开发板和主机
1.功能不同:帮助开发者进行嵌入式系统的开发和调试,具有较强的硬件拓展能力,可以连接各种传感器/执行器等外设。主机为满足一般的计算需求而设计,具备更强的计算和图形处理能力。
2.架构不同:开发板通常采用ARM,主机多为x86或x64
3.接口不同:开发板提供较多的GPIO,SPI,I2C,UART等,方便连接各种外设。主机提供更多的USB,HDMI,音频接口等。
CPU,GPU,NPU,TPU
- CPU即中央处理器(Central Processing Unit)
- GPU即图形处理器(Graphics Processing Unit)
- TPU即谷歌的张量处理器(Tensor Processing Unit),ASIC专用集成电路,由特定使用者要求和特定电子系统的需要而设计、制造。
- NPU即神经网络处理器(Neural network Processing Unit),保证存储和处理一体化,这与冯诺伊曼架构的CPU,GPU有先天区别。
算力的概念
常用FLOPS作为计量单位。FLOPS是Floating-point Operations Per Second的缩写,即每秒所能够进行的浮点运算数目(每秒浮点运算量)。
MGTPE(一百万,十亿,一万亿,一千万亿,一百亿亿)
3090:35.6T,RK3588:6T
FLOPs 是floating point of operations的缩写,是浮点运算次数,可以用来衡量算法/模型复杂度。
边缘计算
边缘计算对于云计算,就好比脊髓对于大脑,边缘计算反应速度快,无需云计算支持,但低智能程度较低,不能够适应复杂信息的处理。
交换机,路由器
交换机用于局域网内网的数据转发。
路由器用于连接局域网和外网。
ONNX,tensorRT模型
模型部署流水线:
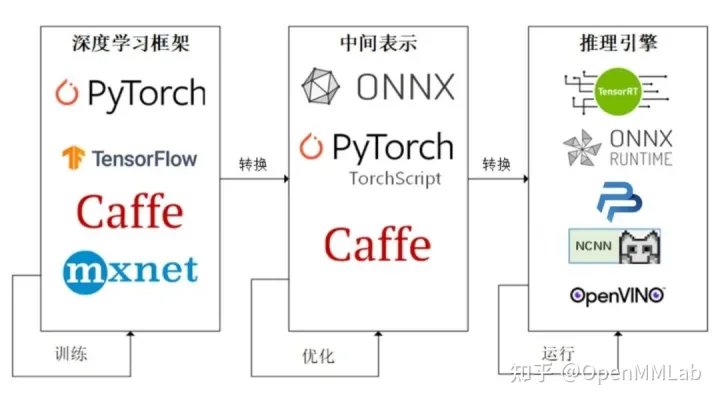
ONNX是一种便于在各个主流深度学习框架中迁移的中间表达格式,一般部署会经过ONNX,再由推理引擎转换为特定的模型格式进行推理。
具体推理后端使用的模型格式。TensorRT 是由 NVIDIA 发布的深度学习框架,用于在其硬件上运行深度学习推理。TensorRT 提供量化感知训练和离线量化功能,用户可以选择 INT8 和 FP16 两种优化模式。TensorRT 经过高度优化,可在 NVIDIA GPU 上运行, 并且可能是目前在 NVIDIA GPU 运行模型最快的推理引擎。
CUDA,cuDNN
CUDA是nvidia开发的用于加速GPU计算任务的并行计算平台。包括一些库和工具,比如CUDA Runtime API,CUDA Driver API,cuDNN等。推理引擎是其中一部分,用于加速深度学习模型的推理过程。cuDNN就是一个加速库。CUDA实现了可以调用GPU,而cuDNN实现了使CUDA更符合深度神经网络的使用,网上装用CUDA和cuDNN的电脑比只装CUDA的电脑的训练速度快1.5倍。
API&SDK
API:Application Programming Interface,应用程序编程接口。
SDK:Software Development Kit,软件开发工具包。辅助开发某一类软件的相关文档、演示举例和一些工具的集合。
从根本上来讲,这两者的没有什么值得比较的地方,本质上是具有很强关联性的两个存在。我们可以将 SDK 解释为封装好功能的一个软件包,而这个软件包几乎是封闭的状态,只有一个接口可以进行访问,那这个接口就是我们所了解的 API。
RK3588
2021.12.16发布,2022量产。
橙派5使用RK3588S内置NPU加速yolov5推理,实时识别数字达到50fps
硬件简介:ARM架构,8nm工艺,四核Cortex-A76和四核Cortex-A55(共8核)CPU,Mali-G610 GPU,6T算力NPU。
推理方式:1.借助RKNN-Toolkit2模拟NPU。2.PC端开发,板端推理。3.版端开发推理。4.PC端开发编译成可执行文件,版端推理。(4与1,2,3的区别在于使用了c++接口API,需要将代码编译成可执行文件。)
一些报错:取不出结果,可能是输入的格式问题,也可能是硬件本身有问题,都排查一下。
Orin
Jetson Download Center | NVIDIA Developer
百度nvidia-jetpack