Spark常用代码
文章目录
- Spark常用代码
-
- 1. 创建RDD方法
- 2. 专门读取小文件wholeTextFiles
- 3. rdd的分区数
- 4. Transformation函数以及Action函数
- 5. 重分区函数
- 6. 聚合函数
- 7. 搜狗搜索词案例的实战
- 8. RDD缓存和checkpoint
- 9. 流量日志分析代码
- 10. 累加器和广播变量
- 11. spark sql入门
-
- 11.1 方式一:RDD转Dataframe的第一种方式 createDataFrame
- 11.2 方式二:通过StructedType构建DataFrame
- 11.3 方式三 直接toDF
- 11.4 方式四 由pandas构建
- 11.5 外部数据转换成df
- 11.6 sparksql实现wordcount
- 11.7 Iris data的实现
- 11.8 电影数据集案例
- 11.9 数据清洗一
- 11.10 数据清洗二
- 11.11 电影评分项目一
- 11.12 spark读写mysql
- 11.13 Sparksql
- 11.14 开窗函数
- 11. 15 UDF(User defined aggregation function)
- 11.15 使用装饰器来定义udf
- 11.16 混合类型的输出
- 11.17 udf实战
- 11.8 pandasUDF
1. 创建RDD方法
有两个不同的方式可以创建新的RDD
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("createWholeTextFile").setMaster("local[*]")
sc = SparkContext(conf=conf)
file_rdd = sc.textFile("/export/workspace/bigdata-pyspark_2.3.0/PySpark-SparkCore_2.3.0/data/ratings100")
print("file_rdd numpartitions {}".format(file_rdd.getNumPartitions())) # 100 100个文件100个分区
# 用于读取小文件并自动压缩分区
wholefile_rdd = sc.wholeTextFiles("/export/workspace/bigdata-pyspark_2.3.0/PySpark-SparkCore_2.3.0/data/ratings100")
print("wholefile_rdd numpartitions {}".format(wholefile_rdd.getNumPartitions())) # 2 把100个文件压缩到2个分区
result = wholefile_rdd.take(1)
# print(result) # (location, value)的形式
# 获取前面的路径
path_list = wholefile_rdd.map(lambda x: x[0]).collect()
sc.stop()
2. 专门读取小文件wholeTextFiles
from pyspark import SparkConf, SparkContext
conf = SparkConf().setAppName("createWholeTextFile").setMaster("local[*]")
sc = SparkContext(conf=conf)
file_rdd = sc.textFile("/export/workspace/bigdata-pyspark_2.3.0/PySpark-SparkCore_2.3.0/data/ratings100")
print("file_rdd numpartitions {}".format(file_rdd.getNumPartitions())) # 100 100个文件100个分区
# 用于读取小文件并自动压缩分区
wholefile_rdd = sc.wholeTextFiles("/export/workspace/bigdata-pyspark_2.3.0/PySpark-SparkCore_2.3.0/data/ratings100")
print("wholefile_rdd numpartitions {}".format(wholefile_rdd.getNumPartitions())) # 2 把100个文件压缩到2个分区
result = wholefile_rdd.take(1)
# print(result) # (location, value)的形式
# 获取前面的路径
path_list = wholefile_rdd.map(lambda x: x[0]).collect()
sc.stop()
3. rdd的分区数
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
# spark入口申请资源
conf = SparkConf().setAppName("createRDD").setMaster("local[5]")
# 应该充分使用资源,线程数设置成CPU核心数的2-3倍
# conf.set("spark.default.parallelism", 10)
sc = SparkContext(conf=conf)
# 创建rdd的第一种方法
collection_rdd = sc.parallelize([1, 2, 3, 4, 5, 6])
print(collection_rdd.collect())
# 获取分区数
print("rdd number of partitions ", collection_rdd.getNumPartitions())
# 解释:
# 设置了5个核心,默认是5个分区,如果是local[*] 默认是2个分区
# conf.set("spark.default.parallelism", 10)优先使用此值
# 如果sc.parallelize也设置了分区,那么最优先使用api设置的分区数
# 如果是读取文件夹下面的文件,sc.textFile, minPartitions失效,有多少个文件就有多少个分区,下面100个文件返回了100个分区
file_rdd = sc.textFile("/export/workspace/bigdata-pyspark_2.3.0/PySpark-SparkCore_2.3.0/data/ratings100",
minPartitions=3)
print("file_rdd numpartitions {}".format(file_rdd.getNumPartitions())) # 100 100个文件100个分区
# 用于读取小文件并自动压缩分区,minPartitions参数是生效的。
wholefile_rdd = sc.wholeTextFiles("/export/workspace/bigdata-pyspark_2.3.0/PySpark-SparkCore_2.3.0/data/ratings100",
minPartitions=3)
print("wholefile_rdd numpartitions {}".format(wholefile_rdd.getNumPartitions())) # 2 把100个文件压缩到3个分区
# 打印不同分区数据
collection_rdd = sc.parallelize([1, 2, 3, 4, 5, 6], numSlices=7)
print("collection_rdd number of partitions ", collection_rdd.getNumPartitions())
# 6个数据7个分区,有一个分区是空的 per partition content [[], [1], [2], [3], [4], [5], [6]]
print("per partition content", collection_rdd.glom().collect())
# 关闭spark context
sc.stop()
4. Transformation函数以及Action函数
4.1 Transformation函数
由一个RDD转换成另一个RDD,并不会立即执行的。是惰性,需要等到Action函数来触发。
单值类型valueType
- map
- flatMap
- filter
- mapValue
单值类型函数的demo:
"""
单Value类型RDD转换算子的演示
"""
import re
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("mini").setMaster("local[*]")
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
# map操作
rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6])
rdd_map = rdd1.map(lambda x: x*2)
print(rdd_map.glom().collect())
# [[2, 4, 6], [8, 10, 12]]
# filter操作
print(rdd1.glom().collect())
print(rdd1.filter(lambda x: x > 3).glom().collect())
# flatMap
rdd2 = sc.parallelize([" hello you", "hello me "])
print(rdd2.flatMap(lambda word: re.split("\s+", word.strip())).collect())
# groupBy
x = sc.parallelize([1, 2, 3])
# [('A', [1, 3]), ('B', [2])]
y = x.groupBy(lambda x: 'A' if x % 2 == 1 else 'B')
print(y.mapValues(list).collect())
# mapValue 对value进行操作
# [('a', 6), ('b', 15)]
x1 = sc.parallelize([("a", [1, 2, 3]), ("b", [4, 5, 6])])
print(x1.mapValues(lambda x: sum(x)).collect())
双值类型DoubleValueType
- intersection
- union
- difference
- distinct
双值类型函数的demo:
"""
双Value类型RDD转换算子的演示
"""
import re
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("mini").setMaster("local[*]")
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
# map操作
rdd1 = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = sc.parallelize([1, 2, 3, 4, 5, 6, 7, 8])
# [1, 2, 3, 4, 5, 1, 2, 3, 4, 5, 6, 7, 8]
union_rdd = rdd1.union(rdd2)
print(union_rdd.collect())
# [4, 1, 5, 2, 3]
print(rdd1.intersection(rdd2).collect())
# [8, 6, 7]
print(rdd2.subtract(rdd1).collect())
# [4, 8, 1, 5, 2, 6, 3, 7]
print(union_rdd.distinct().collect())
# [[4, 8], [1, 5], [2, 6], [3, 7]]
print(union_rdd.distinct().glom().collect())
Key-Value类型
- reduceByKey
- groupByKey
- sortByKey
- combineByKey是底层API
- foldByKey
- aggregateByKey
Key-Value类型函数demo
"""
key-Value类型RDD转换算子的演示
"""
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("mini").setMaster("local[*]")
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
# groupByKey
rdd1 = sc.parallelize([("a", 1), ("b", 2)])
rdd2 = sc.parallelize([("c", 1), ("b", 3)])
rdd3 = rdd1.union(rdd2)
key1 = rdd3.groupByKey()
print("groupByKey", key1.collect())
key2 = key1.mapValues(list)
print(key2.collect())
# [('b', [2, 3]), ('c', [1]), ('a', [1])]
# reduceByKey
key3 = rdd3.reduceByKey(lambda x, y: x+y)
print(key3.collect())
# [('b', 5), ('c', 1), ('a', 1)]
# sortByKey
print(key3.map(lambda x: (x[1], x[0])).sortByKey(False).collect())
# [(5, 'b'), (1, 'c'), (1, 'a')].
# countByValue
print(sorted(sc.parallelize([1, 2, 1, 2, 2]).countByValue().items()))
# [(1, 2), (2, 3)]
4.2 Action函数
立即执行的,返回一个非RDD的东西。
- collect
- saveAsTextFile
- first
- take
- takeSample
- top
下面是action相关函数的示例代码
from pyspark import SparkConf, SparkContext
import operator
if __name__ == '__main__':
conf = SparkConf().setAppName("mini").setMaster("local[*]")
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
rdd1 = sc.parallelize([("a", 1), ("b", 2)])
rdd2 = sc.parallelize([("c", 1), ("b", 3)])
print(rdd1.first())
# ('a', 1)
# print(rdd1.take(2))
# spark 2.3.0报错
print(rdd1.top(2))
# [('b', 2), ('a', 1)]
print(rdd1.collect())
# [('a', 1), ('b', 2)]
# reduce
rdd3 = sc.parallelize([1, 2, 3, 4, 5])
# 累加 15
print(rdd3.reduce(operator.add))
# 累乘 120
print(rdd3.reduce(operator.mul))
# takeSample 取样操作
rdd4 = sc.parallelize([i for i in range(10)])
print(rdd4.collect())
print(rdd4.takeSample(True, 3, 123))
# [6, 9, 3]
4.3 其他常见的函数
from pyspark import SparkConf, SparkContext
import operator
def f(iterator):
for x in iterator:
print(x)
def f2(iterator):
yield sum(iterator)
if __name__ == '__main__':
conf = SparkConf().setAppName("mini").setMaster("local[*]")
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
rdd1 = sc.parallelize([("a", 1), ("b", 2)])
print(rdd1.getNumPartitions())
print(rdd1.glom().collect())
# foreach
print(rdd1.foreach(lambda x: print(x)))
# foreachPartition
print(rdd1.foreachPartition(f))
rdd2 = sc.parallelize([1, 2, 3, 4, 5])
print(rdd2.glom().collect())
# map
print(rdd2.map(lambda x: x * 2).collect())
# [2, 4, 6, 8, 10]
# mapPartitions
print(rdd2.mapPartitions(f2).collect())
# [3, 12]
5. 重分区函数
分区调整的API
- repartition 对单值的rdd进行重新分区,repartition调用的是coalesce的api,shuffle传入了True。
- coalesce ,如果shuffle为False情况下增加分区,返回的值是不会改变的。
- partitionBy,只能对Key-Value类型的rdd进行操作。
from pyspark import SparkConf, SparkContext
import operator
def f(iterator):
for x in iterator:
print(x)
def f2(iterator):
yield sum(iterator)
if __name__ == '__main__':
conf = SparkConf().setAppName("mini").setMaster("local[*]")
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6], 3)
print(rdd1.glom().collect())
# [[1, 2], [3, 4], [5, 6]]
# repartition 含有shuffle
print(rdd1.repartition(5).glom().collect())
# [[], [1, 2], [5, 6], [3, 4], []]
# coalesce没有shuffle
print(rdd1.coalesce(2).glom().collect())
# [[1, 2], [3, 4, 5, 6]]
print(rdd1.coalesce(5).glom().collect())
# [[1, 2], [3, 4], [5, 6]] 没有shuffle情况下,增加分区也是无效的
# 相当于调用了repartition方法,进行shuffle
print(rdd1.coalesce(5, True).glom().collect())
# [[], [1, 2], [5, 6], [3, 4], []]
# partitionBy 只能对key-value类型的rdd进行操作,其他类型报错
rdd2 = rdd1.map(lambda x: (x, x))
print(rdd2.glom().collect())
# [[(1, 1), (2, 2)], [(3, 3), (4, 4)], [(5, 5), (6, 6)]]
print(rdd2.partitionBy(2).glom().collect())
# [[(2, 2), (4, 4), (6, 6)], [(1, 1), (3, 3), (5, 5)]]
# rdd1.partitionBy(2) # 报错
6. 聚合函数
6.1 基础聚合函数
对单值rdd进行操作的聚合函数。
- reduce:聚合计算,把rdd的元素安装指定运算法操作,得到一个值
- fold:能指定初始值,以及同时指定分区内,和分区间操作函数(两者设定一样)
- aggregate:能指定初始值,以及同时指定分区内,和分区间操作函数(两者可以分别设定)
from pyspark import SparkConf, SparkContext
import operator
def f(iterator):
for x in iterator:
print(x)
def f2(iterator):
yield sum(iterator)
if __name__ == '__main__':
conf = SparkConf().setAppName("mini").setMaster("local[*]")
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
rdd1 = sc.parallelize([1, 2, 3, 4, 5, 6], 3)
print(rdd1.getNumPartitions())
print(rdd1.glom().collect())
# 21
# reduce 聚合计算
print(rdd1.reduce(operator.add))
# fold 聚合计算
print(rdd1.glom().collect())
# [[1, 2], [3, 4], [5, 6]]
print(rdd1.fold(1, operator.add))
# 25
# 解释:一共3个分区,每个分区内+1,然后分区间再+1. 一共加了4. 所以是25。
# aggregate聚合
rdd2 = sc.parallelize([1, 2, 3, 4])
print(rdd2.glom().collect())
# [[1, 2], [3, 4]]
print(rdd2.aggregate(1, operator.add, operator.mul))
# 分区内用加法,分区间用乘法
# (1+2+1)*(3+4+1)*1 = 32
6.2 Key-Value类型的聚合函数
对key-value类型的rdd进行操作的函数,和常规聚合函数是类似的,只是多了key,在不同key之间进行聚合而已。
- reduceByKey
- foldByKey
- aggregateByKey
from pyspark import SparkConf, SparkContext
import operator
def f(iterator):
for x in iterator:
print(x)
def f2(iterator):
yield sum(iterator)
if __name__ == '__main__':
conf = SparkConf().setAppName("mini").setMaster("local[*]")
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
rdd = sc.textFile("hdfs://node1:8020/pydata/word.txt")
print(rdd.collect())
# ['hello you Spark Flink', 'hello me hello she Spark']
rdd_flatmap = rdd.flatMap(lambda x: x.split(" "))
rdd_map = rdd_flatmap.map(lambda word: (word, 1))
print(rdd_map.collect())
# groupByKey
groupbykey_rdd = rdd_map.groupByKey()
rdd_result = groupbykey_rdd.mapValues(sum)
print("use groupByKey")
print(rdd_result.collect())
# [('Spark', 2), ('Flink', 1), ('hello', 3), ('you', 1), ('me', 1), ('she', 1)]
# reduceByKey 有预聚合,性能好于group_by_key_rdd
print("use reduceByKey")
print(rdd_map.reduceByKey(operator.add).collect())
# [('Spark', 2), ('Flink', 1), ('hello', 3), ('you', 1), ('me', 1), ('she', 1)]
# foldByKey
print("use foldByKey")
print(rdd_map.foldByKey(0, operator.add).collect())
# [('Spark', 2), ('Flink', 1), ('hello', 3), ('you', 1), ('me', 1), ('she', 1)]
# aggregateByKey
print("use aggregateByKey")
print(rdd_map.aggregateByKey(0, operator.add, operator.add).collect())
# [('Spark', 2), ('Flink', 1), ('hello', 3), ('you', 1), ('me', 1), ('she', 1)]
- combineByKey:是Key-value聚合函数的最抽象的写法。需要定义createCombiner(用于创建分区内元素)、mergeValue(分区内元素的操作)、mergeCombiners(分区间元素的操作)这三个函数。
简单的demo
from pyspark import SparkConf, SparkContext
import operator
def createCombiner(value):
return [value]
def mergeValue(x, y):
x.append(y)
return x
def mergeCombiners(x, y):
x.extend(y)
return x
if __name__ == '__main__':
conf = SparkConf().setAppName("mini").setMaster("local[*]")
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
# groupByKey
rdd = sc.parallelize([("a", 1), ("b", 1), ("a", 1)])
# 使用combineByKey 模拟reduceByKey操作
print(rdd.combineByKey(createCombiner, mergeValue, mergeCombiners).collect())
combineByKey实现求人分数平均值的做法:
from pyspark import SparkConf, SparkContext
def createCombiner(x):
"""
分区内元素的创建
:param x:
:return:
"""
return [x, 1]
def mergeValue(x, y):
"""
分区内通元素的操作
:param x:
:param y:
:return:
"""
x.append(y)
return [x[0]+y, x[1]+1]
def mergeCombiners(a, b):
"""
分区之间的操作
:param a:
:param b:
:return:
"""
return [a[0]+b[0], a[1]+b[1]]
if __name__ == '__main__':
conf = SparkConf().setAppName("mini").setMaster("local[*]")
sc = SparkContext(conf=conf)
x = sc.parallelize([("Fred", 88), ("Fred", 95), ("Fred", 91), ("Wilma", 93), ("Wilma", 95), ("Wilma", 98)])
print(x.glom().collect())
combine_rdd = x.combineByKey(createCombiner, mergeValue, mergeCombiners)
print(combine_rdd.collect())
print(combine_rdd.map(lambda x: (x[0], x[1][0]/x[1][1])).collect())
6.3 join相关操作
from pyspark import SparkConf, SparkContext
if __name__ == '__main__':
conf = SparkConf().setAppName("mini").setMaster("local[*]")
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
x = sc.parallelize([(1001, "zhangsan"), (1002, "lisi"), (1003, "wangwu"), (1004, "zhangliu")])
y = sc.parallelize([(1001, "sales"), (1002, "tech")])
print(x.join(y).collect())
# [(1001, ('zhangsan', 'sales')), (1002, ('lisi', 'tech'))]
print(x.leftOuterJoin(y).collect())
# [(1004, ('zhangliu', None)), (1001, ('zhangsan', 'sales')), (1002, ('lisi', 'tech')), (1003, ('wangwu', None))]
print(x.rightOuterJoin(y).collect())
# [(1001, ('zhangsan', 'sales')), (1002, ('lisi', 'tech'))]
7. 搜狗搜索词案例的实战
from pyspark import SparkConf, SparkContext
import re
import jieba
import operator
if __name__ == '__main__':
conf = SparkConf().setAppName("sougou").setMaster("local[*]")
sc = SparkContext(conf=conf)
# TODO 1. 读取数据
sougouFileRDD = sc.textFile("hdfs://node1:8020/bigdata/sougou/SogouQ.reduced")
# 打印行数
# print("sougou count is: ", sougouFileRDD.count())
# 00:00:00 2982199073774412 [360安全卫士] 8 3 download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html
resultRDD = sougouFileRDD\
.filter(lambda line: (len(line.strip()) > 0) and (len(re.split("\s+", line.strip())) == 6))\
.map(lambda line:(
re.split("\s+", line)[0],
re.split("\s+", line)[1],
re.sub("\[|\]", "", re.split("\s+", line)[2]),
re.split("\s+", line)[3],
re.split("\s+", line)[4],
re.split("\s+", line)[5],
))
print(resultRDD.take(3))
# [('00:00:00', '2982199073774412', '360安全卫士', '8', '3',
# 'download.it.com.cn/softweb/software/firewall/antivirus/20067/17938.html'),
# ('00:00:00', '07594220010824798', '哄抢救灾物资', '1', '1', 'news.21cn.com/social/daqian/2008/05/29/4777194_1.shtml'), (
# '00:00:00', '5228056822071097', '75810部队', '14', '5',
# 'www.greatoo.com/greatoo_cn/list.asp?link_id=276&title=%BE%DE%C2%D6%D0%C2%CE%C5')]
# TODO 2. 搜狗关键词统计
recordRDD = resultRDD.flatMap(lambda record: jieba.cut(record[2]))
sougouResult1 = recordRDD\
.map(lambda word: (word, 1))\
.reduceByKey(operator.add)\
.sortBy(lambda x: x[1], False)
print(sougouResult1.take(3))
# [('+', 1442), ('地震', 605), ('.', 575)]
# TODO 3. 用户搜索点击统计
sougouClick = resultRDD.map(lambda record: (record[1], record[2]))
sougouResult2 = sougouClick.map(lambda record: (record, 1))\
.reduceByKey(operator.add)
print("max count is ", sougouResult2.map(lambda x: x[1]).max())
# max count is 19
print(sougouResult2.sortBy(lambda x: x[1], False).take(3))
# [(('9026201537815861', 'scat'), 19), (('7650543509505572', '儿童孤独症的治疗'), 19), (('9882234129973235', 'xiao77'), 17)]
# TODO 4. 搜索时间段统计
hourRDD = resultRDD.map(lambda x: str(x[0])[:2])
sougouResult3 = hourRDD.map(lambda x: (x, 1)).reduceByKey(operator.add).sortBy(lambda x: x[1], False)
print(sougouResult3.collect())
# TODO 5. 停止sparkcontext
sc.stop()
8. RDD缓存和checkpoint
8.1 缓存 Cache
RDD的缓存是保存在CPU,内存或者磁盘,响应快,但是易丢失,rdd依赖关系不会被切断。不能持久化,一般把经常用的rdd缓存,需要action算子才能触发。系统定期使用LRU(least recently used)算法清理缓存
from pyspark import SparkConf, SparkContext, StorageLevel
import time
if __name__ == '__main__':
conf = SparkConf().setAppName("mini").setMaster("local[*]")
sc = SparkContext(conf=conf)
sc.setLogLevel("WARN")
x = sc.parallelize([(1001, "zhangsan"), (1002, "lisi"), (1003, "wangwu"), (1004, "zhangliu")])
y = sc.parallelize([(1001, "sales"), (1002, "tech")])
print(x.join(y).collect())
# [(1001, ('zhangsan', 'sales')), (1002, ('lisi', 'tech'))]
print(x.leftOuterJoin(y).collect())
# [(1004, ('zhangliu', None)), (1001, ('zhangsan', 'sales')), (1002, ('lisi', 'tech')), (1003, ('wangwu', None))]
print(x.rightOuterJoin(y).collect())
# [(1001, ('zhangsan', 'sales')), (1002, ('lisi', 'tech'))]
result = x.join(y)
# 缓存文件操作 相当于 调用self.persist(StorageLevel.MEMORY_ONLY)
# result.cache()
result.persist(StorageLevel.MEMORY_ONLY)
# 需要action算子才能够被激活
result.collect()
result.unpersist()
result.count()
time.sleep(600)
sc.stop()
8.3 spark通过cache和checkpoint进行容错
- 首先检测数据是否有缓存,cache或者persist?
- 然后检查hdfs是否有checkpoint
- 上诉两条都没有的话,就根据依赖关系重新构建。
8.4 cache和checkpoint演示
下面例子分别对cache和checkpoint读取rdd缓存。
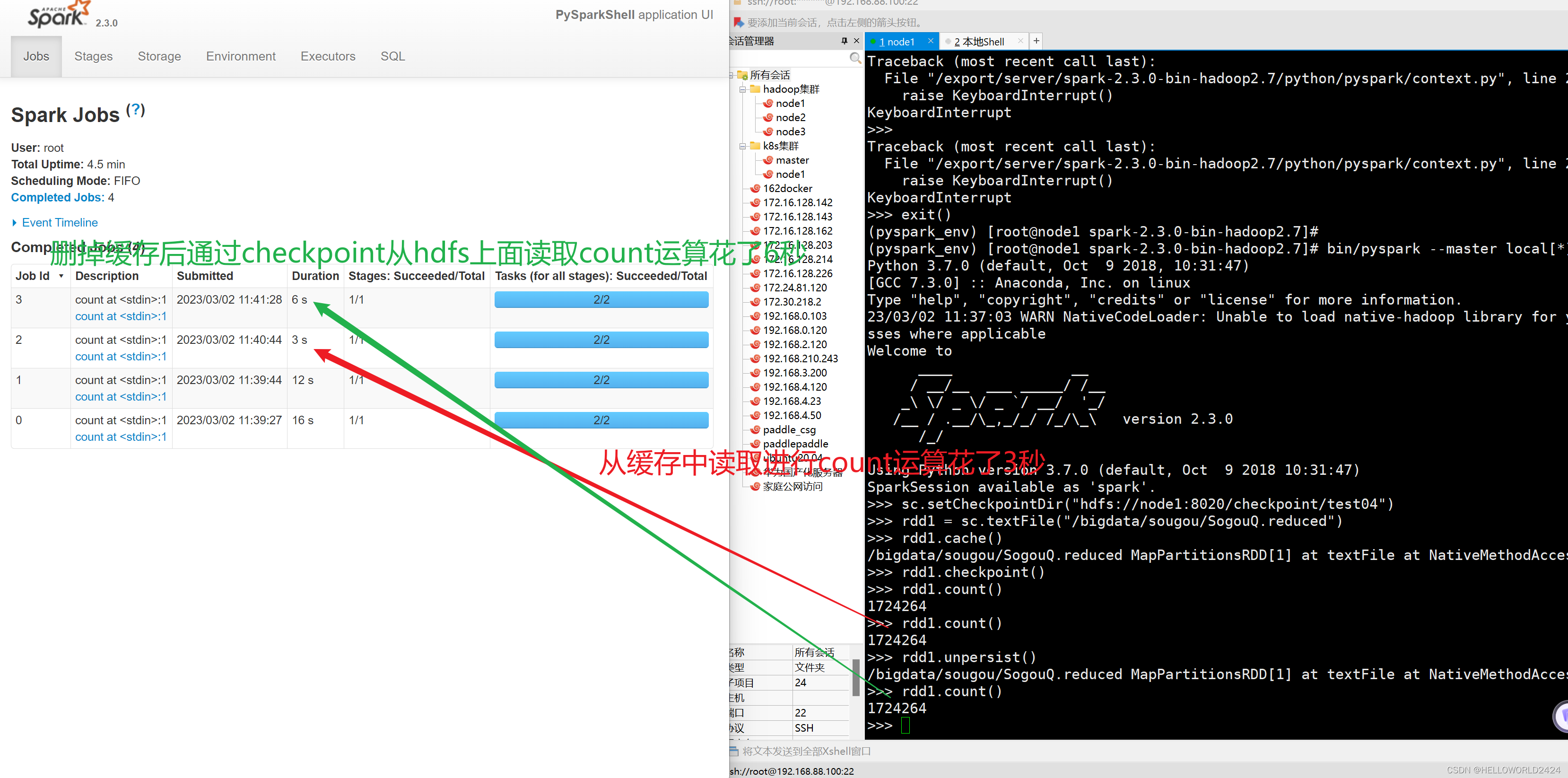
9. 流量日志分析代码
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
def ip_transform(ip):
ips = ip.split(".") # [223,243,0,0] 32位二进制数
ip_num = 0
for i in ips:
ip_num = int(i) | ip_num << 8
return ip_num
def binary_search(ip_num, broadcast_value):
# 16777472
# [('16777472', '16778239', '119.306239', '26.075302'), ('16779264', '16781311', '113.280637', '23.125178')]
start = 0
end = len(broadcast_value) - 1
while (start <= end):
mid = (end + start) // 2
middle = broadcast_value[mid]
if int(middle[0]) <= ip_num <= int(middle[1]):
return mid
elif ip_num < int(middle[0]):
end = mid
else:
start = mid
def main():
# 1. 准备环境
# spark = SparkSession.builder.appName("ipCheck").master("local[*]").getOrCreate()
# sc = spark.sparkContext
conf = SparkConf().setAppName("ipCheck").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 2. 读取用户所在ip信息的文件,切分后选择下标为1字段就是用户的ip
dest_ip_rdd = sc.textFile("hdfs://node1:8020/bigdata/ip/20190121000132394251.http.format")\
.map(lambda x: x.split("|"))\
.map(lambda x: x[1])
print(dest_ip_rdd.take(2))
# 3. 读取城市ip段信息,换区起始ip的long类型(下标2),结束ip的long类型(下标3),经度(下标13),维度(下标14)
city_ip_rdd = sc.textFile("hdfs://node1:8020/bigdata/ip/ip.txt")\
.map(lambda x: x.split("|"))\
.map(lambda x: (x[2], x[3], x[13], x[14]))
print(city_ip_rdd.take(2))
# 广播一份数据到executor,而不是每一个task线程,这样可以减少网络IO传输
city_ip_rdd_broadcast = sc.broadcast(city_ip_rdd.collect())
def GetPos(x):
city_ip_rdd_broadcast_value = city_ip_rdd_broadcast.value
def getResult(ip):
# 4 通过ip转化成long类型的ip
ip_num = ip_transform(ip)
# 5. 采用折半查找ip对应的经纬度
index = binary_search(ip_num, city_ip_rdd_broadcast_value)
return ((city_ip_rdd_broadcast_value[index][2], city_ip_rdd_broadcast_value[index][3]), 1)
# 得到 ((经度,维度), 1)
re = map(tuple, [getResult(ip) for ip in x])
return re
ip_rdd_map_partition = dest_ip_rdd.map(GetPos)
result = ip_rdd_map_partition.reduceByKey(lambda x, y: x+y).sortBy(lambda x: x[1], False)
print("final sorted result")
print(result.take(5))
# [(('108.948024', '34.263161'), 1824), (('116.405285', '39.904989'), 1535), (('106.504962', '29.533155'), 400), (('114.502461', '38.045474'), 383), (('106.57434', '29.60658'), 177)]
sc.stop()
if __name__ == '__main__':
main()
10. 累加器和广播变量
10.1 accumulator累加器
累加器适用于给不同的task来操作的变量,多个线程都能够修改这个变量。
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("minpy").setMaster("local[*]")
sc = SparkContext(conf=conf)
l1 = [1, 2, 3, 4, 5]
l1_textFile = sc.parallelize(l1)
# 错误案例
num = 10
def add(x):
global num
num += x
l1_textFile.foreach(add)
print("value of num is", num)
# 10 是有问题
# 使用累加器解决
# 定义累加器
acc_num = sc.accumulator(10)
def add_num(x):
global acc_num
acc_num.add(x)
l1_textFile.foreach(add_num)
# 25 使用累加器得到正确的结果
print(acc_num)
print(acc_num.value)
10.2 broadcast广播机制
广播机制主要是解决多个task中的网络传输问题。driver端的变量通过broadcast传输以后,到了executor,然后共享给task是只读形式的。
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("broadcast").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 定义rdd
kvFruit = sc.parallelize([(1, "apple"), (2, "orange"), (3, "banana"), (4, "grape")])
print(kvFruit.collect())
fruit_collect_as_map = kvFruit.collectAsMap()
print(fruit_collect_as_map)
fruit_ids = sc.parallelize([2, 1, 4, 3])
# 不使用广播变量的情况下,fruit_collect_as_map会被复制到每个task线程下面,如果fruit_collect_as_map很大,或者查询量大时候
# 会出现很大的网络IO传输问题
fruit_name_0 = fruit_ids.map(lambda index: fruit_collect_as_map[index])
print("查询过后的水果名字")
print(fruit_name_0.collect())
# 使用广播变量, 节点中executor中的block manager会向driver请求一份副本,然后共享到每个task,减少大量IO传输
# 1. 定义广播变量
broadcast_map = sc.broadcast(fruit_collect_as_map)
# 取广播变量
fruit_name = fruit_ids.map(lambda index: broadcast_map.value[index])
print("查询过后的水果名字")
print(fruit_name.collect())
10.3 broadcast和accumulator练习
"""
1. 读取数据
2. 切割字符
3. 定义累加器,这里累加器可以计算非字母的个数
4. 定义广播变量 [# !]
5. 自定义函数累加非字母的表示
6. 执行统计
7 停止sparkcontext
"""
from pyspark import SparkConf, SparkContext
import re
if __name__ == '__main__':
conf = SparkConf().setAppName("sougou").setMaster("local[*]")
sc = SparkContext(conf=conf)
rdd1 = sc.textFile("hdfs://node1:8020/bigdata/data.txt")
"""
hadoop spark # hadoop spark
hadoop spark hadoop spark ! hadoop sparkhadoop spark #
hadoop spark hadoop spark hadoop spark %
hadoop spark hadoop spark hadoop spark !
! hadoop spark hadoop spark hadoop spark
"""
rdd2 = rdd1.filter(lambda line: (len(line) > 0)).flatMap(lambda line: re.split("\s+", line))
print(rdd2.collect())
acc_count = sc.accumulator(0)
symbol_rdd = sc.parallelize(["#", "%", "!"])
# broadcast的变量类型不能为rdd
broadcast_symbol = sc.broadcast(symbol_rdd.collect())
def add_num(x):
global acc_count
if x in broadcast_symbol.value:
acc_count.add(1)
return
rdd2.foreach(add_num)
print("total symbol: ", acc_count.value)
# ['hadoop', 'spark', '#', 'hadoop', 'spark', 'hadoop', 'spark', 'hadoop', 'spark', '!', 'hadoop', 'sparkhadoop', 'spark', '#', 'hadoop', 'spark', 'hadoop', 'spark', 'hadoop', 'spark', '%', 'hadoop', 'spark', 'hadoop', 'spark', 'hadoop', 'spark', '!', '!', 'hadoop', 'spark', 'hadoop', 'spark', 'hadoop', 'spark']
# total symbol: 6
rdd3 = rdd1.filter(lambda line: (len(line) > 0)).flatMap(lambda line: re.split("\s+", line))\
.filter(lambda s: s in broadcast_symbol.value).map(lambda s: (s, 1)).reduceByKey(lambda x, y: x+y)
print(rdd3.collect())
# [('#', 2), ('!', 3), ('%', 1)]
10.4 accumulator注意的问题
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("acc").setMaster("local[*]")
sc = SparkContext(conf=conf)
# 定义
acc_num = sc.accumulator(0)
def add_num(x):
if x % 2 == 0:
acc_num.add(1)
return 1
else:
return 0
rdd1 = sc.parallelize([i for i in range(1, 11)])
even_rdd = rdd1.filter(add_num)
# 没有触发action算子之前,acc_num是0,
print(acc_num.value)
# 0
print(even_rdd.collect())
# 触发action算子后才开始计数
print(acc_num.value)
# 5
# even_rdd算子没有缓存,所以再次触发action算子,会在原来的结果上面重新计数,结果变成10,导致结果异常
print(even_rdd.collect())
print(acc_num.value)
# 10
acc_num = sc.accumulator(0)
even_rdd2 = rdd1.filter(add_num)
# 对even_rdd2缓存
even_rdd2.cache()
even_rdd2.collect()
even_rdd2.collect()
# 缓存操作后,acc_num都为5
print(acc_num.value)
# 5
11. spark sql入门
创建一个环境并读取数据。
from pyspark.sql import SparkSession
from pyspark import SparkConf
if __name__ == '__main__':
conf = SparkConf().setAppName("sparksession").setMaster("local[*]")
spark = SparkSession.builder.config(conf=conf).getOrCreate()
sc = spark.sparkContext
fileDF = spark.read.text("/tmp/pycharm_project_553/PySpark-SparkSQL_2.3.0/data/data.txt")
print("fileDF counts {}".format(fileDF.count()))
fileDF.printSchema()
fileDF.show(truncate=False)
sc.stop()
11.1 方式一:RDD转Dataframe的第一种方式 createDataFrame
sparksql的初体验
from pyspark.sql import SparkSession, Row
if __name__ == '__main__':
spark = SparkSession.builder.appName("test").getOrCreate()
sc = spark.sparkContext
lines = sc.textFile("../data/people.txt")
"""
Michael, 29
Andy, 30
Justin, 19
"""
parts = lines.map(lambda l: l.split(","))
people = parts.map(lambda p: Row(name=p[0], age=int(p[1])))
schemaPeople = spark.createDataFrame(people)
schemaPeople.createOrReplaceTempView("people")
teenagers = schemaPeople.filter(schemaPeople["age"] >= 13).filter(schemaPeople["age"] <= 19)
teenNames = teenagers.rdd.map(lambda p: "Name: " + p.name).collect()
for name in teenNames:
print(name)
# Name: Justin
spark.stop()
11.2 方式二:通过StructedType构建DataFrame
"""
StructedType构建DataFrame
"""
from pyspark.sql import SparkSession, Row
from pyspark.sql.types import StringType, StructType, StructField
if __name__ == '__main__':
spark = SparkSession.builder.appName("test").getOrCreate()
sc = spark.sparkContext
lines = sc.textFile("../data/people.txt")
"""
Michael, 29
Andy, 30
Justin, 19
"""
parts = lines.map(lambda l: l.split(","))
people = parts.map(lambda p: (p[0], p[1].strip()))
schemaString = "name age"
fields = [StructField(field_name, StringType(), True) for field_name in schemaString.split()]
schema = StructType(fields)
schemaPeople = spark.createDataFrame(people, schema)
schemaPeople.createOrReplaceTempView("people")
results = spark.sql("select name from people")
results.show()
spark.stop()
11.3 方式三 直接toDF
"""
toDF构建DataFrame
"""
from pyspark.sql import SparkSession, Row
from pyspark.sql.types import StringType, StructType, StructField
if __name__ == '__main__':
spark = SparkSession.builder.appName("test").getOrCreate()
sc = spark.sparkContext
l = [('Ankit', 25), ('Jalfaizy', 22), ('saurabh', 20), ('Bala', 26)]
rdd = sc.parallelize(l)
df = rdd.toDF(["name", "age"])
df.show()
spark.stop()
11.4 方式四 由pandas构建
"""
pandas构建DataFrame
"""
from pyspark.sql import SparkSession, Row
import pandas as pd
from datetime import datetime, date
if __name__ == '__main__':
spark = SparkSession.builder.appName("test").getOrCreate()
sc = spark.sparkContext
pandas_df = pd.DataFrame({
'a': [1, 2, 3],
'b': [2., 3., 4.],
'c': ['string1', 'string2', 'string3'],
'd': [date(2000, 1, 1), date(2000, 2, 1), date(2000, 3, 1)],
'e': [datetime(2000, 1, 1, 12, 0), datetime(2000, 1, 2, 12, 0), datetime(2000, 1, 3, 12, 0)]
})
df = spark.createDataFrame(pandas_df)
df.show()
df.printSchema()
spark.stop()
11.5 外部数据转换成df
"""
{"name":"Michael"}
{"name":"Andy", "age":30}
{"name":"Justin", "age":19}
"""
# spark is an existing SparkSession
df = spark.read.json("file:///export/pyfolder1/pyspark-chapter03_3.8/data/people.json")
# Displays the content of the DataFrame to stdout
df.show()
11.6 sparksql实现wordcount
"""
explode
"""
from pyspark.sql import SparkSession
from pyspark.sql import functions
if __name__ == '__main__':
spark = SparkSession.builder.appName("word").getOrCreate()
sc = spark.sparkContext
fileDF = spark.read.text("../data/word.txt")
"""
hello you Spark Flink
hello me hello she Spark
"""
explodeDF = fileDF.withColumn("words", functions.explode(functions.split(functions.col("value"), ' ')))
explodeDF.show()
result1 = explodeDF.select("words").groupBy("words").count().orderBy("count", ascending=False)
result2 = explodeDF.select("words").groupBy("words").count().sort("count", ascending=False)
result2.show()
"""
+-----+-----+
|words|count|
+-----+-----+
|hello| 3|
|Spark| 2|
| me| 1|
|Flink| 1|
| you| 1|
| she| 1|
+-----+-----+
"""
11.7 Iris data的实现
from pyspark.sql import SparkSession, Row
from pyspark import SparkConf
import pyspark.sql.functions as F
if __name__ == '__main__':
conf = SparkConf().setAppName("iris").setMaster("local[*]")
spark = SparkSession.builder.config(conf=conf).getOrCreate()
sc = spark.sparkContext
sc.setLogLevel("WARN")
file_rdd = sc.textFile("file:///tmp/pycharm_project_553/PySpark-SparkSQL_2.3.0/data/iris/iris.data")
new_rdd = file_rdd.filter((lambda line: len(line.strip()) > 0 and (lambda line: len(line.strip().split(",")) == 5)))
print(f"count value is {
new_rdd.count()}")
iris_df = file_rdd.filter((lambda line: len(line.strip()) > 0 and (lambda line: len(line.strip().split(",")) == 5))) \
.map(lambda line: line.strip().split(",")) \
.map(lambda x: Row(sepal_length=x[0], sepal_width=x[1], petal_length=x[2], petal_width=x[3], irisclass=x[4])) \
.toDF()
iris_df.printSchema()
iris_df.show(2)
# +-----------+------------+-----------+------------+-----------+
# | irisclass | petal_length | petal_width | sepal_length | sepal_width |
# +-----------+------------+-----------+------------+-----------+
# | Iris - setosa | 1.4 | 0.2 | 5.1 | 3.5 |
# | Iris - setosa | 1.4 | 0.2 | 4.9 | 3.0 |
# +-----------+------------+-----------+------------+-----------+
iris_df.select("sepal_length").show(2)
iris_df.select(iris_df.sepal_length).show(2)
iris_df.select("sepal_length", "sepal_width").show(2)
iris_df.groupby("irisclass").count().show()
iris_df.groupby("irisclass").agg(F.count(F.col("irisclass")).alias("variable")).show()
# +---------------+--------+
# | irisclass | variable |
# +---------------+--------+
# | Iris - virginica | 50 |
# | Iris - setosa | 50 |
# | Iris - versicolor | 50 |
# +---------------+--------+
iris_df.createOrReplaceTempView("table_view")
spark.sql("""
select irisclass, count(1) as count
from table_view
group by irisclass
""").show()
from pyspark.sql import SparkSession, Row
from pyspark import SparkConf
import pyspark.sql.functions as F
if __name__ == '__main__':
conf = SparkConf().setAppName("iris").setMaster("local[*]")
spark = SparkSession.builder.config(conf=conf).getOrCreate()
sc = spark.sparkContext
sc.setLogLevel("WARN")
irisDF = spark.read.format("csv") \
.option("sep", ",") \
.option("header", "true") \
.option("inferSchema", "true") \
.load("file:///tmp/pycharm_project_553/PySpark-SparkSQL_2.3.0/data/iris/iris.csv")
irisDF.show()
irisDF.printSchema()
11.8 电影数据集案例
from pyspark import SparkConf
from pyspark.sql import SparkSession
import re
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
if __name__ == '__main__':
conf = SparkConf().setAppName("movies").setMaster("local[*]")
spark = SparkSession.builder.config(conf=conf).getOrCreate()
sc = spark.sparkContext
sc.setLogLevel("WARN")
# 读取文件
movies_rdd = sc.textFile("file:///tmp/pycharm_project_553/PySpark-SparkSQL_2.3.0/data/ml-100k/u.data")
print("movies count is", movies_rdd.count())
# 数据清洗
# moviesDF = movies_rdd \
# .filter(lambda line: (len(line.strip()) > 0) and (len(re.split("\s+", line.strip())) == 4)) \
# .map(lambda line: re.split("\s+", line.strip())) \
# .map(lambda line: (int(line[0]), int(line[1]), int(line[2]), int(line[3]))) \
# .toDF(["userid", "itemid", "rating", "timestamp"])
"""
root
|-- userid: long (nullable = true)
|-- itemid: long (nullable = true)
|-- rating: long (nullable = true)
|-- timestamp: long (nullable = true)
"""
moviesData = movies_rdd \
.filter(lambda line: (len(line.strip()) > 0) and (len(re.split("\s+", line.strip())) == 4)) \
.map(lambda line: re.split("\s+", line.strip())) \
.map(lambda line: (int(line[0]), int(line[1]), int(line[2]), int(line[3])))
movies_schema = StructType([
StructField('userid', StringType(), True),
StructField('itemid', IntegerType(), False),
StructField('rating', IntegerType(), False),
StructField('timestamp', IntegerType(), False)
])
moviesDF = spark.createDataFrame(moviesData, movies_schema)
moviesDF.show(5)
moviesDF.printSchema()
11.9 数据清洗一
from pyspark import SparkConf
from pyspark.sql import SparkSession
import re
from pyspark.sql.types import StructType, StructField, StringType, IntegerType, FloatType
if __name__ == '__main__':
conf = SparkConf().setAppName("movies").setMaster("local[*]")
spark = SparkSession.builder.config(conf=conf).getOrCreate()
sc = spark.sparkContext
sc.setLogLevel("WARN")
df = spark.createDataFrame([
(1, 144.5, 5.9, 33, 'M'),
(2, 167.2, 5.4, 45, 'M'),
(3, 124.1, 5.2, 23, 'F'),
(4, 144.5, 5.9, 33, 'M'),
(5, 133.2, 5.7, 54, 'F'),
(3, 124.1, 5.2, 23, 'F'),
(5, 129.2, 5.3, 42, 'M'),
], ['id', 'weight', 'height', 'age', 'gender'])
# 删除重复的记录
df1 = df.dropDuplicates()
df1.show()
# 删除除id字段重复的记录
df2 = df1.dropDuplicates(subset=[c for c in df1.columns if c != 'id'])
df2.show()
"""
+---+------+------+---+------+
| id|weight|height|age|gender|
+---+------+------+---+------+
| 5| 133.2| 5.7| 54| F|
| 1| 144.5| 5.9| 33| M|
| 2| 167.2| 5.4| 45| M|
| 3| 124.1| 5.2| 23| F|
| 5| 129.2| 5.3| 42| M|
+---+------+------+---+------+
"""
# 查看某一列是否有重复
import pyspark.sql.functions as F
df3 = df2.agg(F.count("id").alias("id_Count"), F.countDistinct("id").alias("id_distinct_count"))
df3.show()
"""
+--------+-----------------+
|id_Count|id_distinct_count|
+--------+-----------------+
| 5| 4|
+--------+-----------------+
"""
df4 = df2.withColumn("new_id", F.monotonically_increasing_id())
df4.show()
11.10 数据清洗二
from pyspark import SparkConf
from pyspark.sql import SparkSession
import pyspark.sql.functions as F
if __name__ == '__main__':
conf = SparkConf().setAppName("movies").setMaster("local[*]")
spark = SparkSession.builder.config(conf=conf).getOrCreate()
sc = spark.sparkContext
sc.setLogLevel("WARN")
df_miss = spark.createDataFrame([
(1, 143.5, 5.6, 28,'M', 100000),
(2, 167.2, 5.4, 45,'M', None),
(3, None, 5.2, None, None, None),
(4, 144.5, 5.9, 33, 'M', None),
(5, 133.2, 5.7, 54, 'F', None),
(6, 124.1, 5.2, None, 'F', None),
(7, 129.2, 5.3, 42, 'M', 76000)],
['id', 'weight', 'height', 'age', 'gender', 'income'])
# 统计每一行有多少缺失值
df_miss_sum = df_miss.rdd.map(lambda row: (row['id'], sum([c == None for c in row])))
# [(1, 0), (2, 1), (3, 4), (4, 1), (5, 1), (6, 2), (7, 0)]
print(df_miss_sum.collect())
df_miss.agg(F.count("id").alias("id_count"),
F.count("income").alias("income_count"),
F.count("*").alias("all")).show()
"""
+--------+------------+---+
|id_count|income_count|all|
+--------+------------+---+
| 7| 2| 7|
+--------+------------+---+
"""
# 统计每一列多少值没有缺失
df_miss.agg(*[F.count(t).alias(t+"dismissing") for t in df_miss.columns if t!="income"]).show()
"""
+------------+----------------+----------------+-------------+----------------+
|iddismissing|weightdismissing|heightdismissing|agedismissing|genderdismissing|
+------------+----------------+----------------+-------------+----------------+
| 7| 6| 7| 5| 6|
+------------+----------------+----------------+-------------+----------------+
"""
# 统计缺失值的比例
df_miss.agg(*[(1 - F.count(t)/F.count("*")).alias(t + "_rate_missing") for t in df_miss.columns]).show()
"""
+---------------+-------------------+-------------------+------------------+-------------------+-------------------+
|id_rate_missing|weight_rate_missing|height_rate_missing| age_rate_missing|gender_rate_missing|income_rate_missing|
+---------------+-------------------+-------------------+------------------+-------------------+-------------------+
| 0.0| 0.1428571428571429| 0.0|0.2857142857142857| 0.1428571428571429| 0.7142857142857143|
+---------------+-------------------+-------------------+------------------+-------------------+-------------------+
"""
# 删除income列
df_miss.select([c for c in df_miss.columns if c != "income"]).show()
"""
+---+------+------+----+------+
| id|weight|height| age|gender|
+---+------+------+----+------+
| 1| 143.5| 5.6| 28| M|
| 2| 167.2| 5.4| 45| M|
| 3| null| 5.2|null| null|
| 4| 144.5| 5.9| 33| M|
| 5| 133.2| 5.7| 54| F|
| 6| 124.1| 5.2|null| F|
| 7| 129.2| 5.3| 42| M|
+---+------+------+----+------+
"""
# 删除非空值少于 threshold的行
# drop rows that have less than `thresh` non-null values.
df_miss.dropna(thresh=3).show()
"""
+---+------+------+----+------+------+
| id|weight|height| age|gender|income|
+---+------+------+----+------+------+
| 1| 143.5| 5.6| 28| M|100000|
| 2| 167.2| 5.4| 45| M| null|
| 4| 144.5| 5.9| 33| M| null|
| 5| 133.2| 5.7| 54| F| null|
| 6| 124.1| 5.2|null| F| null|
| 7| 129.2| 5.3| 42| M| 76000|
+---+------+------+----+------+------+
"""
# 求解均值
df_miss.agg(*[F.mean(i).alias(i) for i in df_miss.columns if i != "gender"]).show()
"""
+---+------------------+-----------------+----+-------+
| id| weight| height| age| income|
+---+------------------+-----------------+----+-------+
|4.0|140.28333333333333|5.471428571428571|40.4|88000.0|
+---+------------------+-----------------+----+-------+
"""
# 填充缺失值
means = df_miss.agg(*[F.mean(i).alias(i) for i in df_miss.columns if i != "gender"]).toPandas().to_dict(orient="records")[0]
means["gender"] = "missing"
print(means)
# {'id': 4.0, 'weight': 140.28333333333333, 'height': 5.471428571428571, 'age': 40.4, 'income': 88000.0, 'gender': 'missing'}
df_miss.fillna(means).show()
"""
+---+------------------+------+---+-------+------+
| id| weight|height|age| gender|income|
+---+------------------+------+---+-------+------+
| 1| 143.5| 5.6| 28| M|100000|
| 2| 167.2| 5.4| 45| M| 88000|
| 3|140.28333333333333| 5.2| 40|missing| 88000|
| 4| 144.5| 5.9| 33| M| 88000|
| 5| 133.2| 5.7| 54| F| 88000|
| 6| 124.1| 5.2| 40| F| 88000|
| 7| 129.2| 5.3| 42| M| 76000|
+---+------------------+------+---+-------+------+
"""
11.11 电影评分项目一
from pyspark.sql import SparkSession
from pyspark import SparkConf, Row
import pyspark.sql.functions as F
import os
os.environ['SPARK_HOME'] = '/export/server/spark'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
conf = SparkConf().setAppName("movie").setMaster("local[*]")
spark = SparkSession.builder.config(conf=conf).config("spark.sql.shuffle.partitions", "2").getOrCreate()
sc = spark.sparkContext
ratingRDD = sc.textFile("file:///tmp/pycharm_project_553/PySpark-SparkSQL_2.3.0/data/ml-1m/ratings.dat")
ratingDF = ratingRDD \
.filter(lambda line: len(line.strip()) > 0 and len(line.strip().split("::")) == 4) \
.map(lambda line: line.strip().split("::")) \
.map(lambda p: Row(userid=int(p[0]), movieId=int(p[1]), ratings=float(p[2]), timestep=int(p[3]))) \
.toDF()
ratingDF.show(2)
# 获取top10电影,并且每个电影评分次大于200
ratingDF.createOrReplaceTempView("table_view")
# sql 操作
# spark.sql("""
# select movieId, round(avg(ratings), 2) avg_ratings, count(movieId) cnt_movies
# from table_view
# group by movieId
# having cnt_movies>2000
# order by avg_ratings desc, cnt_movies desc
# limit 10
# """).show()
"""
+-------+-----------+----------+
|movieId|avg_ratings|cnt_movies|
+-------+-----------+----------+
| 318| 4.55| 2227|
| 858| 4.52| 2223|
| 527| 4.51| 2304|
| 1198| 4.48| 2514|
| 260| 4.45| 2991|
| 2762| 4.41| 2459|
| 593| 4.35| 2578|
| 2028| 4.34| 2653|
| 2858| 4.32| 3428|
| 2571| 4.32| 2590|
+-------+-----------+----------+
"""
# dsl操作
resultDF = ratingDF.select(["movieId", "ratings"]) \
.groupby("movieId") \
.agg(F.round(F.avg("ratings"), 2).alias("avg_ratings"), F.count("movieId").alias("cnt_movies")) \
.filter("cnt_movies > 2000") \
.orderBy(["avg_ratings", "cnt_movies"], ascending=[0, 0]) \
.limit(10)
resultDF.show()
# 数据输出
# csv
# resultDF.coalesce(1).write.csv("file:///tmp/pycharm_project_553/PySpark-SparkSQL_2.3.0/data/ml-1m/output")
# 写入到mysql
resultDF \
.coalesce(1) \
.write \
.format("jdbc") \
.mode("overwrite") \
.option("driver", "com.mysql.jdbc.Driver") \
.option("url", "jdbc:mysql://node1:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true") \
.option("dbtable", "bigdata.tb_top10_movies") \
.option("user", "root") \
.option("password", "123456") \
.save()
sc.stop()
11.12 spark读写mysql
from pyspark.sql import SparkSession
from pyspark import SparkConf, Row
import pyspark.sql.functions as F
import os
os.environ['SPARK_HOME'] = '/export/server/spark'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
conf = SparkConf().setAppName("movie").setMaster("local[*]")
spark = SparkSession.builder.config(conf=conf).config("spark.sql.shuffle.partitions", "2").getOrCreate()
sc = spark.sparkContext
# 读取文件
jdbcDF = spark.read \
.format("jdbc") \
.option("url", "jdbc:mysql://node1:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true") \
.option("dbtable", "bigdata.tb_top10_movies") \
.option("user", "root") \
.option("password", "123456") \
.load()
jdbcDF.show()
# 写入文件
rdd = sc.parallelize([(9999, 5.5, 9999), (9999, 5.5, 9999)]).map(lambda line: Row(movieId=line[0], avg_ratings=line[1], cnt_movies=line[2]))
df = rdd.toDF()
df.show()
df \
.coalesce(1) \
.write \
.format("jdbc") \
.mode("overwrite") \
.option("driver", "com.mysql.jdbc.Driver") \
.option("url", "jdbc:mysql://node1:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true") \
.option("dbtable", "bigdata.tb_top10_movies") \
.option("user", "root") \
.option("password", "123456") \
.save()
11.13 Sparksql
import os
from pyspark.sql import SparkSession
# 这里可以选择本地PySpark环境执行Spark代码,也可以使用虚拟机中PySpark环境,通过os可以配置
os.environ['SPARK_HOME'] = '/export/server/spark-2.3.0-bin-hadoop2.7'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
spark = SparkSession\
.builder\
.appName("testHive")\
.master("local[*]")\
.enableHiveSupport()\
.config("spark.sql.warehouse.dir", "hdfs://node1:8020/usr/hive/warehouse")\
.config("hive.metastore.uris", "thrift://node1:9083")\
.getOrCreate()
spark.sql("show databases").show()
spark.sql("use sparkhive").show()
spark.sql("show tables").show()
# spark.sql("create table if not exists person (id int, name string, age int) row format delimited fields terminated by ','")
spark.sql("LOAD DATA INPATH '/bigdata/stu.txt' INTO TABLE person")
spark.sql("select * from person ").show()
"""
+---+-----+---+
| id| name|age|
+---+-----+---+
| 1| Tony| 10|
| 2|Janet| 12|
| 3| Jack| 20|
| 4|Sally| 24|
+---+-----+---+
"""
import pyspark.sql.functions as fn
spark.read.table("person")\
.groupBy("name")\
.agg(fn.round(fn.avg("age"), 2).alias("avg_age"))\
.show(10, truncate=False)
spark.stop()
11.14 开窗函数
import os
from pyspark.sql import SparkSession
# 这里可以选择本地PySpark环境执行Spark代码,也可以使用虚拟机中PySpark环境,通过os可以配置
os.environ['SPARK_HOME'] = '/export/server/spark-2.3.0-bin-hadoop2.7'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
spark = SparkSession\
.builder\
.appName("testHive")\
.master("local[*]")\
.enableHiveSupport()\
.config("spark.sql.warehouse.dir", "hdfs://node1:8020/usr/hive/warehouse")\
.config("hive.metastore.uris", "thrift://node1:9083")\
.getOrCreate()
scoreDF = spark.sparkContext.parallelize([
("a1", 1, 80),
("a2", 1, 78),
("a3", 1, 95),
("a4", 2, 74),
("a5", 2, 92),
("a6", 3, 99),
("a7", 3, 99),
("a8", 3, 45),
("a9", 3, 55),
("a10", 3, 78),
("a11", 3, 100)]
).toDF(["name", "class", "score"])
scoreDF.createOrReplaceTempView("scores")
scoreDF.show()
spark.sql("select count(name) from scores").show()
spark.sql("select name, class, score, count(name) over() name_count from scores").show()
"""
+----+-----+-----+----------+
|name|class|score|name_count|
+----+-----+-----+----------+
| a1| 1| 80| 11|
| a2| 1| 78| 11|
| a3| 1| 95| 11|
| a4| 2| 74| 11|
| a5| 2| 92| 11|
| a6| 3| 99| 11|
| a7| 3| 99| 11|
| a8| 3| 45| 11|
| a9| 3| 55| 11|
| a10| 3| 78| 11|
| a11| 3| 100| 11|
+----+-----+-----+----------+
"""
# 聚合开窗函数
spark.sql("select name, class, score, count(name) over (partition by class) name_count from scores").show()
"""
+----+-----+-----+----------+
|name|class|score|name_count|
+----+-----+-----+----------+
| a4| 2| 74| 2|
| a5| 2| 92| 2|
| a1| 1| 80| 3|
| a2| 1| 78| 3|
| a3| 1| 95| 3|
| a6| 3| 99| 6|
| a7| 3| 99| 6|
| a8| 3| 45| 6|
| a9| 3| 55| 6|
| a10| 3| 78| 6|
| a11| 3| 100| 6|
+----+-----+-----+----------+
"""
# ROW_NUMBER 顺序排序
spark.sql("select name, class, score, row_number() over(order by score) rank from scores").show()
"""
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a4| 2| 74| 3|
| a2| 1| 78| 4|
| a10| 3| 78| 5|
| a1| 1| 80| 6|
| a5| 2| 92| 7|
| a3| 1| 95| 8|
| a6| 3| 99| 9|
| a7| 3| 99| 10|
| a11| 3| 100| 11|
+----+-----+-----+----+
"""
# row_number + partitionby分组进行排序
spark.sql("select name, class, score, row_number() over(partition by class order by score) rank from scores").show()
"""
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a4| 2| 74| 1|
| a5| 2| 92| 2|
| a2| 1| 78| 1|
| a1| 1| 80| 2|
| a3| 1| 95| 3|
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a10| 3| 78| 3|
| a6| 3| 99| 4|
| a7| 3| 99| 5|
| a11| 3| 100| 6|
+----+-----+-----+----+
"""
# rank比row_number 更加智能,成绩一样支持并列
spark.sql("select name, class, score, rank() over(partition by class order by score) rank from scores").show()
"""
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a4| 2| 74| 1|
| a5| 2| 92| 2|
| a2| 1| 78| 1|
| a1| 1| 80| 2|
| a3| 1| 95| 3|
| a8| 3| 45| 1|
| a9| 3| 55| 2|
| a10| 3| 78| 3|
| a6| 3| 99| 4|
| a7| 3| 99| 4|
| a11| 3| 100| 6|
+----+-----+-----+----+
"""
# dense_rank 依然是升序来排列,但是和rank的区别在于没有并列的概念,两个第一名,然后接下来的是第二名, 这里加上desc就变成降序了
spark.sql("select name, class, score, dense_rank() over(partition by class order by score desc) rank from scores").show()
"""
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a5| 2| 92| 1|
| a4| 2| 74| 2|
| a3| 1| 95| 1|
| a1| 1| 80| 2|
| a2| 1| 78| 3|
| a11| 3| 100| 1|
| a6| 3| 99| 2|
| a7| 3| 99| 2|
| a10| 3| 78| 3|
| a9| 3| 55| 4|
| a8| 3| 45| 5|
+----+-----+-----+----+
"""
# ntile 排名后进行分组,下面是排名后,分成3个组,1-3
spark.sql("select name, class, score, ntile(3) over(order by score) rank from scores").show()
"""
+----+-----+-----+----+
|name|class|score|rank|
+----+-----+-----+----+
| a8| 3| 45| 1|
| a9| 3| 55| 1|
| a4| 2| 74| 1|
| a2| 1| 78| 1|
| a10| 3| 78| 2|
| a1| 1| 80| 2|
| a5| 2| 92| 2|
| a3| 1| 95| 2|
| a6| 3| 99| 3|
| a7| 3| 99| 3|
| a11| 3| 100| 3|
+----+-----+-----+----+
"""
spark.stop()
11. 15 UDF(User defined aggregation function)
import os
import pandas as pd
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf
from pyspark.sql.types import IntegerType, FloatType
# 这里可以选择本地PySpark环境执行Spark代码,也可以使用虚拟机中PySpark环境,通过os可以配置
os.environ['SPARK_HOME'] = '/export/server/spark-2.3.0-bin-hadoop2.7'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
spark = SparkSession\
.builder\
.appName("testHive")\
.master("local[*]")\
.enableHiveSupport()\
.config("spark.sql.warehouse.dir", "hdfs://node1:8020/usr/hive/warehouse")\
.config("hive.metastore.uris", "thrift://node1:9083")\
.getOrCreate()
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
df_pd = pd.DataFrame(
data={
'integers': [1, 2, 3],
'floats': [-1.0, 0.6, 2.6],
'integer_arrays': [[1, 2], [3, 4.6], [5, 6, 8, 9]]}
)
df = spark.createDataFrame(df_pd)
df.printSchema()
df.show()
def square(x):
return x**2
# udf的demo制定了返回为integer类型,实际返回了float类型会置为空
square_udf_int = udf(lambda z: square(z), IntegerType())
df.select('integers', 'floats', square_udf_int('integers').alias('int_squared'),
square_udf_int('floats').alias('float_squared')).show()
"""
+--------+------+-----------+-------------+
|integers|floats|int_squared|float_squared|
+--------+------+-----------+-------------+
| 1| -1.0| 1| null|
| 2| 0.6| 4| null|
| 3| 2.6| 9| null|
+--------+------+-----------+-------------+
"""
# 同样的指定了float返回得到integer也会变成null
square_udf_float = udf(lambda z:square(z), FloatType())
df.select('integers', 'floats', square_udf_float('integers').alias('int_squared'),
square_udf_float('floats').alias('float_squared')).show()
"""
+--------+------+-----------+-------------+
|integers|floats|int_squared|float_squared|
+--------+------+-----------+-------------+
| 1| -1.0| null| 1.0|
| 2| 0.6| null| 0.36|
| 3| 2.6| null| 6.76|
+--------+------+-----------+-------------+
"""
spark.stop()
11.15 使用装饰器来定义udf
import os
import pandas as pd
from pyspark.sql import SparkSession
from pyspark.sql.functions import udf
from pyspark.sql.types import IntegerType, FloatType
# 这里可以选择本地PySpark环境执行Spark代码,也可以使用虚拟机中PySpark环境,通过os可以配置
os.environ['SPARK_HOME'] = '/export/server/spark-2.3.0-bin-hadoop2.7'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
spark = SparkSession\
.builder\
.appName("testHive")\
.master("local[*]")\
.enableHiveSupport()\
.config("spark.sql.warehouse.dir", "hdfs://node1:8020/usr/hive/warehouse")\
.config("hive.metastore.uris", "thrift://node1:9083")\
.getOrCreate()
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
df_pd = pd.DataFrame(
data={
'integers': [1, 2, 3],
'floats': [-1.0, 0.6, 2.6],
'integer_arrays': [[1, 2], [3, 4.6], [5, 6, 8, 9]]}
)
df = spark.createDataFrame(df_pd)
df.printSchema()
df.show()
# 使用装饰器来定义
@udf(returnType=IntegerType())
def square(x):
return x**2
df.select('integers', square('integers').alias('int_squared')).show()
"""
+--------+-----------+
|integers|int_squared|
+--------+-----------+
| 1| 1|
| 2| 4|
| 3| 9|
+--------+-----------+
"""
spark.stop()
11.16 混合类型的输出
import os
import pandas as pd
from pyspark.sql import SparkSession
import string
from pyspark.sql.functions import udf
from pyspark.sql.types import IntegerType, FloatType, ArrayType, StructType, StructField, StringType
# 这里可以选择本地PySpark环境执行Spark代码,也可以使用虚拟机中PySpark环境,通过os可以配置
os.environ['SPARK_HOME'] = '/export/server/spark-2.3.0-bin-hadoop2.7'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
spark = SparkSession\
.builder\
.appName("testHive")\
.master("local[*]")\
.enableHiveSupport()\
.config("spark.sql.warehouse.dir", "hdfs://node1:8020/usr/hive/warehouse")\
.config("hive.metastore.uris", "thrift://node1:9083")\
.getOrCreate()
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
df_pd = pd.DataFrame(
data={
'integers': [1, 2, 3],
'floats': [-1.0, 0.6, 2.6],
'integer_arrays': [[1, 2], [3, 4.6], [5, 6, 8, 9]]}
)
df = spark.createDataFrame(df_pd)
def convert_ascii(number):
return [number, string.ascii_letters[number]]
array_schema = StructType([
StructField('number', IntegerType(), nullable=False),
StructField('letters', StringType(), nullable=False)
])
spark_convert_ascii = udf(lambda z: convert_ascii(z), array_schema)
df_ascii = df.select('integers', spark_convert_ascii('integers').alias('ascii_map'))
df_ascii.show()
spark.stop()
11.17 udf实战
import os
import pandas as pd
from pyspark.sql import SparkSession
import string
from pyspark.sql.functions import udf
from pyspark.sql.types import IntegerType, FloatType, ArrayType, StructType, StructField, StringType
# 这里可以选择本地PySpark环境执行Spark代码,也可以使用虚拟机中PySpark环境,通过os可以配置
os.environ['SPARK_HOME'] = '/export/server/spark-2.3.0-bin-hadoop2.7'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
spark = SparkSession\
.builder\
.appName("testHive")\
.master("local[*]")\
.enableHiveSupport()\
.config("spark.sql.warehouse.dir", "hdfs://node1:8020/usr/hive/warehouse")\
.config("hive.metastore.uris", "thrift://node1:9083")\
.getOrCreate()
spark.conf.set("spark.sql.execution.arrow.enabled", "true")
@udf(returnType=IntegerType())
def slen(s):
return len(s)
@udf(returnType=StringType())
def to_upper(s):
return s.upper()
@udf(returnType=IntegerType())
def add_one(x):
return x+1
df = spark.createDataFrame([(1, "John Doe", 21)], ("id", "name", "age"))
# 普通的实现方法
result = df.select(slen("name"), to_upper("name"), add_one("age"))
result.show()
"""
+----------+--------------+------------+
|slen(name)|to_upper(name)|add_one(age)|
+----------+--------------+------------+
| 8| JOHN DOE| 22|
+----------+--------------+------------+
"""
# sql实现
spark.udf.register("slen", slen)
spark.udf.register("to_upper", to_upper)
spark.udf.register("add_one", add_one)
df.createOrReplaceTempView("table")
spark.sql("select slen(name) as slen2, to_upper(name), add_one(age) from table").show()
"""
+-----+--------------+------------+
|slen2|to_upper(name)|add_one(age)|
+-----+--------------+------------+
| 8| JOHN DOE| 22|
+-----+--------------+------------+
"""
spark.stop()
11.8 pandasUDF
# -*- coding: utf-8 -*-
# Program function:
import os
import pandas as pd
from pyspark.sql import SparkSession
from pyspark.sql.functions import col, pandas_udf
from pyspark.sql.types import LongType
# Import data types
os.environ['SPARK_HOME'] = '/export/servers/spark'
PYSPARK_PYTHON = "/root/anaconda3/envs/pyspark_env/bin/python"
# 当存在多个版本时,不指定很可能会导致出错
os.environ["PYSPARK_PYTHON"] = PYSPARK_PYTHON
os.environ["PYSPARK_DRIVER_PYTHON"] = PYSPARK_PYTHON
if __name__ == '__main__':
spark = SparkSession.builder \
.appName('test') \
.getOrCreate()
sc = spark.sparkContext
# 方式1:普通方式创建pandas_func
def multiply_func(a: pd.Series, b: pd.Series) -> pd.Series:
return a * b
multiply = pandas_udf(multiply_func, returnType=LongType())
# The function for a pandas_udf should be able to execute with local Pandas data
x = pd.Series([1, 2, 3])
print(multiply_func(x, x))
# 0 1
# 1 4
# 2 9
# dtype: int64
# Create a Spark DataFrame, 'spark' is an existing SparkSession
df = spark.createDataFrame(pd.DataFrame(x, columns=["x"]))
# Execute function as a Spark vectorized UDF
df.select(multiply(col("x"), col("x"))).show()
# +-------------------+
# |multiply_func(x, x)|
# +-------------------+
# | 1|
# | 4|
# | 9|
# +-------------------+
print("=" * 100)
# 方式2:装饰器方法
@pandas_udf(LongType())
def multiply_func1(a: pd.Series, b: pd.Series) -> pd.Series:
return a * b
df.select(multiply_func1(col("x"), col("x")))\
.withColumnRenamed("multiply_func1(x, x)","xxx").show()
spark.stop()