点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达作者丨镜子 编辑丨极市平台
极市导读
本文提出了一个专用于商标的多标签分类和相似性检索系统,综合考虑商标的形状、颜色、商业领域、语义、一般特征,并允许用户对以上特征进行组合和权重分配。

论文地址:https://arxiv.org/pdf/2205.05419v1.pdf
商标检索是我最早接触的一个商业落地项目,商标检索不同于一般的图像检索,有很多独特的性质,当时我花了很长时间去研究和探索,后来我开发的商标检索系统被全球上千家知识产权代理所使用过。如今数年过去,整个深度学习领域发展进步了很多,最近碰巧刷到了arxiv上这篇最新的商标检索论文,于是仔细研读了一番。
0. 简介
商标是一种图片,所以商标检索技术自然是与图像检索领域息息相关的,然而商标的特殊之处在于,它的内容可能是纯文字、纯图形,或者图形和文字的组合,图形也既可能是真实图片(照片),也可以是抽象的图形(圆圈、三角、矩形、线条)。
文字是人类才能识别的一种特殊符号,在商标中很多时候会与图形进行混淆,干扰检索结果;抽象的图形也往往具有歧义性,不同的人会因为关注点的不同而识别为不同的东西。因此,传统的基于图像信息的检索方法,并不一定能在商标检索中取得最理想的效果。
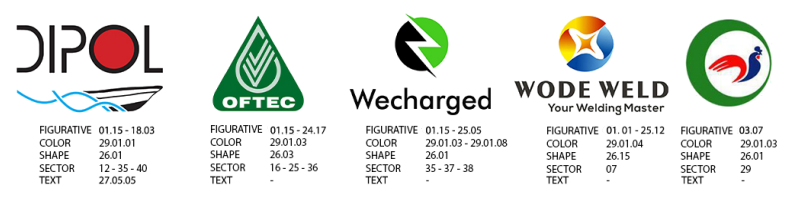
本文提出了一个专用于商标的多标签分类和相似性检索系统,综合考虑商标的形状、颜色、商业领域、语义、一般特征,并允许用户对以上特征进行组合和权重分配。
由于商标中的文字内容通常是公司名称等与分类无关的内容,文字的存在还会被视为图形造成干扰,因此本文提出使用一个文字检测网络定位文字内容,然后通过一个擦除网络来将文字从商标中消除。
目前商标分类方式中最普遍使用和认可的维也纳分类法,在多标签分类任务中也存在一定问题,本文结合另外几种商标分类方式,对维也纳分类进行了重新的梳理和整合。
本文的贡献如下:
在预处理阶段增加了文字检测,以及一个配合使用的文字消除方法,来提升检索效果。
多个模型提取不同特征然后融合,在相似度计算部分提出了一个权重分配方案。
通过对维也纳分类编码进行重组,提出了一套多标签分类标注。
结合现有的分类拓扑结构,从设计的角度来理解和对比维也纳特征和检索。
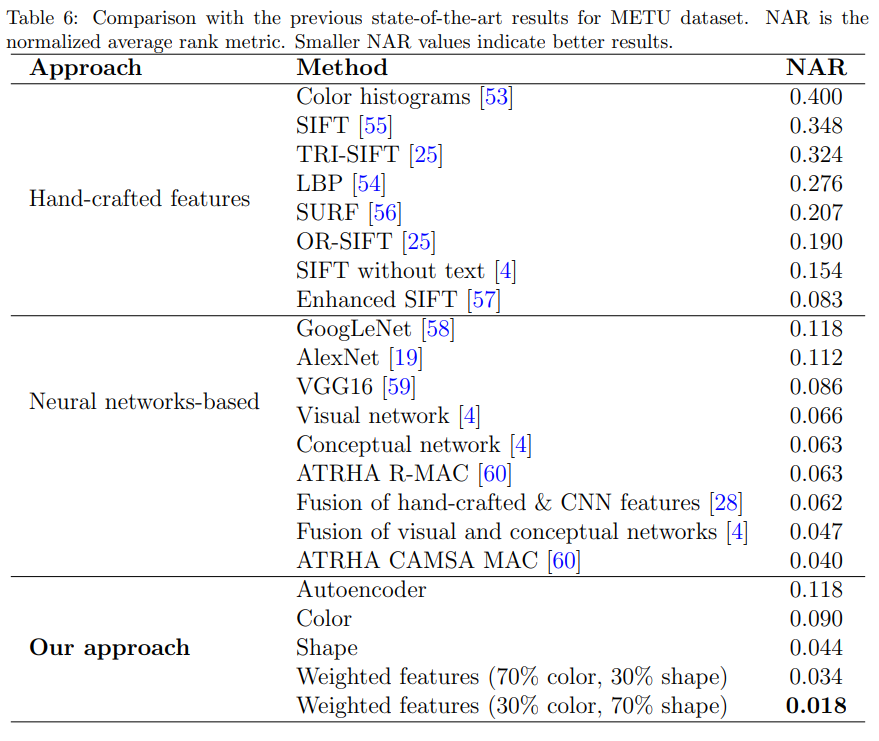
将本文的方法和过去的SOTA方案进行了质量评估
1. 背景
1.1 商标检索
传统的商标检索方法,一般是通过提取一系列手工特征,然后用KNN算法来进行相似度比较,常用的特征包括颜色直方图、形状、SIFT局部特征描述子等,大多数情况下,还需要使用一个词袋系统来减少特征维度,相似度一般基于特征向量的距离。
随着深度学习技术的到来,特征提取很自然地由卷积神经网络来完成,更好的网络结构,不同的监督学习方式,都可以优化特征质量使检索效果提升。
1.2 多标签分类
由于商标是多标签标注的,通常一个商标会带有多个不同的标注信息,因此商标的检索需要一个多标签分类模型。基于深度学习的多标签分类通常依靠在网络输出层使用Sigmoid激活函数,配合BCELoss来监督学习,不过自从ViT火了以后,我之前也有关注到基于Transformer的多标签分类模型,总的来说,多标签分类准确度的提升对于商标检索的质量也是至关重要的。
不过本文使用的多标签分类方法还比较原始,遵循了我上面描述的那一套流程,并没有用到损失函数和模型结构上的改进,如果让我来开发这个系统应该会加上这部分改进。
1.3 数据集和分类拓扑结构
大部分的商标数据普通人其实是很难获取的,虽然商标局的网站允许免费查询,但你想一次性获得大批量的商标数据却是很难的,不过有需求就有市场,业内也有一些的商标数据供应商负责收集和出售这部分数据,而且价格相当不菲。
之后也有人公开了几个免费的商标数据集用于研究目的,包括Large Logo Dataset(LLD)、METU、Logos in the Wild等,但这些数据集大都数据规模较小(不到一百万),且标注上相对简陋,有的甚至只标注了品牌。而国家商标局的数据库里,每个商标都会经过非常详细的分类和标注,这也是商标数据库价格高昂的原因。所以其实也可以发现,如此标注完善且数量庞大的数据应用,使用深度学习技术进行落地应用简直是再合适不过。
目前世界范围内比较通行和公认的商标分类方式叫做维也纳分类(Vienna Classification),是一个叫做World Intellectual Property Oraganization(WIPO)的组织提出来的,在业内我们一般也会把维也纳分类的标签称为维也纳编码,或图形要素编码。
简单来说,维也纳编码是一个三级的树状分类结构,越深层的分类粒度越细,描述了一个商标具有的图形特征、语义概念、颜色、形状等,在此我给出一部分维也纳分类第一级和第二级的内容便于大家理解:


除了维也纳编码以外,也有人提出了不同的商标分类方法,比如Wheeler和Chaves。
Wheeler提出将商标分为三类:
Wordmarks (独立的首字母缩写,公司名称或产品名称)
emblems (公司名称与图片元素密不可分的商标)
only symbols (又分为字形、图形、抽象符号)
但这种分类方式边界不够明确,大量的商标无法被分入单独的一类中,之后Chaves有提出了一种替代方案:
logotypes (与Wordmarks相同,但包含三个子类:纯logotype,带背景的logotype,带装饰的logotype)
logo-symbol (与emblems相同)
logotypes with symbols (logotype与符号的组合)
only sumbols
本文对维也纳分类方式进行了进一步的总结和归纳,分为四类:
Figurative (形象相关)
Colors (颜色相关)
Shapes (形状相关)
Text (文字相关)
接下来我详细介绍一下:
Figurative
包含维也纳第1到第25类的内容,用于描述商标的形象或语义特征,由于维也纳分类第三级过于细致,且很多类下商标数量过少不利于模型分类,因此只使用第一级和第二级分类标签。
Colors
维也纳分类第29类是用于描述颜色的,但其中的一些标签不适用于多标签分类(如29.01.12代表存在两种颜色占主导),因此本文对该类进行了清洗,最终保留13个标签:

Shapes
维也纳分类第26类用于描述形状(如三角形、四边形等),第三级标签同样过于细致且存在歧义,因此只使用第二级分类标签,并把26.07和26.13合并到26.5(其他多边形)中。
Text
维也纳分类第27类定义了文字,但不适用于多标签分类,因此本文将27类只用作该商标是否包含文字的标注。
文中还总结和对比了集中分类方式的异同:

除此以外,本文还使用了尼斯分类,尼斯分类在业内一般称为商品服务大类,其实跟商标的内容并没有太大关联,而且很多大公司通常会把自己的商标在所有大类同时注册,以避免被别人滥用,所以在我看来这个信息的使用并不是特别合理。
2. 方法
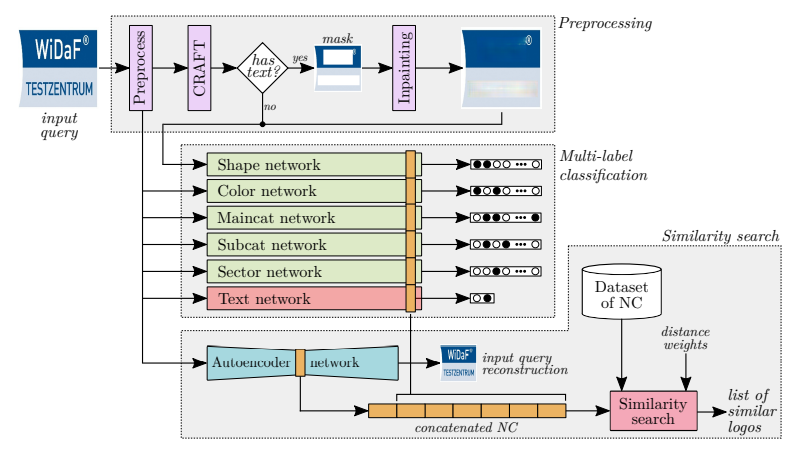
通过图片可以看到,本文的检索系统用到了7个模型,分别是形状、颜色、主类、子类、业务领域、文字、重建特征,其中前6个模型是多标签分类模型,最后的重建特征模型是训练一个自编码器网络,利用encoder-decoder结构来学习通用图形特征。还可以注意到的是,形状模型的输入是消除了文字内容的商标,以此提取的特征是消除了文字影响的。
最后7个模型提取的特征合并成一条特征向量存入数据库中进行最近邻匹配和召回,再利用本文提出的一种加权距离计算公式来进行排序。
2.1 数据预处理
数据预处理阶段第一步是对图片进行裁剪和缩放,让商标占据整个画面,避免商标位置差异对特征提取的影响,第二步使用CRAFT文本检测器来检测文字,然后通过一个消除网络来将文字从商标中消去:

2.2 多标签分类
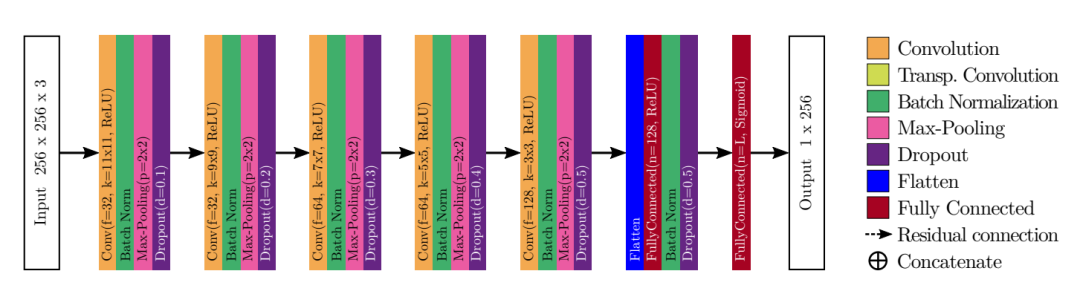
本文使用的多标签分类模型如图所示,可以看到其实是非常简单的,也许是出于推理耗时的考虑没有使用特别复杂的网络。如果让我来设计应该会使用RepVGG(强化推理速度)或基于Transformer的网络(强化特征质量)。
2.3 相似性检索
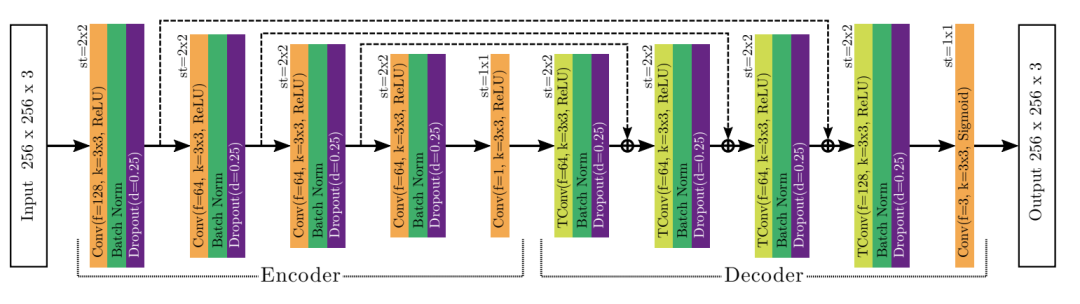
重建特征网络是一个自编码器结构,也是常见的Hourglass网络的形态。
最终的特征向量由7个网络特征合并得到,前6个网络特征维度为128,第7个网络维度为256,对这个特征向量进行了L2归一化处理,提升了检索性能。
相似性比较的方式本文使用了KNN和LabelPowerset两种,但是说实话对大规模数据检索,LabelPowerset不太实用,现在大家都是用的基于近似最近邻的向量检索方案。
相似度计算部分,本文提出了一个用户可以自定义权重的加权方案:
c是不同子特征上的权重,可以看出,计算相似度时,是把每个子特征单独拿出来加权比较计算的。
3. 实现细节
3.1 数据
尽管商标数据的标注信息很丰富,但其中还是存在很多的问题。
最明显的是标注不完备:在标注时,标注员往往只会对最显眼、具有代表性的部分进行标注,具有很强的主观性。举个例子,下面这个商标只会标注红色,而黑色、蓝色不会被标注出来:

标注不完备的问题同样出现在文字标注上,在本文使用的欧盟商标数据中,只有大约30%的数据包含文字存在性标注,根据作者的观察,这类大都是文字作为整个商标的主体,而剩下的海量的商标中都包含有文字,但没有被标注出来。因此,本文使用CRAFT文字检测器对数据进行了一次机器标注。
所有数据在使用时都被缩放为256*256。
3.2 评测指标
本文采用了两种评测指标:
Label Ranking Average Precision(LRAP):
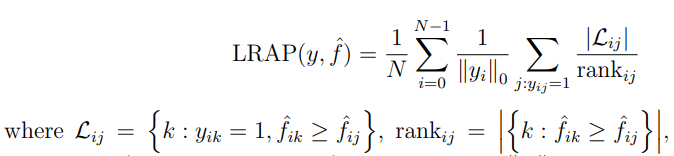
Label Ranking Loss(LRL):
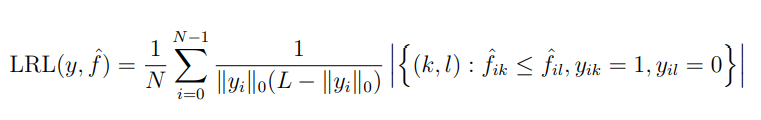
4. 实验结果
4.1 多标签分类
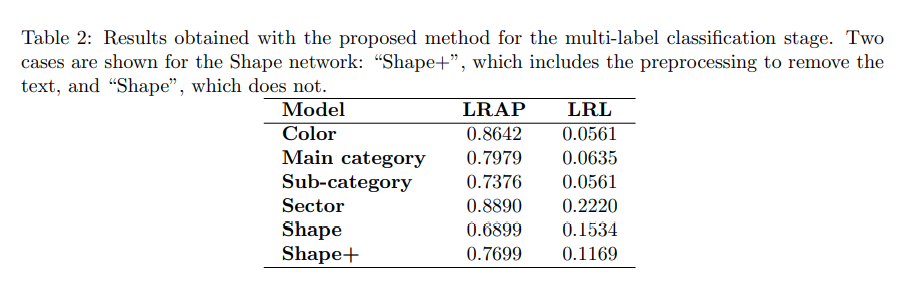
从结果来看,文字消除对于多标签分类正确率的提升还是很明显的,LRAP指标从0.6899提升到了0.7699
4.2 相似性检索

由于检索质量的评估带有很强的主观性,因此这种基于标签召回率和排序的指标我觉得只能作为参考,而且数据规模也限制了相似性匹配的手段选择。
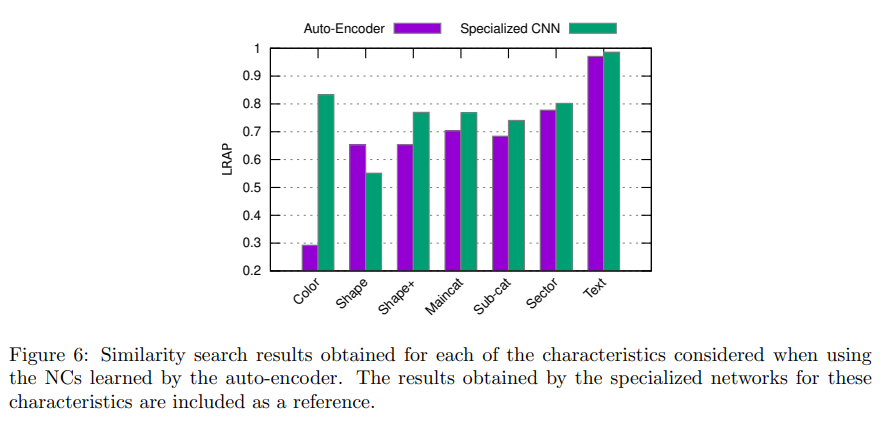
本文对比了自编码器网络特征和特定的自网络特征的检索质量,通过结果可以看出,自编码器网络的特征更专注于形状,而对颜色信息不敏感,几乎在所有的任务上都比不过该任务下的专属网络,但好处是一个网络特征能在几乎所有任务上都取得一个还不错的表现(除了颜色),因此,这可以作为用户没有特殊要求,或对检索速度有较高要求时的特征使用。
4.3 结果展示

从不同子网络召回的结果可以发现,他们基本能完成各自预设的目标,只是从我个人的角度来看,文字网络由于关注的只是“商标中是否包含文字”,所以召回的结果其实在文字内容上是没有相关性的,因此实际产生的价值或许是非常有限的。
基于业务领域的网络特征召回同样存在这个问题,我有提到,商标注册的商品服务大类,跟商标内容实际上是没有相关性的,很多公司都倾向于在尽量多的类别中注册自己的商标,以避免自己的商标被别人注册和滥用。从召回的角度来讲,“我找到你,是因为你跟我在同一个商品大类”,这个逻辑或许是成立的,但是对于检索结果质量的提升我感觉或许比较有限。
而自编码器网络更适用于一些精准匹配,能很好地找到一些高度近似的商标,但后面的结果质量其实是相对较差的。
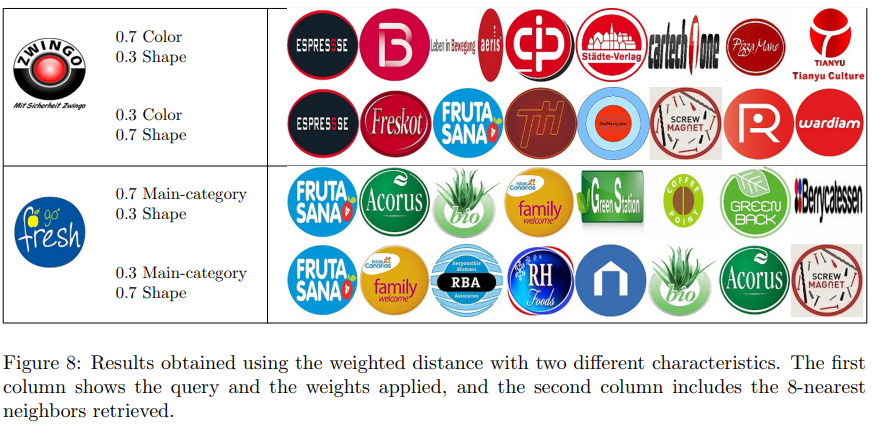
通过调整不同子网络的权重,可以调整排序结果,从实验结果来看是可行的,但要达到理想的效果,我想应该是需要花费很长的实际来测试探索一个最佳的权重比例的。在实际做产品设计时,把权重分配完全交给用户来使用也是不现实的,大部分用户只希望点一下搜索就得到自己想要的结果,需要自己做的调整越少越好。
本文可以提供给我们的一个参考是,30%的颜色权重搭配70%的形状权重,能取得一个在测试数据集上最优的结果。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~