我正在参加「掘金·启航计划」
ES核心概念
ES是面向文档,下面表格是和关系型数据库的对比,一切都是JSON
| 关系数据库(Mysql) | ES |
|---|---|
| 数据库(database) | 索引(indices) 和数据库一样 |
| 表(tables) | types 慢慢会被弃用 7.0已经过时 8.0会彻底废弃 |
| 行(rows) | documents (数据)文档 |
| 字段(columns) | fields |
ES中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)
物理设计:
ES在后台把每个索引划分成多个分片,没分分片可以在集群中的不同服务器间迁移
ES一个人就是一个集群,默认的集群名叫elasticsearch
逻辑设计:
一个索引类型中,包含多个文档
文档(表)
ES是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,ES中,文档有几个重要属性:
1 自我包含 一篇文档同时包含字段和对应的值,也就是同时包含key:value
2 可以是层次的,一个文档中包含自文档,复杂的逻辑实体就是这么来的(其实就是一个JSON对象 Java中可以通过fastjson或者jackson自动进行转换)
3 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能用,在ES中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新字段
类型(字段属性类型 name varchar,name int之类的 )
类型是文档的逻辑容器,就像关系数据库一样,表格是行的容器,类型中对于字段的定义称为映射,在ES中,类型可以不定义设置,ES会去猜测数据类型,有可能出错,当然收到设置数据类型是最安全的
索引(数据库)
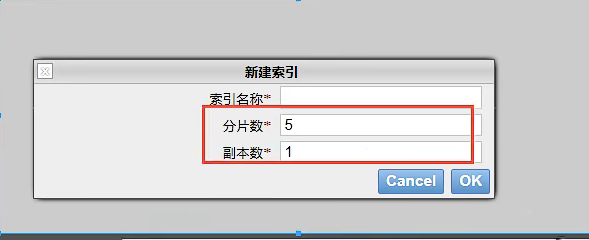
索引就是数据库,索引被分为5个分片,5个分片就是5个倒排索引,一个ES索引是由多个Lucenne库组成的
索引是映射类型的容器,ES中的索引是一个非常大的文档集合,索引存储了映射类型的字段和其他设置,然后他们被存储到了各个分支上,下面研究下分片是如何工作的

倒排索引
ES使用的是一种称为倒排索引的结构,采用Lucenne倒排索引作为底层,这种结构适用于快速的全文索引,一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表
比如现在有两个文档

如果要搜索 to forever,由于文档1的权重(score )更高,所以优先考虑文档1,百度也是这样的机制

在看一个例子,倒排索引会过滤掉全部和查询无关的数据,效率更加高
