
苹果封神头显Vision Pro诞生,直接开启了空间计算之路。
如果开发一个AI助手「贾维斯」,能够让下一代头显在生活中发挥极致,那才真的让人兴奋。
打麻将时,直接问我该弃什么牌?Otter-E给出打牌建议,以后还不是把把胡。

空中飞行时问Otter-E我想停在某个位置,它便会详细讲解让你如何落地。

还有踢球时,也能寻求Otter-E的建议。

甚至,当你看到水里嬉戏的水獭,有感而发,就可以让Otter-E为你做一首五行诗。

以上,便是来自南洋理工大学和微软的研究人员专为AR头显训练的AI助手「Otter-E」。
其实,这是Otter模型的另一个进化体。
Otter是一个基于OpenFlamingo的多模态的模型,在MIMIC-IT上进行了训练,并展示了改进的指令遵循能力和上下文学习。

值得一提的是,Otter在2个消费级的RTX3090 GPU便可跑。

另外,MIMIC-IT横跨了7个图片和视频的数据集,涵盖了各种各样的场景,支持8种语言。
从通用的场景理解,到发现细微差异,再到增强AR头显的第一人称视图理解。

有网友表示,很兴奋能够看到人们为为苹果Vision Pro制作的AI AR应用。

支持8种语言,横跨7个数据集
目前,AI发展最快的领域就集中在对话助手上,AI拥有强大的能力来理解用户的意图,然后执行。
除了大型语言模型(LLMs)的强大概括能力外,指令调优功不可没。
指令调优涉及在一系列不同的高质量的指令上对LLM进行微调。通过指令调优,LLMs获得了对用户意图更强大的理解能力。
虽说LLaVA的性能还算强大,但LLaVA-Instruct-150K仍然存在三个限制。
(1) 有限的视觉多样性。
(2) 以单一的图像作为视觉数据。
(3) 仅有和语言相关的上下文信息:

为了解决这些限制,研究人员引入了多模态上下文指令调整(MIMIC-IT)。
MIMIC-IT有三个最大的特点:
(1) 多样化的视觉场景,包含了一般场景、自我中心视角场景和室内RGB-D图像等不同数据集的图像和视频。
(2) 多个图像(或一个视频)作为视觉数据。
(3) 多模态的语境信息,特点是以多模态格式制定的语境信息,包括多个指令——回应对和多个图像或视频。

论文地址:https://arxiv.org/pdf/2306.05425.pdf
下图为MIMIC-IT的示意图。
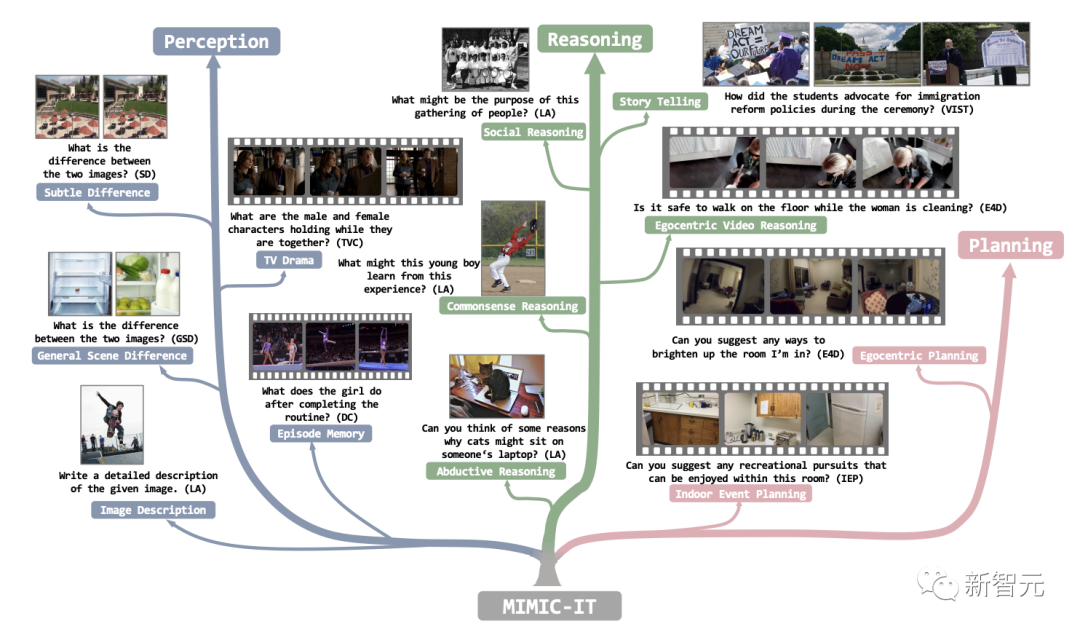
MIMIC-IT的数据集包括280万个多模态指令——反应对,涵盖以下基本能力:感知、推理,以及计划。
每条指令都伴随着多模态的对话背景,使得在MIMIC-IT上训练的VLM能够在交互式指令之后表现出强大的熟练度,并能实现零样本泛化(zero-shot generalization)。
研究人员建立了MIMIC-IT数据集,以支持更多的VLMs获得理解真实世界的能力。
下图是两种模型数据格式的比较:LLaVA-Instruct-150K vs MIMIC-IT
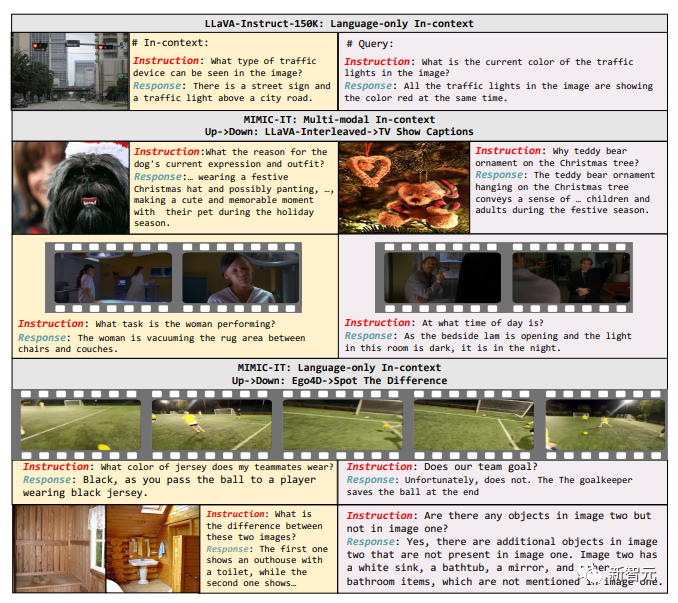
(a) LLaVA-Instruct150K由单一图像和相应的仅有语言的语境信息(黄框部分)组成。
(b) MIMIC-IT在输入数据中容纳了多个图像或视频,并支持多模态的语境信息,即把图像/视频和语言输入都视为语境信息。
同时,研究人员提出了Sythus,这是一个用于生成多语言高质量指令-答案对的自动管道。
在LLaVA提出的框架基础上,研究人员利用ChatGPT来生成基于视觉内容的指令-回应对。
为了确保生成的指令-回应对的质量,研究人员的数据管道将系统信息、视觉注释和上下文中的例子作为ChatGPT的prompt。
由于核心集的质量影响到后续的数据收集过程,研究人员采用了一个冷启动策略。
在冷启动阶段,研究人员采用启发式方法,仅通过系统消息和视觉注释来提示ChatGPT收集上下文中的例子。
这个阶段只有在确定了满意的语境中的例子后才会结束。
在第四步,一旦获得指令-反应对,数据管道将它们扩展为中文(zh)、日文(ja)、西班牙文(es)、德文(de)、法文(fr)、韩文(ko)和阿拉伯语(ar)。
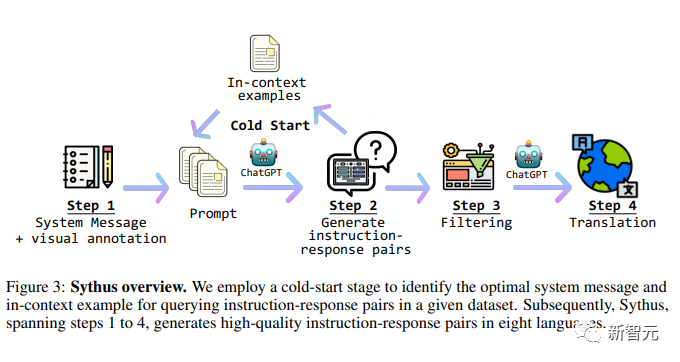
Sythus概述。研究人员采用了一个冷启动阶段来确定最佳的系统信息和语境中的例子,以便在给定的数据集中查询指令-响应对。
随后,Sythus跨越步骤1到4,生成了8种语言的高质量指令-响应对。
下图为MIMIC-IT与其他多模态指令数据集的比较。
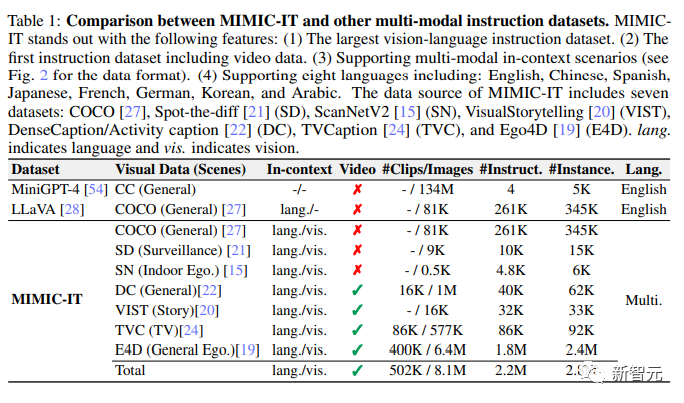
MIMICIT凭借以下特点脱颖而出:
(1) 最大的视觉语言指令数据集。
(2) 第一个包括视频数据的指令数据集。
(3) 支持多模态的上下文场景(数据格式见图2)。
(4) 支持八种语言,包括:英语、中文、西班牙语、日语、法语、德语、韩语和阿拉伯语。
MIMIC-IT的数据源包括七个数据集:COCO, Spot-the-diff, ScanNetV2, VisualStorytelling, DenseCaption/Activity caption, TVCaption, and Ego4D。
其中lang.表示语言,vis.表示视觉。
下图为多模态的语境中指令-反应对的数据统计。
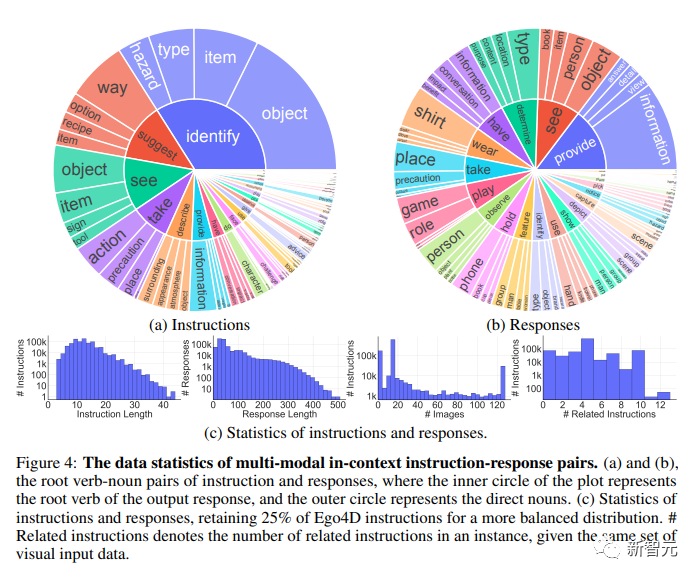
(a)和(b),指令和回应的根动词-名词对,图中内圈代表输出回应的根动词,外圈代表直接名词。
(c)指令和回应的统计,保留了25%的Ego4D指令,以使分布更均衡。

上图表现了Otter在不同场景下的反应实例。
在MIMIC-IT数据集上进行训练后,Otter能够为情境理解和推理、用语境中示例学习,以及自我视觉AI助手。
Otter诞生
研究者展示了MIMIC-IT数据集的各种应用,以及在其上训练的视觉语言模型(VLM)的潜在能力。
研究者首先介绍了Otter,一种使用MIMIC-IT数据集训练的上下文指令调优模型。

接下来,研究人员还探讨了在MIMIC-IT数据集上训练Otter的各种方法,并讨论了可以有效使用Otter的许多场景
- 场景理解和推理
MIMIC-IT数据集包含大约280万个上下文指令-响应对,它们被结构化为一个内聚的模板,以便于完成各种任务。
下面的模板包括图像,用户指令和模型生成的响应,利用人类和助手角色标签,以实现用户与助手的无缝交互。

在MIMIC-IT数据集上训练Otter模型,可以让其获得不同的能力,这一点在LA和SD任务中得到了证明。
在LA任务上的训练,Otter表现出卓越的场景理解力、推理能力和多轮对话能力。同时,在SD任务中,可以熟练地发现日常场景中的一般差异或微妙区别。
如图,在MIMIC-IT数据集上训练后Otter的回应,突出了它在多轮对话中理解和推理的能力。
- 用上下文示例学习
正如前面提到的,关于组织视觉语言在上下文实例的概念,研究人员演示了Otter模型在LA-T2T任务训练后遵循上下文间指令的能力。对于其他任务,输入数据的组织格式如下:

- 自我视觉理解
MIMIC-IT数据集的一个显著特点是,包含了一个第一人称的视频和连续图像的综合集合,来自IEP、E4D场景。
在IEP场景中,内容强调在室内环境中的理解和规划,包含了旨在指导模型根据室内布局进行事件规划的指令和响应。
另一方面,E4D场景专门为第一人称增强现实(AR)头显助理应用定制了指令和响应。
根据这部分数据,研究人员训练了一个自我视觉助手,称为Otter-E,专门为AR头显应用设计的。
MIMIC-IT增强了该模型从第一人称视角感知场景的能力,为即将到来的任务制定策略,并为AR耳机用户提供有价值的见解和建议。
因此,Otter-E模型成为AR头显的一个特殊和有远见的视觉语言模型,为开创性的沉浸式体验铺平道路。
实验评估
如下表,研究人员利用MMAGIBench框架对视觉语言模型的感知和推理能力的广泛评估。
Otter通过在感知和推理任务中实现最高的平均准确性,优于所有基线模型。
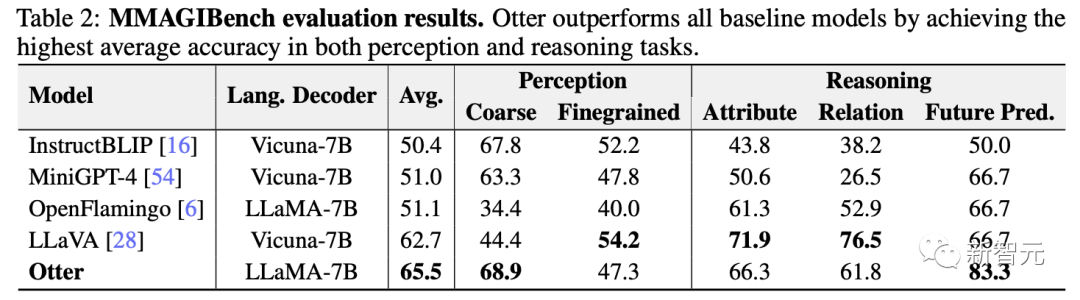
目前视觉语言模型的评估指标,如VQAv2,在稳健性方面存在缺陷。例如,VQAv2主要评估单字或短语的反应,而许多模型则产生句子输出。
为了弥补这一差距,研究人员通过要求ChatGPT将其标签预测,与每个输入的真实标签进行比较来评估这些模型。如果ChatGPT的反应表明预测与相应的标签一致,则认为测试样本是正确的。
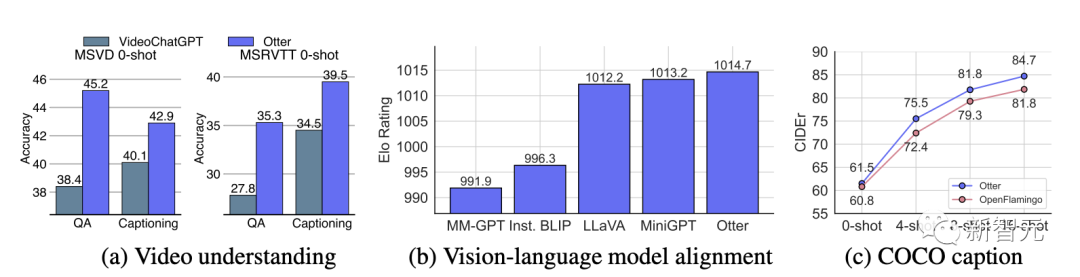
如图,Otter 在视频理解方面的表现优于基线模型。(b)人类评估比较。Otter 展示了优越的实用性和一致性。(c)上下文学习评估中的少量镜头。Otter 优于 OpenFlamingo 作为一个更好的语境和零镜头学习者。
作者介绍
Li Bo

Li Bo是南洋理工大学计算机系一年级博士生,导师是刘子纬。他热衷的深度学习研究话题包括:
基础模型:稳定扩散,GPT,它们似乎有望将具有真正智能的人工智能投入实际应用。
具身AI: 一种通过互动和探索学习解决环境中具有挑战性任务的自主智能体。
这些都是登月计划的狂野梦想,也是Li将长期关注的问题。目前他的第一步研究课题是聚集于真实世界的场景中的计算机视觉和基础模型的新兴能力。
Yuanhan Zhang (张元瀚)

张元瀚是南洋理工的博士生,导师也是刘子纬。他的研究兴趣在于计算机视觉和深度学习。特别是,对表征学习和可转移性感兴趣。
Ziwei Liu(刘子纬)

刘子纬,新加坡南洋理工大学助理教授,并获得南洋学者称号(Nanyang Assistant Professor)。他的研究兴趣包括计算机视觉、机器学习与计算机图形学。
参考资料:
https://www.reddit.com/r/MachineLearning/comments/1460dsr/otter_is_a_multimodal_model_developed_on/
https://otter-ntu.github.io/
https://arxiv.org/pdf/2306.05425.pdf
巴比特园区开放合作啦!



中文推特:https://twitter.com/8BTC_OFFICIAL
英文推特:https://twitter.com/btcinchina
Discord社区:https://discord.gg/defidao
电报频道:https://t.me/Mute_8btc
电报社区:https://t.me/news_8btc
