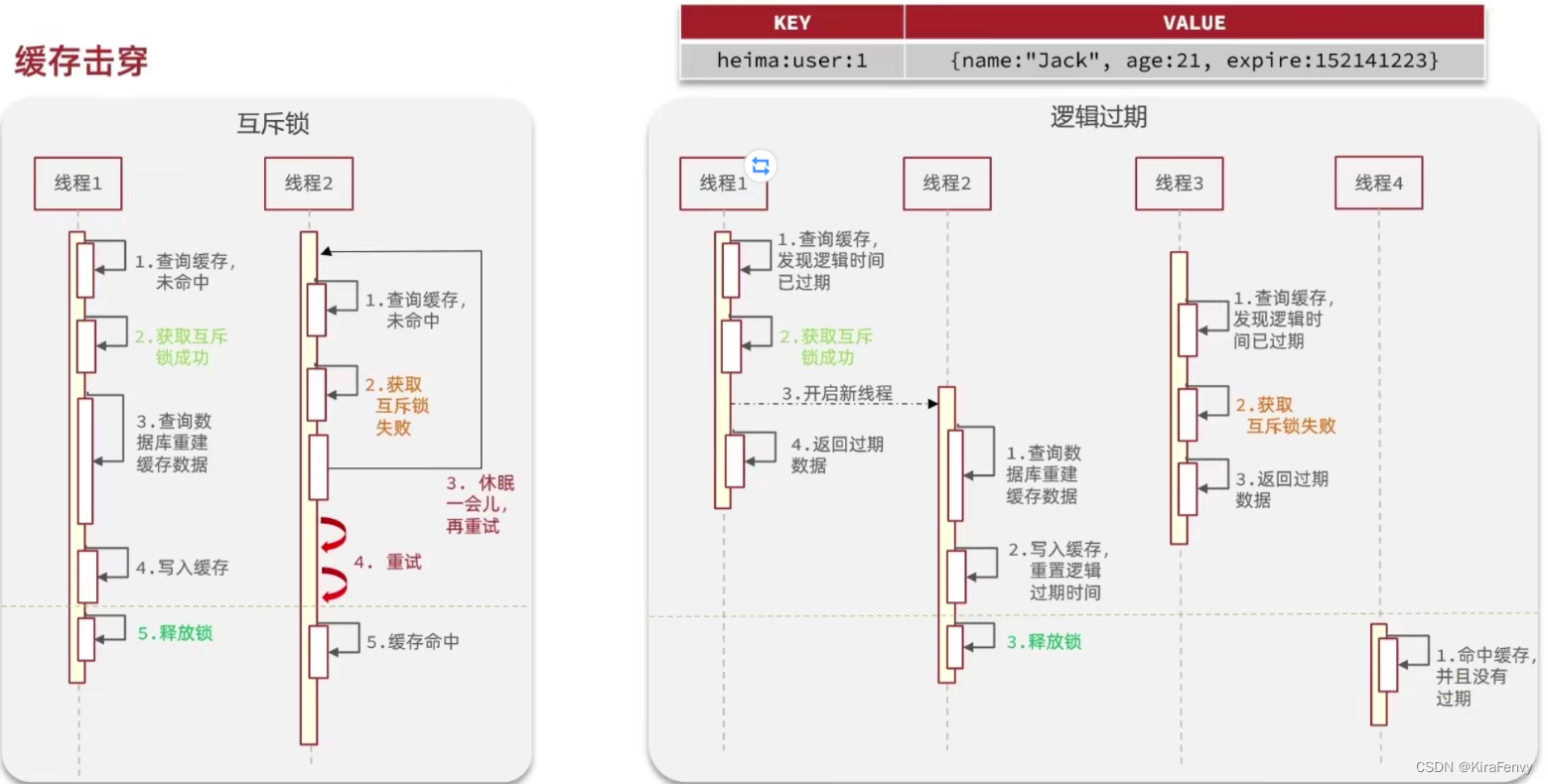
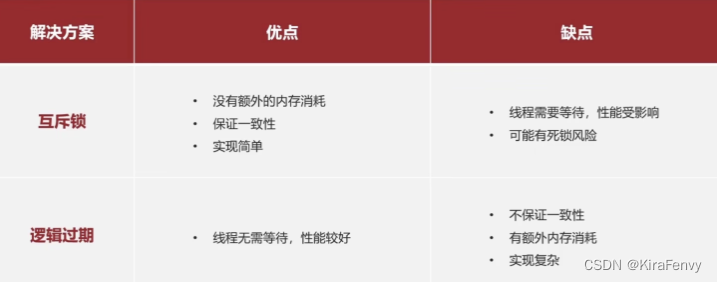
两种解决方案:
1.互斥锁:只有一个线程会负责缓存重建,其余线程拿不到锁,就等着
2.逻辑过期:key设置为永不过期,在value中记录过期时间,业务中根据这个过期时间来判断缓存是否有效;如果缓存已过期,只有一个线程能抢到锁(然后需要再次判断是否存在缓存),开启独立线程去更新缓存,然后立即返回过期数据;其他抢不到锁的线程也立即返回过期数据,不用等着锁释放。
分布式id全局生成
为什么需要分布式全局iD生成器
1.对于订单这种数据,数据库自增的规律性太明显,会暴露一些信息(比如根据昨日和今日的订单号差值看出销量)
2.数据量过大时,不同表的id分别自增,容易出现id冲突
分布式全局ID生成应满足的特点
1.唯一:整个系统每个id都是唯一的
2.递增:虽然不连续,但整体D保持递增,有利于数据库创建索引(也符合自然规律)
3.安全:不能通过id看出敏感业务信息
4.高可用:作为核心服务,不挂掉,否则会影响新数据的生成
5.高性能:作为频繁调用的服务,性能一定要高
Redis自增ID完全可以满足以上几个分布式全局ID的特点。
几种常见的生成方法
·雪花算法:性能更高,引入机器序号,但依赖全局时钟
·数据库自增:单独的自增表,所有id全从这个表取。但性能没有Redis高
·UUID:随机生成十六进制字符串,性能高,但是乱序、字符串会占用更多空间
·Redis自增ID:利用incr命令实现单key的自增
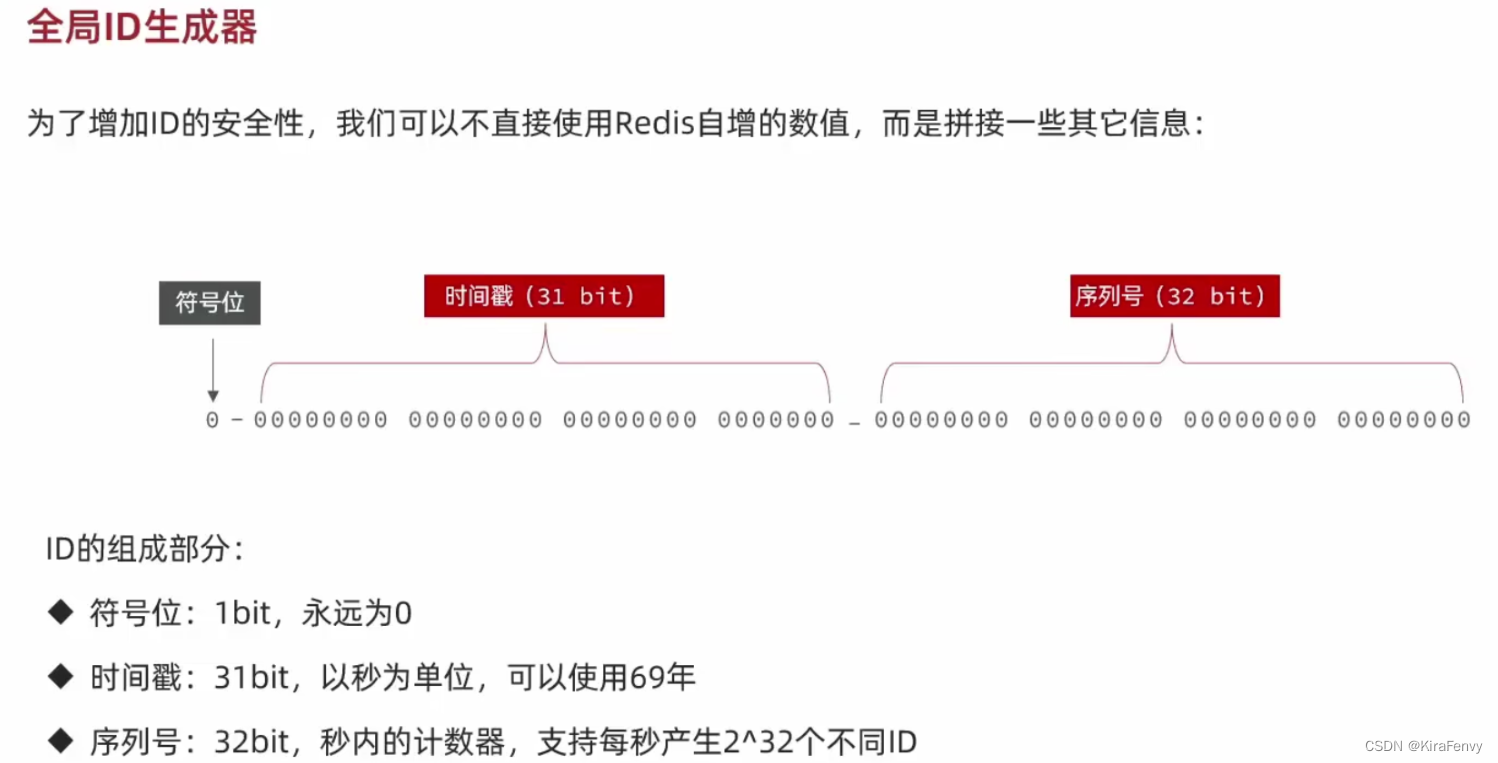
使用Redis的Incr命令,可以实现后32位的原子性递增。
Rdis的key可以设计为[业务]:[类型][日期],这样每天都会从1开始生成序列号。如果用单key,可能会出现生
成序号数溢出2∧32的情沉。
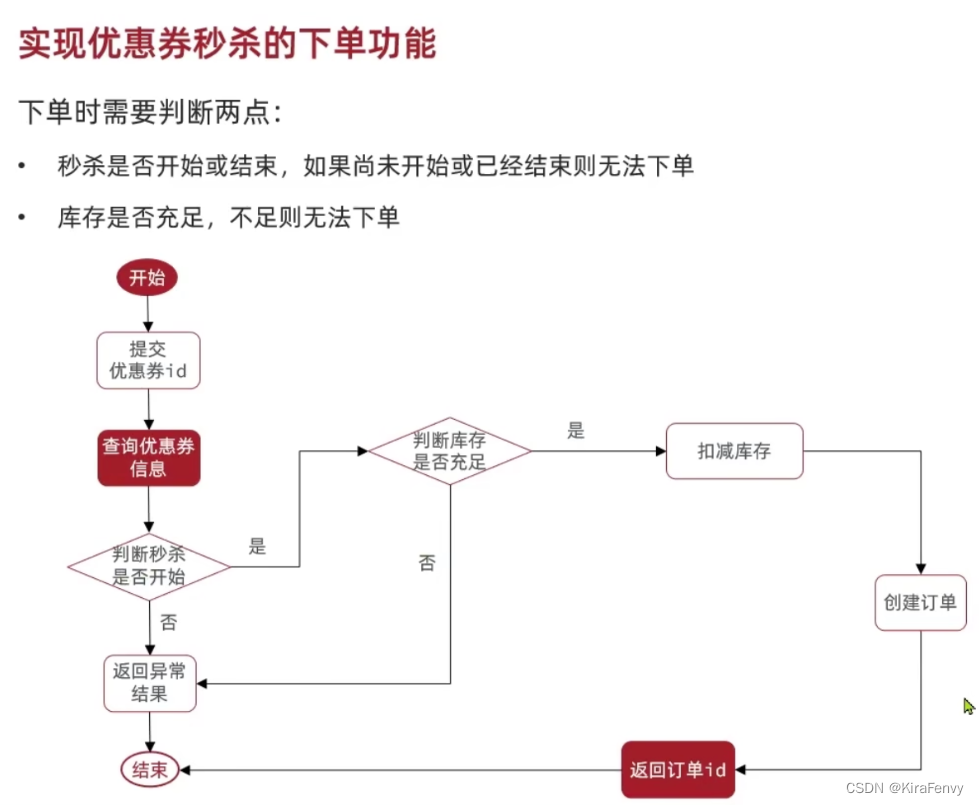
秒杀业务
秒杀业务的核心流程是:判断日期和库存、扣减库存、创建订单
如下图:
订单超卖问题
多个线程查到的库存都>0,都触发了扣库存操作
解决方案:
1)悲观锁:假定每次并发都会冲突,所以干脆给操作整体加锁,将并发改为同步执行,可以通过synchronized关键字实现.
优点是实现简单,缺点是严重影响性能(大家可以同时抢购)。
2)乐观锁:假定并发不一定会冲突,所以不加锁,而是通过判断数据是否在查出来之后被其他线程修改过,来决
定是否允许操作。乐观锁主要有版本号法和CAS两种实现方式。
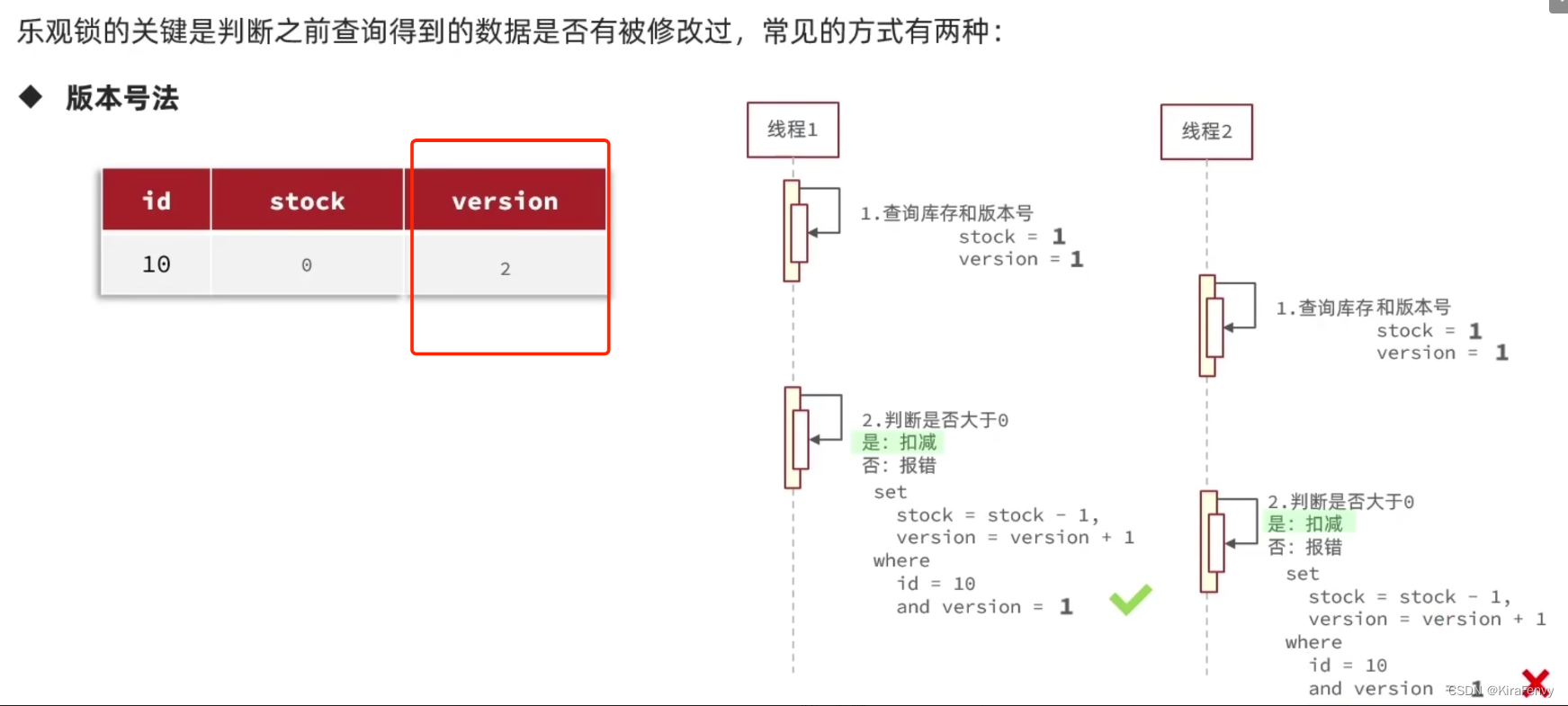
版本号法:
给数据增加一个版本号字段,每次修改操作版本号+1,就可以通过版本号来判断数据是否有被修改。
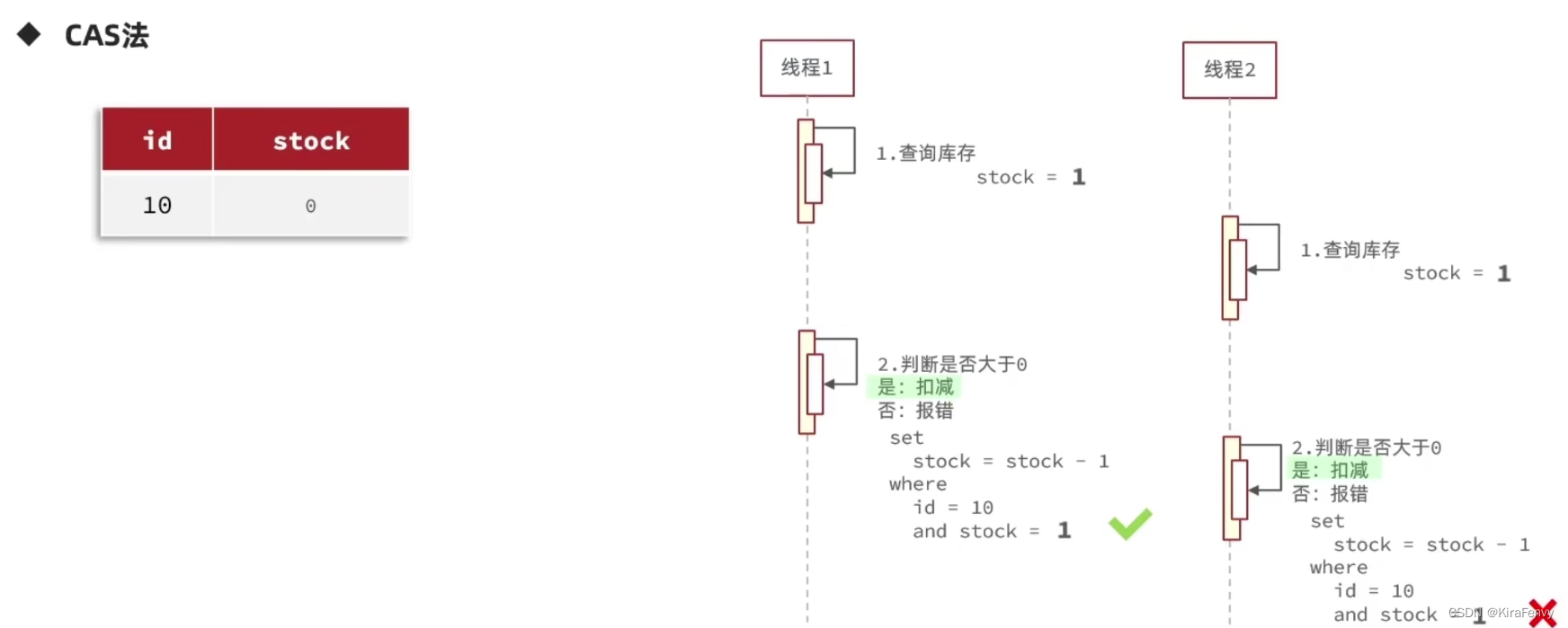
CAS法是用一个每次都会查询和更新的字段替代版本号,这里用stock
一人一单
优惠券或者秒杀活动的目的是为了吸引新用户,因此不能让一个用户把所有东西都抢走了。所以需要额外判断用户
当前下单数是否>0。
这一步操作在多线程场景下依然会出现问题:新用户第一次进来同时抢0次,结果判断下单数都是0,然后就都
抢成功了。
所以还是需要加锁,因为订单是新创建的数据,所以无法使用乐观锁,使用悲观锁实现。
单机实现
单机部署后瑞服务器时,可以使用Java自带的Synchronized关键字作为悲观锁。
要注意以下几个细节问题:
1)synchronized锁的范围不能太大,不能锁住整个对象,会严重影响性能。因为是一人一单,所以可以每个用
户一把独立的锁。
注意,锁住对象时要用toString.intern,保证同id的用户始终是同一个对象:
2)synchonized必须在使用@Transactional注解的方法外层使用,因为@Transactional是使用动态代理,在
方法执行结束后才提交事务。如果把synch「onized写在事务方法内,提交事务前锁已经释放,但比时数据还未更
新,其他线程依然能获取锁并顺利执行。
3)调用事务方法时不能用this对象,因为@Transactional注解实际上是调用Spring生成的代理对象的方法,
如果调用ts对象的方法会无法使用事务功能,所以要获取代理对象并调用。
分布式实现
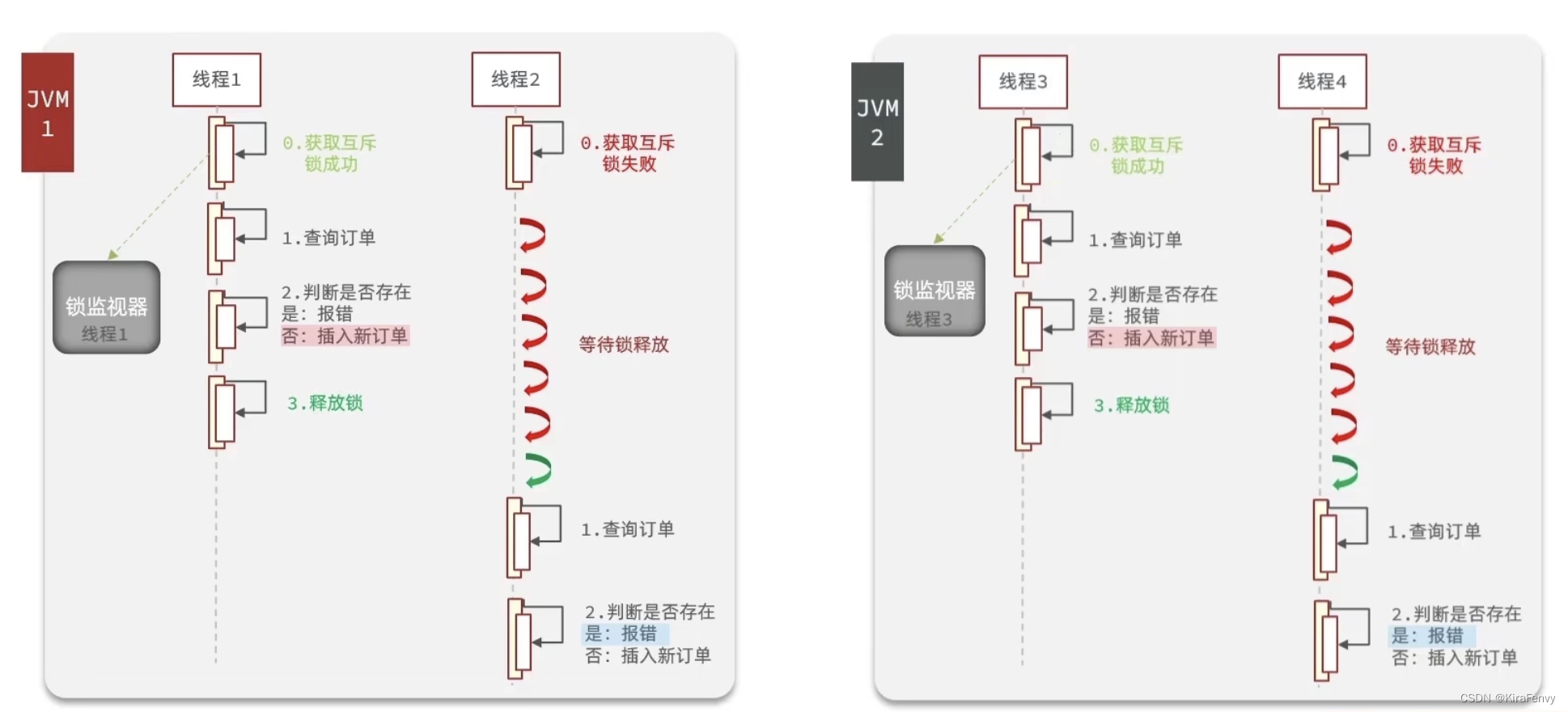
因此,我们不能把锁存储到单个服务器上,而是应该使用一个集中的存储来管理锁,所有进程都能读到它。
这就需要分布式锁。
分布式锁
分布式锁:满足分布式系统或集群模式下多进程可见并且互斥的锁。
分布式锁的两个基本特征:
1.多进程(线程)可见(读写)
2.互斥
还应具备的特征:
1.高可用:不挂机
2.高性能:读写要快
3.安全性:不能出现死锁
实现方式
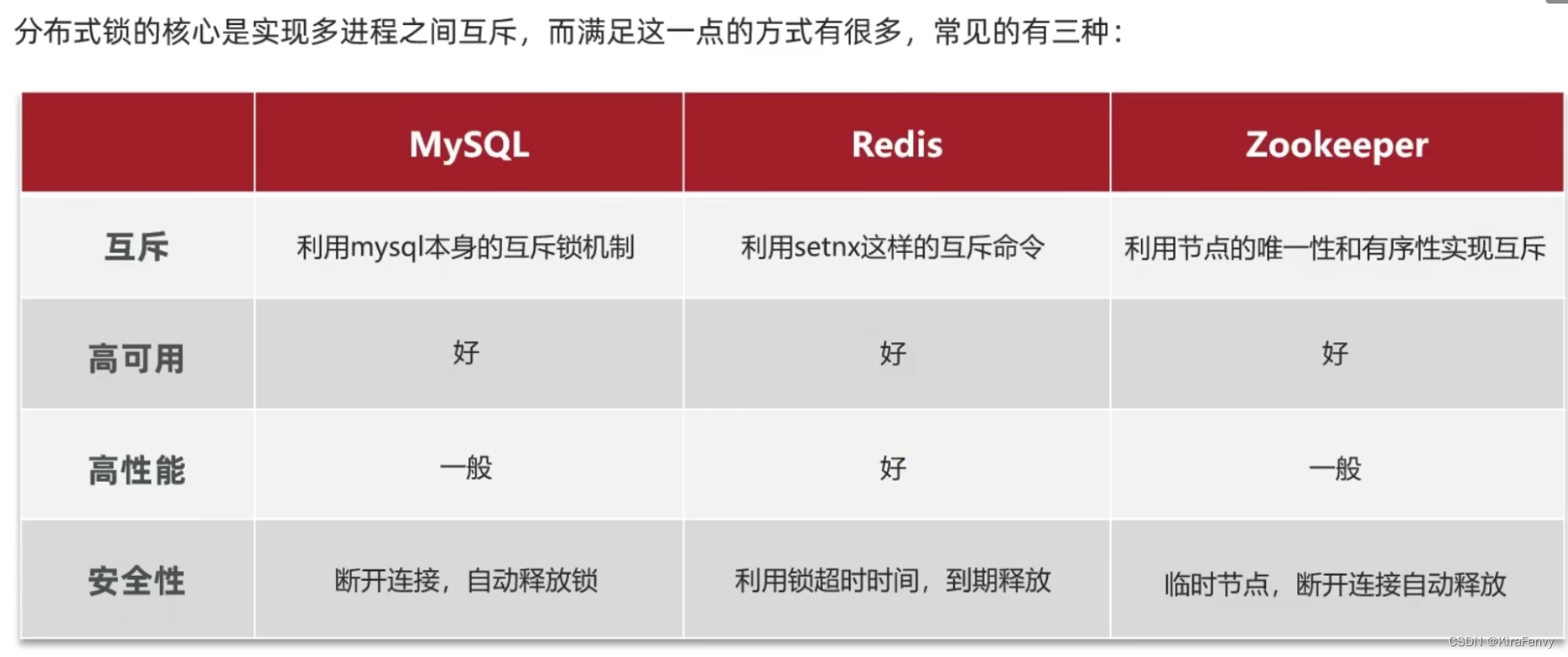
其中,小ySQL的实现成本相对最低、Redis性能最高、Zookeeper可以实现但不推荐使用(Zk重点在于保证强
一致性而不是性能和高可用性,CP模型)
Redis分布式锁实现
获取锁:
·使用setnx命令设置Iock(本质是创建一个rdis键值对),保证只有一个线程获取锁成功(满足互斥)并执行业务逻辑,其他线程可以重试或返回失败。
·必须setex指定lock的过期时间(满足安全性)
注意事项:
1.为了防止setnx后就宕机了导致lock永久存在,必须使用set[key)exnx的原子命令,保证每个lock都有过期时间。
2.锁的ky值建议设计为包含userld的,保证多个用户可以并发执行操作,而不是多个用户抢同一把锁。
释放锁:
·主动释放:业务执行完成删掉key,注意需要把释放锁的逻辑放到finally里保证一定执行
·超时自动释放(key过期)
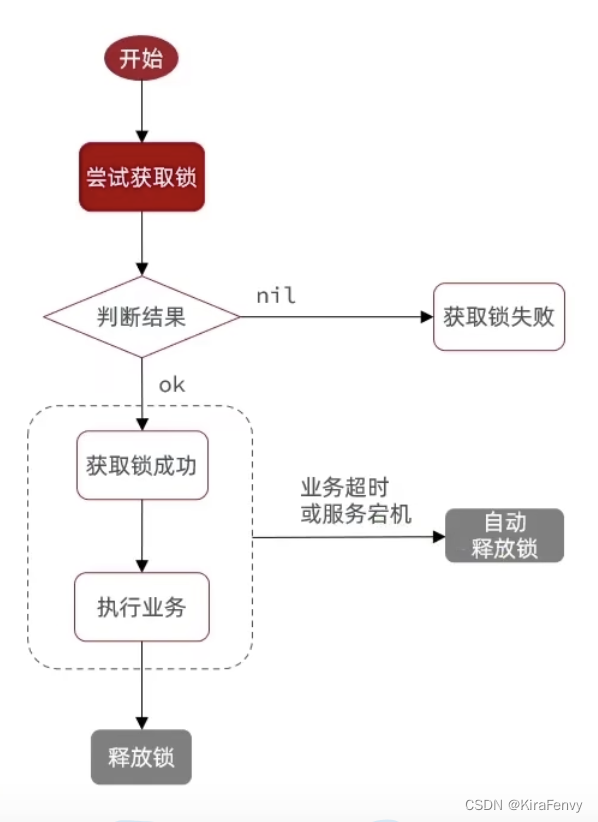
误删问题(待补充)
其它问题
Redisson实现分布式锁
使用方式非常简单:
1)引入独立的redisson包:
不建议引入springboot-starter,因为可能会和springboot内置的redis整合冲突
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson</artifactId>
<version>3.17.6</version>
</dependency>
2)创建一个Redisson客户端
import lombok.Data;
import org.redisson.Redisson;
import org.redisson.api.Redissonclient;
import org.redisson.config.Config;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@ConfigurationProperties(prefix "spring.redis")
@Configuration
@Data
public class RedissonclientConfig{
private String host;
private int port;
private int database;
private String password;
@Bean
public Redissonclient getRedissonclient(){
Config config new Config();
String redisAddress String.format("redis://%s:%s",host,port);
config.usesingleServer().setAddress(redisAddress).setDatabase(database).setPasswor
return Redisson.create(config);
}
}
3)Redisson的lock
RLock lock redissonclient.getLock(lockName);
Object result null;
//获取锁成功,执行方法
if (lock.tryLock(0,leaseTime,TimeUnit.MILLISECONDS)){
log.info("{}getLock",lockName);
try{
doSomething();
}
finally{
if (lock.isHeldByCurrentThread()){
lock.unlock();
}
}
else{
/获取锁失败
log.info("{}not getLock",lockName);
}
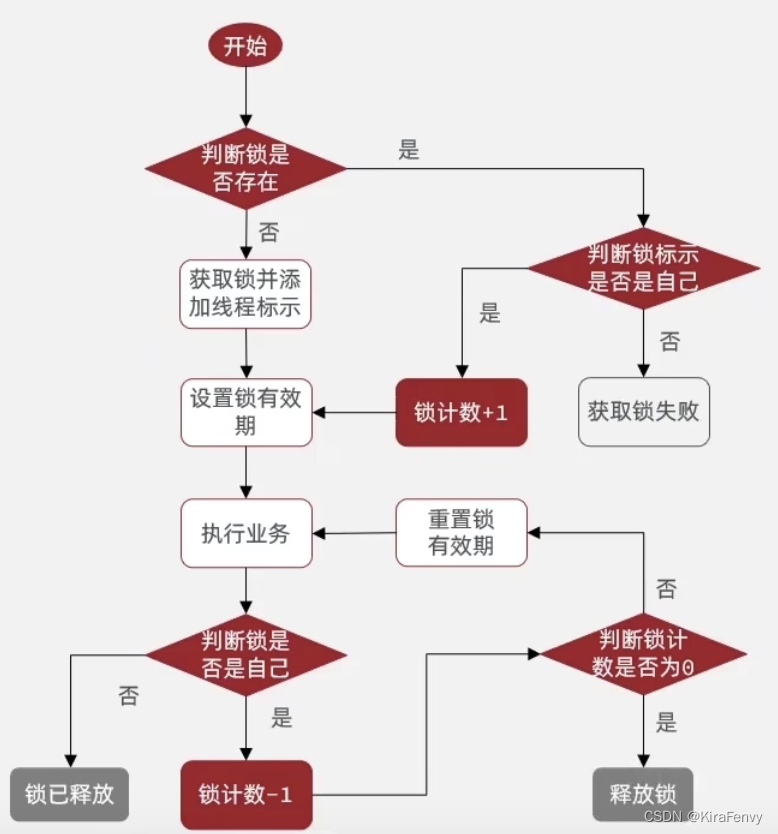
如何实现可重入锁
目的:保证同一个线程可以多次获取同一把锁
解决思路:在锁的value中额外保存当前线程获取锁的次数,每次获取锁+1、释放锁-1,当次数为0时才真正
删除key
采用hash结构来存储锁信息,如图:
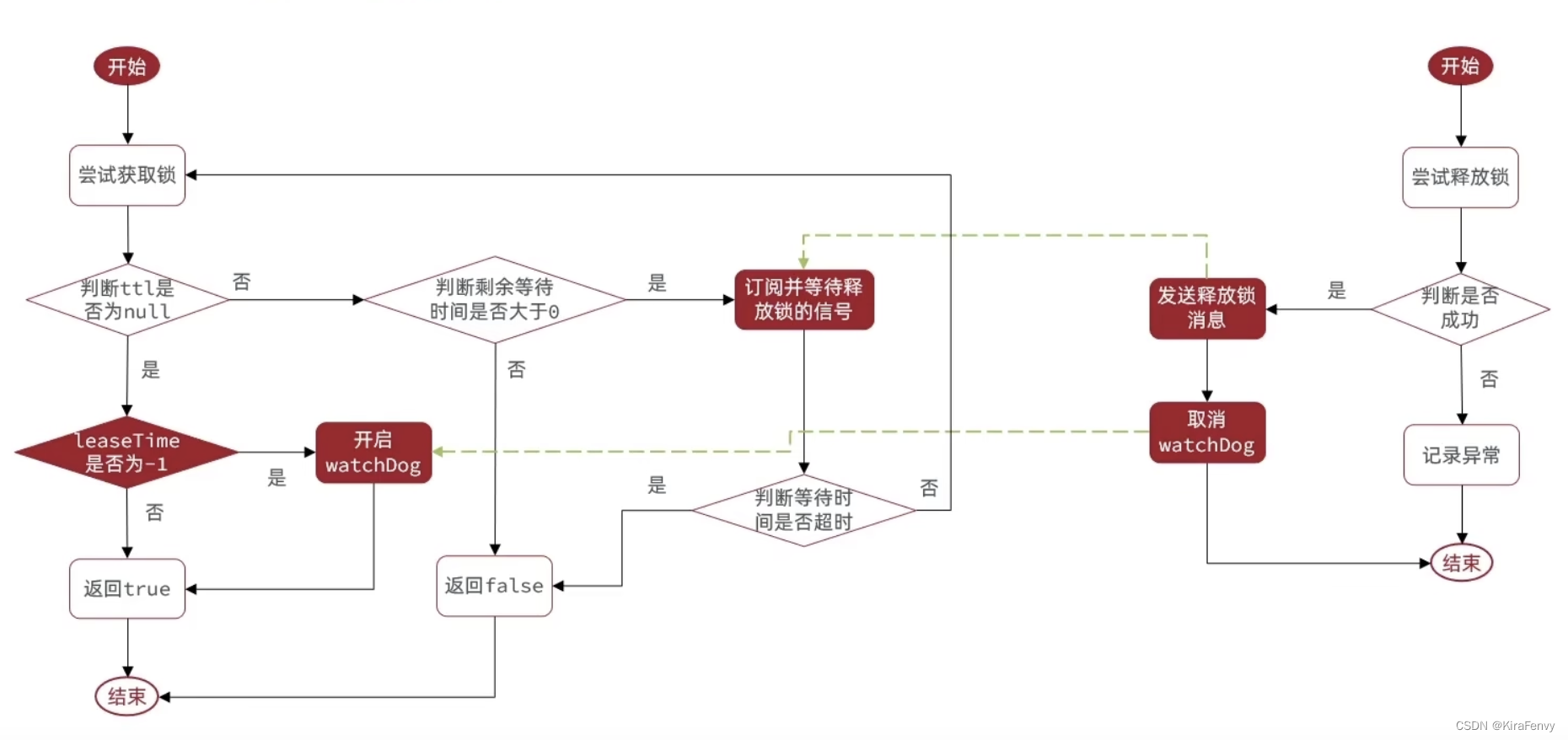
如何重试获取锁
基于Redis Pub/Sub发布订阅机制。如果获取锁失败,则阻塞订阅释放锁的消息;当锁被释放时,会触发推送
告诉其他线程我释放锁啦),然后其他线程再重试获取;如此往复如何防止锁提前超时释放?
防止锁提前超时释放
基于看门狗机制。如果不手动设置锁释放时间(leaseTime),默认设置30秒过期,并且给当前锁注册一个定时
任务,该定时任务每隔1/3的锁释放时间(一般是10秒)会重置锁的过期时间(递归调用,一次续期完了
再)。
需要思考两个问题:
1.如何保证同一个锁只注册一个定时任务?
2.如何防止无限续期?
要解决这些问题,使用全局ConcurrentHashMap来管理锁=>任务信息,key为锁的id,从而保证唯一。当某
个锁释放时,从全局ConcurrentHashMap中取出定时任务并取消掉,然后把锁的信息从Map中删掉即可。
如何解决主从一致性问题
如果使用主从复制的Rdis集群,可能出现主从节点设置的锁状态不一致的问题。
可以使用Redisson的MultiLock(联锁)来解决,核心思想是开启多个独立的Redis主节点,设置锁时必须在
所有主节点都写入成功,才算设置成功。
这样做之后,哪怕有部分节点挂掉,其他线程也无法setnx全部成功,就不会出现重复执行业务的情沉。
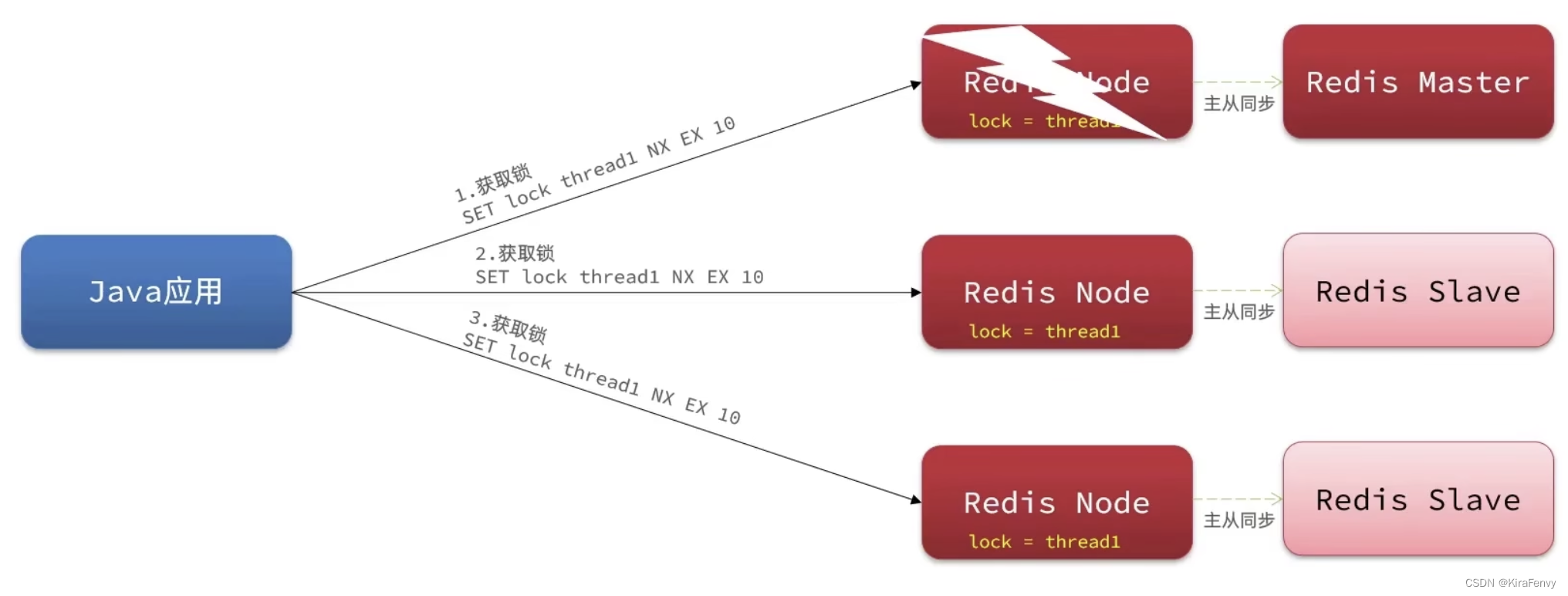
实现MultiLock的几个关键:
1.遍历所有节点,依次设置锁,并使用列表来记录所有主节点的锁是否设置成功。
2.只要有一个节点设置不成功,就要释放所有的锁,从头来过。
3.因为不同节点设置锁成功的时间不同,所以在所有锁设置成功后,要统一设置过期时间(但如果leaseTime=-1就不用了,因为开启了看门狗机制会自动续期)
4.锁释放时间(leaseTime)必须要大于抢锁最大等待时间(waitTime),否则可出现第一个节点抢到锁,最后一个节点还没抢到锁,之前的锁就已经超时释放了。所以如果指定了waitTime和leaseTime,默认leaseTime waitTime 2.
MultiLock最安全,但同样会带来很大的运维成本。
秒杀业务优化
优化思路:
- ·串行改并行:原本由1个线程的操作改为由2个或多个线程同时操作,比如1个线程负责判断秒杀资格,1
个线程负责减库存+创建订单(写) - ·同步改异步:判断完秒杀资格后,就可以返回订单d给前端;:其余的写库操作可以异步执行。
- ·提高判断秒杀资格的性能:读DB改为读Redis
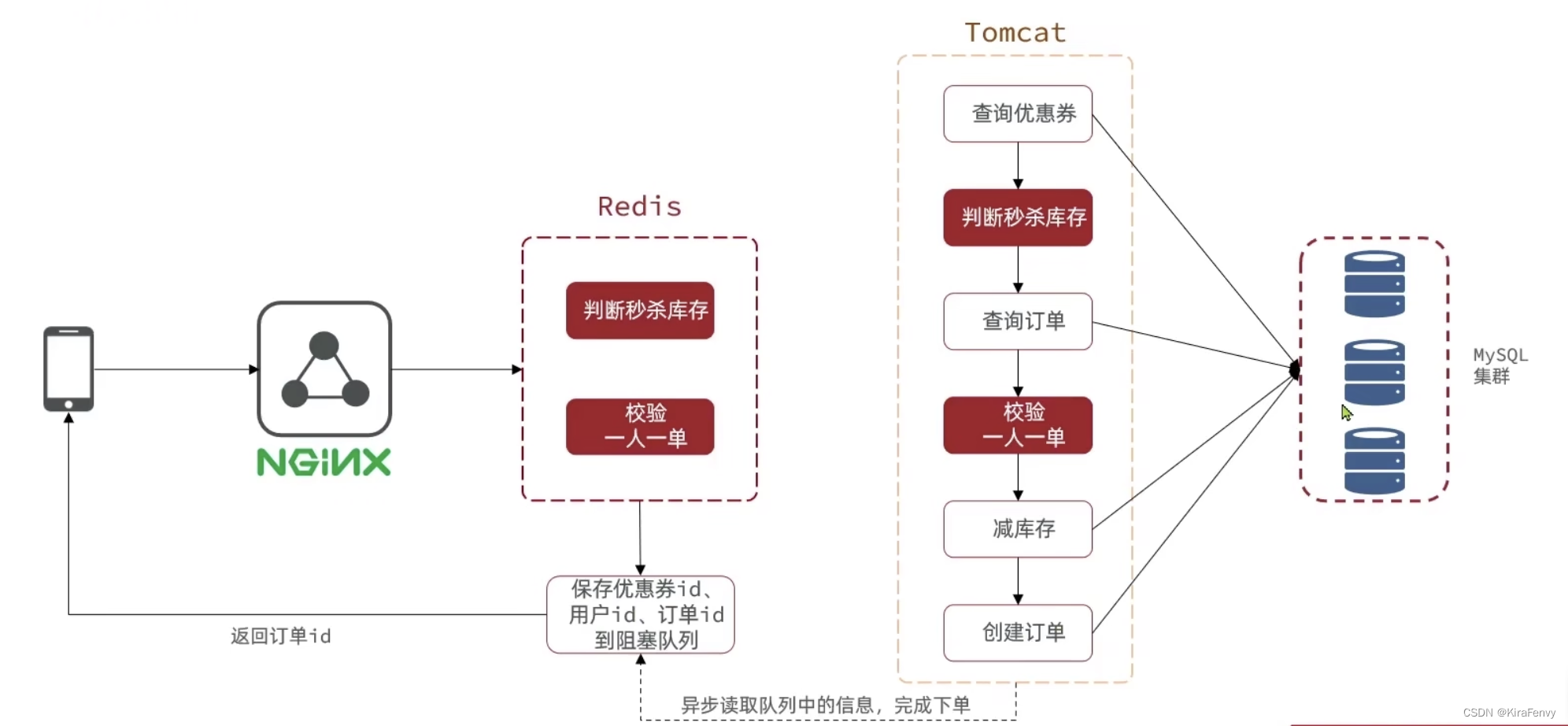
优化后的流程如下:
1)将库存信息提前缓存到Redis中,并使用set来记用户是否已下单,实现仅在Redis里判断秒杀资格
2)将判断秒杀资格的逻辑封装为Lua脚本,保证原子性,原业务流程调用即可
3)确认有秒杀资格后,将订单等信息传递给阻塞队列,单个独立线程串行从队列中取出信息并异步下单
消息队列
JDK阻塞队列可能存在哪些问题?
1.服务器宕机,内存队列中的订单信息全部丢失
2.线程处理错误,已取出单个订单信息,但没有入库
3.受单JVM内存限制
所以,我们需要一个独立的队列来存管订单信息,也就是消息队列。
什么是消息队列?
存管消息的队列,也是一种开发中常用的中间件。
消息队列包括3个角色:
1.消息队列:用于存管消息,类似快递柜
2.生产者:发送消息到队列,类似快递员
3.消费者:从队列取走消息,类似取快递的人
如图:

使用消息队列的优点(或者说是对其的要求)
·可以保证我们消息的安全、不会丢失(快递柜上锁)
·可以解耦生产者和消费者(不用立刻去取快递)
·独立组件,不影响JVM
·可以保证消息一定被接受,避免线程处理错误后订单丢失的问题
·消息是有序的
实现方式
Redis List实现
使用Redis List的结构作为消息队列,使用LPush模拟生产者发送消息入队,使用BRPOP(阻塞弹出)模拟消费者取出消息。没有消息时会保持阻塞状态,从而实现了类似小M阻塞队列的效果。
可以满足消息队列的安全性(Rdis持久化机制)、有序性、独立内存的要求。
缺点:
1.只能存在单消费者
2.消息获取之后就删除了,无法保证业务一定处理成功
Redis Pub/Sub实现
使用Redis的订阅发布模型,生产者可以将消息推送给某个Channel(频道),多个消费者可以订阅该频道,从
而同时得到消息。(可以理解为”你关注的UP主更新啦”)
用到的命令主要是:
·Publish推送
·SubScribe订阅
·PSubScribe订阅某个表达式匹配的多个频道
这样就实现了多生产、多消费。
缺点比较多:
I.Pub/Sub是一次性的,Rdis不会保存发过的消息,没人收的话消息就会丢失
2.因为上一点,它也无法做数据特久化
3.客户端虽然可能会缓存已收到的消息,但也是有上限的,可能还是会丢失消息
Redis Stream
这是Redis5.0新出的数据结构,可以实现单向的消息队列。
核心命令:
·XAdd:添加消息/创建队列,消息会自动特久化、不会丢失,每个消息都有唯一d
·XRead:读取消息,支持多消费者读、可从指定消息id开始读、支持阻塞读最新消息
只用这两个命令还是不够的,因为目前只支特阻塞读最新消息,假设处理消息过程中又来了几条消息,可能出现
漏读消息的情况
为解决上述问题,可以用Stream的以下特性:
·消费组:同组内的多个消费者可以竞争消费(每个消息只有一个消费者抢到),从而提高消费能力(并发
度)。对应命令为XGROUP、XREADGROUP等。
·消息标识:自动记录消费的进度,支特从上次未消费的地方开始接着消费,保证每条消息按顺序消费
·消息确认机制:默认消费的消息为pending状态,会放到每个消费者的pending list中,只有消息由消费者确认(ACK),才会从pending list移除。这样如果消费业务处理异常,可以从pending list的开头依次读取未确认消息,重试处理。(也要避免无限重试,实在处理不成功就强制ACK+业务记日志)
注意,Redis虽然可以实现较完备的消息队列,但还是不如专业的消息队列像Kafka、RabbitMQ、RocketMQ
要专业,比如特久化能力较差、不支持生产确认、消费顺序性等。