一、雪花算法SnowFlake是什么?
SnowFlake是Twitter公司采用的一种算法,目的是在分布式系统中产生全局唯一且趋势递增的ID。
雪花算法这一在分布式架构中很常见的玩意,但一般也不需要怎么去深入了解
- 一方面,一般个人项目用不到分布式之类的大型架构
- 另一方面,就算要用到,市面上很多ID生成器也帮我们完成了这项工作。
二、分库分表带来的问题之全局主键避重问题
2.1 问题详细描述
在生成表主键ID时,可考虑主键自增 或者 UUID,但它们都有很明显的缺点
主键自增:
(1)自增ID容易被爬虫遍历数据。
(2)分表分库会有ID冲突。
UUID:
(1)太长,并且有索引碎片,索引多占用空间的问题
(2)无序。无法做到根据主键排序。
2.2问题解决方法
可考虑通过雪花ID来作为数据库的主键,雪花算法就很适合在分布式场景下生成唯一ID,它既可以保证唯一又可以排序。
为了提高生产雪花ID的效率,在这里面数据的运算都采用的是位运算
雪花ID:静态内部类单例模式实现雪花算法:https://www.cnblogs.com/qdhxhz/p/11372658.html
三、分布式ID的特点
3.1 全局唯一性
不能出现有重复的ID标识,这是基本要求。
3.2 递增性
确保生成ID,对于用户或业务是递增的。
3.3 高可用性
确保任何时候,都能生成正确的ID。
3.4 高性能性
在高并发的环境下,依然表现良好。
四、分布式ID的常见解决方案以及选型
4.1UUID
4.1.1 简介
Java自带的,生成一串唯一随机36位字符串(32个字符串+4个“-”)的算法。
4.1.2 优点
- 可保证唯一性
- 且据说够用N亿年
4.1.3 缺点
- 业务可读性差
- 无法有序递增
4.2 雪花算法SnowFlake
4.2.1 简介
它是Twitter开源的由64位整数组成分布式ID
https://github.com/twitter-archive/snowflake
4.2.2 优点
性能较高
在单机上递增
4.3 UidGenerator
4.3.1 简介
百度开源的分布式ID生成器
基于雪花算法实现
https://github.com/baidu/uid-generator/blob/master/README.zh_cn.md
4.4 Leaf
4.1.1 简介
- 美团开源的分布式ID生成器
- 美团点评分布式ID生成系统
https://tech.meituan.com/2017/04/21/mt-leaf.html
https://tech.meituan.com/MT_Leaf.html
4.1.2 优点
能保证全局唯一
趋势递增
4.1.3 缺点
需要依赖关系数据库、ZK等中间件
五、雪花算法的组成部分
由于在Java中64bit的整数是long类型,所以在Java中SnowFlake算法生成的id就是long来存储的。
SnowFlake算法生成ID的结果是一个64bit大小的整数,它的结构如下图:
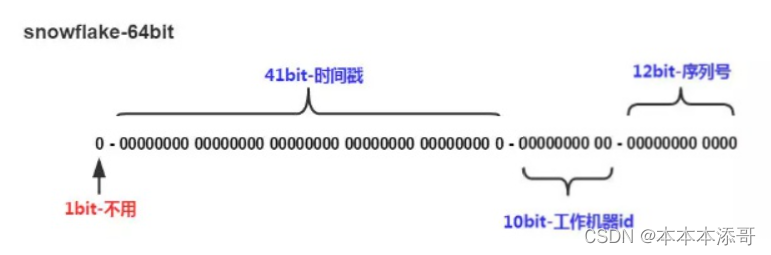
组成部分(64bit)
5.1 第一位 (占用1bit)
其值始终是0,没有实际作用。
因为二进制中最高位是符号位,1表示负数,0表示正数。
生成的ID都是正整数,所以最高位固定为0。
5.2 时间戳 (占用41bit)
总共可以容纳约69年的时间。
精确到毫秒级,41位的长度可以使用69年。
时间位还有一个很重要的作用是可以根据时间进行排序。
5.3 工作机器id(占用10bit)
其中高位5bit是数据中心ID,低位5bit是工作节点ID,最多可以容纳1024个节点。
10位的机器标识,10位的长度最多支持部署1024个节点。
5.4 序列号(占用12bit)
每个节点每毫秒0开始不断累加,最多可以累加到4095,一共可以产生4096个ID。
序列号即一系列的自增id,可以支持同一节点同一毫秒生成多个ID序号。
可以表示的最大正整数是2^12 -1 = 4095,即可以用0、1、2、3、…4094这4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号。
SnowFlake算法在同一毫秒内最多可以生成多少个全局唯一ID呢:
同一毫秒的ID数量 = 1024 X 4096 = 4194304