
前言
三多前笔者在《万字长文漫谈视频理解》[1]一文中,曾经将自己对视频理解的认识进行过简单总结,幸而获得了朋友们的认可,能让读者认可是笔者最为骄傲的成就。现在看来文中观点有不少纰漏狭隘之处,特别是近年来多模态模型的流行,更让视频理解这个方向出现了诸多变革技术,之前在博文《视频分析与多模态融合之一,为什么需要多模态融合》 [2] 曾经尝试对[1]进行补丁,但是限于笔者时间和当时的认识水平,并没有进行展开讨论。本文希望能对近年来的多模态模型进行简单总结,并且简单讨论这些模型在图片搜索和视频搜索这类富媒体检索场景中的应用可能性。笔者入行未深,道行浅薄,如有谬误请见谅并联系指出,本文遵守CC 4.0 BY-SA版权协议,转载请联系作者并注明出处,谢谢。
导读:该文的组织结构
本文的篇幅较长,为了适配不同知识背景的读者,笔者在此提供了本文的导读,请有相关知识背景的读者自行跳转需要的章节。
- 『0x01 视频和图片:信息弥散在时空中』主要介绍了图片与视频的视觉符号,并且简单介绍了文本-视觉的语义对齐与语义融合在信息检索中的应用。
- 『0x02 单模态视频/图片特征表达』主要介绍了图片与视频的单模态表征学习方法,最后也对文本的表征方法进行了简单概述。单模态建模是多模态建模的基础,许多跨模态、多模态建模方法收到了单模态建模的深刻影响,因此笔者认为有必要引入本章。
- 『0x03 语义标签的使用:走向多模态』 主要作为引子介绍多模态与单模态的一些关联与区别,该章作为桥梁桥接着上文单模态建模与下文的多模态建模。
- 『0x04 CLIP之前:多模信息的融合建模』 该部分开始正式开始介绍多模态模型,这章介绍的是CLIP之前的语义融合模型。
- 『0x05 CLIP之后:多模信息的对比、融合建模』 该部分介绍CLIP之后的语义对齐、语义融合模型,这些模型大多都是对CLIP的缺陷的某方面改进。
- 『0x06 End of Journey』 对本文的总结。
0x01 视频和图片:信息弥散在时空中
人是视觉的动物,所见即所得永远是人类最原始的欲望。比起需要让人理解、深思和发挥想象力的文字信息,视频、图片这种富媒体信息在信息传递效率上发挥着绝对优势。如若文字的信息来自于每个符号所背负着的人类社群共识的抽象含义1,以及抽象含义的自由组合产生的无穷变化,那么视频、图片的信息又由什么“视觉符号”去承载着呢?
图片的视觉元素
大多数图片的基础组成元素都是像素(Pixel)2,像素成片成块组成了图片块(Patch)。图片涉及到的题材广泛地分布在各行各业,如Fig 1.1所示,生物影像,遥感照片,网络表情包,用户上传的自然图片,自拍,红外图像等等都可以视为是某种类型的图片。本文较多考虑的是由用户上传的自然图片,下文称之为自然图片(General images)。

自然图片含有复杂的视觉语义,在文章[6]中,作者认为常见的具有区分度(Distinguished)的视觉语义元素有:实体(Entity),属性(Attribution),关系(Relation)等,如Fig 1.2 (a-c) 所示,这些视觉元素偏具象,且是局部语义,比如实体中的大金毛,大橘猫,属性里面的紫色,蓝色,黑色,关系里面的骑着,修理,倒立等等。有些场景中需要表示整个图片的全局视觉语义,需要组合这些局部语义形成全局语义,比如Fig 1.2中的(d),为了识别出图片中所带有的“抑郁,悲伤”的抽象语义,需要提取出图片整体色调,女生趴着,蜡烛熄灭等元素,为了简便,笔者将这种全局语义简称为视觉氛围(Vision Atmosphere),这种抽象语义的建模,笔者认为会类似于后文提到的弱视觉语义数据建模,且按下不表。


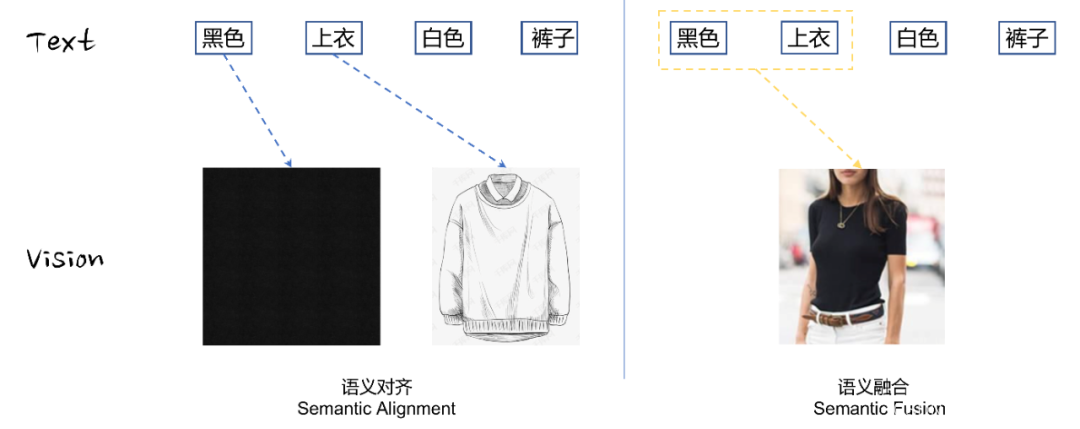
当然这些视觉元素可能只是冰山一角,画家用笔触都可以描述情感,摄影家用光影照样述说故事,图片的具象语义往往是底层语义,抽象语义难以建模,因此也不会是本文的特别关注点(即便弱视觉语义可能和抽象语义有着关联)。因此,在本文笔者认为大多数图片的具象语义通过实体,属性,关系等视觉符号进行传递,而这些视觉符号或多或少和文本信息能够建立关联。这种建立的文本-视觉之间语义的桥梁,通常可以分为两个阶段,语义对齐(Semantic alignment)和语义融合(Semantic fusion),如Fig 1.4所示。
- 语义对齐:指的是将文本中的视觉实体,属性描述,进行对应视觉元素的映射。此处的图文映射关系可称之为基础视觉语义。
- 语义融合:在语义对齐的基础上,对基础视觉语义进行融合、组合,从而形成复杂的复合视觉语义。复合视觉语义包括视觉关系,更为抽象的视觉氛围等。
不难发现,文本语义紧凑,信息密度极大,而图片在相近语义下其通常有大量信息冗余,信息密度低下,因此有众多研究在思考如何压缩图片信息量,有效提取、编码其隐藏的语义,我们后文会继续对此进行讨论。

视频的视觉元素
视频不是图片在时间维度上的简单展开,不同帧间图片的视觉元素在时间上的彼此关联带来了更为复杂多变的视觉符号,即便识别出了视频帧所有的视觉符号,其在时间上的简单接驳并不能完全代表视频的视觉符号。
视频的视觉符号最典型的比如动作,如Fig 1.5 (a)所示,动作序列通常是同个实体特定模式的行为,比如弯腰、捡起、起身,在以视频片段为单位的时候就能视为一整个视觉符号。动作通常是一个连续的线性符号,而视频的多帧特性意味着其存在非线性的帧间关联,如[9,10]中所介绍的通过组织视频非线性流进行动作理解的工作。非线性视频的特性在互联网视频中更为常见,如Fig 1.5 (b,c) 所示,互联网视频受到视频创作者的剪辑,视频通常都会出现镜头、场景的切换,事件的因果关系因此作为视觉符号存在于视频的非线性关系中。通常来说,视频的组成可以层次化地分为以下四部分[10],帧、镜头、事件乃至整个视频都可以视为视频的视觉元素。
帧(Frame) --> 镜头(Shot) --> 事件(Event) --> 视频(Video)
因此,对于视频的视觉元素挖掘,会比图片的视觉元素挖掘复杂很多,有些挖掘方法甚至和视觉本身无关,比如识别视频的OCR信息。在实际应用中,我们暂时不期望能对视频的视觉符号进行深入挖掘,认为其只需要挖掘出其中实体、属性、关系等基础视觉概念,顶多能延伸出一些简单的动作、场景视觉概念、简单事件的视觉概念等。

语义对齐/融合与信息检索
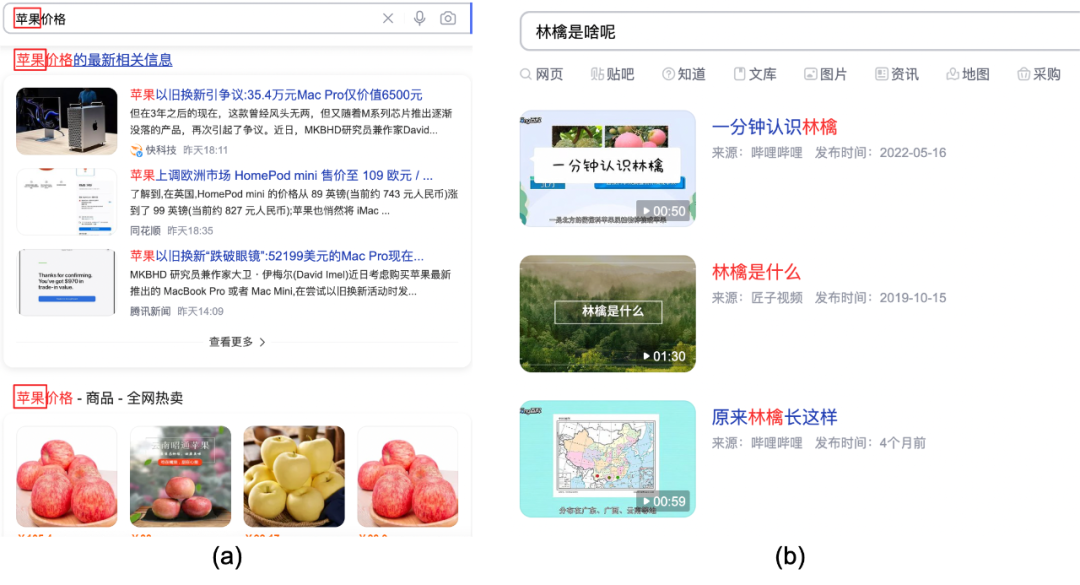
正如笔者在之前文章[25-27]中所谈到的,信息检索中最重要的一块就是相关性(Relevance),可以说相关性决定了整个搜索系统的基础体验好坏与否。在典型的搜索系统中,相关性由文本相关性进行建模,经典的有BM25、TF-IDF等基于词频的描述,在深度学习流行后,渐渐落地了各种端到端的语义相关性建模,如BERT、ERNIE等。这类型模型对相关性的建模是基于字词文本的语义匹配,如Fig 1.6(a)所示,苹果有两种常见语义,分别是电子产品和食物,Fig 1.6(b)展示了其他文本相关性的例子。
0x02 单模态视频/图片特征表达
正如前言所说,笔者曾在[1]中对视频理解进行过讨论,彼时认为动作理解是视频理解的核心任务,而这两年的工作经验告诉我,这个结论是有所偏颇的。首先,采用动作理解的前提是以人为中心的视频内容理解,利用动作理解学习出的视频视觉符号大多集中在人体动作,而对视频中出现的视觉实体、属性、关系等感知能力很弱。我们之前的讨论告诉我们,互联网视频为代表的通用视频视觉信息复杂多变,视频内容不可能都以人为中心,事实上我们线上遇到的视频大多都不可能以人为中心。其次,即便遇到类似直播,知识盘点类,解说类的以人为中心视频,其视频的主要语义也不可能是出镜人物的动作,而是人物的解说内容,此时反而OCR、ASR等信息更为关键。动作理解类的应用主要还是集中在toB类的厂商中,比如摄像头监控,无人机监控,机器人应用等,对于互联网视频而言,采用动作理解技术去理解整个视频的视觉信息是远远不够的,我们更希望能对视频中的视觉实体、属性、关系等视觉符号进行识别。
之前我们在[1]中也谈到过,在传统的动作识别中需要利用大量的动作标签进行视频表征学习,而动作标签往往需要人工标注,这是昂贵且耗时的,因此在[1]的末尾也引出了一些自监督学习的方式去学习动作视频表征。这些自监督方法需要人工去设计各种类型的pretext任务,比如jigsaw puzzle [30],colorization [31],image rotation [32]等,这些pretext任务通常是启发式的,很难保证其跨数据集的泛化性,换句话说就是不够通用。对于一般的通用视频/图片来说,则有其他更高效的自监督学习方法。
图片表征
SimCLR
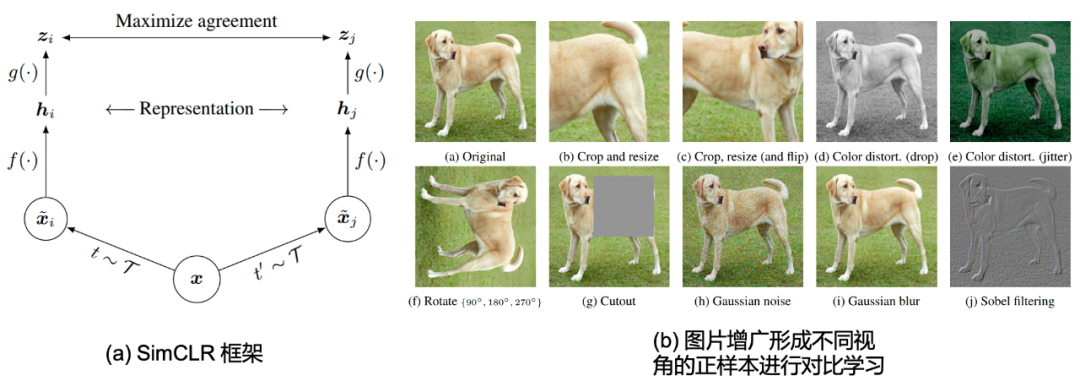
我们开篇介绍的是Hinton老爷子著名的SimCLR [28],该方法通过图片增广(image augmentation)的方式构建出成对的图片正样本对,同时将其他图片视为负样本,这种方法可以在不利用图片标签的前提下,进行自监督学习出图片表征。如Fig 2.1(a)所示,其中的 f ( ⋅ ) f(\cdot) f(⋅)为图片编码器,比如该工作采用的是ResNet-50。 g ( ⋅ ) g(\cdot) g(⋅)表示的是将表示(representation)映射到语义空间(Semantic Space)的映射函数,通常可以用MLP模块进行表示,比如该工作采用的是 z i = g ( h i ) = W 2 σ ( W 1 h i ) z_i = g(\mathbf{h}_i) = W_2 \sigma(W_1\mathbf{h}_i) zi=g(hi)=W2σ(W1hi),其中的 σ ( ⋅ ) \sigma(\cdot) σ(⋅)是ReLU激活函数。而 t ∼ T t\sim \mathcal{T} t∼T和 t ′ ∼ T t^{\prime} \sim \mathcal{T} t′∼T则表示采用同一种图片变换方法 T \mathcal{T} T生成得到的两个图片样本3,在恰当的图片变换下,图片具有标签不变性(instance label invariance),我们可以将其视为是原图片的不同视角,因此可以将这两个图片样本视为是正样本对。在给定batch size为 N N N的情况下,通过图片增广可以产生 2 N 2N 2N个图片,其中每个样本有一个正样本, 2 ( N − 1 ) 2(N-1) 2(N−1)个负样本。该论文中对图片进行的变换如Fig 2.1 (b)所示,主要是裁剪、翻转操作,像素空间处理等。
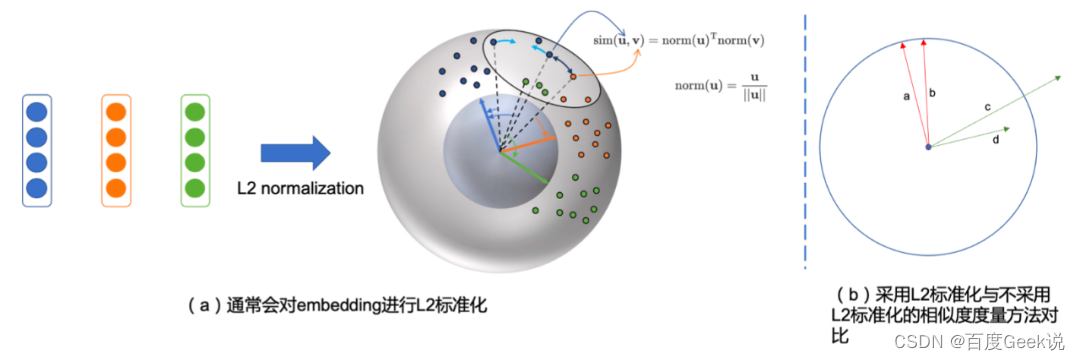
通过采用带温度系数的交叉熵损失作为对比损失进行建模(该损失函数被称之为NT-Xent loss4),如公式(2-1)所示,其中的 s i m ( u , v ) = u T v / ∣ ∣ u ∣ ∣ ∣ ∣ v ∣ ∣ \mathrm{sim}(\mathbf{u}, \mathbf{v})=\mathbf{u}^{\mathrm{T}} \mathbf{v} / ||\mathbf{u}|| ||\mathbf{v}|| sim(u,v)=uTv/∣∣u∣∣∣∣v∣∣表示了余弦相似度度量。不妨将余弦相似度拆开,视为对 u , v \mathbf{u}, \mathbf{v} u,v进行L2标准化(L2 normalization)后进行点乘进行相似度度量,在这个视角中,我们会发现得到的表征都在一个高维球面上,如Fig 2.2所示。公式(2-1)的 τ \tau τ是温度系数,而 1 [ k ≠ i ] \mathbb{1}_{[k \neq i]} 1[k=i]是指示函数,表示仅在 k ≠ i k \neq i k=i的情况下为1,而 < i , j > <i,j> <i,j>是一对正样本对。可以看出公式(2-1)的分母部分是正样本打分加上所有的负样本打分,而分子部分则是正样本打分。从这个角度上看,当batch size越大的时候,产生的负样本数量就越多,正负样本的对比会更为充分,更能学习出具有区分度的特征。
L ( i , j ) = − log exp ( s i m ( z i , z j ) / τ ) ∑ k = 1 2 N 1 [ k ≠ i ] exp ( s i m ( z i , z k ) / τ ) (2-1) \mathcal{L}(i,j) = -\log \dfrac{\exp(\mathrm{sim}(z_i, z_j)/\tau)}{\sum_{k=1}^{2N} \mathbb{1}_{[k \neq i]}\exp(\mathrm{sim}(z_i, z_k)/\tau)} \tag{2-1} L(i,j)=−log∑k=12N1[k=i]exp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)(2-1)
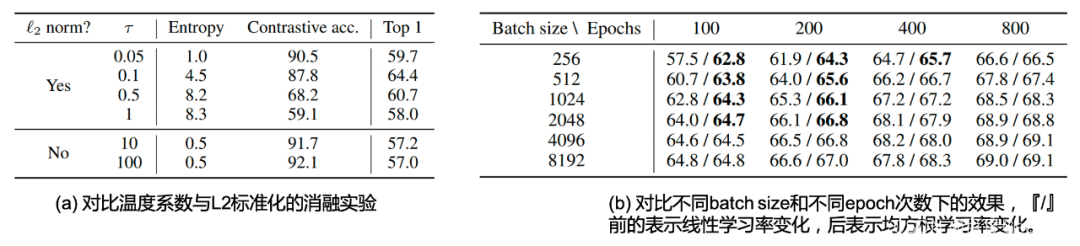
该工作的消融实验对图片变换的组合,温度系数,batch size大小,训练epoch数量,特征表达位置的效果等进行了充分的探索,其试验部分值得诸位读者翻阅原文细看,本博文仅作抛砖引玉之功用,简单对其中笔者认为重要的结论和实验进行介绍。温度系数对于对比学习实在重要,正如笔者在[29]中讨论的,温度系数的大小控制着整个任务的学习难度。在本文也有着对应的消融实验,如Table 2.1 (a)所示,我们发现在采用了L2标准化的情况下,温度系数分别选取{0.05, 0.1, 0.5, 1}情况下,其训练的对比准确率(Contrastive acc.)依次下降,意味着温度系数越大,其对比学习任务难度越大。然而其泛化性能如最后一列所示,在 τ = 0.1 \tau = 0.1 τ=0.1的情况下取得最优,这意味着为了取得最好的表征效果,需要细致地调整对比损失的温度系数。此处对于温度系数的结论和博文[29]的是一致的,即是
加大温度系数将增大对比任务的难度,会尝试将其中的难样本也区分正确;而减小温度系数将减小对比任务的难度,让任务收敛得更好。
区别仅在于在CLIP等工作中,温度系数通常是可学习的(Learnable temperature),而在SimCLR中是固定的温度系数,这并不是本章的重点。同时,我们能看到,采用L2标准化和不采用L2标准化同样会带来明显的性能差距,不采用L2标准化会带来更高的对比训练表现,然而其表征能力都不及采用了L2标准化的结果。这一点也比较容易理解,如Fig 2.2 (b)所示,采用了L2标准化后,如a和b,每个embedding的模都是1,也就是说在模这个维度不存在任何区分度,只能通过embedding的其他更具有区分度的信息进行判断语义。而不采用L2标准化,如c和d,则在训练中不同embedding的模都可能不同,模型会尝试通过模大小这个维度进行区分正负样本,而忽略了embedding本身的语义信息。这很容易导致在训练时期易于收敛,但学习出的表征较差。
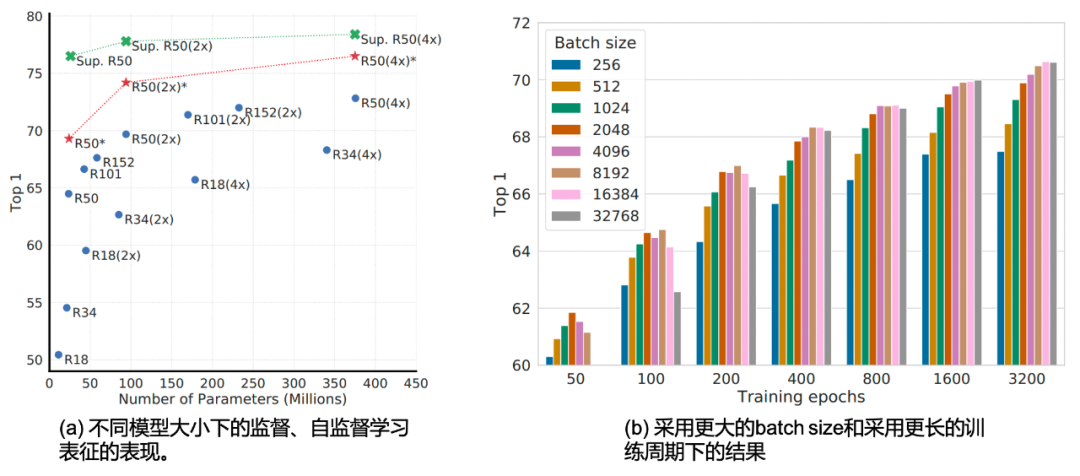
回到我们的消融实验讨论,作者同样对batch size大小在训练时候的影响进行了探索,直观上来看采用更大的batch size可以在同一次迭代中见到更多负样本,能够进行更充分的对比学习。而增大训练的时间,即是增大训练epoch也能在更多的时间上见到更多的负样本,因此效果应该是类似于增大batch size的。如Table 2.1 (b)所示,在固定epoch的情况下,采用了更大batch size的效果比更小的好,在相同大小的batch size情况下,epoch越大效果越好。注意到『/』前的是采用线性学习率放缩,而『/』后的是采用均方根学习率放缩的结果。采用均方根学习率放缩有利于小batch size和少epoch情况下的训练。不难发现,batch size太小所造成的训练劣势,可以被更长的训练周期所弥补。作者也尝试采用更大的batch size和更长的训练周期,如Fig 2.3 (b)所示,我们发现性能似乎已经在batch size等于8192的时候饱和了,但更长的训练周期仍然能提供持续的表现提升。
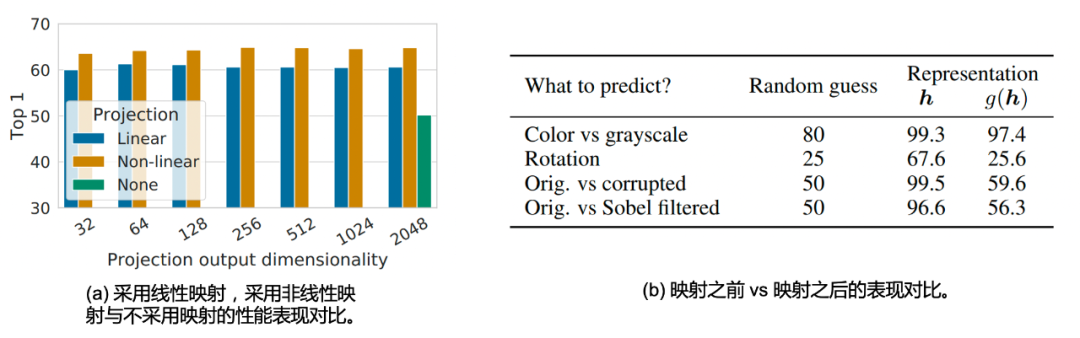
作者也研究了不同的映射 g ( ⋅ ) g(\cdot) g(⋅)方式对于表征性能的对比,如Fig 2.4 (a)所示,无论是在那种输出维度下(32,64,…,1024,2048),采用了非线性映射(也即是ReLU函数)的 g ( ⋅ ) g(\cdot) g(⋅)总是比线性映射的表现更优(3.0%),而不采用任何映射函数总是劣于采用了映射(10.0%)。同时,作者也发现一个比较有趣的结论,采用了映射之前的表征 h h h和采用了映射之后的表征 g ( h ) g(h) g(h)对比,是前者优于后者,这个具体的讨论和本文的主题并不太相关,因此有兴趣的读者请移步论文。
开篇的工作——SimCLR花了较长的篇幅进行介绍,这是因为其对我们后面的基于对比学习的多模态模型的建模和设计都有指导意义。总而言之,我们从以上的讨论中,能看出目前基于对比学习的自监督表征建模,有以下需要注意的点:
- 大模型对于自监督对比学习很重要
- 大batch size和更长的训练周期很重要
- 采用非线性映射头很重要
- 合适的温度系数很重要
- 采用L2标准化很重要
我们将会发现,后面的无论是单模态表征或者跨模态表征的模型,或多或少都有这些点子的影子在。
Memory Bank 与 MoCo
从SimCLR的实验来看,增大batch size可以在更少的训练周期里面获得更好的效果,但是增大batch size通常需要更多的GPU资源。考虑到增大batch size的作用本质是增大一个iteration中能见到的负样本数量,可以考虑通过维护一个虚拟的负样本队列,通过采用历史上的负样本进行对比学习,以实现将batch size大小和负样本数量解耦的目的,而memory bank [34]就是这样一个采用负样本队列的工作。
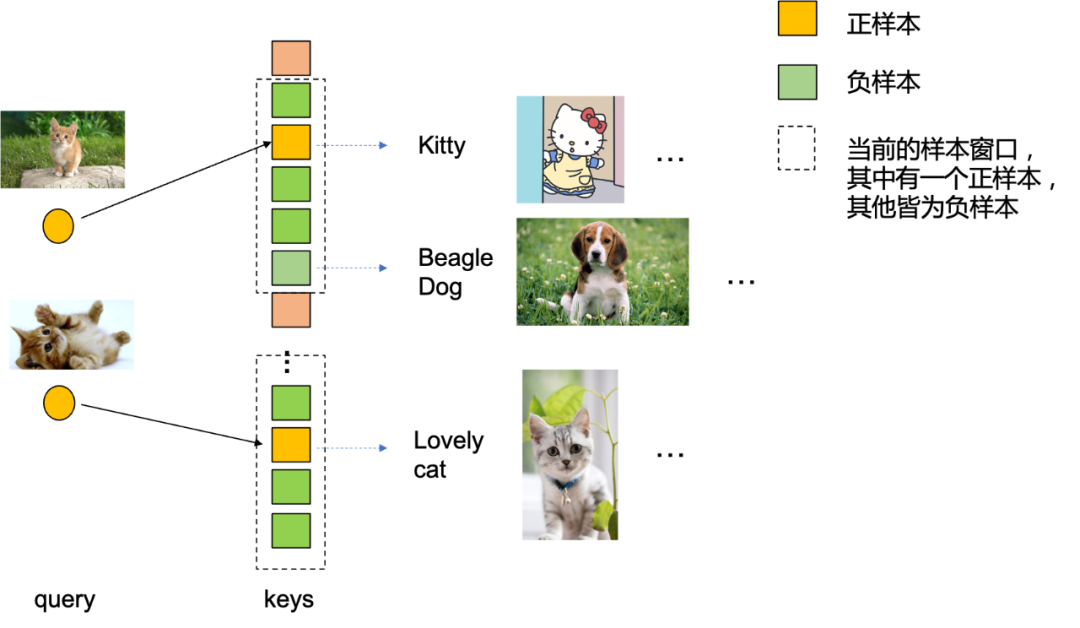
在开始讨论memory bank工作本身之前,我们先尝试换个角度去看待对比学习,如Fig 2.5所示,我们不妨把对比学习中的正负样本匹配看成是通过query在字典里面查询,而正样本匹配则是query匹配到了正确的key,负样本匹配则是匹配到了错误的key。而编码器则可以分为Query编码器和Key编码器,在同模态建模时候QK编码器可以为相同的,在跨模态建模时候则通常是不同的。不难看出,为了Query能在字典中正确地匹配到Key,Query编码器和Key编码器的状态需要保持一致。何为状态一致呢?一般的理解来看,就是Query编码器和Key编码器在训练时是同步收到梯度影响更新的,Query编码器每更新一步,Key编码器就会更新一步。容易发现,SimCLR这种方式建模的Query编码器和Key编码器是相同的,因此QK编码器肯定是状态一致的。
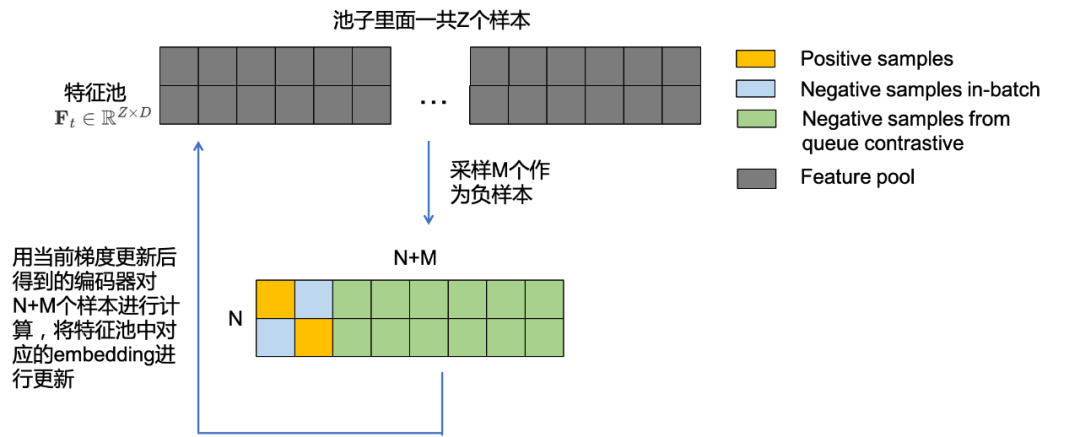
Begin of Memory Bank Algorithm
- 首先用当前的Query编码器 f t ( ⋅ ) f_{t}(\cdot) ft(⋅)对当前所有 Z Z Z个样本进行计算,得到 Z Z Z个embedding,将其称之为 t t t时刻的特征池 F t ∈ R Z × D \mathbf{F}_{t} \in \mathbb{R}^{Z \times D} Ft∈RZ×D。
- 从中特征池里面抽取 M M M个样本作为负样本,记为 M ∈ R M × D \mathbf{M} \in \mathbb{R}^{M \times D} M∈RM×D,与当前的batch size共 N N N个样本进行对比得到 R ( N + M ) × D \mathbb{R}^{(N+M) \times D} R(N+M)×D的负样本打分,同时与当前batch size的样本的对比打分进行组合,如Fig 2.7所示,组成 R N × ( N + M ) \mathbb{R}^{N \times (N+M)} RN×(N+M)个打分,其中有 N N N个正样本打分,其余都是负样本打分,根据这个打分矩阵进行对比损失建模,产生梯度更新Query编码器,并且记为 t + 1 t+1 t+1时刻的Query编码器 f t + 1 ( ⋅ ) f_{t+1}(\cdot) ft+1(⋅)。
- 用 t + 1 t+1 t+1时刻的Query编码器 f t + 1 ( ⋅ ) f_{t+1}(\cdot) ft+1(⋅)对N+M个样本的embedding进行计算后,将对应特征池里面的特征进行更新,得到 F t + 1 ∈ R Z × D \mathbf{F}_{t+1} \in \mathbb{R}^{Z \times D} Ft+1∈RZ×D。
- 回到步骤1进行下一轮训练。
End of Memory Bank Algorithm
从这个过程来看,我们能发现这个过程中是没有Key编码器的,而Key编码的作用被memory bank这个半离线的样本储存单元给取代了。由于memory bank是在全局样本里面进行采样得到负样本,而 t + 1 t+1 t+1时刻的Query编码器结果只会在整个池子里面更新 N + M N+M N+M个样本的embedding,在 t + 2 t+2 t+2时刻中仍然会随机采样负样本,因此无法保证 t + 1 t+1 t+1时刻更新的embedding被采样到作为负样本供给 t + 2 t+2 t+2轮的训练。不难看出,此时Query编码器状态和Key编码器(也即是memory bank)状态是不一致的,且Key编码器落后于Query编码器的步数是无法预期的(因为是在总的样本池子里面随机采样负样本)。这个也正如在Table 2.2里面总结的一样。
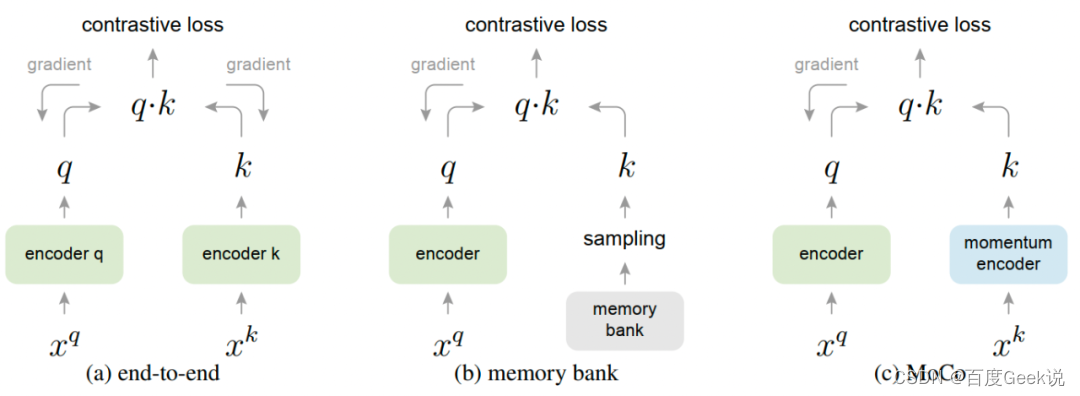
| 提高batch size的方式 | 提高负样本数量的方式 | batch size和负样本数量是否耦合 | Query-Key编码器状态一致性 | 正样本对中QK编码器是否状态一致 | 是否会遇到BN层统计参数泄露 | |
|---|---|---|---|---|---|---|
| 端到端 | all_gather |
通过提高batch size | 是 | 一致更新 | 一致更新 | 是 |
| MoCo | 一般无需提高batch size | 通过维护负样本队列 | 否 | 一致更新,或者Key编码器以固定步数落后于Query编码器 | 一致更新 | 否 |
| Memory Bank | 一般无需提高batch size | 通过维护负样本队列 | 否 | 不一致,Key永远落后于Query,且落后步数不可预期 | 不一致, | 否 |
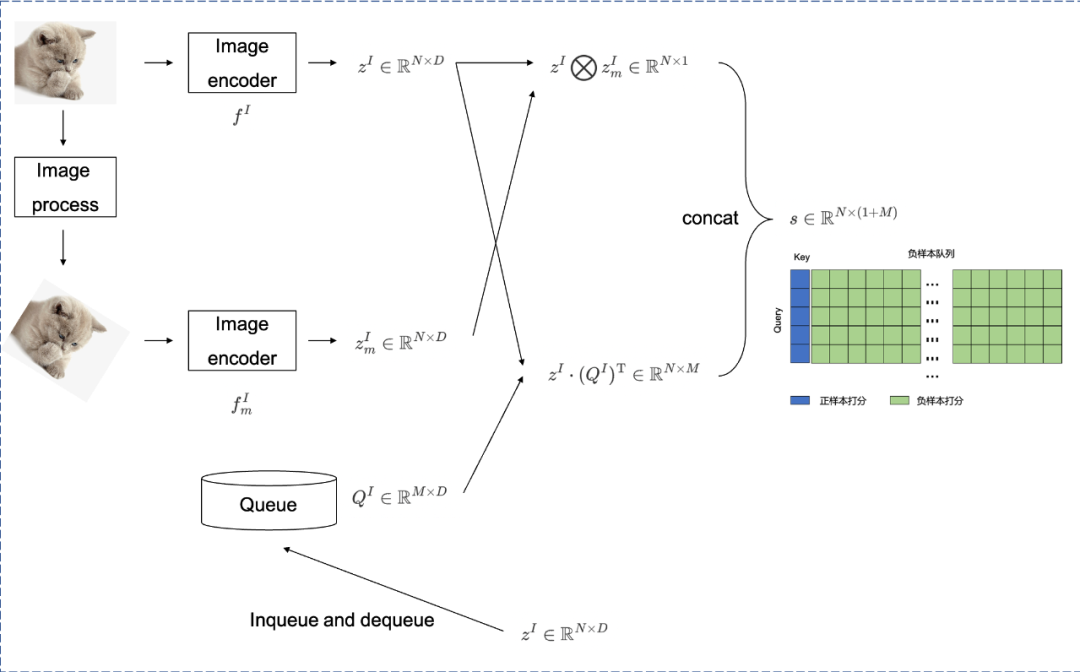
MoCo和memory bank不同在于,MoCo在采用负样本队列进行负样本扩充的前提下,同样采用了Key编码器5。如Fig 2.8所示,其中的 f I f^{I} fI为Query编码器,而 F m I F^{I}_{m} FmI为Key编码器,前者输出的embedding矩阵为 z I ∈ R N × D z^{I} \in \mathbb{R}^{N \times D} zI∈RN×D,后者输出的embedding矩阵则为 z m I ∈ R N × D z^{I}_{m} \in \mathbb{R}^{N \times D} zmI∈RN×D,负样本队列样本数量为固定的 M M M个, Q I ∈ R M × D Q^{I} \in \mathbb{R}^{M \times D} QI∈RM×D。MoCo的整个流程描述如下:
Begin of MoCo Algorithm
- 计算正样本打分,即是计算当前Query编码器和Key编码器的打分,得到 z I ⨂ z m I ∈ R N × 1 z^{I} \bigotimes z^{I}_{m} \in \mathbb{R}^{N \times 1} zI⨂zmI∈RN×1。
- 计算负样本打分,即是计算当前Query编码器和负样本队列的打分,得到 z I ⋅ ( Q I ) T ∈ R N × M z^{I} \cdot (Q^{I})^{\mathrm{T}} \in \mathbb{R}^{N \times M} zI⋅(QI)T∈RN×M。
- 拼接正样本和负样本打分,得到 s ∈ R N × ( 1 + M ) s \in \mathbb{R}^{N \times (1+M)} s∈RN×(1+M),其中第一列总是正样本。
- 更新负样本队列,将当前Query编码器的表针 z I z^{I} zI入队负样本队列 Q I Q^{I} QI,并且将负样本队列中最老的样本进行出队。
- 通过动量更新对Key编码器进行参数更新,以保持对Query编码器的状态跟踪。
- 重复步骤1。
End of MoCo Algorithm
其中第5步的对Key编码器的动量更新很关键,这保证了Key编码器可以对Query编码器进行状态跟踪,动量更新的方式如公式(2-2)所示,其中的 θ K t + 1 , θ K t \theta_{K}^{t+1},\theta_{K}^{t} θKt+1,θKt分别是 t + 1 t+1 t+1和 t t t时刻的Key编码器模型参数,而 θ Q t \theta_{Q}^{t} θQt为 t t t时刻的Query编码器模型参数, m ∈ [ 0 , 1 ) m \in [0,1) m∈[0,1)表示动量系数(本文默认设为 m = 0.999 m=0.999 m=0.999)。通过动量更新的方式,不难看出Key编码器和Query编码器可以保持状态一致,因此正样本打分是状态一致的Query-Key打分。我们继续考察负样本打分,负样本打分来自于Query编码器embedding与负样本队列的打分,负样本队列由过去 T T T个时刻中的Query编码器embedding所填充,此时负样本队列中最老的状态总是落后于当前Query编码器 T T T个时刻,这个落后步数是可以预期的,因此近似可以认为负样本打分也是状态一致的。
θ K t + 1 ← m θ K t + ( 1 − m ) θ Q t (2-2) \theta_{K}^{t+1} \leftarrow m\theta_{K}^{t} + (1-m)\theta_{Q}^{t} \tag{2-2} θKt+1←mθKt+(1−m)θQt(2-2)
在MoCo的训练过程中,可能会遇到Batch Norm层的信息泄露问题,这个不是本文重点,具体见博文[35]。
MAE
Masked AutoEncoder (MAE) [36] 同样也是凯明大佬的代表作之一。考虑到在NLP任务中有Mask Language Model(MLM),其对输入的文本进行掩膜然后尝试通过模型进行缺失令牌的预测,从而让模型学习到令牌的语义(从缺失令牌的上下文中)。正如上文所说,文字是一种信息密度极高的信息媒介,而图片则是一种信息冗余度极高的媒介,既然文字可以通过掩膜文本令牌的方式进行语义建模,图片这种信息密度更低的数据类型没道理不能这样处理。
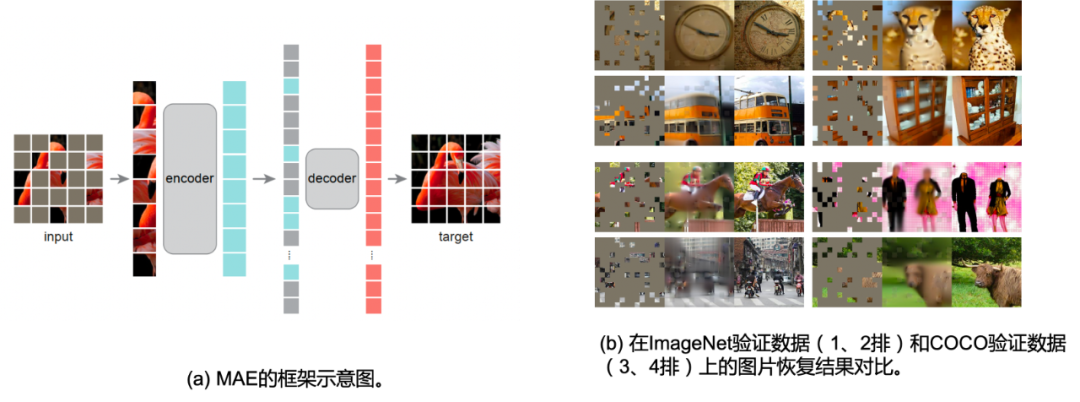
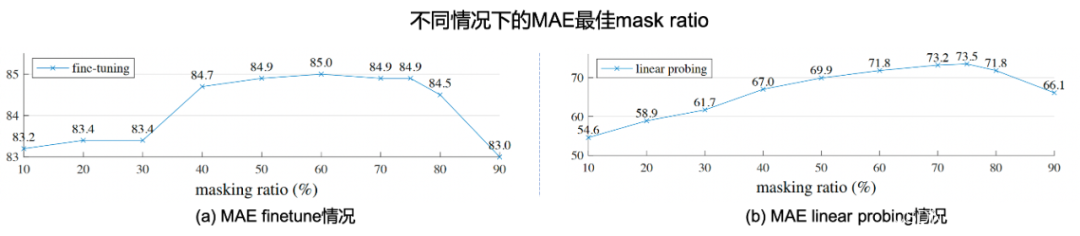
在MAE这篇工作中,如Fig 2.9 (a)所示,首先仿照Vision Transformer [37] 中图片分块的处理,作者首先对图片进行网格划分,将图片均匀划分为多个 16 × 16 16 \times 16 16×16像素大小的图片块,记为一共有 N N N个图片块。随后按照给定的掩膜比例(mask ratio) p p p,以块的粒度对图片块进行随机去除,并将剩余的可见(visable)图片块 x ∈ R M × W × H × C \mathbf{x} \in \mathbb{R}^{M \times W \times H \times C} x∈RM×W×H×C作为ViT encoder的输入,记产出的embedding为 r ∈ R M × D \mathbf{r} \in \mathbb{R}^{M \times D} r∈RM×D,其中 D D D为embedding维度。此时,将缺失的embedding用mask token进行代替(类似于NLP中的[MASK]),将其余的图片块按照原先图片块的位置关系进行排序,通过ViT decoder进行像素级别的重建,即完成了MAE的建模。作者通过finetune任务和linear probe任务,在多个下游数据上进行了测试,证明了MAE对于图片表征学习的有效性,这些实验读者有兴趣可自行翻阅,本文主要对其重建的图片可视化结果进行展示,如Fig 2.9 (b)所示,其第一列表示mask后的图片,第二列表示恢复后的图片,第三列表示ground truth的愿图片,采用mask概率为80%,可以发现其重建图片效果在语义上都是没问题的。特别关注的是,第3排的右边结果,我们发现尽管重建图片和真实图片存在一定的差别(真实图片的人体是没头的,但是重建图片则是含有头的),但是重建图片在语义上更为正确(这个应该是人体的模型,大部分真实的人体都应该有头吧…),由此可知MAE的重建并不是基于记忆,而是基于语义。作者在原文还进行了不少消融实验,本文就列举其中一个对最佳掩膜比例的实验,如Fig 2.10所示,作者在MAE finetune和MAE linear probing的情况下,分别尝试了不同的掩膜比例,其中发现两种情况下的MAE最佳掩膜比例都在75%,而在BERT中,典型的掩膜比例是15%左右,这也一定程度上验证了图片的信息密度的确比文本的高。MAE这种对图片进行掩膜的思想,也直接影响到了跨模态模型的建模,如FLIP [24]。
BEiT
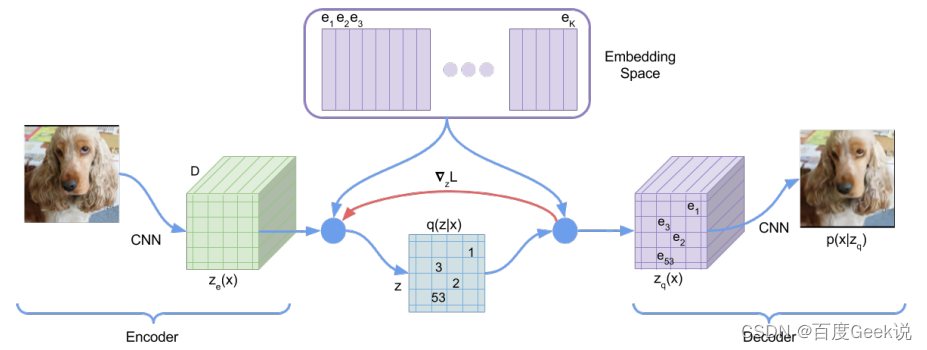
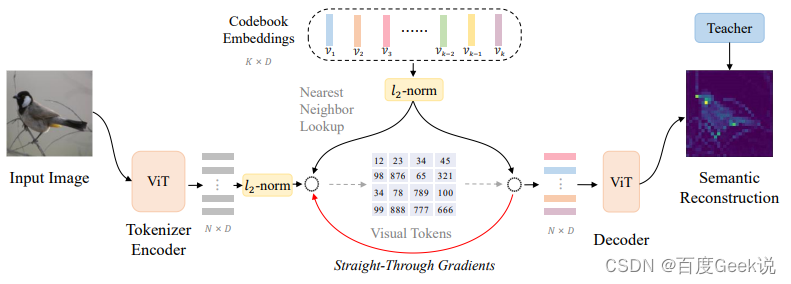
除了MAE这种尝试对图片像素进行重建的工作外,还有一些工作尝试对图片的稀疏视觉令牌进行重建。在此之前,我们可以了解下什么叫做稀疏视觉令牌(sparse visual token),将图片进行分块后,通过模型将图片块映射到某个整型的ID,我们称之为图片块的视觉令牌化,对比稠密的浮点向量,它由于是一个整型的值,因此是稀疏的。图片的信息冗余性是能够对图片块进行视觉令牌化的重要前提,通过令牌化另一方面也可以提取图片的关键语义信息。VQ-VAE [45]就是一种尝试对图片进行稀疏视觉令牌化的工作,如Fig 2.11所示,作者通过图片的像素重建着手,将视觉的稀疏编码看成是中间的隐变量 z z z。通过维护一个向量字典(Embedding space),对图片块编码后的稠密向量在字典中进行最近邻查找,将查找得到后的索引视为是其稀疏编码(也既是稀疏视觉令牌)。整个过程的具体介绍请见博文 [46],此处不累述。
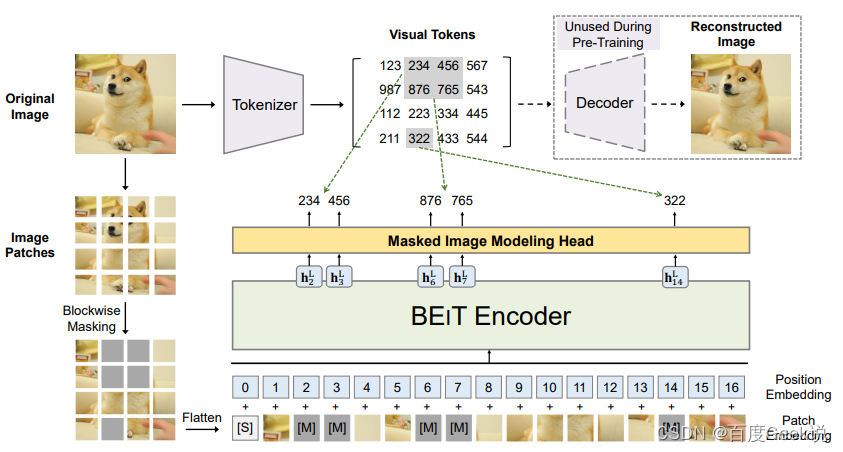
而在BEiT [47]就是尝试对这种视觉令牌进行重建,而不是对像素本身进行重建的工作。像素本身是一种最底层的视觉元素,而若干像素组成的小图片块具有的语义也较为底层,如果对像素作为粒度进行重建,容易导致模型过多关注到像素重建这个底层任务,从而忽视了高层的一些视觉元素和视觉语义。具体来说,在BEiT中,作者引入了所谓Masked Image Modeling(MIM)的任务,一听这个名字我们就想到了BERT的Masked Language Modeling(MLM),没错这个工作就是效仿BERT的思想对图片进行自监督建模。顾名思义,如Vision Transformer一样,MIM这个任务会首先对图片进行分块(Patching),然后通过dVAE [48]对图片块进行视觉令牌化6。如Fig 2.12所示,类似MAE的做法,首先会随机对图片进行掩膜,而不同的点在于掩膜掉的图片块并不会被抛弃,而是用一个特殊的mask向量[M] e [ M ] ∈ R D e_{[M]} \in \mathbb{R}^{D} e[M]∈RD进行替代,多个图片块(包括[M])拉平到序列,表示为 x M x^{\mathcal{M}} xM,将其输入BEiT编码器,对产出的向量 { h i L } \{h_{i}^{L}\} {
hiL}进行视觉令牌的预测。这里面的 i i i是第 i i i个token输出,而 L L L表示了编码器的最后一层层数。通过多类分类器建模这块的视觉令牌预测,如式子(2-3)所示。
p M I M ( z ′ ∣ x M ) = s o f t m a x ( W c h i L + b c ) (2-3) p_{MIM}(z^{\prime}|x^{\mathcal{M}}) = \mathrm{softmax}(\mathbf{W}_c h^{L}_{i}+b_c) \tag{2-3} pMIM(z′∣xM)=softmax(WchiL+bc)(2-3)
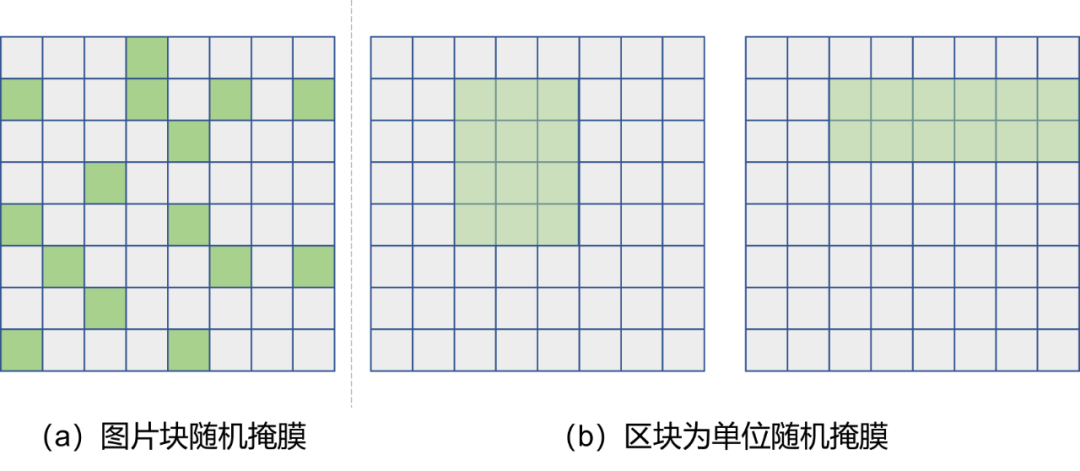
当然,这个对图片块的掩膜并不是随机选取图片块进行的,而是以“区块”(Block)为单位进行选取的,这俩的区别可见Fig 2.13所示,以区块为单位的随机掩膜在固定掩膜图片块数量一致的情况下,可以随机选取区块的长和宽,以及区块在图片中的位置,具体的细节请移步原论文。
BEiT对图片进行稀疏编码,并且通过稀疏编码后的图片块的重建,进而提高图像自监督任务的语义建模能力,这一点非常有创新性。然而遗憾的是BEiT里采用的dVAE的重建目标仍然是像素级的重建,因此其视觉令牌化后的稀疏编码高层语义能力仍可以优化。启发与此,在BEiT v2 [49]中,作者在BEiT的MIM任务基础上,尝试对稀疏令牌化这个过程也进行更为合理的建模。如Fig 2.14所示,在BEiT v2中,作者大部分参考了VQ-VAE的方法,而区别在于最后的重建目标并不是恢复图片的像素,而是对齐Teacher模型的产出。此处的Teacher模型是大型的视觉语义模型,比如CLIP [15] 或者DINO [50],其最后pooling层前的feature map可视为是具有语义特性的特征,表示为 t i \mathbf{t}_i ti,而模型输出则表示为 { o i } i = 1 N \{\mathbf{o}_i\}_{i=1}^{N} {
oi}i=1N。相较于对像素恢复通过MSE建模,此处会采用最大化 t i \mathbf{t}_i ti和 o i \mathbf{o}_i oi的余弦相似度 cos ( o i , t i ) \cos(\mathbf{o}_i, \mathbf{t}_i) cos(oi,ti)进行建模。此处的稀疏令牌是由最近邻查找字典得到的,可用公式(2-4)进行表示,而这个字典会通过梯度进行更新。作者把整个稀疏令牌的学习过程称之为vector-quantized knowledge distillation(VQ-KD),其最终的损失函数如公式(2-5)所示。不难知道,由于最近邻查找是没有梯度的,在实现的时候采用了所谓的“梯度拷贝”的方式复制了梯度,这个具体解释可见博客 [46],而公式(2-5)中的 s g [ ⋅ ] \mathrm{sg}[\cdot] sg[⋅]表示的就是stop gradient,即是停止梯度的意思。我们很容易发现VQ-KD的loss和VQ-VAE的loss其实是一模一样的,因此VQ-KD和VQ-VAE的区别,以笔者的角度来看就是引入了Teacher模型进行了语义知识的蒸馏,这也和它的取名可谓贴切了。
z i = arg min j ∣ ∣ l 2 ( h i ) − l 2 ( v i ) ∣ ∣ 2 (2-4) z_i = \arg \min_{j} ||l_2(\mathbf{h_i})-l_2(\mathbf{v}_i)||_2 \tag{2-4} zi=argjmin∣∣l2(hi)−l2(vi)∣∣2(2-4)
L V Q − K D = min ∑ x ∈ D ∑ i = 1 N − cos ( o i , t i ) + ∣ ∣ s g [ l 2 ( h i ) ] − l 2 ( v z i ) ∣ ∣ 2 2 + ∣ ∣ l 2 ( h i ) − s g [ l 2 ( v z i ) ] ∣ ∣ 2 2 (2-5) \begin{align} \mathcal{L}_{VQ-KD} &= \min \sum_{x\in \mathcal{D}} \sum_{i=1}^{N} -\cos(\mathbf{o}_i, \mathbf{t}_i)+ \\ & ||\mathrm{sg}[l_2(\mathbf{h_i})]-l_2(\mathbf{v}_{z_i})||_2^2 + ||l_2(\mathbf{h_i})-\mathrm{sg}[l_2(\mathbf{v}_{z_i})]||_2^2 \end{align} \tag{2-5} LVQ−KD=minx∈D∑i=1∑N−cos(oi,ti)+∣∣sg[l2(hi)]−l2(vzi)∣∣22+∣∣l2(hi)−sg[l2(vzi)]∣∣22(2-5)
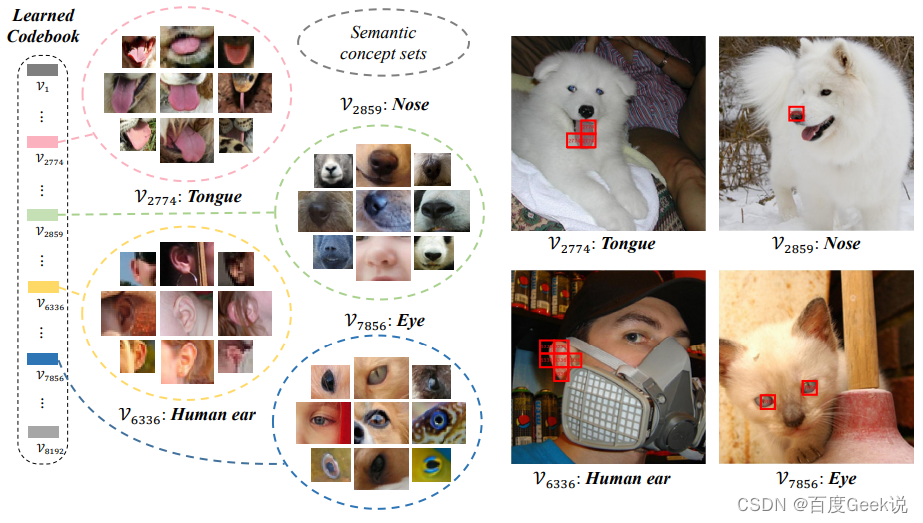
那么学习出来的字典是否符合预期,具有显著的语义特征呢?作者进行了字典的可视化分析,如Fig 2.15所示,在ImageNet valid图片集上对图片块,与训练好后的字典的每个词进行最近邻检索,就可以进行图片块的聚类。我们不难发现,这种方法确实能对同类型语义的视觉概念聚类到某个词向量中,这意味着学习出来的词具有显著的视觉语义概念。
在BEiT v2中还提出用patch aggregation策略以减少图片粒度表征和图片块表征的差异性,也即是[CLS]对应的表征和其他token对应表征的差异,而这不是本文的重点,不再赘述。
视频表征
笔者曾经在《万字长文漫谈视频理解》[1]中提到过视频的自监督建模,其中提到了一些视频建模的自监督方法,比如基于帧序列顺序的预测、基于跟踪、基于视频着色的方法。当前流行的通用视频自监督建模方法,受到了图片建模的很大启示,其产生了基于视频重建的方法,本节主要介绍这类型的方法。
videoMAE
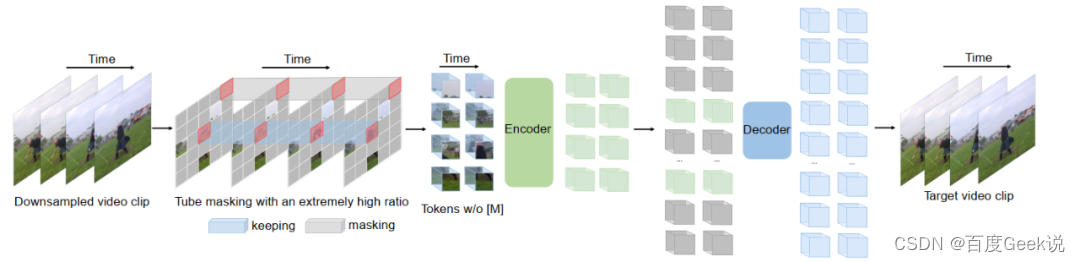
视频作为静态图片在时间域上的展开,其自监督建模受到了很多图片建模的启发,而VideoMAE [51]就是一个受到了图片MAE建模影响的工作,如Fig 2.16所示,videoMAE的流程和图片MAE对比来看是非常相似的。图片的MAE建模考虑随机对图片块进行掩膜,而视频是否也可以直接挪用这个方法呢?如Fig 2.17所示,视频中可行的掩膜方案有几种:随机帧掩膜(random frame masking)、随机图片块掩膜(random masking)、管式掩膜(tube masking)。正如之前的讨论,视频和图片都是有非常丰富信息冗余量的媒体,视频比起图片来说除了空间信息冗余度,还具有着时间上的冗余度7,这一点并不难理解,视频通常在相邻帧的变化都是缓慢的。如果和图片MAE一样采用随机图片块掩膜策略,那么在训练过程中就有可能存在信息的“在时间维度的泄漏”,而这将会导致预测当前图片块的这个目标,会倾向于通过相邻帧的信息进行填补来实现,而不是去学习其语义后进行填补,显然这并不利于模型学习视频的语义。因此本工作采用了所谓的管式掩膜(tube masking),如Fig 2.17 (d)所示,其对同个图片块的相邻帧对应的图片块也进行掩膜,从而减少模型通过“时间捷径”对缺失图片块进行填补的可能性,进而让模型优先去学习视频的语义。

BEVT
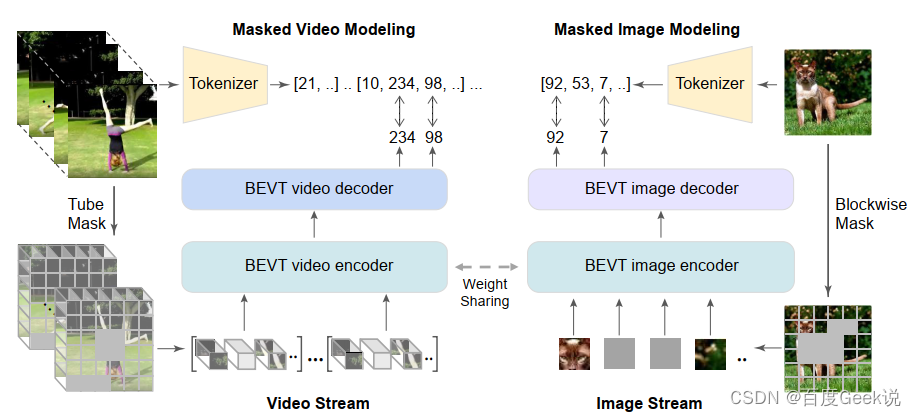
我们在上文提到过,对图片像素的重建任务容易学习出低级视觉特征,而忽略高层语义特征,因此在BEiT和BEiT v2中尝试对视觉稀疏令牌化后的视觉令牌进行重建,从而保证视觉高层语义的建模。对于视频建模而言,同样存在这个问题,因此在BEVT [55]中,作者基于BEiT系列工作的启发,尝试采用对视频块稀疏化后的令牌进行重建,而不是视频像素本身。同时,由于视频固有的时间-空间语义特性,为了更好地对视频的视觉空间特性进行建模,作者采用了视频流(Video Stream)和图片流(Image Stream)同时训练的方式进行,并且其视频编码器和图片编码器是采用权值共享(weight sharing)的。整个模型框架如Fig 2.18所示,本文不对具体技术进行介绍,有兴趣的读者请移步原论文。
文本表征
文本表征不是本文的重点,在此不进行介绍,感兴趣的同学请自行查阅文献。(其实是因为笔者太懒:P,而且笔者自知在文本建模上没有特别系统化的认识,就不班门弄斧了。)
0x03 语义标签的使用:走向多模态
以上我们分别对视觉单模态和文本单模态的自监督表征方法进行了简单介绍,相信大家对自监督建模或多或少也有所了解了。而自本章开始,终于我们将正式地踏入跨模态的地界。欢迎你,我的旅客,至此欢迎来到多模态的世界~
人类语义表达与理解过程
无疑的,我们在进入多模态的世界之前需了解什么是多模态(multiple modality)。在笔者的看法中,无论是文字还是视觉,亦或是语音,甚至于人的肢体语言等等,一切由人的肢体和器官所能用于表达人类思维中的语义与情感的手段,都可以看成是一种模态,而这些模态的组合,以及模态的信息彼此交互就可视为是多模态。如Fig 3.1所示,人类的语义表达和理解可以表达为信息编码、信息解码以及最主要的人类思维部分,人类思维我们姑且看成是黑盒子,它表示了人类的理性与思想。信息编码和信息解码,则是人类通过外部器官,如眼口鼻耳,肢体等表达自己的想法,理解他人的想法的手段。而人类群体的信息交互(包括信息编码、解码)中会对某些具象和抽象概念8达到某种程度的收敛,概念收敛的结果会以共识概念的形式,储存在人类的共识概念库中,变成普适的概念。
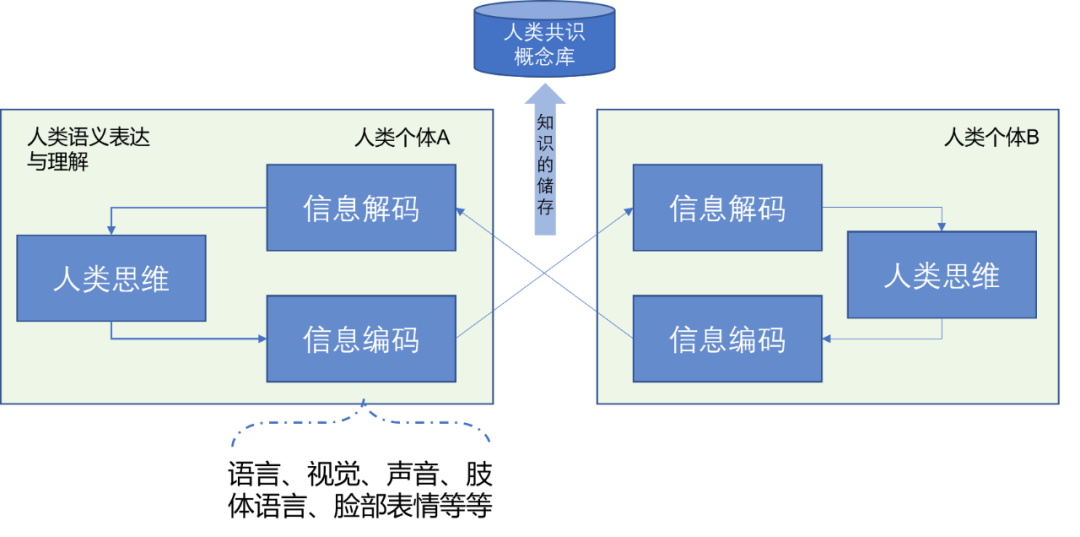
由此我们能够理解,无论是语言、图像、视频、声音、肢体动作、表情这些都是人类表达内心思维想法的手段,我们目前无法对人类最为底层的思维进行理解,因此看成为隐变量 x x x,而这些模态的表达则可以看成是显变量 z z z,信息编码表示为函数 f ( ⋅ ) f(\cdot) f(⋅),那么以视觉编码和文字编码,我们有式子(3-1)。其中 z t e x t , z v i s i o n z_{text}, z_{vision} ztext,zvision可视为是对文字表达和视觉表达的某种数值化表示(numerical Representation),我们目前常用的就是嵌入式表达(Embedding),或者称之为分布式表达(Distributed Representation),一般就是稠密的浮点表达,如 z t e x t ∈ R D z_{text} \in \mathbb{R}^{D} ztext∈RD,当然这种表达不一定是最为精准的。
z t e x t = f t e x t ( x ) z v i s i o n = f v i s i o n ( x ) (3-1) \begin{align} z_{text} &= f_{text}(x) \\ z_{vision} &= f_{vision}(x) \end{align} \tag{3-1} ztextzvision=ftext(x)=fvision(x)(3-1)
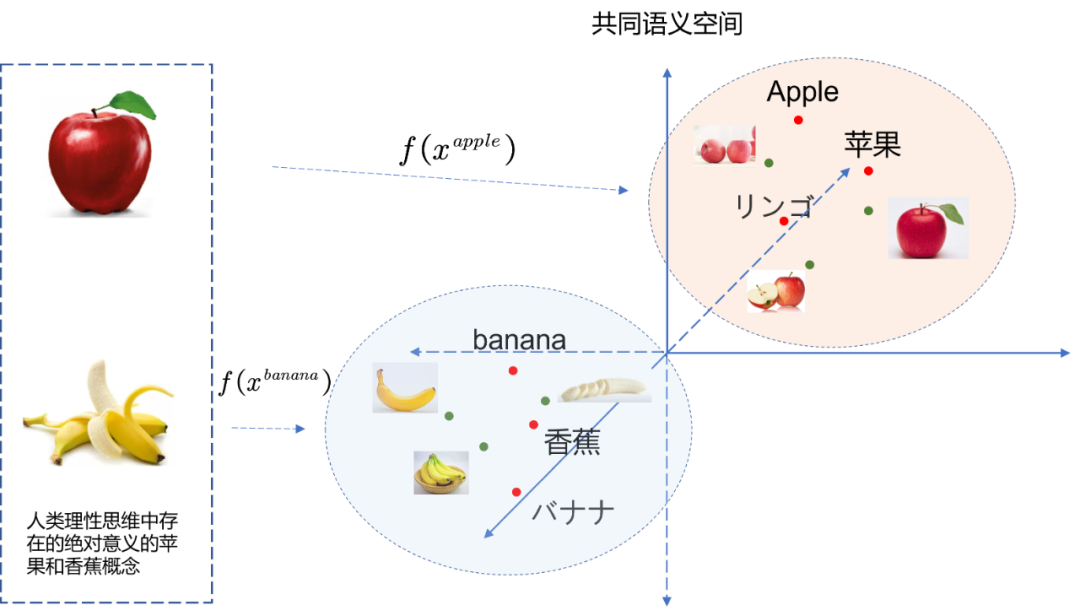
如果在人类共识中,我们对某种概念 x A x_A xA的文本和视觉表达画上了等号,那么可想而知有 f t e x t ( x A ) = f v i s i o n ( x A ) f_{text}(x_A)=f_{vision}(x_A) ftext(xA)=fvision(xA),也就有 z t e x t A = z v i s i o n A z_{text}^{A}=z_{vision}^{A} ztextA=zvisionA,如Fig 3.2所示,一旦确定了某两个跨模态的概念能够画上等号,就可以映射到共同语义空间了,这个过程也正是我们之前讨论过得的语义对齐。这种语义对齐,不仅对于文本和图像适用,对于声音、肢体语言、表情等都是适用的。
语义标签
在分类任务中,我们的标签通常是“硬标签(hard label)”,指的是对于某个样本,要不是类别A,那么就是类别B,或者类别C等等,可以简单用one-hot编码表示,比如[0,1,0], [1,0,0]等,相信做过分类任务的朋友都不陌生。以ImageNet图片分类为例子,人工进行图片类别标注的过程并不是完全准确的,人也会犯错,而且犯错几率不小。那么很可能某些图片会被标注错误,而且图片信息量巨大,其中可能出现多个物体。此时one-hot编码的类别表示就难以进行完整的样本描述。我们这个时候就会认识到,原来标注是对样本进行描述,而描述存在粒度的粗细问题。one-hot编码的标签可以认为是粒度最为粗糙的一种,如果图片中出现多个物体,而我们都对其进行标注,形成multi-hot编码的标签,如[0,1,1]等,那么此时粒度无疑更为精细了,如果我们对物体在图片中的位置进行标注,形成包围盒(bounding box,bbox),那么无疑粒度又进一步精细了。
也就是说,对于标注,我们会考虑两个维度:1)标注信息量是否足够,2)标注粒度是否足够精细。然而,对于一般的xxx-hot标签而言,除了标注其类别,是不具有其他语义(semantic)信息的,也就是说,我们很难知道类别A和类别B之间的区别,类别C与类别B之间的区别。因为人类压根没有告诉他,如Fig 3.3 (a) 所示,基于one-hot标签的类别分类任务,每个标签可以视为是笛卡尔坐标系中彼此正交的轴上的基底,这意味着每个类别之间的欧式距离是一致的,也就是说,模型认为猫,狗,香蕉都是等价的类别,但是显然,猫和狗都属于动物,而香蕉属于植物。基于one-hot标注,模型无法告诉我们这一点。
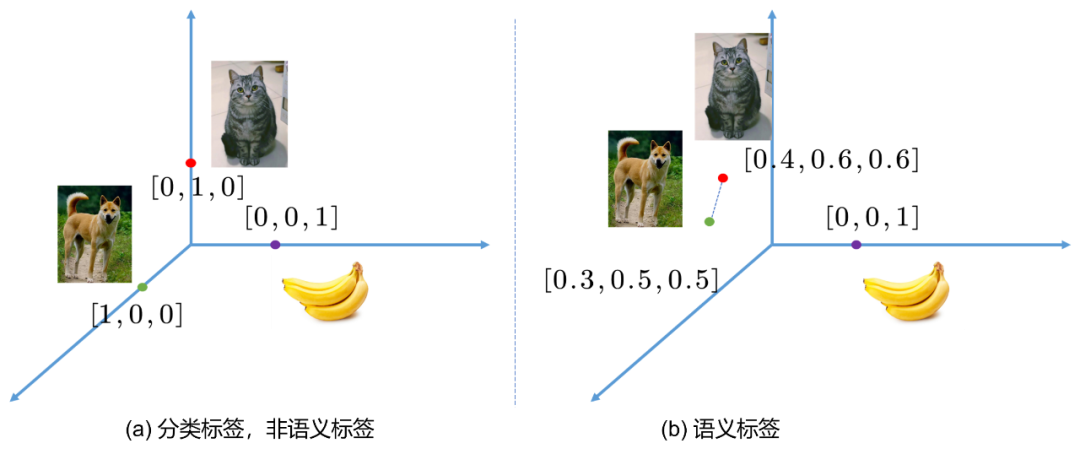
也就是说,猫和狗,相比于香蕉,有着更为接近的语义,也许Fig 3.3 (b)会是个更好的选择。如果我们的标签不再是one-hot的,而是所谓的语义标签,或者在NLP领域称之为分布式标签(Distributing label, Distributing vector)或者嵌入标签(embedding label, embedding vector),那么类别标签之间的欧式距离就可以描述类别之间的相似程度,这个可视为是简单的语义信息,然而很多高层语义信息都依赖于此。
获取语义标签难以依靠于人工标注,因为人的语义标注有以下固有缺陷:
- 人类无法很好客观地描述每个视觉语义之间的相似程度。
- 视觉语义概念数不胜数,人类难以对所有概念进行标注。
- 语义是人类的群体共识,而个体的标注很容易引入个体偏见。
因此,更为可行的方法是采用自监督的方法学习模态内部/模态之间的固有结构,我们知道一个类别称之为“狗”,另一个类别称之为“猫”,还有一个类别是“香蕉”,我们通过word embedding的方法,可以得到每个类别描述的词向量,因为词向量是基于共现矩阵或者上下文局部性原理得到的,因此大概率语义相关的类别会具有类似的词向量,从而实现语义标签的生成。
当然,这种语义标签只能表达粗糙的,低层次的语义信息,比如类别之间的相似程度。如果涉及到更高层的语义呢?比如Video QA场景中,给定一个图片,我们基于图片给出一个问题,然后期望模型回答问题;比如Image Caption,给定图片,然后模型需要尝试用语言对图片进行描述。这些任务都是需要很高层次的语义标注才能实现的。通常来说,此时人工标注能做到的就是给定一个图片,让多个人以相近的标准去进行描述,然后形成图文对<image, text#1, text#2...text#n>,让模型进行学习。当然这种需要大量人力进行标注的工作量惊人,因此更好的方式是在互联网挖掘海量的无标签带噪信息,比如网页中图片的上下文可以认为是相关的,比如朋友圈,微博的图文评论等,这些带有噪声,但是又具有相关性的海量数据也是可以挖掘的。
当然,高层语义信息也依赖于底层语义的可靠,诸如目前很多transformer在多模态的应用,如ViLBERT [53],ERNIE-ViL [54]等,都依赖与词向量的可靠,然后才谈得上高层语义的可靠。从这个角度来看,其实从底层语义,底层CV&NLP任务到高层语义多模态任务,其实是有一脉相承的逻辑在的。
多模态模型需要语义标签数据
什么叫做多模态呢?我们之前已经谈到过了,无非是对于同一个概念,同一个事物通过不同的模态进行描述,常见的如用图片、视频、语言、语音对某一个场景进行描述,这就是多模态的一个例子。多模态目前是一个很火的研究方向,目前视频语义复杂,特别是在搜索推荐系统中,可能包含有各种种类的视频,光从动作语义上很难进行描述。如果扩充到其他更广阔的语义,则需要更加精细的标注才能实现。通常而言,动作分类的类别标注就过于粗糙了。
考虑到搜索推荐系统中广泛存在的长尾现象,进行事无巨细的样本标注工作显然是不可取的,再回想到我们上一节中谈到的“语义标签”的概念,即便有足够的人力进行标注,如何进行合适的样本标注设计也是一件复杂的问题。对于一张图(亦或是一个视频),单纯给予一个动作标签不足以描述整个样本的语义,额外对样本中的每个物体的位置,种类进行标注,对每个样本发生的事情进行文本描述,对样本的场景,环境进行描述,这些都是可以采取的进一步的标注方式。
怎么样的语义标签才是合适的呢?就目前而言,据笔者了解,在预训练阶段,为了保证预训练结果能够在下游任务中有效地泛化,不能对预训练的语义进行狭义的约束,比如 仅 用动作类别语义进行约束就是一个狭义约束。为了使得标注有着更为通用的语义信息,目前很多采用的是多模态融合的方法。
在多模态融合方法中,以图片为例子,可以考虑用一句话去描述一张图中的元素和内容(此处的描述语句可以是人工标注的,也可以是通过网络的海量资源中自动收集得到的,比如用户对自己上传图片的评论,网页图片上下文,描述甚至是弹幕等),比如在ERNIE-VIL [16]中采用的预训练数据集Conceptual Captions (CC) dataset [6],其标注后的样本如Fig 3.2所示。其中的虚线框是笔者添加的,我们注意到左上角的样本,其标注信息是"Trees in a winter snowstorm",通过这简单一个文本,伴随配对的图片,我们可以知道很多信息:
- 在暴风雪下,天气以白色为主。
- 树的形状和模样,一般是直立在土地上的。
- 暴风雪时候,能见度很低。
如果数据集中还有些关于树木的场景的描述文本,比如“Two boys play on the tree”, 那么模型就很有可能联合这些样本,学习到“树(tree)”这个概念,即便没有人类标注的包围盒标签(bounding box label)都可以学习出来,除此之外因为语义标签的通用性,还提供了学习到其他关于暴风雪概念的可能性。通过这种手段,可以一定程度上缓解长尾问题导致的标签标注压力。并且因为文本的嵌入特征具有语义属性,意味着文本标签可以对相近语义的表述(近义词,同义词等等)进行兼容,进一步提高了模型的通用性,这些都是多模态融合模型的特点。
综上所述,笔者认为,多模态融合模型具有以下优点:
- 对标注的精准性要求更低,可以通过人类直观的看图说话的方式进行标注。
- 可以通过互联网大量收集弱标注的图片描述数据,如图片评论,弹幕,用户的自我描述等。
- 语义更为通用,可作为预训练模型供多种下游任务使用。
- 可以缓解长尾问题,对语义相近的场景更为友好。
因此,笔者认为,在当前互联网弱标注数据海量存在的时代,算力大大增强的时代,在跨模态的视频,图片搜索推荐这些应用中,采用多模态融合的方法是势在必行的,是现在和未来的方向。我们后面的系列文章将会对这些方法进行简单的介绍。

0x04 CLIP之前:多模信息的融合建模
笔者前文带领读者了解了一些单模态建模、多模态数据采集等前置知识,本文将带领大家开始正式地接触多模态模型。笔者认为,发表于ICML 2021的对比图文预训练模型(CLIP)可以作为一个分界线,在此之前和在此之后的多模态研究工作有着截然不同的研究范式,其惊艳的zero-shot和few-shot能力进一步引燃了研究者对多模态研究的热情。
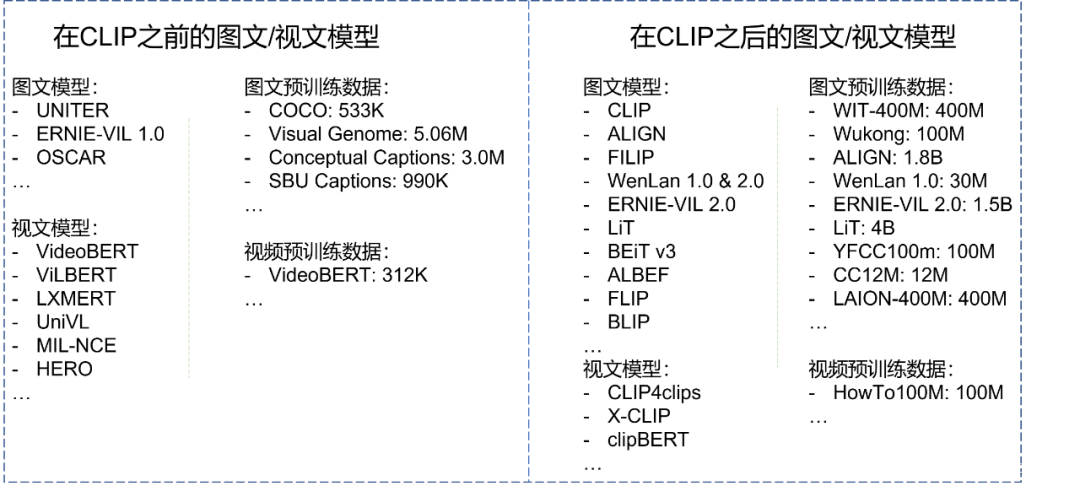
本章不会对CLIP进行细致的介绍,而会把这个荣耀留在第0x05章,届时CLIP将浓墨重彩的登场。抛开CLIP的细节,我们首先对比在CLIP前后的主要多模态模型和所采用的预训练数据集,如Fig 5.1所示,我们发现在CLIP之前的预训练数据都较小,数量级以“百万”为单位,而在CLIP之后呢,预训练数据的大小直接膨胀到了以“十亿、亿”为单位,为什么会存在如此大的数量级差别呢?我们在后文将会揭晓谜底。显然,在CLIP之后的多模态模型才是我们本文的重中之重,但是还请读者大人们耐心,我们在本章还是会介绍一两个在CLIP之前的多模态模型,因其能给我们一些非常有价值的启示。那么,先生们女生们,这边请~
图文模型
UNITER
通用图文表征学习(Universal Image-Text representation learning, UNITER)[57],笔者介绍该工作的原因,在于该工作引入了好几种图文语义融合的损失,而这些损失的优势、缺陷将带给我们启示。UNITER的模型框架如Fig 5.2所示,其输入的数据是一对配对的图文对,模型首先采用Faster RCNN网络对图片进行物体检测,将其中的物体特征(feature proposal)提取出,并作为上层语义融合模型的输入。对于文本端,则采用文本令牌化(Text tokenization)将文本转化为word embedding,同样作为Transformer的输入。此时Transformer的输入分为两大类,图片信息和文本信息。
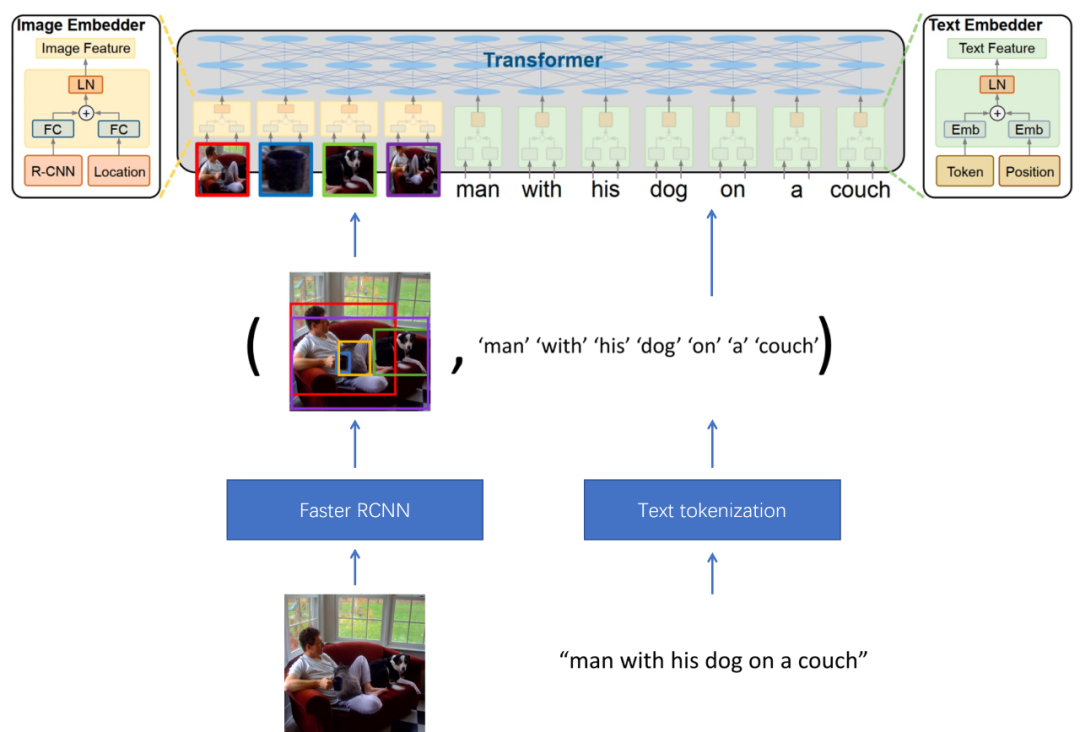
既然笔者认为UNITER中最重要的是多模态语义融合建模方式,那么主要介绍下在这篇文章中采用的loss。如Fig 5.3所示,UNITER主要采用的损失有:
且让我们进行统一的数学形式表示,用 v = { v 1 , ⋯ , v K } \mathbf{v}=\{v_1,\cdots,v_K\} v={ v1,⋯,vK}表示 K K K个图片区域的特征, w = { w 1 , ⋯ , w T } \mathbf{w}=\{w_1,\cdots,w_T\} w={ w1,⋯,wT}表示 T T T个文本令牌,用 m ∈ N M \mathbf{m}\in \mathbb{N}^{M} m∈NM表示被掩膜的索引。
-
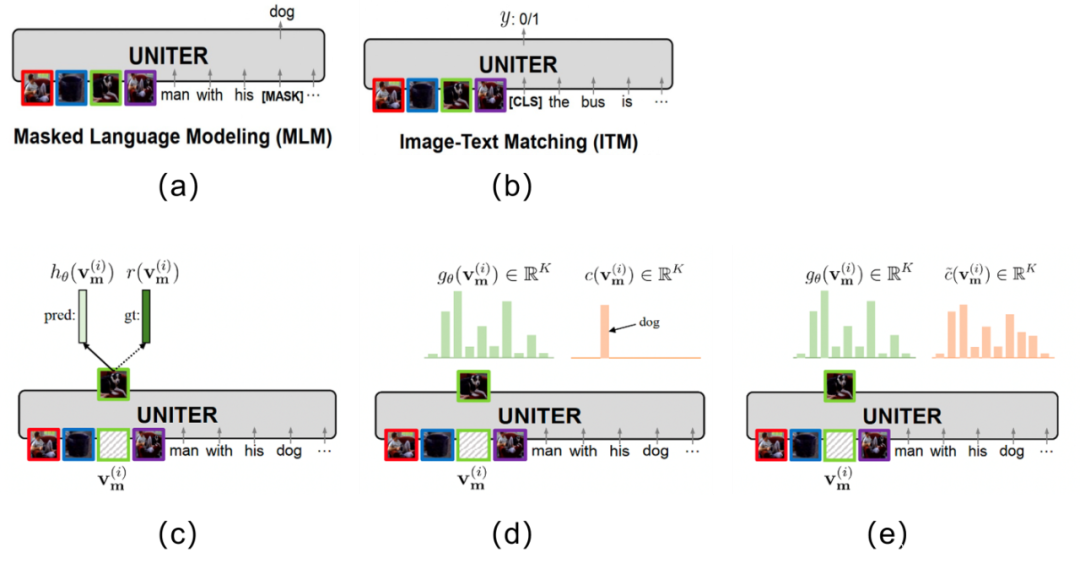
Masked Language Modeling(MLM):这个损失如Fig 5.3 (a)所示,其思想就是随机掩膜住文本令牌,尝试通过图片信息和剩余的文本信息对该掩膜掉的文本进行预测。损失如(5-1)所示,其中的 w / m \mathbf{w}_{/ \mathbf{m}} w/m表示去掉了由 m \mathbf{m} m所表示的索引的文本后的剩余文本令牌。
L M L M ( θ ) = − E ( w , v ) ∼ D log P θ ( w m ∣ w / m , v ) (5-1) \mathcal{L}_{MLM}(\theta) = -E_{(\mathbf{w}, \mathbf{v}) \sim D} \log P_{\theta}(\mathbf{w}_{\mathbf{m}}|\mathbf{w}_{/ \mathbf{m}},\mathbf{v}) \tag{5-1} LMLM(θ)=−E(w,v)∼DlogPθ(wm∣w/m,v)(5-1) -
Image-Text Matching (ITM): 这个损失如Fig 5.3 (b)所示,其思想是通过构造图片匹配的正样本和图文不匹配的负样本,设计出0/1匹配任务,进行语义融合的学习,损失如(5-2)所示。
L I T M ( θ ) = − E ( w , v ) ∼ D [ y log s θ ( w , v ) + ( 1 − y ) log ( 1 − s θ ( w , v ) ) ] (5-2) \mathcal{L}_{ITM}(\theta) = -E_{(\mathbf{w}, \mathbf{v})\sim D}[y\log s_{\theta}(\mathbf{w}, \mathbf{v})+(1-y)\log(1-s_{\theta}(\mathbf{w}, \mathbf{v})) ] \tag{5-2} LITM(θ)=−E(w,v)∼D[ylogsθ(w,v)+(1−y)log(1−sθ(w,v))](5-2) -
Masked Region Modeling—Masked Region Feature Regression (MRFR): 该损失如Fig 5.3 ©所示,公式如(5-3)所示,其思想是随机对图片块进行掩膜,通过尚未掩膜的图片和文本尝试对其进行预测,其中的ground truth为 r ( v m ( i ) ) r(\mathbf{v}_{\mathbf{m}}^{(i)}) r(vm(i)) ,是该掩膜掉的图片块的Faster RCNN对应的输出特征。
f θ ( v m ∣ v / m , w ) = ∑ i = 1 M ∣ ∣ h θ ( v m ( i ) ) − r ( v m ( i ) ) ∣ ∣ 2 2 (5-3) f_{\theta}(\mathbf{v}_{\mathbf{m}}|\mathbf{v}_{/ \mathbf{m}}, \mathbf{w}) = \sum_{i=1}^{M} ||h_{\theta}(\mathbf{v}_{\mathbf{m}}^{(i)}) - r(\mathbf{v}_{\mathbf{m}}^{(i)})||_{2}^{2} \tag{5-3} fθ(vm∣v/m,w)=i=1∑M∣∣hθ(vm(i))−r(vm(i))∣∣22(5-3) -
Masked Region Modeling-Masked Region Classification (MRC): 该损失和3类似,同样是MRM建模,但是其恢复目标不再是特征,而是掩膜目标的类别,如Fig 5.3 (d)和公式(5-4)所示 ,因此通过交叉熵损失进行建模。
f θ ( v m ∣ v / m , w ) = ∑ i = 1 M C E ( c ( v m ( i ) ) , g θ ( v m ( i ) ) ) (5-4) f_{\theta}(\mathbf{v}_{\mathbf{m}}|\mathbf{v}_{/ \mathbf{m}}, \mathbf{w}) = \sum_{i=1}^{M} \mathrm{CE}(c(\mathbf{v}_{\mathbf{m}}^{(i)}), g_{\theta}(\mathbf{v}_{\mathbf{m}}^{(i)})) \tag{5-4} fθ(vm∣v/m,w)=i=1∑MCE(c(vm(i)),gθ(vm(i)))(5-4)
- Masked Region Modeling-Masked Region Classification - KL Divergence (MRC-kl): 该损失和4类似,但是分类目的不再是类别,而是其类别的概率分布,因此通过KL散度进行损失建模。
f θ ( v m ∣ v / m , w ) = ∑ i = 1 M D K L ( c ~ ( v m ( i ) ) ∣ ∣ g θ ( v m ( i ) ) ) (5-5) f_{\theta}(\mathbf{v}_{\mathbf{m}}|\mathbf{v}_{/ \mathbf{m}}, \mathbf{w}) = \sum_{i=1}^{M} D_{KL} (\tilde{c}(\mathbf{v}_{\mathbf{m}}^{(i)})||g_{\theta}(\mathbf{v}_{\mathbf{m}}^{(i)})) \tag{5-5} fθ(vm∣v/m,w)=i=1∑MDKL(c~(vm(i))∣∣gθ(vm(i)))(5-5)
对于ITM而言,情况可能要好一些,由于ITM是以图片的粒度去判断图-文是否匹配,因此在理想情况下,一次能对图片中所有出现过的视觉概念进行对齐。但即便如此,也同样是不够高效的,我们在下一章将会介绍到对比损失,而对比损失以另一种角度,提供了一种高效得多的语义对齐建模方法。但是ITM和MLM难道是截然没有优点?那倒也不尽然,ITM和MLM的建模方式具有“组合”特性,允许图文之间进行充分的信息交互,因此对于语义融合而言是一种更为合适的建模方式。我们通过Fig 5.4观察下UNITER的消融试验结果,我们只关注MLM和ITM相关的试验结果(即是虚红线框出部分),我们注意到ITM试验结果优于MLM,而ITM+MLM的方式又优于前两者单独的结果。这一点正如我们刚才分析的,并不难以理解,ITM以图片为粒度进行语义对齐建模,效率比MLM更高,而ITM+MLM则能在获取更好语义对齐能力的同时,附带语义融合能力。
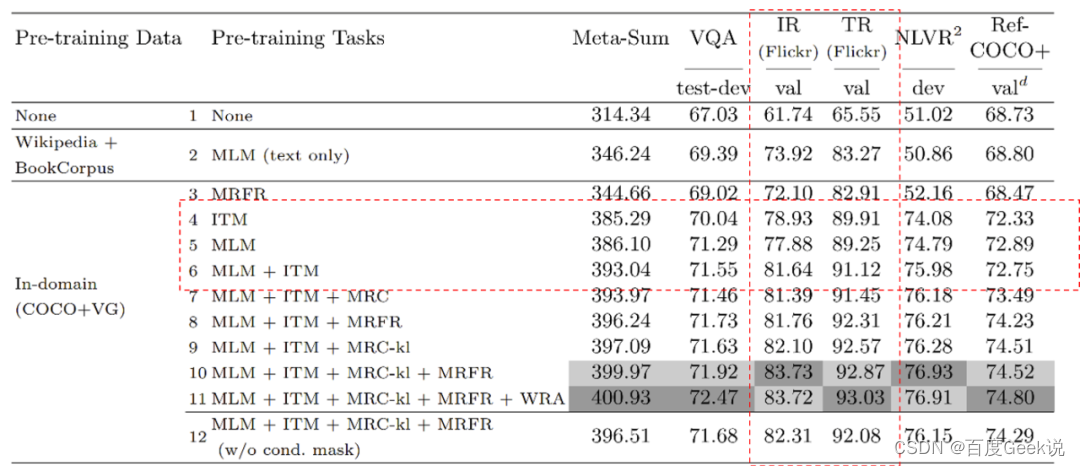
我们能从UNITER的建模和试验中得到那些有价值的结论呢?首先,无论是ITM还是MLM都不是一种理想的语义对齐建模方式,而正如我们第0x00章所分析的,有效的语义对齐是语义融合的前提,直接跳过语义对齐去建模语义融合是不合理的。其次,采用MLM和ITM则强依赖于数据的“干净”,由于ITM和MLM建模方式强假设图片或文本中掩膜掉的内容,可以通过跨模态信息进行恢复,因此图文数据必须是能够匹配且互补的!这一点意味着我们的数据要足够干净,而不能大范围采用来自于互联网的带噪声数据,这也就解释了为什么CLIP前的工作所能采用的预训练数据都只有百万级别,那就是因为干净的标注数据太贵,需要人工进行标注或者确认。这些缺陷,在CLIP之后的工作中或多或少都能得到缓解,真是让人心潮澎湃~
视文模型
VideoBERT
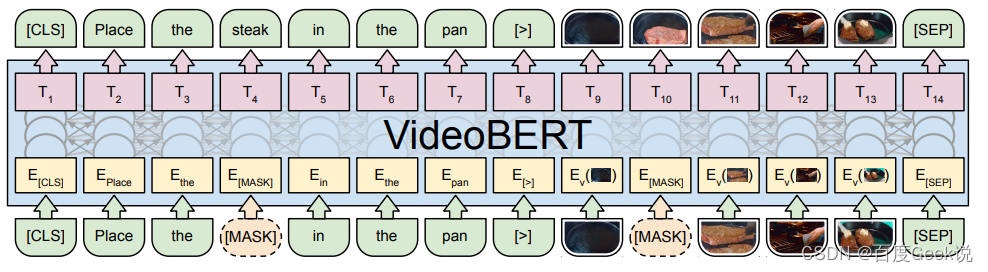
本文不会介绍太多来自于CLIP之前的多模态模型工作,对于视文模型,笔者再补充一个videoBERT [42]。videoBERT也是采用Transformer模型对文本和视觉信息进行建模,只不过此处视觉输入并不是稠密向量了,而是尝试对视觉信息进行令牌化。作为一种早期的视觉令牌化尝试,此处采用的视觉令牌是通过层次K-means聚类得到的聚类中心。对比我们提到的BEiT系列方法或者是VQ-VAE方法,这种通过聚类得到视觉令牌的做法太过于简单了些,并且很难进行规模化,理想点的方式应该是通过维护稀疏视觉词表,通过最近邻查表得到稀疏令牌,如同VQ-VAE一般。
videoBERT给我们的启发主要是,视频信息是一种信息冗余度极高的数据形式,对其进行语义令牌化不仅可以大幅度节省模型的资源需求,而且可以着重于建模语义。同时,如同我们后续会介绍到的BEiT v3中提到的,通过视觉稀疏令牌化的形式进行多模态建模,会使得很多之前难以做到的多模态预训练变得可行。
0x05 CLIP之后:多模信息的对比、融合建模
千呼万唤始出来,犹抱琵琶半遮面,终于,终于我们的CLIP在本章出现了!我们在第0x04章已经初识了CLIP之前的模型,也认识到了他们所固有的一些缺陷,而这些缺陷在CLIP出来之后或多或少得到了缓解,那我们直接步入正题吧。
图文模型
CLIP
对比图文预训练(Contrastive Language-Image Pretraining, CLIP)[15] 是一个具有划时代意义的工作,在CLIP推出后,多模态的研究范式产生了巨大的变革,因此本文的行文线索将CLIP作为一个分界点,而本章则是对CLIP之后的工作进行介绍。既然要介绍CLIP之后的工作,那么CLIP本身就不可避免要大书特书了,我们本节会对CLIP进行介绍。
CLIP的模型结构本身并没有特别多值得注意的地方,其采用的是经典的双塔结构,对于图片域和文本域有着不同的图片编码器(Image Encoder)和文本编码器(Text Encoder)。其中文本编码器采用了经典的Transformer结构,而图片编码器则采用了两种:第一种是改进后的ResNet,作者选择用基于注意力的池化层去替代ResNet的全局池化层,此处的注意力机制同样是与Transformer类似的多头QKV注意力;作者同样采用ViT结构作为第二种图片编码器进行实验。本文用 f T e x t ( ⋅ ) f_{\mathrm{Text}}(\cdot) fText(⋅)表示文本编码器, f I m g ( ⋅ ) f_{\mathrm{Img}}(\cdot) fImg(⋅)表示图片编码器, x I m g ∈ R N × H × W × C \mathbf{x}_{Img} \in \mathbb{R}^{N \times H \times W \times C} xImg∈RN×H×W×C表示一个batch的图片,而 x T e x t ∈ R N × S \mathbf{x}_{\mathrm{Text}} \in \mathbb{R}^{N \times S} xText∈RN×S表示一个batch的文本,那么有:
f i m g = f I m g ( x I m g ) ∈ R N × D i f t e x t = f T e x t ( x T e x t ) ∈ R N × D t (6-1) \begin{aligned} \mathbf{f}_{\mathrm{img}} &= f_{\mathrm{Img}}(\mathbf{x}_{Img}) \in \mathbb{R}^{N \times D_{i}} \\ \mathbf{f}_{\mathrm{text}} &= f_{\mathrm{Text}}(\mathbf{x}_{Text}) \in \mathbb{R}^{N \times D_{t}} \end{aligned} \tag{6-1} fimgftext=fImg(xImg)∈RN×Di=fText(xText)∈RN×Dt(6-1)
通过线性映射层将图片特征 f i m g \mathbf{f}_{\mathrm{img}} fimg和文本特征 f t e x t \mathbf{f}_{\mathrm{text}} ftext都映射到相同的嵌入特征维度 D e D_{e} De,那么有:
f i m g e = f i m g W i m g ∈ R N × D e f t e x t e = f t e x t W t e x t ∈ R N × D e (6-2) \begin{aligned} \mathbf{f}_{\mathrm{img}}^{e} &= \mathbf{f}_{\mathrm{img}} \mathbf{W}_{\mathrm{img}} \in \mathbb{R}^{N \times D_{e}} \\ \mathbf{f}_{\mathrm{text}}^{e} &= \mathbf{f}_{\mathrm{text}} \mathbf{W}_{\mathrm{text}} \in \mathbb{R}^{N \times D_{e}} \end{aligned} \tag{6-2} fimgeftexte=fimgWimg∈RN×De=ftextWtext∈RN×De(6-2)
为了保证图文两个模态的数值尺度的一致性,对其进行L2标准化,如(6-3)所示,这一点我们在上文也曾经介绍过。
G L 2 ( x ) = x i ∑ i D x i 2 (6-3) G_{L2}(\mathbf{x}) = \dfrac{\mathbf{x}_i}{\sqrt{\sum_{i}^{D}\mathbf{x}_i^2}} \tag{6-3} GL2(x)=∑iDxi2xi(6-3)
综合起来,也就有
f i m g n o r m = G L 2 ( f i m g ) f t e x t n o r m = G L 2 ( f t e x t ) (6-4) \begin{aligned} \mathbf{f}^{\mathrm{norm}}_{\mathrm{img}} &= G_{L2}(\mathbf{f}_{\mathrm{img}}) \\ \mathbf{f}^{\mathrm{norm}}_{\mathrm{text}} &= G_{L2}(\mathbf{f}_{\mathrm{text}}) \end{aligned} \tag{6-4} fimgnormftextnorm=GL2(fimg)=GL2(ftext)(6-4)
此时如Fig 6.1所示,对图片嵌入特征和文本嵌入特征进行矩阵相乘。那么形成的打分矩阵上,对角线上都是配对的正样本对打分,而矩阵的其他元素,则是由同个batch内的图片和不配对的文本(相反亦然)组成的负样本。这种策略可以形成 N 2 − N N^2-N N2−N个负样本。整个过程可以用公式(6-5)描述。
M = ( f i m g n o r m ) ( f t e x t n o r m ) T ∈ R N × N (6-5) \mathbf{M} = (\mathbf{f}^{\mathrm{norm}}_{\mathrm{img}}) (\mathbf{f}^{\mathrm{norm}}_{\mathrm{text}})^{\mathrm{T}} \in \mathbb{R}^{N \times N} \tag{6-5} M=(fimgnorm)(ftextnorm)T∈RN×N(6-5)
而后只需要对 M \mathbf{M} M的每一行和每一列求交叉熵损失(分别记为I2T loss和T2I loss),并且加和起来即形成了总损失了。如式子(6-6)所示,此处的交叉熵损失带上了温度系数 τ \tau τ,这能有效地缓解在超大batch size情况下的学习收敛问题,具体见[29],式子中的 q ⋅ k + q \cdot k_{+} q⋅k+表示正样本打分,而 q ⋅ k i q \cdot k_{i} q⋅ki表示当前batch下所有样本打分。其中每一行可以视为是同个图片,与同个batch内其他所有样本对的文本进行组合构成的负样本对形成的损失,而每一列自然就是同个文本,对于每个图片进行组合而构成的损失了。整个过程如下面的伪代码所示。
L q = − log exp ( q ⋅ k + / τ ) ∑ i = 0 N exp ( q ⋅ k i / τ ) (6-6) \mathcal{L}_{q} = -\log \dfrac{\exp(q \cdot k_{+} /\tau)}{\sum_{i=0}^{N} \exp(q \cdot k_{i} / \tau)} \tag{6-6} Lq=−log∑i=0Nexp(q⋅ki/τ)exp(q⋅k+/τ)(6-6)
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
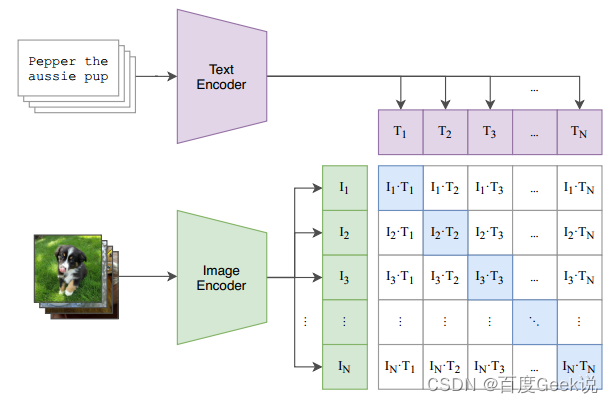
CLIP的模型结构和正负样本组成策略并不复杂,其负样本构成方式是经典的batch negative方式,也即是从batch内部去构成负样本,而CLIP的贡献点在于能够采用海量的来自于互联网的图文对数据(约4亿条图文对)和超大batch size(约32000)进行预训练,并且为了能够充分学习,采用了大容量的模型结构。为何CLIP的这种“朴素”学习方式可以有效进行语义对齐呢?如Fig 6.2所示,在一次对比中,正样本可以和海量的负样本进行对比,这种对比有两种维度:
- 图-文对比:一个图片对应有一个匹配的文本(正样本),和 N − 1 N-1 N−1个不匹配的文本(负样本),此时一次正负样本对比,可以充分地厘清不同文本中的视觉语义对齐。如Fig 6.2中,以第一行视为正样本,那么对于文本中的“幼犬、小狗、小狗宝宝”都是与正样本图片相符的,而其负样本文本“小猫”则和正样本图片不负。因此一次性就厘清了“小狗,幼犬”和“小猫”的语义差别,如果我们的负样本足够大,那么就能够在一次迭代过程中,厘清非常多的文本中的视觉概念,而这是MLM和ITM不能做到的。
- 文-图对比:和图-文对比类似,一个文本对应有一个匹配的图片(正样本),和 N − 1 N-1 N−1个不匹配的图片(负样本),同样一次正负样本的对比,可以厘清不同图片之间的视觉语义对齐。同样以第一行为正样本,那么文本中的"幼犬、小狗、小狗宝宝"等字样只和第一行图片匹配,和其他图片并不能有效匹配,因此能一次性厘清非常多图片中的视觉概念。
由此分析我们不难知道,CLIP的对比学习建模方式和上文介绍到的ITM和MLM方式的本质不同,在CLIP中通过扩大负样本数量,可以以非常高的效率提高语义对齐的能力,而由于采用了双塔结构,模型只需要对 N N N个图片和 N N N个文本进行特征向量计算,最后汇聚起来后进行打分矩阵的计算,如Fig 6.1所示,这个模型计算复杂度是 O ( N ) \mathcal{O}(N) O(N)的,而如果需要通过类似ITM的方式实现类似的对比,由于单塔交互模型的限制, 那么模型计算复杂度将会飙升到 O ( N 2 ) \mathcal{O}(N^2) O(N2),这是不能接受的。同样以图片为粒度进行语义对齐的ITM损失尚不能比肩其效率,以视觉块为粒度建模的MLM就更不用说了。

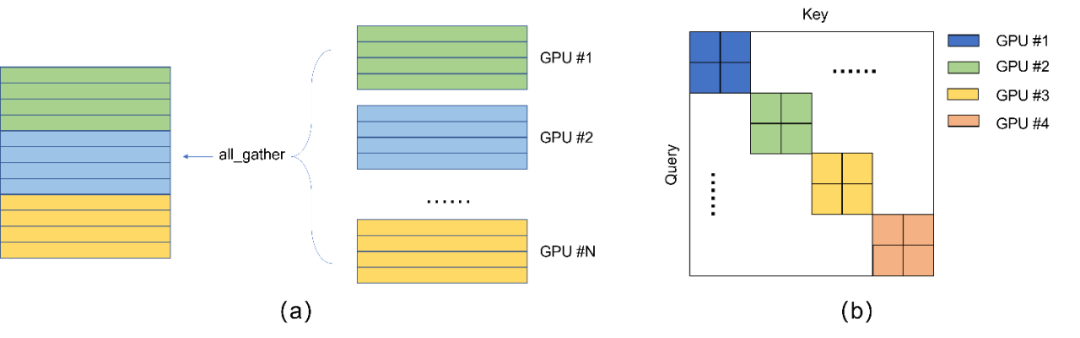
由上文的分析不难知道,CLIP的高效语义对齐能力依赖于超大的负样本数量,而负样本数量则耦合与batch size的大小,在CLIP中通过框架的分布式通信能力all_gather实现,我们本文进行简单介绍。all_gather可以对来自于不同GPU上的向量进行汇聚,具体介绍可见 torch.distributed.all_gather[58],注意到这个过程是不会传播不同GPU上的梯度的,梯度只能来自于本机,具体介绍见 [59]。整个过程如Fig 6.3 (a)所示,all_gather会汇聚来自于不同GPU上的向量,假设每个GPU上的batch size大小为 N N N,一共有 K K K个GPU,那么汇聚后的batch size大小可视为 K N KN KN。但是注意到,由于all_gather机制本身并不传递梯度,因此除了本机的 N N N个样本存在梯度外,其他 ( K − 1 ) N (K-1)N (K−1)N个样本只能视为是常数参与对比,如Fig 6.3 (b)所示,只有对角线上的区块的样本是具有梯度的,而这些样本都是各个GPU上的本机向量。
CLIP的贡献点除了超大batch size的应用外,另外是采用了海量的互联网带噪图文数据,而不是人工精心标注的数据,我们得了解其是如何进行数据采集的。作者在英语维基百科上采集了50万个基础词,这些词都是出现过起码100次的高频词汇,同时在互联网尽可能地采集了大量的图文对数据,通过判断文本中的词汇是否在这50万基础词中进行数据的筛选,同时进行了数据的平衡,使得每个基础词上大概有2万个图文对。最终收集得到了4亿个图文对。我们不难发现这个过程由于对基础词的频次进行了筛选,因此都是一些高频的视觉概念才得以收集。
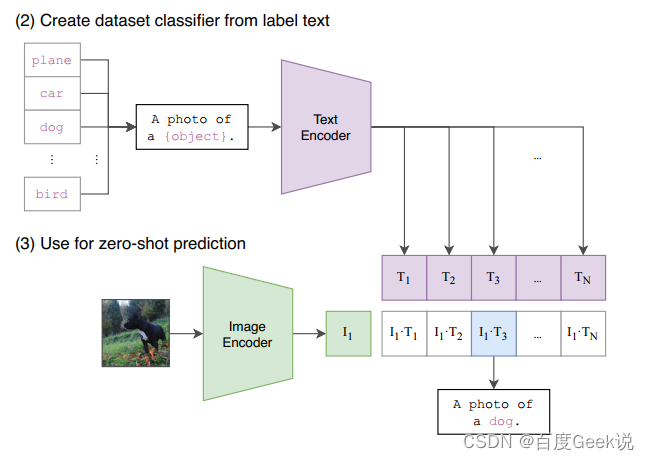
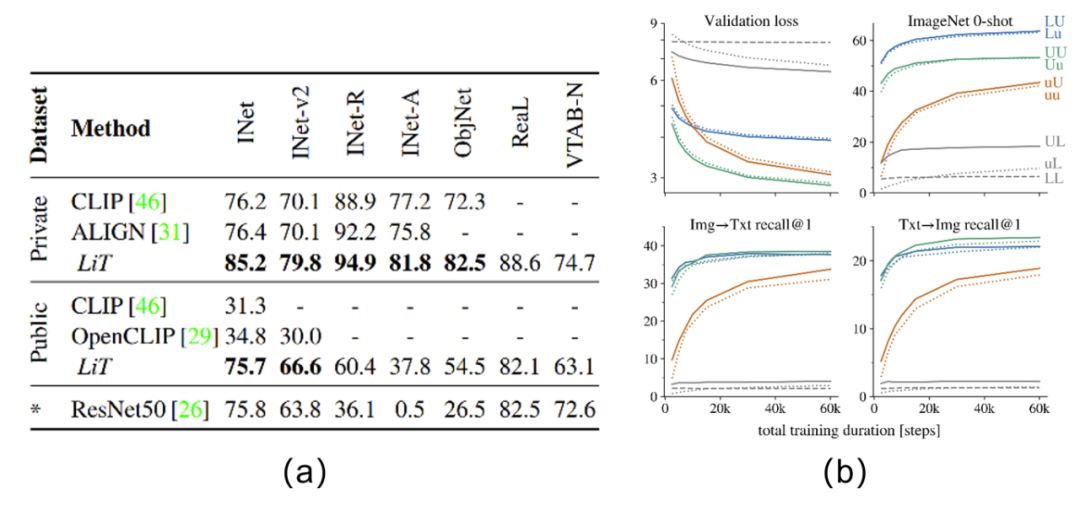
对于笔者而言,CLIP最为震撼的是其zero-shot能力和few-shot能力,其zero-shot性能甚至在某些场景能超越监督训练后的resnet50,真是让人震惊。而且,对于搜索场景而言,本身就容易受到长尾分布的影响,海量样本无法通过人工进行细致标注,强大的zero-shot和few-shot能力在搜索场景中将发挥重要的作用。我们进一步观察CLIP是如何去进行zero-shot任务的。如Fig 6.4所示,考虑到大部分的数据集的标签都是以单词的形式存在的,比如“bird”,“cat”等等,然而在预训练阶段的文本描述大多都是某个短句,为了填补这种数据分布上的差别,作者考虑用“指示上下文”(guide context)对标签进行扩展9。以Fig 6.4为例子,可以用a photo of a <LABEL>.作为文本端的输入,其中的<LABEL>恰恰是需要预测的zero-shot标签。在预测阶段,以分类任务为例子,对所有可能的分类类别文本对<LABEL>进行替代,得到一个CLIP的图文打分,然后将其中最高打分作为最终的预测类别。
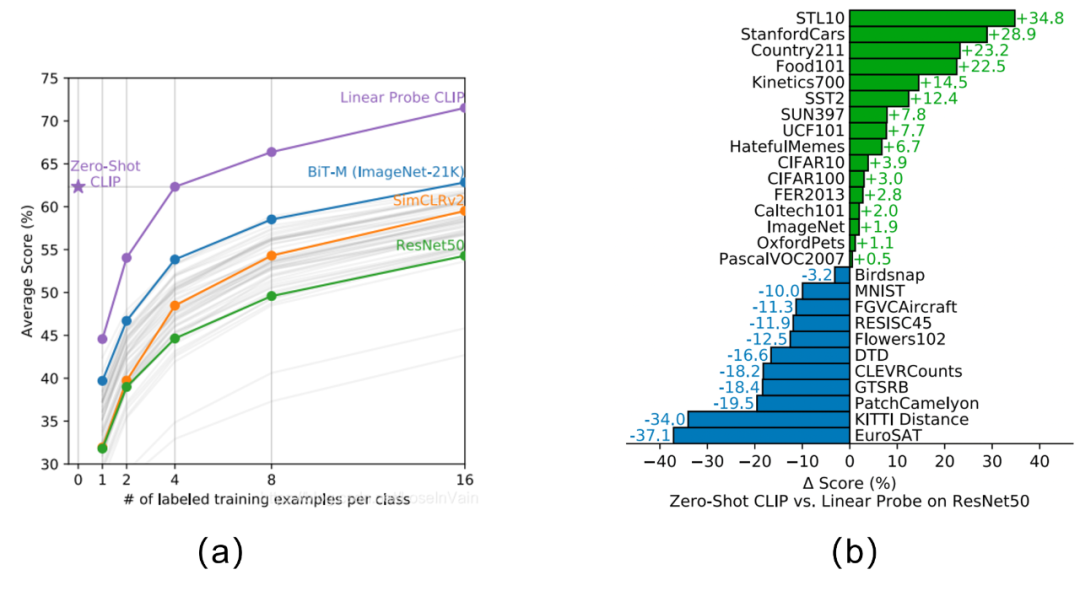
基于这种评估方式,以分类任务为例子,其zero-shot与强监督模型的对比结果见Fig 6.5 (b),对比的模型是强监督的resnet50(在linear probe的评估下[60]),我们发现其在一些数据集上其zero-shot能力甚至能比肩/超过强监督模型。CLIP的zero-shot和few-shot与其他模型的zero-shot/few-shot对比见Fig 6.5 (a),我们发现几个结论:
- zero-shot CLIP已经能够比肩16 shot的BiT-M了。
- few-shot CLIP性能远超其他few-shot模型。
- zero-shot CLIP能够比肩4 shot CLIP,这说明了提供了少量的样本(<4)就对CLIP模型进行finetune可能并不是一个好的做法,有可能会打乱模型在预训练阶段的语义对齐结果,从而影响其泛化性能。
当然,CLIP的论文原文是一个长达40多页的超长论文,里面有着非常详尽的试验分析,在此就不展开了,有兴趣的读者不妨去原文一睹CLIP的风采。总结来看,我们以下归结下CLIP的优点和缺陷,是的,CLIP即便有着革命性的成就,同样也是有缺陷的,而对这些缺陷的改进则引出了后续的一系列工作。
CLIP为什么惊艳?
- 在zero-shot和few-shot任务中的极致性能。
- 能够利用互联网中的海量带噪声数据,避免了对人工标注数据的依赖。
- 大规模对比学习能够实现良好的跨模态语义对齐。
CLIP的缺陷?
- 粗粒度的图片与文本打分,无法建模细粒度的视觉信息:在CLIP中是采用图片粒度与文本粒度进行匹配,形成图文粒度的打分的,在这种粒度下,理论上我们无法对文本和图片中的细粒度语义进行建模。
- 难以实现语义融合: CLIP的学习方式主要集中在了语义对齐,而难以进行语义融合。举个例子,我们的数据集中可能会有“猫在沙发上”“猫在地板上”“猫在地毯上”的图片,但是很少能看到“猫在人头上”的图片,这种我们长尾例子只能通过语义融合进行解决,而CLIP难以对稀疏的组合语义进行建模。
- 集中在了高频的视觉语义概念:由于CLIP中对目标词汇已经进行过高频筛选了,因此可想而知得到的视觉概念都是一些高频的语义概念。
- 集中在了英语语料上:由于该数据主要爬取自英文社区,缺乏多语言,特别是中文的预料。
- 需要大量的GPU资源进行训练:CLIP通过增大batch size的方式去提高负样本数量,而增大batch size则需要通过分布式训练中的
all_gather机制,因此需要大量的GPU资源才能增大batch size,进而提高负样本数量,资源的受限显然限制了进一步提高负样本数量的可能性。
CLIP的这些优势和缺陷,启发了后续一系列精彩纷呈的多模态工作,先事休息,然后让我们继续多模态的旅程吧。
ALIGN
大尺度图片与带噪文本嵌入特征(ALIGN: A Large-scale ImaGe and Noisy-text embedding)[17] 这篇工作在CLIP的基础上,对采用的预训练数据进行了更松弛的约束,因此预训练数据的尺度达到了惊人的18亿级别。在ALIGN中,作者不再对高频语义这个条件进行限制,而是在互联网中尽可能地爬取图文对数据,只采用了非常简单的数据过滤方式。这种数据过滤方式包括:
- 过滤尺寸太小的图片,这类型的图片通常是无意义的图片。
- 过滤太短的文本,这种文本通常无意义。
- 删除一些自动生成的文本,比如拍摄时间等等。
在这篇工作中,自然数据集的指标是比CLIP要更好的(否则也发不出来论文对吧:P ),但是笔者觉得更应该关注的是其结果分析部分,作者进行若干试验可视化了其语义对齐结果。如Fig 6.6所示,其中的(a-b)的试验设置是这样的,给定一张图 x \mathbf{x} x,其ALIGN模型的图像塔特征 f ( x ) ∈ R D f(\mathbf{x}) \in \mathbb{R}^{D} f(x)∈RD,给定一段文本 t \mathbf{t} t(比如"blue", “purple”…),同样可以得到其ALIGN模型的文本塔特征 g ( t ) ∈ R D g(\mathbf{t}) \in \mathbb{R}^{D} g(t)∈RD。那么对于给定的图片和目标文本,可以对其属性进行“编辑”,此处的编辑体现在对图片中的属性,通过文本描述进行添加(“+”)或者移除(“-”),具体做法就是用图像塔特征减去/加上文本塔的特征10,即是 f ( x ) − g ( t ) ∈ R D , f ( x ) + g ( t ) ∈ R D f(\mathbf{x})-g(\mathbf{t})\in \mathbb{R}^{D}, f(\mathbf{x})+g(\mathbf{t})\in \mathbb{R}^{D} f(x)−g(t)∈RD,f(x)+g(t)∈RD,然后在图片库里用增减后的特征去进行最近邻检索,得到最终的图片。如Fig 6.6 (a)所示,其能对玫瑰的颜色进行改变,回想到我们第0x00章所介绍的基础视觉元素,我们就能发现这其实是“属性”(Attribution)的对齐能力。不仅如此,Fig 6.6(a)的第三个例子能对“from distance”这种“关系”(Relation)概念进行感知,证明了其对“关系”建模的语义对齐能力。我们再看到Fig 6.6(b)的例子,我们会发现其不仅能对视觉属性、视觉关系进行对齐,而且还能对“视觉实体”概念进行对齐,否则其不能对图片中去掉“flowers”、添加“rose”等编辑产生响应。因此,Fig 6.6 (a)(b)实验其实直观地展示了大规模对比学习模型的强大语义对齐能力。
不仅如此,我们再看到Fig 6.6 ©(d)试验,这俩试验是通过固定文本加上一些属性,比如“detail”、“on a canvas”去检索图片,这个实验设置比前者简单些。我们不难发现,ALIGN模型除了能对视觉实体、属性、关系进行对齐外,似乎还有建模更复杂的视觉语义的能力,比如画风(“in black and white”),细粒度的视角(“view from bottom”、“view from top”…),这种能力可能是基础语义概念的组合,比如黑白画风多少可以拆分为“黑色+白色”的基础视觉属性组合,但是笔者仍然觉得对细粒度的视角关系有着如此好的感知能力,真的是非常神奇,也许基础视觉概念的组合真的是对复杂视觉语义的感知基础?!

FILIP
惊叹于大规模对比学习模型的强大语义对齐能力后,我们再回过头看看CLIP所欠缺的细粒度建模能力(fine-grained)。笔者已经分析了为何CLIP欠缺这种能力,无他,CLIP在计算图文相似度的时候直接将文本和图片都压缩成一个向量了,那如果不是压缩成一个向量,而是多个向量呢?的确,这是缓解CLIP粗粒度建模的最为直接的方法,而这也正是FILIP(Fine-grain interactive language-image pretraining)[39]的思路。
我们之前在博文 [61] 中曾经讨论过,在图文双塔匹配中,由于需要对图片塔的向量提前进行刷库,一些长尾的,形态较小的物体可能会在训练过程中被忽略,导致图文匹配的时候缺少对细粒度匹配的能力。为了解决这个问题,我们需要提供模型以图片和文本在线交互(online interaction)的能力,将图片以某种形式提取出每个区域的信息(ROI Detector检测每个ROI区域,或者单纯的划分patch,如ViT所做的那样),然后将文本和图片每个区域进行交互,从而模型有能力挖掘出图片中的一些细粒度信息。以第一种方式为例,如Fig 6.7所示,如果采用ROI Detector首先对图片的ROI区域进行提取,如红框所示,通过对文本『黄色桌子上的小黄人』进行在线匹配,即可实现对场景中的小黄人的细粒度匹配。
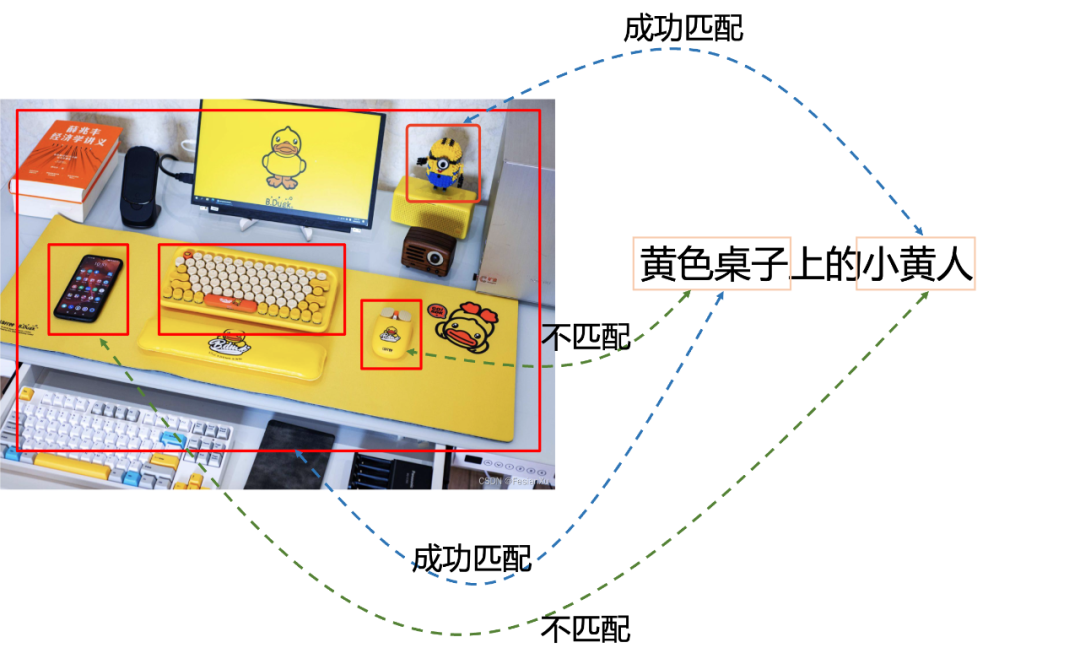
当然,这个前提是有一个足够好的ROI detector,并且其计算复杂度的代价也很高,对于在线应用比如图片搜索来说是一个比较大的负担。FILIP用了一种比较直接,也比较聪明的方法实现在线交互,其方法就是『迟交互(Late Interaction)』,想办法尽可能把交互的操作后移,从而使得pipeline的前端结果可以刷库,减少在线交互的代价。
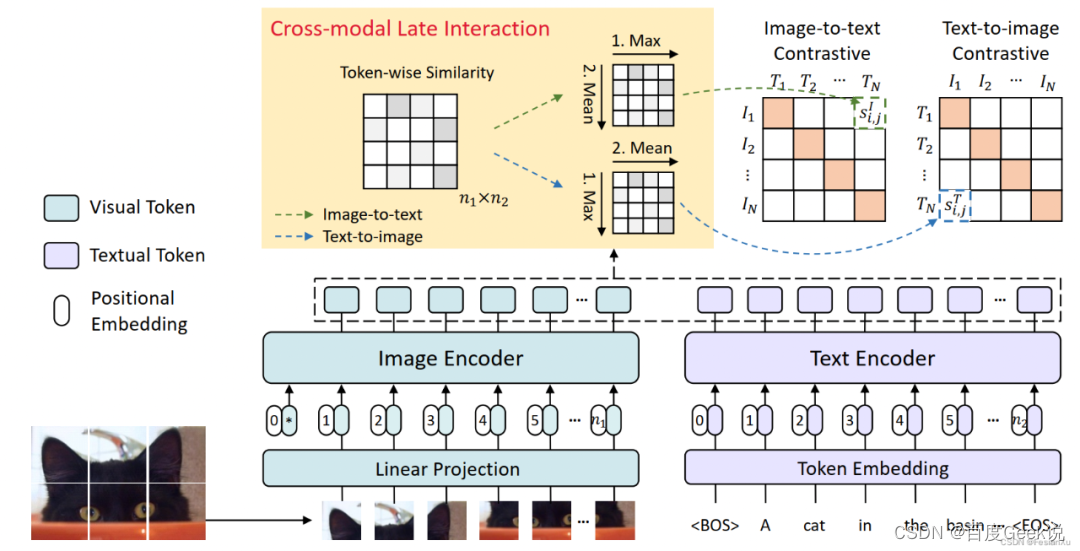
如Fig 6.8所示,FILIP的图片编码器是ViT ,对输入图片进行简单的分块后,进行线性映射输入到Transformer中,其输出就是对应每个Image Patch的Embedding向量,文本侧同样采用Transformer,其输出就是每个token的embedding。如果用 x I x^I xI表示图片样本, x T x^T xT表示文本样本,那么 x i I x_i^I xiI表示batch内图片的第 i i i个样本, x i T x_i^T xiT表示batch内文本的第 i i i个样本,具有同个下标的样本对 { x i I , x i T } \{x_i^I, x_i^T\} {
xiI,xiT}我们认为是一对正样本,而下标不同的样本对 { x i I , x j T } \{x_i^I, x_j^T\} {
xiI,xjT}我们认为是一对负样本。用 f θ ( ⋅ ) f_{\theta}(\cdot) fθ(⋅)表示图片编码器, g ϕ ( ⋅ ) g_{\phi}(\cdot) gϕ(⋅)表示文本编码器,在不存在交互的双塔匹配模型中,如CLIP和ALIGN中,第 i i i个和第 j j j个样本间的相似度定义为:
s i , j I = s i , j T = f θ ( x i I ) T g ϕ ( x j T ) (6-7) s_{i,j}^I = s_{i,j}^T = f_{\theta}(x_i^I)^{\mathrm{T}} g_{\phi}(x_j^{T}) \tag{6-7} si,jI=si,jT=fθ(xiI)Tgϕ(xjT)(6-7)
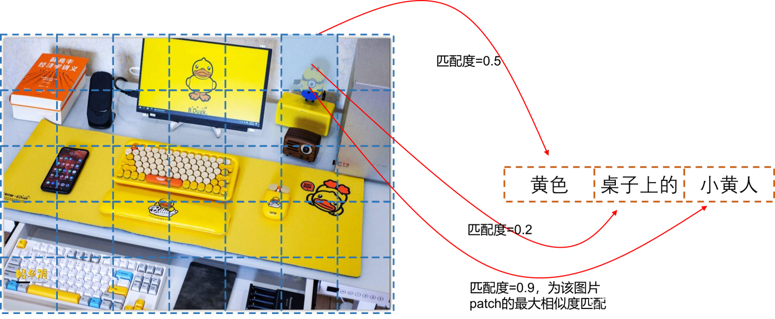
其中 f θ ( x i I ) ∈ R d , g ϕ ( x j T ) ∈ R d f_{\theta}(x_i^I) \in \mathbb{R}^{d}, g_{\phi}(x_j^{T}) \in \mathbb{R}^{d} fθ(xiI)∈Rd,gϕ(xjT)∈Rd,无论是图片编码器还是文本编码器,均对同一个图片/文本只产出一个特征向量,通过计算余弦相似度计算其图文相似性,显然这是一种全局(Global)的相似度计算方式。而在FILIP中,采用ViT和Text Transformer可以对每个图片token和文本token产出『专属』的embedding(可以认为是每个模态的细粒度局部信息),假设 n 1 n_1 n1和 n 2 n_2 n2分别是第 i i i个图片样本和第 j j j个文本样本的token数量,那么有 f θ ( x i I ) ∈ R n 1 × d , g ϕ ( x j T ) ∈ R n 2 × d f_{\theta}(x_i^I) \in \mathbb{R}^{n_1 \times d}, g_{\phi}(x_j^{T}) \in \mathbb{R}^{n_2 \times d} fθ(xiI)∈Rn1×d,gϕ(xjT)∈Rn2×d。 我们怎么计算第 i i i个和第 j j j个样本间的相似度呢?此时就体现了迟交互的作用,对于第 i i i个图片的第 k k k个token而言,分别计算其和第 j j j个文本样本的所有 n 2 n_2 n2个token间的相似程度,并且挑选其中相似度最大的打分,作为第 i i i个图片第 k k k个token的打分代表,这个方式作者称之为『逐令牌最大相似度(token-wise maximum similarity)』。
max 0 ≤ r < n 2 [ f θ ( x i I ) ] k T [ g ϕ ( x i T ) ] r (6-8) \max_{0 \leq r \lt n_2} [f_{\theta}(x_i^I)]_k^{\mathrm{T}} [g_{\phi}(x_i^T)]_r \tag{6-8} 0≤r<n2max[fθ(xiI)]kT[gϕ(xiT)]r(6-8)
当然,对于图片样本 i i i来说,这个只是第 k k k个token的最大相似度打分,而我们有 n 1 n_1 n1个图片token,因此会对这 n 1 n_1 n1个最大相似度打分进行求平均。
s i , j I ( x i I , x j T ) = 1 n 1 ∑ k = 1 n 1 [ f θ ( x i I ) ] k T [ g ϕ ( x i T ) ] m k I (6-9) s_{i,j}^I(x_i^I,x_j^T) = \dfrac{1}{n_1} \sum_{k=1}^{n_1} [f_{\theta}(x_i^I)]_k^{\mathrm{T}} [g_{\phi}(x_i^T)]_{m_{k}^{I}} \tag{6-9} si,jI(xiI,xjT)=n11k=1∑n1[fθ(xiI)]kT[gϕ(xiT)]mkI(6-9)
其中的 m k I m_{k}^I mkI标识了其最大相似度的索引,也就是 m k I = arg max 0 ≤ r < n 2 [ f θ ( x i I ) ] k T [ g ϕ ( x i T ) ] r m_k^I = \arg\max_{0\leq r \lt n_2} [f_{\theta}(x_i^I)]_k^{\mathrm{T}} [g_{\phi}(x_i^T)]_r mkI=argmax0≤r<n2[fθ(xiI)]kT[gϕ(xiT)]r,式子(6-9)是图片-文本侧的相似度度量,类似的,我们也可以定义出文本-图片侧的相似度度量 s i , j T ( x i T , x j I ) s_{i,j}^T(x_i^T,x_j^I) si,jT(xiT,xjI)。 注意到 s i , j I ( x i I , x j T ) s_{i,j}^I(x_i^I,x_j^T) si,jI(xiI,xjT)不一定等于 s i , j T ( x i T , x j I ) s_{i,j}^T(x_i^T,x_j^I) si,jT(xiT,xjI),也就是说基于最大相似度的交互,其跨模态相似度不一定是对称的,这一点和CLIP不同。
接下来我们可视化观察FILIP的细粒度结果,作者采用了Prompt Learning的方式,对数据集采用了Prompt模版的优化,本文就不展开了。在论文中作者对图文细粒度匹配的结果进行了可视化,如Fig 6.10所示,此处的label分别为“Balloon(气球)”,“Lifeboat(救生艇)”,“Small white butterfly(小白蝶)”,“Electric Iocomotive(电力机车)”,而label后面的数字表示label的某位单词在label模版中的位置。举个例子,此处的模版为
Label模版:a photo of a {label}
当label为"Small white butterfly"的时候,label模版即为“a photo of a small white butterfly”,small在该模版中的第5位,white在第6位而butterfly在第7位。按照前文描述的交互方式,我们求出每个图片patch与label模版单词,其中的最大相似度匹配的模版位置ID,然后将这些位置ID中为label位置ID的进行高亮,这样就绘制出了如Fig 6.10所示的结果。我们可以发现这些label物体有些是非常细粒度的,如气球在原图中的视觉占比非常小,CLIP的结果和我们预期的一致,压根没有对这种细粒度物体进行响应。而FILIP的结果则能对图中patch中有气球部分的进行响应。FILIP不仅能对细粒度物体进行响应,对于大物体同样效果不俗,如Fig 6.10 ©所示,这个蝴蝶占据了大半个图片,此时FILIP匹配效果同样能够超过CLIP。

WenLan
我们在介绍CLIP的一节中,已经知道了通过增大负样本数量可以有效地提高对比学习的效率。然而CLIP也好,ALIGN也罢,这些方法都属于是Table 2.2中所提到的端到端方法,其负样本数量和batch size是耦合在一起的,而提高batch size的代价就是珍贵的硬件资源,有什么方法能够将batch size和负样本数量进行解耦呢?我们在第0x01章其实介绍过类似的情况,MoCo就是一种通过维护负样本队列和动量更新编码器,从而实现batch size和负样本数量解耦的方法,只不过MoCo是应用在图片单模态的自监督建模的,这个思想是否能够迁移到多模态呢?
WenLan [18]就是这样的一种方法,可以视为是MoCo在图文多模态上的延伸,由于图文多模态模型具有图片和文本两个模态,两个模态都需要独立维护一个负样本队列,因此有两个负样本队列。并且,由于在MoCo中,只有Query编码器是进行梯度更新的,而Key编码器是进行动量更新的,那么在多模态模型中,我们现在有Image Encoder和Text Encoder两种模态的编码器,让谁充当Query编码器进行梯度更新,让谁充当Key编码器进行动量更新呢?答案就是在WenLan中同时存在两套Query-Key编码器,在第一套编码器中,由Image编码器充当Query编码器,Text编码器充当Key编码器;在第二套编码器中,由Text编码器充当Query编码器,由Image编码器充当Key编码器。
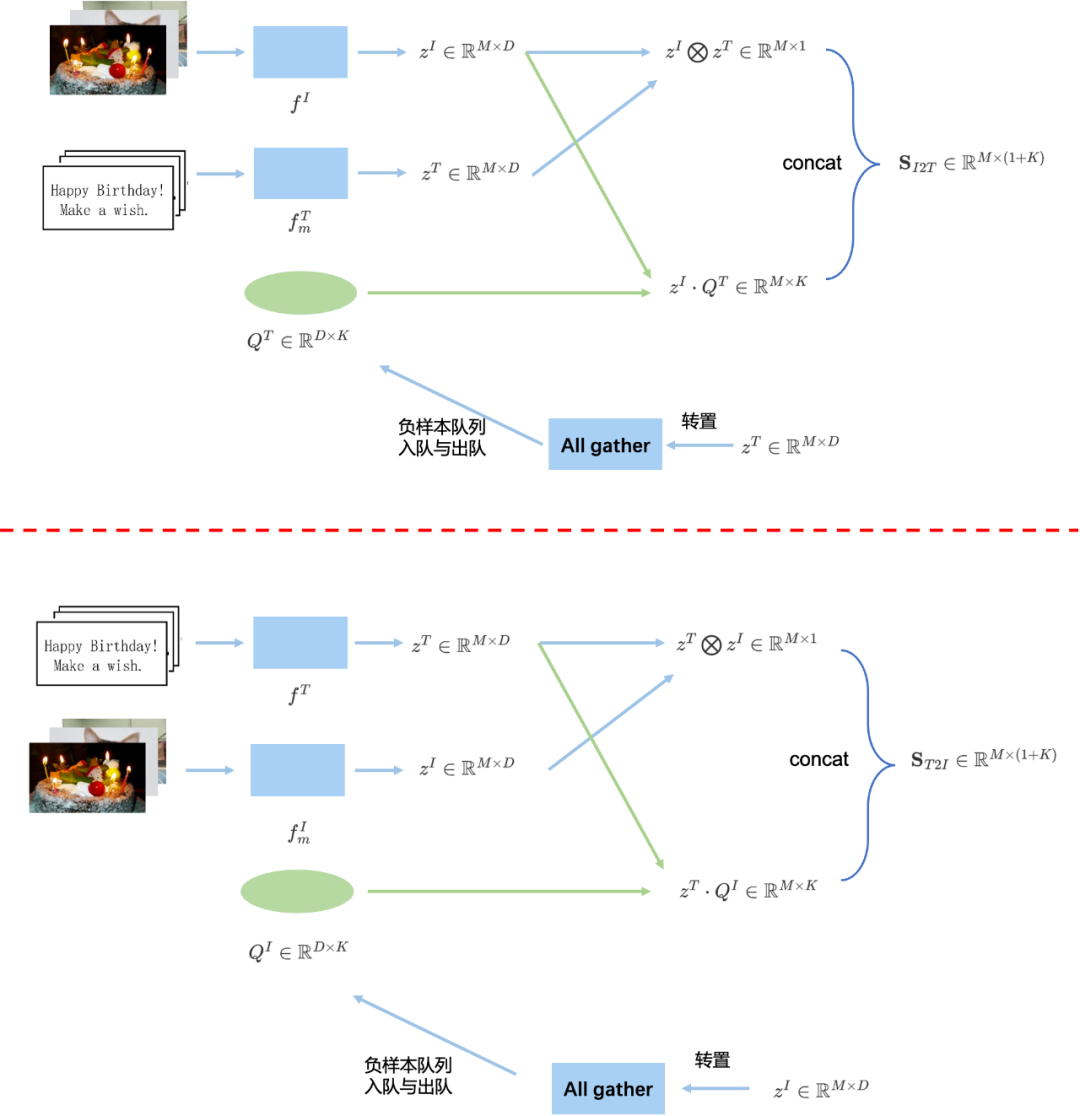
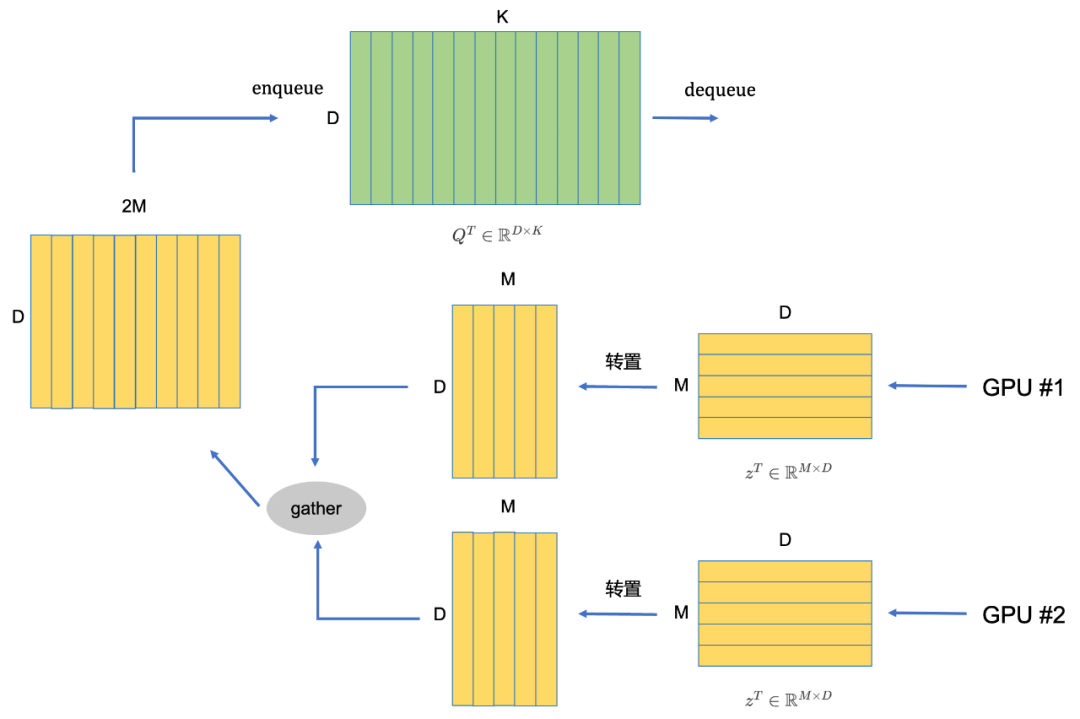
我们用框图详细解释下整个流程,我们以其中一套编码器 f I , f m T f^{I}, f^{T}_m fI,fmT为例子,如Fig 6.11的上半部分所示,假设图片和文本的batch size为 M M M。其中的 Q T ∈ R D × K Q^T\in\mathbb{R}^{D \times K} QT∈RD×K是负样本队列, K K K是队列大小, D D D是特征维度。 z I ∈ R M × D z^{I}\in\mathbb{R}^{M\times D} zI∈RM×D是图片经过 f I f^I fI编码器(Query编码器)后的特征输出, z T ∈ R M × D z^T\in\mathbb{R}^{M \times D} zT∈RM×D是对应的文本经过 f m T f^T_{m} fmT编码器(此处是Key编码器)后的特征输出。定义算子 ⨂ \bigotimes ⨂为:
a ⨂ b = ∑ j ( a ⋅ b ) i j ∈ R M × 1 a ∈ R M × D , b ∈ R M × D (6.10) a \bigotimes b = \sum_{j} (a \cdot b)_{ij} \in\mathbb{R}^{M\times 1}\\ a \in\mathbb{R}^{M\times D}, b\in\mathbb{R}^{M\times D} \tag{6.10} a⨂b=j∑(a⋅b)ij∈RM×1a∈RM×D,b∈RM×D(6.10)
可以发现,其实 z I ⨂ z T z^I \bigotimes z^T zI⨂zT在进行正样本打分,其中的 a ⋅ b ∈ R M × D a \cdot b \in \mathbb{R}^{M \times D} a⋅b∈RM×D 为element-wise乘法,最终对当前输入的 M M M个样本进行了正样本打分,计算代码见Code 6.1;而 z I ⋅ Q T z^I \cdot Q^T zI⋅QT是利用负样本队列 Q T Q^T QT进行负样本打分。最后在最后一个axis进行拼接后,得到了正负样本打分 S I 2 T ∈ R M × ( 1 + K ) \mathbf{S}_{I2T}\in\mathbb{R}^{M \times (1+K)} SI2T∈RM×(1+K) ,其中第一维为正样本打分,其余的 K K K维为负样本打分。随后即可通过交叉熵损失进行计算损失,得到 L I 2 T \mathcal{L}_{I2T} LI2T。完成损失计算后,对Key编码器计算得到的特征进行负样本队列入队,以达到更新负样本队列的目的。注意,此处在具体实现过程中,需要对所有GPU中的 z T z^T zT进行汇聚(all gather),代码可以参考MoCo的实现[63]。
l_pos = torch.einsum('nc,nc->n', [zI, zT]).unsqueeze(-1) # 一个batch中的M个正样本打分计算,大小为M x 1
l_neg = torch.einsum('nc,ck->nk', [zI, QT.clone().detach()]) # 一个batch中的所有样本和负样本队列进行负样本打分,大小为M x K
当然,此处只是一套编码器,如果考虑另一套编码器,那么整体框图如Fig 6.11整体所示,通过另一套编码器我们可以得到损失 L T 2 I \mathcal{L}_{T2I} LT2I,将两套编码器的损失相加得到最终的损失:
L = L I 2 T + L T 2 I (6.11) \mathcal{L} = \mathcal{L}_{I2T}+\mathcal{L}_{T2I} \tag{6.11} L=LI2T+LT2I(6.11)
用下标 j j j表示对向量进行索引,那么这两部分损失可以细化表示为:
L I 2 T = − ∑ j log exp ( z j I ⋅ z j T / τ ) exp ( z j I ⋅ z j T / τ ) + ∑ n T ∈ Q T exp ( z j I ⋅ n T / τ ) L T 2 I = − ∑ j log exp ( z j T ⋅ z j I / τ ) exp ( z j T ⋅ z j I / τ ) + ∑ n I ∈ Q I exp ( z j T ⋅ n I / τ ) (6.12) \begin{aligned} \mathcal{L}_{I2T} &= -\sum_{j} \log\dfrac{\exp(z^{I}_{j} \cdot z^{T}_j / \tau)}{\exp(z^{I}_{j} \cdot z^{T}_j / \tau)+\sum_{n^T\in Q^T} \exp(z^{I}_{j} \cdot n^T / \tau)} \\ \mathcal{L}_{T2I} &= -\sum_{j} \log\dfrac{\exp(z^{T}_{j} \cdot z^{I}_j / \tau)}{\exp(z^{T}_{j} \cdot z^{I}_j / \tau)+\sum_{n^I \in Q^I} \exp(z^{T}_{j} \cdot n^I / \tau)} \end{aligned} \tag{6.12} LI2TLT2I=−j∑logexp(zjI⋅zjT/τ)+∑nT∈QTexp(zjI⋅nT/τ)exp(zjI⋅zjT/τ)=−j∑logexp(zjT⋅zjI/τ)+∑nI∈QIexp(zjT⋅nI/τ)exp(zjT⋅zjI/τ)(6.12)
从框图Fig 6.11来看,对于一个batch的输入 { B T , B I } \{B^{T}, B^I\} {
BT,BI},需要分别喂入两套编码器进行计算,因此计算量和对GPU的显存有比较高的要求,再加上在WenLan里面采用了2560大小的隐层大小,导致其即便在A100中都只能开到每张卡batch size=16的程度。同时,这也约束了负样本队列的大小,也许这是以后可以进一步改进的点。
我们再来说下其对负样本队列的更新策略。对于每个模态,我们会在GPU中手动维护一个队列矩阵 Q ∈ R D × K Q\in \mathbb{R}^{D \times K} Q∈RD×K,以及一个队列指针queue_ptr用于指示在队列的何处更新队列。如Fig 6.12(以其中一套编码器为例子)所示,假设我们现在有两张GPU同时进行数据并行计算[63],那么在Key编码器计算完后产生的特征 z ∈ R M × D z \in \mathbb{R}^{M \times D} z∈RM×D需要入队负样本队列 Q Q Q,此时为了更快速地更新负样本队列,我们会将所有GPU上的特征进行汇聚(gather), 并且计算汇聚后的batch size=G*M,其中的G是卡数。此时根据queue_ptr,在Q[:, queue_ptr:queue_ptr+batch_size]处将汇聚后的特征赋值。整个过程也可见Code 6.2所示。
feature_z_gathered = concat_all_gather(feature_z) # 此处汇聚所有GPU上的相同张量。
batch_size = feature_z_gathered.shape[0]
Q[:, queue_ptr:queue_ptr + batch_size] = feature_z_gathered.transpose()
多模态模型并不能很好地解决这类型的问题,多模态模型能做到把图片的视觉概念挖掘出来就达到了设计目的,至于深入挖掘图片的更为深层次的人文背景,人物关系,作品等等,则需要采用知识图谱(Knowledge Graph)进行概念之间的关联。比如Fig 6.13中的第三个case,我们都知道这个是电影『大话西游』中的一个名场景,但是从视觉中模型只能知道是『一个穿着戏服的男人和一个穿着戏服的女孩在一起』,显然没有用户会用如此不符合检索习惯的语句进行搜索,更可能的检索是『大话西游 假如上天再给我一个机会』『大话西游 名场面』之类的。显然这些概念多模态模型无法捕捉,这也许也就是多模态模型的局限了吧。

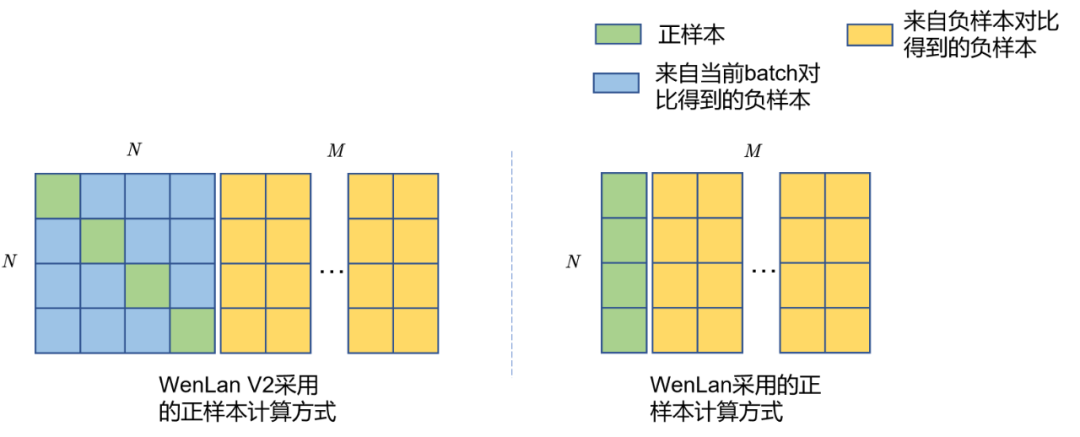
WenLan V2 [64] 在WenLan的基础上进行了一些优化,主要有以下几点:
-
WenLan v2采用了更大的互联网图文数据集进行预训练,数据规模多达6.5亿图文对,并且由于数据来自互联网爬虫得到,没有进行过人工标注,数据更接近与真实生活数据,即是弱视觉语义数据。该数据集对比与在WenLan 1.0中采用的3000万弱语义图文对,显然在数量级上又更上一层楼。
-
从技术上看,该工作去除了WenLan中的Object Detector,因此是不依赖于物体检测结果的图文匹配模型,这个特点使得该工作更适合与实际工业界中的应用,因为涉及到了物体检测意味着需要更多的计算消耗。
-
其计算正样本打分的方式对齐了CLIP的做法,具体区别如Fig 6.14所示。
WenLan v2的细节并不是本文重点,就不多介绍,有兴趣的读者可参考笔者之前的博文[65]。
LiT
回想到我们之前谈到的图文对数据,在理想情况下都应该如同Fig 6.15 左图所示,文本对图片中的视觉元素进行客观地描述,从而模型可以学习到文本与视觉的语义对齐,我们将这种图文对数据称之为强视觉关联(Strong Correlation)。然而在真实互联网数据中,图文对数据并不是如此的理想,很多时候文本描述并不是在描述画面的视觉元素,而是整张图的抽象含义,如Fig 6.15所示,作为对整个图的视觉描述,理想的本应该是
There are several burning candles on a fruit cake. (加粗的为视觉概念)
但是在实际的互联网数据中,很多是对整个场景的抽象描述,比如
Happy birthday! make a wish.
这种抽象描述没有任何视觉元素(实体、属性、关系等),因此我们称之为弱视觉关联(weak correlation)。单纯依靠弱视角关联数据,显然模型无法将没有任何视觉语义的文本对齐到图片中的视觉元素中,这其实也在拷问我们:我们在上文分析中,已经知道了如何对强视觉关联样本建立语义对齐,这种强视觉关联数据都是对具象视觉概念的描述,那么我们如何对抽象的概念进行视觉对齐呢?比如自由、和平、指引、积极向上等等,其实这些抽象概念大多也会有具象的某些视觉联系,比如破碎的枷锁意味着自由,橄榄枝和鸽子象征着和平,灯塔隐含着指引之意,显然抽象概念和对应的隐含视觉概念并不是强视觉关联的,因此也是属于弱视觉关联数据的一种。那么其实又回到了我们一开始的问题,如何对弱视觉关联数据进行跨模态建模呢?问得更基础些,我们如何对弱视觉关联数据进行语义对齐?不回答这个问题,我们将难以对抽象概念进行语义对齐。

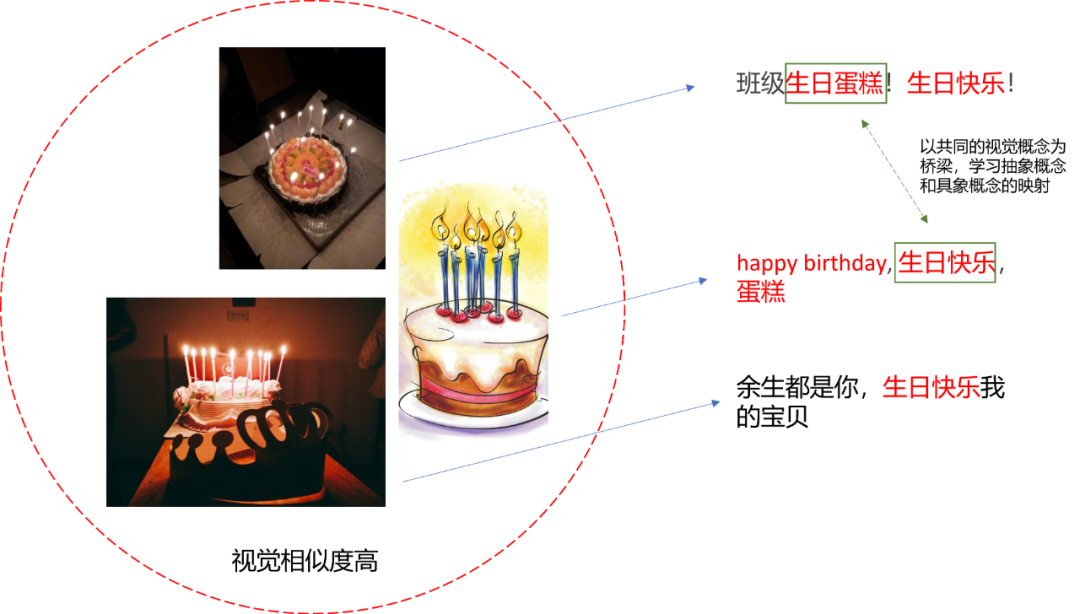
一种可能的回答是,通过大量视觉语义相似数据的对比,从中找出文本抽象概念与文本具象概念的对应关系。具体些,如Fig 6.16所示,假如我们想要学习出“生日快乐”与“生日蛋糕”有着强烈的相关性,那么一种可能的做法,在数据量足够多的时候,我们会有很多与蛋糕图片能够配对的文本,这些文本里面可能有抽象概念,如“生日快乐”,也可能有具象概念,比如“生日蛋糕”,而此时生日蛋糕的图片显然都是视觉语义相似的。通过相同的视觉概念作为桥梁,从而可以学习出抽象概念和具象概念的某些关联,正如Fig 6.16的例子所示,这种方法提供了模型学习出“生日蛋糕和生日快乐是相关”的能力。
以上方案的前提在于两个:第一,需要大量数据,这个互联网足以提供;第二,需要一次性对比大量样本。第一点容易理解,但第二点为何?原因在于,只有一次性对比大量样本,才能提高从中采样到相似视觉概念的图片的概率。这意味着需要提高batch size,而这受到了硬件的制约,我们得另想他法。我们之前不是谈到了其实关键在于寻找相似的视觉语义概念吗,假如我们的视觉语义学习的比较好了,是不是就能固定视觉塔模型了呢?一旦固定了视觉塔的特征,就只剩下了文本塔需要进行预训练,此时显存消耗能够大大减少,我们就能将batch size提高到新的高度。
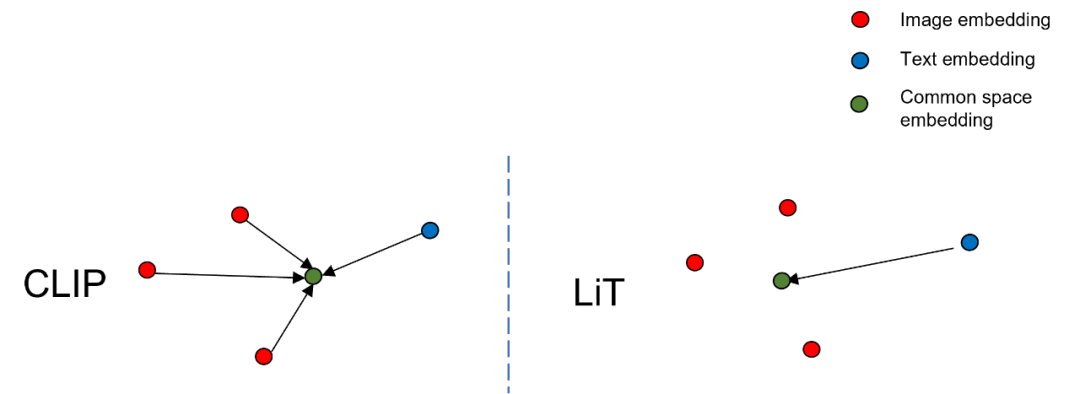
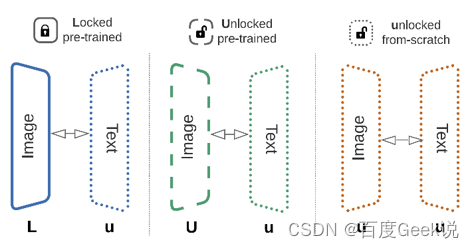
Lock-Image Tuning(LiT)[20]即便这篇工作的出发点并不是这个,但笔者仍然觉得其方法对弱视觉语义的学习有极大帮助。在LiT中,作者通过一些高质量的图片数据集(如JFT-300M、ImageNet-21K、JFT-8B…)先对视觉塔进行预训练,当视觉语义学习的比较充分后,将视觉特征固定,只对文本模型进行对比学习预训练,由于此时不涉及到最占显存的视觉模型,因此能将batch size大幅度提升。如Fig 6.17所示,在传统的CLIP方法下,视觉特征和文本特征是往着所谓的公共语义空间靠拢的,而在LiT方式下,视觉特征固定住了,只有文本特征会往着视觉特征的方向靠拢。
当然,作者也并不只是尝试了将视觉端进行固定,同时作者也尝试了对文本端模型进行固定,或者两者都不固定。同时,作者在不固定视觉/文本端模型的情况下,也分别尝试了进行模型热启,和完全从头训练的不同设置,见Fig 6.18所示,其中的L表示Lock,即是模型参数固定,U表示模型参数不固定且进行预训练热启,u表示模型参数不固定且从头进行训练(train from scratch)。作者在论文中进行了多种试验,最终发现对于zero-shot分类而言,Lu配置(即是图片端固定,文本端不固定且从头训练)是最有效的,如Fig 6.18(b)的ImageNet 0-shot试验结果所示。
ALBEF
从上文的讨论中我们发现,高效的语义对齐都是利用双塔模型,利用大规模对比学习进行预训练得到的,而双塔模型天然适合在检索、推荐场景等工业场景适用。比如在图文信息检索场景中,我们要衡量用户Query和图片之间的图文相关性。假如图片编码器是 y v = f v ( I ) , y v ∈ R D y_v =f_v(I), y_v \in \mathbb{R}^{D} yv=fv(I),yv∈RD,文本编码器是 y w = f w ( T ) , y w ∈ R D y_w = f_w(T), y_w \in \mathbb{R}^{D} yw=fw(T),yw∈RD,而待检索库中所有图片的集合记为 D = { I i ∣ i = 1 , ⋯ , M } \mathcal{D}=\{I_i|i=1,\cdots,M\} D={ Ii∣i=1,⋯,M},那么可以预先对所有图片进行特征提取,形成图片的正排(Forward Index)特征并且建库,记为 D F I = { f v ( I i ) , i = 1 , ⋯ , N } \mathcal{D}_{FI}=\{f_v(I_i),i=1,\cdots,N\} DFI={ fv(Ii),i=1,⋯,N},在用户输入检索词 Q Q Q的时候,只需要对Query进行文本编码器的在线计算,得到文本特征 f w = f w ( Q ) f_w=f_w(Q) fw=fw(Q),然后对待排序的样本进行图片正排库取特征,进行相关性计算(在线计算余弦距离)就可以判断候选图片与Query之间的图文相关程度了。利用双塔模型可以预先建库并且在线计算相关性的特性,可以很大程度上用空间换时间节省很多计算资源,而这也是双塔模型在搜索系统(不仅仅是图文搜索)中被广泛应用的原因之一。
这个世界没有银弹,双塔模型中的图片和文本信息不能在线交互的特性决定了其对一些细致的图文匹配需求无法满足。举个例子,比如去搜索『黑色上衣白色裤子』,那么百度返回的结果如图Fig 6.20 (a) 所示,除去开始三个广告不计,用红色框框出来的Top3结果中有俩结果都是『白色上衣黑色裤子』,显然搜索结果并没有理解到『黑色上衣』和『白色裤子』这两个概念,而是单独对『黑色』『白色』和『上衣』『裤子』这两个属性进行了组合,因此才会得到『白色上衣黑色裤子』被排到Top20结果的情况。而类似的结果同样在谷歌上也会出现,如Fig 6.20 (b)所示。
![![fig-albef-badcase][fig-albef-badcase]](https://img-blog.csdnimg.cn/2ecb8409268c4d23ae23a920f582a9cb.png)
这种多模态匹配细粒度结果不尽人意的原因,很大程度上是双塔模型中的图片编码器和文本编码器无法在线进行交互导致的。可以想象到,我们的图片编码器由于是预先对所有图片提特征进行建库的,那么就无法对所有属性的组合都进行考虑,必然的就会对一些稀疏的组合进行忽略,而倾向于高频的属性组合,因此长尾的属性组合就无法很好地建模。双塔模型这种特点,不仅仅会使得多属性的Query的检索结果倾向于高频组合,而且还会倾向于图片中的一些大尺寸物体,比如Fig 6.21中的小黄人尺寸较小,在进行特征提取的时候,其在整张图片中的重要性就有可能被其他大尺寸物体(比如键盘和显示屏等)掩盖。

这些缺陷其实本质上,是由于双塔模型进行对比学习只对语义对齐进行了建模,而我们在第0x00章的讨论中就已经知道,语义对齐在建模长冷的视觉概念,比如组合型的复杂概念上并不具有优势,为了建模这些组合视觉概念,我们必须同时引入语义融合。语义融合?我们在介绍UNITER的时候,已经知道了单塔交互模型的损失函数大多能对语义融合进行建模,比如ITM和MLM损失等,我们为何不将语义对齐和语义融合都糅合在一起呢?理论上,一种最合适的方式就是先进行足够好的语义对齐训练,进行基础视觉概念的学习,尔后采用语义融合进行组合型的复杂视觉概念学习。
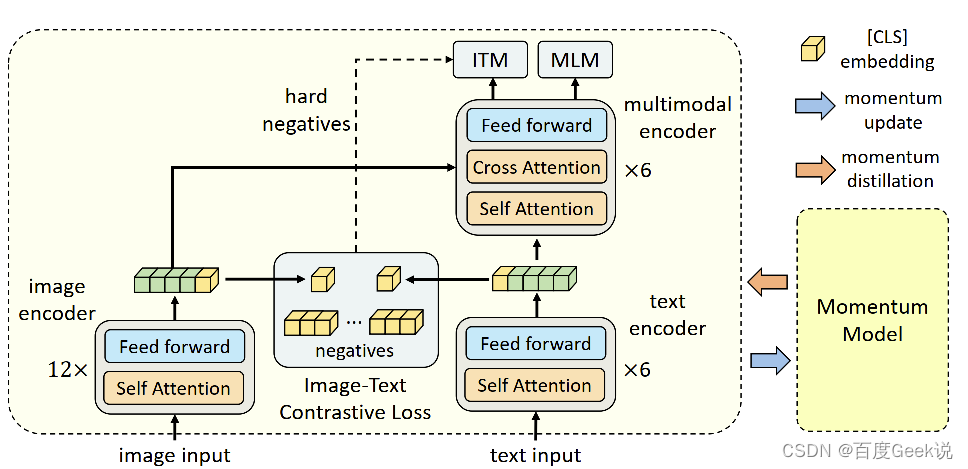
我们不妨对这个过程进行数学形式化表示,我们用 { v C L S , v 1 , ⋯ , v N } \{\mathbf{v}_{CLS},\mathbf{v}_1,\cdots,\mathbf{v}_N\} { vCLS,v1,⋯,vN}表示图片输入 I \mathbf{I} I的图片编码器编码结果,同样对于文本输入 I \mathbf{I} I也能表示其文本编码器后的编码结果 { w C L S , w 1 , ⋯ , w N } \{\mathbf{w}_{CLS},\mathbf{w}_1,\cdots,\mathbf{w}_N\} { wCLS,w1,⋯,wN}。其预训练目标有两大类:
- 语义对齐: 通过单模态编码器(其实就是双塔模型)进行图文对比学习(Image-Text Contrastive Learning,ITC)进行图文语义对齐
- 语义融合:将语义对齐后的图/文特征在多模态编码器中进行跨模态交互,通过Masked Language Model(MLM)和图文匹配(Image-Text Matching,ICM)任务进行图文语义融合。
语义对齐可以通过双塔模型的大规模对比学习进行,其目标是让图片-文本对的相似度尽可能的高,也就是 s = g v ( v c l s ) T g w ( w c l s ) s=g_v(\mathbf{v}_{cls})^{\mathrm{T}}g_w(\mathbf{w}_{cls}) s=gv(vcls)Tgw(wcls),其中的 g v ( ⋅ ) g_v(\cdot) gv(⋅)和 g w ( ⋅ ) g_w(\cdot) gw(⋅)是对[CLS]的线性映射,其将[CLS]特征维度映射到了多模态共同特征子空间。类似于WenLan,在ALBEF模型中,作者同样采用了两个图片/文本样本队列和动量图片/文本编码器,这两个队列维护了最近的动量编码器的 M M M个表征,这些来自于动量编码器的特征表示为 g v ′ ( v c l s ′ ) g_{v}^{\prime}(\mathbf{v}^{\prime}_{cls}) gv′(vcls′)和 g w ′ ( w c l s ′ ) g_{w}^{\prime}(\mathbf{w}^{\prime}_{cls}) gw′(wcls′) 。进行跨模态匹配打分,如式子(6-13)所示
s ( I , T ) = g v ( v c l s ) T g w ′ ( w c l s ′ ) s ( T , I ) = g w ( w c l s ) T g v ′ ( v c l s ′ ) (6-13) \begin{aligned} s(I,T) &= g_v(\mathbf{v}_{cls})^{\mathrm{T}}g_{w}^{\prime}(\mathbf{w}^{\prime}_{cls}) \\ s(T,I) &= g_w(\mathbf{w}_{cls})^{\mathrm{T}}g_{v}^{\prime}(\mathbf{v}^{\prime}_{cls}) \end{aligned} \tag{6-13} s(I,T)s(T,I)=gv(vcls)Tgw′(wcls′)=gw(wcls)Tgv′(vcls′)(6-13)
那么可以定义出图-文/文-图相关性,如式子(6-14)所示,其中的 N N N是batch size(这一点是代码实现,和论文有些偏差[67])
p m i 2 t ( I ) = exp ( s ( I , T m ) / τ ) ∑ m = 1 M + N exp ( s ( I , T m ) τ ) p m t 2 i ( T ) = exp ( s ( T , I m ) / τ ) ∑ m = 1 M + N exp ( s ( T , I m ) τ ) (6-14) \begin{aligned} p^{i2t}_{m}(I) &= \dfrac{\exp(s(I, T_m)/\tau)}{\sum_{m=1}^{M+N}\exp(s(I,T_m)\tau)} \\ p^{t2i}_{m}(T) &= \dfrac{\exp(s(T, I_m)/\tau)}{\sum_{m=1}^{M+N}\exp(s(T, I_m)\tau)} \end{aligned} \tag{6-14} pmi2t(I)pmt2i(T)=∑m=1M+Nexp(s(I,Tm)τ)exp(s(I,Tm)/τ)=∑m=1M+Nexp(s(T,Im)τ)exp(s(T,Im)/τ)(6-14)
令 y i 2 t ( I ) \mathbf{y}^{i2t}(I) yi2t(I)和 y t 2 i ( T ) \mathbf{y}^{t2i}(T) yt2i(T)表示真实的标签,通过交叉熵损失定义出图文对比损失(Image-Text Contrastive Loss, ITC):
L i t c = 1 2 E ( I , T ) ∼ D [ H ( y i 2 t ( I ) , p i 2 t ( I ) ) + H ( y t 2 i ( T ) , p t 2 i ( T ) ) ] (6-15) \mathcal{L}_{itc} = \dfrac{1}{2} \mathbb{E}_{(I,T) \sim D} [H(\mathbf{y}^{i2t}(I), \mathbf{p}^{i2t}(I))+H(\mathbf{y}^{t2i}(T), \mathbf{p}^{t2i}(T))] \tag{6-15} Litc=21E(I,T)∼D[H(yi2t(I),pi2t(I))+H(yt2i(T),pt2i(T))](6-15)
ALBEF模型的底层是双塔语义对齐,其上层是单塔语义融合。为了实现语义融合,论文中采用了Masked Language Model(MLM)损失对正样本对进行建模。作者以 15 % 15\% 15%概率将输入的Token进行替代,将其替代为特殊令牌[MASK],令 T ^ \hat{T} T^表示被掩膜后的文本, p m s k ( I , T ^ ) \mathbf{p}^{msk}(I,\hat{T}) pmsk(I,T^)表示对掩膜后的令牌的预测结果,而 y m s k \mathbf{y}^{msk} ymsk表示被掩膜令牌的真实标签,那么MLM目的在于最小化以下交叉熵损失:
L m l m = E ( I , T ^ ) ∼ D H ( y m s k , p m s k ( I , T ^ ) ) (6-16) \mathcal{L}_{mlm} = \mathbb{E}_{(I, \hat{T})\sim D} H(\mathbf{y}^{msk}, \mathbf{p}^{msk}(I,\hat{T})) \tag{6-16} Lmlm=E(I,T^)∼DH(ymsk,pmsk(I,T^))(6-16)
通过MLM损失建模,可以让多模态实体之间不仅语义对齐,而且能找到各个实体之间的复合语义关系,如Fig 6.24所示,MLM损失约束模型去融合不同实体,挖掘他们之间的多模态关系,从而对被掩膜后的实体做出预测。
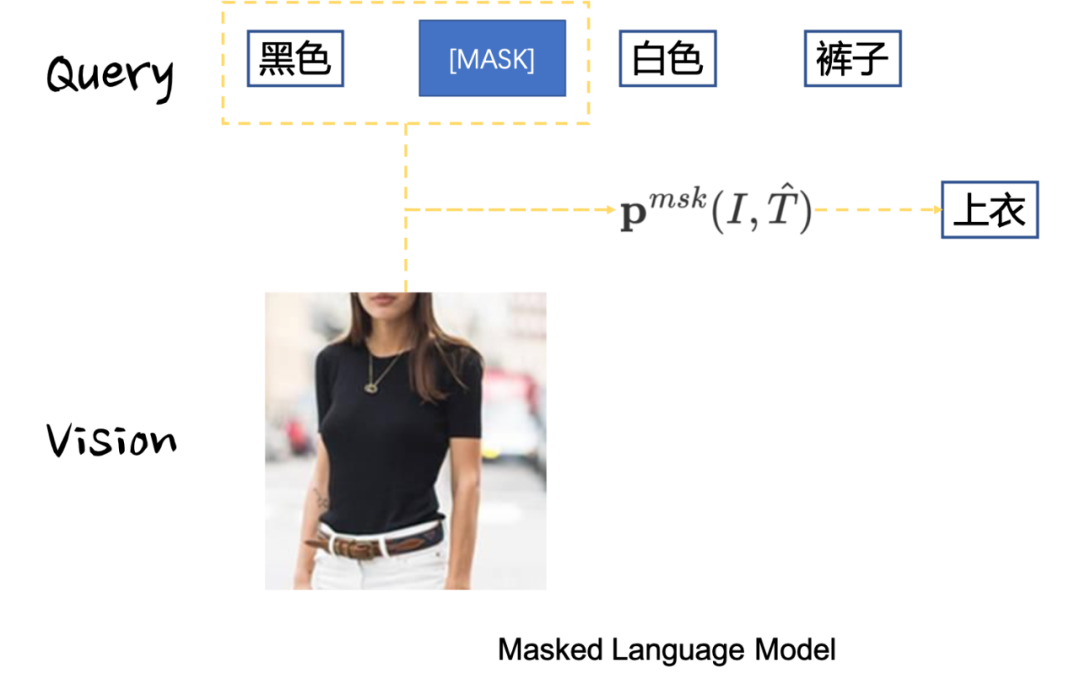
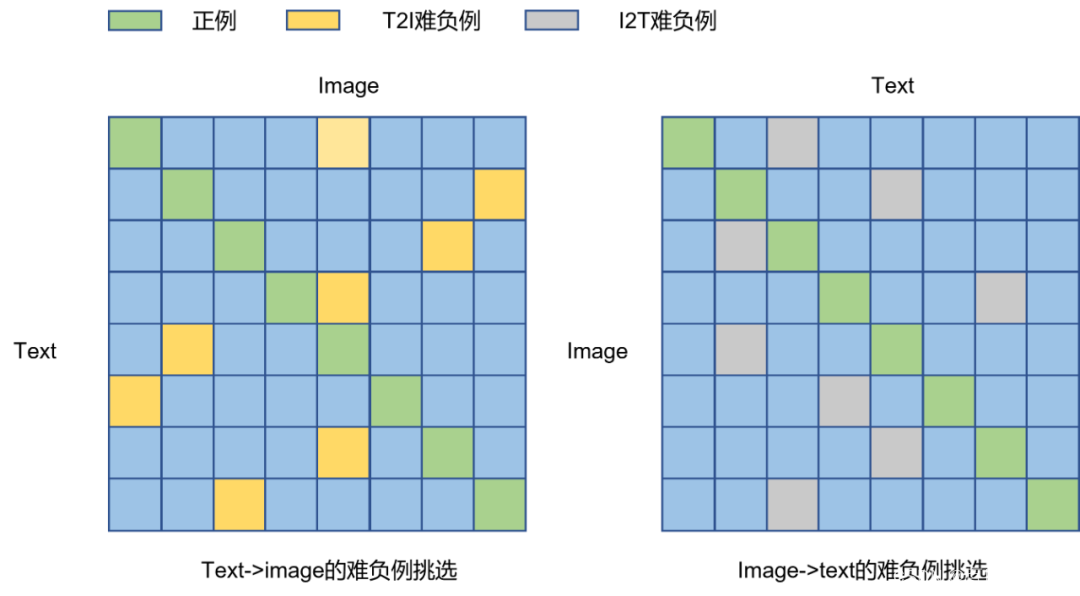
除了MLM损失,文章中还通过图文匹配损失(Image-Text Matching,ITM)对难负样本进行匹配学习,从而期望模型能够对难负样本有着更好的区分能力,从而弥补单塔模型无法进行难负样本选取的缺点,以提升多模态模型的语义对齐和语义融合能力。作者挑选难负样本的依据是根据双塔模型的打分,如Fig 6.23所示,可以挑选出同一个Query下面最为难的Image(打分最高,但却是预测错误的),也可以挑选出同个Image下最难的Query(论文中是根据打分大小设置概率进行采样得到的)。由此可以得到 N N N个正例和 2 N 2N 2N个难负例构成了ITM任务的输入,其损失如式子(6-17)所示。
L i t m = E ( I , T ) ∼ D H ( y i t m , p i t m ( I , T ) ) (6-17) \mathcal{L}_{itm} = \mathbb{E}_{(I,T)\sim D} H(\mathbf{y}^{itm}, \mathbf{p}^{itm}(I,T)) \tag{6-17} Litm=E(I,T)∼DH(yitm,pitm(I,T))(6-17)
最后的预训练阶段损失由以上三个损失构成,如式子(6-18)所示:
L = L i t c + L m l m + L i t m (6-18) \mathcal{L} = \mathcal{L}_{itc}+\mathcal{L}_{mlm}+\mathcal{L}_{itm} \tag{6-18} L=Litc+Lmlm+Litm(6-18)
用于预训练的图文数据大多来自于互联网,通常都是所谓的弱视觉语义数据集,文本中可能有些词语和图片的视觉语义是毫无关系的,图片也可能包含有文本中完全没提到的东西。对于ITC损失而言,一个图片的负样本文本也有可能能够匹配上这个图片(特别是如果该图文对数据来自于用户点击数据);对于MLM损失而言,被掩膜掉的令牌也许被其他令牌替代也能对图像进行描述(甚至可能更合适)。作者认为,在ITC和MLM任务中采用one-hot标签进行训练会对所有的负例进行打压,而不考虑这些负例倒底是不是真正的『负例』。为了解决这个问题,作者提出动量编码器可以看成是单模态/多模态编码器的一种指数滑动平均版本(exponential-moving-average),可以通过动量编码器去生成ITC和MLM任务的『伪标签』。通过动量编码器,我们有动量编码器打分:
s ′ ( I , T ) = g v ′ ( v c l s ′ ) T g w ′ ( w c l s ′ ) s ′ ( T , I ) = g w ′ ( w c l s ′ ) T g v ′ ( v c l s ′ ) (6-19) \begin{aligned} s^{\prime}(I,T) &= g^{\prime}_{v}(\mathbf{v}_{cls}^{\prime})^{\mathrm{T}} g^{\prime}_{w}(\mathbf{w}_{cls}^{\prime}) \\ s^{\prime}(T,I) &= g^{\prime}_{w}(\mathbf{w}_{cls}^{\prime})^{\mathrm{T}} g^{\prime}_{v}(\mathbf{v}_{cls}^{\prime}) \end{aligned} \tag{6-19} s′(I,T)s′(T,I)=gv′(vcls′)Tgw′(wcls′)=gw′(wcls′)Tgv′(vcls′)(6-19)
将(6-19)中的 s ′ s^{\prime} s′替代式子(6-14)中的 s s s,我们得到伪标签 q i 2 t , q t 2 i \mathbf{q}^{i2t}, \mathbf{q}^{t2i} qi2t,qt2i,那么 I T C M o D ITC_{MoD} ITCMoD损失定义为:
L i t c m o d = ( 1 − α ) L i t c + α 2 E ( I , T ) ∼ D [ K L ( q i 2 t ( I ) ∣ ∣ p i 2 t ( I ) ) + K L ( q t 2 i ( T ) ∣ ∣ p t 2 i ( T ) ) ] (6-20) \mathcal{L}_{itc}^{mod} = (1-\alpha)\mathcal{L}_{itc}+\dfrac{\alpha}{2}\mathbb{E}_{(I,T) \sim D} [KL(\mathbf{q}^{i2t}(I) || \mathbf{p}^{i2t}(I)) + KL(\mathbf{q}^{t2i}(T) || \mathbf{p}^{t2i}(T))] \tag{6-20} Litcmod=(1−α)Litc+2αE(I,T)∼D[KL(qi2t(I)∣∣pi2t(I))+KL(qt2i(T)∣∣pt2i(T))](6-20)
类似的, M L M M o D MLM_{MoD} MLMMoD损失可以定义为:
L m l m m o d = ( 1 − α ) L m l m + α E ( I , T ^ ) ∼ D K L ( q m s k ( I , T ^ ) ∣ ∣ p m s k ( I , T ^ ) ) (6-21) \mathcal{L}_{mlm}^{mod} = (1-\alpha)\mathcal{L}_{mlm} + \alpha\mathbb{E}_{(I,\hat{T}) \sim D} KL(\mathbf{q}^{msk}(I, \hat{T}) ||\mathbf{p}^{msk}(I, \hat{T})) \tag{6-21} Lmlmmod=(1−α)Lmlm+αE(I,T^)∼DKL(qmsk(I,T^)∣∣pmsk(I,T^))(6-21)
为何动量编码器可以生成所谓的『伪标签』呢?当数据量比较大的时候,编码器可能在不同的step下见到同一个文本text与不同类型的图片的数据对。考虑一种情况,文本text描述中存在两个实体 鸭子和橙子,在某个数据对中{text,image A}中image A存在鸭子,而只存在橙子的image B可能就被认为是负例了;在某个数据对{text,image B}中存在橙子,而只存在鸭子的image A可能就被视为负例了。通过动量更新编码器,可以看成通过一个动量更新的过程中的时间平滑系数 γ \gamma γ,将不同step下遇到的{text,image A}, {text, image B}样本的标签信息都考虑了,因此可以视为时候『伪标签』信息。
ERNIE-VIL 2.0
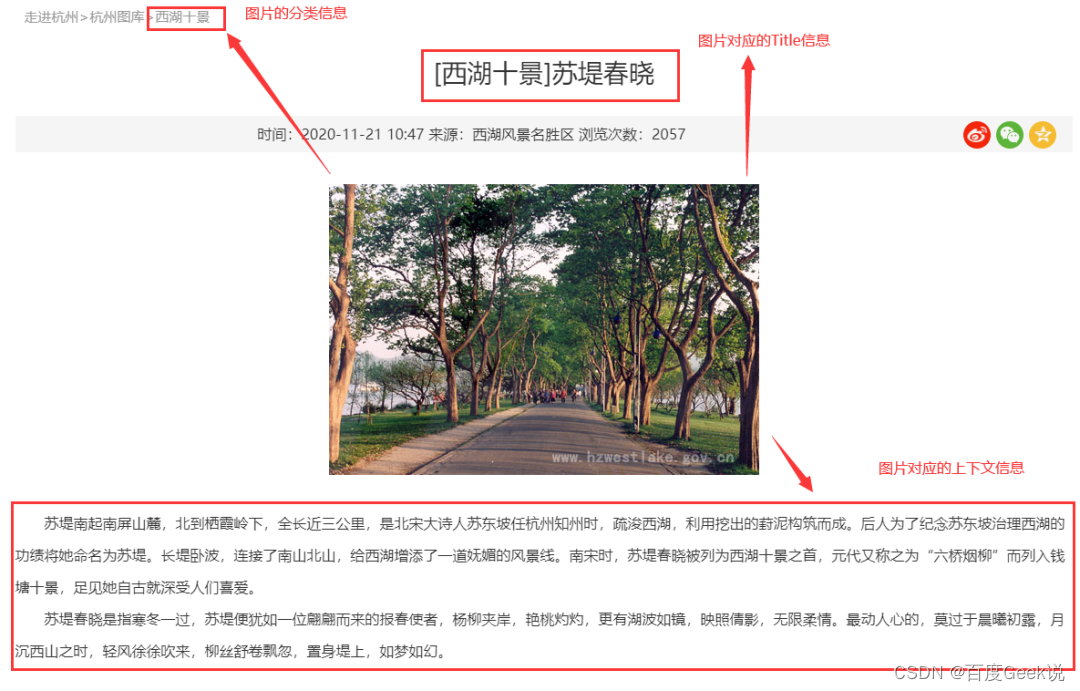
之前的工作大部分只采集了caption信息组成图文对进行预训练,不免浪费了互联网图片中丰富的文本信息。如Fig 6.25所示,网页中的图片附带有着众多不同类型的文本信息可供使用,如图片的标题,图片的类别信息(可以是用户自选的),图片对应的上下文信息等,这些文本信息或多或少都与图片有所关联,在预训练中或多或少能提供帮助。不仅如此,甚至还可以用Object Detector进行图片中的实体识别,对图片进行打tag,生成一系列文本。同时,在商业系统中还能通过点击信号,挖掘出用户query与图片的样本对<query, image>。
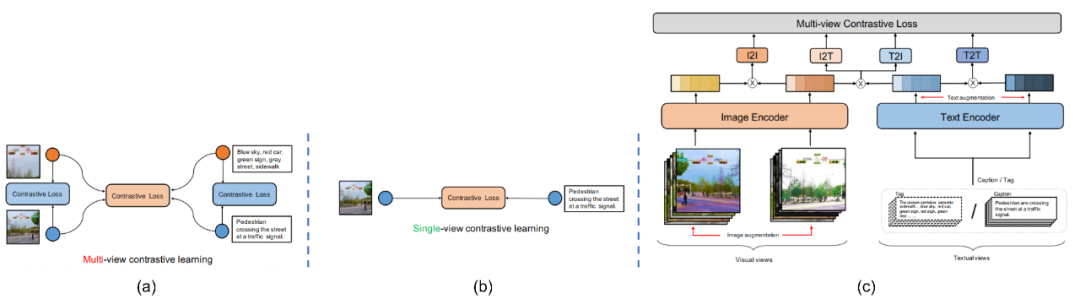
在ERNIE VIL 2.0 [19]中,作者采用了双塔模型,同时采用了CLIP的方式,通过使用112张A100 GPU和all_gather操作,将总batch size提高到了7168。并且,最主要的是,在该论文中作者提出了“多视角对比学习(multi-view contrastive learning)”,其中的多视角指的是同一个模态中(图片、文本),不同视角的表达。比如对于图片而言,可以对图片进行图片增强(image augmentation),比如图片抖动,随机crop等。通过这种手段能生成两个视角的图片,表示原图,表示进行图片增强后的图片。对于文本模态而言,作者认为除了caption之外,这个图片的其他可用文本信息就可视为是多视角文本信息,比如在本文中,作者认为图片的tags是其多视角文本。那么,为图片的caption,为图片的tags(可以是用户自己选定的,也可以是Object Detector等模型生成的)。如Fig 6.26 所示,与单视角对比学习相比,同个模态内和跨模态间都可以组建对比损失。如公式(6-22)所示,其中为正样本对组合,为负样本对组合,其中的表示样本编号。如公式(6-23)所示,通过infoNCE损失对(6-22)中的各类型pair进行损失建模。整个ERNIE-VIL 2.0的模型结构如Fig 6.26 ©所示。
S + = { ( I v 1 i , I v 2 i ) , ( T v 1 i , T v 2 i ) , ( I v 1 i , T v 1 i ) , ( T v 1 i , I v 1 i ) } S − = { ( I v 1 i , I v 2 j ) , ( T v 1 i , T v 2 j ) , ( I v 1 i , T v 1 j ) , ( T v 1 i , I v 1 j ) } , i ≠ j (6-22) \begin{align} S^{+} &= \{(I_{v1}^{i}, I_{v2}^{i}), (T_{v1}^{i}, T_{v2}^{i}), (I_{v1}^{i}, T_{v1}^{i}), (T_{v1}^{i}, I_{v1}^{i})\} \\ S^{-} &= \{(I_{v1}^{i}, I_{v2}^{j}), (T_{v1}^{i}, T_{v2}^{j}), (I_{v1}^{i}, T_{v1}^{j}), (T_{v1}^{i}, I_{v1}^{j})\}, i \neq j \end{align} \tag{6-22} S+S−={(Iv1i,Iv2i),(Tv1i,Tv2i),(Iv1i,Tv1i),(Tv1i,Iv1i)}={(Iv1i,Iv2j),(Tv1i,Tv2j),(Iv1i,Tv1j),(Tv1i,Iv1j)},i=j(6-22)
L ( x , y ) = − 1 N ∑ i N log exp ( ( h x i ) T h y i / τ ) ∑ j = 1 N exp ( ( h x i ) T h y j / τ ) (6-23) L(x, y) = -\dfrac{1}{N} \sum_{i}^N \log\dfrac{\exp((h_{x}^i)^{\mathrm{T}} h_{y}^i/\tau)}{\sum_{j=1}^N \exp((h_{x}^i)^{\mathrm{T}} h_{y}^j/\tau)} \tag{6-23} L(x,y)=−N1i∑Nlog∑j=1Nexp((hxi)Thyj/τ)exp((hxi)Thyi/τ)(6-23)
实验结果就不贴出来了,笔者感觉这种方法比较有意思的是,它可以通过多视角文本样本扩充一些抽象实体的语义。如Fig 6.27 所示,对于(a)中的caption提到的“Dinner”,“晚餐”本质上是一个抽象的实体,没有具象化到某一类型具体的食物,而通过Object Detector得到的tag,我们能知道图片中存在西红柿,洋葱,食物等等实体,通过建立caption和tag的关联,可以让模型学习到Dinner的具象化语义。对于Fig 6.27 (b)和©而言,BMW E90是宝马的其中一个型号,而Gatos Manx应该是主人给猫取的爱称。汽车型号这种语义非常稀疏,而猫的姓名更是稀疏无比,在训练样本中甚至可能没有其他共现的文本出现了,这种语义很难学习出来。而通过建立caption和tag的关联,可以让模型学习到BWM E90是一种白色汽车,而Gatos Manx是一只猫(当然这个有风险,也许有人也叫这个名字呢,emm,但是如同“旺财”“福贵”在猫狗上取名的概率更大一样,这样学习出来的bias似乎也并不是没有可取之处呢?)。因此通过多视角文本的多模态预训练方式,可以扩充抽象语义,学习出稀疏语义。这是ERNIE VIL 2.0一文给予笔者最大的启发。

FLIP
之前我们在讨论单模态自监督建模的时候,曾经提到过MAE和VideoMAE模型,从Fig 2.9 (b)中其实不难发现,即便对图片的大部分区域(80%)进行掩膜,其图片的像素级别重建结果,都仍具备充足的视觉语义信息。这一点容易理解,图片本身就是信息冗余量极大的信息媒介,对其大部分进行掩膜仍然有足够的信息泄漏其视觉语义信息,因此在之前的工作也不乏有进行稀疏令牌化的处理。我们在之前提到将视觉端特征完全固定住的LiT模型,那么是否有一种折中方案,既能减少视觉端模型的资源消耗,又能对视觉端模型也同时进行学习呢?结合以上事实和需求,有学者提出仿照MAE,在CLIP的基础上对输入图片进行大面积的掩膜,将未被掩膜的图片块作为视觉端模型的输入,从而极大程度地减少资源的占用,这就是Fast Language-Image Pretraining(FLIP)[24] 的建模思路。
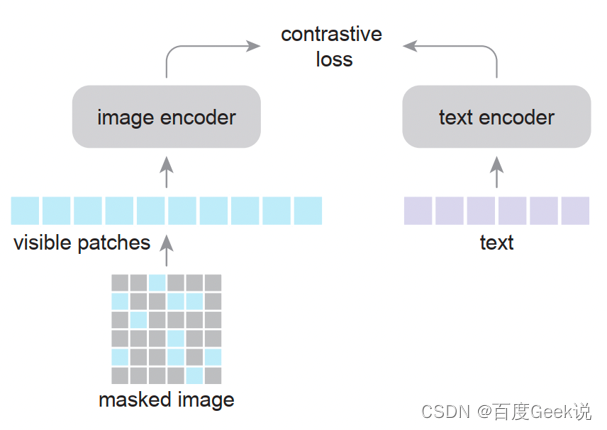
如Fig 6.28所示,在FLIP中作者将图片均匀分块,并且将其大部分进行随机掩膜(50%)后,将未被掩膜部分按序排列作为图片编码器的输入,通过对比学习方式进行建模,通过这种方法大幅度减少了图片端模型的显存和计算资源需求,因此能做到:
- 采用更大的
batch size - 采用更大的视觉端模型
- 能够采用更大的数据集进行预训练
如Fig 6.29所示,采用了FLIP方法后(掩膜50%或75%),能够在更短的时间内达到和原CLIP模型相同的效果,在相同训练时间内,能够达到更好的效果,加速将近3.7倍。
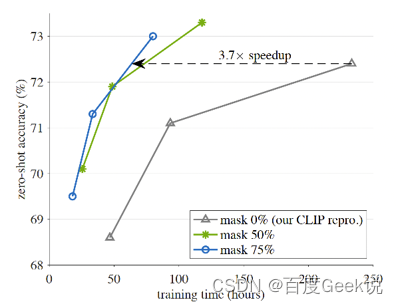
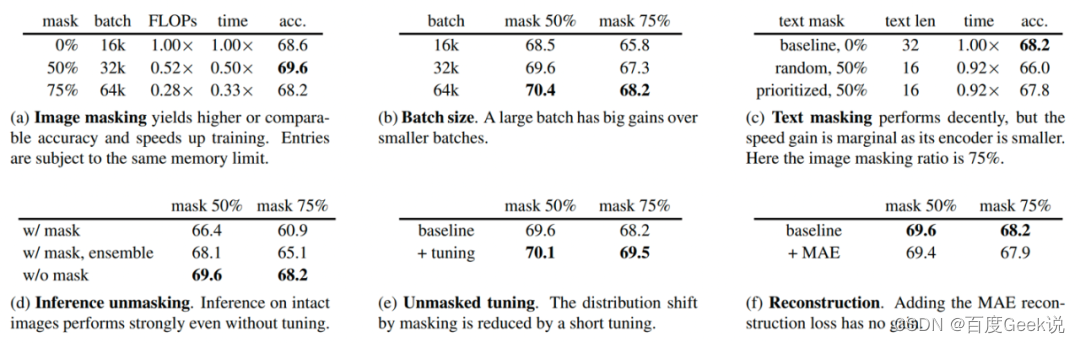
FLIP的方法很直接简单,一贯延续了凯明大佬的风格,在论文里面进行了极为细致的试验,我们这里只摘出一些试验进行分析。如Fig 6.30所示,这是FLIP在ImageNet-1K上进行zero-shot消融试验的结果,其中分别探索了:
- 掩膜比例的影响:掩膜达到50%的比例能够取得最好的效果,大部分图片块对于对比学习的语义对齐而言似乎都是冗余的。
- batch size的影响:FLIP允许batch size开到64k,我们发现无论是在掩膜比例在50%或是75%,果然batch size越大效果越好。
- 是否对文本进行掩膜:文本是一种信息密度极大的媒介,直观上看对其进行掩膜会有较大损失,从实验(c)来看也确实如此,不对其进行掩膜的效果是最好的。
- 在推理阶段是否进行反掩膜:在推理阶段为了图片信息的完整性,直观的做法就是对其掩膜过程进行逆转,用完整的图片进行推理。从试验(d)上看,采用了反掩膜的方式推理效果最好。
- 是否进行反掩膜微调:由于推理时候采用了反掩膜的操作,为了预训练和推理的任务分布一致性,直观来看应该在FLIP预训练完后,对其进行少量的同分布微调。在试验(e)中,作者对FLIP预训练后的结果进行了少量的反掩膜微调,结果确实比基线为佳。
- 是否引入视觉重建任务:是否要在对比学习过程中也引入MAE的重建损失呢?试验(f)告诉我们是不需要的,也许MAE的重建任务偏向于像素级重建,而对比学习学习的语义对齐并不依赖于这种低层视觉语义吧。
再让我们看到FLIP和CLIP的实验对比,如Fig 6.31所示,作者复现了CLIP,同时也采用了OpenCLIP的结果进行对比,采用了FLIP之后在L/14和L/16设置下都能超越CLIP和openCLIP的结果。这样看来FLIP也是值得探索的一种方法。

BEiT v3
我们前文介绍过了对比学习损失在语义对齐任务中的惊艳效果,也早就讨论了为何ITM和MLM损失在语义对齐任务上为何显现劣势,然而是否ITM和MLM损失就真的不能建模语义对齐呢?或者说,这两种损失在语义对齐任务上是否就注定是低效的呢?有趣的是,BEiT v3模型 [68] 似乎给了我们一个不一样的惊喜回答,如Fig 6.32所示,只采用了MLM损失进行建模的BEiT v3模型可谓是六边形战士,在众多视觉、多模态任务上都超越了前辈,达到了state of the art的程度。为何不采用大规模对比学习也可以达到如此好的语义对齐效果?那我们前文讨论的是否是错误的呢?且听笔者慢慢道来。
正如BEiT这个名字所预示的,BEiT v3是BEiT和BEiT v2模型的后续工作,这一系列的一个特点就是采用了视觉的稀疏令牌化去表征视觉特征,当然BEiT v3也不能免俗,同样是深深依赖于视觉稀疏化特征。在BEiT v3中,作者将视觉信息看成是一种“外语”(Imglish),因此将其进行视觉令牌化,令牌化的工具不再采用偏向于像素重建的VQ-VAE方法,而是采用了BEiT v2中所用的基于视觉语义的重建方法,具体请参考第0x01章的内容。通过视觉的稀疏令牌化,此时文本和图片都转换为了一串离散令牌,然后通过Multiway Transformer进行图片、文本、图文对的建模,如Fig 6.33所示。
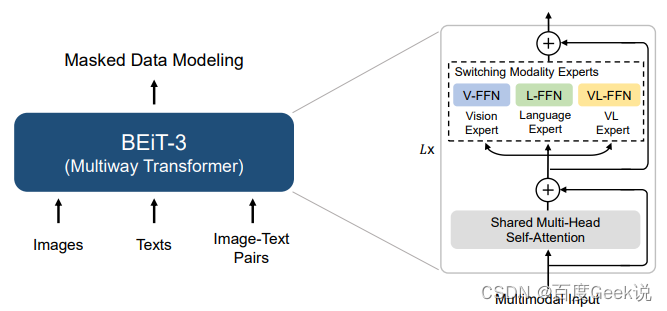
具体来说,如Fig 6.30所示,BEiT v3的前 ( L − F ) x (L-F)x (L−F)x层都由视觉专家V-FFN11和文本专家L-FFN组成,在最上 x x x层则是多模态融合专家VL-FFN,此处 x = 3 x=3 x=3。且不论V-FFN、L-FFN还是VL-FFN,其实本质就是一个Feed-Forward Network,只不过对于不同模态的输入会通过训练控制,路由到不同的FFN模块,因此而得名罢了。我们不妨数学形式化表达下整个输入过程,假如我们的文本令牌记为 T ∈ R M × 1 T\in \mathbb{R}^{M \times 1} T∈RM×1,视觉令牌表示为 V ∈ R N V \in \mathbb{R}^{N} V∈RN,其中 M M M和 N N N为令牌的数量。通过分别查表后,得到文本和视觉的Embedding向量,分别表示为 T e ∈ R M × d T_{e} \in \mathbb{R}^{M \times d} Te∈RM×d和 V e ∈ R N × d V_{e} \in \mathbb{R}^{N \times d} Ve∈RN×d,其图文对Embedding向量不妨表示为两者的拼接,也即是有 V L e = [ V e ; T e ] ∈ R ( M + N ) × d VL_{e} = [V_{e};T_{e}] \in \mathbb{R}^{(M+N) \times d} VLe=[Ve;Te]∈R(M+N)×d。
Fig 6.33中的Shared Multi-Head Self-Attention模组的作用是,不区分文本还是图片亦或是图文对模态,都同样进行多头自注意机制处理,因此得名shared,也即是公式(6-24)中的 X X X可以为 T e T_{e} Te、 V e V_{e} Ve或者是 V L e VL_{e} VLe。
O = s o f t m a x ( Q K T d k + a t t n ) V Q = X W Q ∈ R N × D K = X W K ∈ R N × D V = X W V ∈ R N × D O = X W Q ∈ R N × D (6-24) \begin{align} O &= \mathrm{softmax}(\dfrac{QK^{\mathrm{T}}}{\sqrt{d_k}}+attn)V \\ Q &= XW_{Q}\in \mathbb{R}^{N \times D} \\ K &= XW_{K}\in \mathbb{R}^{N \times D} \\ V &= XW_{V}\in \mathbb{R}^{N \times D} \\ O &= XW_{Q}\in \mathbb{R}^{N \times D} \\ \end{align} \tag{6-24} OQKVO=softmax(dkQKT+attn)V=XWQ∈RN×D=XWK∈RN×D=XWV∈RN×D=XWQ∈RN×D(6-24)
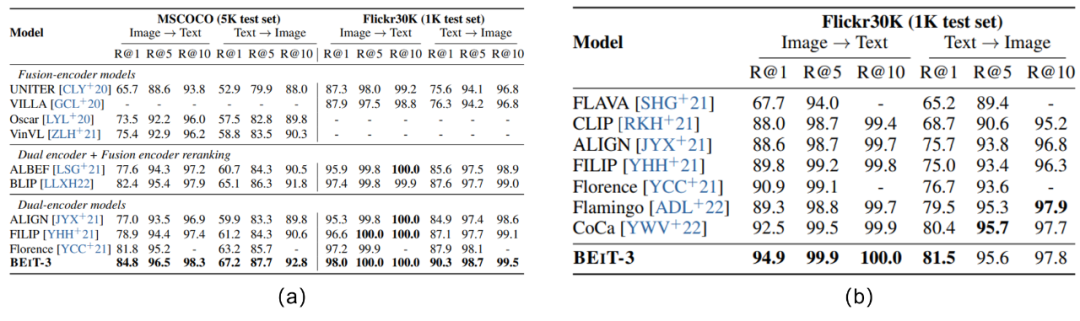
在预训练的时候,只采用了Masked Data Modeling的方式进行建模,而这个本质和MLM是一样的。具体来说,就是甭管单模态输入(文本或者图片),还是多模态输入(图文对),都只对其中的文本/图片进行掩膜操作,并且训练模型尝试进行掩膜令牌的重建。作者对单模态的文本输入进行 15 % 15\% 15%概率的随机掩膜,对于多模态下的文本输入则采用了 50 % 50\% 50%概率的随机掩膜,对于图片的掩膜策略则参考了BEiT v2的方案,这里不再赘述。在BEiT v3中,作者将batch size设置为了6144,也即是2048个单模态文本、2048个单模态图片和2048个多模态图文对。这个远小于典型的对比学习batch size12,而从论文的一系列试验结果来看,如Fig 6.35和Fig 6.32所示,BEiT v3的性能在诸多视觉和多模态任务上都超越了前辈,其中也包括采用了大规模对比学习的CLIP,如Fig 6.35 (b)所示,甚至在CLIP引以为豪的zero-shot实验场景中,BEiT v3都占据了绝对的优势。
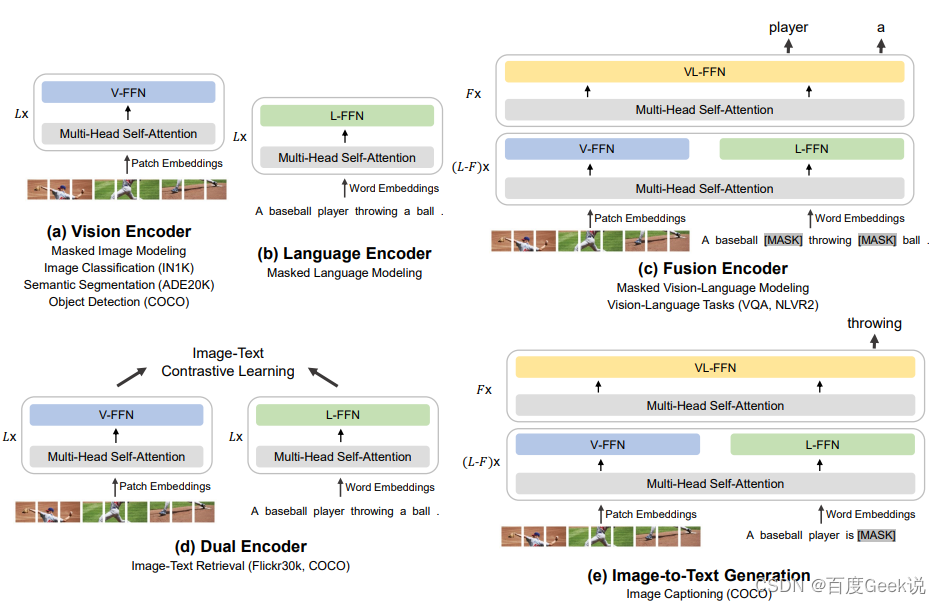
从以上的讨论来看,BEiT v3可谓是大道至简,其只采用了MLM损失进行建模,不仅建模了单模态的表征,还同时建模了语义对齐。如Fig 6.35所示,BEiT v3在检索任务中无论是finetune后结果还是zero-shot结果,都能达到SOTA的程度。为何BEiT v3和我们之前讨论的,同为采用了MLM建模的UNITER表现差别如此之大?难道我们之前对MLM的判断有失偏颇?笔者认为,主要区别在于BEiT v3采用了足够好的视觉语义稀疏化特征,将图片块转化为了稀疏令牌进行MLM方式建模,这样有几个好处:
- 视觉的稀疏令牌和文本的令牌并无本质区别,可视为是同质的输入,对其进行MLM建模类似于是文本的自监督训练,而众所周知,文本的MLM自监督任务已经是目前文本预训练的主流范式之一了。
- 输入单元从图片块变成了单个令牌,训练效率更高,在相同的资源消耗下,可以进行更多次训练。
- 基于视觉令牌的预测,比起像素级预测,更具有语义信息。
从BEiT v3的做法来看,我们发现MLM即便是一种语义融合的建模方式,也并不是不能对语义对齐进行建模,通过引入高度语义化的视觉令牌,再进行跨模态的MLM任务,也能够高效地学习到视觉令牌与文本令牌的语义对齐与语义融合关系13。这样看来,语义融合的损失也并不是不能高效地建模语义融合,于是我们对语义融合和语义对齐建模的认知又更进一步,这两者并不是泾渭分明的彼与此,而是紧密相关的。
视文模型
CLIP4clips
我们在之前介绍了很多CLIP之后的图文匹配模型,在大量图文数据的大规模对比学习预训练下,CLIP的图片语义对齐能力已经很强了,是否能将图片CLIP的能力迁移到视频上呢?如果将视频看成是图片在时间轴上的展开,那么将图片CLIP迁移到视频上的做法是自然而然的,在CLIP4clips [41] 中对这个做法进行了探索。如Fig 6.28所示,作者将图片CLIP预训练好的图片ViT模型参数,直接加载到视频ViT模型中,而此处的视频ViT模型,其实也是单独对视频中的每一帧进行特征提取罢了。让我们进行形式化表达,用 x ∈ R T × W × H × 3 \mathbf{x} \in \mathbb{R}^{T \times W \times H \times 3} x∈RT×W×H×3表示当前输入的视频,其有 T T T帧,对其进行划分patch,每个patch的大小则为 x i ∈ R T × K W × K H × 3 , i = 0 , ⋯ , M \mathbf{x}_{i} \in \mathbb{R}^{T \times K_{W} \times K_{H} \times 3}, i=0,\cdots,M xi∈RT×KW×KH×3,i=0,⋯,M,将其作为ViT的输入(当然,在此之前还需要进行拉直和线性映射),我们取模型的[CLS]向量作为视频的特征输出,表示为 y ∈ R T × D \mathbf{y}\in \mathbb{R}^{T \times D} y∈RT×D,其中的 D D D为Embedding维度。因此,视频的每一帧相当于都单独经过了ViT模型进行特征提取。在这个基础上,作者在这个工作里面主要探索了两点:
- 我们在图片CLIP预训练好的情况下,如何建模视频的时序信息呢?
- 为了减缓图片和视频数据上分布差异,图片CLIP是否需要在视频数据上进行后预训练(post-pretrain)呢?
我们接下来对两个问题进行探索。
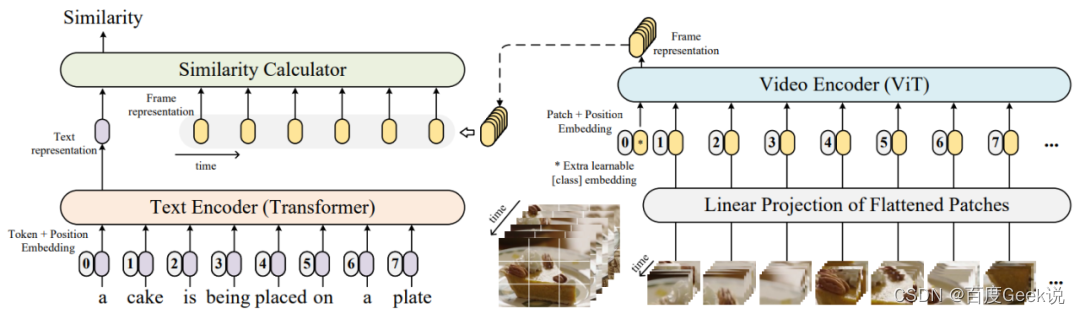

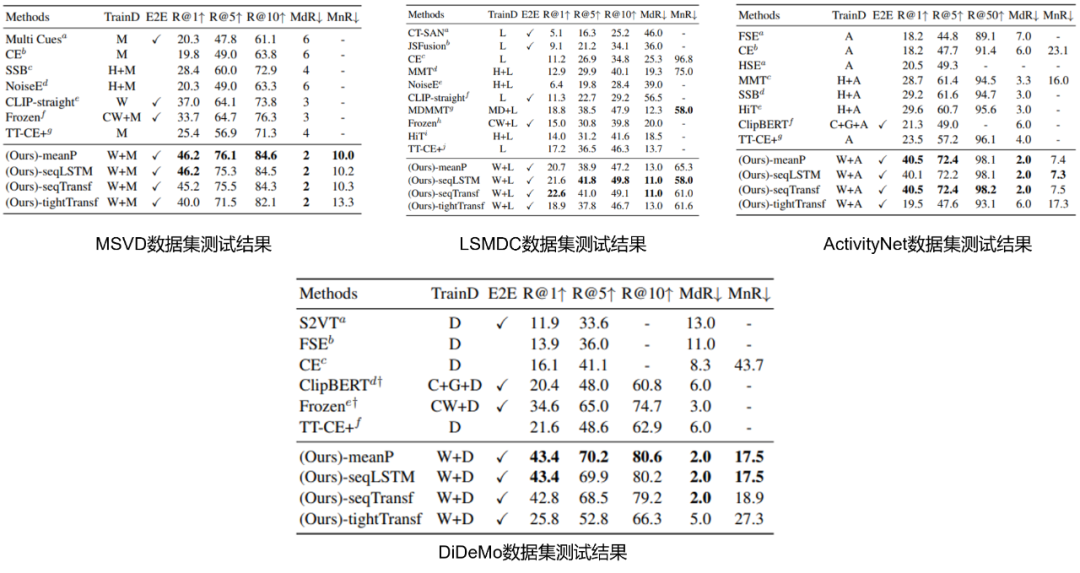
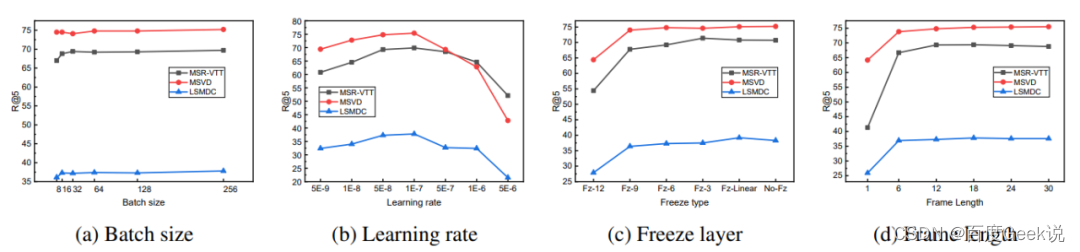
- 在不同数据集上,
meanPool和seqLSTM/seqTransf各有攻城略地之处,在较小型的数据集上,没有引入额外参数的meanPool具有优势(比如MSVD数据集只有不到2000个视频,每个视频时长约60秒)。在数据量较多时如LSMDC数据集(含有约12万视频,每个视频时长在2-30秒之间)和ActivityNet数据集(含有约20000个youtube视频),DiDeMo数据集(含有10000个视频),能看到seqLSTM和seqTransf的效果更佳,对比CLIP-straight的结果,我们能发现虽然同为视觉信息,图片和视频的差别是很大的,因此有必要引入额外的模块对视频时序信息进行建模。 - 在所有四个测试集中,参数量最大的
tightTransf方式的效果都是最差的,由于该模式引入了过多的未经过预训练的参数,因此其训练需要有更多的数据支持,在已经预训练好的模型中,引入新的参数应该尽可能地谨慎。
X-CLIP
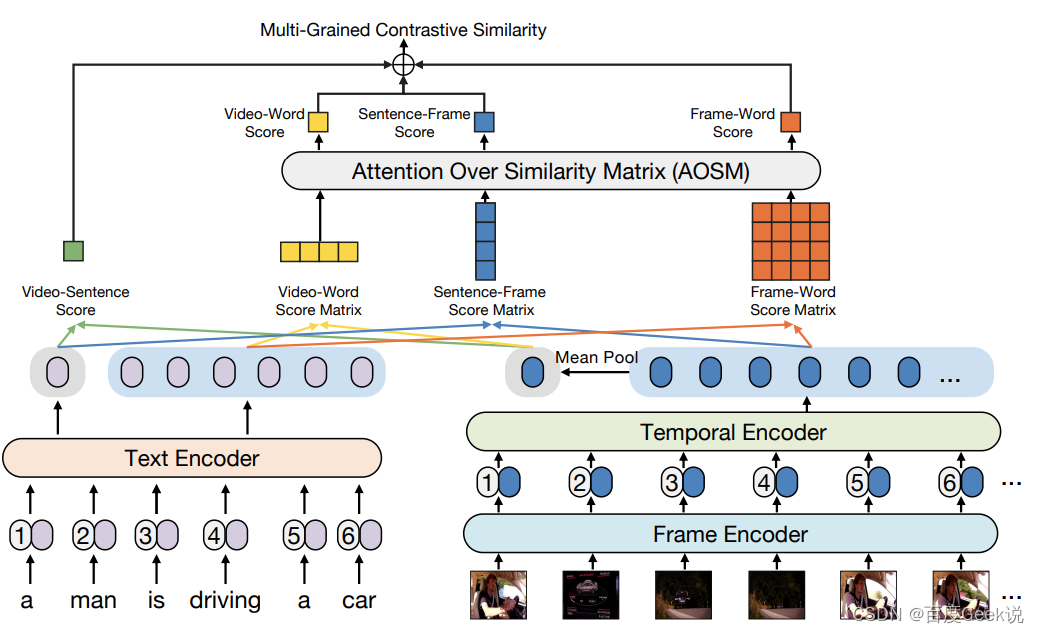
我们在FILIP这篇工作中曾经介绍过图片与文本的细粒度交互建模方式,那么延伸到视频-文本也是有相似的工作的,X-CLIP [38]就是对文本和视频进行多粒度建模的工作。如Fig 6.33所示,通过组合文本端的句子/词、视觉端的视频/帧,可以形成四种不同类型的pair,其中包含有三种不同的粒度。

如Fig 6.34所示,从模型的建模方式来看,无论是视觉端还是文本端都采用了Transformer进行建模,其中视觉端是ViT模型。为了获得文本和视频的细粒度信息,在文本侧不仅利用了[CLS]的输出特征作为句子粒度表征,同样对各个位置的token输出特征作为字词粒度表征。对于视觉端而言,不同帧位置的Transformer特征输出我们视为是帧粒度表征,而对这些表征进行mean pool后结果我们视为是视频粒度表征。且让我们形式化表达,我们用 v ′ ∈ R D v^{\prime} \in \mathbb{R}^{D} v′∈RD表示视频粒度表征, t ′ ∈ R D t^{\prime} \in \mathbb{R}^{D} t′∈RD表示句粒度表征, F ∈ R n × D F \in \mathbb{R}^{n \times D} F∈Rn×D表示帧粒度表征, T ∈ R m × D T \in \mathbb{R}^{m \times D} T∈Rm×D表示字词粒度表征,那么两个模态的粗细表征之间彼此可以构成对比,如下所示
S V − S = ( ( v ′ ) T ( t ′ ) ) ∈ R 1 S V − W = ( T v ′ ) T ∈ R 1 × m S F − S = F t ′ ∈ R n × 1 S F − W = F T T ∈ R n × m (6-25) \begin{align} S_{V-S} &= ((v^{\prime})^{\mathrm {T}}(t^{\prime})) \in \mathbb{R}^{1} \\ S_{V-W} &= (Tv^{\prime})^{\mathrm{T}} \in \mathbb{R}^{1 \times m} \\ S_{F-S} &= Ft^{\prime} \in \mathbb{R}^{n \times 1} \\ S_{F-W} &= FT^{\mathrm{T}} \in \mathbb{R}^{n \times m} \end{align} \tag{6-25} SV−SSV−WSF−SSF−W=((v′)T(t′))∈R1=(Tv′)T∈R1×m=Ft′∈Rn×1=FTT∈Rn×m(6-25)
除了粗粒度对比打分 S V − S S_{V-S} SV−S是一个数值打分外,其他细粒度和交叉粒度打分都为矩阵或者向量,需要采用一定的方法对其进行聚合成数值打分后,才能加和起来形成最终的多粒度对比相似度打分(Multi-grained Contrastive Similarity),那么将这个聚合的过程称之为Attention Over Similarity Matrix(AOSM),如公式(6-26)所示。
S V − S ′ = ( ( v ′ ) T ( t ′ ) ) ∈ R 1 S V − W ′ = ∑ i = 1 m exp ( S V − W ( 1 , i ) / τ ) ∑ j = 1 m exp ( S V − W ( 1 , j ) / τ ) S V − W ( 1 , i ) ∈ R 1 S F − S ′ = ∑ i = 1 n exp ( S F − S ( i , 1 ) / τ ) ∑ j = 1 n exp ( S F − S ( j , 1 ) / τ ) S F − S ( i , 1 ) ∈ R 1 (6-26) \begin{align} S^{\prime}_{V-S} &= ((v^{\prime})^{\mathrm {T}}(t^{\prime})) \in \mathbb{R}^{1} \\ S^{\prime}_{V-W} &= \sum_{i=1}^{m} \dfrac{\exp(S_{V-W}(1,i)/\tau)}{\sum_{j=1}^{m} \exp(S_{V-W}(1,j)/\tau)} S_{V-W}(1, i) \in \mathbb{R}^{1} \\ S^{\prime}_{F-S} &= \sum_{i=1}^{n} \dfrac{\exp(S_{F-S}(i,1)/\tau)}{\sum_{j=1}^{n}\exp(S_{F-S}(j,1)/\tau)} S_{F-S}(i,1) \in \mathbb{R}^{1} \end{align} \tag{6-26} SV−S′SV−W′SF−S′=((v′)T(t′))∈R1=i=1∑m∑j=1mexp(SV−W(1,j)/τ)exp(SV−W(1,i)/τ)SV−W(1,i)∈R1=i=1∑n∑j=1nexp(SF−S(j,1)/τ)exp(SF−S(i,1)/τ)SF−S(i,1)∈R1(6-26)
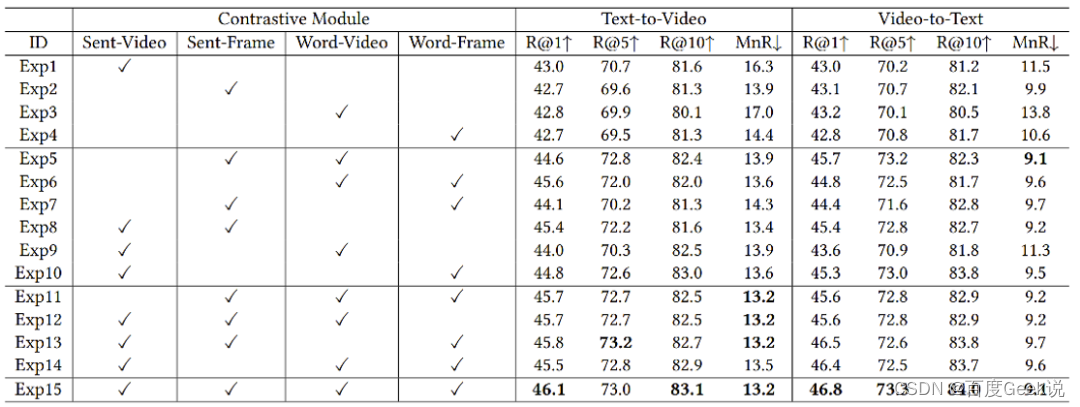
让我们用一个对比实验结束这一章的内容,如Fig 6.35所示,作者在MSR-VTT数据集上,通过组合这四种粒度的打分,进行消融试验对比。其中有几个观察:
- 观察Exp1 - Exp4,我们发现采用了细粒度Word-Frame对比的结果,不一定就比粗粒度的Sent-Video对比更好,笔者猜测,完全通过细粒度去建模对比,可能会缺失一些全局信息,对于检索而言可能并不是一件好事儿。
- 观察Exp4、Exp1与Exp7,我们发现一旦细粒度的Word-Frame对比加上Sent-Frame的交叉粒度对比,其表现就能超过粗粒度表现了,这意味着不仅需要单纯建模细粒度信息,同时还需要考虑粗粒度的信息(比如此时文本是句子粒度的)。同样的结论也可以对比试验Exp1、Exp4和Exp6,或者Exp1、Exp4和Exp10得到。
- 加上了粗粒度,细粒度和交叉粒度后的结果,在所有设定中取得了最优,给我们了一个启示,即便建模了细粒度,也不能抛弃粗粒度和交叉粒度的应用,否则可能学习不充分,导致不能得到最佳效果。
0x06 End of Journey
这是一个漫长的多模态旅途,感谢作为读者和笔者的你我,都能共同到达这里,我们本文算是告一段落了。我们在本文介绍了一些比较有启发性的工作,限于篇幅笔者不可能对浩如烟海的多模态文献都进行整理,作为一个总结,目前常见的多模态匹配模型的优化点,笔者认为可以大致归结为Table 7.1所示的几种方向,其中加粗表示本文进行过介绍。
| 多模态匹配模型优化方向 | 代表性工作举例 |
|---|---|
| 细粒度/多粒度建模 | FILIP [39], X-CLIP [38]… |
| 解耦负样本与batch size的关系/加速预训练 | WenLan 1.0 [18], WenLan 2.0, FLIP [24]… |
| 利用多视角数据 | ERNIE-VIL 2.0 [19]… |
| 扩大规模(Scaling) | CLIP [15], FLIP, ALIGN [17]… |
| 语义对齐+语义融合的重排序 | ALBEF [40], BLIP… |
| 统一的多模态框架 | Florence, FLAVA, BEiT v3, Coca… |
| 图片CLIP迁移到视频CLIP | CLIP4clips [41]… |
| 视觉稀疏令牌化 | VideoBERT [42], BEiT, BEiT v2, BEiT v3, VQ-VAE [45], BEVT, VIMPAC, dVAE… |
| 语义融合模型 | UNITER [43], OSCAR, UniVL… |
| 更好的语义对齐模型 | LiT [44]… |
| 多语言模型 | Wukong, Chinese CLIP, WenLan… |
| 损失函数优化 | CLIP-Lite [70] |
| … | … |
人类的感知是基于外界环境的多模态信息交互获得的,多模信息可谓是人类最为自然的输入模式,可能也是通往更深一层人工智能的通路。笔者深知多模态模型之复杂,因此本文只是对多模态语义匹配模型的一些简单总结,有非常多优秀的工作由于笔者精力、能力有限而未曾细读,实属遗憾,本文仅以抛砖引玉,如若某处能对读者有所帮助,则笔者撰此文的目的就达到了。
如若谈到这些工作的实际业务应用情况,笔者认为对于工业界的应用而言,这些学术论文大多不能直接迁移,原因很简单,业务场景与学术场景有太多gap了。以搜索场景为例子,我们举几个例子:
-
我们的文本侧大多不像是学术工作里面的caption文本,而是用户query,query与caption之间有着太大的gap,并且不同业务之间的用户query也有着显著的差别。一个模型和方法在某个业务上能work,并不代表其能在另一个业务上work,因此读者会发现本文,并没有特别关注到学术论文在benchmark上的指标,而是尝试去挖掘其中可能带来的启发,这些启发对我们认知业务与学术区别有所裨益,在结合了业务知识后能够帮助我们更好地推进业务模型优化。
-
不仅是文本侧有明显gap,在视频/图片上,学术数据和业务数据差别也非常大,在业务中更多的是所谓的弱视觉语义数据,因此我们会发现一些细粒度和多粒度的方法是非常值得尝试的。
-
业务数据规模太大也导致很多方法不能以合理的成本推广,并且受限于上线方式,很多学术前言探索需要落地,需要考虑很多架构优化和方法上的简化。
此处尚远不是终点啊,希望我们以后有机会在新的篇章里面继续我们的多模态旅途,路漫漫其修远兮,吾将上下而求索。
Appendix A. 数据集整理
人工标注数据集
| 数据集 | 数据量 |
|---|---|
| COCO Caption [11] | 533K |
| Visual Genome Dense Captions(VG Caption) [12] | 5.06M |
| Conceptual Captions(CC) [13] | 3.0M |
| SBU Caption [14] | 990K |
| … |
预训练数据集
| 数据集 | 数据量 | 公开与否 | 数据类型 |
|---|---|---|---|
| WIT-400M [15] | 400M | private | image-text |
| WuKong [16] | 100M | public available & Chinese | image-text |
| ALIGN [17] | 1.8B | private | image-text |
| WenLan [18] | 30M | private | image-text |
| ERNIE-VIL 2.0 [19] | 1.5B | private | image-text |
| LiT [20] | 4B | private | image-text |
| YFCC100M [21] | 100M | public available | image-text |
| CC12M [22] | 12M | public available | image-text |
| HowTo100M [23] | 100M | public available | video-text |
| LAION-400M [24] | 400M | private | image-text |
| LAION-2B [24] | 2B | private | image-text |
| … |
Reference
[1]. https://fesianxu.github.io/2022/12/24/video-understanding-20221223/, https://blog.csdn.net/LoseInVain/article/details/105545703,万字长文漫谈视频理解
[2]. https://fesianxu.github.io/2022/12/24/general-video-analysis-1-20221224/, 视频分析与多模态融合之一,为什么需要多模态融合
[3]. https://github.com/basveeling/pcam, PatchCamelyon (PCam)
[4]. https://github.com/phelber/EuroSAT, EuroSAT : Land Use and Land Cover Classification with Sentinel-2
[5]. https://ai.facebook.com/blog/hateful-memes-challenge-and-data-set/, Hateful Memes Challenge and dataset for research on harmful multimodal content
[6]. Yu, F., Tang, J., Yin, W., Sun, Y., Tian, H., Wu, H., & Wang, H. (2021, May). Ernie-vil: Knowledge enhanced vision-language representations through scene graphs. In Proceedings of the AAAI Conference on Artificial Intelligence (Vol. 35, No. 4, pp. 3208-3216). Short for ERNIE-VIL 1.0
[7]. https://www.bilibili.com/video/BV1644y1S7H3, 我想,这以后便是在农村扎根了吧
[8]. https://www.bilibili.com/video/BV1Mg411J7kp, 自制钓鱼佬智能快乐竿
[9]. https://fesianxu.github.io/2022/12/24/nonlinear-struct-video-20221224/, https://blog.csdn.net/LoseInVain/article/details/108212429, 基于图结构的视频理解——组织视频序列的非线性流
[10]. Mao, Feng, et al. “Hierarchical video frame sequence representation with deep convolutional graph network.” Proceedings of the European Conference on Computer Vision (ECCV). 2018.
[11]. Lin, T.Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., Doll´ar, P., Zitnick, C.L.: Microsoft coco: Common objects in context. In: ECCV (2014)
[12]. Krishna, R., Zhu, Y., Groth, O., Johnson, J., Hata, K., Kravitz, J., Chen, S., Kalantidis, Y., Li, L.J., Shamma, D.A., et al.: Visual genome: Connecting language and vision using crowdsourced dense image annotations. IJCV (2017)
[13]. Sharma, P., Ding, N., Goodman, S., Soricut, R.: Conceptual captions: A cleaned, hypernymed, image alt-text dataset for automatic image captioning. In: ACL (2018)
[14]. Ordonez, V., Kulkarni, G., Berg, T.L.: Im2text: Describing images using 1 million captioned photographs. In: NeurIPS (2011)
[15]. Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International Conference on Machine Learning (pp. 8748-8763). PMLR. Short for CLIP
[16]. Gu, J., Meng, X., Lu, G., Hou, L., Niu, M., Xu, H., … & Xu, C. (2022). Wukong: 100 Million Large-scale Chinese Cross-modal Pre-training Dataset and A Foundation Framework. arXiv preprint arXiv:2202.06767. short for WuKong
[17]. Jia, C., Yang, Y., Xia, Y., Chen, Y. T., Parekh, Z., Pham, H., … & Duerig, T. (2021, July). Scaling up visual and vision-language representation learning with noisy text supervision. In International Conference on Machine Learning (pp. 4904-4916). PMLR. Short for ALIGN
[18]. Huo, Y., Zhang, M., Liu, G., Lu, H., Gao, Y., Yang, G., … & Wen, J. R. (2021). WenLan: Bridging vision and language by large-scale multi-modal pre-training. arXiv preprint arXiv:2103.06561. short for WenLan 1.0
[19]. Shan, B., Yin, W., Sun, Y., Tian, H., Wu, H., & Wang, H. (2022). ERNIE-ViL 2.0: Multi-view Contrastive Learning for Image-Text Pre-training. arXiv preprint arXiv:2209.15270. short for ERNIE-VIL 2.0
[20]. Zhai, X., Wang, X., Mustafa, B., Steiner, A., Keysers, D., Kolesnikov, A., & Beyer, L. (2022). Lit: Zero-shot transfer with locked-image text tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 18123-18133). Short for LiT
[21]. Thomee, B., Shamma, D. A., Friedland, G., Elizalde, B., Ni, K., Poland, D., … & Li, L. J. (2016). YFCC100M: The new data in multimedia research. Communications of the ACM, 59(2), 64-73.
[22]. Changpinyo, S., Sharma, P., Ding, N., & Soricut, R. (2021). Conceptual 12m: Pushing web-scale image-text pre-training to recognize long-tail visual concepts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 3558-3568).
[23]. Miech, A., Zhukov, D., Alayrac, J. B., Tapaswi, M., Laptev, I., & Sivic, J. (2019). Howto100m: Learning a text-video embedding by watching hundred million narrated video clips. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 2630-2640).
[24]. Li, Y., Fan, H., Hu, R., Feichtenhofer, C., & He, K. (2022). Scaling Language-Image Pre-training via Masking. arXiv preprint arXiv:2212.00794. Short for FLIP
[25]. https://blog.csdn.net/LoseInVain/article/details/116377189, 从零开始的搜索系统学习笔记
[26]. https://blog.csdn.net/LoseInVain/article/details/126214410, 【见闻录系列】我所理解的搜索业务二三事
[27]. https://blog.csdn.net/LoseInVain/article/details/125078683, 【见闻录系列】我所理解的“业务”
[28]. Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020, November). A simple framework for contrastive learning of visual representations. In International conference on machine learning (pp. 1597-1607). PMLR. short for SimCLR
[29]. https://blog.csdn.net/LoseInVain/article/details/125194144, 混合精度训练场景中,对比学习损失函数的一个注意点
[30]. Noroozi, M. and Favaro, P. Unsupervised learning of visual representations by solving jigsaw puzzles. In European Conference on Computer Vision, pp. 69–84. Springer, 2016. short fot jigsaw puzzles
[31]. Zhang, R., Isola, P., and Efros, A. A. Colorful image colorization. In European conference on computer vision, pp. 649–666.
Springer, 2016. short for colorization
[32]. Gidaris, S., Singh, P., & Komodakis, N. (2018). Unsupervised representation learning by predicting image rotations. arXiv preprint arXiv:1803.07728. short for rotations
[33]. He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 9729-9738). short for MoCo
[34]. Wu, Z., Xiong, Y., Yu, S. X., & Lin, D. (2018). Unsupervised feature learning via non-parametric instance discrimination. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 3733-3742). short for Memory Bank
[35]. https://blog.csdn.net/LoseInVain/article/details/120039316, Batch Norm层在大尺度对比学习中的过拟合现象及其统计参数信息泄露问题
[36]. He, K., Chen, X., Xie, S., Li, Y., Dollár, P., & Girshick, R. (2022). Masked autoencoders are scalable vision learners. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 16000-16009). short for MAE
[37]. Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021. short for ViT
[38]. Ma, Y., Xu, G., Sun, X., Yan, M., Zhang, J., & Ji, R. (2022, October). X-CLIP: End-to-End Multi-grained Contrastive Learning for Video-Text Retrieval. In Proceedings of the 30th ACM International Conference on Multimedia (pp. 638-647). Short for X-CLIP
[39]. Yao, L., Huang, R., Hou, L., Lu, G., Niu, M., Xu, H., … & Xu, C. (2021). Filip: Fine-grained interactive languageimage pre-training. arXiv preprint arXiv:2111.07783. short for FILIP
[40]. Li, J., Selvaraju, R., Gotmare, A., Joty, S., Xiong, C., & Hoi, S. C. H. (2021). Align before fuse: Vision and language representation learning with momentum distillation. Advances in neural information processing systems, 34, 9694-9705.
[41]. Luo, H., Ji, L., Zhong, M., Chen, Y., Lei, W., Duan, N., & Li, T. (2022). CLIP4Clip: An empirical study of CLIP for end to end video clip retrieval and captioning. Neurocomputing, 508, 293-304. short for CLIP4clips
[42]. Sun, C., Myers, A., Vondrick, C., Murphy, K., & Schmid, C. (2019). Videobert: A joint model for video and language representation learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (pp. 7464-7473). Short for VideoBERT
[43]. Chen, Y. C., Li, L., Yu, L., El Kholy, A., Ahmed, F., Gan, Z., … & Liu, J. (2020, August). Uniter: Universal imagetext representation learning. In European conference on computer vision (pp. 104-120). Springer, Cham. Short for UNITER
[44]. Zhai, X., Wang, X., Mustafa, B., Steiner, A., Keysers, D., Kolesnikov, A., & Beyer, L. (2022). Lit: Zero-shot transfer with locked-image text tuning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 18123-18133). Short for LiT
[45]. Van Den Oord, Aaron, and Oriol Vinyals. “Neural discrete representation learning.” Advances in neural information processing systems 30 (2017). short for VQ-VAE
[46]. https://fesianxu.github.io/2022/12/24/discrete-latent-representation-20221223/, 【论文极速读】VQ-VAE:一种稀疏表征学习方法
[47]. Bao, Hangbo, Li Dong, Songhao Piao, and Furu Wei. “Beit: Bert pre-training of image transformers.” arXiv preprint arXiv:2106.08254 (2021). short for BEiT
[48]. Vahdat, Arash, Evgeny Andriyash, and William Macready. “Dvae#: Discrete variational autoencoders with relaxed boltzmann priors.” Advances in Neural Information Processing Systems 31 (2018). short for dVAE
[49]. Peng, Zhiliang, Li Dong, Hangbo Bao, Qixiang Ye, and Furu Wei. “Beit v2: Masked image modeling with vector-quantized visual tokenizers.” arXiv preprint arXiv:2208.06366 (2022). short for BEiT v2
[50]. Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., & Joulin, A. (2021). Emerging properties in self-supervised vision transformers. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 9650-9660). short for DINO
[51]. Tong, Zhan, Yibing Song, Jue Wang, and Limin Wang. “Videomae: Masked autoencoders are data-efficient learners for self-supervised video pre-training.” arXiv preprint arXiv:2203.12602 (2022). short for VideoMAE
[52]. https://fesianxu.github.io/2023/01/20/semantic-label-20230120/, 语义标签(Semantic label)与多模态模型的一些关系
[53]. Lu, Jiasen, Dhruv Batra, Devi Parikh, and Stefan Lee. “Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks.” arXiv preprint arXiv:1908.02265 (2019). short for ViLBERT
[54]. Yu, Fei, Jiji Tang, Weichong Yin, Yu Sun, Hao Tian, Hua Wu, and Haifeng Wang. “Ernie-vil: Knowledge enhanced vision-language representations through scene graph.” arXiv preprint arXiv:2006.16934 (2020). short for ERNIE-VIL 1.0
[55]. Wang, R., Chen, D., Wu, Z., Chen, Y., Dai, X., Liu, M., … & Yuan, L. (2022). Bevt: Bert pretraining of video transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 14733-14743). short for BEVT
[56]. https://blog.csdn.net/LoseInVain/article/details/114958239, 语义标签(Semantic label)与多模态模型的一些关系
[57]. Chen, Y. C., Li, L., Yu, L., El Kholy, A., Ahmed, F., Gan, Z., … & Liu, J. (2020, September). Uniter: Universal image-text representation learning. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XXX (pp. 104-120). Cham: Springer International Publishing. short for UNITER
[58]. https://pytorch.org/docs/stable/distributed.html, DISTRIBUTED COMMUNICATION PACKAGE - TORCH.DISTRIBUTED
[59]. https://amsword.medium.com/gradient-backpropagation-with-torch-distributed-all-gather-9f3941a381f8, Gradient backpropagation with torch.distributed.all_gather
[60]. https://blog.csdn.net/LoseInVain/article/details/103870157, 一些深度学习中的英文术语的纪录
[61]. https://blog.csdn.net/LoseInVain/article/details/122735603, 图文多模态语义融合前的语义对齐——一种单双混合塔多模态模型
[62]. https://github.com/facebookresearch/moco/blob/78b69cafae80bc74cd1a89ac3fb365dc20d157d3/moco/builder.py#L53
[63]. https://blog.csdn.net/LoseInVain/article/details/105808818, 数据并行和模型并行的区别
[64]. Fei, Nanyi, Zhiwu Lu, Yizhao Gao, Guoxing Yang, Yuqi Huo, Jingyuan Wen, Haoyu Lu et al. “WenLan 2.0: Make AI Imagine via a Multimodal Foundation Model.” arXiv preprint arXiv:2110.14378 (2021). short for WenLan v2
[65]. https://blog.csdn.net/LoseInVain/article/details/121699533, WenLan 2.0:一种不依赖Object Detection的大规模图文匹配预训练模型 & 数据+算力=大力出奇迹
[66]. Li, Junnan, Ramprasaath Selvaraju, Akhilesh Gotmare, Shafiq Joty, Caiming Xiong, and Steven Chu Hong Hoi. “Align before fuse: Vision and language representation learning with momentum distillation.” Advances in Neural Information Processing Systems 34 (2021). short for ALBEF
[67]. https://github.com/salesforce/ALBEF/issues/22
[68]. Wang, Wenhui, Hangbo Bao, Li Dong, Johan Bjorck, Zhiliang Peng, Qiang Liu, Kriti Aggarwal et al. “Image as a foreign language: Beit pretraining for all vision and vision-language tasks.” arXiv preprint arXiv:2208.10442 (2022). short for BEiT v3
[69]. Bao, H., Wang, W., Dong, L., Liu, Q., Mohammed, O. K., Aggarwal, K., … & Wei, F. (2021). Vlmo: Unified vision-language pre-training with mixture-of-modality-experts. arXiv preprint arXiv:2111.02358.
[70]. Shrivastava, A., Selvaraju, R. R., Naik, N., & Ordonez, V. (2021). CLIP-Lite: information efficient visual representation learning from textual annotations. arXiv preprint arXiv:2112.07133. short for CLIP-Lite
相同的文本符号所代表的抽象含义并不是一成不变的,而是会随着人类社会的地域,事件,时间等发生变化,也就是说文本的语义是变化着的。举个例子,苹果在过去只是指的食物苹果,在现在又多出了苹果(产品,公司)的语义,黄色在过去只是颜色代表,现在在国内有着情色的含义,而在日本,这个黄色则由桃色,粉色(ピンク)替代了。 ↩︎
光栅化的图片的基础组成部分是像素,而矢量图则可以通过公式进行表达。 ↩︎
有两种方法可供使用:一、原图 t t t与原图的变换 t ′ ∼ T t^{\prime} \sim \mathcal{T} t′∼T作为一对正样本对 < t , t ′ > <t, t^{\prime}> <t,t′>;二、原图 t t t在同一个图片变换 T \mathcal{T} T下产生两个衍生图片 t ′ ∼ T t^{\prime} \sim \mathcal{T} t′∼T , t ′ ′ ∼ T t^{\prime \prime} \sim \mathcal{T} t′′∼T,将这两个衍生图片视为一对正样本对 < t ′ , t ′ ′ > <t^{\prime}, t^{\prime \prime}> <t′,t′′>。前者称之为非对称处理,由于会影响性能而仅在消融实验中采用,SimCLR采用的是后者,也称之为对称性处理。 ↩︎
全称是Normalized Temperature-scaled Cross Entropy,标准化温度系数放缩交叉熵损失。 ↩︎
由于此处的key编码器采用动量更新,因此也被称之为动量编码器。 ↩︎
笔者认为采用VQ-VAE应该也是可以的,未曾试验过。 ↩︎
正因为视频同时有着空间和时间上的冗余度,在视频压缩中同时也有时间和空间维度的信息压缩。 ↩︎
具象概念:现实生活中存在的物体的概念,如苹果,老虎,电脑等。 抽象概念:非现实生活中真实存在的物体概念,如自由、和平、爱情等。 ↩︎
上下文提示词,在其他文献也被称之为prompt,我们本文不区分这两个术语。 ↩︎
这种做法在NLP里面也是一种经典做法,比如 f ( k i n g ) − f ( m a l e ) ≈ f ( q u e u e ) f(king)-f(male) \approx f(queue) f(king)−f(male)≈f(queue),这一定程度代表了embedding的语义对齐能力。 ↩︎
在Multiway Transformer原论文 [69] 中,
V-FFN和L-FFN被称之为“视觉专家”和“文本专家”,采用的是Mixture of Multiple Experts (MMoE) 的思想。 ↩︎CLIP的
batch size高达32k,ALIGN的batch size大概是16k。 ↩︎为了谨慎起见,此处的描述是“视觉令牌与文本令牌的对齐”,而不是“视觉概念与文本概念的对齐”,笔者主要考虑到稀疏的视觉令牌其所蕴含的语义应该是视觉概念的子集,视觉令牌与文本令牌的对齐并不能反推出两个模态的语义对齐。 ↩︎