新一代云原生虚拟数仓 PieCloudDB「云上云」版(Cloud on Cloud)已于 2023 年 3 月14日重磅发布。本篇博客将从导入数据⼊⼿,结合虚拟电商销售数据等实例,详细展示查询计算和查询历史等功能,引导您快速了解和上⼿ PieCloudDB 云上云版本。详细的视频讲解请参照快速上手PieCloudDB视频。
本篇内容大致分为以下五个部分:
- 建立虚拟数仓
- 新建文件夹和SQL文件
- 简单实例:建立数据库和表
- 复杂实例:数据上传 -- 虚拟电商销售数据
- 查询评估:查询历史功能应用
数字计算第一步:虚拟数仓
登录PieCloudDB云上云版本(app.pieclouddb.com),进入主界面,在左侧菜单栏点击「虚拟数仓」。
进入「虚拟数仓」界面,点击右上角「新建虚拟数仓」创建一个新的虚拟数仓。

填写虚拟数仓名称,节点数,节点大小和备注。完成后,点击「确认」启动虚拟数仓。

等待虚拟数仓状态从启动中更新为运行中,即可使用该虚拟数仓执行SQL任务。

新建文件夹和SQL文件
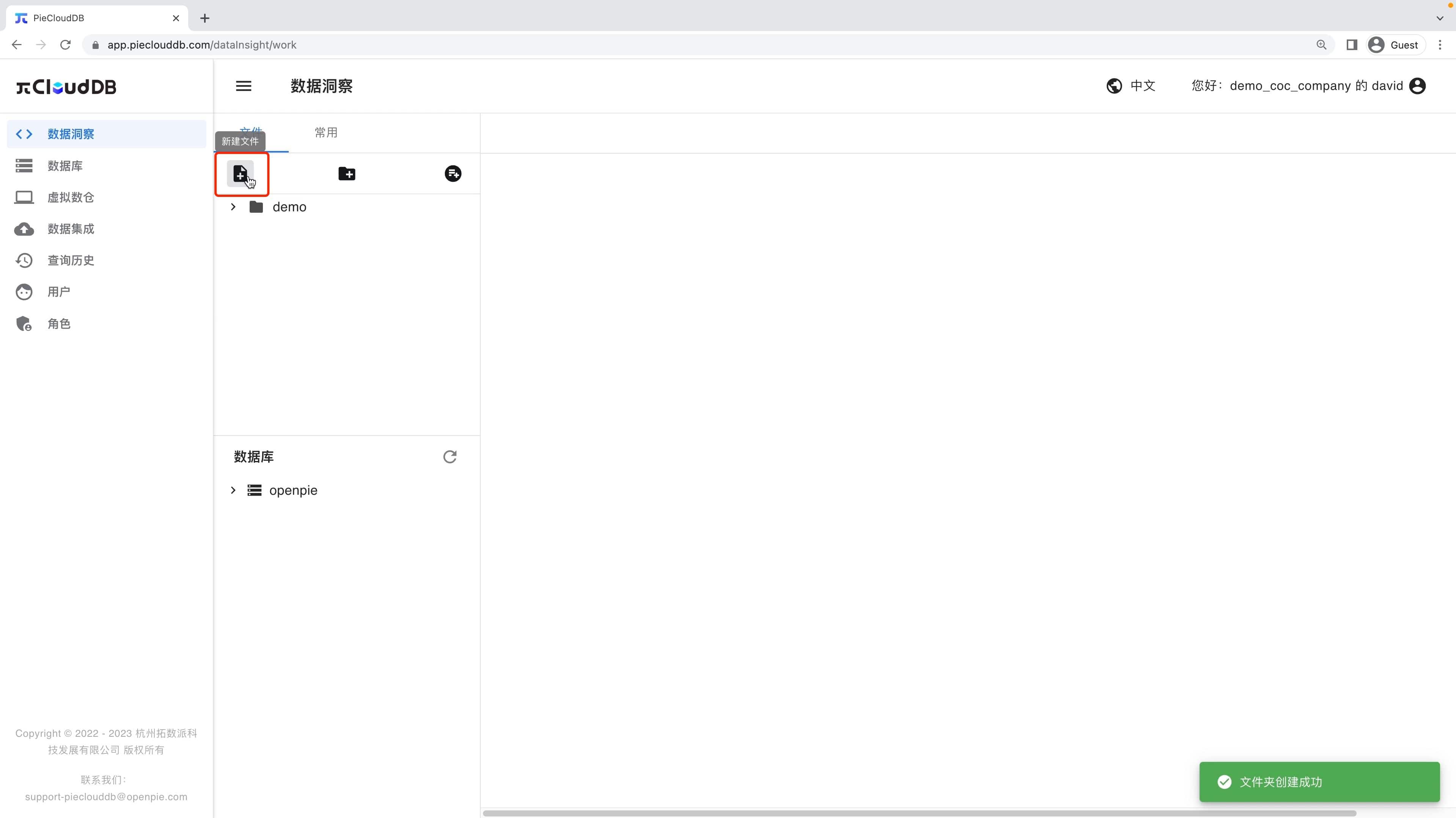
虚拟数仓创建完成且处于运行中后,我们点击「数据洞察」进入「数据洞察」界面。点击图中的文件夹图标创建文件夹。


填入文件夹名称,点击「确认」。

点击如图所示文件图标,建立一个新的SQL文件。
点击文件栏内文件名右侧「···」按钮,可重命名、移动、删除或导出文件。

点击「重命名」,将文件重命名为“demo_query”,点击「确认」完成重命名。

创建SQL文件后,即可在文件内书写查询语句,执行SQL任务。PieCloudDB会自动保存更新的SQL文件。
简单实例:建立数据库和表
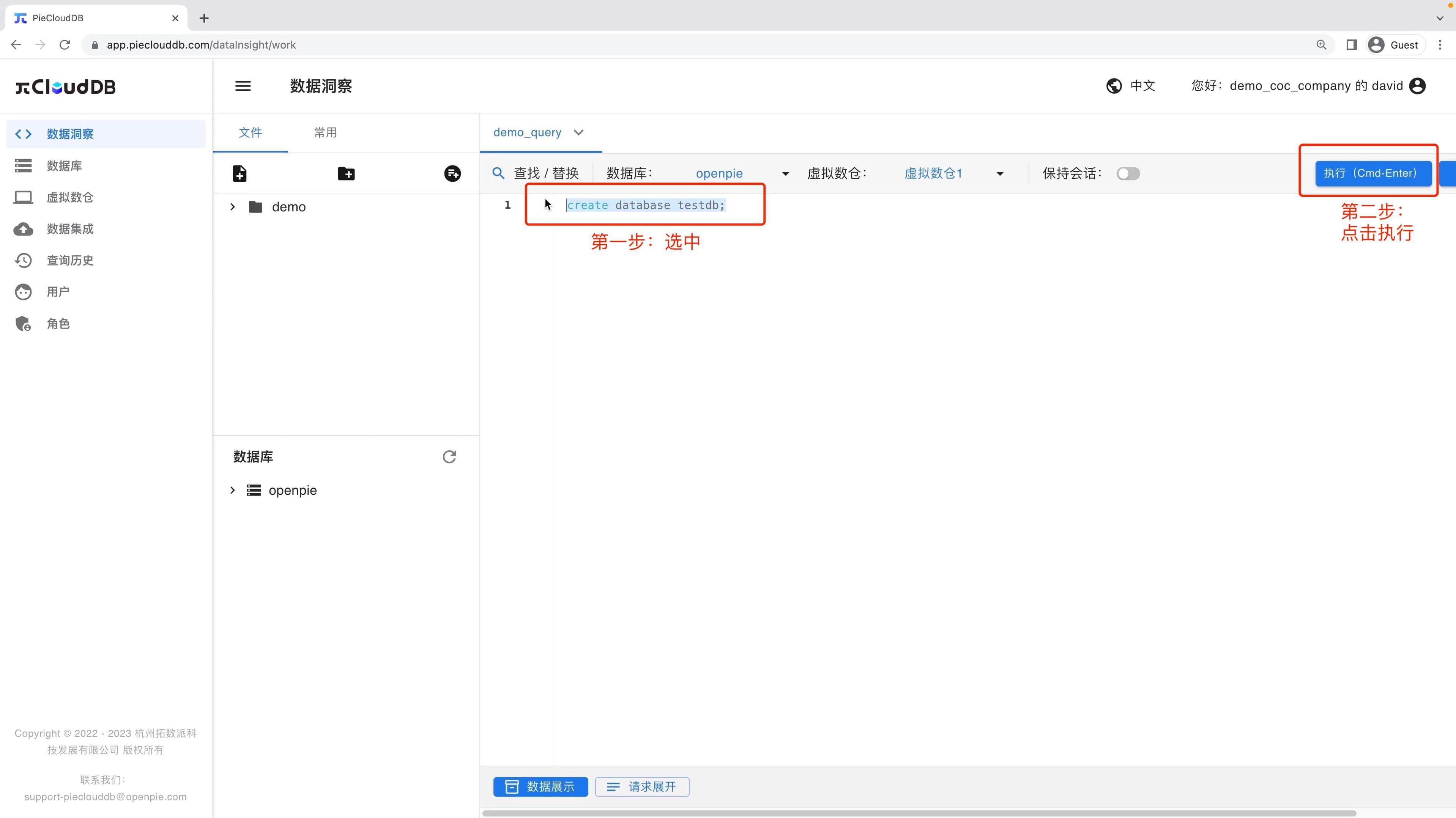
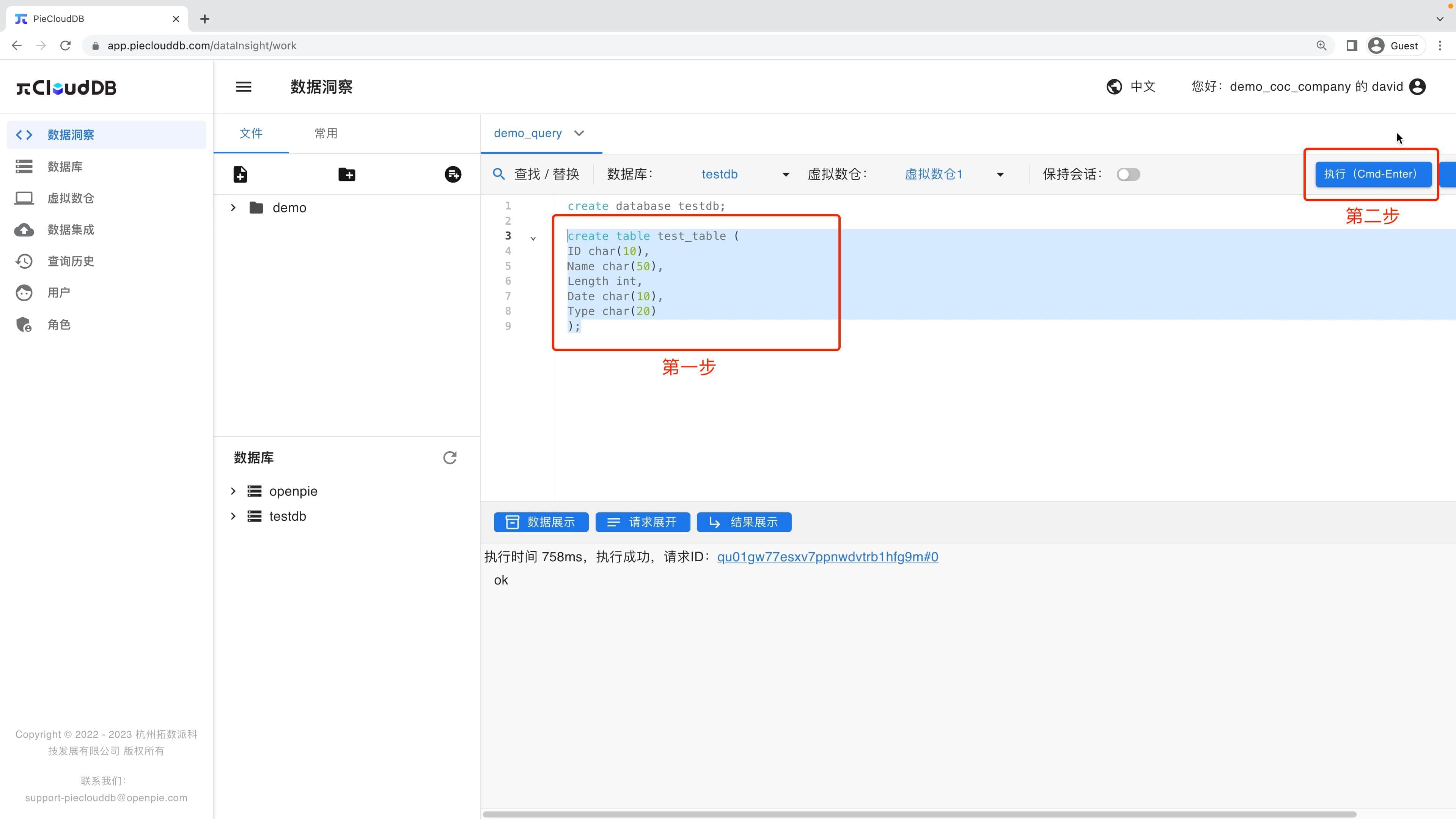
在确保有可用的虚拟仓库后,打开一个SQL文件(这里我们以先前创建的文件demo_query为例),输入以下查询语句。
create database testdb;在运行以上查询前,选择对应的数据库和虚拟数仓执行SQL任务。这里我们选择初始数据库「openpie」,并选择一个可用的虚拟数仓「虚拟数仓1」。

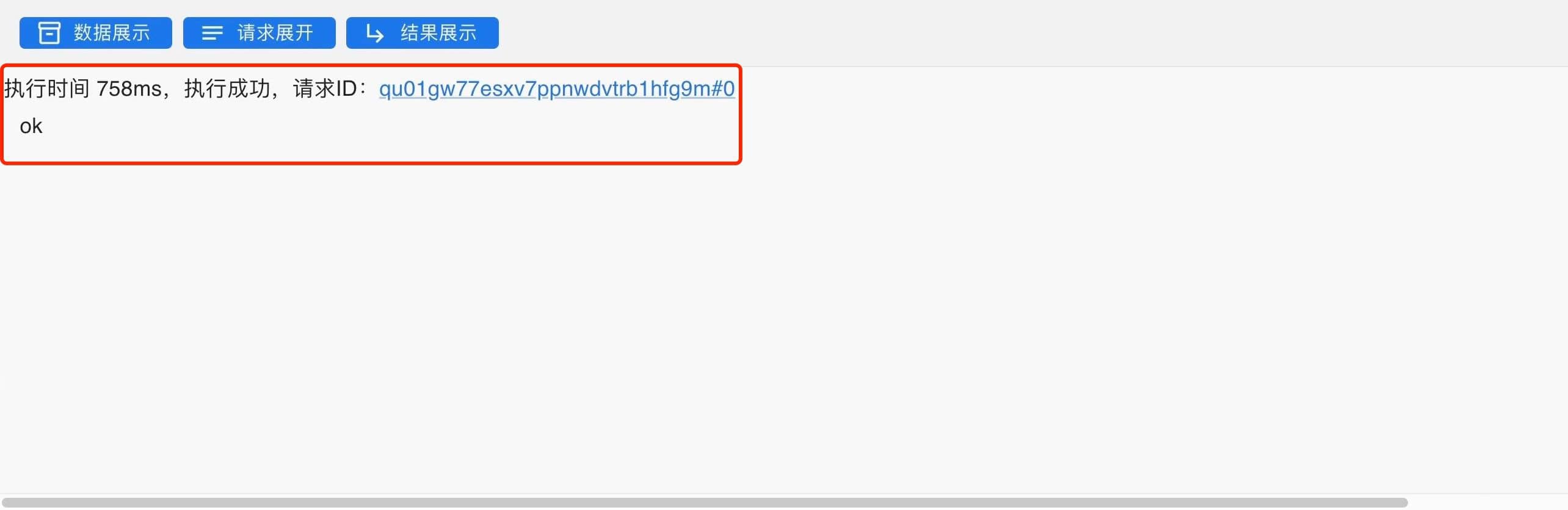
选中该语句并点击执行,执行该查询语句。
结果显示如下,数据库已创建成功。
若想在新建的数据库中创建新表,按如图所示将执行查询的数据库切换为新建的数据库「testdb」。

执行以下语句,创建一个存储电影数据的数据表
create table test_table (
ID char(10),
Name char(50),
Length int,
Date char(10),
Type char(20)
);和先前创建数据库的例子相似,在PieCloudDB中选中并执行该语句。
数据表建立后,运行以下SQL语句,在该表中新增两条记录。
insert into test_table VALUES
('B6717', 'Tampopo', 110, '1985-02-10', 'Comedy'),
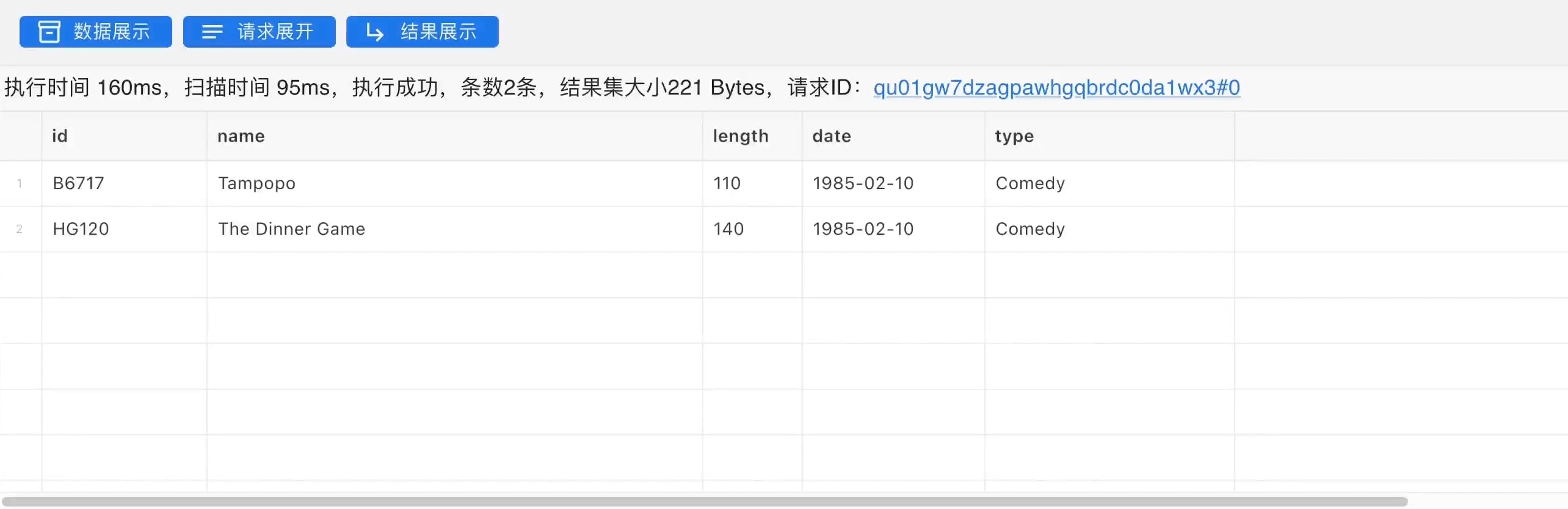
('HG120', 'The Dinner Game', 140, '1985-02-10', 'Comedy');运行以下select语句,在数据表中查看新增的记录。
select * from test_table;在PieCloudDB中结果如图所示。
复杂实例:数据上传 -- 虚拟电商销售数据
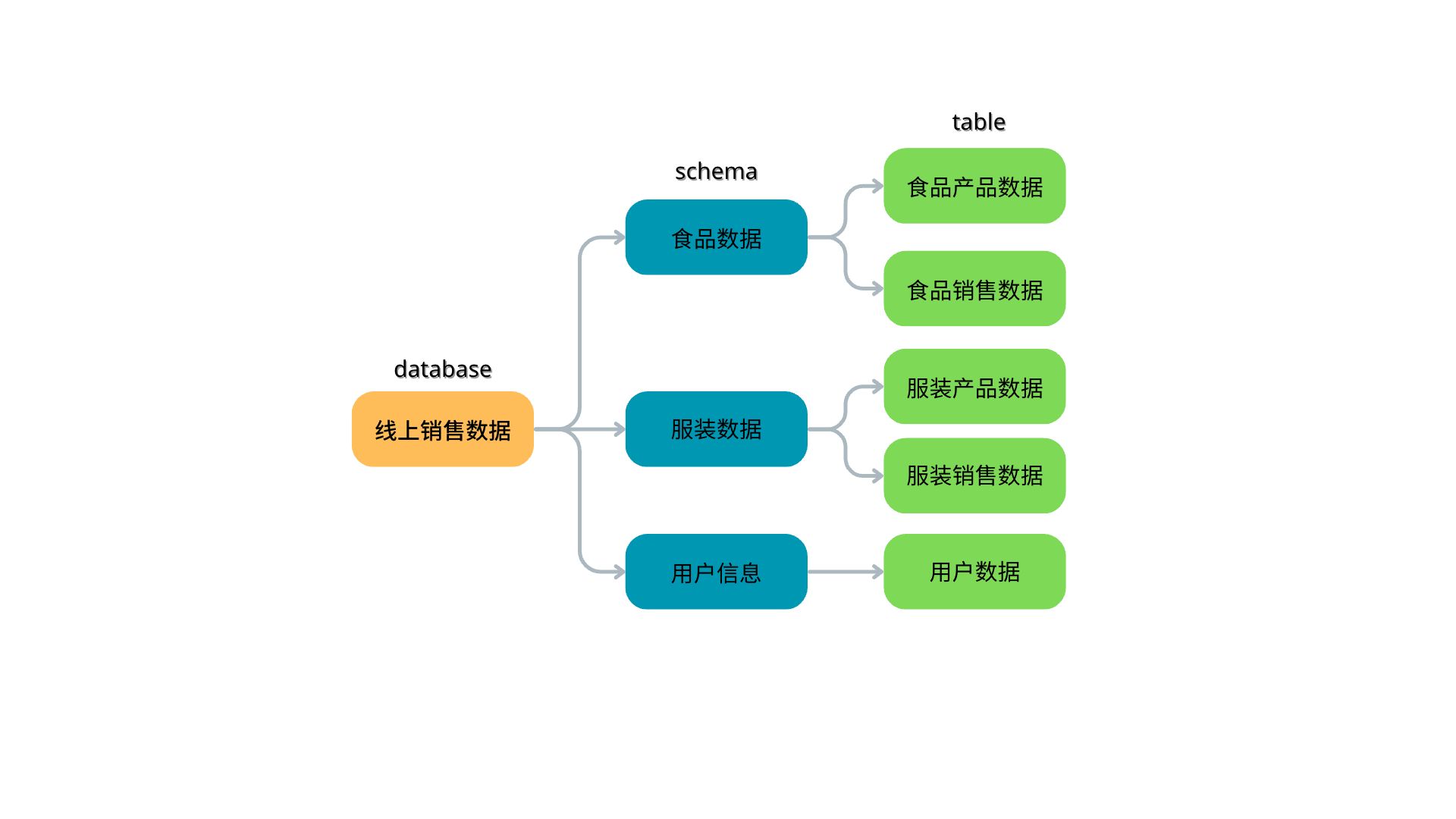
在初步了解PieCloudDB「数据洞察」功能后,我们在这个基础上利用「数据集成」功能,上传更大的数据文件并对数据进行分析。这里我们上传的虚拟电商销售数据结构大致如下。
首先,来到「数据洞察」,运行以下SQL语句,创建数据所需要的数据库。
create database 线上销售数据;与先前简单实例相似,切换执行查询的数据库到「线上销售数据」。运行以下语句,在「线上销售数据」中创建三个schema。
create schema 服装销售数据;
create schema 食品销售数据;
create schema 顾客数据;有了以上schema后,我们即可运行以下语句,在各个schema上创建对应的表。
「食品销售数据」schema——食品相关数据数据:
-- 食品产品数据
create table 食品销售数据.食品产品数据 (
产品编号 VARCHAR(10) NOT NULL,
原料 VARCHAR(5),
类型 VARCHAR(5),
价格 FLOAT,
库存 INT,
产品图片 TEXT
);
-- 2020年至2023年食品交易数据
create table "食品销售数据".交易数据_2020_2023 (
交易编号 VARCHAR(10) NOT NULL,
顾客序号 VARCHAR(10) NOT NULL,
产品编号 VARCHAR(10) NOT NULL,
交易日期 VARCHAR(10),
交易时间 TIME,
件数 INT,
平台 VARCHAR(5)
);「服装销售数据」schema——服装相关数据数据:
-- 服装产品数据
create table 服装销售数据.服装产品数据 (
产品编号 VARCHAR(10) NOT NULL,
颜色 VARCHAR(5),
类型 VARCHAR(5),
价格 FLOAT,
库存 INT,
产品图片 TEXT
);
-- 2020年至2023年服装交易数据
create table "服装销售数据".交易数据_2020_2023 (
交易编号 VARCHAR(10) NOT NULL,
顾客序号 VARCHAR(10) NOT NULL,
产品编号 VARCHAR(10) NOT NULL,
交易日期 VARCHAR(10),
交易时间 TIME,
件数 INT,
平台 VARCHAR(5)
);「顾客数据」schema——用户相关信息:
-- 2020至2023年顾客数据
create table 顾客数据.顾客数据_2020_2023 (
顾客序号 VARCHAR(10) NOT NULL,
顾客姓名 VARCHAR(5),
生日 DATE,
注册日期 DATE,
手机号 VARCHAR(11),
省份 VARCHAR(10),
城市 VARCHAR(10),
地区 VARCHAR(10),
地址 VARCHAR(100)
);创建完所需的表后,逐一上传数据文件至对应的表中。点击左侧菜单栏「数据集成」,选择「导入数据」,进入界面后再选择右上角导入数据,开始导入数据。
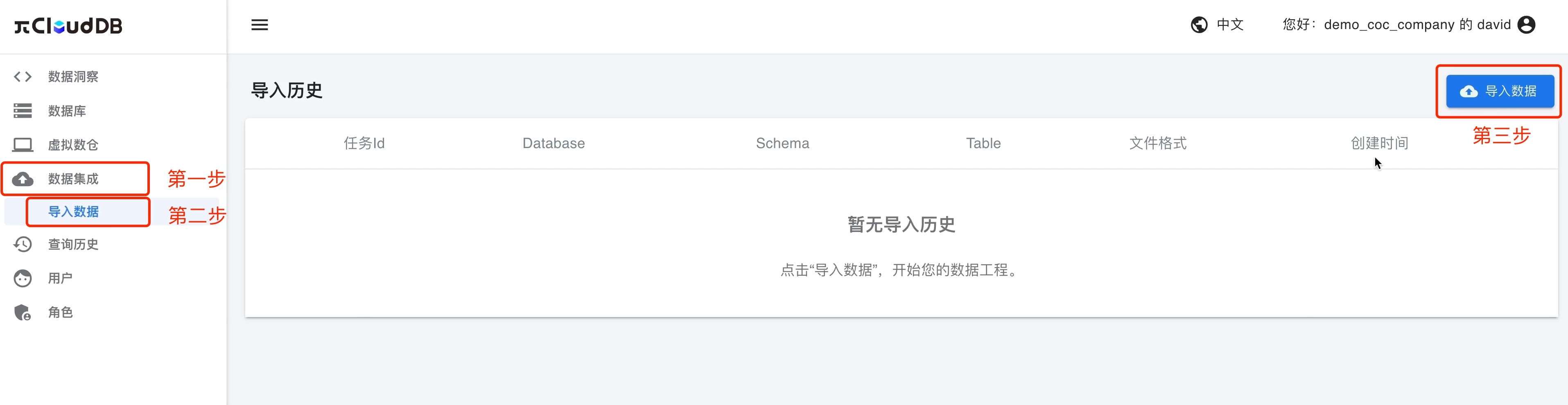
进入「导入数据」界面后,按照如图所示的步骤,上传数据文件至对应数据表。

导入文件后,可点击文件名左侧靠右眼睛式样的图标预览文件,也可点击该位置靠左齿轮式样的图标修改文件的上传选项。右侧的「点击开始」可上传单个文件至数据库。
PieCloudDB也可上传多份数据至同一数据表中。如图所示,服装交易数据由多个数据文件组成。
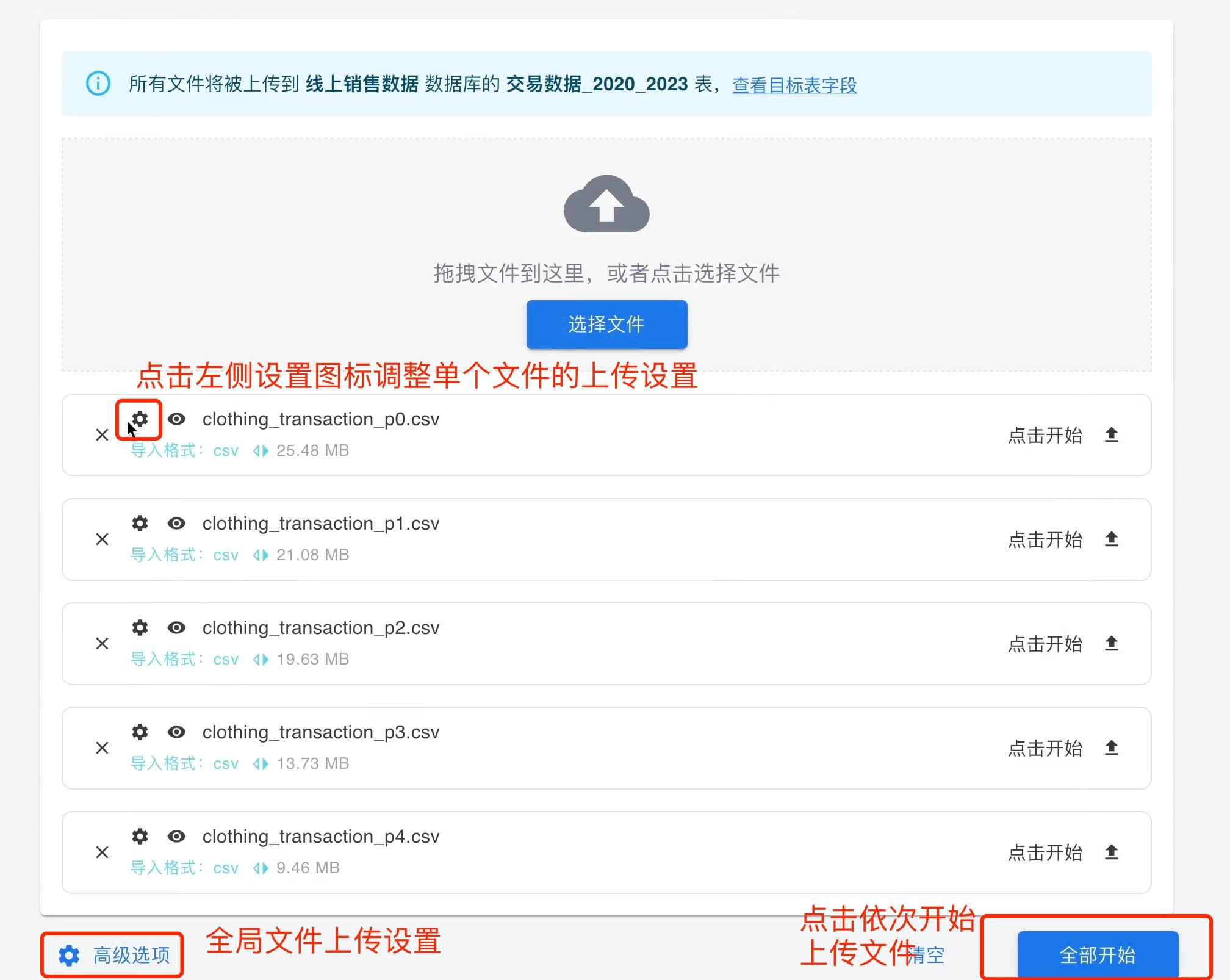
在多个文件的情况下,最下侧的「高级选项」可调整全局的文件上传选项。如个别文件需要单独设置上传选项,如前文提及的一样,点击相应文件名左侧的设置按钮可进行单独设置。由于文件众多,这里点击「全部开始」可依次上传多个文件。
数据加载到各个表中后,我们可以执行一些联合查询来进行数据分析。
以下SQL语句可创立两个视图,一个基于食品交易信息,另一个基于服装交易信息,这样我们可以根据交易的特性,快速查询到对应的商品以及购买商品顾客的信息。
-- 基于服装交易的视图
create view "服装销售数据"."交易数据全部信息_2020_2023" as (
select "交易编号",a."顾客序号", a."产品编号", "交易日期", "交易时间", "件数", "平台", "颜色", "类型", "价格", "库存", "产品图片",
"顾客姓名",c."生日","注册日期","省份","城市","地区","地址"
from "服装销售数据"."交易数据_2020_2023" as a
left join "服装销售数据"."服装产品数据" as b
on a."产品编号" = b."产品编号"
left join "顾客数据"."顾客数据_2020_2023" as c
on a."顾客序号" = c."顾客序号"
order by a."交易日期" desc
);
-- 基于食品交易的视图
create view "食品销售数据"."交易数据全部信息_2020_2023" as (
select "交易编号",a."顾客序号", a."产品编号", "交易日期", "交易时间", "件数", "平台", "原料", "类型", "价格", "库存", "产品图片",
"顾客姓名",c."生日","注册日期","省份","城市","地区","地址"
from "食品销售数据"."交易数据_2020_2023" as a
left join "食品销售数据"."食品产品数据" as b
on a."产品编号" = b."产品编号"
left join "顾客数据"."顾客数据_2020_2023" as c
on a."顾客序号" = c."顾客序号"
order by a."交易日期" desc
);根据这两个视图,我们可以轻松查询到2022年双十二期间以城市为单位的销售额,并根据销售额从高到低进行排序。
select a."省份", a."城市", sum(a."总价") as "销售额"
from (
select "交易编号", "顾客序号", "产品编号", "交易日期", "件数"*"价格" as "总价", "省份", "城市"
from "服装销售数据"."交易数据全部信息_2020_2023"
union
select "交易编号", "顾客序号", "产品编号", "交易日期", "件数"*"价格" as "总价", "省份", "城市"
from "食品销售数据"."交易数据全部信息_2020_2023"
where "交易日期" = '2022-12-12') as a
group by "省份", "城市"
order by "销售额" desc;执行该查询的结果如下:

可以看到,数据中销售的前6名都为直辖市,且前十名当中,长江以北的城市居多。(数据为虚拟数据,城市信息与虚拟客户随机匹配)
我们也可以根据数据表中销售额以及顾客信息,使用window方程查找出服装、食品各板块消费前10%的顾客。
with sale_by_customer as (
(select "顾客序号", sum("件数"*"价格") as "销售额", cast('服装' as varchar(5)) as "销售种类"
from "服装销售数据"."交易数据_2020_2023" as a
left join "服装销售数据"."服装产品数据" as b
on a."产品编号" = b."产品编号"
group by "顾客序号"
order by "销售额" desc, "顾客序号")
UNION
(select "顾客序号", sum("件数"*"价格") as "销售额", cast('食品' as varchar(5)) as "销售种类"
from "食品销售数据"."交易数据_2020_2023" as a
left join "食品销售数据"."食品产品数据" as b
on a."产品编号" = b."产品编号"
group by "顾客序号"
order by "销售额" desc, "顾客序号")),
customer_ranking as (
select *, row_number() over (partition by "销售种类" order by "销售额" desc) as ranking, count(*) over (partition by "销售种类") as cnt -- (select count(*) as cnt from clothes_sale_by_customer) as cnt
from sale_by_customer)
select c."顾客序号","顾客姓名","生日","注册日期","省份","城市","地区","地址", "销售种类" as "vip销售种类"
from customer_ranking as c
left join "顾客数据"."顾客数据_2020_2023" as d
on c."顾客序号" = d."顾客序号"
where cast(ranking as decimal)/cnt <= 0.1
;该查询语句的结果如下,顾客姓名、生日、地址、注册日期均为虚构数据。
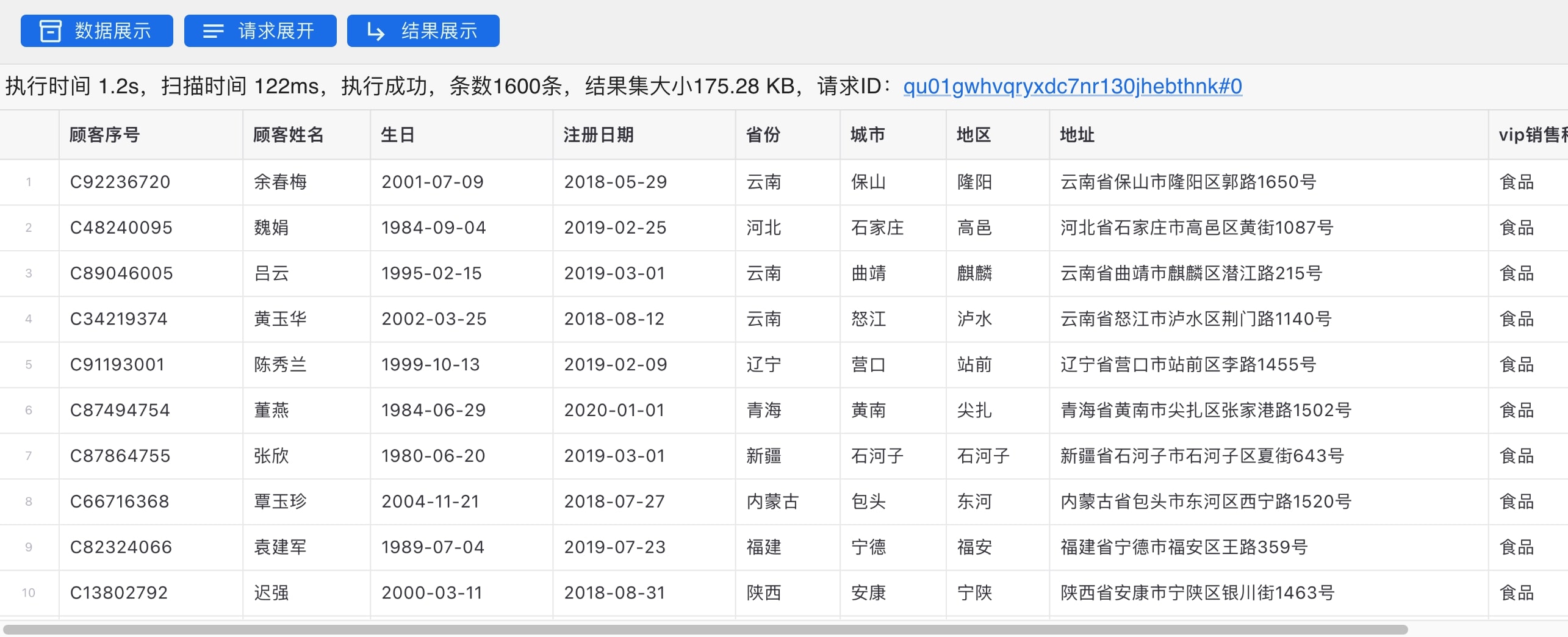
这些用户都是服装、食品各板块的优质客户,为了提升回购率,我们可以考虑给这些用户发放优惠政策,鼓励这些用户回购。
查询评估
点击左侧菜单栏的「查询历史」,即可根据状态以及执行日期查询先前SQL任务的请求历史。
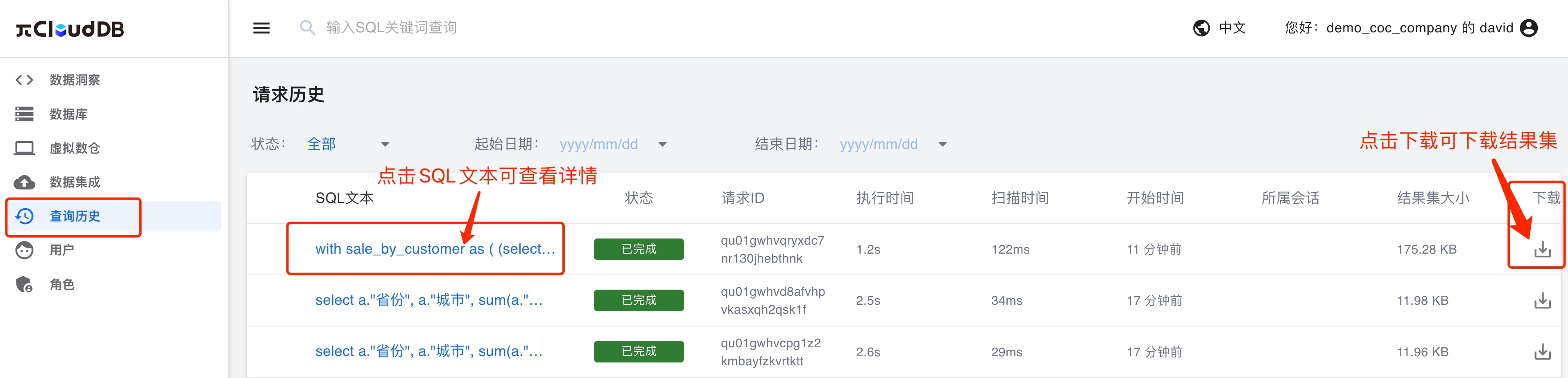
「查询历史」提供SQL任务执行信息、状态、时间等信息,试用版会为用户保留历史请求结果集的下载功能,但可供下载的结果集大小不可超过100MB。
点击SQL文本可提供SQL任务的详细信息。
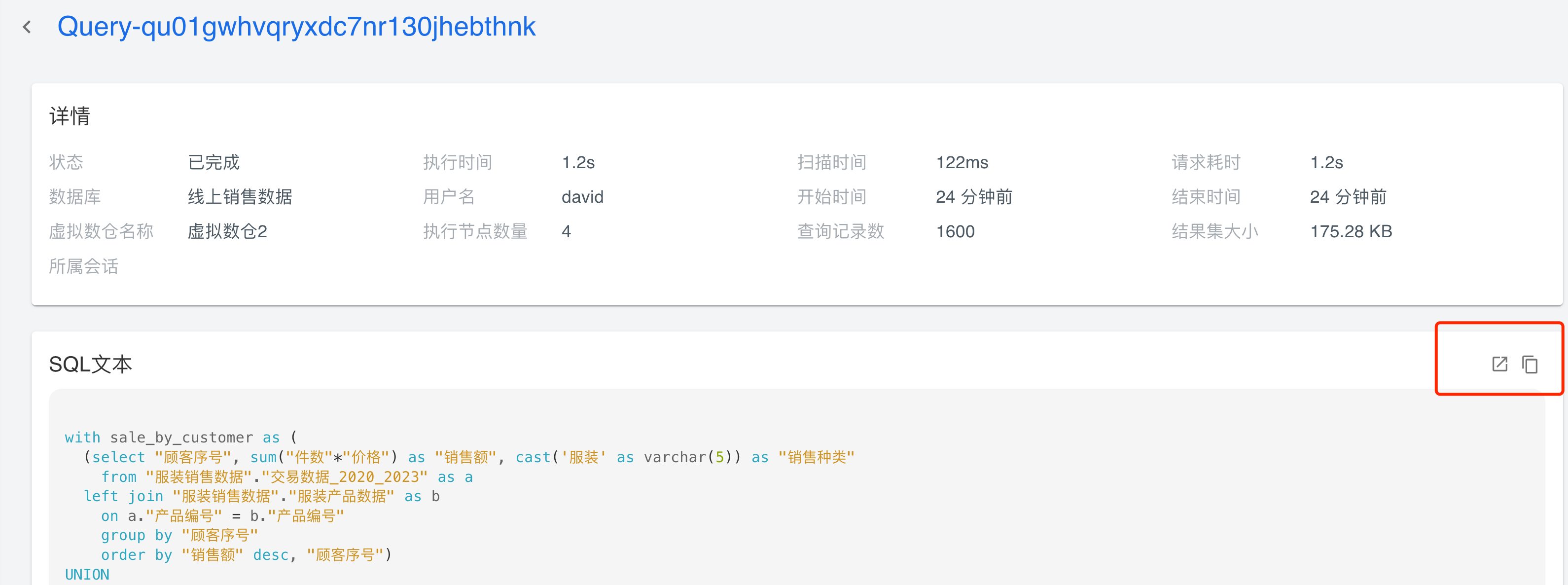
如图所示,SQL文本上侧为任务详情,右上角的两个按钮分别提供在「数据洞察」中打开该文本和复制文本的功能。
结语
至此,我们完成了在PieCloudDB上进行数据实例的演示。欢迎大家登录拓数派官网免费试用PieCloudDB「云上云」版,开启属于自己的的数据探索之旅。