目录:导读
前言
软中断频率过高案例
系统配置
Ubuntu 18.04, 2 CPU,2GB 内存,共两台虚拟机
三个工具
sar:是一个系统活动报告工具,既可以实时查看系统的当前活动,又可以配置保存和报告 历史统计数据。
hping3:是一个可以构造 TCP/IP 协议数据包的工具,可以对系统进行安全审计、防火墙 测试等。
tcpdump:是一个常用的网络抓包工具,常用来分析各种网络问题
通过 docker 运行案例
在 VM1 中执行命令
docker run -itd --name=nginx -p 80:80 nginx
通过 curl 确认 Nginx 正常启动
在 VM2 中执行命令
curl http://172.20.72.58/
通过 hping3 模拟 Nginx 的客户端请求
在 VM2 中执行命令
hping3 -S -p 80 -i u100 172.20.72.58
-S:参数表示设置 TCP 协议的 SYN(同步序列号)
-p:表示目的端口为 80
-i:u100 表示每隔 100 微秒发送一个网络帧
回到 VM1
感觉系统响应明显变慢了,即便只 是在终端中敲几个回车,都得很久才能得到响应
分析系统为什么会响应变慢
以下命令均在 VM1 中执行
通过 top 命令查看系统资源使用情况

系统 CPU 使用率(用户态 us 和内核态 sy )并不高;
平均负载适中,只有 2 个 R 状态的进程,无僵尸进程;
但是软中断进程1号(ksoftirqd/1)的 CPU 使用率偏高,而且处理软中断的 CPU 占比已达到 94;
此外,并无其他异常进程;
可以猜测,软中断就是罪魁祸首;
确认是什么类型的软中断
观察 /proc/softirqs 文件的内容,就能知道各种软中断类型的次数
这里的各类软中断次数,又是什么时间段里的次数呢?
它是系统运行以来的累积中断次数
所以直接查看文件内容,得到的只是累积中断次数,对这里的问题并没有直接参考意义
中断次数的变化速率才是我们需要关注的
通过 watch 动态查看命令输出结果
因为我的机器是两核,如果直接读取 /proc/softirqs 会打印 128 核的信息,但对于我来说,只要看前面两核的信息足以,所以需要写提取关键数据
watch -d "/bin/cat /proc/softirqs | /usr/bin/awk 'NR == 1{printf \"%-15s %-15s %-15s\n\",\" \",\$1,\$2}; NR > 1{printf \"%-15s %-15s %-15s\n\",\$1,\$2,\$3}'"

结果分析
TIMER(定时中断)、 NET_RX(网络接收)、SCHED(内核调度)、RCU(RCU 锁)等这几个软中断都在不停变化;
而 NET_RX,就是网络数据包接收软中断的变化速率最快;
其他几种类型的软中断,是保证 Linux 调度、时钟、临界区保护这些正常工作所必需的,所以有变化时正常的;
通过 sar 查看系统的网络收发情况
上面确认了从网络接收的软中断入手,所以第一步应该要看下系统的网络接收情况
sar 的好处
不仅可以观察网络收发的吞吐量(BPS,每秒收发的字节数)
还可以观察网络收发的 PPS(每秒收发的网络帧数)
执行 sar 命令
sar -n DEV 1

第二列:IFACE 表示网卡
第三、四列:rxpck/s 和 txpck/s 分别表示每秒接收、发送的网络帧数【PPS】
第五、六列:rxkB/s 和 txkB/s 分别表示每秒接收、发送的千字节数【BPS】
结果分析
对网卡 ens33 来说
每秒接收的网络帧数比较大,几乎达到 8w,而发送的网络帧数较小,只有接近 4w;
每秒接收的千字节数只有 4611 KB,发送的千字节数更小,只有2314 KB;
docker0 和 veth04076e3
数据跟 ens33 基本一致只是发送和接收相反,发送的数据较大而接收的数据较小
这是 Linux 内部网桥转发导致的,暂且不用深究,只要知道这是系统把 ens33 收到的包转发给 Nginx 服务即可
异常点
前面说到是网络数据包接收软中断的问题,那就重点看 ens33
接收的 PPS 达到 8w,但接收的 BPS 只有 5k 不到,网络帧看起来是比较小的
4611 * 1024 / 78694 = 64 字节,说明平均每个网络帧只有 60 字节,这显然是很小的网络帧,也就是常说的小包问题
灵魂拷问
如何知道这是一个什么样的网络帧,它又是从哪里发过来的呢?
通过 tcpdump 抓取网络包
已知条件
Nginx 监听在 80 端口, 它所提供的 HTTP 服务是基于 TCP 协议的
执行 tcpdump 命令
tcpdump -i ens33 -n tcp port 80
-i ens33:只抓取 ens33 网卡
-n:不解析协议名和主机名
tcp port 80:表示只抓取 tcp 协议并且端口号为 80 的网络帧
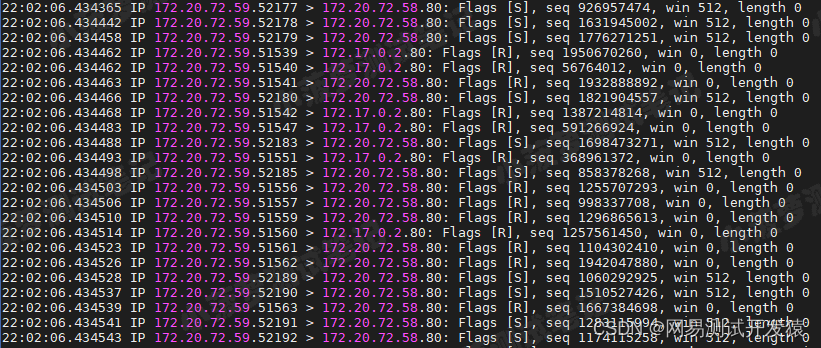
172.20.72.59.52195 > 172.20.72.58.80
表示网络帧从 172.20.72.59 的 52195 端口发 送到 172.20.72.58 的 80 端口
也就是从运行 hping3 机器的 52195 端口发送网络帧, 目的为 Nginx 所在机器的 80 端口
Flags [S]
表示这是一个 SYN 包
性能分析结果
结合 sar 命令发现的 PPS 接近 4w 的现象,可以认为这就是从 172.20.72.59 这个地址发送过来的 SYN FLOOD 攻击
解决 SYN FLOOD 问题
从交换机或者硬件防火墙中封掉来源 IP,这样 SYN FLOOD 网络帧就不会发送到服务器中
分析的整体思路
系统出现卡顿,执行命令,响应也会变慢;
通过 top 查看系统资源情况;
发现 CPU 使用率(us 和 sy)均不高,平均负载适中,没有超 CPU 核数的运行状态的进程,也没有僵尸进程;
但是发现处理软中断的 CPU 占比(si)较高,在进程列表也可以看到软中断进程 CPU 使用率偏高,猜测是软中断导致系统变卡顿的主要原因;
通过 /proc/sorfirqs 查看软中断类型和变化频率,发现直接 cat 的话会打印 128 个核的信息,但只想要两个核的信息;
所以结合 awk 进行过滤,再通过 watch 命令可以动态输出查看结果;
发现有多个软中断类型在变化,重点是 NET_RX 变化频率超高,而且幅度也很大,它是网络数据包接收软中断,暂且认为它是问题根源;
既然跟网络有关系,可以先通过 sar 命令查看系统网络接收和发送的整体情况;
然后可以看到接收的 PPS 会比接收的 BPS 大很多,做下运算,发现网络帧会非常小,也就是常说的小包问题;
接下来,通过 tcpdump 抓取 80端口的 tcp 协议网络包,会发现大量来自 VM2 发送的 SYN 包,结合 sar 命令,确认是 SYN FLOOD 攻击;
| 下面是我整理的2023年最全的软件测试工程师学习知识架构体系图 |
一、Python编程入门到精通

二、接口自动化项目实战
三、Web自动化项目实战
四、App自动化项目实战
五、一线大厂简历
六、测试开发DevOps体系
七、常用自动化测试工具

八、JMeter性能测试

九、总结(尾部小惊喜)
只要心中有梦,不论困难多大,坚持努力,你定能收获成功的喜悦。每一次努力都是种子,播撒在未来,用汗水浇灌,终将开出辉煌的花朵。相信自己,勇往直前,奋斗就是铸就辉煌的力量。
每一次努力都是一次积累,每一份付出都是一种成长,坚持奋斗,不断追求,才能将梦想变为现实。相信自己,勇往直前,只要你肯付出,成功将与你不期而遇!
只有坚持不懈的努力,才能创造辉煌;只有奋发向前的勇气,才能攀登高峰;只有锲而不舍的毅力,才能追求梦想。相信自己,勇往直前,成功将属于你!