一、XML基础知识
1.xml的简介(了解)
** 标记型语言:html是标记型语言
- 也是使用标签来操作
** 可扩展:
- html里面的标签是固定,每个标签都有特定的含义 <h1> <br/> <hr/>
- 标签可以自己定义,可以写中文的标签 <person></person、<猫></猫>
* xml用途
** html是用于显示数据,xml也可以显示数据(不是主要功能)
** xml主要功能,为了存储数据
* xml是w3c组织发布的技术
* xml有两个版本 1.0 1.1
- 使用都是1.0版本,(1.1版本不能向下兼容)
2、xml的应用
* 不同的系统之间传输数据
** qq之间数据的传输
** 画图分析过程
* 用来表示生活中有关系的数据
* 经常用在文件配置
* 比如现在连接数据库 肯定知道数据库的用户名和密码,数据名称
* 如果修改数据库的信息,不需要修改源代码,只要修改配置文件就可以了
3、xml的语法
(1)xml的文档声明(***)
* 创建一个文件 后缀名是 .xml
* 如果写xml,第一步 必须要有 一个文档声明(写了文档声明之后,表示写xml文件的内容)
** <?xml version="1.0" encoding="gbk"?>
*** 文档声明必须写在 第一行第一列
* 属性
- version:xml的版本 1.0(使用) 1.1
- encoding:xml编码 gbk utf-8 iso8859-1(不包含中文)
- standalone:是否需要依赖其他文件 yes/no
* xml的中文乱码问题解决
** 画图分析乱码问题
** 保存时候的编码和设置打开时候的编码一致,不会出现乱码
(2)xml的元素(标签)定义(*****)
** 标签定义
** 标签定义有开始必须要有结束:<person></person>
** 标签没有内容,可以在标签内结束 ; <aa/>
** 标签可以嵌套,必须要合理嵌套
*** 合理嵌套 <aa><bb></bb></aa>
*** 不合理嵌套 <aa><bb></aa></bb>: 这种方式是不正确的
** 一个xml中,只能有一个根标签,其他标签都是这个标签下面的标签
** 在xml中把空格和换行都当成内容来解析,
**** 下面这两段代码含义是不一样的
* <aa>1111111</aa>
* <aa>
11111111111
</aa>
** xml标签可以是中文
** xml中标签的名称规则
(1)xml代码区分大小写
<p> <P>:这两个标签是不一样的
(2)xml的标签不能以数字和下划线(_)开头
<2a> <_aa>: 这样是不正确的
(3)xml的标签不能以xml、XML、Xml等开头
<xmla> <XmlB> <XMLC>: 这些都是不正确的
(4)xml的标签不能包含空格和冒号
<a b> <b:c> : 这些是不正确的
(3)、xml中属性的定义(*****)
* html是标记型文档,可以有属性
* xml也是标记型文档,可以有属性
* <person id1="aaa" id2="bbb"></person>
** 属性定义的要求
(1)一个标签上可以有多个属性
<person id1="aaa" id2="bbb"></person>
(2)属性名称不能相同
<person id1="aaa" id1="bbb"></person>:这个是不正确,不能有两个id1
(3)属性名称和属性值之间使用= ,属性值使用引号包起来 (可以是单引号,也可以是双引号 )
(4)xml属性的名称规范和元素的名称规范一致
(4)、xml中的注释(*****)
* 写法 <!-- xml的注释 -->
** 注意的地方
**** 注释不能嵌套
<!-- <!-- --> -->
<!-- <!-- <sex>nv</sex>--> -->
** 注释也不能放到第一行,第一行第一列必须放文档声明
(5)、xml中的特殊字符(*****)
* 如果想要在xml中现在 a<b ,不能正常显示,因为把<当做标签
* 如果就想要显示,需要对特殊字符 < 进行转义
** < <
> >
(6)、CDATA区(了解)
* 可以解决多个字符都需要转义的操作 if(a<b && b<c && d>f) {}
* 把这些内容放到CDATA区里面,不需要转义了
** 写法
<![CDATA[ 内容 ]]>
- 代码
<![CDATA[ <b>if(a<b && b<c && d>f) {}</b> ]]>
** 把特殊字符,当做文本内容,而不是标签
(7)、PI指令(处理指令)(了解)
* 可以在xml中设置样式
* 写法: <?xml-stylesheet type="text/css" href="css的路径"?>
* 设置样式,只能对英文标签名称起作用,对于中文的标签名称不起作用的。
** xml的语法的总结
所有 XML 元素都须有关闭标签
XML 标签对大小写敏感
XML 必须正确地嵌套顺序
XML 文档必须有根元素(只有一个)
XML 的属性值须加引号
特殊字符必须转义 --- CDATA
XML 中的空格、回车换行会解析时被保留
4、xml的约束
* 为什么需要约束?
** 比如现在定义一个person的xml文件,只想要这个文件里面保存人的信息,比如name age等,但是如果在xml文件中
写了一个标签<猫>,发现可以正常显示,因为符合语法规范。但是猫肯定不是人的信息,xml的标签是自定义的,需要技术来
规定xml中只能出现的元素,这个时候需要约束。
* xml的约束的技术 : dtd约束 和 schema约束 (看懂)
5、dtd的快速入门
* 创建一个文件 后缀名 .dtd
步骤:
(1)看xml中有多少个元素 ,有几个元素,在dtd文件中写几个 <!ELEMENT>
(2)判断元素是简单元素还是复杂元素
- 复杂元素:有子元素的元素
<!ELEMENT 元素名称 (子元素)>
- 简单元素:没有子元素
<!ELEMENT 元素名称 (#PCDATA)>
(3)需要在xml文件中引入dtd文件
<!DOCTYPE 根元素名称 SYSTEM "dtd文件的路径">
** 打开xml文件使用浏览器打开的,浏览器只负责校验xml的语法,不负责校验约束
** 如果想要校验xml的约束,需要使用工具(myeclipse工具)
** 打开myeclipse开发工具
*** 创建一个项目 day05
*** 在day05的src目录下面创建一个xml文件和一个dtd文件
*** 当xml中引入dtd文件之后,比如只能出现name age,多写了一个a,会提示出错
6、dtd的三种引入方式
(1)引入外部的dtd文件
<!DOCTYPE 根元素名称 SYSTEM "dtd路径">
(2)使用内部的dtd文件
- <!DOCTYPE 根元素名称 [
<!ELEMENT person (name,age)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT age (#PCDATA)>
]>
(3)使用外部的dtd文件(网络上的dtd文件)
<!DOCTYPE 根元素 PUBLIC "DTD名称" "DTD文档的URL">
- 后面学到框架 struts2 使用配置文件 使用 外部的dtd文件
- <!DOCTYPE struts PUBLIC "-//Apache Software Foundation//DTD Struts Configuration 2.0//EN"
"http://struts.apache.org/dtds/struts-2.0.dtd">
7.、使用dtd定义元素
* 语法: <!ELEMENT 元素名 约束>
* 简单元素:没有子元素的元素
<!ELEMENT name (#PCDATA)>
*** (#PCDATA): 约束name是字符串类型
*** EMPTY : 元素为空(没有内容)
- <sex></sex>
*** ANY:任意
* 复杂元素:
<!ELEMENT person (name,age,sex,school)>
- 子元素只能出现一次
* <!ELEMENT 元素名称 (子元素)>
* 表示子元素出现的次数
+ : 表示一次或者多次
? :表示零次或者一次
* :表示零次或者多次
* 子元素直接使用逗号进行隔开 ,
** 表示元素出现的顺序
* 子元素直接使用|隔开
** 表示元素只能出现其中的任意一个
8.、使用dtd定义属性
* 语法: <!ATTLIST 元素名称
属性名称 属性类型 属性的约束
>
* 属性类型
- CDATA: 字符串
- <!ATTLIST birthday
ID1 CDATA #REQUIRED
>
- 枚举 : 表示只能在一定的范围内出现值,但是只能每次出现其中的一个
** 红绿灯效果
** (aa|bb|cc)
- <!ATTLIST age
ID2 (AA|BB|CC) #REQUIRED
>
- ID: 值只能是字母或者下划线开头
- <!ATTLIST name
ID3 ID #REQUIRED
>
* 属性的约束
- #REQUIRED:属性必须存在
- #IMPLIED:属性可有可无
- #FIXED: 表示一个固定值 #FIXED "AAA"
- 属性的值必须是设置的这个固定值
- <!ATTLIST sex
ID4 CDATA #FIXED "ABC"
>
- 直接值
* 不写属性,使用直接值
* 写了属性,使用设置那个值
- <!ATTLIST school
ID5 CDATA "WWW"
>
9、实体的定义
* 语法: <!ENTITY 实体名称 "实体的值">
*** <!ENTITY TEST "HAHAHEHE">
*** 使用实体 &实体名称; 比如 &TEST;
** 注意
* 定义实体需要写在内部dtd里面,
如果写在外部的dtd里面,有某些浏览器下,内容得不到
10、xml的解析的简介
* xml是标记型文档
* js使用dom解析标记型文档?
- 根据html的层级结构,在内存中分配一个树形结构,把html的标签,属性和文本都封装成对象
- document对象、element对象、属性对象、文本对象、Node节点对象
* xml的解析方式(技术):dom 和 sax
** 画图分析使用dom和sax解析xml过程
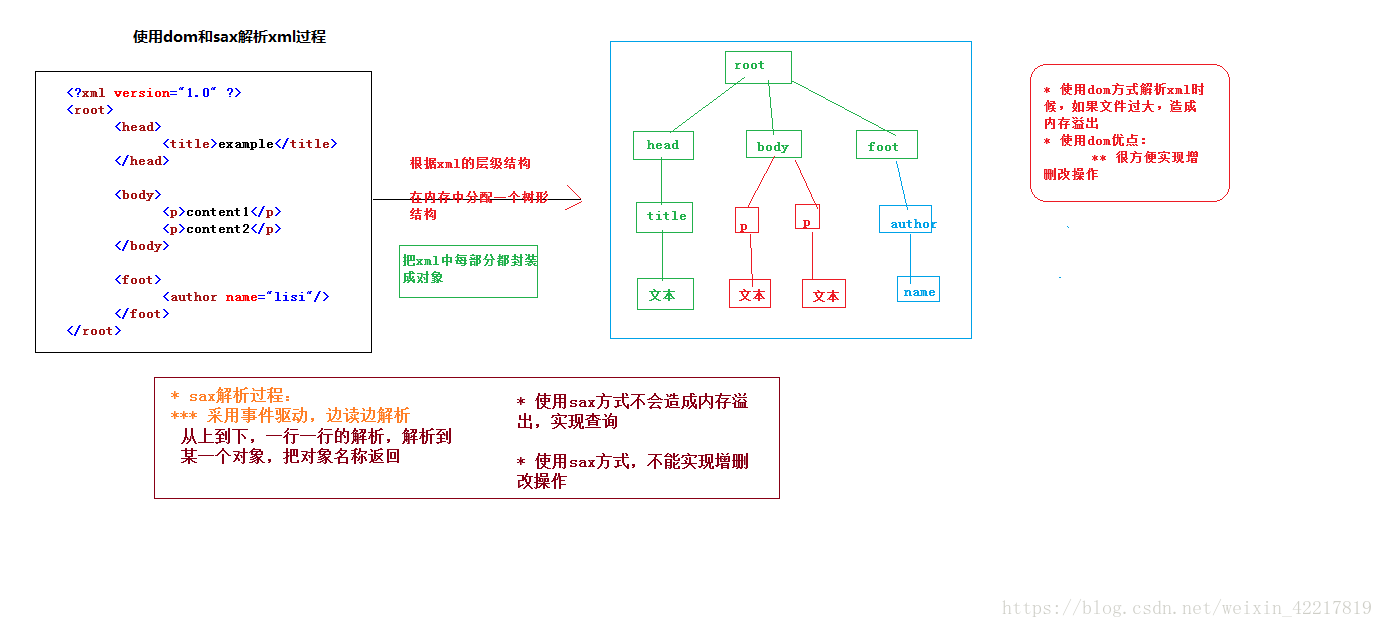
dom解析和sax解析区别:
** dom方式解析
* 根据xml的层级结构在内存中分配一个树形结构,把xml的标签,属性和文本都封装成对象* 缺点:如果文件过大,造成内存溢出
* 优点:很方便实现增删改操作
** sax方式解析
* 采用事件驱动,边读边解析
- 从上到下,一行一行的解析,解析到某一个对象,返回对象名称
* 缺点:不能实现增删改操作
* 优点:如果文件过大,不会造成内存溢出,方便实现查询操作
* 想要解析xml,首先需要解析器
** 不同的公司和组织提供了 针对dom和sax方式的解析器,通过api方式提供
*** sun公司提供了针对dom和sax解析器 jaxp
*** dom4j组织,针对dom和sax解析器 dom4j( 实际开发中)
*** jdom组织,针对dom和sax解析器 jdom
11、schema约束
dtd语法: <!ELEMENT 元素名称 约束>
** schema符合xml的语法,xml语句
** 一个xml中可以有多个schema,多个schema使用名称空间区分(类似于java包名)
** dtd里面有PCDATA类型,但是在schema里面可以支持更多的数据类型
*** 比如 年龄 只能是整数,在schema可以直接定义一个整数类型
*** schema语法更加复杂,schema目前不能替代dtd
12、schema的快速入门
* 创建一个schema文件 后缀名是 .xsd
** 根节点 <schema>
** 在schema文件里面
** 属性 xmlns="http://www.w3.org/2001/XMLSchema"
- 表示当前xml文件是一个约束文件
** targetNamespace="http://www.itcast.cn/20151111"
- 使用schema约束文件,直接通过这个地址引入约束文件
** elementFormDefault="qualified"
步骤
(1)看xml中有多少个元素
<element>
(2)看简单元素和复杂元素
* 如果复杂元素
<complexType>
<sequence>
子元素
</sequence>
</complexType>
(3)简单元素,写在复杂元素的
<element name="person">
<complexType>
<sequence>
<element name="name" type="string"></element>
<element name="age" type="int"></element>
</sequence>
</complexType>
</element>
(4)在被约束文件里面引入约束文件
<person xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.itcast.cn/20151111"
xsi:schemaLocation="http://www.itcast.cn/20151111 1.xsd">
** xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
-- 表示xml是一个被约束文件
** xmlns="http://www.itcast.cn/20151111"
-- 是约束文档里面 targetNamespace
** xsi:schemaLocation="http://www.itcast.cn/20151111 1.xsd">
-- targetNamespace 空格 约束文档的地址路径
* <sequence>:表示元素的出现的顺序
<all>: 元素只能出现一次
<choice>:元素只能出现其中的一个
maxOccurs="unbounded": 表示元素的出现的次数
<any></any>:表示任意元素
* 可以约束属性
* 写在复杂元素里面
***写在 </complexType>之前
--
<attribute name="id1" type="int" use="required"></attribute>
- name: 属性名称
- type:属性类型 int stirng
- use:属性是否必须出现 required
* 复杂的schema约束
<company xmlns = "http://www.example.org/company"
xmlns:dept="http://www.example.org/department"
xmlns:xsi = "http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.example.org/company company.xsd http://www.example.org/department department.xsd"
>
* 引入多个schema文件,可以给每个起一个别名
<employee age="30">
<!-- 部门名称 -->
<dept:name>100</dept:name>
* 想要引入部门的约束文件里面的name,使用部门的别名 detp:元素名称
<!-- 员工名称 -->
<name>王晓晓</name>
</employee>

二、反射
1、什么是反射技术?动态获取指定类以及类中的内容(成员),并运行其内容。应用程序已经运行,无法在其中进行new对象的建立,就无法使用对象。这时可以根据配置文件的类全名去找对应的字节码文件,并加载进内存,并创建该类对象实例。这就需要使用反射技术完成
2、获取class对象的三种方式
获取Class对象的方式一:
通过对象具备的getClass方法(源于Object类的方法)。有点不方便,需要用到该类,并创建该类的对象,再调用getClass方法完成。
Person p = new Person();//创建Peron对象Class clazz = p.getClass();//通过object继承来的方法(getClass)获取Person对应的字节码文件对象
获取Class对象的方式二:
每一个类型都具备一个class静态属性,通过该属性即可获取该类的字节码文件对象。比第一种简单了一些,仅用一个静态属性就搞定了。但是,还是有一点不方便,还必须要使用到该类。Class clazz = Person.class;
获取Class对象方式三:
* 去找找Class类中是否有提供获取的方法呢?
* 找到了,static Class forName(className);
* 相对方便的多,不需要直接使用具体的类,只要知道该类的名字即可。
* 而名字完成可以作为参数进行传递 ,这样就可以提高扩展性。
* 所以为了动态获取一个类,第三种方式最为常用。Class clazz = Class.forName("cn.itcast.bean.Person");//必须类全名
创建Person对象的方式
以前:1,先加载cn.itcast.bean.Person类进内存。
2,将该类封装成Class对象。
3,根据Class对象,用new操作符创建cn.itcast.bean.Person对象。
4,调用构造函数对该对象进行初始化。
cn.itcast.bean.Person p = new cn.itcast.bean.Person();
通过方式三:(此外还可以使用构造,构造可以指定参数---如String.class)
String className = "cn.itcast.bean.Person";
//1,根据名称获取其对应的字节码文件对象
1,通过forName()根据指定的类名称去查找对应的字节码文件,并加载进内存。
2,并将该字节码文件封装成了Class对象。
3,直接通过newIntstance方法,完成该对象的创建。
4,newInstance方法调用就是该类中的空参数构造函数完成对象的初始化。
Class clazz = Class.forName(className);
//2,通过Class的方法完成该指定类的对象创建。Object object = clazz.newInstance();//该方法用的是指定类中默认的空参数构造函数完成的初始化。
清单1,获取字节码文件中的字段。
Class clazz = Class.forName("cn.itcast.bean.Person");
//获取该类中的指定字段。比如age
Field field = clazz.getDeclaredField("age");//clazz.getField("age"); //为了对该字段进行操作,必须要先有指定类的对象。
Object obj = clazz.newInstance();
//对私有访问,必须取消对其的访问控制检查,使用AccessibleObject父类中的setAccessible的方法
field.setAccessible(true);//暴力访问。建议大家尽量不要访问私有
field.set(obj, 789);
//获取该字段的值。
Object o = field.get(obj);
System.out.println(o);
备注:getDeclaredField:获取所有属性,包括私有。
getField:获取公开属性,包括从父类继承过来的,不包括非公开方法。
清单2,获取字节码文件中的方法。
//根据名称获取其对应的字节码文件对象
Class clazz = Class.forName("cn.itcast.bean.Person");
//调用字节码文件对象的方法getMethod获取class对象所表示的类的公共成员方法(指定方法),参数为方法名和当前方法的参数,无需创建对象,它是静态方法
Method method = clazz.getMethod("staticShow", null);
//调用class对象所表示的类的公共成员方法,需要指定对象和方法中的参数列表
method.invoke(null, null);
………………………………………………………………………………………………………
Class clazz = Class.forName("cn.itcast.bean.Person");
//获取指定方法。
Method method = clazz.getMethod("publicShow", null);
//获取指定的类对象。
Object obj = clazz.newInstance();
method.invoke(obj, null);//对哪个对象调用方法,是参数组好处:大大的提高了程序的扩展性。