3.1综述
TensorFlow是一个编程系统,使用图来表示计算任务,图中的节点被称之为op(operation的缩写),一个op获得0个或者多个tensor,执行计算,产生0个或多个tensor。每个tensor是一个类型化的多维数组。例如,你可以将一组图像素集表示为一个四维浮点数数组,这四个维度分别是[batch, height, width, channels]。
一个TensorFlow图描述了计算的过程,为了进行计算,图必须在会话里被启动,会话将图的op分发到诸如CPU或GPU之类的设备上,同时提供执行op的方法,这些方法执行后,将产生的tensor返回。在python语言中,返回的tensor是numpy ndarry对象;在C/C++语言中,返回的是tensor是tensorflow::Tensor实例。
3.2计算图
通常,TensorFlow 编程可按两个阶段组织起来: 构建阶段和执行阶段; 前者用于组织计算图,而后者利用 session 中执行计算图中的 op 操作。
例如, 在构建阶段创建一个图来表示和训练神经网络,然后在执行阶段反复执行一组 op 来实现图中的训练。
TensorFlow 支持 C++、 Python 、Go、Java等编程语言。目前, TensorFlow 的 Python 库更加易用, 它提供了大量的辅助函数来简化构建图的工作, 而这些函数在 C 和 C++ 库中尚不被支持。这三种语言的会话库 (session libraries) 是一致的。
构建计算图
刚开始基于 op(source op) 建立图的时候一般不需要任何的输入源 (source op),例如输入常量(Constance),再将它们传递给其它 op 执行运算。
Python 库中的 op 构造函数返回代表已被组织好的 op 作为输出对象,这些对象可以传递给其它 op 构造函数作为输入。
TensorFlow Python库中有一个默认图(default graph),op构造器可以为其增加节点。这个默认图对许多程序来说已经足够用了,可以阅读Graph类
文档,来了解如何管理多个视图。
import tensorflow as tf
# 创建一个常量op, 产生一个1x2矩阵,这个op被作为一个节点
# 加到默认视图中
# 构造器的返回值代表该常量op的返回值
matrix1 = tf.constant([[3., 3.]])
# 创建另一个常量op, 产生一个2x1的矩阵
matrix2 = tf.constant([[2.], [2.]])
# 创建一个矩阵乘法matmul op,把matrix1和matrix2作为输入:
product = tf.matmul(matrix1, matrix2)默认图现在拥有三个节点,两个constant() op,一个matmul() op. 为了真正进行矩阵乘法运算,得到乘法结果, 你必须在一个会话 (session) 中载入动这个图。
在会话中载入图
构建过程完成后就可运行执行过程。为了载入之前所构建的图,必须先创建一个会话对象 (Session object)。会话构建器在未指明参数时会载入默认的图。
完整的会话 API 资料,请参见会话类 Session object
。
# 启动默认图
sess = tf.Session()
# 调用sess的'run()' 方法来执行矩阵乘法op,传入'product'作为该方法的参数
# 上面提到,'product'代表了矩阵乘法op的输出,传入它是向方法表明,我们希望取回
# 矩阵乘法op的输出。
#
#整个执行过程是自动化的,会话负责传递op所需的全部输入。op通常是并发执行的。
#
# 函数调用'run(product)' 触发了图中三个op(两个常量op和一个矩阵乘法op)的执行。
# 返回值'result'是一个numpy 'ndarray'对象。
result = sess.run(product)
print result
# ==>[[12.]]
# 完成任务,关闭会话
sess.close()会话在完成后必须关闭以释放资源。你也可以使用”with”句块开始一个会话,该会话将在”with”句块结束时自动关闭。
with tf.Session() as sess:
result = sess.run([product])
print resultTensorFlow 事实上通过一个“翻译”过程,将定义的图转化为不同的可用计算资源间实现分布计算的操作,如 CPU 或是显卡 GPU。通常不需要用户指定具体使用的 CPU或 GPU, TensorFlow 能自动检测并尽可能的充分利用找到的第一个 GPU 进行运算。
如果你的设备上有不止一个 GPU,你需要明确指定 op 操作到不同的运算设备以调用它们。使用with…Device语句明确指定哪个 CPU 或 GPU 将被调用:
with tf.Session() as sess:
with tf.device("/gpu:1"):
matrix1 = tf.constant([[3., 3.]])
matrix2 = tf.constant([[2.], [2.]])
product = tf.matmul(matrix1, matrix2)使用字符串指定设备,目前支持的设备包括:
“/cpu:0”:计算机的 CPU;
“/gpu:0”:计算机的第一个 GPU,如果可用;
“/gpu:1”:计算机的第二个 GPU,以此类推。
关于使用 GPU 的更多信息,请参阅 GPU 使用。
现在我们来总结一下前面的例子,完整代码如下。
【代码参见附件test1_session.py】
import tensorflow as tf
matrix1 = tf.constant([[3, 3]])
matrix2 = tf.constant([[2],[2]])
product = tf.matmul(matrix1, matrix2) # matrix multiply np.dot(m1, m2)
# method 1
sess = tf.Session()
result = sess.run(product)
print(result)
sess.close()
# method 2
with tf.Session() as sess:
result2 = sess.run(product)
print(result2)3.3交互式使用
文档中的python示例使用一个会话Session来启动图,并调用Session.run()方法执行操作。
为了便于使用诸如IPython之类的python交互环境,可以使用InteractiveSession代替Session类,使用Tensor.eval()和Operation.run()方法代替Session.run()。这样可以避免使用一个变量来持有会话.
【代码参见附件test2_ InteractiveSession.py】
import tensorflow as tf
sess = tf.InteractiveSession()
x = tf.Variable([1.0, 2.0])
a = tf.constant([3.0, 3.0]);
# 使用初始化器initializer op的run()方法初始化x
x.initializer.run()
# 增加一个减法sub op,从x减去a。运行减法op,输出结果
sub = tf.subtract(x,a)
#sub = tf.sub(x,a)#最新的TensorFlow已经弃用tf.sub
print(sub.eval())
#print
#[-2. -1.]3.4张量(Tensors)
TensorFlow 程序使用 tensor数据结构来代表所有的数据,计算图中,操作间传递的数据都是 tensor. 你可以把 TensorFlow 的张量看作是一个 n 维的数组或列表。 一个 tensor包含一个静态类型 rank,和一个 shape。想了解 TensorFlow 是如何处理这些概念的, 参见Rank, Shape,和 Type]。
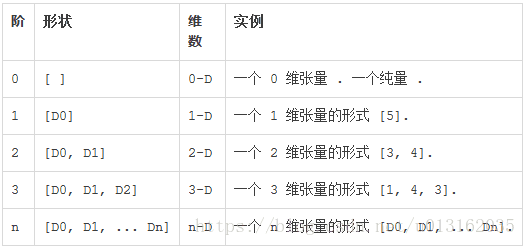
在 Tensorflow 系统中,张量的维数被描述为阶,但是张量的阶和矩阵的阶并不是同一个概念。张量的阶是张量维数的一个数量描述,下面的张量(使用 python 中 list 定义的)就是 2 阶:
t = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
你可以认为一个二阶张量就是我们平常所说的矩阵,一阶张量可以认为是一个向量。对于一个二阶张量,你可以使用语句 t[i, j] 来访问其中的任何元素,而对于三阶张量你可以通过 t[i, j, k] 来访问任何元素。

Tensorflow 文档中使用了三种记号来方便地描述张量的维度:阶,形状以及维数。以下展示了它们之间的关系:
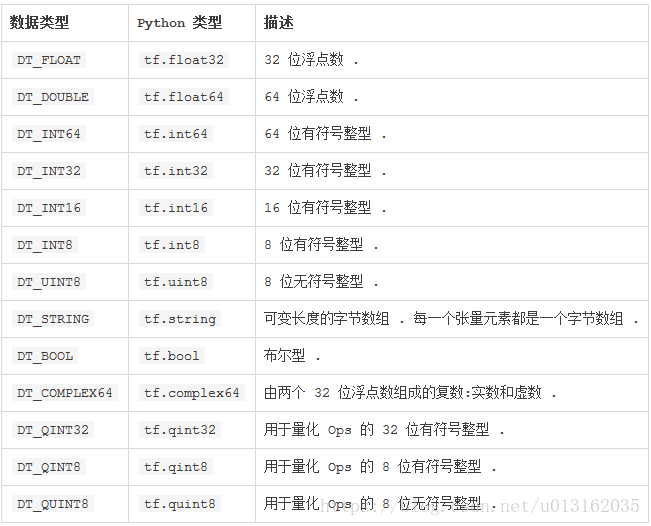
除了维度,tensor 有一个数据类型属性。你可以为一个张量指定下列数据类型中的任意一个类型。
好了,上面介绍了Tensor的相关概念,接下来,笔者带领大家生成tensor的方法。
① tf.zeros(shape, dtype=tf.float32, name=None)
#tf.zeros([2, 3], int32) ==> [[0, 0, 0], [0, 0, 0]]
② tf.ones(shape, dtype=tf.float32, name=None)
#tf.ones([2, 3], int32) ==> [[1, 1, 1], [1, 1, 1]]
③ tf.zeros_like(tensor, dtype=None, name=None)
新建一个与给定的 tensor 类型大小一致的 tensor,其所有元素为 1。
# ‘tensor’ is [[1, 2, 3], [4, 5, 6]] tf.ones_like(tensor) ==> [[1, 1, 1], [1, 1, 1]]
④ tf.constant(value, dtype=None, shape=None, name=’Const’) 创建一个常量 tensor,先给出 value,可以设定其 shape:
# Constant 1-D Tensor populated with value list. tensor = tf.constant([1, 2, 3, 4, 5, 6, 7]) => [1 2 3 4 5 6 7] # Constant 2-D tensor populated with scalar value -1. tensor = tf.constant(-1.0, shape=[2, 3]) => [[-1. -1. -1.] [-1. -1. -1.]
⑤ tf.fill(dims, value, name=None)
创建一个形状大小为 dim 的 tensor,其初始值为 value
# Output tensor has shape [2, 3]. fill([2, 3], 9) ==> [[9, 9, 9],[9, 9, 9]]
⑥ tf.ones_like(tensor, dtype=None, name=None)
在tensorflow程序中所有的数据都通过张量的形式来表示。从功能的角度看,张量可以被理解为多维数组。其中零阶张量表示标量(scalar)也就是一个数;一阶张量为向量,也就是一维数组;n阶张量可以理解为一个n维数组。但张量的实现并不是直接采用数组的形式,它只是对TensorFlow中运算结果的引用。
在张量中并没有保存数字,它保存的是如何得到这些数字的计算过程。 如下代码,并不会得到加法的结果,而会得到对结果的一个引用。
【代码参见附件test3_tensor.py】
import tensorflow as tf
# 创建两个变量
a=tf.constant([1.0,2.0],name='a')
b=tf.constant([2.0,3.0],name='b')
result=tf.add(a,b,name='add')
print(result)
#print
#Tensor(“add:0”, shape=(2,), dtype=float32)从上面的代码可以看出TensorFlow中的张量和NumPy中的数组不同,TensorFlow计算的姐结果不是一个具体的数字,而是一个张亮结构。从上面代码运行的结果可以看出,一个张量主要保存三个属性:名字(name)、维度(shape)和类型(type)。
张量的第一个属性名字不仅是一个张量的唯一标识符,它同样也给出出了这个张量是如何计算出来的。TensorFlow的计算可以通过计算图的模型来建立,而计算图上的每个节点代表了一个计算,计算的结果就保存在张量之中。所以张量和计算图上的节点所代表的计算结果是对应的。这样张量的命名就可以通过“node:str_output”的形式来给出。其中node为节点的名称,str_output表示当前张量来自节点的第几个输出。比如上面代码打出来的“add:0”就说明result这个张量是计算节点”add”输出的第一个结果(编号从零开始)。 张量的的第二个属性是张量的维度(shape)。这个属性描述了一个张量的维度信息。张量的第三个属性是类型(type),每个张量会有唯一的类型。TensorFlow会对参与运算的所有张量进行类型检查,当发现类型不匹配时会报错。
张量的使用可以总结为两大类。第一类用途是对中间计算结果的引用。当一个计算包含很多计算结果时,使用张量可以很大的提高代码可读性。一下为使用张量和不使用张量记录中间结果来完成向量相加的代码对比。
import tensorflow as tf
#使用张量记录中间结果
a=tf.constant([1.0,2.0],name='a')
b=tf.constant([2.0,3.0],name='b')
result=a+b
#直接结算
result=tf.constant([1.0,2.0],name='a')+
tf.constant([2.0,3.0],name='b')从上面的程序样例可以看到a和b其实就是对常量生成这个运算结果的引用,这样在做加法时可以直接使用这两个变量,而不需要再去生成这些常量。同时通过张量来存储中间结果,这样可以很方便的获取中间结果。比如在卷积神经网络中,卷积层或者池化层有可能改变张量的维度,通过result.get_shape函数来获取结果张量的维度信息可以免去人工计算的麻烦。
张量的第二类情况是当计算图构造完成之后,张量可以来获得计算结果,也就是得到真实的数字。虽然张量本身没有存储具体的数字,但可以通过会话session得到这些具体的数字。比如使用tf.Session().run(result)语句来得到计算结果。
3.5变量(Variables)
变量维持了图执行过程中的状态信息。下面的例子演示了如何使用变量实现一个简单的计数器,更多细节详见变量章节。
【代码参见附件test4_variables.py】
import tensorflow as tf
# 创建一个变量,初始为标量0
state = tf.Variable(0, name="counter")
# 创建一个op,其作用是使`state`增加1
one = tf.constant(1)
new_value = tf.add(state, one)
update = tf.assign(state, new_value)
# 启动图后,变量必须先经过init op初始化
# 首先先增加一个初始化op到图中
init_op = tf.initialize_all_variables()
# 启动图
with tf.Session() as sess:
# 运行init op
sess.run(init_op)
# 打印 state 的初始值
print(sess.run(state))
# 运行op, 更新state 并打印
for _ in range(3):
sess.run(update)
print(sess.run(state))输出结果:
# 0
# 1
# 2
# 3代码中assign()操作是图所描述的表达式的一部分,正如add()操作一样,所以在调用run()执行表达式之前,它并不会真正执行赋值操作。
通常会将一个统计模型中的参数表示为一组变量。例如,你可以将一个神经网络的权重作为某个变量存储在一个tensor中。在训练过程中,通过反复训练图,更新这个tensor。
3.6取回(Fetches )
为了取回操作的输出内容, 可以在使用 Session 对象的 run() 调用执行图时,传入一些 tensor, 这些 tensor 会帮助你取回结果. 在之前的例子里, 我们只取回了单个节点state,但是你也可以取回多个 tensor。对于了解C语言的朋友来说,这个就如同函数的方返回值,在前文中对取回(Fetches)有所使用,在这里只是单独讲解而已。
【代码参考附件test5_fetches.py】
import tensorflow as tf
input1 = tf.constant(3.0)
input2 = tf.constant(4.0)
input3 = tf.constant(5.0)
intermed = tf.add(input2, input3)
mul = tf.multiply(input1, intermed)
#mul = tf.mul(input1, intermed)#最新的TensorFlow已经tf.mul请读者朋友注意咯
with tf.Session() as sess:
result = sess.run([mul, intermed])
print(result)
# print
# [27.0, 9.0]需要获取的多个 tensor 值,在 op 的一次运行中一起获得(而不是逐个去获取 tensor)。
3.7供给(Feeds )
上述示例在计算图中引入了 tensor,以 常量 (Constants) 或 变量 (Variables) 的形式存储。TensorFlow 还提供给 (feed) 机制,该机制可临时替代图中的任意操作中的 tensor可以对图中任何操作提交补丁, 直接插入一个 tensor。
feed 使用一个 tensor 值临时替换一个操作的输出结果。你可以提供 feed 数据作为run() 调用的参数。feed 只在调用它的方法内有效,方法结束,feed 就会消失. 最常见的用例是将某些特殊的操作指定为”feed” 操作,标记的方法是使用tf.placeholder()为这些操作创建占位符。
【代码参考附件test6_fdeed.py】
import tensorflow as tf
input1 = tf.placeholder(tf.float32)
input2 = tf.placeholder(tf.float32)
ouput = tf.multiply(input1, input2)
#ouput = tf.mul(input1, input2)#最新的TensorFlow已经tf.mul请读者朋友注意咯
with tf.Session() as sess:
print(sess.run(ouput, feed_dict={input1: [7.], input2: [2.]}))
# print
# [ 14.]3.8总结-线性模型实例
看到这里,笔者相信很多朋友都还是云里雾里,不知所云,前面只是TensorFlow的基本概念,接下来笔者带领大家来看一个线性模型实例,看完这个例子,我相信你对TensorFlow的模型建立就很清晰了,好了,废话不说,我们开始吧。
Tensorflow编程包含两个步骤:构造计算图;运行计算图。
第一步:构建计算图
构造一个简单的计算图:每个节点将0或多个tensor作为输入,输出一个tensor。一种类型的节点是常量节点constant,就如同tensorflow中的常数,它有0个输入,输出一个值。
构建两个浮点型tensor:node1和node2
node1 = tf.constant(3.0, tf.float32)
node2 = tf.constant(4.0) # also tf.float32 implicitly
print(node1, node2)输出结果:
Tensor("Const:0", shape=(), dtype=float32) Tensor("Const_1:0", shape=(), dtype=float32)可以看出,打印结果并不是我们期待的3.0 , 4.0,因为这是打印的节点(属于计算操作),当评估运行之后,才是我们期待的值。评估一个节点,必须在一个会话Session中运行计算图,会话封装了Tensorflow运行时的状态和控制。
第二步:创建会话Session对象
接下来创建一个Session会话对象,调用run方法,运行计算图,去评估node1和node2。
sess=tf.Session()
result = sess.run([node1,node2])
print(result)输出结果:
[3.0, 4.0]到这里,一个最基本的TensorFlow模型就就已经建好了,对于以上模型是最基本TensorFlow代码,就像学习C语言的Hello World。接下来我们将创建更加复杂的模型,也就是一个大家最常见的线性模型优化。
我们知道,使用计算操作将多个节点组合,以此构建更复杂的计算,例如将两个常量节点相加,产生一个新的计算图:
node3 = tf.add(node1, node2)
result = sess.run(node3)
print("node3: ", node3)
print("sess.run(node3): ",result)输出结果:
node3: Tensor("Add:0", shape=(), dtype=float32)
sess.run(node3): 7.0Tensorflow提供了一个名为TensorBoard的部分,可以以图片的方式展示计算图。
这个计算图不是特别有趣,因为它产生的是一个常量结果。计算图可以使用占位符placeholder参数化的从外部输入数据,placeholder的作用是在稍后提供一个值,也就是前文提及的供给(Feeds )。
# 构造计算图
a=tf.placeholder(tf.float32)
b=tf.placeholder(tf.float32)
adder_node=a+b
#运行计算图
print("adder_node:",adder_node)
print(sess.run(adder_node,{a:3,b:4.5}))
print(sess.run(adder_node,{a:[1,3],b:[2,4]}))输出结果:
adder_node: Tensor("add:0", dtype=float32)
7.5
[ 3. 7.]我们可以添加一个操作,使计算图更加复杂:
add_and_triple=adder_node * 3
print("add_and_triple:",add_and_triple)
print("sess run result:",sess.run(add_and_triple,{a:3,b:4.5}))输出结果:
add_and_triple: Tensor("mul:0", dtype=float32)
sess run result: 22.5在机器学习中,需要模型可以任意输入,为了模型具有可训练能力,需要修正计算图,使对于同样的输入得到新的输出。变量Variable允许我们为计算图添加训练参数。构造一个变量,需要提供类型和初始值:
W=tf.Variable([.3],tf.float32)
b=tf.Variable([-.3],tf.float32)
x=tf.placeholder(tf.float32)
linear_model=W*x+b常量节点在调用tf.constant时就被初始化,而变量在调用tf.Variable时并不初始化,必须显性的执行如下操作:
init = tf.global_variables_initializer()
sess.run(init)意识到init对象是Tensorflow子图初始化所有全局变量的句柄是重要的,在调用sess.run(init)方法之前,所有变量都是未初始化的。因为x是一个占位符,我们可以指定几个值来评估linear_model模型(训练),运行计算图:
print("linear_model:",linear_model)
print(sess.run(linear_model,{x:[1,2,3,4]}))输出结果:
linear_model: Tensor("add_1:0", dtype=float32)
[ 0. 0.30000001 0.60000002 0.90000004]我们创建了一个模型,但是不知道这个模型的效果怎么样,基于训练数据来评估模型,还需要一个placeholder y 来提供期望值,我们需要一个损失函数loss function。损失函数测量当前模型与真实数据之间的差距,对于线性模型,我们使用标准损失函数,求模型预测结果与实际数据之间差值的平方和sum the squares of the deltas。linear_model - y 构造了一个向量,对应每个元素的差值,我们调用tf.square求平方,使用tf.reduce_sum求和所有的平方差为一个标量scalar。
y=tf.placeholder(tf.float32)
squared_deltas=tf.square(linear_model-y)
loss=tf.reduce_sum(squared_deltas)
print("loss:",loss)
print(sess.run(loss,{x:[1,2,3,4],y:[0,-1,-2,-3]}))输出结果:
loss: Tensor("Sum:0", dtype=float32)
23.66我们可以通过手动的方式将参数W和b置为W=-1,b=1,使模型最优,即损失函数最小。初始化后的变量可以通过tf.assign来更改,tf.assign后需要tf.run生效
fixW=tf.assign(W,[-1.])
fixb=tf.assign(b,[1.])
sess.run([fixW,fixb])
print("fix loss:",sess.run(loss,{x:[1,2,3,4],y:[0,-1,-2,-3]}))输出结果:
fix loss: 0.0我们猜想最优的W和b值,但是在机器学习中,就是自动的寻找这些最优的模型参数。Tensorflow提供了优化器Optimizer慢慢改变每个变量来最小化损失函数。最简单的Optimizer是梯度下降gradient descent,它根据损失函数相对于该变量的导数大小来修改参数值,一般来讲,手动计算导数是乏味且易出错的,Tensorflow可以使用方法tf.gradients自动的为给定模型计算导数。优化器通常做这个工作。
optimizer=tf.train.GradientDescentOptimizer(0.01)
train=optimizer.minimize(loss)
print("train:\n",trian)
sess.run(init)#重置变量到初始化值
for i in range(1000):
sess.run(train,{x:[1,2,3,4],y:[0,-1,-2,-3]})
print(sess.run([W,b]))输出结果:
train:
name: "GradientDescent"
op: "NoOp"
[array([-0.9999969], dtype=float32), array([ 0.99999082], dtype=float32)]到此,我们实现了一次真实的机器学习,尽管我们只实现的是简单的线下回归,不需要多少Tensorflow core代码,然而复杂的模型和方法输入数据会需要更多的代码量,因此Tensorflow对于一般的模式、结构和功能提供了高级别的抽象。
好了,笔者对以上代码优化,完整代码如下。
【代码参考附件full_code.py】
import tensorflow as tf
import numpy as np
#【第一步】准备数据
#创建原始数据,使用 NumPy 生成假数据(phony data), 总共 100 个点
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data*0.6 + 0.6
#【第二步】构造线性模型
Weights = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
biases = tf.Variable(tf.zeros([1]))
y = Weights*x_data + biases
#【第三步】求解模型
#定义损失函数,误差的均方差
loss = tf.reduce_mean(tf.square(y-y_data))
# 选择梯度下降的方法
optimizer = tf.train.GradientDescentOptimizer(0.5)
# 迭代的目标:最小化损失函数
train = optimizer.minimize(loss)
#【第四步】初始化数据,tf 的必备步骤,主要声明了变量,就必须初始化才能用
init = tf.initialize_all_variables()
# 设置tensorflow对GPU的使用按需分配,配置好GPU才能使用以下两行代码
#config = tf.ConfigProto()
#config.gpu_options.allow_growth = True
#【第五步】创建Session会话。启动图
sess = tf.Session()
#sess = tf.Session(config = config)配置好GPU才能使用以下代码
sess.run(init)
#【第六步】训练模型的到结果,迭代,反复执行上面的最小化损失函数这一操作(train op),拟合平面
for step in range(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(Weights), sess.run(biases))输出结果:
0 [0.45143753] [0.9062223]
20 [0.54057676] [0.6306117]
40 [0.5854129] [0.6075145]
60 [0.5964192] [0.60184467]
80 [0.59912103] [0.60045284]
100 [0.5997842] [0.60011125]
120 [0.599947] [0.6000273]
140 [0.59998703] [0.6000067]
160 [0.5999968] [0.6000017]
180 [0.5999992] [0.60000044]
200 [0.59999967] [0.6000002]