1、Apriori算法
一、Apriori 算法概述
Apriori 算法是一种最有影响力的挖掘布尔关联规则的频繁项集的 算法,它是由Rakesh Agrawal 和RamakrishnanSkrikant 提出的。它使用一种称作逐层搜索的迭代方法,k- 项集用于探索(k+1)- 项集。首先,找出频繁 1- 项集的集合。该集合记作L1。L1 用于找频繁2- 项集的集合 L2,而L2 用于找L2,如此下去,直到不能找到 k- 项集。每找一个 Lk 需要一次数据库扫描。为提高频繁项集逐层产生的效率,一种称作Apriori 性质的重 要性质 用于压缩搜索空间。其运行定理在于一是频繁项集的所有非空子集都必须也是频繁的,二是非频繁项集的所有父集都是非频繁的。
- 关联分析
关联分析是一种在大规模数据集中寻找有趣关系的任务。这些关系可以有两种形式:(1)频繁项集,(2)关联规则。
(1)频繁项集
频繁项集:是经常出现在一块的物品的集合。
量化方法:支持度(support)。支持度是数据集中包含该项集的记录所占的比例。例如数据集[[1, 3, 4], [2, 3, 5], [1, 2, 3], [2, 5]]中,项集{2}的支持度为3/4,项集{2,3}的支持度为1/2。
(2)关联规则
关联规则:暗示两种物品之间可能存在很强的关系。
量化计算:可信度或置信度(confidence)。可信度是针对一条关联规则(如{2}-->{3})来定义的。{2}-->{3}这条规则的可信度为“支持度{2,3}/支持度{2}”,即2/3,意味着包含{2}的所有记录中2/3符合规则包含{2,3}。
- Apriori原理
无论频繁项集还是关联规则都需要计算支持度。如果数据量小,计算一个项集的支持度可以针对每个项集扫描所有数据,然后统计该项集出现的总数除以总的交易记录数,就可以得到支持度。但是对于N个物品的数据集共有2N-1中项集组合,即使4个物品也需要遍历数据集15次,100种物品有中可能的项集组合,对现代计算机而言,需要很长的时间才能完成运算,何况事实上,商店都会有上百上千种商品。Apriori算法可以降低计算时间,减少可能感兴趣的项集。
如果某个项集是频繁的,那么它的所有子集也是频繁的。如若{2,3}是频繁的,那么{0}、{1}也一定是频繁的。反过来同样,如果一个项集是非频繁集,那么它的所有超集也是非频繁的。如若{2,3}是非频繁的,那么{0,2,3}、{1,2,3}、{0,1,2,3}也是非频繁项。所以如果计算出{2,3}的支持度是非频繁的,那么{0,2,3}、{1,2,3}、{0,1,2,3}的支持度就不用计算了。
Apriori原理可以避免项集数目的指数增长,从而在合理时间内计算出频繁项集。
- Apriori算法发现频繁项集
Apriori算法流程:
1)首先,基于数据集生成个数为1的项集的列表C1;
2)根据频繁项集函数,计算C1中各元素的支持度,去掉不满足最小支持度的元素,生成满足最小支持度的频繁项集列表L1;
3)根据创建候选项集函数,基于L1生成k=2的候选项集列表C2;
4)根据频繁项集函数,基于C2生成满足最小支持度的k=2的频繁项集列表L2;
5)增加k的值,重复3)、4)生成Lk,直到Lk为空时,返回L列表,L包含L1、L2、L3... 
以下是创建候选项集函数及解释。

一般初始项集个数为1,由k=1的项集生成k=2的项集。所以k的初始值也为2。如果要生成个数为k的项集,则比较前k-2项,如果相等合并,正好比较的项各剩下1个不相等的元素,这样合并后个数就为k-2+1+1=k项。(以下是举例推导过程,忽略C2经过滤后生成L2,直接将C2视为L2,相当于支持度为0)。比较前k-2个元素,可以减少遍历列表的次数。比如想利用{0,1}、{0,2}、{1,2}来创建三元素项集,如果将每两个集合合并,就会得到{0,1,2}、{0,1,2}、{0,1,2}。同样的结果结合会重复3次,还需要处理以得到非重复结果。现在只比较第k-2=1个元素,第1个元素相同才合并集合,得到{0,1,2},只有一次操作,这样就不需要遍历列表来寻找非重复值。
算法:Apriori 算法的频繁项集的产生
五、代码:
输入:数据集D;最小支持度阈值min_sup
输出:D 中的频繁项集L
(1) L1 = find_frequent_1-itemset( D );
(2) for( k=2; Lk−1≠Φ; k++)
(3) {
(4) Ck = apriori_gen(Lk−1); // 产生候选项集
(5) for all transactions t ∈D
(6) {
(7) Ct = subset(Ck, t); // 识别 t 包含的所有候选
(8) for all candidates c∈Ct
(9) {
(10) c.count++; // 支持度计数增值
(11) }
(12) }
(13) Lk = { c∈Ck | c.count≥min_sup} // 提取频繁k-项集
(14) }
(15) return L=∪kLk;
procedure apriori_gen(Lk−1
)
(1) for each itemset l1∈Lk−1
(2) for each itemset l2∈Lk−1
(3) if( l1[1]=l2[1] ∧…∧ ( l1[k-2]=l2[k-2] ) ∧ ( l1[k-1]<l2[k-2] ) then
(4) {
(5) c = join( l1, l2 ); // 连接:产生候选
(6) if has_infrequent_subset( c, Lk−1) then
(7) delete c; // 减枝:移除非频繁的候选
(8) else
(9) add c to Ck
(10) }
(11) return Ck;
procedure has_infrequent_subset( c, Lk−1
)
// 使用先验知识判断候选项集是否频繁
(1) for each ( k-1 )-subset s of c
(2) if s ∉Lk−1 then
(3) return TRUE;
(4) return FALSE;
----部分内容参考自Apriori算法原理总结 - 刘建平Pinard - 博客园 (cnblogs.com)
- AdaBoost算法
- 简介
Adaboost算法是一种提升方法,将多个弱分类器,组合成强分类器。
AdaBoost,是英文”Adaptive Boosting“(自适应增强)的缩写,由Yoav Freund和Robert Schapire在1995年提出。
它的自适应在于:前一个弱分类器分错的样本的权值(样本对应的权值)会得到加强,权值更新后的样本再次被用来训练下一个新的弱分类器。在每轮训练中,用总体(样本总体)训练新的弱分类器,产生新的样本权值、该弱分类器的话语权,一直迭代直到达到预定的错误率或达到指定的最大迭代次数。
总体——样本——个体三者间的关系需要搞清除
总体N。样本:{ni}i从1到M。个体:如n1=(1,2),样本n1中有两个个体。
算法原理
(1)初始化训练数据(每个样本)的权值分布:如果有N个样本,则每一个训练的样本点最开始时都被赋予相同的权重:1/N。
(2)训练弱分类器。具体训练过程中,如果某个样本已经被准确地分类,那么在构造下一个训练集中,它的权重就被降低;相反,如果某个样本点没有被准确地分类,那么它的权重就得到提高。同时,得到弱分类器对应的话语权。然后,更新权值后的样本集被用于训练下一个分类器,整个训练过程如此迭代地进行下去。
(3)将各个训练得到的弱分类器组合成强分类器。各个弱分类器的训练过程结束后,分类误差率小的弱分类器的话语权较大,其在最终的分类函数中起着较大的决定作用,而分类误差率大的弱分类器的话语权较小,其在最终的分类函数中起着较小的决定作用。换言之,误差率低的弱分类器在最终分类器中占的比例较大,反之较小。
二、算法流程:
第一步:
初始化训练数据(每个样本)的权值分布。每一个训练样本,初始化时赋予同样的权值w=1/N。N为样本总数。

D1表示,第一次迭代每个样本的权值。w11表示,第1次迭代时的第一个样本的权值。
N为样本总数。
第二步:进行多次迭代,m=1,2….M。m表示迭代次数。
使用具有权值分布Dm(m=1,2,3…N)的训练样本集进行学习,得到弱的分类器。

该式子表示,第m次迭代时的弱分类器,将样本x要么分类成-1,要么分类成1.那么根据什么准则得到弱分类器?
准则:该弱分类器的误差函数最小,也就是分错的样本对应的 权值之和,最小。

计算弱分类器Gm(x)的话语权,话语权am表示Gm(x)在最终分类器中的重要程度。其中em,为上步中的εm(误差函数的值)。

该式是随em减小而增大。即误差率小的分类器,在最终分类器的 重要程度大。
c)更新训练样本集的权值分布。用于下一轮迭代。其中,被误分的样本的权值会增大,被正确分的权值减小。
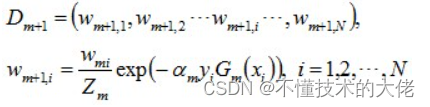
Dm+1是用于下次迭代时样本的权值,Wm+1,i是下一次迭代时,第i个样本的权值。
其中,yi代表第i个样本对应的类别(1或-1),Gm(xi)表示弱分类器对样本xi的分类(1或-1)。若果分对,yi*Gm(xi)的值为1,反之为-1。其中Zm是归一化因子,使得所有样本对应的权值之和为1。

第三步迭代完成后,组合弱分类器。

然后,加个sign函数,该函数用于求数值的正负。数值大于0,为1。小于0,为-1.等于0,为0.得到最终的强分类器G(x)

利用前向分布加法模型(简单说,就是把一起求n个问题,转化为每次求1个问题,再其基础上,求下一个问题,如此迭代n次),adaboost算法可以看成,求式子的最小。tn时样本n对应的正确分类,fm是前m个分类器的结合(这里乘了1/2,因为博主看的文章的am是1/2*log(~~),这个无所谓,无非是多个1/2少个1/2。

然后,假设前m-1个相关的参数已经确定。通过化简E这个式子,我们可以得到:

其中,是一个常量。

其中,Tm是分类正确的样本的权值,Mm是分类错误的样本的权值。式子不算难,自己多看几遍就能理解了。
到现在,可以看出,最小化E,其实就是最小化。

这个式子是什么?看看前面,这个就是找弱分类器时的准则!
然后得到了弱分类器ym后,我们可以进推导出am和样本的权值。)其中,ε是

三、实际应用:
(1)用于二分类或多分类
(2)特征选择
(3)分类人物的baseline
四、代码:
#encoding=utf-8
import pandas as pd
import time
from sklearn.cross_validation import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.ensemble import AdaBoostClassifier
if __name__ == '__main__':
print("Start read data...")
time_1 = time.time()
raw_data = pd.read_csv('../data/train_binary.csv', header=0)
data = raw_data.values
features = data[::, 1::]
labels = data[::, 0]
#随机选取33%数据作为测试集,剩余为训练集
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0)
time_2 = time.time()
print('read data cost %f seconds' % (time_2 - time_1))
print('Start training...')
# n_estimators表示要组合的弱分类器个数;
# algorithm可选{‘SAMME’, ‘SAMME.R’},默认为‘SAMME.R’,表示使用的是real boosting算法,‘SAMME’表示使用的是discrete boosting算法
clf = AdaBoostClassifier(n_estimators=100,algorithm='SAMME.R')
clf.fit(train_features,train_labels)
time_3 = time.time()
print('training cost %f seconds' % (time_3 - time_2))
print('Start predicting...')
test_predict = clf.predict(test_features)
time_4 = time.time()
print('predicting cost %f seconds' % (time_4 - time_3))
score = accuracy_score(test_labels, test_predict)
print("The accruacy score is %f" % score)
-------部分内容参考自AdaBoost 算法原理及推导 - liuwu265 - 博客园 (cnblogs.com)