[TOC]
引言
提供快速部署高可用k8s集群的工具,基于二进制方式部署和利用ansible-playbook实现自动化,既提供一键安装脚本,也可以分步执行安装各个组件,同时讲解每一步主要参数配置和注意事项。
特点
集群特性:TLS 双向认证、RBAC 授权、多Master高可用、支持Network Policy。
门槛
需要掌握基础kubernetes docker linux shell 知识,关于ansible建议阅读 ansible超快入门 基本够用。
环境准备
节点信息
| 节点信息/主机名 | 内网IP | 安装软件 |
|---|---|---|
| master1 | 192.168.16.8 | ansible+calico+API server+scheduler+controller manager+etcd |
| master2 | 192.168.16.9 | calico+API server+scheduler+controller manager+etcd |
| master3 | 192.168.16.15 | calico+API server+scheduler+controller manager+etcd |
| node1 | 192.168.16.10 | calico+kubelet+kube-proxy |
| node2 | 192.168.16.11 | calico+kubelet+kube-proxy |
| node3 | 192.168.16.12 | calico+kubelet+kube-proxy |
| 负载均衡内网 | 192.168.16.16 | |
| harbor主机 | 192.168.16.3 | harbor |
- 为了节约资源,本次部署中,master也作为etcd部署机。
- VPC中创建LB,以
LB-IP:port形式作为kube-apiserver地址,组成多master集群的内部API接口。 - habor主机使用之前harbor部署的即可。
- 各节点云主机的创建概不赘述。
计算节点规格
测试环境,6个节点一律用2C 4G 40G默认磁盘即可。
架构图
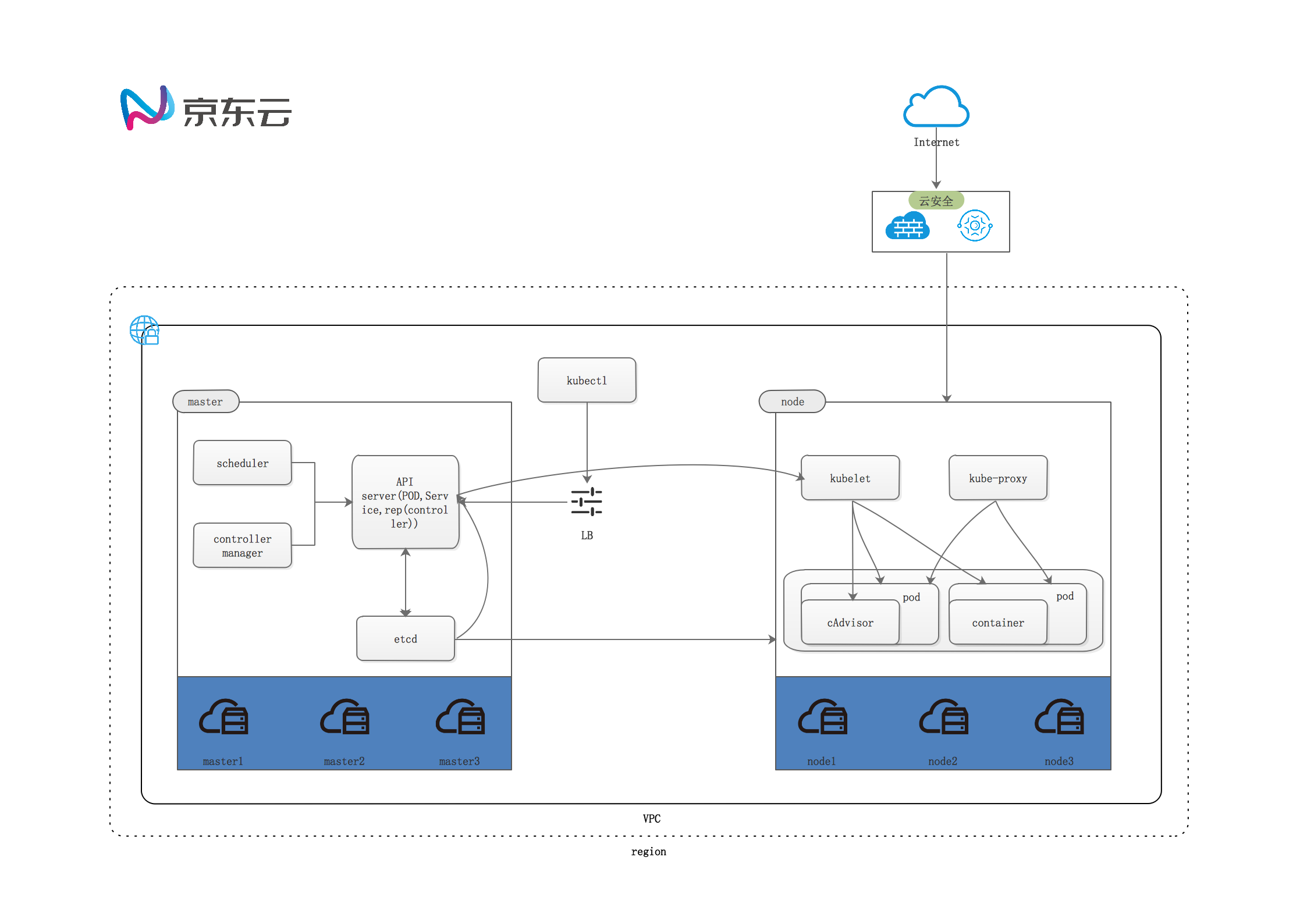 

安装
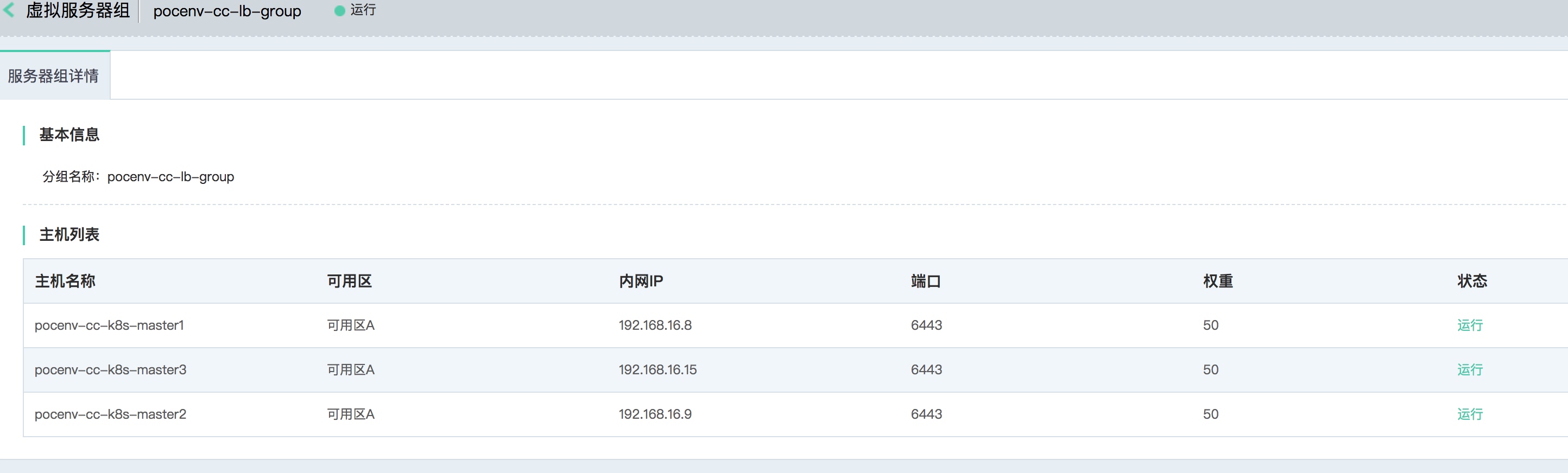
负载均衡信息
公有云已经有负载均衡服务,用来代替haproxy+keepalived解决方案。如下是负载均衡以及相关信息:
虚拟服务器组信息:

监听规则信息 :
 

master1节点操作
通过ansible安装,在6个节点中任意一台节点操作即可,本文中在master1节点操作。
安装依赖以及ansible
ansbile的版本建议在2.4以上,否则会报无法识别模块。
apt-get update && apt-get upgrade -y
apt-get install python2.7 git python-pip
pip install pip --upgrade
pip install ansible安装python加密模块
pip install cryptography --upgrade
#重新安装pyopenssl,否则会报错
pip uninstall pyopenssl
pip install pyopenssl配置ansible ssh密钥
ssh-keygen -t rsa -b 2048 #3个回车
ssh-copy-id $IP #$IP为本虚机地址,按照提示输入yes 和root密码,将密钥发送至各节点(包括本机内网IP)各节点操作
基础软件安装
apt-get update && apt-get upgrade -y && apt-get dist-upgrade -y
apt-get purge ufw lxd lxd-client lxcfs lxc-common -yDNS设置
为了防止/etc/resolv.conf中的DNS被重写,将DNS地址写入/etc/resolvconf/resolv.conf.d/base:
cat << EOF >> /etc/resolvconf/resolv.conf.d/base
nameserver 103.224.222.222
nameserver 103.224.222.223
nameserver 8.8.8.8
EOF修改hostname
hostname分为三种:
pretty hostname: 也就是比较好看的hostname,用来取悦自己的;),如设置为“Zhjwpku’s Laptop”
static hostname: 用来在启动的时候初始化内核的hostname,保存在/etc/hostname中
transient hostname: 瞬态的主机名,是系统运行时临时分配的主机名,例如使用hostname node1 设置的主机名node1就为transient hostname使用hostnamectl可以对以上三种主机名进行设置,如不指定则默认将static跟transient同时设定。
在各节点设置对应的hostname:
#$HostNames是各节点对应的主机名称
hostnamectl set-hostname $HostName 修改/etc/hosts文件
所有节点将节点信息添加至/etc/hosts:
cat <<EOF >> /etc/hosts
192.168.16.8 master1
192.168.16.9 master2
192.168.16.15 master3
192.168.16.10 node1
192.168.16.11 node2
192.168.16.12 node3
192.168.16.3 harbor.jdpoc.com
EOF配置ansible
安装部署操作在master1节点操作即可,使用ansible脚本一键执行。
下载ansible模板以及K8S 1.9.6二进制文件并解压:
cd ~
wget http://chengchen.oss.cn-north-1.jcloudcs.com/ansible.tar.gz
wget http://chengchen.oss.cn-north-1.jcloudcs.com/k8s.196.tar.gz
tar zxf k8s.196.tar.gz
tar zxf ansible.tar.gz
#将bin目录中的文件移动至ansible/bin目录
mv bin/* ansible/bin/
#移动ansible目录至/etc
mv ansible /etc/编辑ansible的配置文件。
cd /etc/ansible
cp example/hosts.m-masters.example hosts
vi hosts根据实际情况修改,本次部署如下配置:
# 部署节点:运行这份 ansible 脚本的节点
# 实际情况修改
[deploy]
192.168.16.8
# etcd集群请提供如下NODE_NAME、NODE_IP变量,注意etcd集群必须是1,3,5,7...奇数个节点
# 实际情况修改
[etcd]
192.168.16.8 NODE_NAME=etcd1 NODE_IP="192.168.16.8"
192.168.16.9 NODE_NAME=etcd2 NODE_IP="192.168.16.9"
192.168.16.15 NODE_NAME=etcd3 NODE_IP="192.168.16.15"
[kube-master]
# 实际情况修改
192.168.16.8 NODE_IP="192.168.16.8"
192.168.16.9 NODE_IP="192.168.16.9"
192.168.16.15 NODE_IP="192.168.16.15"
####################在公有云环境中,可使用负载均衡,无需部署####################
# 负载均衡至少两个节点,安装 haproxy+keepalived
#[lb]
#192.168.1.1 LB_IF="eth0" LB_ROLE=backup # 注意根据实际使用网卡设置 LB_IF变量
#192.168.1.2 LB_IF="eth0" LB_ROLE=master
#[lb:vars]
#master1="192.168.1.1:6443" # 根据实际master节点数量设置
#master2="192.168.1.2:6443" # 需同步设置roles/lb/templates/haproxy.cfg.j2
#master3="192.168.1.x:6443"
#ROUTER_ID=57 # 取值在0-255之间,区分多个instance的VRRP组播,同网段不能重复
#MASTER_PORT="8443" # 设置 api-server VIP地址的服务端口
#################################################################################
# 实际情况修改
[kube-node]
192.168.16.10 NODE_IP="192.168.16.10"
192.168.16.11 NODE_IP="192.168.16.11"
192.168.16.12 NODE_IP="192.168.16.12"
# 如果启用harbor,请配置后面harbor相关参数,如果已有harbor,注释即可
[harbor]
#192.168.1.8 NODE_IP="192.168.1.8"
# 预留组,后续添加master节点使用,无预留注释即可
[new-master]
#192.168.1.5 NODE_IP="192.168.1.5"
# 预留组,后续添加node节点使用,无预留注释即可
[new-node]
#192.168.1.xx NODE_IP="192.168.1.xx"
[all:vars]
# ---------集群主要参数---------------
#集群部署模式:allinone, single-master, multi-master
# 根据实际情况选择:单机部署、单master、多master
DEPLOY_MODE=multi-master
#集群 MASTER IP即 LB节点VIP地址,并根据 LB节点的MASTER_PORT组成 KUBE_APISERVER
# 根据我们之前创建的负载均衡,填写内网IP即可,端口可自定义
MASTER_IP="192.168.16.16"
KUBE_APISERVER="https://192.168.16.16:8443"
#TLS Bootstrapping 使用的 Token,使用 head -c 16 /dev/urandom | od -An -t x | tr -d ' ' 生成
# 在系统中执行以上命令,生成结果替换下面变量即可
BOOTSTRAP_TOKEN="a7383de6fdf9a8cb661757c7b763feb6"
# 集群网络插件,目前支持calico和flannel
# 本次部署使用了calico
CLUSTER_NETWORK="calico"
# 部分calico相关配置,更全配置可以去roles/calico/templates/calico.yaml.j2自定义
# 设置 CALICO_IPV4POOL_IPIP=“off”,可以提高网络性能,条件限制详见 05.安装calico网络组件.md
CALICO_IPV4POOL_IPIP="always"
# 设置 calico-node使用的host IP,bgp邻居通过该地址建立,可手动指定端口"interface=eth0"或使用如下自动发现
# 公有云默认即可
IP_AUTODETECTION_METHOD="can-reach=223.5.5.5"
# 部分flannel配置,详见roles/flannel/templates/kube-flannel.yaml.j2
FLANNEL_BACKEND="vxlan"
# 服务网段 (Service CIDR),部署前路由不可达,部署后集群内使用 IP:Port 可达
SERVICE_CIDR="10.68.0.0/16"
# POD 网段 (Cluster CIDR),部署前路由不可达,**部署后**路由可达
CLUSTER_CIDR="172.21.0.0/16"
# 服务端口范围 (NodePort Range)
NODE_PORT_RANGE="20000-40000"
# kubernetes 服务 IP (预分配,一般是 SERVICE_CIDR 中第一个IP)
CLUSTER_KUBERNETES_SVC_IP="10.69.0.1"
# 集群 DNS 服务 IP (从 SERVICE_CIDR 中预分配)
CLUSTER_DNS_SVC_IP="10.69.0.2"
# 集群 DNS 域名
CLUSTER_DNS_DOMAIN="cluster.local."
# etcd 集群间通信的IP和端口, **根据实际 etcd 集群成员设置**
ETCD_NODES="etcd1=https://192.168.16.8:2380,etcd2=https://192.168.16.9:2380,etcd3=https://192.168.16.15:2380"
# etcd 集群服务地址列表, **根据实际 etcd 集群成员设置**
ETCD_ENDPOINTS="https://192.168.16.8:2379,https://192.168.16.9:2379,https://192.168.16.15:2379"
# 集群basic auth 使用的用户名和密码
BASIC_AUTH_USER="admin"
BASIC_AUTH_PASS="jdtest1234"
# ---------附加参数--------------------
#默认二进制文件目录
bin_dir="/root/local/bin"
#证书目录
ca_dir="/etc/kubernetes/ssl"
#部署目录,即 ansible 工作目录,建议不要修改
base_dir="/etc/ansible"
#私有仓库 harbor服务器 (域名或者IP),如已有harbor,注释即可
#HARBOR_IP="192.168.16.3"
#HARBOR_DOMAIN="harbor.jdpoc.com"快速安装kubernetes 1.9
以下两种安装选择一种模式安装即可。
分步安装
按顺序执行01-06 yaml文件:
cd /etc/ansible
ansible-playbook 01.prepare.yml
ansible-playbook 02.etcd.yml
ansible-playbook 03.docker.yml
ansible-playbook 04.kube-master.yml
ansible-playbook 05.kube-node.yml
ansible-playbook 06.network.yml如出错,根据实际错误信息核实/etc/ansible/hosts文件中的配置。
一步安装
cd /etc/ansible
ansible-playbook 90.setup.yml清理
如果部署错误,可选择清理已安装程序:
cd /etc/ansible
ansible-playbook 99.clean.yml部署集群DNS
DNS 是 k8s 集群首先需要部署的,集群中的其他 pods 使用它提供域名解析服务;主要可以解析 集群服务名 SVC 和 Pod hostname;目前 k8s v1.9+ 版本可以有两个选择:kube-dns和 coredns,可以选择其中一个部署安装。此次部署中使用kubedns。
kubectl create -f /etc/ansible/manifests/kubedns- 集群 pod默认继承 node的dns 解析,修改 kubelet服务启动参数
--resolv-conf="",可以更改这个特性,详见 kubelet 启动参数 - 如果使用calico网络组件,直接安装dns组件,可能会出现如下BUG,分析是因为calico分配pod地址时候会从网段的第一个地址(网络地址)开始,临时解决办法为手动删除POD,重新创建后获取后面的IP地址
# BUG出现现象
$ kubectl get pod --all-namespaces -o wide
NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE
default busy-5cc98488d4-s894w 1/1 Running 0 28m 172.20.24.193 192.168.97.24
kube-system calico-kube-controllers-6597d9c664-nq9hn 1/1 Running 0 1h 192.168.97.24 192.168.97.24
kube-system calico-node-f8gnf 2/2 Running 0 1h 192.168.97.24 192.168.97.24
kube-system kube-dns-69bf9d5cc9-c68mw 0/3 CrashLoopBackOff 27 31m 172.20.24.192 192.168.97.24
# 解决办法,删除pod,自动重建
$ kubectl delete pod -n kube-system kube-dns-69bf9d5cc9-c68mw验证DNS服务
新建一个测试nginx服务
kubectl run nginx --image=nginx --expose --port=80确认nginx服务:
root@master1:/etc/ansible/manifests/kubedns# kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-7587c6fdb6-vjnss 1/1 Running 0 30m测试pod busybox:
root@master1:/etc/ansible/manifests/kubedns# kubectl run busybox --rm -it --image=busybox /bin/sh
If you don't see a command prompt, try pressing enter.
/ # cat /etc/resolv.conf
nameserver 10.69.0.2
search default.svc.cluster.local. svc.cluster.local. cluster.local.
options ndots:5
/ # nslookup nginx
Server: 10.69.0.2
Address 1: 10.69.0.2 kube-dns.kube-system.svc.cluster.local
Name: nginx
Address 1: 10.69.152.34 nginx.default.svc.cluster.local
/ # nslookup www.baidu.com
Server: 10.69.0.2
Address 1: 10.69.0.2 kube-dns.kube-system.svc.cluster.local
Name: www.baidu.com
Address 1: 220.181.112.244
Address 2: 220.181.111.188如果能解析成功nginx与外网域名,说明dns部署成功,如果无法解析,说明kube-dns有问题,请通过kubectl get pod --all-namespaces -o wide,获取到kube-dns所在node节点,并通过docker logs查看详细日志,有很大概率是由于上文提到的BUG导致的。
部署dashboard
部署:
kubectl create -f /etc/ansible/manifests/dashboard/kubernetes-dashboard.yaml
#可选操作:部署基本密码认证配置,密码文件位于 /etc/kubernetes/ssl/basic-auth.csv
kubectl create clusterrolebinding login-on-dashboard-with-cluster-admin --clusterrole=cluster-admin --user=admin
kubectl create -f /etc/ansible/manifests/dashboard/ui-admin-rbac.yaml验证:
# 查看pod 运行状态
kubectl get pod -n kube-system | grep dashboard
kubernetes-dashboard-7c74685c48-9qdpn 1/1 Running 0 22s
# 查看dashboard service
kubectl get svc -n kube-system|grep dashboard
kubernetes-dashboard NodePort 10.68.219.38 <none> 443:24108/TCP 53s
# 查看集群服务,获取访问地址
root@master1:~# kubectl cluster-info
Kubernetes master is running at https://192.168.16.16:8443
# 此处就是我们要获取到的dashboard的URL地址。
kubernetes-dashboard is running at https://192.168.16.16:8443/api/v1/namespaces/kube-system/services/https:kubernetes-dashboard:/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.
# 查看pod 运行日志,关注有没有错误
kubectl logs kubernetes-dashboard-7c74685c48-9qdpn -n kube-system访问页面时,将访问URL中的IP地址更换为负载均衡的外网IP地址,打开页面后会显示如下信息:

获取访问token:
kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep admin-user | awk '{print $1}')打开页面出现dashboard 新版本自带的登陆页面,我们选择“令牌(Token)”方式登陆,粘贴获取到的token,点击登陆:
 

部署heapster
Heapster 监控整个集群资源的过程:首先kubelet内置的cAdvisor收集本node节点的容器资源占用情况,然后heapster从kubelet提供的api采集节点和容器的资源占用,最后heapster 持久化数据存储到influxdb中(也可以是其他的存储后端,Google Cloud Monitoring等)。
Grafana 则通过配置数据源指向上述 influxdb,从而界面化显示监控信息。
部署
部署很简单,执行如下命令即可:
kubectl create -f /etc/ansible/manifests/heapster/验证
root@master1:~# kubectl get pods -n kube-system |grep -E "heapster|monitoring"
heapster-7f8bf9bc46-w6xbr 1/1 Running 0 2d
monitoring-grafana-59c998c7fc-gks5j 1/1 Running 0 2d
monitoring-influxdb-565ff5f9b6-xth2x 1/1 Running 0 2d查看日志:
kubectl logs heapster-7f8bf9bc46-w6xbr -n kube-system
kubectl logs monitoring-grafana-59c998c7fc-gks5j -n kube-system
kubectl logs monitoring-influxdb-565ff5f9b6-xth2x -n kube-system访问grafana
#获取grafana的URL连接
root@master1:~# kubectl cluster-info | grep grafana
monitoring-grafana is running at https://192.168.16.16:8443/api/v1/namespaces/kube-system/services/monitoring-grafan/proxy打开连接:
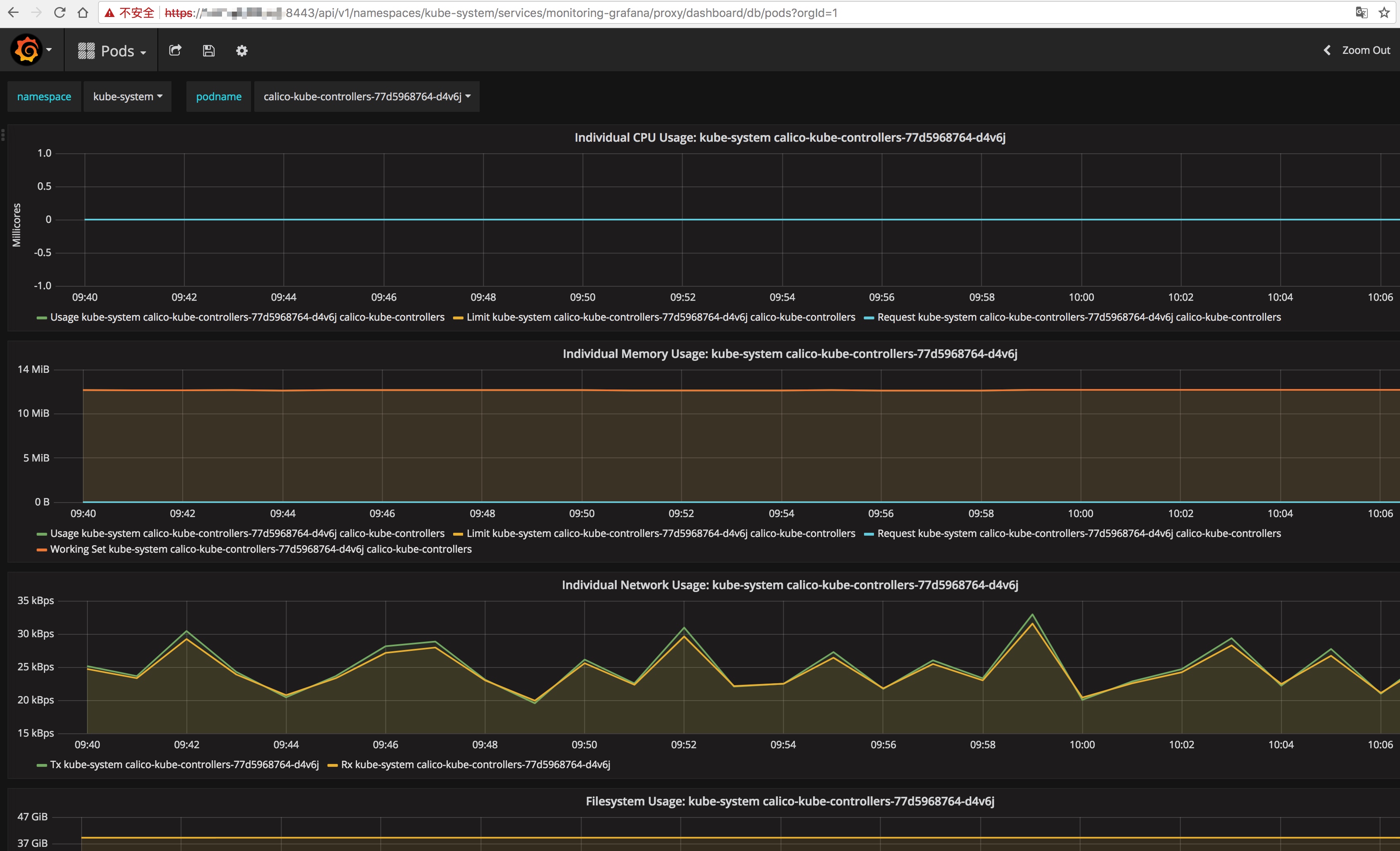 

可以看到各 Nodes、Pods 的 CPU、内存、负载等利用率曲线图,如果 dashboard上还无法看到利用率图,使用以下命令重启 dashboard pod:
- 首先删除
kubectl scale deploy kubernetes-dashboard --replicas=0 -n kube-system - 然后新建
kubectl scale deploy kubernetes-dashboard --replicas=1 -n kube-system
部署完heapster,直接使用 kubectl 客户端工具查看资源使用
# 查看node 节点资源使用情况
$ kubectl top node
# 查看各pod 的资源使用情况
$ kubectl top pod --all-namespaces