推荐系统
- 假设有四位用户对3部爱情片和2部动作片分别进行了评分。其中每个用户都有一部没有给出评分,推荐系统就根据这些数据来推测用户对这些未评分的电影会给出多少分。
- 其中:n_u表示用户数量;n_m表示电影数量;r(i,j)=1表示第j位用户已经对第i部电影进行了评分。y(i,j)表示第j位用户给第i部的电影的评分

解决此类问题可以使用线性回归的思想,那么我们的目标就是优化一个θ,来使的θ.T*x的值与实际值y(i,j)相近。公式如下:


1 协同过滤
选择特征:
- 比如说我们已经知道了用户对电影的评分(θ),我们要寻找一个特征。
- 我们的优化目标就从θ转到了优化x。

-
第一个式子的目标是优化θ,其中i:r(i,j)=1是指对该用户评价过的电影求和
-
第二个式子的目标是优化x,其中j:r(i,j)=1是指对某一部电影对评价过它的用户j求和
-
第三个式子的目标是同时优化θ和x,其中(i,j):r(i,j)=1是指对所有有分数的电影进行求和。

-
流程:
注:这里不用加x0和θ0

矢量化计算:
-
例子:通过用户最佳浏览的商品来推测出用户可能会购买的其他产品
-
紫色圈的数据表页用户1对于电影1的评分

均值归一化:
-
假设我们现在有了用户5,并且用户5对所有的电影都没有给出评分。那么当我们尝试去优化θ(5)的时候,我们得到的θ(5)应该是[0,0],这样我们的算法在预测用户5对电影的评分是就都是0。

-
首先取前面四个用户对每一部电影的评分均值,然后得出向量μ。用μ来作为用户5对每个电影的评分

2 协同过滤代码实战
- 读取数据,分析数据
文件当中包含的数据包括:Y:每个用户对每一步电影的评分(每一列表示每一个用户对所有电影的评分情况);R:每个用户是否对某一步电影进行了评分(是=1,否=0)
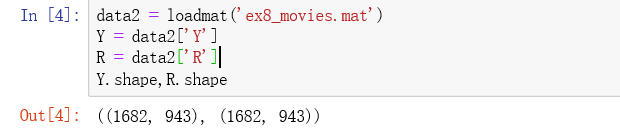
data2 = loadmat('ex8_movies.mat')
Y = data2['Y']
R = data2['R']
Y.shape,R.shape
结果如下:
- 根据公式编写代价函数
def cost(params,Y,R,features):
"""计算代价函数
Params:
params:存放X与Theta数据的narray
Y:电影数量*用户数量的矩阵(包含了每一位用户对所有电影的平分情况)
R:电影数量*用户数量的矩阵(用1表示第i个用户对第j部电影进行了评分)
features:特征数量
return:
J:代价函数"""
Y= np.mat(Y)
R = np.mat(R)
num_movies,num_users = Y.shape
X = np.reshape(params[:num_movies*features],(num_movies,features)) #(1682,10)
Theta = np.reshape(params[num_movies*features:],(num_users,features)) #(943,10)
J = 0
error = np.multiply(X@Theta.T - Y,R) #(1628,943),乘R的原因在于计算评价过的电影的误差
square_error = np.power(error,2)
J = (1/2) * np.sum(square_error)
return J
if __name__ == '__main__':
movies = 5
users = 4
features = 5
X_ = X[:movies,:features]
Theta_ = Theta[:users,:features]
Y_ = Y[:movies,:users]
R_ = R[:movies,:users]
params_ = np.concatenate((np.ravel(X_),np.ravel(Theta_)))
J = cost(params_,Y_,R_,features)
print(J)
结果如下:

- 编写代替度函数的代价函数
def cost(params,Y,R,features):
"""计算代价函数
Params:
params:存放X与Theta数据的narray
Y:电影数量*用户数量的矩阵(包含了每一位用户对所有电影的平分情况)
R:电影数量*用户数量的矩阵(用1表示第i个用户对第j部电影进行了评分)
features:特征数量
return:
J:代价函数
grad:包含X与Theta梯度函数的narray"""
Y= np.mat(Y)
R = np.mat(R)
num_movies,num_users = Y.shape
X = np.reshape(params[:num_movies*features],(num_movies,features)) #(1682,10)
Theta = np.reshape(params[num_movies*features:],(num_users,features)) #(943,10)
J = 0
X_grad = np.zeros((num_movies,features))
Theta_grad = np.zeros((num_users,features))
error = np.multiply(X@Theta.T - Y,R) #(1628,943),乘R的原因在于计算评价过的电影的误差
square_error = np.power(error,2)
J = (1/2) * np.sum(square_error)
X_grad = error@Theta #(1682,10)
Theta_grad = error.T@X #(943,10)
grad = np.concatenate((np.ravel(X_grad),np.ravel(Theta_grad)))
return J,grad
- 编写带正则化的梯度函数
def reg_cost(params,Y,R,features,learning_rate):
"""计算代价函数
Params:
params:存放X与Theta数据的narray
Y:电影数量*用户数量的矩阵(包含了每一位用户对所有电影的平分情况)
R:电影数量*用户数量的矩阵(用1表示第i个用户对第j部电影进行了评分)
features:特征数量
return:
J:代价函数"""
Y= np.mat(Y)
R = np.mat(R)
num_movies,num_users = Y.shape
X = np.reshape(params[:num_movies*features],(num_movies,features)) #(1682,10)
Theta = np.reshape(params[num_movies*features:],(num_users,features)) #(943,10)
J = 0
X_grad = np.zeros((num_movies,features))
Theta_grad = np.zeros((num_users,features))
error = np.multiply(X@Theta.T - Y,R) #(1628,943),乘R的原因在于计算评价过的电影的误差
square_error = np.power(error,2)
J = (1/2) * np.sum(square_error)
J = J + (learning_rate/2)*np.sum(np.power(Theta,2))
J = J + (learning_rate/2)*np.sum(np.power(X,2))
X_grad = error@Theta + (learning_rate*X)#(1682,10)
Theta_grad = error.T@X + (learning_rate*Theta)#(943,10)
grad = np.concatenate((np.ravel(X_grad),np.ravel(Theta_grad)))
return J,grad
- 来给自己推荐电影,这里运用练习中给出的数据,首先读取文件,存储到字典当中
with open('movie_ids.txt',encoding= 'gbk') as f:
movie_idx={
}
for each_movie in f:
each_movie = each_movie.strip()
tokens = each_movie.split(' ',1)
movie_idx[int(tokens[0])-1] = tokens[1]
ratings = np.zeros((1682, 1)) #添加自己的一列
ratings[0] = 4
ratings[6] = 3
ratings[11] = 5
ratings[53] = 4
ratings[63] = 5
ratings[65] = 3
ratings[68] = 5
ratings[97] = 2
ratings[182] = 4
ratings[225] = 5
ratings[354] = 5
Y_add = np.append(Y,ratings,axis=1)
R_add = np.append(R,ratings!=0,axis=1)
movie_idx[0]
- 进行均值归一化
步骤:计算每一部电影的评价分->用原来的电影评分-平均分->
movies_num =Y.shape[0]
user_num =Y.shape[1]
features =10
learning_rate = 10.
X_test = np.random.random(size=(movies_num*features)) #随机初始化
Theta_test = np.random.random(size=(user_num*features))
params_test = np.concatenate((X_test.ravel(),Theta_test.ravel()))
# 均值归一化
Ymean = np.zeros((Y.shape[0],1)) #初始化所有电影的评价得分
Ynorm = np.zeros((Y.shape[0],user_num))
m = Y.shape[0]
for i in range(m):
index = np.where(R[i,:]==1)[0]
Ymean[i] = Y[i,index].mean()
Ynorm[i,index] = Y[i,index]-Ymean[i]
Ynorm.mean()

- 训练模型
from scipy.optimize import minimize
fmin = minimize(fun=reg_cost
,x0=params_test
,args=(Ynorm,R_add,features,learning_rate)
,method = 'CG', jac = True,options={
'maxiter':100})
fmin
协同优化

- 推荐电影
X = np.reshape(fmin.x[:movies_num*features],(movies_num,features))
Theta = np.reshape(fmin.x[movies_num*features:],(user_num,features))
predictions = X@Theta.T #所有的预测值
my_pred = predictions[:,-1].reshape(Ymean.shape[0],1) + Ymean #预测我自己的电影偏好
#获取喜欢电影前十部的索引
inx = np.argsort(my_pred,axis=0)[::-1]
count = 1
for i in range(10):
movie_name = movie_idx[int(inx[i,:])]
print('Top {} movies U might like:{}'.format(count,movie_name))
count+=1

3 大数据算法
3.1 随机梯度下降
-
如果当我们的数据集有10000000条数据,那么这个计算量就会非常的大,此时如果再去使用梯度下降,我们会耗费过多的计算力。大数据算法就是用来解决这个问题的。
-
Stochastic梯度下降算法的思想是首先,随机打乱数据,然后每一次迭代只要拟合一个训练样本即可。其中cost函数发生了变化。

-
随机梯度下降是迂回前进的,最后会在全局最优的周围徘徊。

3.2 Mini-batch 梯度下降
-
Mini-batch梯度下降就是每次迭代计算b个样本。

-
在使用随机梯度下降时,由于我们的θ优化走的是一条迂回的路线,因此我们有可能有时会错失获取最佳θ的机会。面对这个问题,我们可以每迭代1000次就计算一次代价函数,有助于我们选择最好的θ

- 在绘制代价函数时可能会遇到以下四种情况:
- 通过让α变小,我们可以获得红色的折线
- 第二幅图显示了,如果我们每5000个样本计算一次代价函数值,那么我们就会获得一个相对平滑的曲线
- 第三幅图显示了,我们如果每1000个样本计算一次代价函数值可能不会得到这么好的效果,应加大数量
- 第四幅图显示了,α过大出现的情况

4 在线学习算法
-
从时候的数据流当中进行学习
-
例子:比如你拥有一个快递网站,用户访问你的网站获取将其包裹从A地邮寄到B地的价格(x),然后决定是否邮寄(y)。在线学习算法就是每次一有用户进来就优化一次θ,然后随着用户进来的越来越多,我们的模型会越来越适应消费者的需求。这种方法适用于用户流比较大的网站。

4.1 Map-Reduce:
- 思想:将训练集数据分成k份,分别传给k个计算机进行计算,随后汇总到一个中心处理的计算机,来进行最后的处理,可以计算的非常的快速。


5 Photo OCR
-
Photo OCR又称照片光学字符识别,目的是让计算机提取图片中的文字,然后通过输入一些文字就可以找到目标照片
-
Pipeline
首先找到文字部分,然后切割识别,分类。


6 滑动窗口分类
- 例子:识别行人
- 首先给定训练集,有行人和没有行人,训练出一个分类模型

2. 然后用一个矩形框去遍历图片的所有像素,然后找到行人。

- 例子:文字识别
-
首先给出正样本和负样本

-
然后用框去遍历,下左白色部分是指程序认为有文字的地方

- 然后再去放大白色区域部分,找到符合的部分

全部知识点
