作者:doremi
mongodb的集群搭建方式主要有三种,主从模式,Replica set模式,sharding模式, 三种模式各有优劣,适用于不同的场合,属Replica set应用最为广泛,主从模式现在用的较少,sharding模式最为完备,但配置维护较为复杂。本文我们来看下Replica Set模式的搭建方法。
Mongodb的Replica Set即副本集方式主要有两个目的,一个是数据冗余做故障恢复使用,当发生硬件故障或者其它原因造成的宕机时,可以使用副本进行恢复。另一个是做读写分离,读的请求分流到副本上,减轻主(Primary)的读压力。
Replica Set是mongod的实例集合,它们有着同样的数据内容。包含三类角色:
(1)主节点(Primary)
接收所有的写请求,然后把修改同步到所有Secondary。一个Replica Set只能有一个Primary节点,当Primary挂掉后,其他Secondary或者Arbiter节点会重新选举出来一个主节点。默认读请求也是发到Primary节点处理的,需要转发到Secondary需要客户端修改一下连接配置。
(2)副本节点(Secondary)
与主节点保持同样的数据集。当主节点挂掉的时候,参与选主。
(3)仲裁者(Arbiter)
不保有数据,不参与选主,只进行选主投票。使用Arbiter可以减轻数据存储的硬件需求,Arbiter跑起来几乎没什么大的硬件资源需求,但重要的一点是,在生产环境下它和其他数据节点不要部署在同一台机器上。
注意,一个自动failover的Replica Set节点数必须为奇数,目的是选主投票的时候要有一个大多数才能进行选主决策。
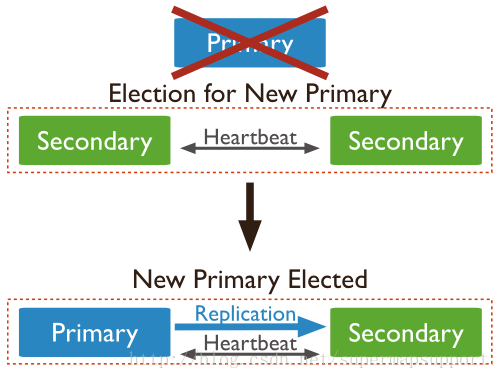
(4)选主过程
其中Secondary宕机,不受影响,若Primary宕机,会进行重新选主:
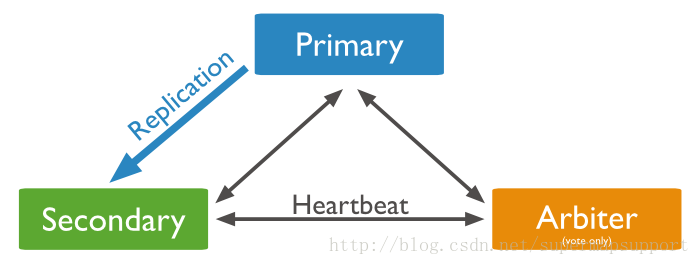
####使用Arbiter搭建Replica Set
偶数个数据节点,加一个Arbiter构成的Replica Set方式:
搭建集群
| 主机 | 用途 |
|---|---|
| 192.168.255.141 | 主节点(master) |
| 192.168.255.142 | 备节点+仲裁点(slave+arbiter) |
#####在/opt下解压mongodb
tar -zxvf mongodb-linux-x86_64-ubuntu1404-3.2.4
创建数据目录
mkdir -p data/mongodb/{master,slave,arbiter}
#####二、创建配置文件
主节点:vi /etc/mongodb_master.conf
#master.conf
dbpath=/opt/data/mongodb/master
logpath=/opt/mongodb/master.log
pidfilepath=/opt/mongodb/master.pid
#keyFile=/opt/mongodb/mongodb.key
directoryperdb=true
logappend=true
replSet=testdb
bind_ip=192.168.255.141
port=27017
#auth=true
oplogSize=100
fork=true
noprealloc=true
#maxConns=4000
备份节点:vi /etc/mongodb_slave.conf
#slave.conf
dbpath=/opt/data/mongodb/slave
logpath=/opt/mongodb/slave.log
pidfilepath=/opt/mongodb/slave.pid
#keyFile=/opt/mongodb/mongodb.key
directoryperdb=true
logappend=true
replSet=testdb
bind_ip=192.168.255.142
port=27017
#auth=true
oplogSize=100
fork=true
noprealloc=true
#maxConns=4000
仲裁点:vi /etc/mongodb_arbiter.conf
#arbiter.conf
dbpath=/opt/data/mongodb/arbiter
logpath=/opt/mongodb/arbiter.log
pidfilepath=/opt/mongodb/arbiter.pid
#keyFile=/opt/mongodb/mongodb.key
directoryperdb=true
logappend=true
replSet=testdb
bind_ip=192.168.255.142
port=27019
#auth=true
oplogSize=100
fork=true
noprealloc=true
#maxConns=4000
备注:
keyFile和auth选项要在集群配置好后,并且添加了验证用户后在启用
参数说明:
dbpath:存放数据目录
logpath:日志数据目录
pidfilepath:pid文件
keyFile:节点之间用于验证文件,内容必须保持一致,权限600,仅Replica Set 模式有效
directoryperdb:数据库是否分目录存放
logappend:日志追加方式存放
replSet:Replica Set的名字
bind_ip:mongodb绑定的ip地址
port:端口
auth:是否开启验证
oplogSize:设置oplog的大小(MB)
fork:守护进程运行,创建进程
moprealloc:是否禁用数据文件预分配(往往影响性能)
maxConns:最大连接数,默认2000
#####三、启动mongodb
/opt/mongodb/bin/mongod -f /etc/mongodb_master.conf
/opt/mongodb/bin/mongod -f /etc/mongodb_slave.conf
/opt/mongodb/bin/mongod -f /etc/mongodb_arbiter.conf
#####四、在主节点进行配置
连接mongoDB
配置集群

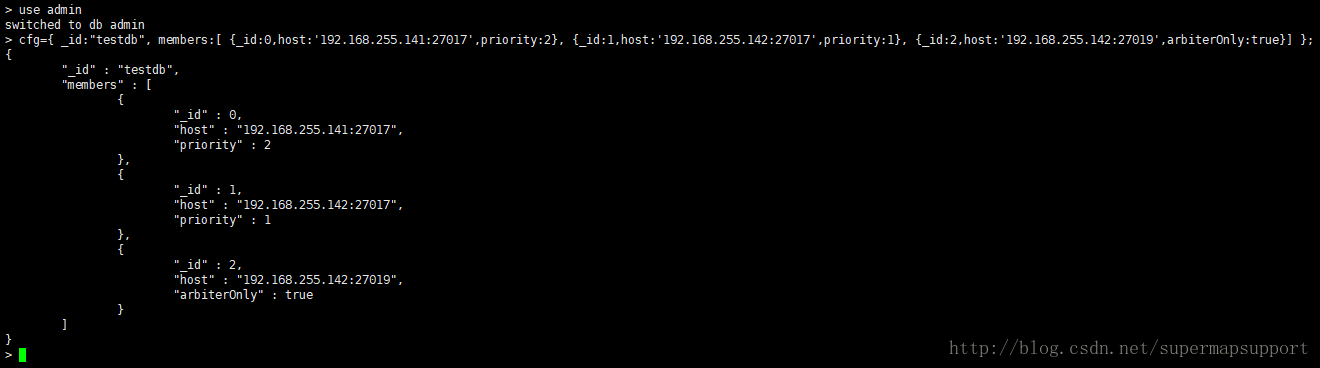
cfg={ _id:"testdb", members:[ {_id:0,host:'192.168.255.141:27017',priority:2}, {_id:1,host:'192.168.255.142:27017',priority:1}, {_id:2,host:'192.168.255.142:27019',arbiterOnly:true}] };
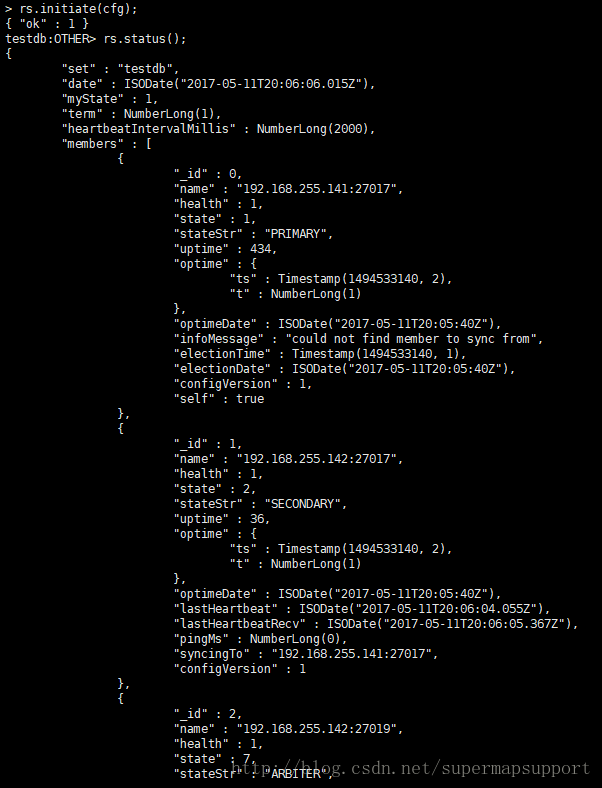
rs.initiate(cfg)
说明:
cfg名字可选,只要跟mongodb参数不冲突,_id为Replica Set名字,members里面的优先级priority值高的为主节点,对于仲裁点一定要加上arbiterOnly:true,否则主备模式不生效
priority表示优先级别,数值越大,表示是主节点
arbiterOnly:true表示仲裁节点
使集群cfg配置生效rs.initiate(cfg)
查看是否生效rs.status()
“stateStr” : "PRIMARY"表示主节点, “stateStr” : "SECONDARY"表示从节点, “stateStr” : “ARBITER”,表示仲裁节点
添加节点命令
添加secondary:rs.add({host: "192.168.255.141:27019", priority: 1 })
添加仲裁点:rs.addArb("192.168.255.142:27019")
移除节点:rs.remove({host: "192.168.255.141:27019"})
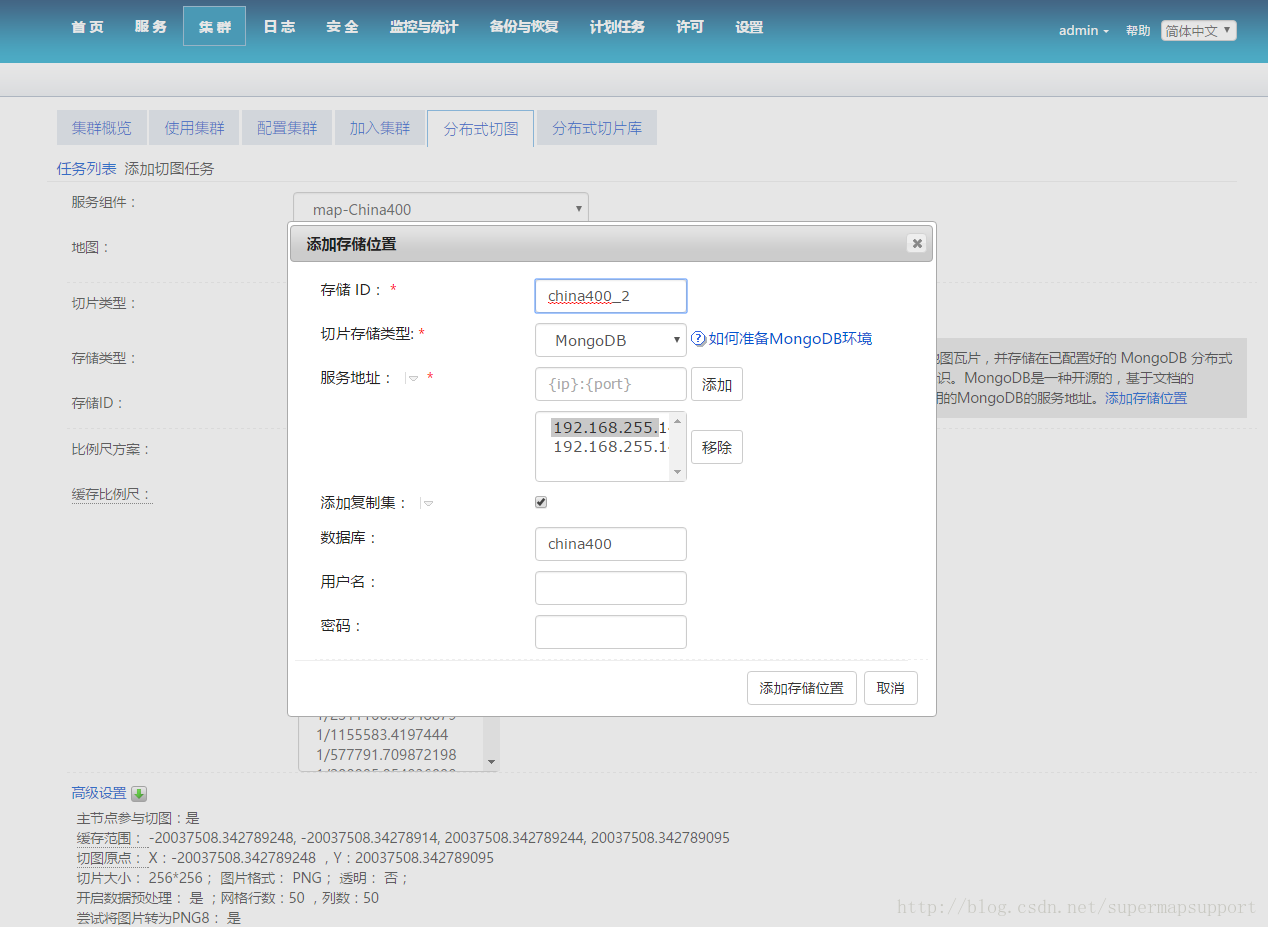
####在iServer中配置使用MongoDB集群
在分布式切图选项中添加MongoDB存储位置
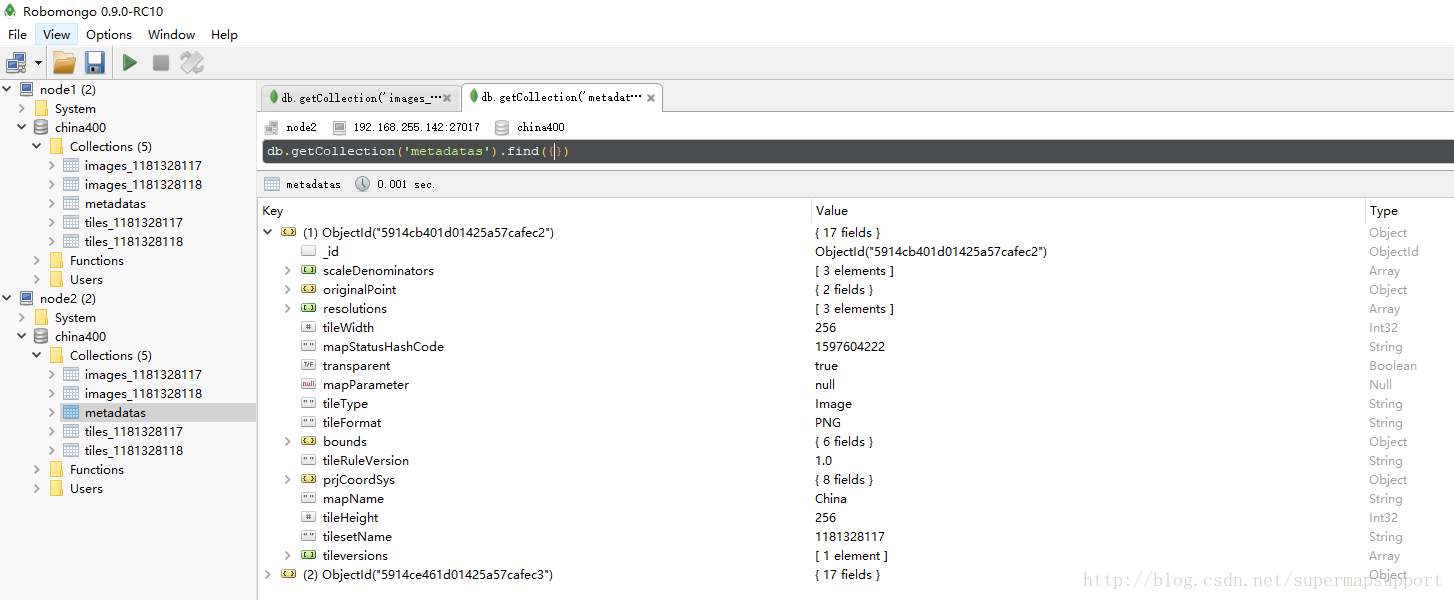
添加之后,开始切图,就可以在mongoDB中看到瓦片已经存储在各个节点中了
发布瓦片服务,浏览地图