C语言传统的处理错误的方式
一、异常的概念及用法
我们直接用代码进行讲解:
double Division(int a, int b)
{
// 当b == 0时抛出异常
if (b == 0)
throw "Division by zero condition!";
else
return ((double)a / (double)b);
}
void Func()
{
int len, time;
cin >> len >> time;
cout << Division(len, time) << endl;
}
int main()
{
try
{
Func();
}
catch (const char* errmsg)
{
cout << errmsg << endl;
}
catch (...)
{
cout << "unkown exception" << endl;
}
return 0;
}在Division这个函数中,当b等于0时我们手动抛了一个异常,注意throw后面跟的是一个对象,比如上面代码中我们就是抛出一个string对象,一旦抛异常了就会跳到距离最近的catch中,注意这里的距离是代码运行的距离,就比如cin>>len输入后的下一句运行代码是cout<<一样。在catch的时候编译器也是根据类型捕获的,如果catch(int)那么捕获的就是一个int对象,我们上面的代码中是string对象所以所以捕获的时候用const char*类型,当然...代表捕获任意类型的对象,一般情况下都会把catch(...)放在return之前,这样就可以捕获未知异常了。
下面我们演示一下抛异常结果没有任何一个catch的类型是匹配的情况:
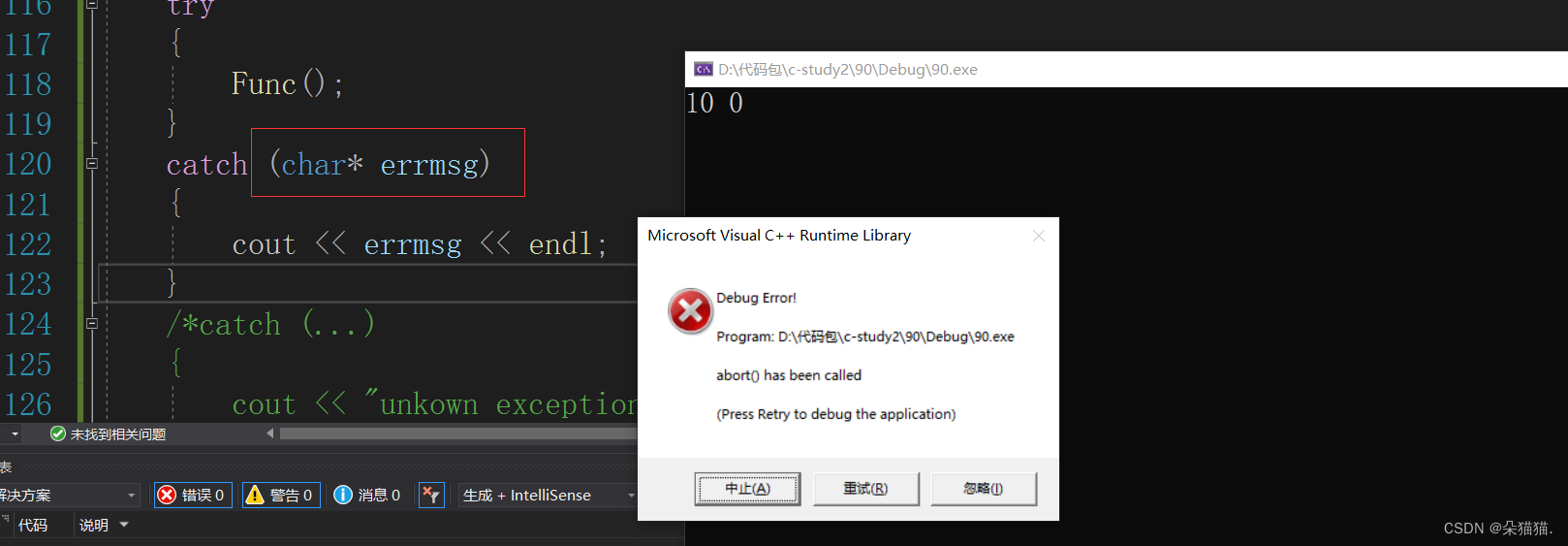
当我们将const char*改为char*后我们发现无法捕获了,这是因为我们抛出的是一个字符串常量,默认就是const类型的,一旦捕获不到异常那么程序就会直接终止掉。
总结:异常的抛出和匹配原则

上面这种情况一旦我们在113行的函数中抛异常了,那么立马会跳到main函数的catch中,这就导致我们无法释放a的资源导致内存泄漏,那么我们该如何避免这种问题呢?我们只需要try catch一下就好:
void Func()
{
int* a = new int;
int len, time;
cin >> len >> time;
try
{
cout << Division(len, time) << endl;
}
catch (const char* errmsg)
{
delete a;
cout << "delete a" << endl;
cout << errmsg << endl;
}
}
当然如果我们不想在func函数中处理异常,而是只想释放掉a的空间然后在main函数中统一处理异常的话我们可以这样写:
void Func()
{
int* a = new int;
int len, time;
cin >> len >> time;
try
{
cout << Division(len, time) << endl;
}
catch (...)
{
delete a;
cout << "delete a" << endl;
throw;
}
}这样写的意思是先用...捕获任意类型的异常,当我们捕获到异常后我们不处理先释放掉a的空间,然后将异常重新抛出去让main函数中的catch去处理,throw后面什么也不跟就是重新抛出异常:
总结:

当然如果我们确定类型也可以这样:

当然我们也可以演示一下抛string类:

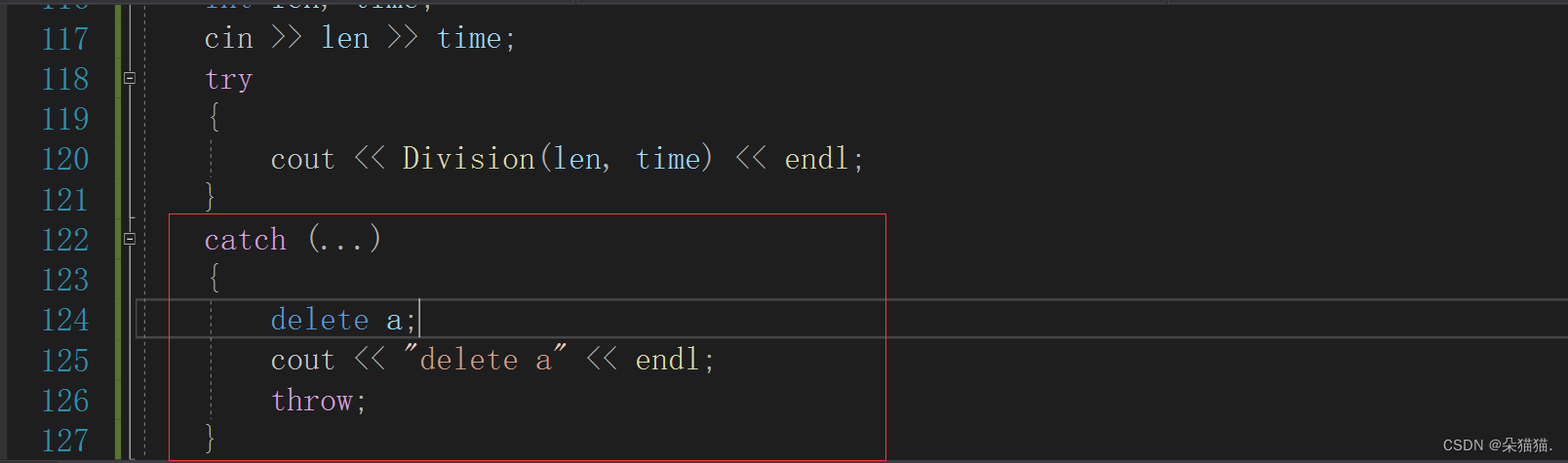
我们想抛什么类型的异常都可以按照这样的方式抛出。
下面我们看看在函数调用链中异常栈展开匹配原则:

了解了以上调用过程后我们看看自定义异常体系
二、自定义异常体系
下面我们给出实例代码:
#include <Windows.h>
class Exception
{
public:
Exception(const string& errmsg, int id)
:_errmsg(errmsg)
, _id(id)
{}
virtual string what() const
{
return _errmsg;
}
protected:
string _errmsg;
int _id;
};
class SqlException : public Exception
{
public:
SqlException(const string& errmsg, int id, const string& sql)
:Exception(errmsg, id)
, _sql(sql)
{}
virtual string what() const
{
string str = "SqlException:";
str += _errmsg;
str += "->";
str += _sql;
return str;
}
private:
const string _sql;
};
class CacheException : public Exception
{
public:
CacheException(const string& errmsg, int id)
:Exception(errmsg, id)
{}
virtual string what() const
{
string str = "CacheException:";
str += _errmsg;
return str;
}
};
class HttpServerException : public Exception
{
public:
HttpServerException(const string& errmsg, int id, const string& type)
:Exception(errmsg, id)
, _type(type)
{}
virtual string what() const
{
string str = "HttpServerException:";
str += _type;
str += ":";
str += _errmsg;
return str;
}
private:
const string _type;
};
void SQLMgr()
{
srand(time(0));
if (rand() % 7 == 0)
{
throw SqlException("权限不足", 100, "select * from name = '张三'");
}
//throw "xxxxxx";
}
void CacheMgr()
{
srand(time(0));
if (rand() % 5 == 0)
{
throw CacheException("权限不足", 100);
}
else if (rand() % 6 == 0)
{
throw CacheException("数据不存在", 101);
}
SQLMgr();
}
void HttpServer()
{
// ...
srand(time(0));
if (rand() % 3 == 0)
{
throw HttpServerException("请求资源不存在", 100, "get");
}
else if (rand() % 4 == 0)
{
throw HttpServerException("权限不足", 101, "post");
}
CacheMgr();
}
int main()
{
while (1)
{
Sleep(1000);
try {
HttpServer();
}
catch (const Exception& e) // 这里捕获父类对象就可以
{
// 多态
cout << e.what() << endl;
}
catch (...)
{
cout << "Unkown Exception" << endl;
}
}
return 0;
}首先有一个父类叫exception,这个类用一个string和int来处理异常,注意这里的what是个虚函数。sql是一个数据库异常处理函数,在公司中通常有多个组,每个组有着不同的项目,比如我们上面写的sql,http,cache等,为了统一所有项目的异常处理,所以有父类execption,其他的异常处理对象都是继承这个父类的,我们在上面的每一个项目中都模拟了抛异常的问题,下面我们运行起来看看结果:


其实我们不难发现,这就好像我们用qq微信突然没有网了或者什么异常情况,这种情况不会强制退出我们的qq软件,而是程序自己重新先尝试连接,多次连接不上就会弹一个框显示网络错误等信息。了解了以上知识后我们再看看异常安全和异常规范。
异常安全:
比如C++98是这样:
// 这里表示这个函数会抛出A/B/C/D中的某种类型的异常
void fun() throw(A,B,C,D);
// 这里表示这个函数只会抛出bad_alloc的异常
void* operator new (std::size_t size) throw (std::bad_alloc);
// 这里表示这个函数不会抛出异常
void* operator delete (std::size_t size, void* ptr) throw();
// C++11 中新增的noexcept,表示不会抛异常
thread() noexcept;
thread (thread&& x) noexcept;所以在C++11中,我们的某个函数只要确定一定不会抛异常那么在最后加上noexcept关键字。
下表是c++中每个异常出现的说明:
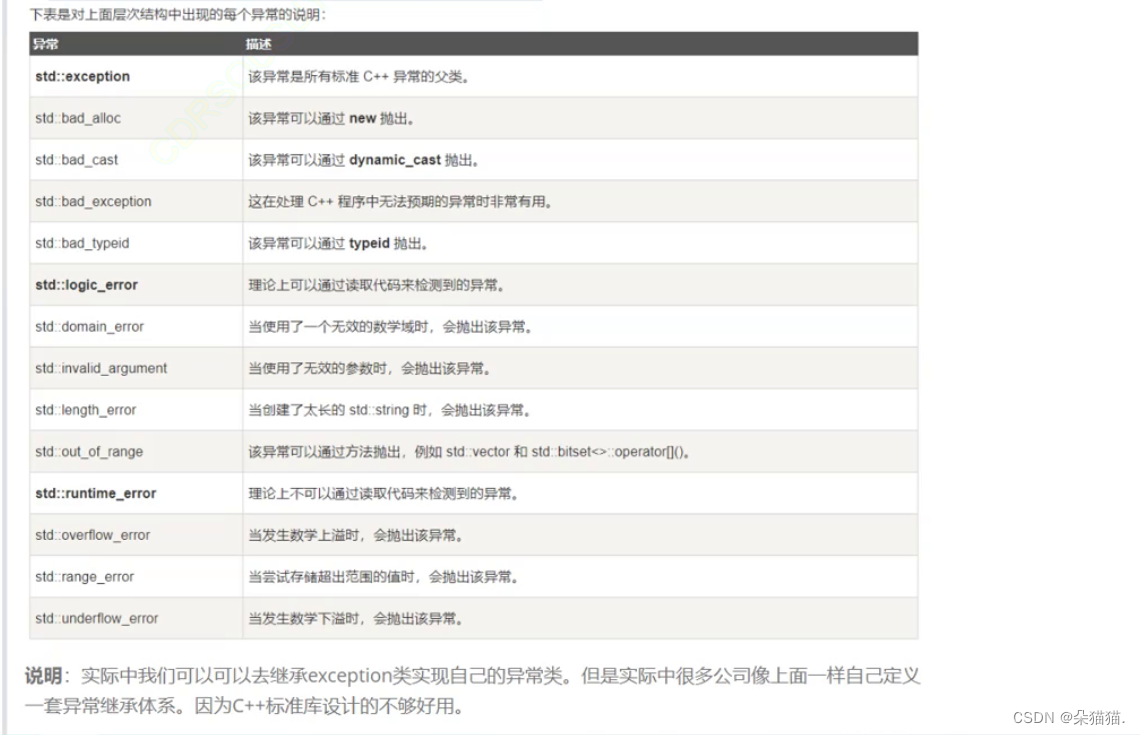
下面我们再看看异常的优缺点:
int ConnnectSql()
{
// 用户名密码错误
if (...)
return 1;
// 权限不足
if (...)
return 2;
}
int ServerStart() {
if (int ret = ConnnectSql() < 0)
return ret;
int fd = socket()
if(fd < 0)
return errno;
}
int main()
{
if(ServerStart()<0)
...
return 0;
}总结
对于异常来讲,我们只需要会用try catch以及了解一些异常的概念,如果可以的话尽量规范自己遇到不会抛异常的类就在后面加上noexcept关键字。