使用davidsandberg大侠的facenet 代码时, https://github.com/davidsandberg/facenet , 对于训练结果评价,提示类似如下:
Accuracy: 0.99650+-0.00252
Validation rate: 0.98367+-0.00948 @ FAR=0.00100
可以看到有两个评价方法,accracy 和 validation rate。 我对 accracy 和 val rate的计算方式是明白的,但中间的逻辑(为什么要这样算) 有疑问,很长时间都没弄明白..
首先 计算方式如下:
accuracy =(判断正确的 同一个人+ 判断正确的 不同的人) / 所有数据
validation rate = 判断正确的同一个人的数量 / 所有的同一个人 的数量 (这时有个数字 代码写死为0.001,后面细说)
但为什么要有两个指标评价? accuracy不就够了么? 而且貌似val rate比accuracy 更重要,更能反映训练结果的好坏。
开始时,我的训练的结果是acc 90%, val rate 10%, 后来提升到了 acc 98%, val rate 60%
我的疑问/思路,举个例子来说 当acc 90%, val rate 10%时:
设所有数据是100份, 现在我的accuraccy为90%,则 (判断正确 同一个人+ 判断正确 不同的人 )总和为90人,假设同一人的情况 实际数量为50:10%val则 5个判断对,则判断正确不同的人需要90-5=85个, 50+85>100, 不可能
假设同一人的情况 实际数量为80:10%val则 8个判断对,则判断正确不同的人需要90-8=72个, 80+72>100, 不可能
假设同一人的情况 实际数量为10:10%val则 1个判断对,则判断正确不同的人需要90-1=89个, 10+89约等于100,有可能
而最后一种就是不平衡数据集, 而我的测试集是比较平衡的,不会100组数据中只有10个人左右是相同的 。 问题到底在哪呢?
先看/理解好 知乎这条问题:
https://www.zhihu.com/question/30750849

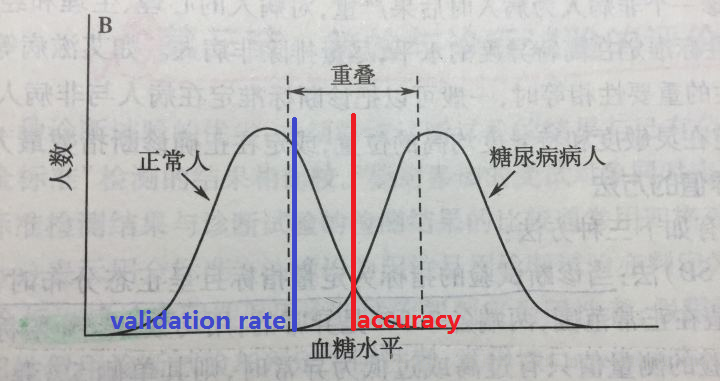
现在看垂直的这条分界线 也就是我们最后要设定的判断阈值,把交叉的部分分成了假正 假负 两块区域。
现在把 误报率 也就是假正 ,变为很小的0.001,就是要把蓝色的线 移到靠近左边的虚线。(把假正降到很小很小的0.001)
而这时,validtateion rate不高,就说明我们训练的结果 还不够分得开,交叉的地方太大了:假正假负都太多, 我们需要 假正假负都尽量小
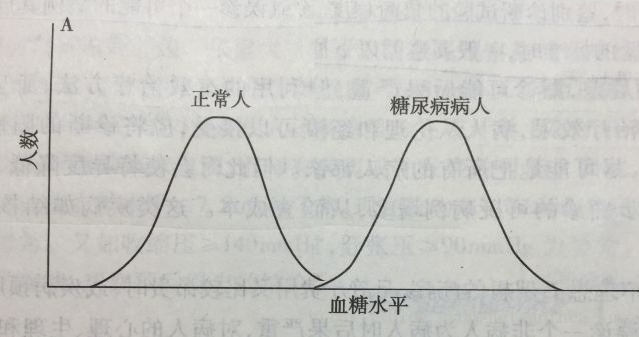
如果我们的是模型训练得好(类似下图,交叉的地方很小),误报率 即使设为很低的0.001, val rate也可以高。下图是我们的训练目标, 上图是我们还没训练得足够好的情况。
扫描二维码关注公众号,回复:
1548160 查看本文章

所以,与不平衡数据集没关系,是我们的网络训练得不够。
那为什么模型训练得不好,accuracy仍可达90%或更高以上呢? 我想像中的,只有达到上图的效果了,accuracy才会达到99%, 实际下图这种情况,也可以达到accuracy99%, validation rate 60%。
另外红线和蓝线,分别就是accuracy和validation rate 的门限值设置方法。也就是为什么有两个评价标准,且val rate比accuracy 更重要,更能反映训练结果的好坏。