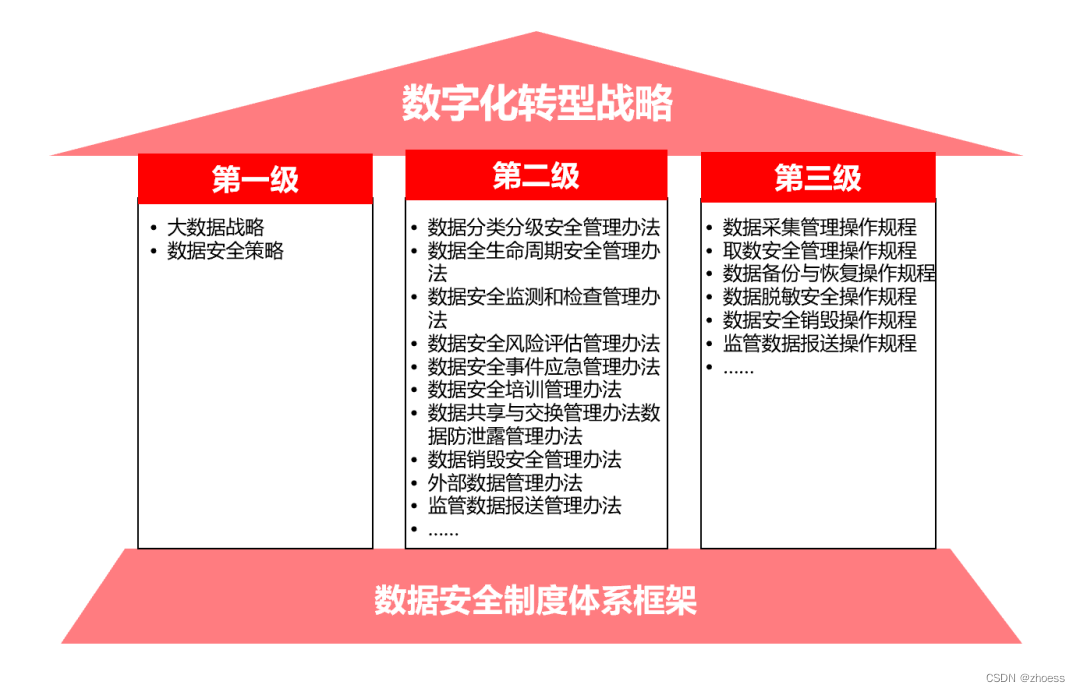
场景:
数据安全首届大赛已经结束了,使得我对数据安全分类分级的产生了一些感想,如何去识别?如何去准确识别?如何去覆盖全面的识别呢?
现状
现状许多人还在尝试找到真正实现自动化的方式,许多的厂家包括公司依旧尝试着人工智能的方法,这导致了许许多多的企业消费了大量人力。现状业内虽然嘴上说着人工智能人工智能,其实仅仅是一个人工的孵化而已,并未达到真正的全自动。
想法:
咱们大数据已经发展依旧,难道那些数据发掘技术、机器学习、AI智能仅仅存在话里吗?数据均会存在一些特征,我们既然能够用人工去书写正则,为什么不能使用机器自动输出正则。我想ChatGPT是可以实现的吧?数据安全分类分级仅仅是一个开头,但俗话说到好,完事开头难,当积累了许多经验后,后续的API、防泄漏、脱敏、敏感操作,那不都有迹可循。而且 其实分类分级是很重要的一步,当客户拥有我们的分类分级系统,并且得到了肯定,那么后续的开展只能由我们这边进行了,因为我们拥有客户满意的匹配特征,且这个特征的可复制性高。
可能因为我才疏学浅,或许没有考虑到很多细节方面的事,也仅供大家探讨探讨,相互学习吧