网内计算:可编程数据平面和技术特定应用综述
摘要——与云计算相比,边缘计算提供了更靠近终端设备的处理,降低了用户体验的延迟。最新的In-Network Computing范例采用可编程网络元素在数据达到边缘或云服务器之前计算,促进了常见的基于边缘/云服务器的计算,提出了更靠近终端设备的线速处理能力。本文讨论了In-Network Computing的用例、使能技术和协议。根据我们的研究,考虑到可编程数据平面作为一种使能技术,潜在的In-Network Computing应用包括In-Network分析、In-Network缓存、In-Network安全和In-Network协调。此外,在云计算、边缘计算、5G/6G和NFV的范围内,还有针对特定技术的In-Network Computing应用。在本次调查中,我们在所提出的分类框架下审查了现有技术水平。此外,我们还提供了一组提出的标准,从方法学、主要结果以及应用特定标准等方面对方法进行比较。最后,我们讨论了所学到的经验,并强调了一些潜在的研究方向。
关键词——In-Network Computing、可编程数据平面、软件定义网络、云计算、边缘计算、6G和网络功能虚拟化。
I. 介绍
多年来,计算历史经历了从传统并行计算、网格计算到云计算的不同范例的演进。云计算[1]提供了包括基础设施即服务(IaaS)、平台即服务(PaaS)和软件即服务(SaaS)在内的各种服务模型,带来了可扩展性、按需资源 provisioning、按量计费的价格模型以及方便的应用和服务 provisioning 等优势和功能。
IaaS(Infrastructure as a Service,基础架构即服务)是基础层。在这一层,通过虚拟化、动态化将IT基础资源(计算、网络、存储)聚合形成资源池。资源池即计算能力的集合,终端用户(企业)可以通过网络获得自己需要的计算资源,运行自己的业务系统。这种方式使用户不必自己建设这些基础设施,而是通过付费即可使用这些资源。
在IaaS层之上的是PaaS(Platform as a Service,平台即服务)层。这一层除了提供基础计算能力,还具备了业务的开发运行环境,提供包括应用代码、SDK、操作系统以及API在内的IT组件,供个人开发者和企业将相应功能模块嵌入软件或硬件,以提高开发效率。对于企业或终端用户而言,这一层的服务可以为业务创新提供快速、低成本的环境。
最上层是SaaS(Software as a Service,软件即服务)。实际上,SaaS在云计算概念出现之前就已经存在,并随着云计算技术的发展得到了更好的发展。SaaS的软件是“拿来即用”的,不需要用户安装,软件升级与维护也无须终端用户参与。同时,它还是按需使用的软件,与传统软件购买后就无法退货相较具有无可比拟的优势。
5G及其后续时代引入了各种新应用,如移动视频会议、车联网、电子医疗保健、在线游戏和虚拟现实。通过将工业界和学术界的不同研究倡议融合在一起,这些新应用需要在1∼100 Gbps的规模和0.1∼1毫秒的往返延迟的低延迟方面提供高数据速率[2],[3]。云计算无法满足这些不断增长的需求,因为存在一些问题。主要问题在于云资源与终端设备之间的距离很远,并且连接是通过互联网建立的,这会导致延迟方面的问题。此外,云服务器的处理能力处于一个无法满足新兴需求的范围内。例如,Amazon EC2云服务中最新一代通用计算实例的处理能力在5∼50 Gbps的范围内[4]。然而,这种处理能力无法有效地响应大量应用程序和物联网模式,这些应用程序需要高数据速率(例如,高质量360度视频的多个Gbps)来竞争处理资源利用率。
边缘计算的思想[5],包括云端、移动边缘计算和雾计算等各种概念,被引入以解决与云相关的问题。边缘计算提供靠近网络边缘和终端设备的资源。虽然延迟将得到改善,处理能力也将得到增强,但从长远来看,它不可能持续支持不断增长的流量爆炸。此外,延迟仍远远达不到超低延迟应用程序所需的要求,例如往返延迟要求在0.1毫秒以内的应用程序。
最近提出的分布式云计算的概念通过利用智能邻近设备的计算和存储容量进行计算或缓存卸载,改善了云端、移动边缘计算和雾计算范式的延迟 [6],[7]。然而,计算和功耗限制问题、邻近设备的移动性以及更重要的是将计算卸载到邻近设备的安全方面是重大挑战。具有高处理能力的更安全、节能和稳定的计算基础设施可以显著改善计算,并被视为现有计算范式的补充。在这个方向上,基于可编程数据平面技术(SDN的进化概念)的网络计算范式可以在网络边缘提供高处理能力的、节能的网络元素。
数据平面:解决数据该怎么转发,某个数据这个口进来那个口出去,本地的,路由器的功能,决定从路由器输入端口到达的分组如何转发到输出端口。
其转发分组除了传统的基于目标地址和转发表,提出了一种新的基于SDN的方法:基于多个字段+流表。
控制平面:解决数据该怎么走,网络范围内的逻辑,决定数据报如何在路由器之间路由,决定数据报从源到目标主机之间的端到端路径。
其控制方法除了传统的被在路由器中实现,提出了一种新的基于SDN的方法:在远程的服务器中实现,实现了下文提到的转发设备和控制平面分离。
为了简化流量工程和网络管理,并允许更方便地开发新的协议和应用程序,引入了软件定义网络(SDN)[8]的概念,其中转发设备与控制平面分离。根据SDN的概念,网络智能和路由策略通过基于软件的逻辑集中控制器应用。因此,构成数据平面的网络元素是简单的数据包转发设备,可以通过开放接口(例如OpenFlow [9])进行编程。SDN成为了可编程数据平面(PDP)[10],[11]的一种推动者。PDP的基本特征是能够通过一些高级语言对数据包进行编程处理。因此,与传统固定功能绑定在交换芯片内不同,PDP为网络运营商提供了控制数据包处理任务的灵活性,从而加快了新数据平面功能的采用和便于原型开发。此外,实现新的数据平面功能,无需重新设计交换机的ASIC,节约了大量的资本支出。
SDN字面意思是软件定义网络,其试图摆脱硬件对网络架构的限制,这样便可以像升级、安装软件一样对网络进行修改,便于更多的APP(应用程序)能够快速部署到网络上。
像交换机和路由器这样的网络元素提供了终端设备和边缘基础设施之间的连接,以及边缘和云基础设施之间的连接。利用可编程网络元素,不仅是为了连接,而且是为了计算,是计算范式的一种新趋势,即称为网内计算[12],[13]。现在,可编程交换机可以在线速处理(例如,Intel可编程交换机的处理能力为12.8 Tb/s [14])时每秒处理数十亿个数据包,并支持亚微秒级的数据包处理延迟[15]。利用网内计算,数据包可以在路径上并在到达边缘/云服务器之前以线速处理。事实上,与常见的边缘和云计算范式使用的边缘或云服务器相比,网内计算范式可以在更接近终端设备的位置提供更快的处理设施。本文对网络内计算进行了全面的调查。本文的贡献如下:
- 对网络内计算主题进行的第一次调查。
- 讨论支持网络内计算的技术和协议,以及硬件方面的讨论。
- 基于网络内计算在各种应用和专业主题中的应用情况提出了一种新的研究分类方法。所提出的分类方法还包括最新技术,例如5G/6G、边缘计算和网络功能虚拟化(NFV)的应用。
- 对相关研究进行批判性评估,并提出了评估和比较研究的新方法、性能和应用相关的标准。
- 从方法、实现和性能增益等方面对相关研究进行了审查和比较,即延迟/吞吐量改善、带宽节省和功耗降低。
- 提供了对网络内计算这个新兴话题的经验教训和研究方向。
在接下来的章节中,我们首先给出网络内计算的定义。然后,我们讨论现有的相关调查和教程。接下来,将给出文献分类和调查组织。在调查的其余部分中,我们将使用INC作为网络内计算的缩写。
A. 网内计算的定义
在本节中,我们首先简要介绍涉及网络内计算概念的网络元素,然后我们提供文献中网络内计算的定义,最后,我们将介绍一些用于指定网络内计算的特性,并给出网络内计算提供的计算能力的示意图。网络内计算范式提倡利用网络元素(即可编程交换机、FPGA和智能网卡)进行编程计算的想法。可编程交换机具有被编程以解析和操作到达的数据包字段的能力。FPGA是具有编程逻辑块的半导体元件,可用于对数据包进行有针对性的处理。类似地,智能网卡提供了专用硬件加速功能的实现以及定制数据包处理的功能。第II-A节详细介绍了这些网络元素的体系结构和功能。
对于网络内计算,目前没有标准的定义。ACMSIGARCH在[16]中提供了以下定义:网内计算指的是在网络元素内执行程序,这些程序通常在终端主机上运行。它侧重于在网络中进行计算,使用已经存在于网络中并已经用于转发流量的设备。Sapio等人[12]提供了一种基于将计算卸载到网络元素的定义:网内计算是将一组计算操作从终端主机卸载到交换机和智能网卡等网络元素中。Ports和Nelson [13]将网络内计算定义为:在可编程网络硬件上以线速运行的应用程序特定功能,提供比传统服务器实现更高的吞吐量和更低的延迟。
根据定义和我们调查的研究,可以为网络内计算定义一些特征:
- 它侧重于在网络元素中执行的计算。这个计算可以是程序、进程、操作、网络功能等;
- 涉及的网络元素(例如交换机和路由器、FPGA和智能网卡)可以被编程来执行预期的计算;
- 除了计算之外,网络元素还执行路由和转发数据包的默认过程;
- 在不使用网络的情况下,计算应该由通用处理器在应用主机或任何其他终端主机(例如服务器、控制器)中完成。
根据我们调查的研究,我们提出图1以说明网络内计算提供的计算能力的原理图。网络内计算结构由蓝色云中的网络元素组成,这些网络元素可以位于终端设备和边缘计算提供的服务器之间(例如MEC服务器、雾节点、云端设备),也可以位于终端设备和云数据中心之间(甚至可以位于边缘服务器和云服务器之间)。绿色路径说明了一条端到端的通信路径,可以在离云端服务器之前的某个点(例如点2)截断,通过在网络元素上的中间节点应用网络内计算,这些节点可以是可编程交换机、FPGA或嵌入主机中的智能网卡加速器。类似地,沿着红色路径的流量可能会在边缘服务器之前的网络元素上进行处理(例如点1),并将结果从比较接近边缘服务器的位置返回到终端设备。
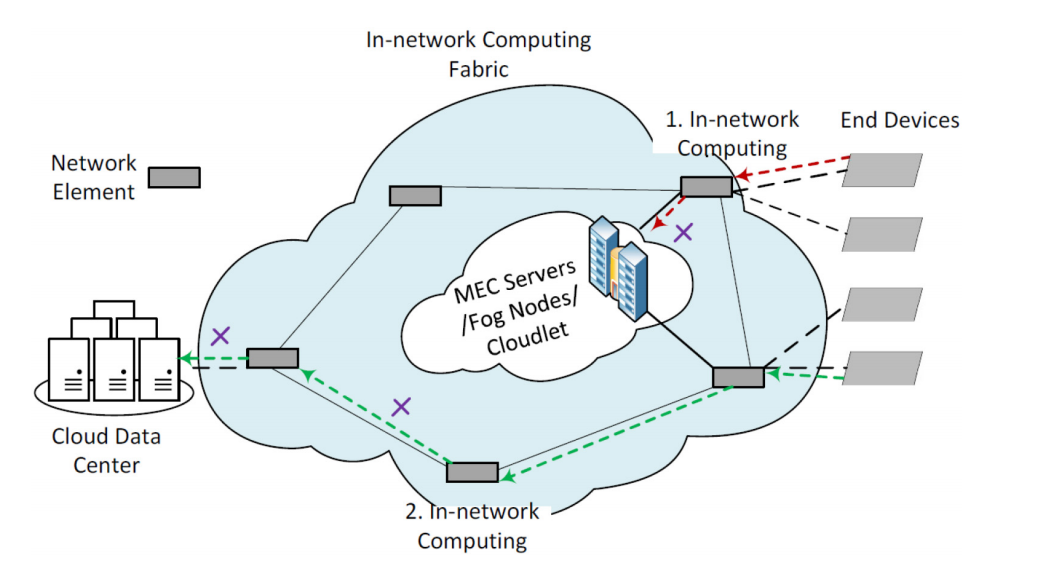
图1. 网络内计算结构的原理图。蓝色云中的网络元素形成网络内计算结构。红色和绿色路径分别说明了与边缘和云的通信。如十字标记所示,这些路径可以在中间网络元素中应用网络内计算,在边缘/云服务器之前的点1和点2处截断。
B. 现有相关调查和教程
在本节中,我们将讨论现有的相关调查和教程,并讨论我们的调查与它们进行比较的贡献。
1. 可编程数据平面的调查
该类别的调查聚焦于可编程数据平面,但缺乏对网络内计算的视角。与这些调查相比,我们的调查与现有研究有四个明显的区别:首先,我们在网络内计算范围内提出了一种基于应用和专题的新分类方法;其次,我们对网络内计算论文进行了全面而批判性的评论,包括最近技术(如5G/6G、边缘计算、NFV)范围内的应用;第三,我们介绍了支持网络内计算的技术、协议和硬件方面的内容;第四,我们从我们提出的方法论/性能/应用相关标准的角度对我们调查的研究进行评估和广泛比较,这在文献中尚未见到。在我们讨论可编程数据平面的调查/教程时,我们还将强调其他区别。
Stubbe [17]提供了关于P4编译器和解释器的简短调查。Bifulco和Rétvári [10]提供了关于可编程网络元素设计和实现中的抽象、架构和问题的调查。Han等人[11]概述了现有的PDP虚拟化方案,并讨论了它们的利弊。Kaljic等人[18]对软件定义网络中的数据平面可编程性和灵活性进行了调查。数据平面架构通过数据平面灵活性和可编程性进行评估。根据评估ForCES和OpenFlow数据平面架构的限制,给出了一些解决数据平面灵活性和可编程性问题的方法。然而,[10]、[11]、[17]、[18]中的文章缺乏对可编程数据平面上现有应用、相关挑战和潜在研究方向的评估。
[19]、[20]中的文章侧重于有状态数据平面。Zhang等人[19]概述了有状态数据平面的基本组件和现有的有状态平台(例如OpenState、OPP、FAST等)。该文章回顾了一些基于有状态数据平面的应用,如负载均衡、防火墙、SYN洪水检测、大流量检测等。Dargahi等人[20]对有状态SDN数据平面研究进行了概述,并关注数据平面可编程性的安全方面。作者们确定了一些攻击场景,并突出了交换机中有状态处理的一些漏洞。然而,该调查未讨论除安全性之外的现有应用、相关挑战和潜在研究方向。
Da Costa Cordeiro等人[21]描述了支持数据平面可编程性的重要编程语言。作者们考虑了数据平面可编程性文献的两个类别:1)可编程安全性和可靠性管理,包括针对策略建模和分析、策略验证、入侵检测和预防的研究;2)增强的会计和性能管理,包括网络监测、流量工程和负载均衡的研究。该调查只讨论了有限数量的论文。
Kfoury等人[22]提供了从传统网络到可编程网络的演进概述,描述了可编程交换机和P4的作用,并回顾了使用P4开发的应用,例如网络遥测、物联网、网络性能和网络与P4测试。虽然这篇文章比该领域中的其他教程/调查提供了更多细节,但我们的调查与该研究仍然存在一些主要差异。我们的调查提出了一种不同的分类法,根据网络内计算的应用和涉及的专题进行分类。此外,[22]没有对大量的网络内计算论文进行审查,例如最新技术领域的论文,如5G/6G、NFV和边缘计算(请参阅我们的调查第七部分,了解我们涵盖的广泛论文范围),以及其他范围的论文,如[23]、[24]、[25]、[26]、[27]、[28]、[29]等。此外,我们从新方法/性能/应用相关标准的角度评估和比较了这些研究,而这些标准在[22]中没有考虑。最后,[22]中的研究方向主要集中在数据平面解决方案上,以克服可编程交换机的约束,例如交换机资源、算术计算和编程。相反,我们提供了各种应用的研究方向,这些方向为各个应用领域的研究空白和相关研究方向提供了见解。
2.关于网络内计算的教程
据我们所知,目前还没有关于网络内计算的调查,而我们的研究提供了首次的调查。有三篇简短的教程,即[13]、[30]、[31],列举了一些网络内计算范围内的论文,但没有解释每篇论文的操作和主要思想,也没有给出任何研究的分类、技术细节、比较、经验教训或具体的研究方向。我们的调查可以很容易地与这些教程区分开来,因为现有的教程只有几页的篇幅。以下是对这些教程的更多详细信息。
Ports和Nelson[13]在网络内计算方面提供了一个简短的教程。它介绍了可编程网络元素,并讨论了网络内计算的有效使用。然后,它对有限数量的网络内计算应用进行分类,并建议采用适当的网络元素来实现它们。Benson[30]简要概述了网络内计算的管理挑战,并解释了现有管理技术的局限性。它只列举了一些网络内计算应用,没有进行任何评论。Kannan和Chan[31]从软件定义网络之前的努力开始,对可编程网络的演进进行了简要介绍,包括最近的可编程数据平面。他们讨论了数据平面可编程性的优势。作者将数据平面应用分为两类,即网络监测和网络内计算。该教程仅列出了属于上述类别的一些论文,并未对它们进行任何评论。而且,在网络内计算的类别中,所列出的论文没有任何结构。读者可以很容易地推断出,上述任何教程都没有对文献中的网络内计算论文进行评论或分类,也没有对网络内计算的支持技术和协议进行讨论。这篇综合调查旨在填补这个空白。
C. 文献分类和调查组织
本文提供了对现有论文的调查,这些论文是在同行评审的场合下介绍的,并涵盖了算法、协议和架构等领域的内容。本文采用一组明确的标准对这些文献进行了综述。在本节中,首先讨论了文献分类,然后介绍了调查的组织方式。
1. 文献分类
我们已经确定了共计106篇论文将在本调查中进行审查。我们收集了符合以下任一标准的论文:(i)标题中明确使用了“in-network computing”这一术语,(ii)明确使用了在第I-A节中定义的“in-network computing”作为论文的动机。图2展示了调查的分类法。由于在网络内计算的范围内的论文已经为各种应用提供了网络内解决方案,所以在分类法的第一层级上,我们根据文献中找到的应用将论文进行了分类,即(i)网络内分析,(ii)网络内缓存,(iii)网络内安全,(iv)网络内协调和(v)技术特定应用。然后,在每个分类中,我们根据与该分类的上下文中涉及到的特定主题对论文进行了分类。
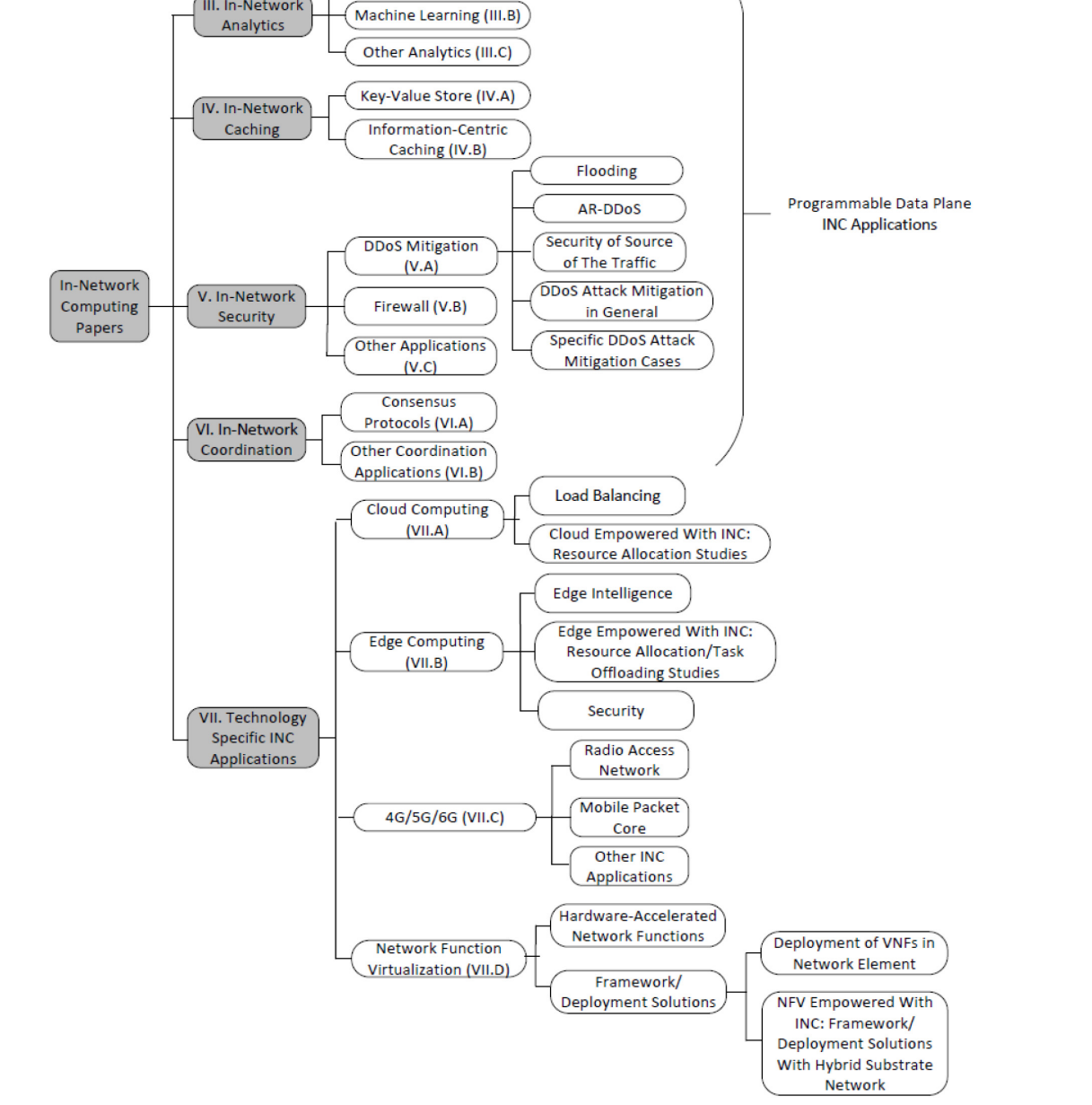
图2. 在网络计算范围内调查研究的分类方案。方框内的数字表示各个部分和子部分。
这种分类的动机在于清晰地定义了网络内计算的参与情况。实际上,通过观察图2中的每个叶节点,读者可以识别特定应用中涉及到的专门主题的层次结构,以及其中涉及到的网络内计算。这里我们提供三个例子:首先,考虑图2中的Flooding,可以清楚地看到网络内计算已经参与其中,以提供防范洪水攻击的解决方案,这属于DDoS攻击缓解的范畴,通常用于安全应用。其次,考虑Edge Intelligence,可以明确网络内计算已经参与其中,以提供边缘智能,这属于边缘计算的范畴,通常用于技术特定的应用。第三,考虑到Cloud Empowered With INC: Resource Allocation Studies,可以清楚地看到网络内计算已经参与了在资源分配时增强云计算的过程,这属于云计算的范畴,通常用于技术特定的应用。类似地,对于图2中的每个叶节点,通过从叶子到根的路径追踪,可以找到网络内计算在专门主题和应用中的参与情况。现在,我们对每个分类的结构提供更多细节,并对每个分类中论文划分的语义/原因给出一些补充说明。请注意,由于网络内计算主题处于初级阶段,我们可以根据每个分类中找到的论文数量来扩展每个分类中的专门主题。
第一类别,即基于分析类型的网络内分析,被结构化为三个子类别:(i) 数据聚合,(ii) 机器学习,和 (iii) 其他分析方法。
在第二类别中,即网络内缓存,我们发现论文提供了基于键值存储的缓存方法。此外,信息中心缓存的主题也与网络内缓存相关。因此,我们确定了两个子类别:(i) 键值存储,和 (ii) 信息中心缓存。
在第三类别中,即网络内安全,大部分论文利用网络内计算来减轻分布式拒绝服务(DDoS)攻击。还有一些研究提供防火墙解决方案。还有一些论文提供各种安全应用程序。因此,网络内安全被分为三个子类别:(i) DDoS攻击减轻方法,(ii) 防火墙方法,和 (iii) 其他安全应用程序。在DDoS攻击减轻方面,根据攻击类型,我们识别出五个子类别,即:(i) 针对洪泛攻击的减轻方法,(ii) 针对AR-DDoS攻击的减轻方法,(iii) 考虑流量来源安全性的方法,(iv) 总体上考虑DDoS攻击减轻的方法,以及 (v) 特定DDoS攻击减轻案例。
第四类别,即网络内协调,包括两个子类别:(i) 共识协议,和 (ii) 其他协调应用程序。
在第五类别中,即特定技术的网络内计算应用程序,基于技术,我们确定了四个子类别:(i) 云计算,(ii) 边缘计算,(iii) 4G/5G/6G,和 (iv) 网络功能虚拟化。
在云计算领域,我们确定了两个子类别:(i) 提供数据中心负载均衡的论文,和 (ii) 在具备网络内计算能力的云计算中提供资源分配解决方案的论文。
在边缘计算领域,我们确定了三个子类别:(i) 提供边缘智能解决方案的论文,(ii) 在具备网络内计算能力的边缘计算中提供资源分配解决方案的论文,以及 (iii) 提供边缘计算安全解决方案的论文。
在移动通信领域,无线与核心的划分是移动通信文献中众所周知的划分方式。我们认为将网络内计算引入到无线接入和核心功能中是合适的。因此,4G/5G/6G类别包括三个子类别:(i) 无线接入网络解决方案,(ii) 移动数据核心解决方案,和 (iii) 其他应用程序。
在NFV范围内,论文提供了NFV的框架或部署解决方案。此外,硬件加速网络功能是NFV范围内的一个主题,与网络内计算相关。因此,我们确定了两个类别:(i) 硬件加速网络功能,和 (ii) 框架/部署解决方案,该类别又分为两个子类别:(i) 关注在网络元素中部署虚拟网络功能(VNFs)的论文,和 (ii) 在具备网络内计算能力的NFV环境中提供混合底层网络的部署解决方案的论文。
NFV(Network Function Virtualization)是一种网络技术,它旨在通过将网络功能软件化和虚拟化,把网络功能从专用硬件设备中解耦出来,从而提高网络的灵活性和可扩展性。简单来说,NFV技术就是将传统的网络设备(如路由器、防火墙、负载均衡器等)中的功能软件化,以便能够在通用硬件上运行。这样做可以提高网络的灵活性和可编程性,降低网络设备的成本,并且更容易进行网络功能的更新和维护。
2. 调查组织
第二节讨论了网络内计算的支持技术和协议。然后,我们提出了两个应用案例(即网络内分析和网络内缓存),以说明网络内计算的概念,并介绍了网络内计算的优势。最后,我们提出了用于对文献中的网络内计算论文进行分类、评估和比较的标准。在第三节中,我们概述了网络内分析的研究,包括数据聚合方法、机器学习方法和其他网络内分析方法。在第四节中,我们将介绍网络内缓存方法的概述,包括键值存储应用和信息中心缓存。在第五节中,我们回顾了网络内安全范围内的研究,包括DDoS攻击减轻方法、防火墙方法和其他安全应用程序。第六节回顾了网络内协调方法,包括共识协议和其他协调应用程序。第七节中,我们回顾了特定技术应用,包括云计算、边缘计算、4G/5G/6G和网络功能虚拟化。图2展示了第三节到第七节调查的组织结构。此外,在每个部分的结尾,我们提供了该部分的摘要、比较和经验教训。在第八节中,我们讨论了一些潜在的研究方向。最后,在第九节中,论文进行了总结。
II. 技术、协议、说明性用例和标准
在本节中,我们首先解释了使网络内计算成为可能的技术和消息转发协议。然后,我们提供了两个应用案例来说明网络内计算的概念,并强调了一些网络内计算的优势。最后,我们解释了我们在调查中分析和比较研究的标准。
A. 支持技术
1. 软件定义网络
软件定义网络(Software Defined Networking,SDN)是一种网络范式,旨在促进远程网络管理以及部署新的路由策略、协议和应用程序。根据SDN的概念,数据平面中的转发硬件与控制决策解耦。图3a和图3b展示了SDN的概念与传统网络中设备中的嵌入式控制进行对比。网络运营和路由策略的智能逻辑上通过在控制平面中开发的基于软件的解决方案进行集中管理,而网络元素则成为简单的数据转发设备,形成数据平面,可以通过开放接口(如OpenFlow [9]、ForCES [32]等)进行编程。
OpenFlow是一种网络协议,用于实现SDN(软件定义网络)中的控制平面和数据平面的分离。OpenFlow协议定义了一组消息格式和处理规则,用于在控制器和数据平面之间进行通信和交换信息。具体来说,OpenFlow协议允许控制器与网络设备(如交换机、路由器)进行通信,以控制网络设备的转发行为。控制器可以通过下发流表项来控制网络设备的数据转发,流表项定义了数据包如何匹配和转发的规则。与传统网络不同,OpenFlow协议使得网络管理员可以通过控制器对网络进行全局管理和控制,从而提高网络的灵活性和可编程性。OpenFlow已经成为SDN领域最常用的网络协议之一,并被广泛应用于数据中心、企业网络和运营商网络等领域。
简单来说,SDN就是使硬件只负责转发,而逻辑控制(如何转发)交由中央控制安排
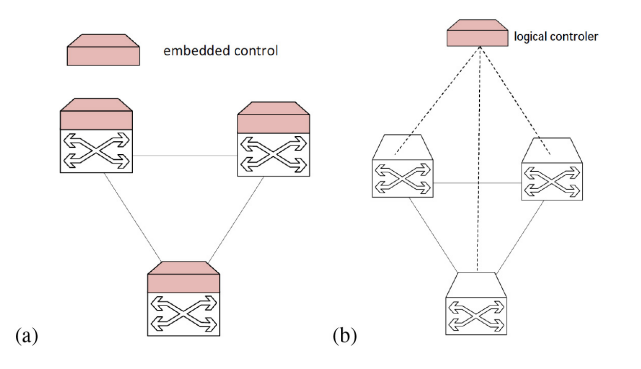
图3。(a)传统网络,(b)软件定义的网络。
OpenFlow [9]是最流行的SDN协议。在该协议中,转发设备,即OpenFlow交换机,包含多个流表和一个通过OpenFlow协议与控制器进行通信的抽象层。每个流表包含多个流条目,用于定义数据包处理和转发策略。通常,流条目包括:a) 匹配字段/规则,包含数据包头部、入口端口和元数据中的信息,用于匹配传入的数据包;b) 计数器,用于收集流的统计信息(例如,到达的数据包数量、流持续时间);c) 一组操作,用于在匹配发生时对数据包进行操作。当数据包到达OpenFlow交换机时,会对数据包头部字段与匹配字段进行匹配。如果匹配成功,相关的操作集将被应用。控制器通过OpenFlow协议与交换机通信,可以向交换机的流表中添加、更新或删除流条目。在控制方面,网络控制器的可扩展性和性能、SDN控制器与交换机之间的响应式或主动式通信,以及南向和北向通信的实现(与转发元素和网络服务相关)是设计SDN控制器时面临的一些挑战。ONOS、OpenDaylight、Floodlight [33]、Beacon [34]和RouteFlow [35]是一些SDN控制器实现的示例。
2.可编程数据平面
可编程数据平面技术所涉及的主要要素如下:
(i)控制平面与数据平面的分离
数据平面可编程性的主要贡献者是将控制平面与数据平面解耦的概念,通过标准API来实现两个平面之间的交互[8],[36]。事实上,数据平面可以由控制平面管理下的“dumb”的网络元素来实现。这些“dumb”的网络元素向控制平面公开了嵌入式状态信息,从而实现了网络的可编程性。
(ii)数据平面
数据平面是网络的最基本基础设施,用于处理网络元素接收或传送的数据包。数据平面采用硬件组件和特定的软件方法的组合来实现。数据平面功能可以在各种网络元素中实现,例如ASIC、FPGA、网络处理器、网络接口卡(NIC),基于数据包分类引擎。网络元素技术以不同的方式向控制平面公开数据包处理原语,并使用各种编程语言来访问数据包处理原语。在这里,我们将详细讨论参与网络内计算的网络元素的硬件和功能方面的细节。
这里的原语通常是指可编程网络设备中的底层操作和功能,如数据包的匹配、转发、修改、丢弃等操作。通过提供这些原语,网络设备可以向上层控制器提供一组抽象接口,使得控制器可以通过这些接口来控制网络设备的数据处理行为。
a.可编程交换机
SDN交换机可以分为硬件交换机和软件交换机两类。Barefoot Tofino [37]、Cavium XPliant [38]和Flexpipe [39]是硬件交换机的示例。另一方面,软件交换机在CPU上执行基于数据包分类算法的数据包处理逻辑[10]。OVS [40]、PISCES [41]、NetBricks [42]和BMv2 [43]是软件交换机的示例。可编程网络交换机的功能可以抽象为匹配-操作流水线。独立于协议的交换机架构(PISA)是一种基于匹配-操作的著名的可编程交换机架构[11]。图4a展示了PISA的示意图。
硬件交换机和软件交换机是两种不同的网络交换机实现方式,主要区别如下:
- 实现介质:硬件交换机使用专用的交换机芯片实现,软件交换机使用通用服务器或计算机与软件相结合实现。硬件交换机可以提供更高的转发性能,软件交换机的转发性能依赖于服务器配置。
- 可编程性:硬件交换机的转发逻辑通常是固化在芯片中的,难以修改。软件交换机使用软件来实现转发逻辑,更易于编程和修改。例如使用P4语言可以方便编程软件交换机。
- 成本:硬件交换机因为使用专用芯片,成本较高。软件交换机只需要通用计算平台,成本较低。
- 功能:硬件交换机提供的功能取决于芯片设计,不易扩展。软件交换机的功能可以通过软件扩展和升级实现。例如,软件交换机更易于支持新兴的SDN和网络虚拟化功能。
- 能耗:硬件交换机通常功耗较低,因为使用专用的高度优化的电路。软件交换机运行在通用计算平台上,功耗较高。
该架构由可编程的子结构组成,包括解析器、匹配-操作流水线和解析器。解析器从接收到的数据包中提取头部,并将其存储在称为Packet Header Vectors(PHVs)的中间寄存器中[44],这些PHVs被视为流水线阶段的输入。在流水线的每个阶段,使用匹配-操作表对提取的头部进行处理。在硬件交换机中,匹配-操作表是在三态内容寻址存储器芯片(TCAM)中实现的,而在软件交换机中,它们是在SDRAM中实现的。还有一种混合情况,即匹配-操作表可以同时位于TCAM和SDRAM中。当匹配不发生时,数据包将被发送回设备/SDN控制器,并相应地对表条目进行所需的更新。当发生匹配时,将执行操作,并将数据包发送到下一个匹配-操作表以进一步进行所需的处理。在每个匹配-操作表中,通过算术逻辑单元(ALUs)应用操作逻辑。通过一个操作,将对数据包字段执行操作,并将结果存储在PHVs中。存储在SRAM中的其他对象,如计数器或寄存器,可以用于执行对先前操作的输出进行状态操作。在流水线阶段的处理完成后,处理过的头部被发送到解析器,解析器将组合这些头部以重构数据包。控制平面可以通过向匹配-操作表中写入条目来管理数据包处理。
PISA提供了一个抽象模型,可以通过各种方式进行增强,以创建具体的架构。例如,一个典型的交换机可以在入口和出口之间拥有单独的流水线,并且在入口和出口流水线之间可以有一个队列管理模块,即调度器(图4b)。此外,具体的架构中还可以包括用于高级处理的专用组件,例如哈希/校验和计算。目前最先进的可编程交换机可以以线速处理的速度处理十亿个数据包 [15]。例如,英特尔第二代P4可编程以太网交换芯片可以提供高达12.8 Tb/s的吞吐量 [14]。
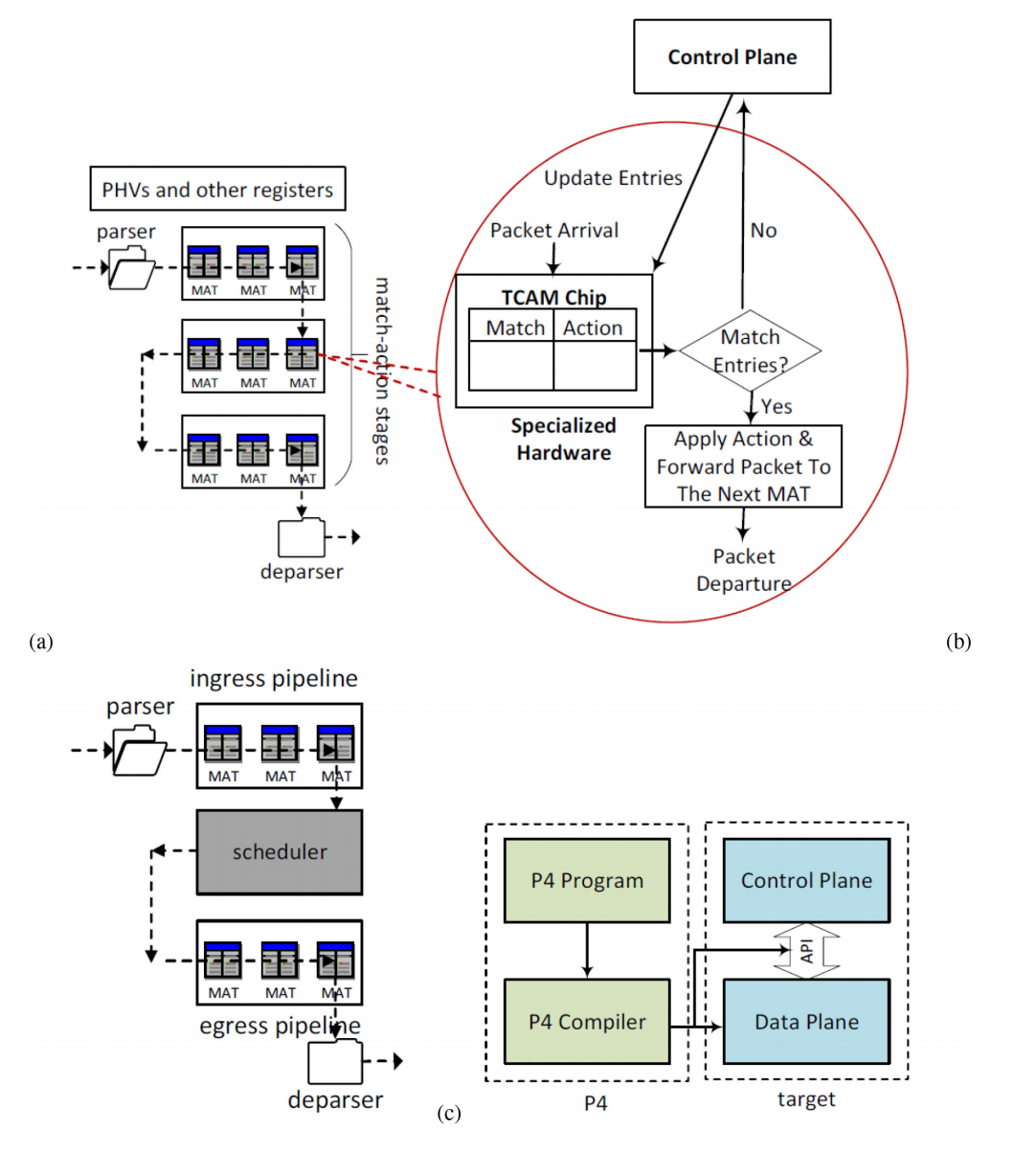
图4。(a)PISA交换机架构,(b)是一个典型的交换机架构,©P4程序与目标的关系。
b.FPGA
FPGAs(可编程门阵列)是一种半导体元件,具有在制造后进行编程和配置以实现所需数据包处理的能力。如图5所示,FPGA的硬件架构包括三个主要元素[45]:(i)计算逻辑块(CLBs),(ii)路由能力(用实线连接CLBs表示),(iii)I/O块。通过查找表和触发器,CLBs提供了一个可编程矩阵的计算单元,最终连接到I/O块。I/O块可以通过像PCIe这样的互连与CPU和系统进行通信。路由能力是通过交换盒和连接盒等互连组件实现的,它提供了连接CLBs之间的连通性,为生成复杂的计算逻辑提供了便利。与具有最高性能的专用ASIC设计相比,利用高时钟速度和存储带宽的最新FPGA已经在许多用例中缩小了性能差距,同时具有灵活性和成本效益的优势[46]。一个众所周知的最新版本是基于FPGA的SUME,它利用了一块带有四个10 Gb以太网端口的Xilinx Virtex 7 FPGA [47]。更近期的基于FPGA的原型平台是Corundum [48],具备在FPGA上提供100 Gbps网络接口的能力。
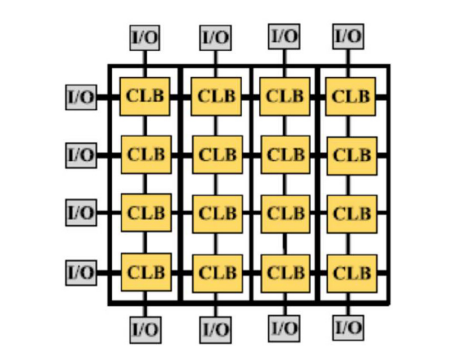
图5。FPGA架构。[45].
c.智能网卡
网卡是外部硬件组件,可以通过PCIe接口连接到计算节点。网卡实现了一些标准的物理层和MAC层功能,以及一些互联网协议层功能。实际上,网卡负责从互联网接收和发送数据包,以及在将IP数据包传递到操作系统或应用层之前对其进行初始处理。智能可编程网卡技术已经发展,可以使用通用或专用的数据平面语言(例如P4、eBPF)对网卡进行编程。网卡不仅可以实现专用的硬件加速功能,还可以像FPGA单元一样编程,执行定制化的数据包处理。与其他加速器(如FPGA)相比,在数据包到达后直接在网卡上进行处理可以避免将数据包从系统内存传输到加速器内存以进行处理所带来的延迟。然而,将网卡用于网络内计算仍然面临开发过程和性能问题的挑战[46],[49]。特别是为了解决服务器应用程序卸载中的开发抽象问题,Floem [50]提供了数据布局、缓存和并行性以及设备间程序组件之间的通信策略的编程抽象。最先进的智能网卡可实现每秒400 Gb/s的高速数据包处理[51]。
PCIe(Peripheral Component Interconnect Express)是一种计算机总线技术,用于连接计算机内部的各种硬件设备,如显卡、网卡、存储控制器等,以实现高速数据传输和通信。PCIe是PCI(Peripheral Component Interconnect)总线的升级版,采用串行通信协议,以提高数据传输速度和带宽利用率。
(iii)数据平面编程语言
文献中存在各种数据平面编程语言,例如P4 [52]、OpenState [53]、Domino [54]和NetKAT [55],其中P4是最广泛使用的编程语言。P4是一种高级编程语言,用于在可编程网络元素中处理数据包[52],[56]。虽然P4最初是为可编程硬件或软件交换机设计的,但它的范围已扩展到支持包括网卡和FPGA在内的各种其他设备。因此,在P4的规范中,通用术语"target"用于表示所有这些设备。与传统的固定功能交换机相比,其功能由各个制造商定义,P4程序可以定义交换机功能。控制平面将通过P4编译器生成的API与数据平面进行通信,以在数据平面中使用表格和其他对象时提供灵活性。
P4的设计遵循三个主要要求[56]:(i)使控制器能够重新配置交换机中的数据包解析/处理,(ii)为数据包转发的通用上下文指定数据包解析/处理,与使用的协议无关,(iii)独立于底层交换机的详细信息对交换机进行编程。P4程序包含以下主要组成部分:(i)头部,用于定义字段的顺序和结构以及字段值的约束,(ii)解析器,用于指定数据包中的头部和它们的序列,(iii)匹配-动作表,用于定义数据包处理,(iv)应用于匹配字段的动作,并具备从简单基本操作生成复杂操作的能力,(v)控制程序,确定应用于数据包的匹配-动作表的控制顺序和流程。P4编译器将程序描述映射到特定目标的硬件/软件平台上。编译过程分为两个阶段。首先,将P4控制程序转换为表依赖图结构,定义表之间的依赖关系。然后,通过特定于目标的映射,将上述图映射到交换机的特定资源上。图4c说明了P4程序与目标之间的关系。
3. 边缘计算
边缘计算(也称为云端、移动边缘计算或雾计算)在网络边缘、接近终端设备的位置提供资源,以减少延迟并实现移动数据卸载等功能[5]。在本节的其余部分,我们将对边缘计算范式进行概述。
Cloudlet:云端,由Satyanarayanan等人提出[57],是位于移动设备附近的服务器集群。移动设备可以将计算任务卸载到在云端运行的虚拟机(VM)中,以克服设备上有限的可用资源。基于虚拟机技术,云端的资源可以动态扩展和收缩,并且对于服务请求具有可扩展性。移动设备可以将它们的计算任务卸载到附近的云端,从而克服设备上资源限制的问题,并确保实时交互响应。如果移动设备附近无法访问云端,仍然可以连接到远程云端,但获取所需服务的响应时间将会降低。
多接入边缘计算(MEC):MEC是由欧洲电信标准协会(ETSI)引入的概念,最初以移动边缘计算(MEC)的名称启动。最初,它包括移动网络和虚拟机作为虚拟化技术。然而,随后这个想法扩展到支持非移动网络需求,并包括其他虚拟化技术。实际上,MEC通过可由LTE宏基站(eNodeB)和多无线电接入技术站点访问的移动边缘计算服务器,在网络边缘提供云计算设施。
多接入(Multi-Access)是指MEC架构支持多种不同的接入方式,包括无线接入(如4G、5G网络)、有线接入(如WLAN、光纤网络)等。
在MEC架构中,边缘节点可以通过多种不同的网络接入方式与移动终端设备进行通信和交互。例如,在无线接入方式下,边缘节点可以通过4G、5G等移动通信网络与移动终端设备进行通信,提供低延迟、高带宽的计算和存储服务。在有线接入方式下,边缘节点可以通过WLAN、光纤等有线网络与移动终端设备进行通信和交互。
多接入体现在MEC架构的边缘节点可以支持多种不同的网络接入方式,这使得MEC架构可以根据应用需求和网络环境的变化进行自适应和调整,提供更优质、更高效的移动应用服务。同时,多接入也为移动终端设备提供了更多的选择和灵活性,可以根据应用需求和用户喜好进行选择和切换。
雾计算:雾计算将云计算从网络的核心延伸到网络边缘,从而在靠近终端设备的网络边缘提供计算设施。雾计算部署靠近用户并位于终端用户和云之间的雾节点(例如边缘交换机、网关、智能手机、接入点等)。与云端和MEC不同,雾计算不以独立模式运行,而是与云的存在相结合。
分散式云计算:分散式云计算的最新想法可以看作是边缘计算的进化版本,它利用智能设备(例如智能手机、手机、传感器、无人机、汽车等)的计算和存储能力来增强边缘计算的计算/存储能力,并在设备附近提供云计算能力。这种范式引入的计算连续性不仅提高了延迟体验,还缓解了边缘服务器/数据存储超载和由于边缘基础设施部署而导致的高成本问题。然而,设备的计算/存储和能源限制、设备的移动性以及计算/内容卸载到附近设备的安全方面仍然是主要挑战。有关更多详细信息,可以参考调研报告[6],[7]。
4. 新兴网络内计算中的技术的作用
在本节中,我们解释了所提到的技术如何在实现网络内计算方面发挥作用:
可编程数据平面:可编程数据平面提供了在网络内执行计算的基础设施。所需的计算(例如数据分析、安全策略、缓存、负载均衡等)在可编程数据平面中实现。可编程交换机和路由器、FPGA和智能网卡是可编程数据平面元素的示例,它们已在网络内计算的范围内使用。
边缘计算:边缘计算可以通过提供网络内计算设备(即位于网络边缘的网络元素)来促进网络内计算,以便在到达远程服务器之前在路径上执行所需的计算。实际上,边缘计算与网络内计算的结合已在多项研究中讨论,例如[15],[58]。在这方面,与常规边缘服务器相比,计算可以在路径上更靠近终端设备进行。
软件定义网络(SDN):根据网络内计算的概念,在网络元素上执行计算、决策或控制具有减少SDN控制器干预的潜力,如[59],[60]所讨论的那样。然而,SDN控制器仍然可以执行必要的管理任务,以及根据系统的整体视图高效执行的任务,例如在数据平面中安装和更新规则,配置和安装数据平面上的程序和功能,配置网络以阻止恶意流量,验证等[60],[61],[62],[63],[64]。
B.支持协议
截至本文作者所知,目前尚未在文献中提出针对广泛的网络计算应用的专门通信协议。因此,在网络计算范围内的现有研究使用已经存在的消息传递机制。不基于IP寻址的消息传递机制有望实现网络内计算能力。在本节中,我们讨论了四种现有的非基于IP的消息转发机制,并解释了它们如何实现网络内计算。
1. 未知消息转发
未知路由算法是一种不使用查询语义或目标节点地址来做转发决策的转发协议机制。在这方面,泛洪[65]和随机游走[66]是最流行的算法。这些算法可以用来在网络中广播消息,以便网络元素可以检查消息并在实现计算的情况下应用所需的计算。然而,这些方法在产生的流量方面并不高效。
2. 信息中心化网络(ICN)
互联网被广泛用于传播信息和数据,而不是用于源和目的地之间的一对一通信,这成为了将来互联网架构的一个原则。在这方面,最初的想法是由Gritter和Cheriton [67]提出的。ICN主张部署网络内缓存以及多播传输,以更有效地向用户提供信息。基于ICN,信息的命名和匹配独立于其位置,因此可以从网络中的任何位置提供。在请求到达时,网络将定位可以提供所需信息的最佳源。对ICN的详细调查可以参考[68]。在ICN的同一方向上,将信息视为所需计算,将命名视为计算名称,使得可以查询计算,网络元素可以根据设备的位置提供计算。
3. 面向服务的网络
面向服务的网络是ICN的扩展版本,为未来的互联网(例如6G[69])提供对内容和计算服务的支持。每个计算服务可以通过唯一名称来识别其功能和参数。它使用三个阶段的操作来执行一个函数:(i)将请求转发到函数,(ii)获取所需数据,(iii)计算并返回结果。此外,它支持在函数之间进行链接以提供更复杂的服务。这种计算范式使得可以在网络内执行计算函数而无需知道位置。
最近,在[69]中提出了面向内容/计算/上下文感知的服务中心化网络协议的采用版本,被认为对于6G非常有前途。请求包含服务标识符、目标对象和上下文的兴趣/数据名称用于转发和知识目的。在服务标识符之后,目标对象指示转发方向,而上下文对象为函数计算提供附加信息。当一个兴趣到达时,数据平面元素的内容存储将被搜索,以根据上下文信息获取缓存的内容或计算结果。如果缓存未命中,协议还允许在数据平面元素中进行本地计算,即进行网络内计算,或通过转发流程管道程序转发兴趣。SDN控制器也通过支持新的匹配字段(即服务、对象和上下文)、更先进的转发技术来处理缓存、执行函数和函数链,以及根据数据/兴趣处理的上下文设计新的流表。
考虑到在新兴的6G垂直服务中(例如URLLC应用,如自动驾驶、工业控制)提供超低延迟(ULL),如[69]所建议的,超低延迟要求可以作为服务请求的一部分插入到兴趣/数据名称协议中,以应用相应的网络内计算/缓存,以及延迟感知的转发策略。由于延迟感知的数据包转发超出了本文的范围,因此在这里提及一些标准化尝试。IEEE 802.1时序网络标准提供了ULL网络的链路层支持,而IETF确定性网络标准提供了补充的网络层ULL支持。有兴趣的读者可以参考[70]了解IEEE TSN和IETF DetNet标准及相关研究。
4. 基于语义的消息转发
在基于语义的消息转发中,消息的路由是基于其含义而不是IP地址进行的[71],[72]。为了将消息发送到特定的网络节点,需要在消息中插入一个语义键,其含义类似于网络中所定位节点的描述。一旦消息到达网络,它就会被传递到由语义键定义的目标目的地,然后目标节点可以回复消息源。实际上,网络可以被视为一组相互连接的语义路由器,每个路由器比较消息中的语义键和存储在语义路由表中的资源描述之间的相似度,以决定下一跳目的地。
另一种形式的语义路由是内容路由,它已被用作点对点网络中的路由机制[71]。内容路由算法还利用嵌入在用户查询中的语义信息,在每个跳点上做出路由决策。在内容路由中,语义或对象通过关键字进行标识,并且广告和查询是用这些关键字来表达的。与基于地址的路由相比,在语义路由中,对象是通过键进行标识的,这些键是通过对与对象相关的关键字应用哈希函数构造的。由于基于键的路由将选择具有该键的特定资源来处理消息,因此它比基于关键字的消息路由更有效。然而,基于键的查询路由不支持部分匹配语义。相反,内容路由系统可以通过使用盲目搜索方法来支持部分匹配查询。然而,生成的查询路由流量将很大,并且无法保证搜索的完整性。
智能泛洪是最常用的内容路由技术之一。它根据一些标准(如先前的查询结果、节点的容量、内容类型等)将消息转发给一些邻居,从而减少盲目搜索方法的开销。Ahmed等人对内容路由提供了详细的描述[71]。在网络内计算的上下文中,语义可以被视为可以由网络元素实现的计算。为了方便搜索机制,网络元素可以将其支持的计算暴露给类似于语义路由表的数据结构。基于消息中的语义,即计算信息,可以利用这样的数据结构将消息路由到可以应用计算的网络元素。
C.说明性的用例和网络内计算的好处
在本节中,我们通过在网络分析和网络缓存范围内的两个用例来说明网络内计算的概念。对于每个用例,我们讨论了没有网络内计算的过程以及有网络内计算的过程。
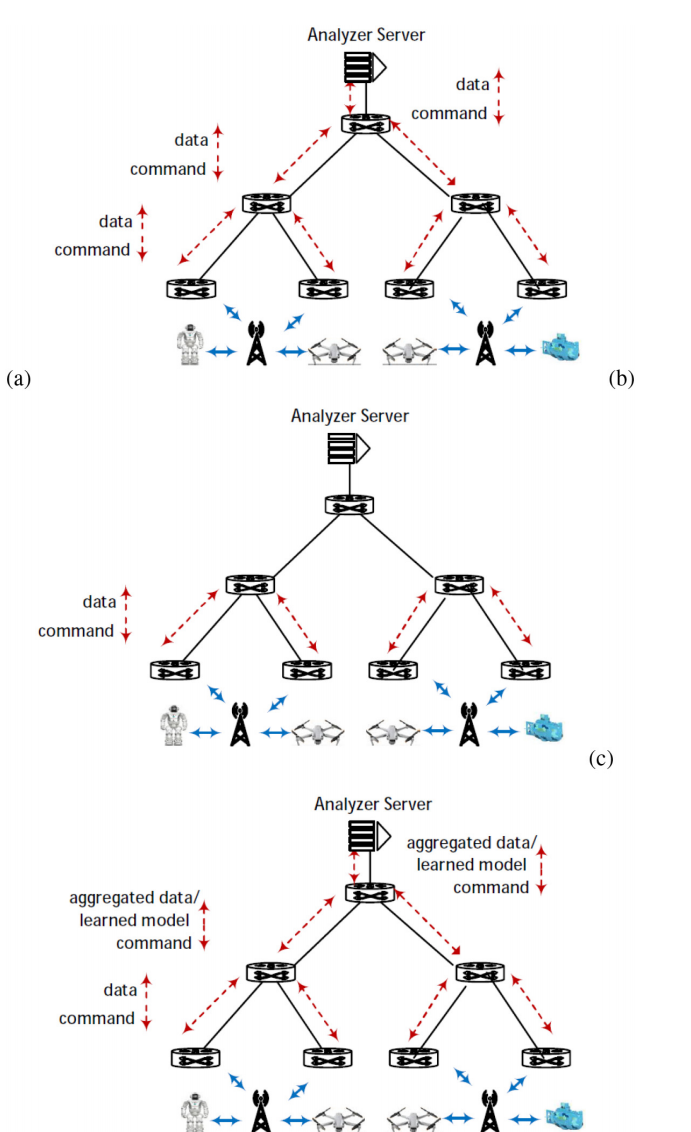
图6。(a)在不进行网络内计算的情况下对接入层的数据进行分析,(b)当收集的数据足以应用分析时,通过网络内计算对数据进行分析,©利用网络内计算对接入层收集的整个数据进行分析。
1. 网内计算
图6a说明了在具有分层结构的网络中可以执行数据分析的场景。在接入层,数据从一些设备(例如IoT设备)收集,并馈入一个交换机网络,以达到执行分析的服务器,即所谓的分析服务器。该服务器可以实现机器学习(ML)或某种聚合以推断模型。分析服务器可以是位于边缘的服务器。在服务器执行分析之后,它将返回到目标设备(例如执行器)的相应命令。
图6b说明了交换机是可编程的并且利用网络内计算的场景。该场景适用于在应用分析之前已经收集了足够的数据的情况。例如,在中间层的交换机上已经收集了所需的数据,可以应用ML /聚合。假设已经在中间层交换机中实现了ML /聚合方法,以便交换机可以对它们接收到的数据包应用分析。在这种情况下,在数据到达分析服务器之前在网络内运行ML /聚合不仅可以在靠近终端设备处终止流量并在网络的更高层节省带宽,还可以确保快速的命令发出。
图6c说明了当需要将接入层收集的所有数据都包含在分析中时的情况。即使在这种情况下,通过将ML /聚合方法卸载到可编程交换机中,网络内计算也可能是有效的。交换机在数据穿越网络时对数据执行ML /聚合操作。数据从绑定到网络接入层的交换机进入网络,并沿着网络向上移动,ML /聚合在交换机处发生。可编程交换机从其所有子节点接收数据并执行ML /聚合操作。学习的模型/聚合数据由交换机发送到其父交换机。分析服务器执行最终的学习/聚合,并向下转发命令到设备。学习的模型或聚合数据的数量小于原始数据的大小,因此在数据穿越网络时减少了数据量,而不是等待数据到达分析服务器才对其进行操作。因此,带宽节省的优势在这种情况下同样存在。
suffificient data has been gathered before applying the analytic和all data collected in the access layer is required to be included in the analytic(图b和图c)的区别:
前者意思是在应用分析方法之前已经收集了足够的数据。这种情况下,不需要将接入层收集的所有数据都包含在分析中,收集到一定量的样本数据就可以进行分析和模型推断。
后者意思是需要将接入层收集的所有数据都包含在分析中,不能遗漏任何数据。这种情况下,需要更多的数据才能进行精确的分析和模型推断。
两种情况的主要区别在数据量和精度上:
第一种情况下,不需要所有数据,有一定的数据样本即可,所以数据量较小但精度可能稍差。
第二种情况下,需要利用所有数据,数据量很大但可以达到更高的精度。
举个例子:
如果要分析用户购买行为,第一种情况下可以抽取一定比例的用户数据进行分析,建模,这时候数据量不大但模型精度可能不太高。
第二种情况下需要分析所有用户的购买数据,数据量很大,但可以建立一个非常精确的用户行为模型。
2. 网内缓存

图7。(a)一般的缓存系统,(b)网络内缓存。
图7a显示了当有存储服务器或原始服务器为用户提供内容时,缓存的一般情况。存储服务器可以由边缘计算提供。用户设备可以通过可编程交换机网络连接到存储服务器。项被建模为键值对。不失一般性,我们假设存储服务器具有足够的容量来存储所有项。控制器将数据包转发规则应用于交换机。在一般情况下并且没有网络内计算的情况下,交换机扮演数据包转发的角色。当读请求到达网络时,交换机将应用已安装的转发规则并将请求转发到存储服务器。请求将沿着整个路径到达存储服务器。然后,与请求的键相关联的值将返回所有路径以到达用户。
图7b显示了当我们有网内缓存时的交付方案。用户设备和存储服务器之间的网络交换机负责为键值对项目实现路径缓存,并使用标准协议路由数据包。预期使用网内缓存服务的数据包可能与普通数据包区分开来,以便对其执行必要的处理,以提供网内缓存服务。交换机具有作为匹配操作表实现的键值存储模块,用于存储热门项目。控制器负责根据网内缓存策略更新交换机存储中的热门项目。可以根据交换机计算并发送到控制器的项目统计信息来检测热门项目。当读取查询到达时,交换机检查缓存是否包含该项目。如果是缓存命中,交换机将关联的值返回给用户。否则,请求将继续向存储服务器前进。在路径上,一旦任何交换机检测到该键,数据包的旅程将被截断。因此,通过网内缓存可以实现更低的延迟。
3.网内计算的好处
(i)高吞吐量
网络元素可以每秒处理数十亿个数据包。例如,Barefoot发布的Tofino芯片支持12.8 Tb/s的线速处理。因此,与基于主机的解决方案相比,网络内计算范式提供了数量级更高的吞吐量处理能力。
(ii) 低延迟
基于主机的解决方案受到固有的不确定延迟和抖动的影响。相比之下,网络元素支持亚微秒级的处理延迟。由于管道设计在每个阶段不访问外部存储器,因此延迟几乎是稳定的,即低抖动。正如我们通过说明性用例所讨论的那样,网络内计算在网络内部执行计算,因此交易在路径内终止,避免了将数据绕道到远程服务的情况。因此,由于从网络元素到终端主机的数据传输而导致的延迟将被节省。实际上,网络内计算可以在用户附近执行计算,并将计算带到边缘/云计算服务器之外。
(iii) 减少带宽使用
正如我们通过说明性用例所讨论的那样,网络内计算在路径上终止数据计算,并在到达边缘/云服务器之前终止。因此,将节省带宽使用,可以避免回程链路上的流量拥塞。
(iv) 负载平衡
通过利用网络内计算,一种负载平衡出现。请求可以在路径上由网络元素响应,并在到达终端主机之前进行处理。在这方面,工作负载在网络元素和终端主机之间分配。例如,可以将延迟不敏感应用程序的流量转发到终端主机,而网络元素可以容纳延迟敏感的应用程序。
(v) 能源效率
网络元素在执行操作时消耗的能量较少。一个典型的可编程交换机每瓦能源使用量可以执行数十亿次操作。例如,Arista 7170系列可编程交换机每100 G端口消耗不到5瓦。另外,[27]中的实验表明,网络元素中数百万次查询操作将消耗不到1瓦的功率。网络元素每瓦能源使用量的处理能力比通用计算机更高效。此外,由于网络元素是网络的组成部分,其默认任务是进行数据包转发,因此在空闲模式下消耗的能量不高。相比之下,通用计算机在空闲模式下存在高能耗的问题。
D. 分类、评估和比较标准
在本节中,我们提出了一套标准来分类、评估和比较网络计算范围内的文献研究。
1. 提出的分类
在第一级别上,我们建议基于网络内计算的应用来对研究进行分类。为了澄清网络内计算的涉及范围,在每个应用类别中,我们建议根据网络内计算在该类别上下文中涉及的专业主题来组织论文。第I-C节详细介绍了我们提出的分类结构。在这里,为了方便阅读,我们提供了第一级别上建议的分类概述。我们发现有五个类别,即分析、缓存、安全、协调和技术特定应用:
(i) 网络内分析:此类研究利用网络元素在路径上执行分析(例如,机器学习、数据聚合、重流检测、查询处理、控制、深度数据包检查),而无需将数据传递到终端主机执行分析。
(ii) 网络内缓存:此类研究利用网络元素在存储服务器上构建一个网络内缓存系统,以减少数据访问时间。在这个研究类别中,我们发现了在键值存储应用程序范围内进行的研究,以及在信息为中心的缓存范围内进行的研究。
(iii) 网络内安全:此类研究在网络元素中执行部分或全部功能,以检测和减轻网络攻击,以减少安全目的专用服务器所带来的攻击缓解延迟和操作成本。
(iv) 网络内协调:通过在分布式系统中实现共识协议来达成某些数据值或操作序列的一致性,这可以视为一种协调。在文献中,还存在其他类型的协调,例如锁管理系统、组播通信、一致性协调。此类研究将执行协调所需的部分或全部功能卸载到网络元素上,以减少协调延迟。
(v) 技术特定应用:此类研究提供与特定技术相关的各种网络内计算应用,包括云计算、边缘计算、4G/5G/6G和网络功能虚拟化。这个研究类别中的研究将特定于某种技术的部分功能卸载到网络元素上。
2.提出评估和比较标准
我们提出了两类标准来分析、比较和评估网络内计算论文:通用标准和特定应用标准。
(i) 通用标准:
我们提出以下标准来分析、比较和评估所有可能的网络内计算解决方案,如下所示:
• 网络内计算:网络内计算是在网络元素中执行的任务或计算。实际上,网络元素的逻辑组件(例如可编程交换机的匹配-动作表,可位于TCAM/SDRAM中;FPGA的计算逻辑块;智能网卡的可编程组件等)可以通过语言(例如P4)进行编程,以执行网络内计算。根据应用程序的不同,网络内计算可以是一种数据聚合、机器学习算法、流量统计计算、安全策略、移动通信技术中的无线电/核心网络功能或一般网络功能等。这一标准为研究人员提供了洞察力,可以评估目标计算是否可以在特定的网络元素中实现。此外,一些经验教训可以从未在网络元素中实现的特定计算中得到,以填补研究的空白。
• 协同设计:该标准定义了在所提出的方法中,网络元素是否与非网络元素(例如服务器、控制器)一起使用来执行所需的计算或决策。所需的计算是基于问题的上下文定义的。在网络内分析中,执行分析;在网络内缓存中,执行缓存并回复请求;在网络内安全中,执行攻击缓解;在网络内协调中,执行协调(例如共识协议中的共识)是所需的计算。类似地,在技术特定应用程序中,所需的计算是根据目标问题的上下文确定的。例如,在尝试在网络中执行LTE EPC控制平面时,所需的计算是LTE EPC控制平面功能。每当所提出的方法是协同设计方法时,仅在网络元素中执行所需计算的一部分,否则整个所需计算都实现在网络元素中。在这方面,非协同设计方法可以完全在网络中实现。该标准为研究人员提供了有关网络内计算在处理各种问题方面的能力的见解。此外,一些经验教训可以从研究的空白中得到,例如在应对网络元素的硬件限制时提供协同设计方法。
• 数据结构:该标准定义了在实现中使用的网络元素的数据结构。我们已经报告了使用的知名数据结构:布隆过滤器(提供测试元素是否为集合成员的能力的数据结构)、草图(能够汇总有关网络的信息的数据结构,例如获取需要固定大小内存的流量统计信息)、哈希表[44],[73]。
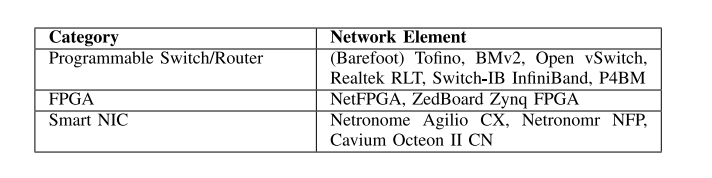
• 网络元素:该标准定义了用于评估的网络元素。我们在文献中发现了三类网络元素:可编程交换机/路由器、FPGA和网络接口卡(NIC)。表格I说明了每个类别中的设备。该标准为研究人员提供了有关确定用于特定应用程序的网络元素的见解。此外,该标准还提供了有关各种网络元素的使用分布情况的见解,因此可以从中得出一些经验教训来填补研究的空白。
表I 在网络内计算研究中使用的网络元素的类别
• 平台:该标准定义了用于评估方法的平台,可以是硬件或软件。请注意,当评估中使用网络元素的软件版本(例如BMv2、软件路由器、模拟交换机)时,我们将平台视为软件。
• 主要结果:本调查提供了网络内计算设备在延迟、吞吐量、带宽节省和功耗方面取得的主要结果。
(ii) 应用特定标准
我们还提出了一些应用特定的标准,用于比较研究。在这里,我们提供标准的摘要,并将读者引用到每个应用程序的专门部分以获取详细信息。
• 网络内分析:我们将用于在网络元素中实现分析的简化技术(例如量化、预计算)视为标准。此外,考虑到分析的目的是推断基于收集的数据构建的模型,我们将使用包括模型复杂度、模型准确性、推断速度和带宽消耗(由于数据传输)的标准来比较方法。我们还提出了一种用于比较在网络中实现分析的技术以应对硬件限制的方法,包括硬件限制类型、技术操作和由于应用技术而妥协的标准。
• 网络内缓存:在这个范围内的方法提供了网络内缓存机制来促进内容/项目的访问。我们将包含网络内缓存层次结构的缓存机制定义为深缓存,否则定义为浅缓存。我们将考虑网络内缓存机制类型(即浅缓存/深缓存)作为标准。此外,我们将使用包括缓存层次结构、请求处理中的负载均衡、内容/项目访问延迟、网络边缘可用存储和带宽消耗(由于内容传输)的标准来比较方法。
• 网络内安全:考虑到这些方法的目标是缓解攻击,我们将使用模型攻击检测系统状态、攻击检测模型、攻击检测准确性、缓解延迟(包括检测和应用安全策略的延迟)和带宽消耗(由于流量传输以检测攻击)等标准来比较方法。
• 技术特定应用程序:我们评估方法是否应用了任何优化方法来优化系统或应用程序相关的性能指标。此外,我们将从计算节点类型、处理成本、延迟/吞吐量和功耗等标准的角度比较文献中的方法与基于服务器/专用硬件的方案的优缺点。我们还将讨论资源分配技术在应对混合底层网络(包括网络元素和通用计算单元)方面的优缺点,包括运行时适应性和容错性等标准。
在本调查的其余部分,我们回顾了我们发现与网络内计算相关的不同论文,并根据上述类别和我们早期指定的标准进行讨论。每当调查的方法是一种共同设计方法时,我们将解释其背后的原因。比较将得到逻辑上的解释以及在文献中收集的证据的支持。
III. 网内分析
在这一部分,我们概述了在网络内执行分析的现有研究。图2第III节说明了本节的结构。我们对数据聚合、机器学习和其他分析三个类别中的网络内分析研究进行了概述。数据聚合概述了从不同源收集数据并对数据应用一些聚合函数或操作的研究,这可以视为从数据中组装聚合模型的一种分析。在这些研究中,利用网络元素执行数据聚合。机器学习类别概述了在网络元素中实现机器学习技术的研究。最后,其他分析类别包括在网络内分析范围内进行的其他研究,包括重流量检测、控制、查询处理、复杂事件处理和深度数据包检查。在本节的其余部分,我们介绍了上述类别中的研究,并最终对研究进行了总结,并讨论了学到的见解和经验教训。
A.数据聚合
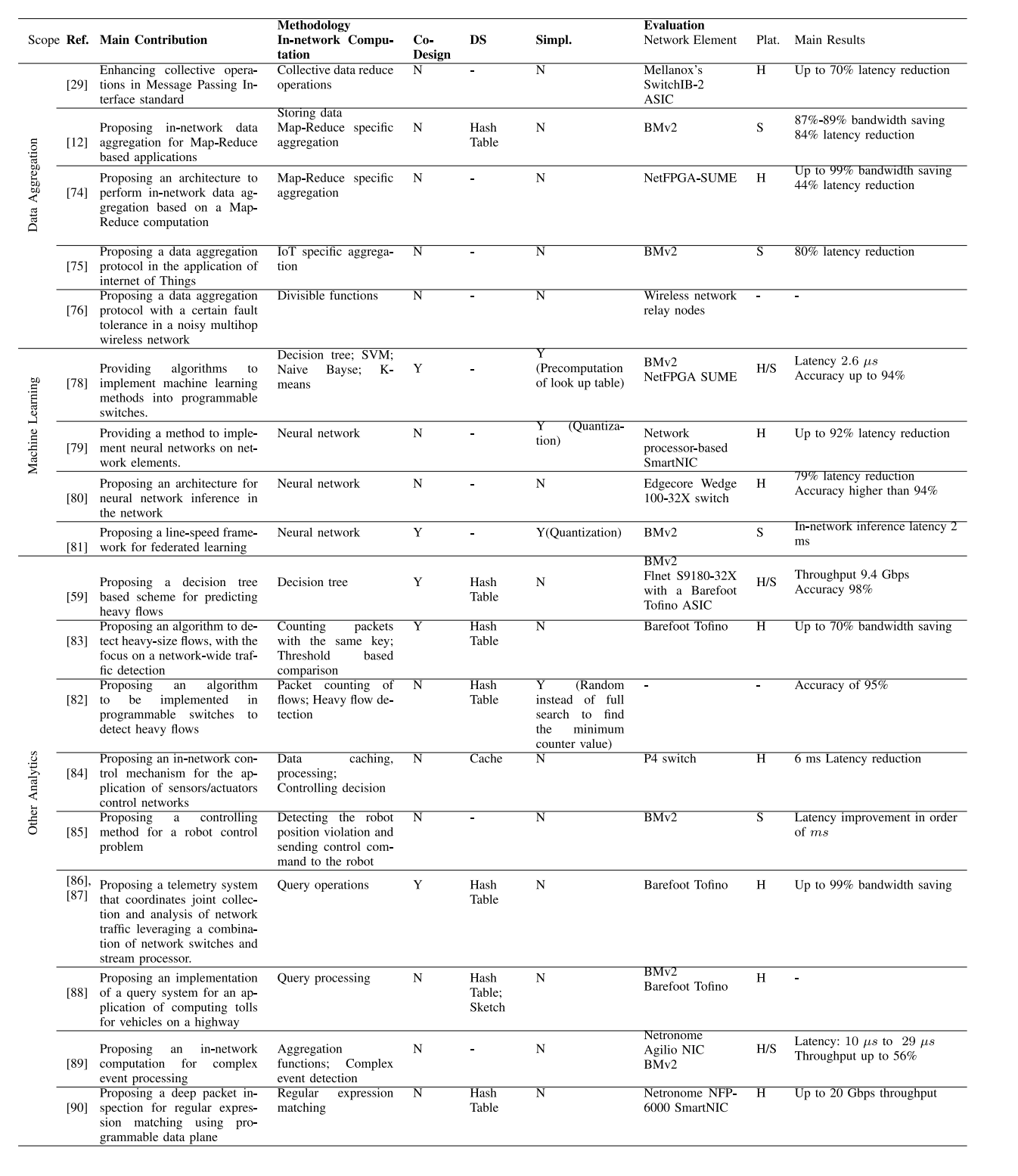
数据聚合是一种通过应用聚合函数或操作将来自不同来源的数据组合起来的技术。网络内数据聚合在网络元素上设置聚合覆盖层,以在数据通过覆盖层时聚合数据。与传输数据到集中式主机以进行聚合的基于主机的聚合相比,在网络内聚合不仅减少了网络中的流量,而且利用了网络元素的快速处理速度,减少了聚合时间。在这个研究类别中,[12],[29],[74],[75],[76],[77]采用类似的多级数据聚合架构,通常基于树形结构,但是它们提供了适用于各种应用程序的协议。[29]提出了一种用于高性能计算应用程序的数据聚合协议,[12],[74]的研究提供了基于Map-Reduce应用程序的数据聚合协议。[75]的研究为物联网应用提供了网络内聚合,[76],[77]的研究提出了用于无线网络的网络内聚合。
高效的高性能计算架构需要评估可代替的系统元素以适当地分配数据操作,而不是将所有数据的处理负载到本地或远程CPU上。将数据操作卸载到网络中,随着数据的移动,可以释放CPU周期用于计算,降低通信延迟以及在网络上传输的数据量。为了实现这些目标,Graham等人[29]将高性能计算中常用的通信模式,即消息传递接口(MPI)标准中的集合操作,卸载到网络中。作者提出了一种分层聚合协议,将操作卸载到网络中以进行数据聚合。在网络元素中执行包括小数据减少、全局减少和障碍等减少操作。数据从其叶子节点进入聚合树,并在树中向上移动,同时在聚合节点处执行数据减少操作。聚合节点从其所有子节点接收聚合请求并执行聚合操作。每个聚合节点上的每个集合操作使用一个数据结构来跟踪集合操作的进度。聚合的结果由聚合节点发送到树结构中的其父节点。根聚合节点执行最终的聚合操作,生成聚合操作的结果,并将结果转发给目的地。该协议还支持容错机制,以应对可能发生的错误,包括传输级错误、终端节点错误和协议错误。网络内计算是在Mellanox的SwitchIB-2 ASIC中实现的集合数据减少操作。评估结果表明,操作完成的延迟可以提高70%。
[12]和[74]的研究针对基于Map-Reduce的应用程序执行网络内数据聚合。Sapio等人[12]设计了一个聚合系统,在该系统中,对于每个reducer,构造一个跨度树,其中reducer作为根节点,包括所有mappers到reducer的路径。然后,网络控制器配置网络元素执行每棵树的聚合,并通过树形结构转发流量。每个映射任务生成一组键值对,这些键值对在reducer之间进行分区。分区通过UDP数据包传输到reducer,其中每个数据包包含一个前导部分和一系列键值对。前导部分定义了键值对的数量和数据包所属的树ID。对于每棵树,网络元素在内存中存储键和值。作者提出了一种算法,由每个网络元素执行,其中元素聚合存储在其内存中的值和它收到的新值。所提出的算法还编程网络元素将聚合结果转发到朝向目标的下一个节点。网络内计算,即存储数据以及Map-Reduce特定的聚合由BMv2实现。对于Word-Count应用程序,实验表明,所提出的方法提供了87%-89%的带宽节省和84%的延迟降低。
[74]的作者基于Map-Reduce计算提出了一种执行网络内数据聚合的体系结构。所提出的体系结构由交换机、头部提取模块、负载分析器和控制器组成。(i)交换机聚合从不同端口到达的流,并将聚合结果发送到下一个跳点。此外,它也正常转发数据包。(ii)头部提取模块检查数据包头,并将正常数据包发送到基于传统路由的L2/L3信息的转发模块。然而,在数据包被标记为聚合目的的情况下,数据包将被转发到负载分析器。(iii)负载分析器接受以键值对格式化的有效载荷,并基于它们的长度将这些对分配给不同的处理引擎。处理引擎聚合哈希表中存储的相同键的值。(iv)控制器构建聚合树并配置交换机。网络内计算是Map-Reduce特定的聚合,由NetFPGA-SUME开发板实现。作者使用Verilog HDL开发了数据平面,并将其编译为NetFPGA-SUME开发板,并实现了一个简单的类MapReduce系统,以分区/聚合模式工作。所提出的体系结构已经获得了高达99%的数据减少率和高达44%的作业完成时间的降低。
不同于基于键的聚合[12]和[74],Madureira等人[75]根据服务ID执行聚合,以涵盖各种物联网服务。作者提出了一个多级数据聚合体系结构,用于在物联网应用程序中聚合数据。数据在多级体系结构的元素中传输时进行聚合。聚合协议在网络元素的链路层(L2)中运行。数据包头包含三个主要元素:(i)服务ID,用于标识属于同一物联网应用程序的相似数据集。(ii)数据计数器,用于定义数据块的数量。(iii)类型,指示要用于转发数据包的转发机制。聚合层次结构中的交换机从层次结构中的其他交换机接收数据包,并在满足某些条件后根据数据包的服务ID聚合它们的数据(例如平均值)。主要条件是当接收到的具有相同服务ID的数据数量达到阈值时。作者还提出了一些技术来应对在实现中不受交换机支持的循环和矩阵数据结构。网络内计算是物联网特定的聚合,由BMv2实现。在物联网设备和雾计算网关作为接收端的环境下进行的模拟结果表明,与在物联网设备中执行聚合的情况相比,所提出的方法在平均延迟方面快了5倍。
[76]提出了一种在嘈杂的多跳无线网络中具有一定故障容忍度的数据聚合协议。该研究的主要讨论在[77]中给出。每个节点将m位整数作为输入,并在每个节点收集预定义数量的读数后开始计算。作者重点关注可分配函数的执行。在网络分簇后,提出了两种簇内和簇间协议。簇内协议利用簇头的协调来在簇内对数据应用函数。通过应用簇间协议,本地聚合结果通过簇头和中继节点路由到接收节点。编码数据成编码词和接收数据后解码也包括在簇内和簇间协议中。此外,利用簇之间的调度进行传输以减少由于并发传输而产生的干扰。所提出的协议的效率针对恒等函数和受限类型阈值函数得到了改进。作者还分析了协议的复杂性。网络内计算是可分配函数,由无线网络中继节点实现。尽管与其他数据聚合方法相比,该方法讨论了网络中更一般的函数应用,但讨论是基于分析的,并没有对所提出的方法进行评估。
B.机器学习
机器学习算法广泛用于对传入数据包进行分类或执行回归。将数据包头字段和流量统计数据作为输入特征,这些算法能够从收集的网络跟踪数据中学习流量模式,并对未来的输入进行预测。为了应用机器学习,一个未知的数据包需要被转发到远程服务器上运行学习算法。然而,这样会带来较高的延迟和带宽消耗。已经进行了研究,利用网络内计算来减少学习处理时间,更早地响应事件,并在接近边缘时终止流量。[78]实现了各种分类方法,包括决策树、SVM和朴素贝叶斯,[79],[80]实现了神经网络,最后[81]通过网络元素实现了联邦学习。在本节的其余部分,我们将提供有关上述研究的更多细节。
在[78]中,Xiong和Zilberman考虑了在交换机上实现决策树、SVM、朴素贝叶斯和K-means聚类。作者利用查找表存储计算结果,提出了一些算法来在交换机上实现上述分类和聚类。对于决策树,在管道的每个阶段,一个特征与其所有潜在值进行匹配。结果,即表示树中分支发生的动作,被编码到元数据字段中。管道中的最后一个阶段根据所有特征的元数据字段计算最终结果。SVM在多个表中实现,每个表都指示输入与超平面的关系。事实上,匹配-动作表中的键是给定输入的特征集,动作是表决,表示输入是否属于超平面内部或外部。一旦一个输入与所有表(即所有超平面)匹配,得票数最高的类别将是分类的结果。朴素贝叶斯通过使用每个类别一个表,以及将特征作为键来实现。返回的值是一个整数值,表示朴素贝叶斯学习中使用的概率。作者还讨论了不同映射的聚类和特征到表格的K-means聚类。网络内计算是决策树、SVM、朴素贝叶斯和K-means,它们在BMv2和NetFPGA SUME中实现。所提出的方法被认为是一种协同设计方法,因为它在学习中使用所需的数学初始化查找表。评估是针对物联网流量分类进行的,有多个类别(例如音频、视频等)。报道了以线速率进行分类(推理)的延迟,即2.6微秒,以及高达94%的准确性。
[79]讨论了在网络元素上实现神经网络。通过实验,作者展示了当采用GPU或TPU等离线加速器运行AlexNet神经网络时,数据移动的开销很高。通过在路径上实现加速器,可以减少额外的数据移动开销。然而,利用网络元素执行神经网络处理需要对处理进行拆分,这将产生开销。作者通过建议适当的拆分机制来减少开销。全部或部分神经网络参数存储在网络元素的SRAM中。使用一种称为量化的过程,即将激活和参数进行二值化,简化了神经网络的全连接层的操作,从而减少了表示神经网络激活和参数所需的位数,并使用更简单的算术运算。网络内计算是神经网络,它在基于网络处理器的SmartNIC中实现。神经网络的单层处理在网络中需要1毫秒,而当处理由CPU执行时,此延迟高达12毫秒。
类似于[79],卢和林[80]提出了一种在网络中进行神经网络推理的方法。作者开发了一个数据转发处理系统,允许数据包克隆到交换机内核进行在线推理。为了提供交换机内推理的能力,使用了一种称为神经计算棒(NCS)的硬件。NCS通过USB接口连接到P4交换机,以便处理克隆数据包并进行实时推理。所提出的架构包括两个阶段:(i)离线模型训练阶段,使用CNN架构LeNet-5创建推理模型;(ii)在线推理阶段,利用NCS在线进行推理。网络内计算是神经网络,它在Edge-core Wedge 100-32X交换机中实现。对于基于卷积神经网络的恶意软件分类问题,当在网络中进行推理时,推理时间为9毫秒,而在服务器中进行推理时为44毫秒。准确率高于94%。
Qin等人[81]利用网络内计算,提出了一个面向联邦学习的线速框架。在网关中执行具有二进制权重和符号函数作为激活函数的神经网络分类,该网关转发网络域内设备的数据包。实值权重的神经网络存储在控制平面中,通过执行反向传播在网关中重新训练分类算法。经过本地训练后,网关将本地更新发送到作为聚合器的云端。为了降低通信成本,每个网关仅报告本地更新的1位符号。然后,云端将通过多数表决机制宣布结果。网络内计算是神经网络,使用BMv2实现。所提出的方法是一种协同设计方法,因为它利用云计算进行聚合,利用控制平面进行反向传播和更新。针对具有120个神经元的一个全连接隐藏层,用于恶意软件流量检测的评估表明,在网络中推理的延迟对于95%的数据包都少于2毫秒。
C. 其他分析
网络内计算已经在重型流量检测[59]、[82]、[83]、控制[84]、[85]、查询处理[86]、[87]、[88]、复杂事件处理[89]和深度数据包检查[90]的应用中得到利用。在本节中,我们对这些研究进行概述。
重型流量检测(Heavy Hitter Detection)是网络监控和安全领域的一个重要问题。它的目标是检测网络流量中数据量最大的流(Heavy Hitter Flow)。
重型流量检测对于许多网络管理应用程序都有好处,包括减轻链路拥塞、检测网络攻击、调度网络容量等。现有的重型流量检测方法通常在软件定义网络的控制平面上实现。因此,由于控制平面和数据平面之间频繁通信而导致决策制定时的开销和额外延迟。网络内计算已被利用来减少这种开销。[59]、[83]、[82]的研究类似于在数据平面中实现计算每个流的数据包数以估算流大小。对于计数值的分析,[59]使用了机器学习方法,而[82]、[83]则建议采用基于阈值的决策。
张等人[59]提出了一种基于决策树的方案,用于在可编程数据平面上检测重型流量。所提出的方法包含离线模型训练和在线推理两个步骤。在离线模型训练中,控制器训练决策树并将其编译到目标交换机的资源中。在在线推理中,基于决策树,在可编程数据平面上检测重型流量。在流水线中,提取第一个数据包的头部并将相应的信息保存在寄存器中。当流的接收数据包数量达到阈值时,将通过决策树对流进行评估,并在检测到重型流量时用标志标记。因此,可以在检测时采取所需的操作。网络内计算是决策树推理阶段,使用BMv2和Flnet S9180-32X以及Barefoot Tofino 32D ASIC实现。所提出的方案是一种协同设计方法,因为训练阶段由控制器执行。检测精度高达98%,硬件交换机的平均吞吐量为9.4 Gbps。
Sivaraman等人[82]也提出了一种算法,用于在可编程交换机中检测重型流量。与[59]类似,使用一个表来识别流关键字及其相关计数器,其中计数器表示与流相关的数据包计数。在数据包到达时,如果表缺少其对应流的计数信息,并且表中有空间,则将新流插入表中并将其初始计数值设置为1。然而,当流的计数信息已经在表中时,相应的流计数器将被更新。在表已满且缺少流信息的情况下,表中具有最小计数器值的流条目将被替换以指示新到达流的统计信息。流的数据包计数和重型流量检测是网络内计算。所提出的方法可以在消耗不到80 KB的内存的情况下,以95%的准确度检测重型流量。
Vestin等人[84]利用网络内计算来应用于传感器/执行器控制网络。传感器定期生成数据,将这些数据传输到控制器进行分析。因此,控制器向执行器发送控制动作。为了减少与控制器通信所导致的延迟,作者将控制器的部分功能卸载到可编程交换机的数据平面中。交换机将缓存传感器值的历史记录。对应于控制决策的逻辑表达式被转换为合取范式,并在交换机表中实现。因此,交换机将触发对执行器的控制决策。此外,当存在链路故障时,提出了一种主动式链路修复方案。网络内计算包括数据缓存、处理和控制决策,在P4交换机中实现。实验结果表明,与控制器发送控制动作的情况相比,所提出的方法将传感器-执行器延迟降低了6毫秒。
Cesen等人[85]专注于超低延迟机器人控制问题,其中网络由机器人和控制器组成,机器人臂被编程执行结构良好的重复任务。控制器与机器人之间进行TCP通信。控制器分析来自机器人侧的传入消息,并相应地发送控制命令,例如当机器人偏离特定阈值位置时向机器人发送停止消息。网络元素位于控制器和机器人之间,用于转发机器人和控制器之间的流量。作者认为,将延迟关键的应用程序卸载到交换机上,通过将某些控制机制更接近机器人,可以减少延迟。对于上述用例,检测特定机器人位置并相应地向机器人发送停止移动命令是由BMv2实现的网络内计算。评估结果表明,与控制器发出的命令延迟相比,控制命令发出的延迟几乎可以忽略不计,顺序为纳秒级。
研究[86]、[88]提出了网络遥测和车辆收费计算的网络内查询处理。现有的流处理器遥测系统会产生大量带宽和处理成本,并且无法在每秒数亿次操作的规模上提供高效处理,这是现代网络的需求。使用现代流处理器支持这些要求将由于每个核的低处理能力而产生高成本。另一方面,仅依赖可编程交换机提供查询处理系统将因交换机处理能力的限制而牺牲表达能力。
Gupta等人[86]利用混合可编程交换机和流处理器来实现表达能力和可扩展性。作者提供了一个接口,用于表达各种常见遥测任务的查询。每个查询包括一系列数据流操作(例如过滤器、映射、归约和连接)。数据流操作被映射到数据平面中的匹配-动作表。一些操作,例如连接,在数据平面中实现成本较高,因此被分成一组子操作。在数据平面中决定执行每个子操作,最终将结果合并在流处理器中。为了决定分区,提出了一个规划器,它解决一个整数线性规划,最小化发送到流处理器的数据包数量,同时考虑交换机可用资源的约束条件。Teixeira等人[87]通过提供更多的功能来监视交换机内部的数据包处理来扩展[86]中的系统。网络内计算是在Barefoot Tofino中实现的查询操作。所提出的方法是一种协同设计方法,因为它将流处理器与交换机结合使用以处理查询操作。评估结果显示,与基准相比,流处理器的工作负载可以减少高达99%。
Jepsen等人[88]讨论了一种用于计算高速公路车辆收费的查询系统的实现。查询系统接收历史数据,例如车辆的位置和速度、对车辆征收的收费、两个高速公路路段之间的行驶时间等。定义了各种应用程序的查询和通知,例如向车辆发送收费通知、事故通知、查询向车辆征收的收费等。使用P4语言在交换机中实现了基准测试。定义了具有固定宽度字段的P4头,其中包括指定数据类型的字段,例如用于位置报告的数据或用于警报事故的数据。因此,根据数据类型,定义了表和控制流,指示在管道中处理数据包的方向。作者还提供了一些关于在P4中实现通用状态抽象的挑战的观点。网络内计算是在BMv2和Barefoot Tofino上实现的查询处理,并且代码可在线获取,但作者在论文中没有提供任何评估。
网络数据包携带着基本事件,例如传感器数据和管理数据如入侵检测系统或异常检测。通过评估传入的信息即基本事件,复杂事件处理(CEP)可以推断出更高级别的知识,即复杂事件。传统的CEP是在服务器或覆盖网络上执行的。然而,正如Kohler等人所建议的那样,通过利用网络内部计算进行CEP,可以避免数据流向远程服务器的绕道,从而减少通信延迟,优化带宽消耗。此外,网络硬件的高处理能力可以提供高效的CEP系统。作者表明,在P4中表达CEP操作是可行的。数据平面由一组互连的可编程网络处理元素和主机组成。主机托管基于事件的应用程序,可以是事件源或事件接收器。事件源观察基本事件并传播它们,而事件接收器接收并对复杂事件做出反应。网络处理元素实现非CEP数据包的转发,以及CEP功能,即窗口运算符和事件检测引擎。窗口运算符存储和聚合多个头字段的最后几个值。事件检测引擎基于状态机实现,检测复杂事件。作者还提出了一个将CEP操作编译为P4代码的工具。网络内部计算包括聚合函数和复杂事件检测,这在Netronome Agilio智能网卡和BMv2中均有实现。评估说明了在延迟和吞吐量方面,与BMv2相比,NIC的表现更为优越。对于由两个基本事件组成的复杂事件,NIC的检测延迟在10微秒至29微秒之间,吞吐量在16%至56%之间。
深度数据包检查(DPI)通过研究数据包的有效负载以发现作为正则表达式编写的模式。DPI可以使用专用设备(即中间件)部署,也可以在终端主机上作为软件实现。前者成本高昂且难以管理和更新,而后者会对通用计算机产生计算负担,并因服务器负载而导致性能波动。为了解决这些问题,Hypolite等人利用现有的网络处理硬件以实现DPI的线速率。所提出的方法利用Aho-Corasick算法编译正则表达式,并将其转换为确定性有限自动机,该自动机使用状态转移表实现。终止状态表示模式匹配,使用表将终止状态映射到匹配的模式集。所提出的方法提供了无状态内数据包和有状态间数据包的正则表达式匹配能力。网络内部计算是为了实现DPI而进行的正则表达式匹配,使用Netronome NFP-6000 SmartNIC实现。评估显示吞吐量增益高达20 Gbps。
D. 总结,比较,见解和经验教训
在本节中,我们首先简要总结了在网络内部分析范围内进行的研究,然后讨论了比较、见解和所学到的教训。
1. 总结
本节概述了在网络内部分析范围内所进行的研究。已经进行了几项研究,提出了网络内部数据聚合的方法[12],[29],[74],[75],[76],[77]。与基于主机的聚合相比,其中数据被传输到集中式主机以进行聚合,在网络内部进行数据聚合可以减少网络流量的数量和聚合时间。为了进行数据聚合,跨越网络构建了多层覆盖。然后,从多个源收集数据,并在网络元素上执行聚合函数,随着数据源发起的流量通过构建的覆盖层上升。研究人员为各种应用程序提出了数据聚合方法,包括高性能计算应用程序[29]、基于Map-Reduce的应用程序[12],[74]、物联网应用[75]和无线网络[76],[77]。根据应用程序的不同,定义了不同的聚合函数:HPC特定函数,例如Message Passing Interface标准中的集体操作[29],Map-Reduce特定函数[12],[74],物联网特定函数[12],无线网络特定函数,例如可分函数[74]。
与通常需要将流量转发到远程服务器或主机的常见机器学习技术不同,网络内部应用机器学习可以减少延迟和带宽消耗。一些研究已经专注于在网络元素中实现机器学习。[78]研究了在可编程交换机上实现各种分类方法,包括决策树、支持向量机、朴素贝叶斯以及K均值聚类。[79],[80]考虑了在网络元素中实现神经网络。[81]研究通过网络元素实现联邦学习。由于网络元素的内存和处理限制,一些简化技术已经应用,例如量化技术[79]和简化的神经网络模型[81]。
还进行了其他网络内部分析的研究。现有的重流量检测方法通常在软件定义网络范例的控制平面上实现。在网络元素中检测重流量可以减少决策制定中的开销和额外延迟。基于在数据平面中对每个流计数数据包的重流量检测机制已经在[59],[82],[83]中被考虑。[84],[85]的研究利用可编程数据平面进行控制目的。在[84]中,研究了利用交换机解析数据包,并在传感器/执行器控制网络中最终进行控制决策。[85]中将简单的机器人控制卸载到可编程交换机中。[86],[87],[88]考虑了查询处理的网络内部实现。最后,网络元素已被利用于复杂事件处理[89]和深度数据包检查[90]。
2.比较、见解和所学到的教训
表II、网络内分析的比较,DS(数据结构),SIMPL(简化),PLAT(平台)、Y(是)、N(否)、H(硬件)、S(软件)
表三:在网络中实现机器学习时应对硬件限制的技术比较

**表四:比较网络内分析、基于服务器/控制器的分析和共同设计方案**
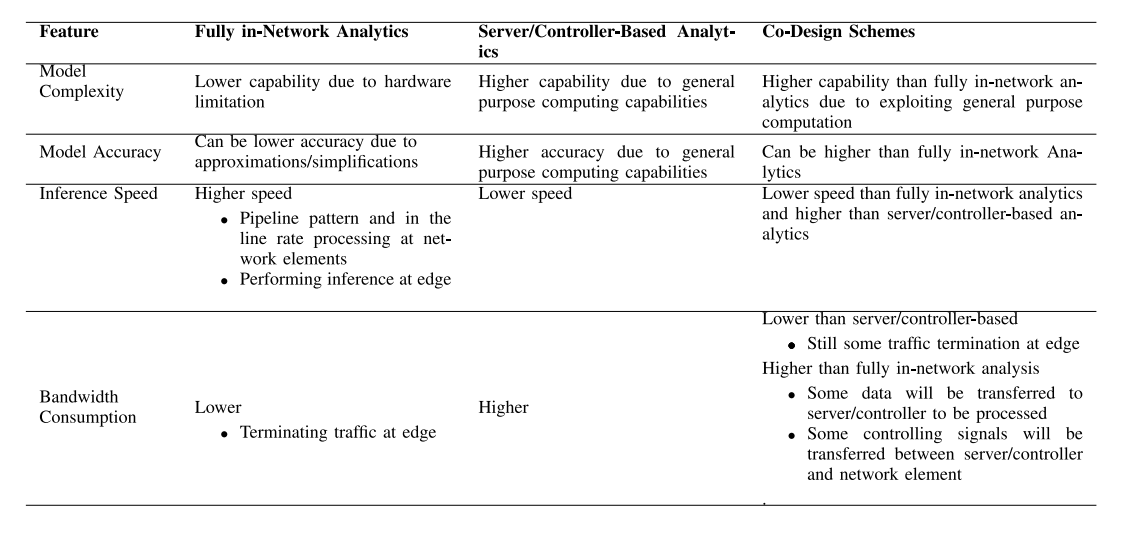
表II从贡献、方法论(网络内部计算、共同设计标准、方法中使用的网络元素的数据结构、方法中使用的简化技术)和评估(网络元素、仿真平台、主要结果)等方面比较了审查的研究。从表II中可以看出,文献中的研究要么完全在网络中实现所需的分析(共同设计为“N”),要么遵循共同设计方法(共同设计为“Y”),在此方法中,网络元素与服务器或控制器结合使用,提供所需的分析。
• 技术应对硬件限制的比较:表III比较了应对硬件限制的使用技术。在[79],[81]中提倡的量化技术通过在学习模型中应用简化,例如在神经网络中使用二进制权重或符号函数作为激活函数,从而促进推断计算。然而,通过量化,精度会因通过网络内部计算实现的推断速度而受到牺牲。另一方面,[78]中的预先计算技术预先计算所需的统计数据,例如朴素贝叶斯中基于高斯的似然计算,并在网络元素中填充所需的查找表。与量化技术相比,这种技术具有获取更高精度的潜力,并提供更精确的统计信息。作为另一种硬件限制,由于具有有限的流水线/阶段和匹配-动作表条目,还存在并行处理限制。数据包重新循环通过重新循环数据包通过网络元素以应用所需的处理来应对这种限制[79]。然而,这会增加延迟,可能在高循环轮次中导致线速率处理违规。根据[79],要在具有最多96个神经元并行能力的交换机上执行单层的4096个神经元,需要将数据包循环43次,这会延长延迟。
表IV从模型复杂度、模型精度、推断速度和带宽消耗等方面比较了完全在网络中实现的分析方法、基于服务器/控制器的分析方法(这是[79],[80],[84],[85]等研究中进行比较的基准),以及共同设计方案(参见表II中的共同设计方案)。
• 模型复杂度:由于硬件限制(例如有限的阶段/管道/逻辑单元数量、有限的匹配-动作表条目、寄存器和数据结构)以及缺乏类似浮点运算的通用计算能力(例如在可编程交换机/路由器中),完全在网络中实现的方法的能力比基于服务器/控制器的分析方法低。通过利用通用处理计算能力,共同设计方案可以促进完全在网络中实现的分析方法。例如,利用通用计算机预先计算似然概率,并将计算注入网络元素(在可用寄存器中),使得实现像Baysian和SVM这样的复杂学习模型成为可能[78]。另一个例子是,在流处理器服务器中处理复杂查询,同时在网络中卸载简单查询处理,正如[86]中所提倡的那样,可以实现复杂查询处理模型。
• 模型精度:与基于服务器/控制器的实现相比,完全在网络中实现的分析可能会导致较低的精度,因为在网络元素中实现目标分析可能需要进行简化和近似处理,例如在神经网络中使用二进制权重或符号激活函数,而不是更精确的激活函数,如sigmoid函数[81]。共同设计方法具有通过将复杂操作卸载到通用计算单元中而获得更高精度的潜力,与完全在网络中实现的方案相比。
• 推断速度:完全在网络中实现的分析方法具有在网络元素中与线速率相近的兼容管道模式处理到达的数据包的能力,并且可以在接近终端设备的位置进行处理。因此,与基于服务器/控制器的分析相比,预计推断速度更快。例如,在智能NIC中实现的单层神经网络中,[79]报道了推断延迟减少高达92%。共同设计方案具有与基于服务器/控制器的分析相比获得更高推断速度的潜力,因为仍然有一部分计算在网络中进行。
• 带宽消耗:完全在网络中实现的分析方法将节省带宽消耗,因为数据流量在边缘处终止,不需要传输到服务器或控制器。例如,在[74]中,对于一个map-reduce应用程序,节省带宽高达99%。共同设计方法仍在边缘处执行一些流量处理,因此其带宽消耗将低于基于服务器/控制器的方案。但是,带宽消耗可能比完全在网络中分析更高,因为某些数据仍将传输到服务器/控制器进行处理,或者某些控制信号将在服务器/控制器和网络元素之间传输。例如,在[81]的研究中,流量在云中的聚合器和在边缘节点中实现的网络内神经网络之间传输,以执行加权聚合以构建联合学习方法中的全局学习模型。要有一个有效的共同设计方案,需要进行优化决策,以便在服务器/控制器和网络元素之间最小化通信开销的情况下最优地分配计算。
还有一些见解可以从中吸取一些教训:
• 高键值体积的聚合:[12],[74]研究了基于键值数据结构的网络内数据聚合。然而,对于存在大量键(例如,在文本中出现大量单词的单词计数应用程序),没有建议任何数据聚合机制。这是关键的,因为网络元素的内存限制大小不能占据任意数量的键。一个得出的教训是需要更多的研究努力来为高键值提供聚合机制。
• 机器学习:另一个洞见是,只有四个研究探讨了网络元素上的机器学习实现,其中[79],[80],[81]考虑了神经网络实现,而只有[78]考虑了非神经网络的学习机制。然而,该研究假定用于学习过程中的数学函数的计算已经在设备内设置为查找表。一个得出的教训是需要更多的研究来在网络元素内实现非神经网络的学习方法。特别是,需要更多的研究来开发实现非神经网络学习方法中的数学函数的方法(例如朴素贝叶斯,SVM等)。另一个洞见是,即使神经网络方法进行了简化(例如在权重或激活函数中),为了在网络元素中实现学习,这可能会导致精度降低。需要更多的研究来追求在不使用简化技术的情况下实现神经网络的可行性。
• 共同设计:共同设计方法对于网络内分析尤为重要。原因是由于网络元素的处理和内存限制,不是所有函数或操作都可以在网络元素中实现。此外,并非所有操作或函数都可以映射到特定的网络转发架构,如匹配-动作表。那些在网络元素中无法实现的功能或操作仍可以保留在终端主机或控制器中。少数研究在分析应用程序中提供了共同设计方法。例如,[86]研究利用共同设计方法,在查询处理中利用流处理器实现复杂操作。我们可以得出的教训是需要更多的研究努力来提供网络内分析的共同设计方法。
IV. 网内缓存
在本节中,我们概述了在网络中进行缓存的现有研究。图2,第四节说明了本节的结构。我们首先概述了键值存储范围内的研究,其中高频键值对的缓存被卸载到网络元素中,以减少为基于键值存储的应用程序服务查询时的延迟。然后,我们概述了NDN作为ICN中的基本架构,我们发现它与网络内缓存兼容。其他ICN架构的全面调查可以在[68]中找到。
A. 键值存储
许多互联网服务的操作,包括搜索服务、社交网络和电子商务,都依赖于高性能的键值存储。为了在数据中心能够响应海量请求,需要扩展存储服务器,这会增加功耗。此外,基于键值存储的服务通常对端到端延迟非常敏感。利用网络内计算有潜力显著提高键值存储系统的性能。在网络元素中缓存内容可以节省在网络中的数据遍历,减少延迟,并且非常适合处理同一信息的频繁请求。[91],[92],[93],[94],[95]的研究提倡采用分层缓存系统,在高级别和接近网络边缘的位置,网络内缓存操作加速查询处理,而在低级别的缓存中,存储服务器操作。然而,这些研究在实现网络内缓存的网络元素(例如FPGA,可编程交换机)以及缓存协议的详细信息方面存在差异。此外,在[96]中提出了一个具有可编程交换机的复制键值存储在数据平面上,并且在[92]中提出了一个带有网络内缓存的分布式共享内存系统。需要注意的是,上述研究都将存储数据和缓存功能作为网络内计算来执行。此外,它们都是共同设计方法,因为请求的数据是从网络元素或后端存储获取的。在本节的其余部分,我们将提供更多细节。
Tokusashi等人提出了一种分层的基于键值的缓存系统,其中高层存在基于FPGA的网络内缓存,低层存在一个memcached服务器[91]。作者采用了多核处理器方法进行查询处理。所提出的架构包括一个处理单元(PE)网络、多个PE、一个存储器网络和包括DRAM、SRAM和CAM的存储器。传入的查询被分散在PE元素之间,每个PE处理一部分查询。一旦查询被处理,PE就会访问存储器网络。存储器网络中存在三种类型的存储器:包含哈希表桶和数据存储块的DRAM;包含块信息的SRAM;以及作为查找表检索键值对的CAM。
当查询到达时,PE解析数据包以提取键,其哈希用作指向DRAM中地址的指针。如果DRAM中存在键,则会被视为命中。对于命中的SET命令,键值对会在DRAM中更新。对于带有新键的SET命令,PE根据存储在SRAM中的空闲描述符列表将其分配给块。对于命中的GET查询,会向客户端返回一个响应。但是,在缓存中未命中的情况下,请求将被转发到主机上的memcached服务器,并相应地更新缓存和DRAM中的键和值,以包括以后的使用。评估结果显示全线速吞吐量(最高可达13 Mquery/s),同时具有较低的延迟(1.1 µs)和比仅使用memcached服务器的情况下更高的功耗效率(提高了80%)。
Jin等人考虑了另一个分层缓存系统,其中在高层采用可编程的顶部交换机,在低层使用存储服务器[93]。作者提出了一种基于网络内计算的键值存储架构,用于在数据中心内平衡机架内所有存储服务器的负载。作者利用理论讨论,通过在顶部交换机中缓存特定数量的项目,可以执行存储服务器之间的负载平衡。为了在顶部交换机中启用缓存,他们提出了一种架构,包括顶部交换机、控制器和存储服务器。
该交换机提供了基于路径的键值项缓存,并支持使用标准L2/L3协议进行数据包路由。它具有键值缓存模块,用于存储最热门的项,以及统计元素,用于保持每个缓存项的查询频率,并检测未缓存项的热门查询。控制器通过接收交换机的统计报告更新缓存,并决定要插入(驱逐)哪些项到(从)缓存中。
读查询由交换机处理,而写查询则转发到存储服务器。对于读查询,当交换机中有缓存命中时,它会将缓存值插入数据包头。查询的统计频率元素也将在交换机中更新。当有缓存未命中时,查询将被转发到存储服务器进行处理,并回复给客户端。如果交换机检测到未命中的查询为热门查询,则会通知控制器,以便控制器决定缓存策略。使用Barefoot Tofino进行的评估表明,与基准相比,可以实现高达40%的延迟降低和最高10倍的吞吐量增加。
Liu等人提出了一种深层的网络内缓存结构,与仅使用顶部交换机的[93]不同[94]。所提出的网络内缓存结构为数据中心网络提供缓存原语。服务器机架通过包括顶部交换机和核心交换机在内的分层交换机连接。当数据包到达交换机时,数据包将被转发到网络加速器进行计算。网络加速器提取数据包有效载荷中的键/值对和命令,并执行相关操作。对于新的键/值对写入命令,加速器分配空间并将数据写入。如果命令是基于键读取值,则加速器将进行缓存查找。如果未命中,则网络加速器沿其原始路径转发请求。如果命中,则网络加速器构造响应并将其发送到交换机。作者讨论了多路径缓存和处理客户端、交换机或服务器故障的情况。作者通过Cavium XPliant交换机和OCTEON网络加速器原型验证了所提出的缓存结构。他们的原型将请求延迟降低了30%以上,并在集群配置中将吞吐量翻了一倍。
与[94]类似,[95]的研究也提供了一个多级网络内缓存结构,包括顶部交换机和缓存交换机。然而,在[94]中,网络内缓存结构中的负载平衡不能得到保证,而[95]则考虑了负载平衡。Liu等人[95]提出了一种网络内缓存架构,用于集群存储系统,在其中负载信息被利用来平衡网络内缓存结构中缓存交换机之间的查询负载。所提出的架构包括缓存控制器、缓存交换机、存储服务器和客户端库。(i)控制器决定缓存分区并在系统重新配置事件(包括机架/交换机插入和系统故障)下更新缓存分配。(ii)缓存交换机从控制器接收缓存分区和缓存热门键值对象。此外,基于附带机制的网络内遥测机制被实现在交换机中,以分发它们的负载信息,为查询分布在缓存之间提供指导。(iii)存储服务器托管键值存储。(iv)客户端库提供应用程序访问键值存储的功能。
根据所提出的架构,缓存对象的读查询由缓存交换机回复。另一方面,未缓存对象的读查询以及写查询被转发到存储服务器。缓存交换机的负载存储在顶部交换机的芯片内存中,并相应地提出了一种考虑交换机负载的路由机制。作者还提供了缓存一致性机制以及处理控制器/链路/交换机故障的机制。评估结果显示,与未执行缓存的情况相比,吞吐量最高提高了8.5倍。
Jin等人[96]提出了一种复制的键值存储架构,包括数据平面和控制平面。(i)数据平面构建了一个经过复制的网络内键值存储,并管理读/写查询。使用基于哈希的机制将键值存储分布在数据平面中的多个交换机上。当交换机收到带有读/写操作的数据包时,它执行所需的操作并更新目标IP,要么是到下一个链节点(例如,未命中发生),要么是到客户端IP(例如,命中发生)。为了解决数据包乱序到达的问题,序列号被用来序列化写查询。(ii)控制平面管理交换机表和寄存器,以及由于交换机故障而进行的系统重新配置。交换机故障分为快速故障转移和故障恢复两个步骤。在快速故障转移中,控制器重新配置网络以继续使用剩余的交换机节点提供查询服务。在故障恢复中,控制器将修复后的交换机添加为新的复制节点。由于故障恢复需要将状态复制到新的副本中,所以它需要比快速故障转移更长的时间。评估结果显示,与像Zookeeper这样的基于服务器的解决方案相比,吞吐量最高提高了105倍。
Wang等人[92]提出了一种具有网络内缓存和缓存一致性管理的机架级分布式共享内存系统。整个架构由一组内存节点、一个顶部交换机和一个影子节点组成。(i)每个内存节点都包括一个全局内存来存储块。此外,它还有一个应用程序线程组件,用于执行应用程序逻辑并通过写/读接口访问全局内存。它还有缓存代理组件,用于在内存中传输缓存数据。(ii)除了使用标准的L2/L3协议路由正常数据包外,交换机负责存储热块,并执行缓存一致性协议的部分,包括请求的序列化和多播。具体而言,它管理访问共享数据的锁。(iii)影子节点帮助在交换机和内存节点之间迁移缓存块的所有权。评估结果显示,在键值存储、图引擎和事务处理工作负载上,分别比分布式共享内存实现高出4.2倍、2.3倍和2倍的吞吐量加速。
B. 以信息为中心的缓存
从以主机为中心的通信模型向基于访问信息的兴趣模型的互联网使用的演变,引入了信息中心网络(ICN)的概念。根据ICN,信息是通过命名机制请求的,并且可以从网络中的节点检索,而不考虑它们的物理位置。尽管该概念早于网络内计算引入,但我们看到ICN架构与网络内缓存一致。特别地,命名数据网络(NDN,也称为内容中心网络)的基本架构引入了提供内容存储以在网络中缓存信息的内容路由器。在这里,我们提供关于NDN的概述,作为ICN中的基本架构,我们认为它与网络内缓存兼容。我们建议有兴趣的读者参考[68],了解信息中心网络架构的全面调查。
在NDN [97]中,订阅者通过INTEREST消息请求信息对象,回复将是一些DATA消息。消息由存储三个数据结构的内容路由器(CR)转发:(i) 转发信息库(FIB)将信息名称映射到输出接口,以便转发INTEREST消息,(ii) 挂起的兴趣表(PIT)用于存储正在等待DATA消息的INTEREST消息,(iii) 内容存储(CS)用于缓存已通过CR传递的信息对象。
当INTEREST消息到达CR时,将在CS中查找名称与请求前缀匹配的信息对象。如果发生命中,结果将通过DATA消息通过输入接口发送回去。否则,将在FIB中执行匹配,以确定消息转发的输出接口。然后,INTEREST的输入接口将存储在PIT中,并将INTEREST转发到由FIB确定的CR。
当DATA消息到达CR时,信息对象将存储在CS中,并在PIT中执行匹配,以查找通过哪些接口转发DATA消息。
C. 总结,比较,见解和经验教训
在本节中,我们首先简要总结了在网络内缓存范围内进行的研究,然后讨论比较、见解和所学到的教训。
1.总结
本节概述了在网络内缓存范围内进行的研究。在这类研究中,网络内计算是缓存键-值或内容,并处理到达网络元素的查询。所有调查的网络内缓存方法都被视为协同设计方法,因为缓存服务是通过网络内缓存结构和后端存储服务器的联合提供的。
键值存储在数据中心中的部署,对于响应查询会出现高延迟。网络内缓存可以避免在网络中遍历数据,减少延迟并增加吞吐量。[91],[92],[93],[94],[95]中的研究构建了一个网络内缓存结构,用于处理查询,位于存储服务器之上。虽然[91]开发了基于FPGA的网络内缓存结构,但[92],[93],[94],[95]则利用可编程交换机来实现网络内缓存结构。在[91],[92],[93]中,网络内缓存结构较浅,包括顶部交换机或FPGA,而在[94],[95]中较深,包括一组交换机的层次结构。一般来说,无论何时,查询请求命中网络内缓存结构,请求的值都将被返回。另一方面,未命中网络内缓存结构的请求将被转发到存储服务器。[91],[92],[93],[94],[95]中的研究在缓存协议的细节方面有所不同。此外,在键值存储类别中,[96]提出了在数据平面中使用可编程交换机的复制键值存储,[92]介绍了一种具有网络内缓存的分布式共享内存系统。
ICN的概念是通过命名机制直接请求信息或数据,并且可以从网络中的节点检索,而不考虑它们的物理位置,这似乎与网络内缓存一致。特别地,命名数据网络的基本架构在内容路由器处提供内容存储,以在网络中缓存信息。[68]提供了ICN架构的全面调查。
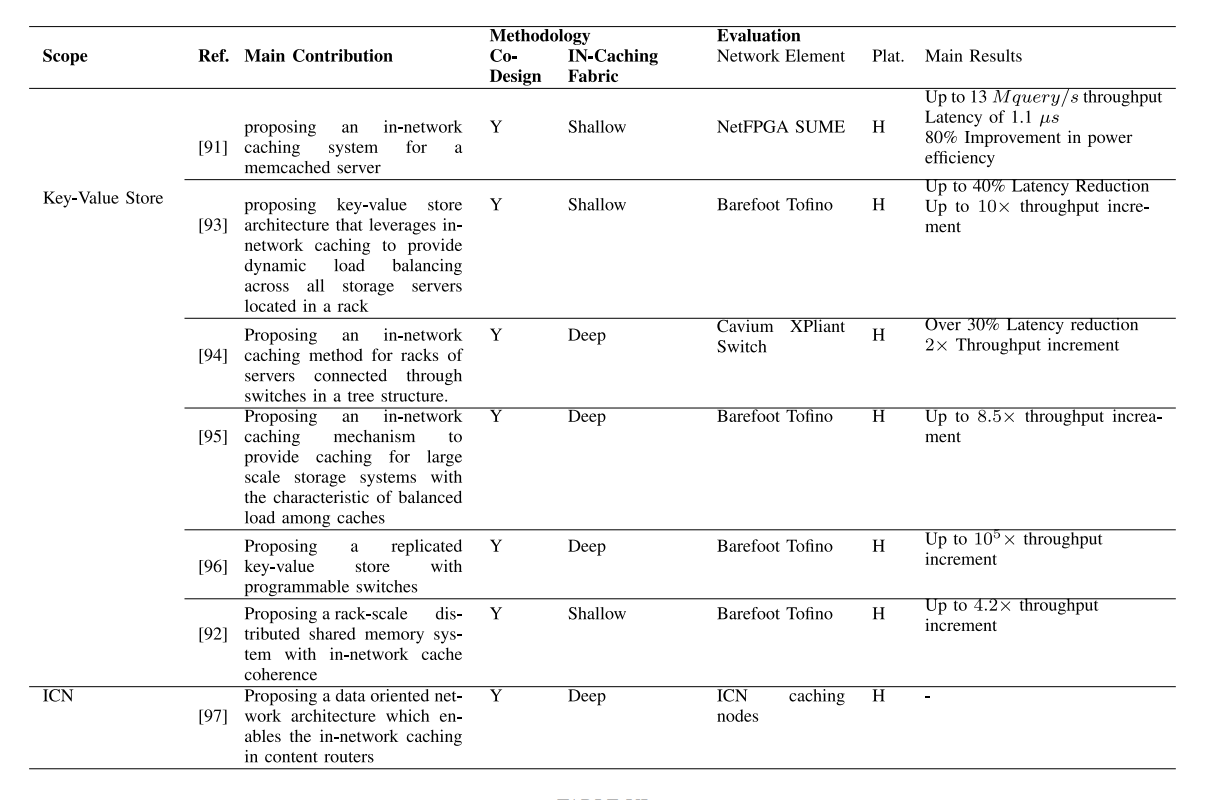
2. 比较、见解和所学到的教训
表v 网络内缓存研究的比较,这些研究执行存储数据和缓存功能作为网络内计算
表vi 浅/深网络缓存与基于服务器的缓存的比较

表VII 在实现网络内缓存时应对存储限制的技术比较

表V从贡献、方法(协同设计标准、网络内缓存结构)和评估(网络元素、模拟平台、主要结果)的方面比较了所审查的研究。从表V可以看出,文献中的研究要么提供浅层的网络内缓存结构,要么提供深层的网络内缓存结构。表VI比较了浅层和深层网络内缓存方案以及基于服务器的缓存方案,在这些方案中,云中的原始服务器或网络中的存储服务器存储内容。请注意,在许多研究中,例如[91],[94],[96],在云或存储服务器上进行缓存的情况是进行比较的基线。
• 缓存层次结构:浅层网络内缓存方案构建两个层次的层次结构,包括网络内缓存元素和原始服务器(也称为存储服务器)。深层网络内缓存方案构建了包括超过两个层次的层次结构:具有一组网络内缓存元素和原始服务器的网络内缓存结构的层次结构。另一方面,基于云的缓存方案提供一个缓存级别,即位于云中的原始服务器。
• 负载均衡:在基于服务器的缓存方案中,所有请求都将由缓存服务器回复,并且没有负载均衡的机会。相反,浅层网络内缓存方案提供了负载均衡的功能,因为请求将由网络内缓存元素或原始/存储服务器处理。另一方面,与浅层网络内缓存方案相比,例如[92],[93],深层网络内缓存方案,例如[94],[95],[96]将提高负载均衡,因为它们在网络内缓存结构之间以及在网络内缓存结构与原始/存储服务器之间提供了各种维度的负载均衡。
• 内容/项目访问延迟:深层网络内缓存方案提供了接近边缘的多个网络内缓存中的内容访问以及高度的负载均衡,可以为用户提供最低的体验延迟。另一方面,基于服务器的缓存方案只提供原始或存储服务器上的内容访问,并且不支持负载均衡,将由于远距离和核心网络拥塞而经历高延迟。[94]中报道了超过30%的延迟降低。因此,预计会提高吞吐量,例如[96]中报告了与基于服务器的键值存储解决方案相比,达到105倍的查询处理吞吐量提高。
• 边缘存储:浅层网络内缓存方案通过逻辑单元、匹配-动作表和寄存器(例如,可编程交换机中十几/几百兆字节的顺序)提供非常有限的存储。相反,深层网络内缓存方案将提供一个存储容量,该容量是在网络内缓存结构层中多个网络元素的存储容量的累积。基于服务器的缓存方案在边缘不提供存储。
• 带宽消耗:基于服务器的缓存方案由于通常位于云中的服务器的数据流而在下行链路上消耗相当多的带宽。相反,浅层网络内缓存方案通过在边缘提供内容来减少带宽消耗。深层网络内缓存方案可以通过在网络内缓存结构提供更多的存储容量来服务更多的请求,从而与浅层方案相比具有更高的带宽节省。
表VII比较了文献中应对实现网络内缓存中存储限制的技术。有两种技术:基于键值的缓存和利用深层网络内缓存结构。基于键值的缓存,例如[91],[92],[93],侧重于基于键值对的检索系统,该系统根据与匹配-动作表兼容的键值对的小尺寸来组织数据。优点是兼容性和内容/项目存储和检索的简单性,缺点是由于存储容量限制,例如TCAM和SDRAM大小限制,仅能在网络元素中存储少量的键值对。相反,深层网络内缓存结构技术利用网络内缓存结构中的多个网络元素(通常在文献中将缓存组织为层次结构)。例如[94],[95],[96]以及ICN等研究提倡这种技术。优点是网络内缓存的存储将扩展到缓存结构的容量。此外,通过利用织物中的多个网络元素来提高容错性。然而,缺点是需要更复杂的存储和检索算法。此外,还需要一致性机制来在网络内缓存之间保持读/写操作的数据一致性。
还有一些见解可以从中吸取一些教训:
• 缓存中的网络元素:在网络内缓存的范围内,大多数研究都使用可编程交换机ASIC实现了网络内缓存(参见表V)。[91]中采用了FPGA驱动的实现。然而,[91]中提出的方法不具有可扩展性,因为它仅为一个memcached服务器提供缓存结构。在实际系统中存在大量的服务器,考虑到FPGA的内存短缺,单个FPGA不足以为大量服务器提供负载均衡。这项工作的教训是需要更多的研究工作,以提供基于FPGA或NIC的网络内缓存结构。此外,还没有研究从性能标准(包括延迟和吞吐量)比较基于FPGA或NIC的网络内缓存结构与基于交换机可编程ASIC的网络内缓存结构。因此,我们学到的另一个教训是需要比较各种类型的网络内缓存结构的研究。
• 网络内缓存结构中的负载均衡:考虑到网络内缓存结构中的负载均衡对于确保整个缓存系统的性能非常重要,另一个洞见是网络内缓存结构中的负载均衡仅在[95]中讨论。在这项研究中,从网络内缓存结构中的交换机收集的负载遥测信息被查询路由用于确保缓存交换机之间的负载平衡。但是,交换机应用的网络内遥测机制具有通信开销,并且消耗负载信息分发的带宽。我们学到的教训是需要更多的研究工作以高效的方式提供网络内缓存结构中的负载均衡。
v.网内安全
本节中,我们提供了网络内安全研究的综述。图2,第V节说明了本节的结构。我们首先回顾了分布式拒绝服务(DDoS)攻击缓解的研究,然后是提供防火墙解决方案的研究,最后,我们概述了其他网络内安全应用。
A. DDoS攻击缓解
网络环境经常受到恶意攻击者控制的DDoS攻击的困扰。为了缓解DDoS攻击,使用洗刷服务来处理云中的攻击。但是,这种机制会导致流量重新路由,增加延迟并增加运营商的成本,以提供资源来处理攻击。此外,当在云中部署洗刷时,存在泄漏与用户相关的私人信息的风险。为了解决这些问题,基于网络的DDoS攻击缓解依靠网络元素分析数据包样本或流记录,以在网络中执行攻击检测和缓解。
多项研究提供了针对洪水攻击的缓解机制。这些包括SYN洪水攻击[61],[98],TCP洪水攻击[99]和链接洪水攻击[100]。SYN / DNS反欺骗是[60]的重点。[101],[102]的研究重点是容积DDoS攻击。[103]的研究介绍了一种用于AR-DDoS攻击的网络内防御架构。[104],[105],[106]提供了包括多种DDoS攻击的攻击缓解的更一般的视角。考虑流量来源,[107]考虑了源地址验证的主动方法,而[108],[109],[110]的研究则检测并丢弃欺骗流量。一些特定情况也已经被考虑。[111]的研究提供了一种安全的重复地址检测,以防止DoS攻击。最后,[112]的研究考虑了向下游提供DDoS保护服务的使用情况,例如大学和数据中心。上述研究将检测和/或缓解机制的一部分或全部卸载到网络元素中。以下是对这些研究的回顾。
DNS欺骗(DNS spoofing)是指攻击者通过篡改DNS服务器的缓存或响应数据,将用户访问的网址指向攻击者控制的恶意网站,以此来窃取用户的敏感信息或进行其他恶意行为。
1.洪水攻击
通常部署为SYN代理的SYN特定防御机制,使用SYN cookie或SYN身份验证来缓解SYN洪水攻击。Scholz等人[98]讨论了使用P4在数据平面上实施SYN cookie和SYN身份验证策略与基于内核绕过的软件包处理相比的优点。目标将解析数据包,并由匹配操作管道实现的L2转发规则转发。SYN cookie和SYN身份验证策略的计算,包括cookie计算和白名单设置,在目标上实现:(i)一些与cookie相关的功能,例如生成时间戳,加密哈希计算在P4目标中实现。(ii)作者讨论了两种实现白名单的选项:首先,数据平面通知控制平面需要列入白名单的流/ IP地址,控制平面将向表中插入一个条目;其次,利用布隆过滤器数据结构进行白名单设置。网络内计算,即SYN cookie和SYN身份验证策略在多个P4目标上实现:T4P4S [113],一种基于DPDK的P4软件目标,在商用现成硬件上运行;NFP-4000 Agilio SmartNIC NPU和NetFPGA SUME。评估显示,NetFPGA可以处理大约13 Mpps的SYN洪水攻击。
Lin等人[61]也考虑了SYN洪水攻击的缓解。在攻击中,大量带有虚假源IP地址的ACK数据包被发送到服务器,因此,服务器响应SYN/ACK数据包到原始源。但是,服务器没有收到相应的ACK / FIN数据包。根据所提出的方法,在距离服务器最近的交换机上计算SYN / ACK和ACK / FIN数据包的数量,计算出这些值的比例来确定攻击。在检测到异常后,恶意源IP的流量将被丢弃,并通知控制器。所提出的网络内攻击缓解降低了SDN控制器上的流量。此外,作者提出了一些合并机制,以合并转发表中的规则,以减少内存消耗的成本。网络内计算包括基于SYN / ACK和ACK / FIN数据包比例检测SYN洪水攻击以及丢弃恶意源IP的数据包,由BMv2实现。与控制器轮询交换机收集信息和执行检测的情况相比,所提出的网络内检测方法将流量量减少了高达4000字节/秒。
Musumeci等人[99]提出了一种基于机器学习的攻击检测机制,重点关注TCP洪水攻击。来自P4交换机的流量信息定期被收集并由洪水检测模块进行分析以检测攻击。分析是通过机器学习分类器进行的。考虑到收集信息的时间窗口,一些特征用于分类:时间窗口内的数据包平均大小;TCP数据包的百分比;UDP数据包的百分比;TCP / UDP比率;带有活动SYN标志的TCP数据包的百分比。作者还建议,可以将详细的流量特征从攻击检测模块卸载到P4交换机中。为了执行卸载,所提出的方法利用了P4语言启用的有状态数据平面的潜力,以在P4交换机内实现数据包镜像、头部镜像和元数据提取。网络内计算,即流量特征提取由BMv2实现。所提出的方法是一种协同设计方法,因为在非网络元素上实现的TCP洪水检测模块与网络元素协作以侦测TCP洪水攻击。使用SVM和随机森林进行的评估表明,检测准确率超过98%。此外,P4交换机可以在大约110微秒内提取特征,而服务器端特征提取模块需要大约15秒的时间。
网络内实现链路洪水攻击缓解不仅可以在任何位置/时间检测可疑的流量,而且还省略了使用集中式控制器来部署新配置的必要性。应用这种集中式重新配置需要很长时间,这段时间攻击者可以利用来改变他们的策略。在这方面,Xing等人[100]提出了一种通过在交换机中实现一些增强器来检测和缓解网络中的链路洪水攻击的方法。在默认模式下,路由是根据控制器计算的最优策略进行的。但是,在检测到攻击时,警报会在网络中传播,并且攻击缓解增强器将在交换机中被激活。为了最小化对正常流量的干扰,攻击缓解增强器将重新路由恶意流,而正常流将仍然通过控制器确定的原始最优路径进行路由。网络内计算,即链路洪水攻击的检测和缓解由BMv2实现。评估表明,与集中式SDN控制器重新配置网络的情况相比,所提出的方法将正常用户流的吞吐量提高了80%。
Afek等人[60]针对DDoS攻击的SYN和DNS反欺骗进行了研究。使用OpenFlow和P4目标实现了两种不同的SYN反欺骗方法,即HTTP重定向和TCP重置,以及一种DNS反欺骗方法。主要方法是基于cookie的通信协议,即基于SYN-cookie的方法。在到达SYN数据包时,会发送一个包含生成的哈希cookie的ACK消息作为响应。只有当客户端回复正确的cookie时才会进行身份验证。将SYN-cookie方法转换为原始步骤,以便将每个原始步骤实现为SDN数据平面中的一个操作。通过利用数据平面,例如SYN cookie生成等一些身份验证任务可以在不与控制器通信的情况下完成。为了应对交换机中TCAM大小限制,作者提出了一种将所提出的解决方案的复杂性分布在多个交换机上的方法。基于SYN-cookie方法的原语实现的SYN和DNS反欺骗功能组成的网络内计算,使用Open vSwitch 2.3.1实现。评估表明,所提出的缓解方法可以成功地处理攻击速率高达206 Kpps的Http请求,并保持吞吐量高达278 Kpps。
[101]和[102]的研究重点是针对大规模的DDoS攻击,许多主机汇聚流量到一个或少数几个受害者。[101]考虑了攻击检测,而[102]提出了一种缓解方法。当攻击发生时,源IP地址和目标IP地址的分布会偏离合法模式。Lapolli等人[101]通过Shannon熵分析测量这种偏差。事实上,预计在攻击的情况下,源IP地址的熵会增加,目标IP地址的熵会减少。作者提出了一种基于P4实现的熵估计的异常检测方法。所提出的方法由以下三个步骤组成:(i)在观察窗口内连续到达的数据包中,估计IP地址的熵。(ii)在观察窗口结束时,根据最近熵值的中心趋势和离散度,建立合法流量的模型。(iii)计算攻击检测的阈值。根据这些阈值,将检测到攻击。基于Shannon熵估计、合法流量的统计特性计算和基于阈值的攻击检测的网络内计算由BMv2实现。评估结果表明,所提出的方法可以以98.2%的准确率和250毫秒的延迟检测到DDoS攻击。
利用[101]提出的基于熵的分析,Gonzalez等人[102]提出了一种网络内推迟机制来缓解大规模的DDoS攻击。所提出的机制将控制平面从关键路径中移除,以加速防御。在所提出的方法中,首先通过数据包源IP地址的熵分析检测攻击。然后,在检测到攻击后,受害者旁边的转发设备会向上游转发设备发出警报。因此,这些设备将过滤可疑流的数据包,如果它们也检测到攻击,它们将警报其上游转发设备。该过程将重复进行,以将恶意流量限制在其源附近。网络内计算,即检测和缓解大规模DDoS攻击由BMv2实现。已报道检测准确率高达94%,反应攻击的延迟为0.1毫秒(从攻击开始)。
2.Amplified Reflection DDoS Attack(AR-DDoS)
在AR-DDoS攻击中,攻击者利用UDP协议的无连接性向互联网上的服务器发送欺骗性请求,该服务器则响应受害者的放大回复。Khooi等人[103]提出了一种防御AR-DDoS攻击的架构,该架构不依赖于任何洗净服务器,同时提供更快的攻击检测和缓解。所提出的架构在ISP网络的边界(即对等侧)和接入侧(面向客户)部署有有状态可编程路由器,以跟踪给定协议中请求/响应的计数。使用count-Min Sketches实现请求/响应的计数跟踪。然后,提出了一种分布式协议,用于在边界和接入路由器中,基于计数值达成可能的攻击共识。最后,在每个边界路由器上开发了一个访问控制列表,用于指示被滥用的服务器的IP地址并禁止恶意流量。网络内计算包括通过BMv2实现的AR-DDoS攻击的检测和缓解。评估结果表明,所提出的方法能够以99.8%的准确率在数据平面中检测和识别攻击。
Amplified Reflection DDoS Attack (AR-DDoS)是一种利用UDP协议的无连接性和网络上的反射服务器,通过欺骗反射服务器向目标服务器发送具有伪造源IP地址的请求,以获取更大的响应,进而使目标服务器的带宽和计算资源受到攻击的一种DDoS攻击方式。攻击者通过欺骗反射服务器向目标服务器发送大量的UDP请求,由于反射服务器会响应请求,而响应的数据包大小通常比请求的数据包大小大得多,攻击者可以通过欺骗反射服务器获取更大的响应,从而放大攻击流量,对目标服务器造成压力。
3.流量源的安全性
[107]、[108]、[109]和[110]的研究考虑了流量源的安全性。[107]提倡主动的源地址验证策略,而[108]、[109]和[110]的研究则以反应性的方式检测和丢弃欺骗性流量。
基于标记的源地址验证解决方案存在一些缺点,包括不安全的密钥协商、对路由器的重加密算法和计算开销,以及使用非标准标头。为了克服这些问题,Yang等人[107]采用了一种安全密钥协商机制,该机制可以在可编程路由器中实现。所提出的方法结合了椭圆曲线Diffie-Hellman短暂密钥协商和资源公钥基础设施,以实现安全密钥协商并抵御中间人攻击。基于协商的密钥,作者设计了一种网络内标记生成算法,将源地址映射到伪随机标记。所提出的标记生成方法将标记插入适当的数据包头字段中,以保持与标准标头的兼容性。网络内计算,即标记生成是由商业P4交换机实现的。实验结果表明,所提出的方法通过过滤欺骗性数据包,可节省高达200 kbps的带宽。
Gondaliya等人[108]提倡在中间交换机上部署反欺骗机制,而不是在源节点或目标节点上部署。为了检测和丢弃伪造源IP地址的欺骗性数据包,作者详细解释并分析了几种基于P4的反欺骗机制的实现,包括:网络入口过滤、欺骗性预防方法、反向路径转发的变体和SAVI。作者解释了实现每种反欺骗机制的匹配-动作表。网络内计算,即反欺骗机制是在NetFPGA SUME硬件上实现的。根据评估结果,在数据包生成速率为8.5 Gbps,欺骗性数据包比例为12.5%的情况下,反欺骗机制的吞吐量约为7.5 Gbps。
类似于[108],[109]、[110]的作者也关注过滤欺骗性流量。作者提倡一种Hop Count Filtering(HCF)防御机制,该机制可以使用IP-to-Hop-Count(IP2HC)映射表过滤欺骗性IP流量。他们建议在可编程交换机内集成HCF机制,而不是将其应用于终端主机。这将早期识别欺骗性流量并节省网络带宽资源。所提出的架构包括两个数据平面和控制平面,分别称为缓存和镜像。数据平面服务于最活跃和合法的IP地址,而控制平面管理其余的IP地址,存储IP2HC映射表并更新系统状态以适应网络动态。数据平面运行三个模块:(i)一个IP2HC模块,用于验证数据包,(ii)一个TCP会话监视模块,用于跟踪合法的跳数并更新跳数值,(iii)一个统计模块,用于计算合法/欺骗性IP的统计信息。当数据包的跳数检查成功时,相应的统计信息将被更新,并将转发数据包。然而,当检查失败时,数据包将被丢弃,并增加欺骗性数据包计数器的值。欺骗性数据包计数器的值将定期报告给控制平面。
为了克服交换机的内存限制,控制平面保持流量的全局视图。它利用二叉树数据结构聚合IP地址的信息,并维护全局IP2HC映射表。此外,欺骗性数据包计数器用于计算数据包检查失败的数量,以用于调整系统状态。网络内计算由硬件Tofino交换机实现,包括IP2HC检查、TCP会话监视和计算合法/欺骗性IP命中的统计信息。所提出的方法是一种协同设计方法,因为控制平面在非网络元素上实现,处理一部分IP地址,维护全局IP2HC映射表,并在数据平面中执行所需的更新。对于跳数分布遵循高斯分布的欺骗性流量,所提出的方法可以防止欺骗性流量进入网络主机,并节省大约200 Mbps的带宽。
4. 一般的DDoS攻击的缓解
[104]、[105]、[106]提出了一种更为通用的攻击缓解视角,涵盖了多种DDoS攻击。Friday等人[104]在网络边缘使用可编程交换机,在流量进入网络内部设备之前对其进行分析。交换机可以在无需控制器干预的情况下进行流量分析。为了捕获过多的SYN请求和服务器连接的消耗,交换机实现了多种功能和统计信息:(i)在入口SYN数据包上进行一种签名匹配;(ii)使用Bloom过滤器计算签名计数;(iii)每个预定义时间窗口内的SYN请求数量;(iv)TCP连接的到达时间;(v)在不关闭已经存在的会话的情况下,在时间窗口内建立的最大连续会话数。一旦交换机数据平面收集到上述数据,控制器就会收集它们进行流量分布公式的制定,从而计算阈值。阈值将根据交换机发送,交换机将比较其统计信息,检测攻击并丢弃恶意流量。网络内计算包括统计计算(关于签名、SYN请求、TCP连接和会话建立)、攻击检测和丢弃恶意流量,这些都是由BMv2实现的。所提出的方法是一种协同设计方法,因为控制器估计流量分布并计算攻击检测的阈值。对于DDoS和体积型攻击,仅使用所提出的方法最多只有3.5%的客户端会遇到可以忽略的延迟。此外,对于SYN洪水攻击,检测延迟低于0.25秒。
另一种通用的DDoS攻击缓解方法在[105]中提出。基于语言NetCor [114],定义了三类防御原语:(i)监视器,收集网络流量的统计信息;(ii)动作,指定对特定类型的数据包采取的防御决策;(iii)分支,表达防御的控制流程。每个原语类别可以由多个原语组成。例如,对于动作原语,可以定义丢弃、通过、难题、记录等。然后,确定交换机和/或服务器上所需原语的资源量。根据分析结果,所提出的方法将原语所需的步骤划分为服务器和交换机之间,并决定在交换机中使用资源,例如匹配-动作表、寄存器。
作为下一步,为防御策略构建一个图结构,其中节点是防御原语,边表示流量的流动。根据原语的资源使用情况分析,将原语执行映射到交换机的阶段。考虑到SRAM和ALU的限制,将映射问题制定为整数线性规划优化,最大化在交换机中执行的计算。作者还讨论了所提出的方法如何在运行时处理动态攻击。网络内计算,即收集数据包统计信息和防御操作,是在Barefoot Tofino上实现的。所提出的方法是一种协同设计方法,因为使用了交换机和服务器来实现所需的原语。对SYN洪水、DNS放大以及HTTP和UDP洪水攻击进行的评估表明,可以快速恢复合法流量的吞吐量,并通过过滤攻击UDP数据包大约恢复20 Gbps的带宽。与需要数十微秒的中间盒和NFV系统相比,数据包可以在数百纳秒内处理。
与[104]、[105]相比,Liu等人[106]提出了一种更广泛的检测方法,涵盖了16种体积型DDoS攻击。此外,与[104]、[105]中的研究不同,[106]中的缓解模块将以按需方式由交换机应用,以优化硬件资源限制。在体积型攻击中,攻击者发送大量流量或请求数据包以耗尽受害者的带宽或资源。检测逻辑识别所有攻击,而缓解模块则按需安装以优化硬件资源使用。所提出的方法基于通用草图运作,这使得使用单个算法跟踪广泛的指标成为可能。作者考虑了三个组成部分来实现缓解:(i)过滤数据包,(ii)分析以识别恶意流量,以及(iii)更新过滤。针对每个组成部分,使用经过交换机优化的逻辑设计了缓解函数库。当攻击姿态改变时,使用近似最优的启发式方法计算新的资源分配,以将流量重定向到其他可用交换机,成本最小。网络内计算是基于通用草图的攻击检测和缓解技术,这些技术是在Barefoot Tofino上实现的。所提出的方法可以在保持吞吐量为380 Gbps的同时缓解攻击。
5. 特定的DDoS攻击缓解案例
重复地址检测在IPv6地址配置中非常重要,因此同一子网中的所有节点都能够使用唯一的IPv6地址加入网络并进行通信。在重复地址检测中,节点发送一个或多个邻居请求(NS)消息,并在没有现有节点发送邻居广告(NA)消息时配置地址。在DoS攻击中,将会存在伪造的NA消息,从而无法配置IPv6地址。现有的解决方案要么需要修改协议,要么依赖于容易出现单点故障的中央控制器。为了克服这些问题,Kuang等人提出了一种在网络内安全地进行重复地址检测的方法。所提出的方法利用可编程交换机过滤伪造的NA消息,而无需中央控制节点或修改重复地址检测协议。通过网络内计算,即过滤伪造的NA消息,BMv2实现了这种方法。评估结果表明,所提出的方法可以成功地防止重复地址检测的DoS攻击,且开销可以忽略不计。通过网络内处理,NS/NA消息处理的延迟已降低了高达40%。
Dimolianis等人[112]假设为大学和数据中心提供DDoS保护服务的使用情况。在所提出的缓解方法中,P4设备从子网的流量监视中提取一些特征。根据这些特征,进行异常检测并向缓解系统提供适当的警报。定义了三个特征,并提倡基于阈值的异常检测:(i)每个时期总入流量的数量和分散性,采用移动平均方法计算;(ii)子网重要性,计算为特定子网在时期内的入流量百分比;(iii)数据包对称性,定义为在时期内对于一个子网的入站数据包与出站数据包的比例。该特征用于避免将一个接收大量良性流量的子网错误地检测为受害者。以上三个特征通过阈值进行比较以确定攻击检测。在实现中,利用P4寄存器实现所需的计数器、数组和概率数据结构。此外,所述特征的分析包括在网络元素管道中。在网络内计算方面,即流量特征分析和攻击检测是在Netronome Agilio CX SmartNIC(吞吐量1-2 Mbps)中实现的。
B. 防火墙
已经进行了一些研究,以提出网络内防火墙解决方案。Vörös和Kiss [115] 提供了一个第三层防火墙解决方案,Datta等人 [116] 给出了一个第三层和第四层防火墙解决方案。Vörös和Kiss [115] 在可编程路由器中实现了一个第三层防火墙。在所提出的方法中,违反安全规则或产生过多数据包速率的MAC地址和IP地址被添加到一个名为Ban List的列表中。路由器中的计数器用于测量度量标准以定义Ban List,例如每个主机生成的数据包速率,建立连接的尝试次数等。所提出的方法通过实现IPv6和UDP头将已定义的头扩展到路由器中,即以太网和IPv4头。在解析TCP/UDP数据包后,将研究数据包的字段是否在Ban List中。与Ban List匹配的数据包将被丢弃。在网络内计算方面,即第三层防火墙策略是在P4路由器中实现的。
Datta等人 [116] 提出了一个可配置的第三层和第四层防火墙,该防火墙开发成为软件交换机。作者引入了一个控制器,以实现防火墙的集中管理。高级安全策略作为输入提供给控制器,相应地控制器将安全规则发送到交换机。安全规则是基于P4数据平面中的转发表实现的。此外,控制器通过远程过程调用通道与交换机通信,以激活或停用防火墙。在网络内计算方面,即第三层和第四层防火墙策略是通过BMv2实现的。所提出的方法是一种协同设计方法,因为控制器向交换机注入安全规则,并对防火墙策略进行集中控制。
C. 其他安全应用程序
除了DDoS或防火墙之外,已经进行了许多研究,涉及网络内安全应用。在[117]中提出了基于随机森林的网络内攻击缓解方法。[62]提出了一种基于区块链的网络内攻击检测方法。[118],[119]的研究侧重于IP地址的隐私威胁。[120]考虑针对窃听的网络免疫性。[121]研究了网络隐蔽通道的缓解。Laraba等人[122]侧重于减轻明示拥塞通知(ECN)协议的滥用。[63],[64]关注Bring Your Own Device环境的安全性。
在[117]中,随机森林算法被嵌入到可编程交换机中以检测网络中的攻击。所提出的方法倡导在网络内计算,而不是将数据传输到中央位置以确定攻击发生的情况。考虑到交换机的内存限制,它们分析UNSW-NB15数据集[123]以选择一组重要特征,并选择要在交换机中实现的决策树数量。决策树的级别和决策逻辑在匹配操作阶段中实现。操作参数(例如比较阈值)由控制平面配置。作者还提供了一种估算某些特征(例如比特率和TCP往返时间)的机制,这些特征在学习过程中使用。最后,他们将嵌入在交换机中使用的随机森林算法中的多棵树进行了扩展。网络内计算,即随机森林是通过BMv2实现的。所提出的方法检测到超过94%的攻击。
Yazdinejad等人[62]提出了一种基于区块链的方法,用于在软件定义网络中检测攻击。为了支持区块链,定义了一种在交换机中进行数据包解析的架构,该架构能够提取区块链头字段。使用SDN控制器编写的函数,研究在交换机中到达的数据包的模式,以检测攻击。如果检测到攻击,则会执行交易以在SDN控制平面中进行验证。SDN控制器检查交易的有效性,并将验证结果返回给交换机。网络内计算,即攻击检测是通过ZedBoard Zynq FPGA实现的。所提出的方法是一种协同设计方法,因为验证步骤是由SDN控制器执行的。结果表明,对于各种攻击(例如DoS和探测),检测率在70%以上。
基于IP地址的Internet流量存在隐私威胁,通信用户和设备的信息可以通过IP地址泄露。遮蔽发送者和接收者的IP地址的现有方法要么在用户端安装软件(例如Tor浏览器),要么对网络硬件进行一些修改。为了克服这些问题,Datta等人[118]提出了一种网络内监视机制。所提出的方法在数据包进入中间自治系统之前加密数据包头中的IP地址,并在数据包退出中间自治系统时解密源IP地址和目标IP地址。所提出的方法还加密TCP序列和确认号以防止对手识别哪些数据包属于同一TCP流。网络内计算是IP地址的加密和解密。
与[118]类似,Chang等人[119]提出了一种基于加密的IP地址防御机制。所提出的方法假定发送者/接收者交换机是受信任的,而位于路径中间的交换机可能是恶意的。发送边界交换机对地址执行基于密码学的转换,并构建相应的数据头。其他不受信任的交换机根据SDN控制器发出的流表将数据包转发到接收交换机。在接收交换机处,解开数据包头中的协商参数,解密地址字段,并将普通IP数据包发送到目标主机。网络内计算,即IP地址的加密和解密是通过使用P4语言的BMv2实现的。使用所提出的方法,转发数据包的往返时间小于8毫秒。
Liu等人[120]提出了一种使用可编程数据平面来提高网络对窃听的免疫性的方法。所提出的方法由三个防御线组成。第一条线路是转发策略,在该策略下,流量包通过各种网络路径和协议(例如IPv4,IPv6)无序转发。第二条线路提供干扰,使窃听者无法适当地分类流量。它基于传输加密算法工作,其中流的流量包分布到多个流中。在第三个防御线路中,使用基于加密的对策加密数据包负载。在网络内计算中,即使用P4在BMv2中实现的上述防御线路。实验结果表明,所提出的方法可以使窃听变得困难,并将传输吞吐量相对于基线方法提高32%。
Xing等人[121]提出了一种云系统中网络隐蔽信道威胁的缓解算法。他们专注于两类网络隐蔽信道威胁,分别称为时间信道和存储信道。作为前者的一个例子,攻击者可以使用数据包间的延迟来在秘密消息中编码1或0。作为后者的一个例子,攻击者可以将秘密数据嵌入TCP序列号或ACK字段中。作者将尽可能多的原语转移到数据平面作为快速路径防御,并在交换机控制平面上执行慢速路径防御,该平面拥有强大的通用CPU和RAM。
快速路径由三个组件组成:(i)连接监控,它执行TCP监视并将它们存储为键值;(ii)数据包间延迟特征,它基于比较接收到的数据包的时间戳和来自同一流的上一次看到数据包的时间戳来近似数据包间延迟分布;(iii)存储信道防御,它采用一组防御技术来操作数据包内的某些数据,以防御攻击。慢速路径防御还有三个模块用于信道防御:(i)统计数据包间延迟测试,它查询所选连接的数据包间延迟间隔,并对时间信道检测执行统计测试;(ii)时间信道防御,它向可疑连接的数据包注入随机延迟,以破坏时间调制;(iii)性能增强器,它可以增加TCP连接的性能,以减少由于防御而引起的性能降低的成本。网络内计算,即快速路径组件是在Tofino上实现的。所提出的缓解算法是一种协同设计方法,因为某些信道防御模块,即慢速路径,是在通用CPU上实现的。在实验中,在时间信道设置中,服务器向客户端发送文件,而在存储信道设置中,客户端正在向服务器上传文件。所提出的方法适用于服务器防御。所提出的方法在存储攻击的数据传输时间为33秒(相对于无防御增加了0.3%)。对于时间信道,所提出的防御方法需要60秒(相对于无防御增加了3%)。
ECN是一种位于IP和TCP层之间的协议,由网络交换机用于根据交换机队列占用情况指示可能的拥塞。恶意的TCP终端可以操纵ECN位,使发送方产生网络中没有拥塞的幻觉。Laraba等人[122]提出了一种网络内ECN滥用缓解机制,可在网络中运行而无需修改TCP。首先,将协议规范转换为扩展有限状态机(EFSM),并相应地将其扩展为不良行为状态。然后,EFSM转换为P4编写的程序,编译版本将安装在PISA目标交换机上。最后,基于EFSM,跟踪每个连接的状态,并在进入标记为不良行为的状态时,由程序触发预定义的操作,例如删除数据包,重新路由数据包,生成警报,应用纠正措施等。网络内计算包括基于EFSM跟踪流,ECN攻击检测和缓解,实现在BMv2中。评估表明,所提出的安全方法可以恢复由恶意TCP终端引起的25%吞吐量损失。
在企业允许员工在工作中使用其私人平板电脑,手机和笔记本电脑的BYOD环境中,安全性具有挑战性。在服务器端实施的安全方法可能不是很有效,因为它们没有访问客户端侧的上下文信息,而且它们在处理方面没有交换机快。[63],[64]的研究提出了一种基于上下文感知的网络内安全解决方案。作者提出了一种基于Pyretic Net-Core[114]的新语言来描述安全策略。在工作时间内阻止某些服务,基于距离的访问控制以及在管理员在线的情况下允许访问是这些策略的示例。在客户端安装一个模块,负责收集设备上下文信息并将其嵌入网络流量中。编译器将策略程序作为输入,并生成两个输出:(i)用于网络元素的配置文件,描述客户端模块应收集并嵌入数据包中的信息;(ii)用P4编写的交换机程序,部署在可编程交换机上以强制执行安全策略。最后,在SDN控制器中实现运行时模块,用于在交换机上配置P4程序,并与网络元素通信以部署上下文配置。这种集中控制仅用于策略部署或更改,这通常是不频繁的,而数据包处理决策直接在交换机上进行。网络内计算,即安全策略在BMv2和Wedge 100BF Tofino中实现。在以客户端 - 服务器为基础的通信场景中,所提出的方法可以针对单个安全上下文执行120万次检查。
D. 总结,比较,见解和经验教训
在本节中,我们首先简要总结了在网络内安全范围内所做的研究,然后讨论了其见解和经验教训。
表VIII是网络内DDOS攻击缓解的比较
表IX:网络内防火墙与其他安全应用程序的比较
表X :全网络内实现的安全方案、基于服务器/控制器的安全方案和协同设计方案的比较
1. 总结
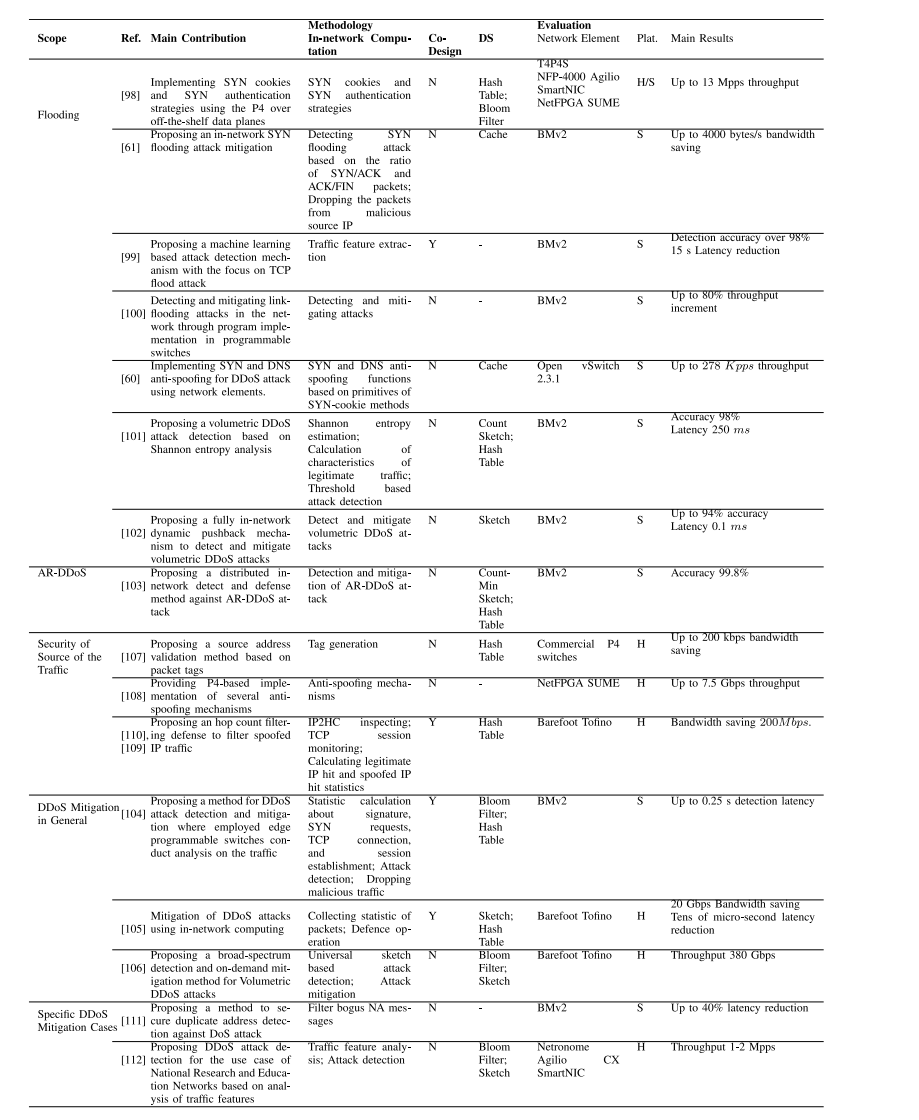
本部分概述了在网络安全范围内的研究。为了缓解DDoS攻击,需要将流量重定向到云中的清洗服务器,这会导致较高的延迟和操作成本。在网络中卸载部分或全部检测和缓解DDoS攻击所需的功能将减少延迟和操作成本。已经提出了几种网络内DDoS缓解方法。在[60],[61],[98],[99],[100],[101],[102]中研究了网络内洪水攻击缓解,包括SYN,TCP和链路洪水。通常,在洪水攻击中,一些检测原语,例如cookie计算,白名单估计,关于SYN / ACK数据包的统计信息,关于TCP / UDP数据包的统计信息,IP地址的熵分析,被离线处理到网络元素。此外,缓解原语,例如丢弃数据包,重定向可疑流,是在检测到攻击后由网络元素执行的操作。在[103]中考虑了AR-DDoS攻击缓解。考虑到流量来源的安全性,在[107]中研究将标记生成卸载到可编程路由器中进行源地址验证,而[108],[109],[110]中的研究则通过在网络元素中实现跳数过滤来过滤伪造的流量。在[104],[105],[106]中提出了包括多种DDoS攻击的攻击缓解的更一般的视角。这些研究将收集有关网络流量和连接的统计信息,关于攻击发生的决策(例如应用基于阈值的方法)或防御机制(例如根据特定控制流程丢弃或执行其他操作)卸载到网络元素中。还研究了其他特定的网络内DDoS攻击缓解情况,例如在[111]中进行的重复地址检测以及在[112]中为大学提供DDoS保护服务。
有几种网络内防火墙解决方案:[115]在第3层,[116]在第3层和第4层。通常,通过在TCAM中实现的规则定义机制或通过与禁止列表匹配,在网络元素中检测到恶意数据包。如果被识别为恶意,则数据包将被丢弃。除了DDoS或防火墙之外,还进行了几项网络内安全研究。
这些包括基于随机森林的攻击缓解[117],基于区块链的攻击检测[62],为IP地址减少隐私威胁[118],[119],对窃听进行网络免疫[120],缓解网络隐蔽通道威胁[121],缓解ECN协议滥用[122],以及Bring Your Own Device环境的安全性[63],[64]。在这些研究中,根据应用程序,执行检测原语(例如决策树,TCP连接统计计算,安全策略)以及缓解原语(例如对一部分数据包进行加密/解密,数据包丢弃)的网络元素被执行。
2. 比较、见解和经验教训
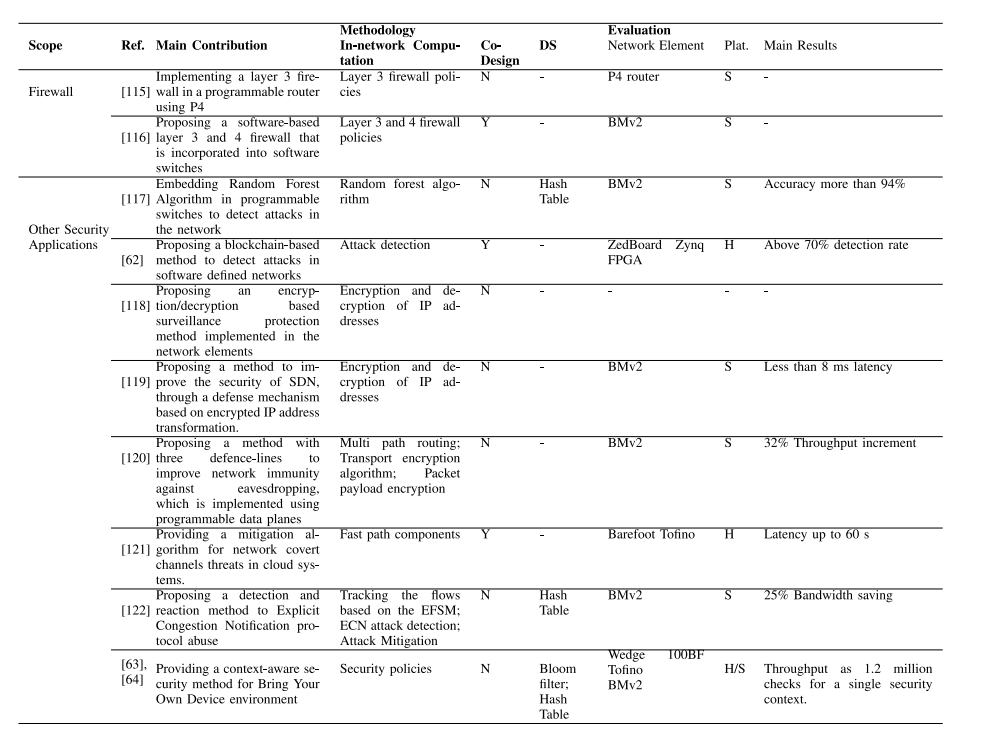
表VIII和IX从贡献、方法论(网络内计算、共同设计准则、方法中使用的网络元素的数据结构)和评估(网络元素、仿真平台、主要结果)等方面比较了被审查的研究。可以看出,这些研究要么完全在网络中实现安全机制(在共同设计条目中为“N”的研究),要么采用共同设计方法(在共同设计条目中为“Y”的研究),其中网络元素与服务器或控制器结合使用,提供所需的安全机制。
表X比较了完全在网络中的安全方案、基于服务器/控制器的安全方案(在许多研究中作为比较基准,例如[61]、[99]、[100]、[105])以及共同设计方案,从系统状态建模、检测模型、攻击检测精度、缓解延迟和带宽消耗等方面进行比较。
• 建模系统状态:完全在网络中的安全方法处理和分析到达网络元素的流量,因此具有系统的局部视图。相比之下,在基于服务器/控制器的方案中,从网络的各个节点生成的流量以集中的方式进行分析,因此具有全局视图的能力。类似地,共同设计方案可以利用通用计算来模拟具有全局视图的系统。
• 检测模型:在网络元素中实现检测模型存在硬件限制(例如,有限的阶段/管道/逻辑单元数量、有限的匹配-操作条目数量、寄存器、FPGA中逻辑单元之间的特定通信等)。因此,与基于服务器/控制器的方案相比,网络元素中可以实现更简单的模型。相比之下,复杂的检测模型(如深度神经网络)可以在SDN控制器或服务器中实现以检测攻击[124]。与完全在网络中的安全方案相比,共同设计方案将具有更高的能力来实现复杂的攻击检测模型,因为通用计算单元可用。例如,在[99]中,TCP/UDP数据包特征提取被卸载到P4交换机中,而SVM和随机森林学习模型被实现在传统服务器中以分析提取的特征并检测TCP洪水攻击。这与完全在网络中的方案不同,后者大多在网络元素中实现基于简单阈值的检测机制,例如[101]、[112]、[117]。
• 攻击检测精度:基于服务器/控制器的方案由于能够实现复杂的准确检测机制,并利用全局系统建模,因此可以实现最高的准确度。具有更简单的检测模型和局部系统视图能力的完全在网络中的安全方案可能会比基于服务器/控制器的方案具有更低的准确度。共同设计方案可以实现比完全在网络中的安全方案更准确的复杂攻击检测模型,并且由于利用了通用计算的潜力,可以具有全局系统建模的潜力,因此可以实现更高的准确度。例如,在[99]中,采用通用计算进行基于分类的TCP洪水攻击检测模块操作,除了通过网络内特征捕获程序,还报道了98%以上的检测准确度。
• 缓解延迟:完全在网络中的方案可以具有最低的攻击缓解延迟,因为网络元素可以以比控制器/服务器方案中使用的传统计算系统更高的吞吐量处理数据包。此外,由于可以在不将数据包传输到SDN控制器或清洗服务器的情况下检测到攻击,因此可以节省时间。因此,可以在数据平面触发缓解,而无需SDN控制器或清洗服务器的干预。例如,[111]中提出的方法可以在可编程交换机中缓解重复地址检测的DoS攻击,延迟降低了40%。共同设计方案在控制器/清洗服务器中执行一部分处理/决策(例如,[109]、[110]),可能需要控制信号/流量在控制器/清洗服务器和网络元素之间传输,因此与完全在网络中的安全方案相比可能会经历更多的延迟。
• 带宽消耗:完全在网络中的安全方法不需要将流量传输到清洗服务器或(SDN)控制器,因此与基于控制器/服务器的方法相比,可以节省带宽。例如,[107]中的源地址验证应用程序的实验结果显示,对伪造数据包进行网络过滤可以节省高达200 kbps的带宽。共同设计方法可能会比完全在网络中的安全方案消耗更多的带宽,因为服务器/控制器和网络元素之间的通信开销会增加。在[99]中,从数据平面中提取特征并传输到TCP洪水检测模块是网络元素和服务器之间通信开销的一个例子。
还有一些见解可以从中吸取一些教训:
• 攻击检测多样性:我们的文献综述发现,大多数研究提供了针对DDoS攻击的安全解决方案,特别是洪水攻击。但是,对于许多其他攻击,研究较少。例如,只有一项研究考虑了AR-DDoS攻击[103]或网络隐蔽信道威胁[121],只有两项研究提供了防火墙解决方案(即[115]、[116])。然而,对于重新路由流量到远程服务器以检测攻击会导致高延迟和操作成本的广泛攻击类型,可以通过网络内安全设备来解决。得出的教训是需要更多的研究努力,为除洪水攻击之外的攻击提供网络内安全解决方案,如AR-DDoS攻击缓解、防火墙解决方案和网络隐蔽信道威胁缓解等。
• 基于机器学习的攻击检测:另一个观点是,大多数研究在网络元素中执行基于简单阈值的检测机制,收集可编程网络元素中的统计数据与阈值进行比较,以确定是否发生攻击。尽管阈值检测的ALU要求足够简单,可在许多处理受限的网络元素中实现,但检测准确度可以通过应用更准确的检测机制来提高。机器学习技术可以获得更高的准确度。然而,只有[117]在网络中使用机器学习来检测攻击。得出的教训是需要更多的研究努力,将机器学习应用于网络元素中,以检测网络中的攻击。
• 共同设计安全方案:另一个观点是,少数研究(例如[104]、[109])采用共同设计的网络内安全方法,其中网络元素与服务器或SDN控制器一起用于检测和缓解攻击。共同设计方法可以实现更有效的攻击检测。虽然可编程网络元素是估计流量统计数据的良好候选者,但每个网络元素具有流量分布的局部视图,不能有效确定检测攻击发生所需的参数。例如,为了提高检测准确度,可以由服务器或SDN控制器基于流量的全局视图定义检测攻击所需的参数(例如阈值),而流量分析可以在网络元素中执行。我们得出的教训是需要在网络内共同设计安全领域进行更多研究。
VI.网内协调
分布式系统中的参与实体可能需要就某些数据值或操作序列达成一致,以进行计算或系统操作。这种协议可以通过执行共识协议来实现。然而,共识机制需要完成多个参与者之间的通信往返以达成一致,因此存在高延迟的问题。将实现共识算法所需的部分/全部功能卸载到网络元素中,将有可能减少延迟。除了共识协议外,文献中还有其他利用网络内计算加速协调的协调机制。本节中,我们概述了网络内协调领域的研究。图2、第VI节说明了本节的结构。
A.共识协议
Paxos共识协议的参与者可以扮演三种角色:提议者(proposers),向分布式系统提议一个数值;接受者(acceptors),选择一个数值;学习者(learners),学习接受者选择的数值。协议开始时,提议者提出数值,当学习者知道接受者选择的值时,协议结束。整个协议可以通过多次迭代来实现,在每个迭代中,消息在可以部署在服务器上的不同角色之间传递。
Paxos可以分为两个阶段。在第一阶段中,提议者选择一个回合号,并向一部分接受者发送准备请求。当接收到回合号比先前接收到的回合号更大的准备请求时,接受者通过回复承诺拒绝未来具有较小回合号的请求。但是,如果接受者已经接受了一个请求,则会返回接受的值和对应的回合号给提议者。当提议者从一部分接受者那里收到回复后,第二阶段开始。
第二阶段提供了一个过程,提议者通过该过程选择一个值。当提议者在回复中没有接收到值时,它将选择一个新值。另一方面,如果在第一阶段中接收到了一些值,则提议者将选择具有最高回合号的值。选择后,提议者将向相同部分的接受者发送一个接受请求,其中包括所选的值和关联的回合号。因此,接受者将确认接收并将接受的值发送给学习者,除非接受者已经确认了具有更高回合号的另一个请求。当部分接受者接受一个值时,就会达成共识。
共识协议中涉及的角色可以在网络交换机中实现,以减少消息在网络中的传输路径,从而降低达成共识所需的延迟。Dang等人在[125]、[126]中使用P4提出了Paxos协议第二阶段的网络内计算。在[127]中,作者描述了在网络中实现包括两个阶段的完整Paxos实现。网络内计算已在Tofino和NetFPGA SUME中实现。在[125]、[126]中,将共识协议的一部分卸载到网络中属于共同设计方法,而[127]中在网络中完全实现共识协议则不属于共同设计方法。他们提供了Paxos的开源实现,与数据中心中基于主机的共识相比,延迟至少可以提高3倍,吞吐量可以提高4个数量级。
在[128]中,作者定义了基于数据中心的有序不可靠多播(OUM)通信,根据该通信定义了NOPaxos作为复制协议。作者假设在顶部交换机和聚合交换机之间存在树状结构。在聚合交换机以上的更高级别通信由核心交换机提供。在OUM通信中,客户端向一组接收者发送消息。没有消息传递的保证,但是接收到的消息顺序有保证。为了实现这个目标,所有目标为特定OUM组的数据包将通过单个排序器发送,以便在路由到目标之前为每个数据包插入一个序列号。SDN控制器将组织转发规则,将消息路由到排序器和组成员。作者讨论了排序器的三种可能的实现方式:可编程网络交换机、网络处理器和端点主机。为了实现容错性,如果排序器失败或与OUM组成员断开连接,控制器将选择并配置一个新的排序器。基于OMU通信,作者提出了基于领导者协调的复制协议NOPaxos。即使排序是复制协议的一部分,所提出的方法仍是一种共同设计方法。排序器的网络内计算,即排序器在Cavium Octeon II CN68XX网络处理器上实现。评估结果表明,延迟低于200微秒,吞吐量高于50 Kops/s。
B.其他协调的应用程序
除了共识协议之外,文献中还存在其他的网络内协调应用。在[134]中,提出了一种锁管理系统。在[135]中,考虑到基于组播通信的协调机制,用于事务处理系统。在[136]中,提出了一种基于网络内共识的协调机制,用于维护数据中心的一致性。
在[134]中,Yu等人利用网络内计算提出了一种锁管理系统。客户端的请求被发送到锁定系统,该系统通过交换机和服务器的协调处理请求。具体而言,锁的管理分布在锁服务器之间。通过从目录服务获取信息,每个请求的目标IP将设置为负责所需锁的服务器IP。当请求到达交换机时,如果交换机持有请求的锁对象信息并且锁可用,交换机将为该请求授予锁。但是,如果锁不可用,则如果有足够的内存,请求将插入队列中。如果交换机不持有锁对象信息或内存不足,则请求将转发到由目标IP定义的锁服务器。作者还讨论了在同一轮时间内获取锁和数据的可能性,以减少往返时间。从实现的角度来看,寄存器数组被用于排队锁的请求,为锁定服务定义了特定的UDP端口。一个锁请求包含多个字段,包括动作类型(锁获取/释放)、锁ID、事务ID和客户端IP。此外,锁ID到关联寄存器数组的映射以及授予和释放锁的操作是通过匹配-动作表实现的。最后,作者将将分配锁给交换机的问题制定为一种类似于分数背包问题的优化问题,并在多项式时间内解决。网络内计算,即锁管理在Barefoot Tofino中实现。所提出的方法是一种协同设计方法,因为由于交换机的内存限制,锁服务器与交换机共同处理锁。所提出的方法将吞吐量提高了18倍,将延迟降低了20倍,相对于基准方案。
在[135]中,Li等人考虑了一个事务处理系统,其中客户端通过组成分片的分布式存储系统执行事务。作者利用网络内计算来协调事务,以提高性能。通过操纵IP和UDP头,所提出的协议引入了组播通信,其中消息被传输到多个具有排序保证的多播组。组播通信使用集中式序列器实现,当它失败时可以由SDN控制器替换。序列器本身可以通过多种方式实现,包括交换机设备、网络中间件和终端主机,作者认为将序列器实现在交换机中可以实现最高的性能。整个协议分为三层:(i)网络内并发控制层,该层在分片内和跨分片操作,并提供一致的事务排序,但不能保证消息传递的可靠性;(ii)独立事务层,负责操作的可靠性和原子性;(iii)一般事务层,通过构建使用独立元素的事务来提供事务的隔离性。网络内通信,即序列器是通过P4语言在Cavium Octeon CN6880网络处理器中实现的。该方法是协同设计,因为所需功能的一部分在网络中实现。评估结果在标准基准测试中实现了高达35倍的吞吐量和高达80%的低延迟,相对于传统设计。
C. 总结,比较,见解和经验教训
在本节中,我们首先简要总结了在网络内协调的范围内所做的研究,然后讨论了其见解和经验教训。
表XI:网络内协调研究的比较
1.总结
本节概述了在网络协调范围内进行的研究。文献中提出了多种共识协议。这些协议使参与者能够达成共识,即就系统操作所需的某个数据值或操作序列达成一致意见。将实现共识算法所需的部分/全部功能转移到网络中可以减少共识延迟。在这一研究领域中,Paxos协议的第二阶段[125],[126]已经在网络元素中实施,而该协议的完整实现已在[127]中提出。在[128]中提出的有序的不可靠多播通信中,通过使用可编程网络交换机实现了序列模块,该模块具有在将数据包转发到其目的地之前向每个数据包添加序列号的作用。Raft共识协议的一部分在[129]中被转移到可编程交换机中,而在[130]中对其进行了修改。在用于分布式SDN中的持久性和正确操作的提议协议中,拜占庭容错功能已被转移到可编程交换机中[131],[132],[133]。
文献中还有其他利用网络计算加速协调的协调机制。[134]中介绍了一个锁管理系统。[135]中提出了一种基于组播通信的协调机制,用于事务处理系统,其在可编程交换机中执行序列。最后,在[136]中,为了数据中心的一致性,提出了一种协调机制,利用网络计算进行广播。
2. 比较、见解和经验教训
表XI从贡献、方法论(网络计算、共同设计标准)和评估(网络元素、仿真平台、主要结果)等方面比较了审查的研究。总体见解是,大多数网络共识研究将所提议的协议的一部分功能转移到数据平面。在数据平面中完全实现共识协议具有比部分转移场景更高效的潜力,如[127]所示。我们得到的经验教训是,需要更多的研究努力,以提供在数据平面中完全实现的共识协议。
另一方面的见解是,只有三项研究,即[134],[135],[136],提出了除共识之外的协调机制。我们得到的经验教训是,需要更多的研究努力,利用网络计算为网络和分布式系统提供除共识协议以外的协调解决方案。
VII.特定技术的网络计算应用
本节中,我们研究云计算、边缘计算、4G/5G/6G和网络功能虚拟化中具有特定技术的网络计算应用。图2第VII节说明了本节的结构。
A.云计算
本节中,研究范围涵盖了云计算,其中提供了数据中心的负载均衡或资源分配解决方案。
1. 负载均衡
针对虚拟IP地址(VIP)服务的数据包可以与服务器池(DIP池)映射。网络计算可以消除基于软件的负载均衡器的需求,因此降低了用于负载均衡的服务器的高成本,以及软件实现中的高延迟和抖动。Miao等人[137]利用网络计算在数据中心提供了负载均衡器,通过在交换机中实现两个表(称为connTable和VIPTable)来实现。VIPTable定义了可以映射到VIP的DIP池。另一方面,connTable将每个TCP连接映射到一个DIP,即连接数据包将通过关联的DIP来接收所需的服务。考虑了两个主要挑战:(i) 为了在有限的SRAM中存储大量连接,存储连接键的哈希摘要而不是实际的连接键。此外,存储DIP池版本而不是实际的DIP;(ii)作者描述了DIP池可能在连接的生命周期内通过添加或删除服务器来更新的现象。他们将每个连接的一致性定义为特定连接的所有数据包在连接的生命周期内与同一个DIP相关联的要求。使用布隆过滤器来跟踪连接到达,并相应地实现用于连接的一致DIP映射机制。网络计算即负载均衡在P4交换机中实现。所提出的方法可以在线速率下平衡一千万个连接的负载。
Ye等人[138]提出了一种数据中心的多路径负载平衡方法。他们考虑了P4交换机之间的树状连接结构(可能具有多个根),每个交换机都有一张表来保持到叶交换机的所有路径的利用率。在所提出的方法中,每个交换机都知道其端口的链路带宽,因此可以将利用率估计为传输速率与带宽的比率。根据所提出的方法,流量以flowlets的粒度处理。当数据包到达交换机时,通过比较当前和先前时间戳来计算到达时间间隔。如果大于阈值,则将数据包视为新的flowlet。然后使用加权利用率表来选择flowlet的新路径。检测flowlet,估计路径利用率和数据包路由的网络计算在BMv2中实现。对于基于客户端-服务器的请求和叶、脊、核的拓扑结构,所提出的方法将流完成时间缩短了2%。
[139] 提出了一种用于数据中心中延迟敏感的远程过程调用(RPC)调用的传输协议。所提出的协议是一个请求/响应导向的协议,不保存跨请求的状态,其中由客户端发起一些参数(例如源IP地址、UDP端口和RPC序列号)来标识请求。请求的目标与处理请求的服务器解耦,从而放宽了点对点RPC通信的语义。路由器根据负载平衡策略识别合适的目标服务器并将消息传递给它。为了减少路由器处理瓶颈,路由器仅决定请求的第一个数据包,而其余数据包则传输到同一服务器。服务器向路由器发送空闲和可用状态的反馈消息,用于负载平衡决策。作者在软件路由器上实现了随机、轮询、JSQ和加入有界最短队列(JBSQ)负载平衡策略,而对于Tofino数据平面仅实现了JBSQ,因为更简单。与基准方法相比,16台工作机群集上Web索引搜索的延迟提高了5.7倍。与基准方法相比,具有主/从复制的4节点集群上的键值存储请求吞吐量提高了4.8倍以上。
与[137]、[138]、[139]强调在网络元件中完全实现负载均衡不同,Gandhi等人[140]利用网络计算和软件实现的组合来为数据中心提供更灵活的负载均衡。基于软件的负载均衡器有两个限制:处理数据包的容量限制和高可变延迟。为了应对这些限制,作者利用数据中心中已经存在的可编程交换机来部署可伸缩、高性能的负载均衡器。他们利用交换机中未使用的ECMP和隧道表项来执行流量分流和数据包封装。实际上,将虚拟IP地址映射到直接IP地址的数据库存储在交换机中以实现负载均衡。由于负载平衡功能,即流量分发和封装在数据平面中管理,因此它可以具有低延迟/成本,同时具有高容量。另一方面,交换机故障的管理具有挑战性,因此与基于软件的负载均衡器相比,将会有一些灵活性上的妥协。为了克服这个限制,作者利用交换机和软件负载均衡器的组合。交通主要由交换机管理,而软件负载均衡器则扮演备份的角色,以增强灵活性。作者还提出了一种贪婪算法,以决定在交换机之间划分映射,以克服交换机内存限制。网络计算,即流量分流和数据包封装,是在基于仿真的交换机中实现的。所提出的方法是一种协同设计方法,因为它利用了软件实现的负载均衡器和可编程交换机的组合来执行负载均衡。结果表明,所提出的方法提供的容量比纯软件负载均衡器高10倍,成本只是软件负载均衡器的一小部分,同时还将延迟降低了10倍或更多。
2.基于INC的云资源分配研究
这类研究提供了一些在增强网络计算的云计算环境中的云资源分配解决方案。Tokusashi等人[27]提出了一种在线资源分配方案,该方案可以动态地将应用程序的计算任务从数据中心的服务器和网络之间进行转移。为了决定是否进行网络计算,提出了两种类型的控制器:网络控制和主机控制。在网络控制中,当应用程序交换的平均消息数量偏离预定义的阈值时,工作负载将由网络处理。在主机控制中,当应用程序的功耗或CPU使用率超过阈值时,控制器将工作负载转移至网络。网络计算,即应用程序的执行,是通过NETFPGA和Tofino实现的。所提出的方法是一种协同设计方法,因为它利用了数据中心服务器和网络元素的组合来服务应用程序。实验表明,使用FPGA可以将商用CPU上的软件系统的功耗提高100倍,使用ASIC实现可以提高1000倍。
Blöcher等人[28]提出了一种在数据中心服务器和网络资源环境下的资源分配方案。租户使用一些预定义的API描述其应用程序,并将其提交为复合有向图形式。复合集合通过复合存储库中的一些模板来定义。每个复合可以是聚合、负载均衡、缓存、数据库功能等功能,可以由网络计算节点和数据中心服务器的组合来执行。租户还定义了所需的网络计算节点或服务器的特性,例如服务器的CPU核心数和RAM大小,以及网络计算节点的编程版本和吞吐量。一旦应用程序被提交,它就会被转换为多态资源请求,即服务器和网络任务组成的图形。多态资源请求的资源分配被建模为优化问题,其目标是在尊重服务器和网络计算资源限制的同时,为最大数量的请求分配资源。提出了启发式方法来解决这个优化问题。所提出的方法是一种协同设计方法,因为它利用了数据中心服务器和网络元素的组合来服务应用程序。使用一个4000台机器集群的工作负载跟踪实验表明,可以将网络绕行减少20%,放置延迟减少50%。
Wu和Madhyastha [141]考虑了一个情况,在这种情况下,第三方即插件提供商可以通过公开新服务的API来增强云提供商的能力。在这种多提供商环境中,可以将P4程序安装在网络交换机中,以决定将数据包转发到适当的目标,该目标可以是插件VM或云服务,根据由插件处理是否需要识别处理的过程。网络计算是在插件VM和云服务之间分发数据包。
B.边缘计算
本节概述了针对边缘计算技术的INC应用。首先,我们概述了将网络计算应用于边缘智能提供的研究。其次,我们概述了在基于INC的边缘计算中讨论资源分配/任务卸载方法的研究。我们已经看到,任务卸载方法是一种资源分配的一种形式,因为在任务卸载中也会对任务分配资源的决策进行一定的处理。第三,我们将讨论我们在边缘计算安全范围内发现的关于INC应用的安全机制。
1. 边缘智能
在边缘智能方面的研究中,[15]利用网络计算来执行涉及移动边缘计算的边缘智能服务中关键子任务,以加速整个智能/控制场景。另一方面,[69],[81]中的研究通过网络计算对联合学习过程进行优化。Mai等人[15]提出了一种丰富了网络计算的移动边缘架构,用于工业物联网,在该架构中,需要在边缘提供智能和控制的低延迟要求的关键子任务被卸载到网络元素中,而其余的子任务由移动边缘计算执行。在所提出的架构中,传感器/执行器与MEC服务器之间的连接是通过可编程网络元素提供的。考虑了两个用例:机器人运动控制和火灾检测。
对于机器人运动控制用例,动作被定义为一个乘法操作,即当前机器人状态向量和参数矩阵的乘积,其中参数矩阵是通过机器学习学习得到的。控制矩阵乘法需要较少的计算和存储容量,因此被卸载到可编程交换机中,而参数矩阵的学习过程则在MEC中执行更复杂的过程。由机器人传感器收集的状态数据被封装在UDP数据报中,并发送到解析传入数据包头以提取状态数据的网络元素。然后,进行乘法操作,结果将返回给机器人。同时,UDP数据包将被转发到MEC,以执行机器学习操作以更新参数矩阵,并相应地在网络元素中更新矩阵。
对于火灾检测用例,利用复杂事件处理(CEP)引擎根据传感器监测数据流检测潜在的火灾危险。通过一个工具,应用程序功能转换为一组“匹配-动作”,分析数据流以便于检测火灾。匹配操作将在可编程交换机中执行,而计算和存储密集型的规则学习过程则在MEC中执行。每当检测到复杂事件(如火灾危险信号)时,交换机将发送报警信息。每当CEP引擎接收到连续的温度事件超过预定义阈值时,匹配就会发生。网络计算,即轻量级的关键子任务(如机器人运动控制应用中的矩阵乘法)是在P4交换机中实现的。所提出的方法是一种协同设计方法,因为它利用了MEC服务器来执行像学习这样的复杂任务。评估结果表明,复杂事件可以成功被检测到。
Qin等人[81]提出了一种联合学习方法,用于由一个中央云和多个边缘网络域组成的系统。对于每个域,有一个网关节点负责:(i)将该域的设备的数据包转发到/从中转站,(ii)基于神经网络的二进制分类。网关从传入数据包的头部提取比特,并将其作为输入提供给神经网络进行分类。在网关执行神经网络分类的同时,在本地更新之后进行聚合。网络计算是使用BMv2实现的神经网络。由于云端参与聚合,所以提出的方法是一种协同设计方法。对于恶意软件流量检测的用例,评估显示,与没有联合学习的情况相比,联合学习提高了近20%的检测精度(精度约为95%)。
服务中心网络、软件定义网络以及边缘智能的进展已经影响了未来的网络。李等人[69]共同考虑了这些技术,提出了网络智能的概念。作者解释了一种内容/计算/上下文感知的服务中心网络协议采用版本,在该协议中,软件定义网络中的节点可以宣布对于特定上下文的内容和/或计算的兴趣,并由能够为所请求的上下文提供内容/计算的节点提供服务。所提出的协议使边缘节点之间能够进行网络计算。作者将联合学习作为边缘智能的应用重点,其中聚合器和位于网络边缘的多个工作节点执行联合学习。作者定义了一个场景,在该场景中,用于在特定数据上执行本地训练的工作节点可以向其他节点发送其对数据内容的兴趣,如果这些节点具有数据,则可以通过网络计算直接进行本地训练。这种通过网络计算进行训练的卸载可以减少通信开销。网络计算是缓存和模型训练,这些都是使用Open vSwitch实现的。然而,评估受到限制。对于一个具有四个交换机和一个用户的小型网络拓扑结构,在基于卷积神经网络的图像分类应用中进行联合学习时,作者只报告了网络中的流量率,并未对学习进行任何比较。
2. 具有INC增强的边缘计算环境中的资源分配/任务卸载

图8。使用FPGA加速计算器[144]增强了边缘的计算
这类研究提供了在增强了网络计算的边缘计算环境中的资源分配或任务卸载解决方案。虽然[58]、[142]、[143]使用优化方法解决了资源分配问题,但[144]提供了一种具有任务卸载功能的架构,用于将任务卸载到增强了FPGA加速器的边缘处理器。Ali等人[58]专注于像户外摇滚音乐会和体育赛事这样的用例,这些场合建设有线网络并不划算。作者设计和实现了在无线网状网络上提供所需服务的架构,其中微服务在半永久无线网状设备上实现。实际上,网状网络元素,例如网状继电器节点、网状路由器等,主要用于路由数据包,并作为进行网络计算的雾节点以提供微服务。所提出的架构包括IoT、fog和应用三层,以及一个fog控制器。IoT层中的设备生成数据,而fog层中提供API以将微服务放置在无线fog节点上以进行计算。此外,网络信息,包括fog节点的内存/存储/CPU利用率以及链路负载和数据包丢失的信息,被用于决定应该执行计算的fog节点。应用层中使用已构建容器的存储库,以提供按需容器来安装fog节点中的微服务。fog控制器控制着雾节点、IoT设备和微服务之间的通信。此外,雾控制器通过最小化响应时间的算法执行微服务托管的雾节点的选择。网络计算,即微服务执行,是在网状网络元素上实现的。对于端到端的消息传递场景,所提出方法的延迟对于小于650个节点的fog网络而言不到6毫秒。
Lia等人[142]提出了一种资源分配解决方案,用于边缘计算领域,在该领域中,使用SDN启用的节点执行给定的输入任务。将计算任务在SDN启用的节点上的安置被建模为一个整数线性规划问题,其目标是最小化网络使用量,同时遵守预定义的任务延迟约束。通过CPLEX优化工具找到了最优解。网络计算是由SDN启用的节点执行的任务执行。仿真结果表明,在延迟约束高达100毫秒的情况下,与基于云的计算方法相比,任务卸载到云端的比例降低了99%,交换的数据量降低了10倍。
Cooke和Fahmy [143]考虑了一个分布式和混合的计算环境,包括分布在各个层中的计算节点,包括网络的边缘层、中间层(例如网关和路由器)以及云数据中心。节点具有软件和硬件加速实现的能力。将计算节点的实现决策和节点分配给任务的问题建模为优化问题。针对物体跟踪用例(通过相机),他们评估了将任务分布到各种实现方案的性能指标,包括延迟、吞吐量、能量消耗以及成本。各种情况在各个层上应用了网络计算。网络计算是由FPGA加速器实现的任务执行。所提出的方法是协同设计的,因为任务由软件(在通用计算节点上)和硬件加速资源执行。针对上述用例,添加FPGA加速器获得了0.8秒的延迟,133个相机帧每秒的吞吐量和1.56(能量单位)的能量,而在云处理中实现则获得了1.9秒、3.4个相机帧每秒和30的延迟、吞吐量和能量。
Xu等人[144]提出了一种基于FPGA加速的加速方法,部署在网络边缘,用于将计算密集型任务卸载以加速移动应用程序。作者提出了一个系统架构,其中移动设备连接到一个无线边缘网络,包括一个WiFi路由器和通过以太网连接的FPGA板。无线边缘网络中的边缘卸载管理器组件将决定在增强了FPGA加速器的边缘处理器内执行请求的计算还是将请求转发到远程云(见图8)。考虑了三种应用程序:(i)手写数字识别,它基于类似LeNet-5的卷积神经网络模型运行。(ii)物体识别,它基于二进制神经网络模型执行。(iii)人脸检测,它基于基于相似性检查的计算机视觉算法运行。网络计算是神经网络推理和计算机视觉算法操作,这些操作在ARMA-FPGA板(Xilinx Zc706)中实现。所提出的方法是协同设计方法,因为只有可以在加速器上执行的操作被卸载到FPGA,而其余操作在通用CPU上执行。实验结果表明,与基于通用CPU的边缘/云卸载相比,所提出的方法将响应时间和执行时间分别减少了3倍和15倍,并节省了移动设备和边缘节点分别为29.5%和16.2%的能量。
3. 安全性
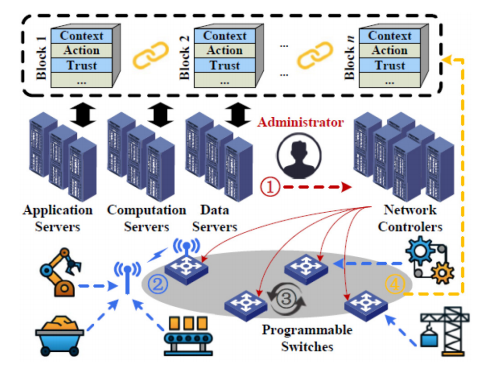
图10 基于虚拟化平台[155]的网络计算体系结构。
在本节中,我们解释了我们在边缘计算范围内调查的研究中发现的安全机制。为了减少传输开销和提高服务能力,在工业物联网的大规模机器通信中,将运行在集中式服务器上的访问控制程序迁移到边缘数据平面设备中,这是由宋等人提出的[145]。图9展示了所提出方法的结构。各种异构终端发送不同服务的请求,例如感知、数据上传和所需的控制信令。整个过程分为四个步骤:(i)系统初始化:在此步骤中,管理员通过控制平面内的网络管理应用程序设置适当的访问控制策略。策略根据一些上下文变量定义,例如,终端的感知频率、终端和服务对象之间的距离。根据上下文变量的值,定义操作,并且控制器在靠近终端的边缘可编程交换机上设置整个策略。(ii)请求发送:终端向访问设备发送其服务请求以及上下文信息。(iii)请求处理:访问设备,即交换机从数据包头中提取上下文信息,并根据匹配的服务对象应用相应的规则,即允许、拒绝、警报、重新认证。控制器将实时与交换机进行交互以更新策略。(iv)生成安全日志:记录和评估终端的访问行为,以便根据报告的上下文、请求上传特征和终端恶意行为的历史计算终端的信任值。交换机将计算统计数据,例如大小、频率和请求的服务对象。基于日志,可以在服务器上实现复杂的攻击检测(例如DoS攻击)方法。为了确保日志的可信度,作者使用了区块链作为数据结构。为了应对交换机存储限制,提出了一种算法,在交换机上动态部署策略。网络内计算计算访问服务的统计数据,并运行在BMv2中实现的访问控制策略。所提出的方法是一种协同设计方案,由于控制器与数据平面的实时交互以及在服务器上实现的攻击检测。与集中式方法相比,由于交换机的管道速度以及靠近终端的处理,授权决策时间已经减少了8毫秒。通过过滤非法流量以及在边缘响应,网络中传输的流量体积减少了近3倍。
Zhang等人[146]提出了一种基于信号处理的安全大图像数据处理方法,通过雾计算环境实现。我们在这个类别中考虑了这项研究,因为作者的主要重点在于使处理过程安全。在提出的方法中,通过离散小波变换表示的彩色图像被采样和压缩,使用一种先进的信号处理技术称为压缩感知。正弦逻辑调制映射被用来构造用于执行压缩感知编码的测量矩阵。此外,为了安全目的,还生成了经过身份验证的测量作为颜色图像的编码。生成的测量值被归一化(出于安全目的)并发送到雾节点进行图像后处理,使用特定的安全机制进行增强,例如提取值顺序、分解测量值和掩蔽能量值(基于置换扩散体系结构来隐藏能量信息)。最后,相关数据被传输到数据中心用于存储、重建和完整性认证。作者已经在FPGA中的雾节点中实现了所提出的处理,以加速处理。网络内计算是使用安全机制增强的图像后处理,实现在DE2-70 FPGA中。所提出的方法是一种协同设计,因为云数据中心用于存储、重建和完整性认证。实验结果表明,在某些攻击下,所提出的方法可以保障隐私安全。此外,使用所提出的方法,重建时间已经减少了近2倍。
C. 4G/5G/6G
我们首先回顾在4G/5G/6G的无线接入网络(RAN)中利用网络内计算的研究,然后解释了在移动核心网络方面已经进行的研究,最后回顾了在4G/5G/6G其他领域利用网络内计算的研究。
1.无线接入网络
在[147]中,LTE的RAN部署了一个边缘网关设施。[148]的研究将下一代NodeB的部分功能卸载到可编程交换机中。最后,[149]的研究通过利用网络内计算改进了RAN中的切换操作。
Aghdai等人[147]提出了一种LTE无线接入网络中的边缘网关,使服务运营商能够在移动用户的近距离部署网络功能。他们将两个功能视为边缘网关的主要功能:(i)向移动边缘用户提供内容传递;(ii)在流量分配中应用负载平衡策略将接收到的流量引导到MEC服务之一。网络内计算,即上述边缘网关功能在IP传输的边缘处实现,使用Netronomr NFP4000 P4目标实现。对于UE通过中间网关连接到托管SPGW、HSS和MME组件的节点的简单拓扑结构,LTE协议栈和所提出的网关的端到端延迟平均为50微秒。
Vörös等人[148]专注于使用可编程交换机实现5G RAN下一代NodeB(gNodeB)的实现,以获得高吞吐量。考虑到一些gNodeB功能,例如加密/解密不能在可编程交换机中实现,因此采用了使用可编程交换机和外部服务的混合方法。实际上,主要数据包处理是在可编程交换机中实现的,而复杂的功能由外部服务执行。网络内计算,即gNodeB部分功能的实现,使用P4硬件交换机实现。所提出的方法是一种协同设计方法,因为gNodeB的复杂功能由使用通用处理器的服务提供。在P4硬件交换机上的评估表明,所提出的混合方法可以成为现有gNodeB解决方案的替代方法。
Palagummi和Sivalingamf [149]考虑了下一代RAN,其中基带单元功能分为中央单元(CU)和多个分布单元(DU)。作者关注在移动用户设备(UE)需要在DU之间进行切换时的切换问题。作者提出了一种资源分配方法,其中资源在UE路径上提前分配。CU/DU的功能被分解为三个组件,包括计算服务器、P4交换机和控制器。基于P4的交换机在CU和DU之间运行。在CU/DU的功能中,网络内计算包括跟踪UE的移动行为并提前在DU中执行资源分配,这些功能在P4BM软件交换机中实现。由于CU/DU的部分功能被卸载到网络中,所提出的方法是一种协同设计方法。实现结果显示,所提出的方法在切换时间上减少了约18%和25%。
2. 移动数据核心
在[150]中,描述了对LTE EPC移动数据核心进行重新设计的研究,其中将一些控制平面过程卸载到可编程交换机中。[151]的研究提出了在可编程交换机中实现的5G移动数据核心的网关。最后,[152]利用网络内计算来实现Serving Gateway的用户平面,而[153]则提出了用于User Plane Function的网络内实现。
LTE EPC(Long-Term Evolution Evolved Packet Core)的控制平面包括附着、脱离、S1释放、业务请求和切换等过程。大部分信令流量与S1释放和业务请求等过程有关,这些过程操作用户特定的上下文。因此,Shah等人提出将这些过程卸载到可编程数据平面交换机的数据包处理管道中,从而提高控制平面的吞吐量和延迟。同时,他们考虑了三个挑战:第一,控制平面在交换机中存储的状态与集中式控制平面中的主副本状态不一致。为解决这一挑战,卸载的控制平面状态与其主副本状态进行同步。第二,为了在交换机中存储用户上下文,同时尊重交换机的内存限制,将用户上下文分区存储在多个交换机中。第三,为了处理交换机故障并避免丢失存储在交换机中的用户上下文,将用户上下文在交换机之间进行复制,并提出一种应对交换机故障的机制。在LTE EPC的控制平面中,即S1释放和业务请求过程的网络内计算,通过BMv2和Netronome Agilio CX智能网卡实现。因为LTE EPC的其他控制平面功能是在非网络元素中实现的,所以该方法是一种协同设计方法。硬件原型显示,当交换机硬件存储65K并发用户的状态时,吞吐量和延迟分别提高了102倍和98%。
Singh等人关注5G移动数据包核心架构。根据这种架构,上行和下行IP流量通过信令网关(SGW)路由到无线电网络的eNodeB站点。实际上,多个eNodeB和它们之间的切换由SGW管理。移动数据包核心与外部IP网络之间的连接以及数据包过滤、计费策略和服务质量管理等功能由Packet Data Network Gateway(PGW)处理。另一方面,移动性管理实体(MME)执行安全程序,例如用户认证、会话处理和跨网络的用户跟踪。
作者定义了Evolved Packet Gateway(EPG),它是SGW和PGW功能的合并。作者在可编程交换机上实现了vEPG用户平面功能,同时将vEPG控制平面保留在x86服务器上。实现vEPG用户平面的管道包括L2表、上行和下行防火墙表、GTP封装和解封表以及IPv4路由表。移动数据包核心架构中的SGW和PGW的网络内计算即用户平面功能在Barefoot Tofino硬件上实现。所提出的方法在线路速率下运行,延迟不到2微秒。
Shen等人描述了5G数据包处理的简化架构。在这种架构中,Serving Gateway(SGW)由控制平面(SGW-C)和用户平面(SGW-U)组成,多个SGW-U由一个SGW-C控制。后向连接提供基站、核心网络和边缘网络之间的连接,后向传输的流量基于GPRS隧道协议(GTP)。
Backhaul传输的GTP数据包通过SGW-U转换为以太网数据包,然后发送到边缘服务器。另一方面,在向后传输之前,需要将边缘服务器上的以太网数据包转换为GTP数据包。为此,专用软件/硬件负责处理GTP头。由于基于软件的方法传输吞吐量低,作者利用可编程网络元素实现了5G移动边缘网络的SGW-U系统。使用Realtek RLT 9310交换机和FPGA平台实现了网络内计算,即SGW-U功能。实验结果显示,达到了10 Gbps的吞吐量和5微秒的数据包处理延迟。
Paolucci等人提供了一个5G X-haul测试平台,通过使用实现了用户面功能(UPF)模块的P4交换机进行了增强。网络内计算,即UPF功能,由GTP协议封装/解封装功能以及5G MEC架构中的N3-N6-N9流量转发组成。此外,通过使用BMv2和P4代码在网络中实现了监测GTP流性能指标,如经验延迟。流量的经验延迟低于200微秒。
3.其他INC应用
有几项研究利用网络内计算在其他4G/5G/6G应用中。分别在[154]和[155]中考虑了5G片段流和6G任务的处理。Ricart-Sanchez等人[154]演示了一种在5G网络片段中处理流的网络内解决方案。他们通过6元组(5G用户源和目标IP、5G用户源和目标端口、区分服务代码点和与用户设备和5G核心网络之间建立的无线电隧道相关的GTP隧道ID)定义了网络片段。这些6元组在匹配/操作阶段的TCAM表中使用,以定义网络片段。动作被定义为对片段执行的操作。网络元素流水线已扩展以实现排队规则,以在处理片段的流程中应用基于优先级的规则。根据排队规则,低优先级队列将不会被处理,直到高优先级队列被处理。实际上,定义了几个不同的队列,允许为片段定义各种类型的QoS。网络内计算,即5G片段流的处理是在P4-NetFPGA中实现的。在私人数据中心部署的5G边缘到核心基础设施上进行的评估结果显示,最高优先级队列的端到端延迟在0.5毫秒以下,最低优先级队列的端到端延迟在3毫秒以下。
Hu等人[155]提出了一种在6G中应用网络内计算的体系结构,如图10所示。所提出的体系结构将网络功能卸载到具有交换芯片的主机系统中,其中高性能交换芯片实现数据包处理功能。在这方面,不仅提供了应用程序部署的灵活性,而且还提供了应用程序迁移的能力。实际上,可以在主机上设置虚拟化环境,具有在容器中运行应用程序的能力,这些容器可以根据调度策略在主机之间迁移。作者将向网络内计算设备卸载操作在数据流上的任务的决策建模为一个多目标优化问题,该问题最小化总体数据传输开销、能源消耗以及资源空闲率。提出了一种算法来解决这个优化问题。网络内计算是通过包含PX30 Cortex-A35 CPU的INC-Server实现的任务执行。对于数据聚合应用程序,由于网络内处理,云服务器的负载降低了60%,能源消耗降低了50%。
Wu等人[156]关注物联网应用程序,其连接数量比增强移动宽带应用程序高出几个数量级。另一方面,每个连接设备提供的数据流量远低于传统4G通信中的流量。在考虑到向多个目的地传输数据的情况下,多个小数据将被编码为一个块,在数据帧被传输之前在P4交换机上进行。然后,通过eMBMS承载,块从交换机传输到LTE-M单元中的目标设备。在数据包到达IoT设备后,解码将在目标处完成。使用所提出的方法,与基准相比,用于数据传输的无线电资源块的数量减少了8倍。
Gökarslan等人[157]提出了一种用于工业5G网络的可编程数据平面,它减少了处理,提供了网络监视机制,并增强了网络的安全性。所提出的数据平面管道在RAN和用户平面功能(UPF)之间的连接上运行。将GTP数据包发送到UPF或将数据包转发到另一个gNodeB的路由决策被卸载到位于gNodeB之间的P4交换机上。作者还在P4管道中部署了监视和安全功能,以增强5G的性能。网络内计算,即流量路由决策、监视和安全功能在BMv2中实现。与传统的5G架构相比,所提出的方法将单元内网络延迟降低了2倍。此外,安全规则可以在10毫秒内更新,置信度为95%。
Ricart-Sanchez等人[158]提出了一种5G移动网络的硬件加速的第4层防火墙。所提出的防火墙位于边缘和核心网络之间,以保护5G用户以及基础设施。防火墙通过采用解析器、匹配-操作表和解析器来实现。MAC、IP、UDP/TCP和通用分组无线电服务隧道协议(GTP)的标头被定义为要解析的内容。在解析之后,数据包将通过匹配-操作管道进行处理,其中数据包的提取字段定义了丢弃或转发操作。TCAM表被定义为包括5G用户源/目标IP和端口、传输协议类型和GTP隧道信息作为匹配部分。对于恶意数据包,将应用DROP操作,而默认情况下则是允许操作。最后,未被丢弃的数据包将被重构并通过5G基础设施传输。作者在[159]中扩展了他们的研究,以支持5G中的多租户。网络内计算,即第4层防火墙策略是在P4-NetFPGA NIC [160]中实现的。在评估中,网络中的数据包处理延迟比基于软件的解决方案快2493倍,边缘节点和核心节点之间的吞吐量增益高达3.5 Gb/s。
D. 网络功能虚拟化
网络功能虚拟化(NFV)是一种范式,它将网络功能与应用特定集成电路(ASIC)和特定硬件分离,并在虚拟化基础设施(例如虚拟机和容器)中实现这些功能。这一努力结果在于以更低的成本和更高的灵活性来处理网络功能更新。虚拟机/容器的部署消耗高资源,由于操作系统在虚拟化层上的开销会产生额外负担,而且VNF所需的性能和吞吐量可能无法提供。网络计算已被利用来解决这些问题。研究可分为两组:硬件加速网络功能和框架/部署解决方案。
1.硬件加速网络功能
为了降低网络功能(NF)在通用硬件上作为软件运行时的性能问题,硬件加速技术已被用于虚拟网络功能。NF需要执行诸如路由操作的IP/MAC查找,基于隧道的转发的封装和解封装数据包,以及安全性的数据包加密和解密等任务。为了执行这些任务,需要频繁监视网络接口控制器(NIC)并通过NF处理IP数据包,这会消耗大量的CPU周期和I/O交互。被归类为定制和专用技术的硬件加速技术可以提高该过程的效率。
专用硬件加速是为特定功能而设计的硬件,其能力受到重新编程和更改硬件行为的限制或没有这样的能力。因此,专用硬件加速不在网络计算的范围内,网络计算要求对网络元素进行通用编程的灵活性。定制加速更具成本效益,可编程和可配置,这使得根据应用程序采用新的网络功能和协议成为可能。这些加速器的一般思路是将一些处理过程卸载到网络元素(例如FPGA,智能NIC,可编程交换机)中,以便在由一般CPU执行的处理过程之前或之后对数据包进行处理。在网络功能的背景下,校验和计算、加密和解密、拆分和重建数据包[161]、路由[162]、负载均衡[163]等都是可以卸载到网络元素中以节省CPU周期和增强网络功能性能的功能示例。我们建议感兴趣的读者参考[45],[161]以获取更多详细信息。
2.框架/部署解决方案
这类研究提出了框架和部署解决方案,以在NFV计算环境中利用网络计算。尽管有一类研究专注于在网络元素中部署VNF,但另一类研究则提供在具备网络计算能力的NFV环境中的框架/部署解决方案。
a.在网络元素中部署VNF
Kundel等人[164],[165]使用P4并开发出一个在中央办公室重构为数据中心(CORD)环境中部署的宽带网络网关数据平面,以提供电信提供商的要求。讨论了宽带网络网关系统的虚拟网络功能:流量速率强制执行、客户隧道、流量访问控制、流量分离、认证、授权和计费、队列和分层调度等。宽带网络网关功能在上行和下行数据平面上执行。网络计算,即宽带网络网关功能,是在裸机Tofino、BMv2、Netronome SmartNIC和P4-NetFPGA中实现的。对于一个订阅者通过FPGA和P4数据平面(Tofino)连接到核心网络的场景,并且进行10000个数据包的VOIP传输,端到端延迟最大为14.5微秒。同样,Osinski等人[166]将虚拟宽带网络网关的一些功能卸载到可编程ASIC上,但他们的研究中没有详细信息或评估。
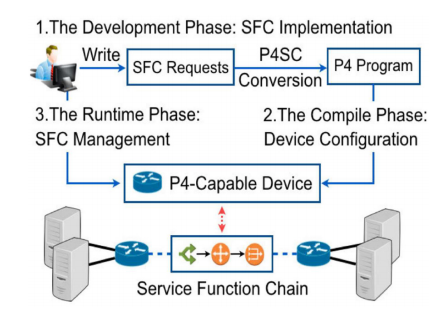
图11。在支持p4的设备[170]上的服务功能链接框架。
Osinski等人在[167],[168]中提出了一个NFV框架,用于在数据中心中实例化VNFs,可以在软件交换机或硬件设备(如顶部交换机、SmartNIC或FPGA)中运行。该框架的原型基于OpenStack Neutron、P4语言和BMv2软件交换机实现。
Mafioletti等人[169]基于对VNF的功能组件进行分析,提出了在网络元素上部署VNF的方法。作者提出了一个框架,将VNF分解为小型嵌入式网络功能(eNF),以便在网络元素上部署。检查了服务功能链中VNF的功能组件,以发现流量处理中的重复。因此,VNF中的公共组件合并为一个新组件,据此定义了要卸载到网络元素的eNF。最后,定义了相应的P4原语,包括标题的解析和分类以及需要进行数据包丢弃和计数的操作,以及eNF的功能。还定义了基于哈希表和布隆过滤器的链接机制,以确定链中的网络流量方向。网络计算,即小型网络功能,是在智能NIC上实现的。对于具有三个VNF的防火墙VNF链应用程序,当所有VNF在网络中运行时,与所有VNF在软件中运行(3300微秒)的情况相比,延迟可以降低76×(43微秒)的因子。已实现最高8×的吞吐量提升。
在[170],[171]中进行的研究设计了一个框架,用于在具有硬件能力和P4可编程性的P4设备上进行服务功能链接(SFCs),以提高性能以及在实现服务功能链(SFCs)方面的灵活性。如图11所示,所提出的框架为运营商提供了几个高级原语,以便他们生成所需的SFC请求。此外,转换器根据给定的SFC请求生成相应的P4程序。转换器应用基于最长公共子序列的算法,以合并P4程序中的多个SFC。网络计算,即网络功能,是在Tofino上实现的。对于现实世界中的SFC的评估表明,与基于软件的NFV解决方案相比,吞吐量提高了10000倍。类似地,延迟将降低10000倍。
b. 具备INC技术的NFV(混合基础网络的框架/部署解决方案)
在[172]、[173]中考虑了在混合基础网络上部署VNF(虚拟网络功能)的实现,包括网络元素和通用计算节点。Lopes等人[172]提出了一个平台,用于管理和分配VNF组件,这些组件在异构架构中由FPGA和通用处理器组成。作者提供了VNF组件属性的指南和讨论,以帮助选择每个VNF组件的适当基础。在网络计算中,即VNF组件在NetFPGA上实现。所提出的方法是一种共同设计方法,因为VNF组件部署在包括网络元素和通用处理器的混合基础环境中。对于深度数据包检查和防火墙功能,与软件解决方案相比,该方法的吞吐量提高了2倍,可达800 Mbps。
Moro等人[173]提出了一种优化框架,用于在混合基础网络上部署VNF。作者将VNF分解为多个较小的函数,称为µVNF,然后将它们分布在可编程交换机、NIC和边缘/雾计算节点组成的混合基础设施上。然后,作者开发了一个优化框架,以选择最小部署成本的分解,以及确定每个µVNF所部署的节点。作者还部署了一个工具,通过该工具,多个µVNF可以在一个P4程序中集成,以便在可编程交换机上实例化。研究了所提出算法在链路故障条件下的鲁棒性。所提出方法中的网络计算是µVNF的执行。所提出的方法是一种共同设计方法,因为µVNF的执行分布在包括网络元素和边缘/雾计算节点的混合基础环境中。与基准线相比,所提出的方法将部署成本提高了3倍。
E. 总结,比较,见解和经验教训
在本节中,我们首先简要总结技术特定的应用,然后讨论所得到的见解和经验教训。
1. 总结
有多项研究应用了网络计算在云计算中。[137]、[138]、[139]、[140]的研究利用网络计算在数据中心中提供负载均衡。它们将负载均衡卸载到网络元素中。[27]、[28]、[141]的研究为云环境中的数据中心应用提供资源分配,这些应用加入了INC。在[27]、[28]中,网络元素被利用来执行应用程序或应用程序组件计算。[141]的研究利用网络计算在混合云提供程序和附加提供程序中。
在边缘计算范围内也有几项研究应用了网络计算。一些研究旨在提供边缘智能配备。[15]只将智能识别或控制场景的关键子任务卸载到网络中,[69]、[81]的研究则利用网络计算进行联邦学习的优化。还有一些研究在边缘计算中提供了资源分配或任务卸载方法,这些方法加入了网络计算[58]、[142]、[143]、[144]。
此外,在4G/5G/6G范围内已经进行了几项研究。[147]、[148]、[149]的研究利用网络计算在无线接入网络(RAN)中实现更高的吞吐量和更低的延迟。在这些研究中,类似于流量引导、负载均衡、gNodeB的某些功能以及无线电资源分配的计算已经被卸载到可编程交换机中。[150]、[151]、[152]、[153]的研究利用网络计算来简化移动数据核心。他们利用网络元素执行一些控制平面过程,或可卸载的移动数据核心网络功能,如Serving Gateway和User Plane Function。[154]、[155]、[156]、[157]、[158]的研究利用网络计算来加速4G/5G/6G的其他领域的处理,包括5G网络切片、6G应用、LTE服务IoT应用和5G网络的监控/安全性。
网络功能虚拟化由于虚拟机/容器的部署而消耗大量资源。此外,操作系统在超级管理程序上引起的开销可能无法满足所需的性能和吞吐量。网络计算已经被利用在多项研究中来克服这些问题。[45]、[161]的调查中考虑了硬件加速的网络功能。有些研究提出框架/部署解决方案,以利用NFV环境中的网络计算。一些研究专注于在网络元素[164]、[165]、[167]、[168]、[169]、[170]、[171]中部署VNF。通常,所提出的框架/部署建议将整个VNF或VNF功能的一部分通过分解VNF实现在网络元素中,例如SmartNIC、FPGAs、可编程交换机。[172]、[173]的研究提供了在带有网络计算增强的NFV环境中的框架/部署解决方案,即网络元素和通用计算节点的混合。
2. 比较、见解和经验教训
表XII、XIII、XIV和XV比较了云、边缘、4G/5G/6G和NFV范围内的技术特定研究。这些研究从贡献、方法论(网络计算、共同设计、优化/目标函数)和评估(网络元素、仿真平台、主要结果)方面进行比较。从中可以得出一些见解,可以从中学到一些经验教训。
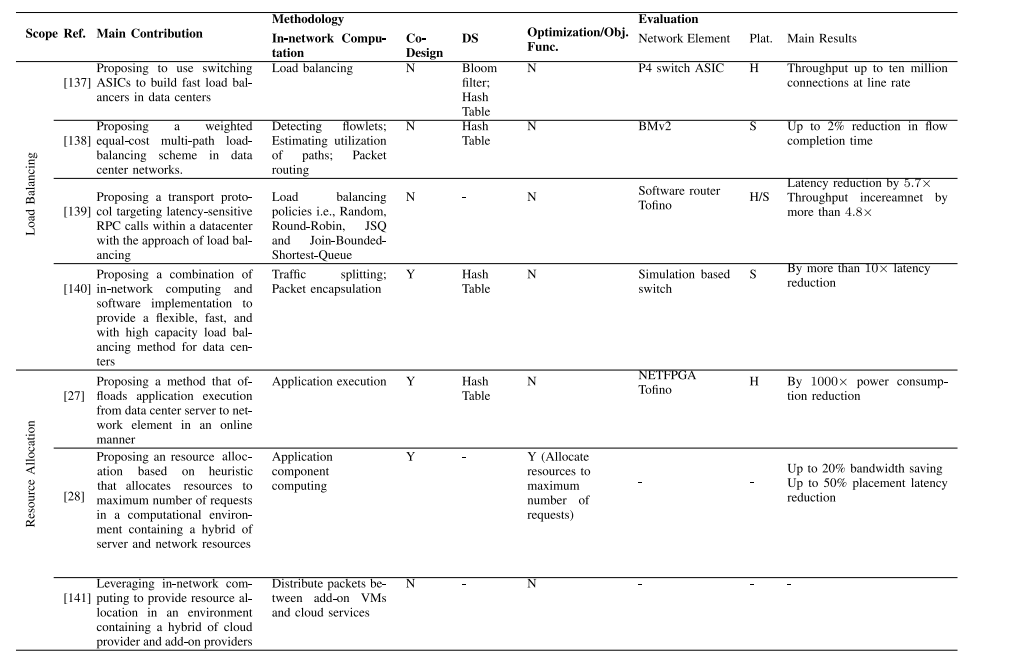
表XII:在云计算中的工作原理的比较
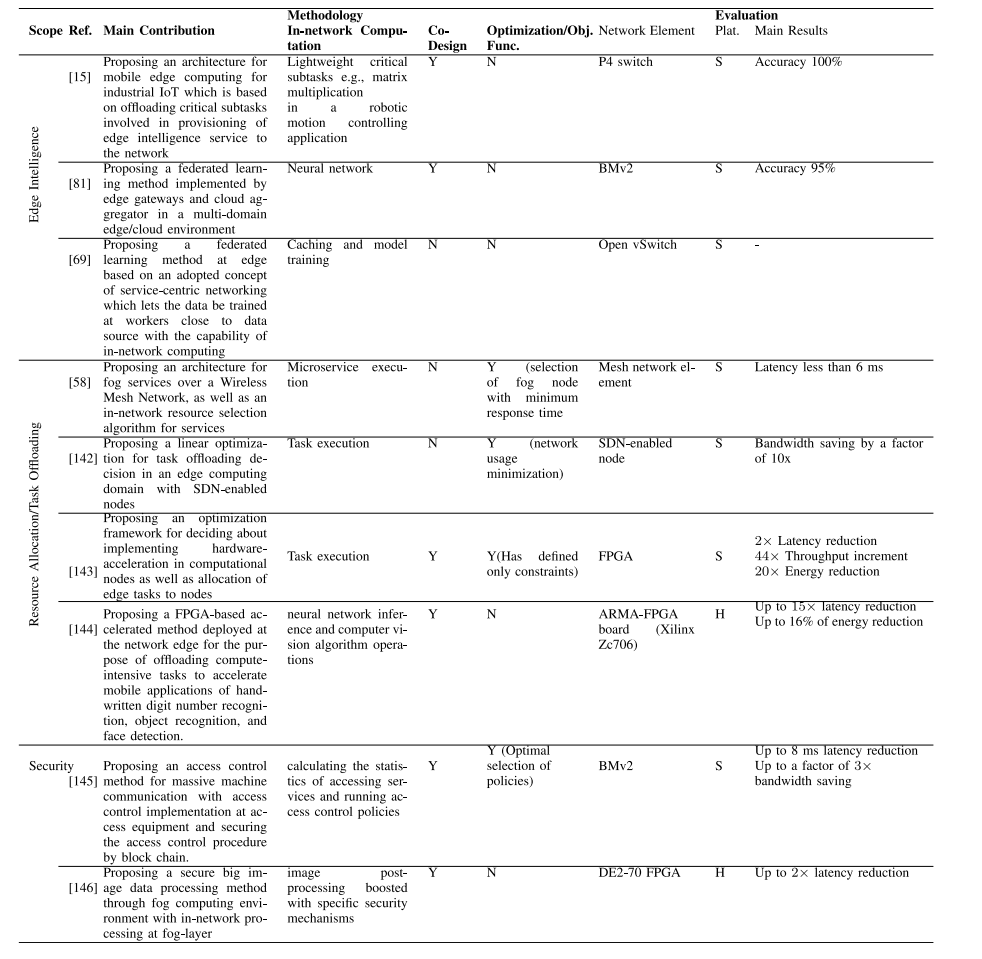
表XIII:在边缘计算范围内的工作的比较
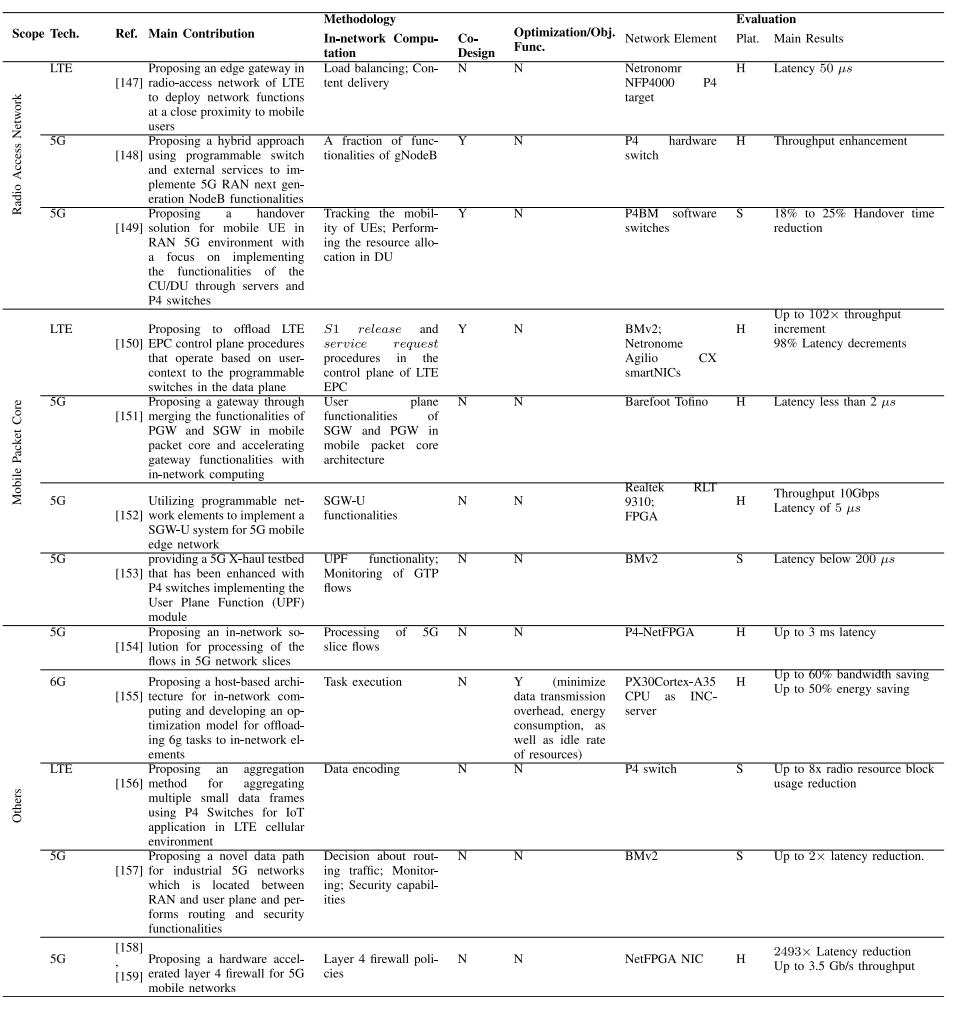
表 XIV:4G/5G/6G范围内的工程比较。技术方面的日常工作。(技术)
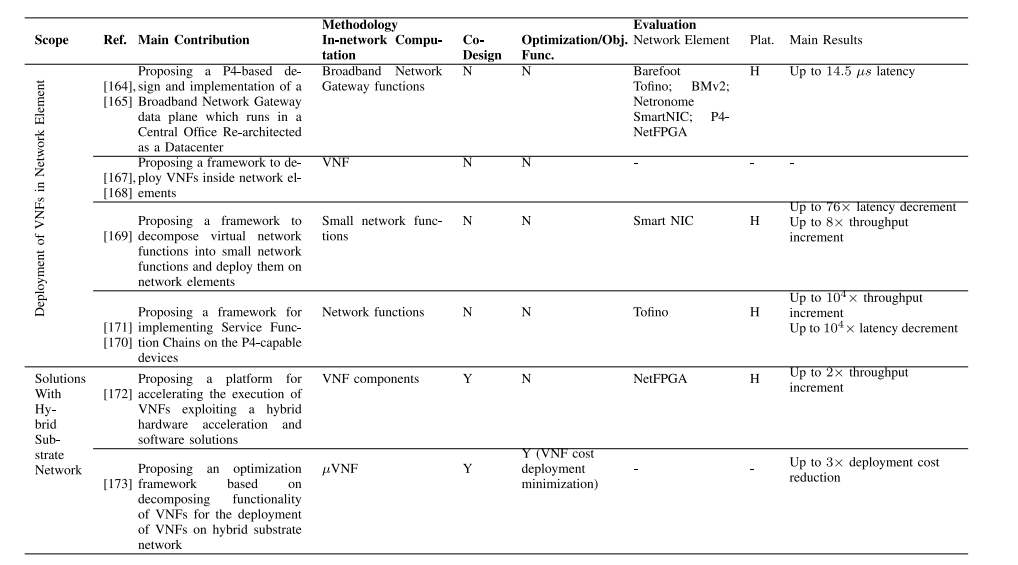
表XV:在NFV范围内的解决方案/部署工作的比较
• 容错性:一个总体观点是,很少有研究,例如[140],[150],考虑到技术特定应用中的容错性。容错性对于网络计算至关重要,因为网络元素,尤其是交换机,可能会失败。此外,拥塞可能导致网络元素不可用。以5G RAN为例,当将RAN功能卸载到交换机的执行由于交换机故障而失败时,可能会发生一些潜在的故障,这对于具有高可用性要求的服务是不可接受的,例如UE与核心网络之间的连接可能会中断,漫游的失效等。我们得到的经验教训是需要更多的研究努力来为网络计算提供容错技术。
• 带有INC的计算环境:另一个见解是,大多数研究都集中在实现网络元素所需的功能上。然而,基础设施由异构资源组成,包括具有各自能力和属性的网络元素和计算节点的混合体。虽然网络元素提供了相当高的处理速度,但与具有强大处理和内存能力的计算节点相比,它们的灵活性较低。在这方面,需要进行优化以定制权衡并达到最优决策。很少有研究对混合基础设施网络进行了优化:[28]专注于在带有INC的云中最大化请求的接受,[173]在带有INC的NFV中最小化VNF部署成本。我们得到的经验教训是需要更多的研究努力来决定在混合基础设施中计算分配的最优策略,特别是在缺乏这种优化视角的5G/6G环境中。
• 优化:调查的研究大多考虑通过实现所需的功能来利用网络计算,例如在新一代移动通信中实现5G RAN、移动数据核心功能、虚拟网络功能、边缘智能等。然而,为了有效利用网络计算,除了现有技术外,还需要提供解决方案来决定在目标计算环境中优化系统或应用程序相关的性能指标的最佳策略。很少有研究考虑了这种优化方法,主要集中在边缘计算[58],[142],[145]范围内,侧重于响应时间和资源利用率的优化。我们得到的经验教训是需要更多的研究努力来提供解决方案,采用优化各种系统/应用程序相关标准的方法,特别是对于像NFV、云计算和5G/6G这样的技术。这对于优化由于将计算从高功耗通用计算节点转移到低功耗网络元素而产生的功耗消耗尤为重要,因为唯一考虑此事项的研究是[155]。能源效率特别是6G设计的重要焦点,为6G增强的网络计算提供节能优化的资源分配,可以视为未来的研究趋势。
在接下来的部分,我们从计算节点、性能指标和方法论的角度提供更多比较。一般来说,这些技术中的网络内处理应用旨在在QoS标准(例如吞吐量和延迟改进)上获得卓越的表现,以及在资源利用标准(例如功耗和带宽消耗减少)方面与现有基于服务器/专用硬件的解决方案进行比较。这些标准的主要表现已在表XII、XIII、XIV和XV中报告。为了更好地比较,表XVI比较了网络内实现的功能与基于服务器/专用硬件方案,这些方案是许多研究的比较基线,例如[157]、[169]、[170]、[171]、[172]。我们以下提供更多详细信息:
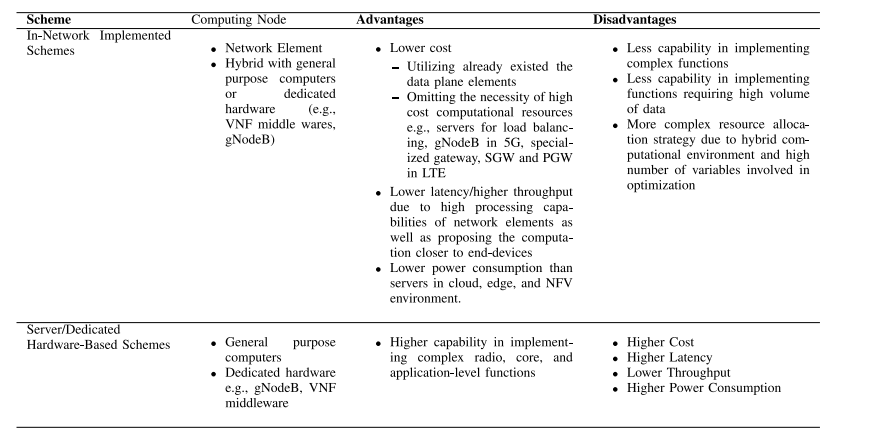
表XVI:比较完全网络实现的技术功能,与服务器/专用硬件的方案

表XVII:混合计算环境下资源分配方案的比较
• 计算节点:服务器/专用硬件方案利用通用计算机或专用硬件(例如VNF中间件、gNodeB)作为计算节点。相比之下,网络内实现的方案中,网络元素作为计算节点发挥重要作用,尽管利用网络元素和其他非网络元素资源的混合也是可能的。
• 成本:与服务器/专用硬件方案相比,通过在已经存在的数据平面元素中管理处理并省略计算资源的高成本(例如用于负载均衡的服务器[137]、[140]或专用硬件,例如5G中的gNodeB[148]或专用网关,例如5G中的SGW和PGW[151]),网络内实现的方案可以降低成本。
• 延迟/吞吐量:与基于服务器/专用硬件的解决方案相比,网络内方案可能会导致延迟更低/吞吐量更高的解决方案,因为网络元素具有高处理能力,并且将计算提议更接近最终设备。文献中报道了与基于软件的云负载均衡器[140]相比延迟降低10倍,由于在边缘进行FPGA加速[144]而在移动应用中降低高达15倍的延迟,通过扮演雾节点角色的网状中继/路由节点的端到端消息传递延迟小于6毫秒[58],以及在网络内LTE协议栈和网关处理中的延迟为50微秒[147],以及下一代RAN中在分布式单元之间漫游时间减少了25%。作为增强吞吐量的例子,[170]、[171]中对真实世界服务功能链的评估说明,在软件NFV解决方案中,软件方法将具有大约0.01 Mbps的吞吐量,而通过网络内实现网络功能,将会获得大约102 Mbps的吞吐量。另一个例子是,通过将LTE EPC控制面操作卸载到可编程交换机[150]中,吞吐量增加了102倍。
• 功耗:网络元素的每瓦能量使用的处理能力比云、边缘和NFV环境中的服务器高得多。例如,可编程交换机每瓦使用量可以执行数十亿次操作。然而,大多数调查研究并未评估网络内计算对功耗消耗的影响,需要进行更多的研究评估。[27]的研究表明,通过将高消息交换量的云应用程序卸载到网络或将高功耗应用程序从服务器卸载到网络,与在云计算环境中基于通用CPU的软件系统相比,功耗可提高100倍。此外,[155]报告由于在网络内处理6G任务而实现的节能高达50%。
• 网络内实现方案的缺点:与基于服务器/专用硬件的解决方案相比,网络内实现方案有两个缺点:(i) 由于硬件限制,网络内实现方案在实现具有复杂性或高数据需求的功能方面具有较少的能力。这些功能可以是NFV、云/边缘或新一代通信的应用层功能,以及4G/5G/6G中的无线接入或核心功能。利用除网络元素以外的通用计算单元的共设计方案扩展了网络内解决方案的能力。[15]的研究是一个机器人运动控制应用程序的例子,它将控制矩阵学习卸载到MEC服务器中,同时在可编程交换机中执行矩阵与当前状态向量的乘法。另一个例子是[145]中的机器通信应用程序,它在可编程交换机的网络边缘实现访问控制策略,并将复杂的攻击检测保留在服务器中。考虑到数据量,将虚拟IP分区为直接IP映射元素以用于数据中心中的负载均衡是[140]中使用的一种策略,以应对内存限制。同样,在[150]中,处理LTE EPC移动分组核心过程的用户上下文被分配给多个交换机。
(ii) 考虑包括非网络资源(即云、边缘、NFV、4G/5G/6G中的通用计算资源)以及网络元素的混合计算环境,在与服务器/专用硬件解决方案相比较时,资源分配决策将变得更加复杂。[28]的研究旨在将资源分配给最大数量的云应用程序,而[173]的研究旨在最小化VNF部署,提出了优化技术来应对资源的异构性。然而,问题中可能涉及到高维度的优化变量,例如网络元素的资源利用率、网络元素和通用计算资源之间的通信成本/时间、网络元素的处理能力等。由于优化变量的数量很大,传统的优化方法可能效率不高,未来研究可能需要探索更高级别的优化方法,如机器学习。
• 网络内部实现方案的缺点:与服务器/专用硬件解决方案相比,网络内部实现方案有两个缺点:(i) 由于硬件限制,网络内部实现方案在实现具有复杂性或高数据要求的功能方面具有较少的能力。这些功能可以是 NFV、云/边缘计算或新一代通信中的应用程序级功能,也可以是 4G/5G/6G 中的无线接入或核心功能。利用除网络元素之外的通用计算单元的协同设计方案可以扩展网络内部解决方案的能力。[15] 中的研究是机器人运动控制应用的一个例子,它将控制矩阵学习卸载到 MEC 服务器中,同时在可编程交换机中执行矩阵乘积与当前状态向量的运算。另一个例子是[145] 中的研究,它在可编程交换机中实现访问控制策略,并在服务器中保持复杂的攻击检测。考虑到数据量,将虚拟 IP 划分为用于数据中心中可编程交换机之间负载平衡的直接 IP 映射元素是[140] 中使用的一种策略,类似地,[150] 中将用户上下文划分为处理 LTE EPC 移动数据核心过程的交换机。(ii) 考虑到混合计算环境,包括非网络资源(即云、边缘、NFV、4G/5G/6G 中的通用计算资源)以及网络元素,与服务器/专用硬件解决方案相比,资源分配决策将变得更加复杂。[28] 中的研究旨在将资源分配给最大数量的云应用程序,[173] 中的研究旨在最小化 VNF 部署,它们提出了优化技术来应对资源的异构性。然而,问题中可能涉及高维优化变量,例如网络元素的资源利用、网络元素和通用计算资源之间的通信成本/时间、网络元素的处理能力等。由于优化变量的数量很大,传统的优化方法可能效率不高,因此探索更先进的机器学习优化方法可能是未来的潜在研究方向。
在本节的结尾,我们比较了在前述技术中采用 INC 的现有资源分配方案。在调查的研究中,[27]、[28]、[58]、[172]、[173] 在混合计算环境中执行资源分配。它们可以在线方式[27]、[58]或离线方式[172]、[173]执行分配。表 XVII 比较了在线和离线方案。在线方案在运行时动态分配资源。一个优点是能够在运行时采用分配,并提供在网络资源和传统计算资源之间切换的机会。例如,[27] 中的研究提供了一种动态在网络元素和云服务器之间切换应用程序运行的机会,具体取决于应用程序的功耗和消息交换变化等参数。此外,在线方案由于可以更改已分配的失败资源而提高了容错能力。这是关键的,因为像交换机这样的网络元素容易出现故障或拥塞。另一方面,缺点是运行时资源分配决策的开销。在离线方案中,网络元素和通用计算资源在编译时分配给计算,没有运行时开销,并提供找到计算的最佳放置的能力。缺点是在运行时没有灵活性,并且在资源故障的情况下不具备容错能力。
VIII.研究方向
在本节中,我们将讨论最重要的研究方向,主要是从我们的文献综述中获得的经验教训,随着网络内计算的成熟,这将是无价的。我们将有一个单独的通用研究方向部分,其中包括可以应用于各种应用的研究方向,即网络内分析、网络内缓存、网络内协调、网络内安全以及特定技术的应用。
A. 网络内分析
与将数据传输到集中式主机进行聚合的基于主机的分析相比,网络内部分析可以减少网络中的流量流量量,并减少分析时间。一些研究已经显示了网络内部分析在数据聚合、机器学习和其他类型的分析(如重流检测、控制和查询处理)方面的潜力。
1.机器学习
少数研究在可编程网络元素中实现了机器学习,这些研究与在通用计算机上实现的机器学习方法相距甚远。可行的神经网络实现起点可以是[79]、[81] 中的研究。然而,[79] 利用量化简化神经操作,[81] 利用二进制权重和符号函数作为激活函数。由于这些简化可能导致精度降低,一个研究方向是研究在网络元素或网络元素和通用计算机的混合中实现神经网络的可行性,而不需要任何简化,以实现更低的推理延迟而不影响准确性。考虑到深度神经网络作为机器学习研究的趋势,由于存储所有神经网络参数可能会受到内存限制的限制,因此一个研究方向是利用研究中建议的技术来克服可编程数据平面设备的内存限制,并相应地调整机器学习实现。[174] 中的研究已经提出利用远程直接内存访问(RDMA)设施的外部内存来扩展交换机的内存。[175] 中的作者提出了一种架构,可以让顶部交换机的流表安装在本地内存或机架中的多台服务器上的外部内存中。可以使用 RDMA 访问外部流表,该技术可以通过基于 RDMA 的网络适配器或普通网络适配器支持。因此,一个有趣的研究方向是适应内存扩展机制下的深度神经网络实现。考虑到非神经学习方法,决策树的网络内部实现已经在[59]、[117] 中完成。在网络元素上实现其他非神经学习方法可能是另一个研究方向。[78] 中的研究可以成为朴素贝叶斯和 SVM 的起点。然而,该研究假设所需数学函数的计算已经在设备内部设置为查找表,并没有提供有关这种计算的任何详细信息。为了实现完整的非神经学习方法,需要调查在可编程网络元素或网络元素和通用计算机的混合中实现所需的数学函数的可行性。
2.协同设计分析
由于网络元素的处理和内存限制,不是所有类型的分析都可以在网络元素中实现。此外,特定分析所需的功能可能难以映射到网络转发架构(如匹配-操作表)中,甚至是不可能的。利用网络元素与非网络元素(如服务器、控制器)结合进行分析的协同设计方法似乎对于网络内部分析非常有前途。分析中不可实现或实现复杂的功能或操作可以在通用计算节点(如服务器、控制器)上执行。少数研究利用协同设计方法进行分析。例如,[86] 中提出了一种协同设计方法,用于查询处理,其中简单的操作在数据平面中执行,而复杂的操作由流处理器执行。协同设计方法可以是一个宝贵的研究方向,特别是对于具有复杂判别函数或基于核的计算的机器学习分析,在这种情况下,在网络元素上进行实现可能很复杂或不可行。
B. 网内缓存
文献中的研究(例如[92]、[93]、[94]、[95]、[96])利用网络内部缓存结构来便于内容/项访问。这些研究提供了访问和修改内容/项的协议。然而,为了拥有高效的网络内部缓存结构,可以考虑更多的标准。例如,发起内容/项请求的终端设备可能是移动的。在这方面,重新配置存储在网络元素内的数据以在终端设备附近提供内容的问题可能会出现。由于网络内部计算处于初始阶段,因此我们调查的研究缺乏网络内部缓存结构的移动覆盖范围和重新配置解决方案。对于基于键值的检索系统,当内容可能是复合的(即由分布在网络元素之间的几个键组成)时,这个问题变得复杂。因此,一个潜在的研究方向是根据终端设备的移动模式,提供优化解决方案和控制机制来决定重新配置存储在网络内部缓存中的数据。
C. 网络内安全
网络内部安全比网络内部分析、缓存和协调受到更多研究社区的关注。然而,正如我们从调查的研究中所学到的教训所述,仍然存在一些需要填补的研究空白。我们讨论可能的研究方向,主要是从我们调查的研究中所学到的教训中得出的。
1. 基于机器学习的攻击检测
文献中大多数攻击检测方法都是基于阈值的,通过将流量统计信息(例如,SYN/ACK数据包统计信息、TCP/UDP数据包和连接统计信息、流和子网的统计信息)与某些阈值进行比较来检测攻击。然而,机器学习技术可以在网络元素上实现,并可以以更高的准确率处理攻击检测。一项起点是[117]中使用随机森林方法检测网络中的攻击。其他机器学习方法,特别是神经网络,其实现在网络元素中已被证明是可行的,可以用于检测各种网络攻击。
2. 协同设计攻击检测/缓解
在网络安全范围内调查的研究表明,使用可编程网络元素执行安全相关功能(例如,估计流量统计信息、计算某些流量特征、检测攻击和攻击缓解)可以获得有希望的结果。然而,每个网络元素可以针对其服务的本地流量建立流量分布模型。本地流量分布无法有效确定检测攻击发生的参数。通过应用协同设计方法,网络元素可以与(SDN)控制器结合使用,在检测和缓解攻击方面发挥作用。控制器可以为网络元素建立的模型提供全局视图,因此可以更准确地决定攻击检测参数(例如,阈值)。因此,控制器和网络元素的协同设计方法,以便检测和缓解网络攻击,可能是一个有趣的研究方向。[104]、[109]中提出的协同设计方法旨在包括攻击缓解的全局模型。[109]的研究重点是过滤欺骗流量,而[104]的重点是DDoS攻击缓解。可以探索协同设计方法,通过网络元素和控制器等全局实体的协作来详细说明全局模型,以缓解网络中的各种攻击。
D. 特定技术应用
网络内部计算已经被用于特定技术,包括云/边缘计算、4G/5G和网络功能虚拟化的四分之一的研究。然而,在网络内部计算成熟之前,仍然存在一些需要填补的研究空白。在本节中,我们介绍这些研究方向。
1.混合环境的编排
在这些环境中,网络基础设施提供各种异构资源,包括网络元素的混合(例如,可编程交换机和路由器、FPGA、智能NIC)和其他节点(例如,物理计算节点、虚拟机、虚拟网络功能、存储节点)。网络元素可以以线速处理速度提供相当高的处理速度,并且可以在路径上操作数据包,省略长数据包遍历的必要性。然而,与具有强大处理和内存能力的计算节点相比,网络元素的灵活性较低。此外,根据所需功能的不同,实现网络元素中的每个网络功能可能会很复杂或不可行。因此,一个宝贵的研究方向是编排各种资源来处理所需的应用程序,这需要资源分配和流量引导解决方案来部署所需的应用程序。然而,正如我们从教训中所学到的,大多数研究都着重于在网络元素上实现所需的功能,例如[58]、[147]、[150]、[152]、[153]、[165]。[143]中的研究决定在计算边缘节点中实现硬件加速,但没有优化任何特定的目标函数。[28]中提供了在网络元素和云计算节点的混合中进行资源分配的研究,并旨在最大化请求接受。[173]的研究考虑了在由网络元素和NFV计算节点组成的混合基础架构中进行VNF分解,并旨在最小化部署成本。值得进一步研究和努力的是,在考虑其他目标的情况下提供编排方法,例如吞吐量最大化、带宽最小化、功耗最小化和服务质量度量(例如延迟、可靠性)。此外,需要研究提供适用于具有网络内部计算功能的5G/6G系统的编排机制,因为当前的技术水平缺乏编排机制。
2. 容错网络内部计算
容错对于网络内部计算至关重要,因为网络元素,特别是交换机,可能会由于拥塞而失败或不可用。托管移动数据包核心或5G RAN的交换机的故障可能会导致服务失败。在像火灾检测这样的应用中,检测火灾并发出警报被卸载到交换机上,例如[15],交换机故障可能会导致灾难性后果。因此,为网络内部计算应用程序提供容错机制至关重要。在我们调查的技术领域中,少数研究,例如[140]、[150],考虑了容错。需要更多的研究工作来为网络内部计算应用程序提供容错技术。
3. 计算迁移
考虑到云、边缘、5G/6G和NFV的技术为终端设备提供服务,终端设备的移动性(例如,车载网络、手机)需要解决方案,使计算能够在接近终端设备的地方进行,以满足应用程序的超低延迟要求。在这方面,由于网络内部计算处于起步阶段,在我们调查的研究中,计算迁移尚未得到研究。在网络内部计算的情况下,计算/任务的迁移需要对目标网络元素进行重新编程。为了避免这种重新编程的额外开销,最初的尝试是[155]中的研究,建议将具有虚拟化环境并配备高性能交换机芯片(用于数据包处理)的主机视为一种网络内部计算节点。然而,[155]中的架构是一个抽象的架构,该论文没有提供详细的讨论或任何评估。一个潜在的研究方向将是提供适用于网络内部计算节点的计算迁移架构和优化解决方案,以便在网络内部计算节点之间迁移计算。
E. 通用研究方向
本节中,我们讨论了可引入的研究方向,这些方向独立于网络计算应用或应用网络计算的特定技术。
1.协作式网络计算
与常见的计算机和服务器不同,网络元素的一个挑战是资源的稀缺性,即计算能力和存储限制。在这方面,基于交换机之间的协作设计解决方案可以被视为应对资源稀缺性的有价值的研究方向。在协作场景中,期望在网络元素之间分配所需的功能或数据,以及交换机之间进行通信以执行所需的功能或决策。我们调查的许多研究努力实现适合可编程网络元素的功能,并且不会固有地要求协作,例如 [119],[136],[139],[151]。然而,网络计算有潜力应用于具有大量功能空间的场景,在这些场景中,在单个设备中适应所需功能是不可能的。这样的协作场景的例子是 [176] 中的研究,其中交换机扮演DNS服务器的角色。由于域名空间可能很大,无法适应单个交换机,因此通过从一个交换机引用到另一个交换机来实现迭代解决方案。一个有价值的研究方向是利用协作式网络计算来协作解决需要大量功能空间的问题。例如,5G/6G移动数据包核心功能提供或NFV中的服务功能链接都是需要收集功能集的问题,其中并非所有功能都适合放在单个网络元素中,因此具有利用协作式网络计算方法满足所需功能的潜力。
2.适当的网络元素选择
各种网络元素在计算能力、存储能力和吞吐量方面不同[13]。因此,可以使用各种标准来选择适当的网络元素来处理特定应用程序,例如要在数据包上执行的计算类型和数量、网络元素处理后的扇出数据大小、计算的状态和数据存储在网络元素中所需的大小。我们调查的大多数研究在网络计算范围内使用可编程交换机实现网络计算,而很少有研究考虑在FPGA或智能NIC上实现,而没有讨论网络元素选择的原因。因此,一个研究方向可以是分析应用程序要求和设备功能,以提供适用于特定应用程序的网络元素的适当选择方向。起点可以是[13],[177]的研究。虽然[177]探索了七种最先进的软件交换机的设计空间,并比较了它们在路由NFV流量的特定应用程序下的性能,但[13]具有更一般的视角。事实上,[13]提供了一些基于几个应用程序特征(例如每个数据包的操作数量、数据包处理后所需的存储量和输出大小)实现几个应用程序的指南。然而,它缺乏任何评估来评估所提供的指南。最后,[13]没有谈论像网络安全、网络协调或技术特定应用程序这样的应用程序。
3.网络设备限制与网络计算
网络计算应用程序开发中的一个重要挑战是网络元素在计算和存储方面的限制。当前的网络元素(例如可编程交换机)仅支持在非浮点值上执行有限的算术操作。处理计算限制的方法是实现共同设计方法,其中复杂计算由通用处理器执行,例如 [15],[86]。通过共同设计方法,延迟会增加,但仍然有一部分计算会在网络中以高性能执行。另一种方法是应用简化和近似技术,例如 [79],[81]。这种方法以保持网络性能为代价换取精度。可以进一步研究这些技术,以应对计算限制。
网络元素中存储的数据量受芯片上内存的大小限制(例如可编程交换机的内存容量在几十到几百兆字节的范围内)。最近,一些关于内存限制的增强提出了。例如,[174]通过利用具有远程直接内存访问(RDMA)功能的外部内存扩展了交换机的内存容量。[175]提出通过在机架服务器中安装交换机来扩展顶部交换机的流表。特别是,网络计算应用程序,如网络缓存和网络分析,它们的性能高度依赖于可访问的内存,可以在这些增强的场景中进行研究应用。
4.网络计算的性能方面
文献中的研究已经广泛说明了与基于服务器/控制器/软件的解决方案相比,网络解决方案在延迟和吞吐量方面的表现优越。然而,网络元素(例如可编程交换机、NIC)的性能可能会随着不同的流量负载和不同的数据包大小而变化。例如,在[169]中,讨论了一个具有三个VNF的防火墙VNF链应用程序,当数据包大小小于1280字节且所有VNF都被卸载到智能NIC时,延迟将减少76倍(从软件解决方案的3300微秒到网络解决方案的43微秒)。然而,当数据包大小增加时,NIC上的数据包处理可能会对延迟测量产生负面影响。实际上,在1518字节的数据包中,未卸载和完全卸载之间的延迟提升约为100微秒。在这种情况下,[169]的作者认为适宜将部分VNF卸载到网络中。然而,我们仍然存在一个研究空白,即在各种网络流量和数据包大小的不同条件下评估网络计算的收益,在各种应用程序中这可能是一个潜在的研究方向。
IX.结论
软件定义网络(SDN)、可编程数据平面、边缘计算以及信息/服务中心化网络等协议,使得网络计算(In-Network Computing,INC)成为可能。本文首次对INC这一主题进行了调查研究。所提出的研究分类包括网络内分析、网络内缓存、网络内安全、网络内协调以及针对云/边缘计算、5G/6G和NFV的技术特定应用。相关研究按照提出的方法论/实现相关标准进行比较,例如网络内执行的计算、完全网络内实现或协同设计方法、所使用的网络元素/数据结构,以及在延迟、吞吐量、节省带宽和功耗方面所获得的性能提升。此外,还提出了应用特定标准以进行方案比较。
我们的研究表明,与基于服务器/SDN控制器的方案相比,在考虑应用特定标准时,INC的方案将获得好处。网络内分析可以获得更高的推理速度,并减少数据传输所需的带宽消耗。网络内浅/深度缓存方案可以提供边缘存储,从而减少内容访问延迟、内容传输所需的带宽消耗,并提供更好的请求服务平衡。网络内安全方案可以降低缓解延迟,并减少所需的流量分析所需的带宽消耗。与基于服务器/专用硬件的方案相比,将技术(例如新一代移动通信的无线接入网/移动数据核心功能、虚拟网络功能、边缘智能)的功能实现在网络内,将减少所需的计算成本和功耗,并提供更低的延迟和更高的吞吐量。
然而,我们的研究表明,由于网络元素的硬件限制,存在可能妥协的应用特定标准。针对每个应用类别,已在调查研究中广泛讨论了妥协标准和应对硬件限制的技术。此外,协同设计方法已被研究作为将INC与通用计算丰富的机制,对于各种应用类别,已经讨论了完全网络内实现方案的好处和妥协的应用特定标准。为了处理混合计算环境,还提供了针对技术特定应用程序的资源分配方案的补充评估。
最后,我们讨论了这一新兴领域的潜在研究方向。
引用
[1] Q. Zhang, L. Cheng, and R. Boutaba, “Cloud computing: State-of-the- art and research challenges,” J. Internet Services Appl., vol. 1, pp. 7– 18, Apr. 2010.
[2] V. Ziegler et al., “6G architecture to connect the worlds,” IEEE Access, vol. 8, pp. 173508– 173520, 2020.
[3] M. Agiwal, A. Roy, and N. Saxena, “Next generation 5G wireless
networks: A comprehensive survey,” IEEE Commun. Surveys Tuts., vol. 18, no. 3, pp. 1617– 1655, 3rd Quart., 2016.
[4] “Amazon Cloud Service.” [Online]. Available: https://aws.amazon.com/ ec2/instance-types/
[5] C. Mouradian et al., “A comprehensive survey on fog computing: State-of-the-art and research challenges,” IEEE Commun. Surveys Tuts., vol. 20, no. 1, pp. 416–464, 1st Quart., 2018.
[6] A. J. Ferrer, J. M. Marquès, and J. Jorba, “Towards the decentralised
cloud: Survey on approaches and challenges for mobile, ad hoc, and edge computing,” ACM Comput. Surveys, vol. 51, no. 6, pp. 1–36,
2019.
[7] M. Mehrabi et al., “Device-enhanced MEC: Multi-access edge comput-
ing (MEC) aided by end device computation and caching: A survey,” IEEE Access, vol. 7, pp. 166079– 166108, 2019.
[8] B. A. A. Nunes et al., “A survey of software-defined networking:
Past, present, and future of programmable networks,” IEEE Commun. Surveys Tuts., vol. 16, no. 3, pp. 1617– 1634, 3rd Quart., 2014.
[9] N. McKeown et al., “OpenFlow: Enabling innovation in campus networks,” ACM SIGCOMM Comput. Commun. Rev., vol. 38, no. 2, pp. 69–74, 2008.
[10] R. Bifulco and G. Rétvári, “A survey on the programmable data plane:
Abstractions, architectures, and open problems,” in Proc. Conf. High Perform. Switch. Routing, 2018, pp. 1–7.
[11] S. Han, S. Jang, H. Choi, H. Lee, and S. Pack, “Virtualization in
programmable data plane: A survey and open challenges,” IEEE J. Commun. Soc., vol. 1, pp. 527–534, 2020.
[12] A. Sapio et al., “In-network computation is a dumb idea whose time has come,” in Proc. Conf. Hot Topics Netw., 2017, pp. 150– 156.
[13] D. R. Ports and J. Nelson, “When should the network be the computer?” in Proc. Conf. Hot Topics Oper. Syst., 2019, pp. 209–215.
[14] “Intel Second-Generation Programmable Switch.” [Online]. Available: https://www.intel.com/content/www/us/en/products/network-io/ programmable-ethernet- switch
[15] T. Mai, H. Yao, S. Guo, and Y. Liu, “In-network computing powered
mobile edge: Toward high performance industrial IoT,” IEEE Netw., vol. 35, no. 1, pp. 289–295, Jan./Feb. 2021.
[16] “Sigarch.” [Online]. Available: https://www.sigarch.org/in-network- computing-draft/
[17] H. Stubbe, “P4 compiler & interpreter: A survey,” J. Future Internet Innov. Internet Technol. Mobile Commun., vol. 47, pp. 1–6, May 2017.
[18] E. Kaljic, A. Maric, P. Njemcevic, and M. Hadzialic, “A survey on data plane flexibility and programmability in software-defined networking,” IEEE Access, vol. 7, pp. 47804–47840, 2019.
[19] X. Zhang, L. Cui, K. Wei, F. P. Tso, Y. Ji, and W. Jia, “A survey on stateful data plane in software defined networks,” J. Comput. Netw., vol. 184, Jan. 2021, Art. no. 107597.
[20] T. Dargahi et al., “A survey on the security of stateful SDN data planes,” IEEE Commun. Surveys Tuts., vol. 19, no. 3, pp. 1701– 1725, 3rd Quart., 2017.
[21] W. L. da Costa Cordeiro, J. A. Marques, and L. P. Gaspary, “Data
plane programmability beyond OpenFlow: Opportunities and chal- lenges for network and service operations and management,” J. Netw. Syst. Manag., vol. 25, no. 4, pp. 784–818, 2017.
[22] E. F. Kfoury, J. Crichigno, and E. Bou-Harb, “An exhaustive sur-
vey on P4 programmable data plane switches: Taxonomy, applications, challenges, and future trends,” IEEE Access, vol. 9, pp. 87094–87155,
2021.
[23] M. G. Venkata, G. Bloch, G. Shainer, and R. Graham, “Accelerating OpenSHMEM collectives using in-network computing approach,” in Proc. Symp. Comput. Architect. High Perform. Comput., 2019, pp. 212–219.
[24] E. Bulut and M. Yuksel, “Integrating in-network computing for secure
and efficient cascaded delivery in DTNs,” in Proc. Workshop Netw.
Meets Intell. Comput., 2019, pp. 19–24.
[25] I. Kettaneh et al., “Falcon: Low latency, network-accelerated schedul- ing,” in Proc. P4 Workshop Europe, 2020, pp. 7– 12.
[26] F. Yang et al., “Understanding the performance of in-network comput-
ing: A case study,” in Proc. IEEE Conf. Parallel Distrib. Process. Appl. Big Data Cloud Comput. Sustain. Comput. Commun. Soc. Comput.
Netw., 2019, pp. 26–35.
[27] Y. Tokusashi et al., “The case for in-network computing on demand,” in Proc. EuroSys Conf., 2019, pp. 1– 16.
[28] M. Blöcher, L. Wang, P. Eugster, and M. Schmidt, “Switches for HIRE: Resource scheduling for data center in-network computing,” in Proc. ACM Conf. Archit. Support Program. Lang. Oper. Syst., 2021, pp. 268–285.
[29] R. L. Graham et al., “Scalable hierarchical aggregation protocol
(SHARP): A hardware architecture for efficient data reduction,” in Proc. Workshop Commun. Optim. HPC, 2016, pp. 1– 10.
[30] T. A. Benson, “In-network compute: Considered armed and dangerous,” in Proc. Workshop Hot Topics Oper. Syst., 2019, pp. 216–224.
[31] P. G. Kannan and M. C. Chan, “On programmable networking evolution,” CSI Trans. ICT, vol. 8, pp. 69–76, May 2020.
[32] A. Doria et al., “Forwarding and control element separation (ForCES)
protocol specification,” IETF, RFC 5810, 2010.
[33] “Floodlight, An Open SDN Controller.” [Online]. Available: https:// floodlight.atlassian.net/wiki/spaces/floodlightcontroller/overview
[34] “Beacon.” [Online]. Available: https://openflow.stanford.edu/display/ beacon/home
[35] M. R. Nascimento et al., “Virtual routers as a service: The routeflow approach leveraging software-defined networks,” in Proc. Conf. Future Internet Technol., 2011, pp. 34–37.
[36] A. Doria et al., “Forwarding and control element separation (ForCES)
protocol specification,” IETF, RFC 5810, 2010.
[37] “Barefoot Tofino: World’s Fastest P4-Programmable Ethernet Switch ASICs.” [Online]. Available: https://www.intel.com/content/www/us/ en/products/network-io/programmable-ethernet- switch/tofino- series/ tofino.html
[38] “XPliant Ethernet Switch Product Family.” [Online]. Available: https: //www.openswitch.net/cavium/
[39] “Intel FlexPipe.” [Online]. Available: https://www.intel.com/content/ dam/www/public/us/en/documents/product-briefs/ethernet- switch- fm6000- series-brief.pdf
[40] B. Pfaff et al., “The design and implementation of Open vSwitch,” in Proc. USENIX Symp. Netw. Syst. Design Implement., 2015, pp. 117– 130.
[41] M. Shahbaz et al., “Pisces: A programmable, protocol-independent software switch,” in Proc. ACM SIGCOMM Conf., 2016, pp. 525–538.
[42] A. Panda et al., “NetBricks: Taking the V out of NFV,” in Proc.USENIX Symp. Oper. Syst. Design Implement., 2016, pp. 203–216.
[43] “BMv2 Software Switch.” [Online]. Available: http://bmv2.org/
[44] N. Gebara et al., “Challenging the stateless quo of programmable switches,” in Proc. ACM Workshop Hot Topics Netw., 2020, pp. 153– 159.
[45] P. Shantharama, A. S. Thyagaturu, and M. Reisslein, “Hardware-
accelerated platforms and infrastructures for network functions: A survey of enabling technologies and research studies,” IEEE Access, vol. 8, pp. 132021– 132085, 2020.
[46] O. Michel, R. Bifulco, G. Retvari, and S. Schmid, “The programmable
data plane: Abstractions, architectures, algorithms, and applications,” ACM Comput. Surveys, vol. 54, no. 4, pp. 1–36, 2021.
[47] N. Zilberman, Y. Audzevich, G. A. Covington, and A. W. Moore,
“NetFPGA SUME: Toward 100 Gbps as research commodity,” IEEE Micro, vol. 34, no. 5, pp. 32–41, Sep./Oct. 2014.
[48] A. Forencich, A. C. Snoeren, G. Porter, and G. Papen, “Corundum: An open-source 100-Gbps NIC,” in Proc. Symp. Field Program. Custom
Comput. Mach., 2020, pp. 38–46.
[49] G. P. Katsikas, T. Barbette, M. Chiesa, D. Kosti, and G. Q. Maguire,
“What you need to know about (SMART) network interface cards,” in Proc. Conf. Passive Active Netw. Meas., 2021, pp. 319–336.
[50] P. M. Phothilimthana et al., “FLOEM: A programming system for NIC- accelerated network applications,” in Proc. USENIX Symp. Oper. Syst. Design Implement., 2018, pp. 663–679.
[51] S. Choi, M. Shahbaz, B. Prabhakar, and M. Rosenblum, “λ-NIC:
Interactive serverless compute on programmable smartNICs,” in Proc. Conf. Distrib. Comput. Syst., 2020, pp. 67–77.
[52] “P4: Language Specification.” [Online]. Available: https: //opennetworking.org/wp-content/uploads/2020/10/P416-language- specification.html#fig-p4prg
[53] G. Bianchi, M. Bonola, A. Capone, and C. Cascone, “OpenState:
Programming platform-independent stateful OpenFlow applications inside the switch,” ACM SIGCOMM Comput. Commun. Rev., vol. 44, no. 2, pp. 44–51, 2014.
[54] A. Sivaraman et al., “Packet trans.: High-level programming for line- rate switches,” in Proc. ACM SIGCOMM Conf., 2016, pp. 15–28.
[55] C. J. Anderson et al., “NetKAT: Semantic foundations for networks,” ACM Sigplan Notices, vol. 49, no. 1, pp. 113– 126, 2014.
[56] P. Bosshart et al., “P4: Programming protocol-independent packet pro- cessors,” ACM SIGCOMM Comput. Commun. Rev., vol. 44, no. 3, pp. 87–95, 2014.
[57] M. Satyanarayanan, P. Bahl, R. Caceres, and N. Davies, “The case for VM-based cloudlets in mobile computing,” IEEE Pervasive Comput., vol. 8, no. 4, pp. 14–23, Oct.–Dec. 2009.
[58] S. Ali, M. Pandey, and N. Tyagi, “Wireless-fog mesh: A framework for in-network computing of microservices in semipermanent smart environments,” J. Netw. Manag., vol. 30, no. 6, 2020, Art. no. e2125.
[59] X. Zhang, L. Cui, F. P. Tso, and W. Jia, “pHeavy: Predicting heavy flows in the programmable data plane,” IEEE Trans. Netw. Service Manag., vol. 18, no. 4, pp. 4353–4364, Dec. 2021.
[60] Y. Afek, A. Bremler-Barr, and L. Shafir, “Network anti-spoofing with
SDN data plane,” in Proc. Conf. Comput. Commun., 2017, pp. 1–9.
[61] T.-Y. Lin et al., “Mitigating SYN flooding attack and ARP spoofing in
SDN data plane,” in Proc. Asia–Pac. Netw. Oper. Manag. Symp., 2020, pp. 114– 119.
[62] A. Yazdinejad, R. M. Parizi, A. Dehghantanha, and K.-K. R. Choo, “P4-to-blockchain: A secure blockchain-enabled packet parser for soft- ware defined networking,” J. Comput. Security, vol. 88, Jan. 2020, Art. no. 101629.
[63] A. Morrison, L. Xue, A. Chen, and X. Luo, “Enforcing context-aware BYOD policies with in-network security,” in Proc. USENIX Workshop Hot Topics Cloud Comput., 2018, pp. 1–9.
[64] Q. Kang et al., “Programmable in-network security for context-aware
BYOD policies,” in Proc. USENIX Security Symp., 2020, pp. 595–612.
[65] V. Kalogeraki, D. Gunopulos, and D. Zeinalipour-Yazti, “A local search mechanism for peer-to-peer networks,” in Proc. Conf. Inf. Knowl.
Manag., 2002, pp. 300–307.
[66] Q. Lv et al., “Search and replication in unstructured peer-to-peer networks,” in Proc. Conf. Supercomput., 2002, pp. 84–95.
[67] M. Gritter and D. R. Cheriton, “An architecture for content routing support in the Internet,” in Proc. Symp. Internet Technol. Syst., vol. 1,
2001, pp. 37–48.
[68] G. Xylomenos et al., “A survey of information-centric networking research,” IEEE Commun. Surveys Tuts., vol. 16, no. 2, pp. 1024– 1049, 2nd Quart., 2013.
[69] X. Li, R. Xie, F. R. Yu, T. Huang, and Y. Liu, “Advancing software- defined service-centric networking toward in-network intelligence,” IEEE Netw., vol. 35, no. 5, pp. 210–218, Sep./Oct. 2021.
[70] A. Nasrallah et al., “Ultra-low latency (ULL) networks: The IEEE
TSN and IETF DetNet standards and related 5G ULL research,” IEEE Commun. Surveys Tuts., vol. 21, no. 1, pp. 88– 145, 1st Quart., 2018.
[71] R. Ahmed and R. Boutaba, “A survey of distributed search tech- niques in large scale distributed systems,” IEEE Commun. Surveys Tuts., vol. 13, no. 2, pp. 150– 167, 2nd Quart., 2010.
[72] A. Biswas, S. Mohan, and R. Mahapatra, “Optimization of semantic routing table,” in Proc. Conf. Comput. Commun. Netw., 2008, pp. 1–6.
[73] R. F. Martins, F. L. Verdi, R. Villaça, and L. F. U. Garcia, “Using probabilistic data structures for monitoring of multi-tenant P4-based networks,” in Proc. IEEE Symp. Comput. Commun., 2018, pp. 204–207.
[74] F. Yang et al., “SwitchAgg: A further step towards in-network com- puting,” in Proc. IEEE Conf. Parallel Distrib. Process. Appl. Big Data Cloud Comput. Sustain. Comput. Commun. Soc. Comput. Netw., 2019, pp. 36–45.
[75] A. L. R. Madureira, F. R. C. Araújo, and L. N. Sampaio, “On sup-
porting IoT data aggregation through programmable data planes,” J. Comput. Netw., vol. 177, Aug. 2020, Art. no. 107330.
[76] C. Li and H. Dai, “Efficient in-network computing with noisy wireless channels,” IEEE Trans. Mobile Comput., vol. 12, no. 11, pp. 2167–2177, Nov. 2013.
[77] C. Li et al., “Towards efficient designs for in-network computing with noisy wireless channels,” in Proc. IEEE INFOCOM Conf., 2010, pp. 1–8.
[78] Z. Xiong and N. Zilberman, “Do switches dream of machine learning? Toward in-network classification,” in Proc. ACM Workshop Hot Topics Netw., 2019, pp. 25–33.
[79] D. Sanvito, G. Siracusano, and R. Bifulco, “Can the network be the AI accelerator?” in Proc. Workshop In Netw. Comput., 2018, pp. 20–25.
[80] Y.-S. Lu and K. C.-J. Lin, “Enabling inference inside software switches,” in Proc. Asia–Pac. Netw. Oper. Manag. Symp., 2019, pp. 1–4.
[81] Q. Qin, K. Poularakis, K. K. Leung, and L. Tassiulas, “Line-speed and scalable intrusion detection at the network edge via federated learning,” in Proc. Netw. Conf., 2020, pp. 352–360.
[82] V. Sivaraman et al., “Heavy-hitter detection entirely in the data plane,” in Proc. Symp. SDN Res., 2017, pp. 164– 176.
[83] R. Harrison, Q. Cai, A. Gupta, and J. Rexford, “Network-wide heavy hitter detection with commodity switches,” in Proc. Symp. SDN Res., 2018, pp. 1–7.
[84] J. Vestin, A. Kassler, and J. Åkerberg, “FastReact: In-network control and caching for industrial control networks using programmable data planes,” in Proc. Conf. Emerg. Technol. Factory Autom., vol. 1, 2018, pp. 219–226.
[85] F. E. R. Cesen et al., “Towards low latency industrial robot control in programmable data planes,” in Proc. IEEE Conf. Netw. Softw., 2020, pp. 165– 169.
[86] A. Gupta et al., “Sonata: Query-driven streaming network telemetry,” in
Proc. ACM Special Interest Group Data Commun., 2018, pp. 357–371.
[87] R. Teixeira, R. Harrison, A. Gupta, and J. Rexford, “PacketScope:
Monitoring the packet lifecycle inside a switch,” in Proc. Symp. SDN Res., 2020, pp. 76–82.
[88] T. Jepsen et al., “Life in the fast lane: A line-rate linear road,” in Proc.
Symp. SDN Res., 2018, pp. 1–7.
[89] T. Kohler et al., “P4CEP: Towards in-network complex event process- ing,” in Proc. Workshop In Netw. Comput., 2018, pp. 33–38.
[90] J. Hypolite et al., “DeepMatch: Practical deep packet inspection in the data plane using network processors,” in Proc. Conf. Emerg. Netw. Exp. Technol., 2020, pp. 336–350.
[91] Y. Tokusashi, H. Matsutani, and N. Zilberman, “LAKE: The power of in-network computing,” in Proc. Conf. Reconfig. Comput. FPGAs, 2018, pp. 1–8.
[92] Q. Wang et al., “Concordia: Distributed shared memory with in- network cache coherence,” in Proc. USENIX Conf. File Storage Technol., 2021, pp. 277–292.
[93] X. Jin et al., “Netcache: Balancing key-value stores with fast in-network caching,” in Proc. Symp. Oper. Syst. Principle, 2017, pp. 121– 136.
[94] M. Liu et al., “Incbricks: Toward in-network computation with an in- network cache,” in Proc. Conf. Archit. Support Program. Lang. Oper. Syst., 2017, pp. 795–809.
[95] Z. Liu et al., “Distcache: Provable load balancing for large-scale storage systems with distributed caching,” in Proc. USENIX Conf. File Storage Technol., 2019, pp. 143– 157.
[96] X. Jin et al., “NetChain: Scale-free sub-RTT coordination,” in Proc.USENIX Symp. Netw. Syst. Design Implement., 2018, pp. 35–49.
[97] V. Jacobson et al., “Networking named content,” in Proc. Conf. Emerg.
Netw. Exp. Technol., 2009, pp. 1– 12.
[98] D. Scholz, S. Gallenmüller, H. Stubbe, and G. Carle, “SYN flood defense in programmable data planes,” in Proc. P4 Workshop Europe, 2020, pp. 13–20.
[99] F. Musumeci et al., “Machine-learning-assisted DDoS attack detection
with P4 language,” in Proc. Conf. Commun., 2020, pp. 1–6.
[100] J. Xing, W. Wu, and A. Chen, “Architecting programmable data plane
defenses into the network with FastFlex,” in Proc. ACM Workshop Hot Topics Netw., 2019, pp. 161– 169.
[101] Â . C. Lapolli, J. A. Marques, and L. P. Gaspary, “Offloading real-time
DDoS attack detection to programmable data planes,” in Proc. Symp. Integr. Netw. Service Manag., 2019, pp. 19–27.
[102] L. A. Q. González et al., “BUNGEE: An adaptive Pushback mechanism
for DDoS detection and mitigation in P4 data planes,” in Proc. Symp. Integr. Netw. Manag., 2021, pp. 393–401.
[103] X. Z. Khooi, L. Csikor, D. M. Divakaran, and M. S. Kang, “DIDA: Distributed in-network defense architecture against amplified reflection DDoS attacks,” in Proc. Conf. Netw. Softw., 2020, pp. 277–281.
[104] K. Friday, E. Kfoury, E. Bou-Harb, and J. Crichigno, “Towards a uni- fied in-network DDoS detection and mitigation strategy,” in Proc. IEEE Conf. Netw. Softw., 2020, pp. 218–226.
[105] M. Zhang et al., “Poseidon: Mitigating volumetric DDoS attacks with programmable switches,” in Proc. Conf. NDSS, 2020, pp. 1–9.
[106] Z. Liu et al., “JAQEN: A high-performance switch-native approach for
detecting and mitigating volumetric DDoS attacks with programmable switches,” in Proc. USENIX Security Symp., 2021, pp. 37–48.
[107] X. Yang, J. Cao, and M. Xu, “SEC: Secure, efficient, and compatible source address validation with packet tags,” in Proc. Perform. Comput. Commun. Conf., 2020, pp. 1–8.
[108] H. Gondaliya, G. C. Sankaran, and K. M. Sivalingam, “Comparative evaluation of IP address anti-spoofing mechanisms using a P4/NetFPGA-based switch,” in Proc. P4 Workshop Europe, 2020, pp. 1–6.
[109] G. Li et al., “NETHCF: Enabling line-rate and adaptive spoofed IP traffic filtering,” in Proc. IEEE Conf. Netw. Protocols, 2019, pp. 1– 12.
[110] J. Bai, J. Bi, M. Zhang, and G. Li, “Filtering spoofed IP traffic using
switching ASICs,” in Proc. ACM SIGCOMM Conf. Posters Demos, 2018, pp. 51–53.
[111] P. Kuang, Y. Liu, and L. He, “P4DAD: Securing duplicate address
detection using P4,” in Proc. IEEE Conf. Commun., 2020, pp. 1–7.
[112] M. Dimolianis, A. Pavlidis, and V. Maglaris, “A multi-feature DDoS
detection schema on P4 network hardware,” in Proc. Conf. Innov. Clouds Internet Netw. Workshops, 2020, pp. 1–6.
[113] P. Vörös et al., “T4P4S: A target-independent compiler for protocol- independent packet processors,” in Proc. Conf. High Perform. Switch. Routing, 2018, pp. 1–8.
[114] C. Monsanto et al., “Composing software defined networks,” in Proc.
USENIX Symp. Netw. Syst. Design Implement., 2013, pp. 1– 13.
[115] P. Vörös and A. Kiss, “Security middleware programming using P4,” in Proc. Conf. Human Aspects Inf. Security Privacy Trust, 2016, pp. 277–287.
[116] R. Datta, S. Choi, A. Chowdhary, and Y. Park, “P4Guard: Designing
P4 based firewall,” in Proc. IEEE Mil. Commun. Conf., 2018, pp. 1–6.
[117] J.-H. Lee and K. Singh, “SwitchTree: In-network computing and traffic analyses with random forests,” J. Neural Comput. Appl., vol. 2020, pp. 1– 12, May 2020.
[118] T. Datta, N. Feamster, J. Rexford, and L. Wang, “SPINE: Surveillance protection in the network elements,” in Proc. USENIX Workshop Free Open Commun. Internet, 2019, pp. 1–9.
[119] D. Chang, W. Sun, and Y. Yang, “A SDN proactive defense mech-
anism based on IP transformation,” in Proc. Conf. Safety Produce Informatization, 2019, pp. 248–251.
[120] G. Liu et al., “P4NIS: Improving network immunity against eavesdrop- ping with programmable data planes,” in Proc. IEEE Conf. Comput. Commun. Workshops, 2020, pp. 91–96.
[121] J. Xing, A. Morrison, and A. Chen, “NetWarden: Mitigating network covert channels without performance loss,” in Proc. USENIX Workshop Hot Topics Cloud Comput., 2019, pp. 1–7.
[122] A. Laraba et al., “Defeating protocol abuse with P4: Application to explicit congestion notification,” in Proc. Netw. Conf., 2020, pp. 431–439.
[123] N. Moustafa and J. Slay, “UNSW-NB15: A comprehensive data set for network intrusion detection systems,” in Proc. Mil. Commun.Inf. Syst. Conf., 2015, pp. 1–6.
[124] A. El Kamel, H. Eltaief, and H. Youssef, “On-the-fly (D)DoS attack mitigation in SDN using deep neural network-based rate limiting,” J. Comput. Commun., vol. 182, pp. 153– 169, Jan. 2022.
[125] H. T. Dang et al., “NetPaxos: Consensus at network speed,” in Proc.
ACM SIGCOMM Symp. Softw. Defined Netw. Res., 2015, pp. 1–7.
[126] H. T. Dang, M. Canini, F. Pedone, and R. Soulé, “Paxos made switch- Y,” ACM SIGCOMM Comput. Commun. Rev., vol. 46, no. 2, pp. 18–24,
2016.
[127] H. T. Dang et al., “P4xos: Consensus as a network service,” IEEE/ACM Trans. Netw., vol. 28, no. 4, pp. 1726– 1738, Aug. 2020.
[128] J. Li, E. Michael, N. K. Sharma, A. Szekeres, and D. R. Ports, “Just
say NO to Paxos overhead: Replacing consensus with network order- ing,” in Proc. USENIX Symp. Oper. Syst. Design Implement., 2016, pp. 467–483.
[129] Y. Zhang, B. Han, Z.-L. Zhang, and V. Gopalakrishnan, “Network-
assisted RAFT consensus algorithm,” in Proc. SIGCOMM Posters Demos, 2017, pp. 94–96.
[130] M. Kogias and E. Bugnion, “HovercRaft: Achieving scalability and fault-tolerance for microsecond-scale datacenter services,” in Proc. Conf. Comput. Syst., 2020, pp. 1– 17.
[131] E. Sakic et al., “P4BFT: A demonstration of hardware-accelerated BFT in fault-tolerant network control plane,” in Proc. ACM SIGCOMM Posters Demos, 2019, pp. 6–8.
[132] E. Sakic, N. Deric, E. Goshi, and W. Kellerer, “P4BFT: Hardware- accelerated Byzantine-resilient network control plane,” in Proc. IEEE Global Commun. Conf., 2019, pp. 1–7.
[133] S. Han, S. Jang, H. Lee, and S. Pack, “Switch-centric Byzantine fault tolerance mechanism in distributed software defined networks,” IEEE Commun. Lett., vol. 24, no. 10, pp. 2236–2239, Oct. 2020.
[134] Z. Yu et al., “Netlock: Fast, centralized lock management using pro- grammable switches,” in Proc. ACM Special Interest Group Data Commun. Appl. Technol. Archit. Protocols Comput. Commun., 2020, pp. 126– 138.
[135] J. Li, E. Michael, and D. R. Ports, “ERIS: Coordination-free consistent trans. using in-network concurrency control,” in Proc. Symp. Oper. Syst. Principle, 2017, pp. 104– 120.
[136] Z. István, D. Sidler, G. Alonso, and M. Vukolic, “Consensus in a box:
Inexpensive coordination in hardware,” in Proc. USENIX Symp. Netw. Syst. Design Implement., 2016, pp. 425–438.
[137] R. Miao et al., “SilkRoad: Making stateful layer-4 load balancing fast
and cheap using switching ASICs,” in Proc. ACM Special Interest Group Data Commun., 2017, pp. 15–28.
[138] J.-L. Ye, C. Chen, and Y. H. Chu, “A weighted ECMP load balancing
scheme for data centers using P4 switches,” in Proc. Conf. Cloud Netw.,
2018, pp. 1–4.
[139] M. Kogias et al., “R2P2: Making RPCs first-class datacenter citizens,” in Proc. USENIX Annu. Tech. Conf., 2019, pp. 863–880.
[140] R. Gandhi et al., “DUET: Cloud scale load balancing with hardware and software,” ACM SIGCOMM Comput. Commun. Rev., vol. 44, no. 4, pp. 27–38, 2014.
[141] Z. Wu and H. V. Madhyastha, “Rethinking cloud service marketplaces,” in Proc. Workshop Hot Topics Netw., 2016, pp. 134– 140.
[142] G. Lia et al., “Optimal placement of delay-constrained in-network com- puting tasks at the edge with minimum data exchange,” in Proc. IEEE 5G World Forum, 2021, pp. 481–486.
[143] R. A. Cooke and S. A. Fahmy, “A model for distributed in-network and near-edge computing with heterogeneous hardware,” J. Future Gener. Comput. Syst., vol. 105, pp. 395–409, Apr. s2020.
[144] C. Xu et al., “The case for FPGA-based edge computing,” IEEE Trans. Mobile Comput., vol. 21, no. 7, pp. 2610–2619, Jul. 2022.
[145] F. Song et al., “Smart collaborative contract for endogenous access control in massive machine communications,” IEEE Internet Things J., early access, Dec. 10, 2021, doi: 10.1109/JIOT.2021.3134366.
[146] Y. Zhang et al., “Privacy-assured FogCS: Chaotic compressive sensing for secure industrial big image data processing in fog computing,” IEEE Trans. Ind. Informat., vol. 17, no. 5, pp. 3401–3411, May 2021.
[147] A. Aghdai, M. Huang, D. Dai, Y. Xu, and J. Chao, “Transparent edge gateway for mobile networks,” in Proc. Conf. Netw. Protocols, 2018, pp. 412–417.
[148] P. Vörös, G. Pongrácz, and S. Laki, “Towards a hybrid next generation
NodeB,” in Proc. P4 Workshop Europe, 2020, pp. 56–58.
[149] P. Palagummi and K. M. Sivalingam, “SMARTHO: A network initiated handover in NG-RAN using P4-based switches,” in Proc. Conf. Netw. Service Manag., 2018, pp. 338–342.
[150] R. Shah, V. Kumar, M. Vutukuru, and P. Kulkarni, “TurboEPC:Leveraging dataplane programmability to accelerate the mobile packet core,” in Proc. Symp. SDN Res., 2020, pp. 83–95.
[151] S. K. Singh, C. E. Rothenberg, G. Patra, and G. Pongracz, “Offloading virtual evolved packet gateway user plane functions to a programmable ASIC,” in Proc. Workshop Emerg. In Netw. Comput. Paradigms, 2019, pp. 9– 14.
[152] C.-A. Shen et al., “A programmable and FPGA-accelerated GTP offloading engine for mobile edge computing in 5G networks,” in Proc. Conf. Comput. Commun. Workshops, 2019, pp. 1021– 1022.
[153] F. Paolucci et al., “User plane function offloading in P4 switches for enhanced 5G mobile edge computing,” in Proc. Conf. Design Rel. Commun. Netw., 2021, pp. 1–3.
[154] R. Ricart-Sanchez, P. Malagon, J. M. Alcaraz-Calero, and Q. Wang, “P4-NetFPGA-based network slicing solution for 5G MEC archi- tectures,” in Proc. Symp. Archit. Netw. Commun. Syst., 2019, pp. 1–2.
[155] N. Hu, Z. Tian, X. Du, and M. Guizani, “An energy-efficient in-network computing paradigm for 6G,” IEEE Trans. Green Commun. Netw., vol. 5, no. 4, pp. 1722– 1733, Dec. 2021.
[156] X. Wu, Z. Jin, W.-K. Jia, and X. Shi, “Aggregating multiple small-data frames using arithmetic encoding in P4 switches,” in Proc. Annu. Consum. Commun. Netw. Conf., 2021, pp. 1–6.
[157] K. Gökarslan, Y. S. Sandal, and T. Tugcu, “Towards a URLLC-aware programmable data path with P4 for industrial 5G networks,” in Proc. IEEE Conf. Commun. Workshops, 2021, pp. 1–6.
[158] R. Ricart-Sanchez, P. Malagon, J. M. Alcaraz-Calero, and Q. Wang, “Hardware-accelerated firewall for 5G mobile networks,” in Proc. Conf. Netw. Protocols, 2018, pp. 446–447.
[159] R. Ricart-Sanchez et al., “NetFPGA-based firewall solution for 5G multi-tenant architectures,” in Proc. Conf. Edge Comput., 2019, pp. 132– 136.
[160] J. W. Lockwood et al., “NetFPGA—An open platform for Gigabit-rate network switching and routing,” in Proc. Conf. Microelectron. Syst. Educ., 2007, pp. 160– 161.
[161] L. Linguaglossa et al., “Survey of performance acceleration techniques for network function virtualization,” Proc. IEEE, vol. 107, no. 4, pp. 746–764, Apr. 2019.
[162] C. Fernández, S. Giménez, E. Grasa, and S. Bunch, “A P4-enabled RINA interior router for software-defined data centers,” J. Comput., vol. 9, no. 3, p. 70, 2020.
[163] H. Ballani et al., “Enabling end-host network functions,” ACM SIGCOMM Comput. Commun. Rev., vol. 45, no. 4, pp. 493–507, 2015.
[164] R. Kundel et al., “P4-BNG: Central office network functions on pro- grammable packet pipelines,” in Proc. Conf. Netw. Service Manag., 2019, pp. 1–9.
[165] K. Ralf et al., “OpenBNG: Central office network functions on pro- grammable data plane hardware,” J. Netw. Manag., vol. 31, no. 1, 2021, Art. no. e2134.
[166] T. Osin´ski et al., “Unleashing the performance of virtual BNG by offloading data plane to a programmable ASIC,” in Proc. P4 Workshop Europe, 2020, pp. 54–55.
[167] T. Osin´ski, H. Tarasiuk, L. Rajewski, and E. Kowalczyk, “DPPx: A P4- based data plane programmability and exposure framework to enhance NFV services,” in Proc. Conf. Netw. Softw., 2019, pp. 296–300.
[168] T. Osin´ski, M. Kossakowski, H. Tarasiuk, and R. Picard, “Offloading data plane functions to the multi-tenant cloud infrastructure using P4,” in Proc. Symp. Archit. Netw. Commun. Syst., 2019, pp. 1–6.
[169] D. R. Mafioletti et al., “PIaFFE: A place-as-you-go in-network frame-
work for flexible embedding of VNFs,” in Proc. Conf. Commun., 2020, pp. 1–6.
[170] D. Zhang et al., “P4SC: A high performance and flexible framework for service function chain,” IEEE Access, vol. 7, pp. 160982– 160997,
2019.
[171] X. Chen et al., “P4SC: Towards high-performance service function chain implementation on the P4-capable device,” in Proc. Symp. Integr. Netw. Service Manag., 2019, pp. 1–9.
[172] F. B. Lopes, G. L. Nazar, and A. E. Schaeffer-Filho, “VNFAccel: An FPGA-based platform for modular VNF components acceleration,” in Proc. Symp. Integr. Netw. Manag., 2021, pp. 250–258.
[173] D. Moro, G. Verticale, and A. Capone, “A framework for network function decomposition and deployment,” in Proc. Conf. Design Rel. Commun. Netw., 2020, pp. 1–6.
[174] D. Kim et al., “Generic external memory for switch data planes,” in Proc. ACM Workshop Hot Topics Netw., 2018, pp. 1–7.
[175] Y. Xue and Z. Zhu, “Hybrid flow table installation: Optimizing remote placements of flow tables on servers to enhance PDP switches for in- network computing,” IEEE Trans. Netw. Service Manag., vol. 18, no. 1, pp. 429–440, Mar. 2021.
[176] J. Woodruff, M. Ramanujam, and N. Zilberman, “P4DNS: In-network DNS,” in Proc. Symp. Archit. Netw. Commun. Syst., 2019, pp. 1–6.
[177] T. Zhang et al., “Performance benchmarking of state-of-the-art soft- ware switches for NFV,” J. Comput. Netw., vol. 188, Apr. 2021, Art. no. 107861.