需求概述
分布式系统中,有一些需要使用全局唯一 ID 的场景,这种时候为了防止ID冲突可以使用36位的通用唯一识别码/UUID(Universally Unique Identifier),但是 UUID 有一些缺点,首先他相对比较长,另外 UUID 一般是无序的。有些时候我们希望能使用一种简单一些的 ID,并且希望 ID 能够按照时间有序生成。
Twitter-Snowflake 产生背景
Twitter 早期用 MySQL 存储数据,随着用户的增长,单一的 MySQL 实例没法承受海量的数据,后来团队就研究如何产生完美的自增 ID,以满足两个基本的要求:
- 每秒能生成几十万条 ID 用于标识不同的 记录;
- 这些 ID 应该可以有个大致的顺序,也就是说发布时间相近的两条记录,它们的 ID 也应当相近,这样才能方便各种客户端对记录 进行排序。
【Twitter-Snowflake】算法就是在这样的背景下产生的。
Snowflake 核心结构
Twitter 解决这两个问题的方案非常简单高效:每一个 ID 都是 64 位数字,由时间戳、工作机器节点和序列号组成, ID 是由当前所在的机器节点生成的。如图:
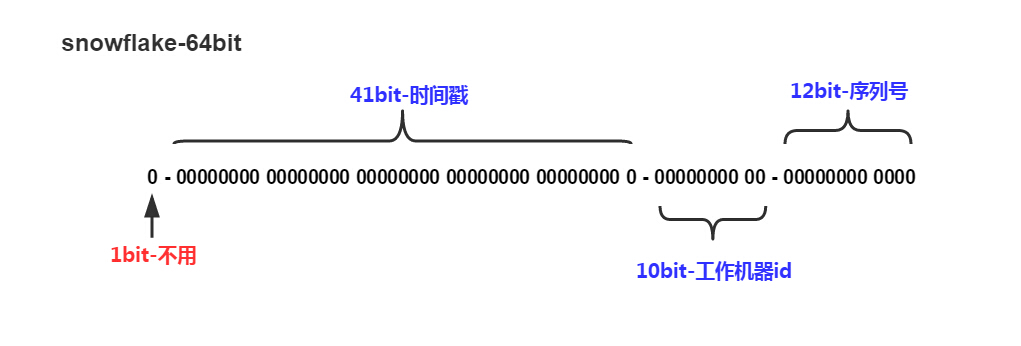
下面先说明一下各个区间的作用。
- 符号位(Symbol bit):用于区分正负数。1为负数,0为整数。一般不需要负数,所以值固定为0。
- 时间戳(Time stamp):一共预留 41bit 保存毫秒级时间戳。因为毫秒级时间戳长度是 13 位:41 位二进制最大值 (T) 是:$2^{41}-1 = 2199023255551 $ , 刚好 13 位。可以表示的年份 = T / (360024 365 * 1000) = 69.7 年(时间戳是从 1970, 1, 1, 0, 0, 0 开始)。换算成 Unix 时间也就是可以表示到:2039-09-07 23:47:35:
大家会觉得这个时间不够用啊,没关系,后面会讲如何优化。
- 工作机器(Work machine):预留了 10bit 保存机器ID。由5位 datacenterId 和 5位 workerId (10位的长度最多支持部署1024个节点)组合,只要机器 ID 不一样,每毫秒生成的 ID 是不一样的。一共可以支持多少台机器同时生成 ID 呢? 答案是 1023 台($2^{10}-1$)。
如果工作机器比较少,可以使用配置文件来设置这个 ID,或者使用随机数。如果机器过多就得单独实现一共工作机器 ID 分配器了,比如使用 redis 自增,或者利用 Mysql auto_increment 机制也可以达到效果。
- 序列号(Serial number):序列号一共是 12bit,为了处理在同一机器同一毫秒内需要给多条消息分配 ID 的情况,一共可以产生4095个序列号(0~4095, $2^{12}-1$)。
综上:一共加起来刚好 64=>(1+41+10+12)位,为一个 Long 型(转换成字符串长度为 19),同一台机器 1 毫秒内可产生 4095 个 ID,全部机器1毫秒内可产生 4095 * 1023 个 ID。snowflake 生成的 ID 整体上按照时间自增排序,并且整个分布式系统内不会产生 ID 碰撞(由 datacenter 和 workerId 作区分),由于全是在各个机器本地生成,效率非常高。
优化
1、时间戳优化
如果时间戳取当前毫秒级时间戳,那么只能表示到2039年,远远不够。我们发现,1970到当前时间这个区间其实是永远都不会用了,那么,为何不使用偏移量呢?也就是时间戳部分不直接取当前毫秒级时间戳,而是在此基础上减去一个过去时间:
id = (1572057648000 - 1569859200000) << 22; 输出:
id=9220959240192000上面代码中,第一个时间戳是当前毫秒级时间戳,第二个则是一个过去时间戳(1569859200000表示2019-10-01 00:00:00)。这样我们可以表示的年大概是 当前年份(例如2019) + 69 = 2088 年,很长一段时间内都够用。
2、序列号优化
序列号默认取0,如果已经使用了则自增。若自增到4096,也就是同一毫秒内的序列号用完了,怎么办呢?需要等待至下一毫秒。部分代码示例:
//同一毫秒并发调用
if (ts == (iw.last_time_stamp)) {
//序列号自增
iw.sequence = (iw.sequence+1) & MASK_SEQUENCE;
//序列号自增到最大值4096,4095 & 4096 = 0
if (iw.sequence == 0) {
//等待至下一毫秒
ts = time_re_gen(ts);
}
} else { //同一毫秒没有重复的
iw.last_time_stamp = ts;
}C# 实现分布式自增ID算法snowflake(雪花算法)
- 通用泛型单例(ReflectionSingleton)实现,如下代码:
using System;
using System.Reflection;
namespace NSMS.Helper
{
/// <summary>
/// 普通泛型单例模式
/// 优点:简化单例模式构建,不需要每个单例类单独编写;
/// 缺点:违背单例模式原则,构造函数无法设置成private,导致将T类的构造函数暴露;
/// </summary>
/// <typeparam name="T">class</typeparam>
[Obsolete("Recommended use ReflectionSingleton")]
public abstract class Singleton<T> where T : class, new()
{
protected static T _Instance = null;
public static T Instance
{
get
{
if (_Instance == null)
{
_Instance = new T();
}
return _Instance;
}
}
protected Singleton()
{
Init();
}
public virtual void Init()
{
}
}
/// <summary>
/// 反射实现泛型单例模式【推荐使用】
/// 优点:1.简化单例模式构建,不需要每个单例类单独编写;2.遵循单例模式构建原则,通过反射去调用私有的构造函数,实现了构造函数不对外暴露;
/// 缺点:反射方式有一定的性能损耗(可忽略不计);
/// </summary>
/// <typeparam name="T">class</typeparam>
public abstract class ReflectionSingleton<T> where T : class
{
private static T _Intance;
public static T Instance
{
get
{
if (null == _Intance)
{
_Intance = null;
Type type = typeof(T); //1.类型强制转换
//2.获取到T的构造函数的类型和参数信息,监测构造函数是私有或者静态,并且构造函数无参,才会进行单例的实现
ConstructorInfo[] constructorInfoArray = type.GetConstructors(BindingFlags.Instance | BindingFlags.NonPublic);
foreach (ConstructorInfo constructorInfo in constructorInfoArray)
{
ParameterInfo[] parameterInfoArray = constructorInfo.GetParameters();
if (0 == parameterInfoArray.Length)
{
//检查构造函数无参,构建单例
_Intance = (T)constructorInfo.Invoke(null);
break;
}
}
if (null == _Intance)
{
//提示不支持构造函数公有且有参的单例构建
throw new NotSupportedException("No NonPublic constructor without 0 parameter");
}
}
return _Intance;
}
}
protected ReflectionSingleton() { }
public static void Destroy()
{
_Intance = null;
}
}
}- snowflake 分布式 id 实现,如下代码:
using System;
using System.Threading;
namespace NSMS.Helper
{
/// <summary>
/// 【C#实现Snowflake算法】
/// 动态生产有规律的ID,Snowflake算法是Twitter的工程师为实现递增而不重复的ID需求实现的分布式算法可排序ID
/// Twitter的分布式雪花算法 SnowFlake 每秒自增生成26个万个可排序的ID
/// 1、twitter的SnowFlake生成ID能够按照时间有序生成
/// 2、SnowFlake算法生成id的结果是一个64bit大小的整数
/// 3、分布式系统内不会产生重复id(用有datacenterId和machineId来做区分)
/// =>datacenterId(分布式)(服务ID 1,2,3.....) 每个服务中写死
/// =>machineId(用于集群) 机器ID 读取机器的环境变量MACHINEID 部署时每台服务器ID不一样
/// 参考:https://www.cnblogs.com/shiningrise/p/5727895.html
/// </summary>
public class Snowflake : ReflectionSingleton<Snowflake>
{
/// <summary>
/// 构造函数私有化
/// </summary>
private Snowflake() { }
#region 初始化字段
private static long machineId;//机器ID
private static long datacenterId = 0L;//数据ID
private static long sequence = 0L;//序列号,计数从零开始
private static readonly long twepoch = 687888001020L; //起始的时间戳,唯一时间变量,这是一个避免重复的随机量,自行设定不要大于当前时间戳
private static readonly long machineIdBits = 5L; //机器码字节数
private static readonly long datacenterIdBits = 5L; //数据字节数
public static readonly long maxMachineId = -1L ^ -1L << (int)machineIdBits; //最大机器ID
public static readonly long maxDatacenterId = -1L ^ (-1L << (int)datacenterIdBits);//最大数据ID
private static readonly long sequenceBits = 12L; //计数器字节数,12个字节用来保存计数码
private static readonly long machineIdShift = sequenceBits; //机器码数据左移位数,就是后面计数器占用的位数
private static readonly long datacenterIdShift = sequenceBits + machineIdBits; //数据中心码数据左移位数
private static readonly long timestampLeftShift = sequenceBits + machineIdBits + datacenterIdBits; //时间戳左移动位数就是机器码+计数器总字节数+数据字节数
public static readonly long sequenceMask = -1L ^ -1L << (int)sequenceBits; //一微秒内可以产生计数,如果达到该值则等到下一微妙在进行生成
private static long lastTimestamp = -1L;//最后时间戳
private static readonly object syncRoot = new object(); //加锁对象
#endregion
#region Snowflake
/// <summary>
/// 数据初始化
/// </summary>
/// <param name="machineId">机器Id</param>
/// <param name="datacenterId">数据中心Id</param>
public void SnowflakesInit(short machineId, short datacenterId)
{
if (machineId < 0 || machineId > Snowflake.maxMachineId)
{
throw new ArgumentOutOfRangeException($"The machineId is illegal! => Range interval [0,{Snowflake.maxMachineId}]");
}
else
{
Snowflake.machineId = machineId;
}
if (datacenterId < 0 || datacenterId > Snowflake.maxDatacenterId)
{
throw new ArgumentOutOfRangeException($"The datacenterId is illegal! => Range interval [0,{Snowflake.maxDatacenterId}]");
}
else
{
Snowflake.datacenterId = datacenterId;
}
}
/// <summary>
/// 生成当前时间戳
/// </summary>
/// <returns>时间戳:毫秒</returns>
private static long GetTimestamp()
{
return (long)(DateTime.UtcNow - new DateTime(1970, 1, 1, 0, 0, 0, DateTimeKind.Utc)).TotalMilliseconds;
}
/// <summary>
/// 获取下一微秒时间戳
/// </summary>
/// <param name="lastTimestamp"></param>
/// <returns>时间戳:毫秒</returns>
private static long GetNextTimestamp(long lastTimestamp)
{
long timestamp = GetTimestamp();
int count = 0;
while (timestamp <= lastTimestamp)//这里获取新的时间,可能会有错,这算法与comb一样对机器时间的要求很严格
{
count++;
if (count > 10) throw new Exception("The machine may not get the right time.");
Thread.Sleep(1);
timestamp = GetTimestamp();
}
return timestamp;
}
/// <summary>
/// 获取长整形的ID
/// </summary>
/// <returns>分布式Id</returns>
public long NextId()
{
lock (syncRoot)
{
long timestamp = GetTimestamp();
if (Snowflake.lastTimestamp == timestamp)
{
//同一微妙中生成ID
Snowflake.sequence = (Snowflake.sequence + 1) & Snowflake.sequenceMask; //用&运算计算该微秒内产生的计数是否已经到达上限
if (Snowflake.sequence == 0)
{
//一微妙内产生的ID计数已达上限,等待下一微妙
timestamp = GetNextTimestamp(Snowflake.lastTimestamp);
}
}
else
{
//不同微秒生成ID
Snowflake.sequence = 0L; //计数清0
}
if (timestamp < Snowflake.lastTimestamp)
{
//如果当前时间戳比上一次生成ID时时间戳还小,抛出异常,因为不能保证现在生成的ID之前没有生成过
throw new Exception($"Clock moved backwards. Refusing to generate id for {Snowflake.lastTimestamp - timestamp} milliseconds!");
}
Snowflake.lastTimestamp = timestamp; //把当前时间戳保存为最后生成ID的时间戳
long id = ((timestamp - Snowflake.twepoch) << (int)Snowflake.timestampLeftShift)
| (datacenterId << (int)Snowflake.datacenterIdShift)
| (machineId << (int)Snowflake.machineIdShift)
| Snowflake.sequence;
return id;
}
}
#endregion
}
}以上方法就完成了 snowflake 算法的 C# 实现,还可以基于该算法结合业务扩展,比如生产的 id 带有一定的业务意义,此处还扩展了6为长度的随机字符串,例如订单编号:order 前缀标记,修改如下:
using System;
using System.Text;
namespace NSMS.Helper
{
/// <summary>
/// 集成ID生产规则
/// </summary>
public class IdWorker: ReflectionSingleton<IdWorker>
{
/// <summary>
/// 构造函数私有化
/// </summary>
private IdWorker() { }
#region 获取格式化GUID
public enum GuidType { N, D, B, P, X, Default };
public enum IsToUpperOrToLower { ToUpper, ToLower };
public string GetFormatGuid(GuidType guidType = GuidType.N, IsToUpperOrToLower isToUpperOrToLower = IsToUpperOrToLower.ToLower)
{
string guid = guidType switch
{
GuidType.N => Guid.NewGuid().ToString("N"), // e0a953c3ee6040eaa9fae2b667060e09
GuidType.D => Guid.NewGuid().ToString("D"), // 9af7f46a-ea52-4aa3-b8c3-9fd484c2af12
GuidType.B => Guid.NewGuid().ToString("B"), // {734fd453-a4f8-4c5d-9c98-3fe2d7079760}
GuidType.P => Guid.NewGuid().ToString("P"), // (ade24d16-db0f-40af-8794-1e08e2040df3)
GuidType.X => Guid.NewGuid().ToString("X"), // (ade24d16-db0f-40af-8794-1e08e2040df3)
GuidType.Default => Guid.NewGuid().ToString(), // {0x3fa412e3,0x8356,0x428f,{0xaa,0x34,0xb7,0x40,0xda,0xaf,0x45,0x6f}}
_ => throw new NotImplementedException(),
};
switch (isToUpperOrToLower)
{
case IsToUpperOrToLower.ToUpper:
guid = guid.ToUpper(); //返回大写GUID
break;
case IsToUpperOrToLower.ToLower:
guid = guid.ToLower(); //返回小写GUID
break;
}
return guid;
}
#endregion
/// <summary>
/// 获取机器唯一编码
/// </summary>
/// <returns></returns>
public string GetMachineCodeString() => MachineCode.GetMachineCodeString();
/// <summary>
/// 获取分布式Id(Snowflake)
/// </summary>
/// <param name="prefix">业务标识前缀</param>
/// <param name="machineId">机器Id(集群环境的服务器Id)</param>
/// <param name="datacenterId">分布式数据中心Id(服务Id)</param>
/// <param name="hasRandom">是否开启随机变量</param>
/// <returns></returns>
public string GetSnowflakeId(string prefix, short machineId, short datacenterId, bool hasRandom = true)
{
Snowflake.Instance.SnowflakesInit(machineId, datacenterId);
string randomNo = GenerateRandomNumber(6);
if (hasRandom)
{
if (string.IsNullOrWhiteSpace(prefix)) return $"{randomNo}.{Snowflake.Instance.NextId()}";
else return $"{prefix}.{randomNo}.{Snowflake.Instance.NextId()}";
}
else
{
if (string.IsNullOrWhiteSpace(prefix)) return $"{Snowflake.Instance.NextId()}";
else return $"{prefix}.{Snowflake.Instance.NextId()}";
}
}
#region 获取随机数
/// <summary>
/// 随机数基础数据
/// </summary>
private readonly char[] _RandomBasicData =
{
'0','1','2','3','4','5','6','7','8','9',
'a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z',
'A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'
};
/// <summary>
/// 生产随机数
/// </summary>
/// <param name="length">随机数长度</param>
/// <returns></returns>
public string GenerateRandomNumber(int length)
{
int capacity = _RandomBasicData.Length;
StringBuilder newRandom = new StringBuilder(capacity);
Random rd = new Random();
for (int i = 0; i < length; i++)
{
newRandom.Append(_RandomBasicData[rd.Next(capacity)]);
}
return newRandom.ToString();
}
#endregion
}
}接下来我们调用上面的方法生产测试结果,调用代码如下:
System.Console.WriteLine("【原生使用】Snowflake 生产分布式 id.");
Snowflake.Instance.SnowflakesInit(0, 0); //【Snowflake】初始化
for (int i = 0; i < 5; i++)
{
long id = Snowflake.Instance.NextId(); //生产id
System.Console.WriteLine($"=>序号:[{i + 1}],时间:[{DateTime.Now:yyyy-MM-ddTHH:mm:ss.ffff}],id=[{id}]");
}
System.Console.WriteLine($"\n【扩展使用】Snowflake 生产分布式 id.扩展业务前缀和随机串.");
for (int i = 0; i < 5; i++)
{
string id = IdWorker.Instance.GetSnowflakeId("order", 1, 0); //生产id
System.Console.WriteLine($"=>序号:[{i + 1}],时间:[{DateTime.Now:yyyy-MM-ddTHH:mm:ss.ffff}],id=[{id}]");
}上面调用代码为了演示【原生】和【扩展】方式每种生产5条信息(以时间为参考区分),结果如下:
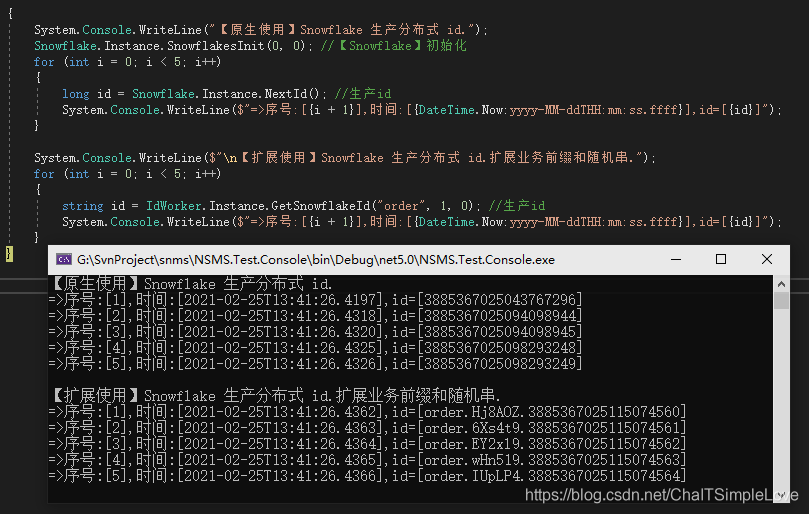
参考:
- TwitterSnowflake 自增 ID 算法 =》https://lequ7.com/TwitterSnowflake-zi-zeng-ID-suan-fa.html
- C# 实现 Snowflake 算法 =》https://blog.csdn.net/w200221626/article/details/52064976