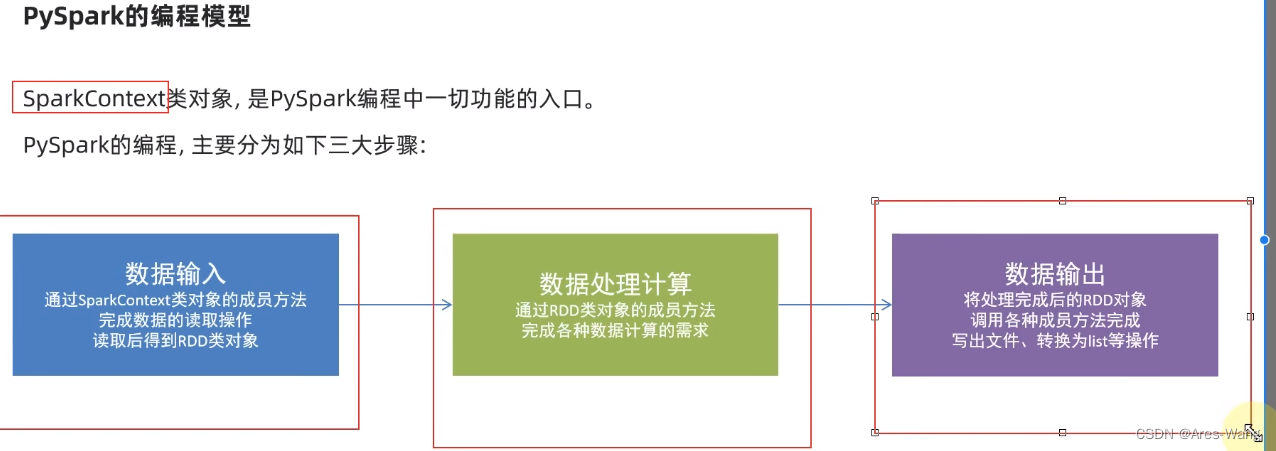
Spark 计算引擎
# 导包
from pyspark import SparkConf, SparkContext
# 设置环境变量
import os
# 设置pyspark 解析器
os.environ['PYSPARK_PYTHION'] = 'D:\dev\python 3.11.4'
# 创建SparkConf类对象
# 运行模式setMaster()可以设置分布式集群
# setAppName() 设置conf名称
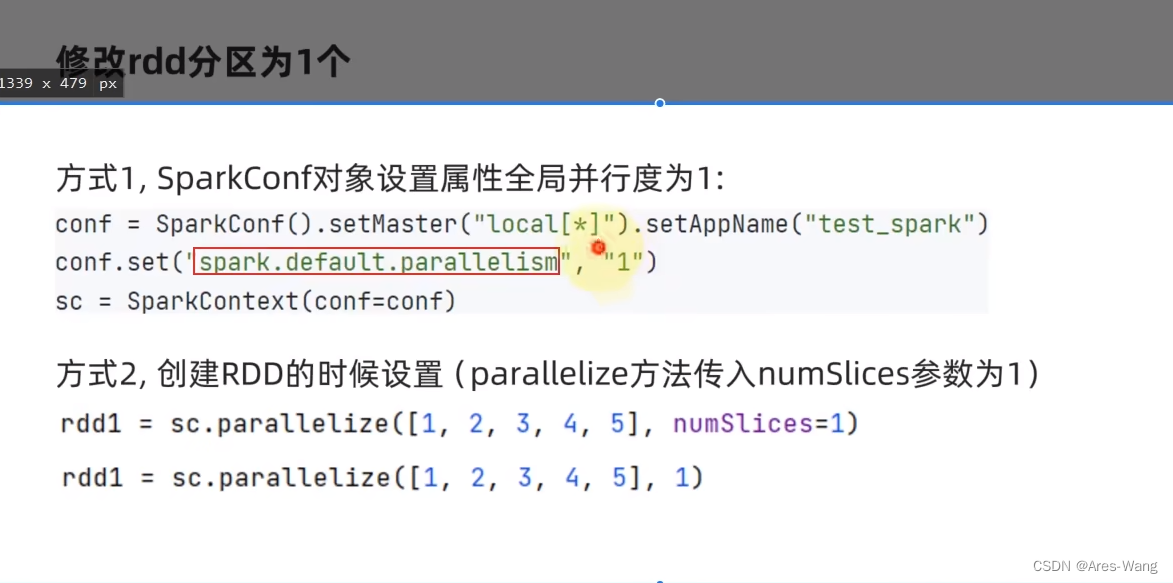
conf = SparkConf().setMaster("Local[*]").setAppName("test_spark_app")
# 基于SparkConf类对象创建SparkContext类对象做为入口 执行环境入口对象 sparkcontext
sc = SparkContext(conf=conf)
# 打印PySpark的运行版本
print(sc.version)
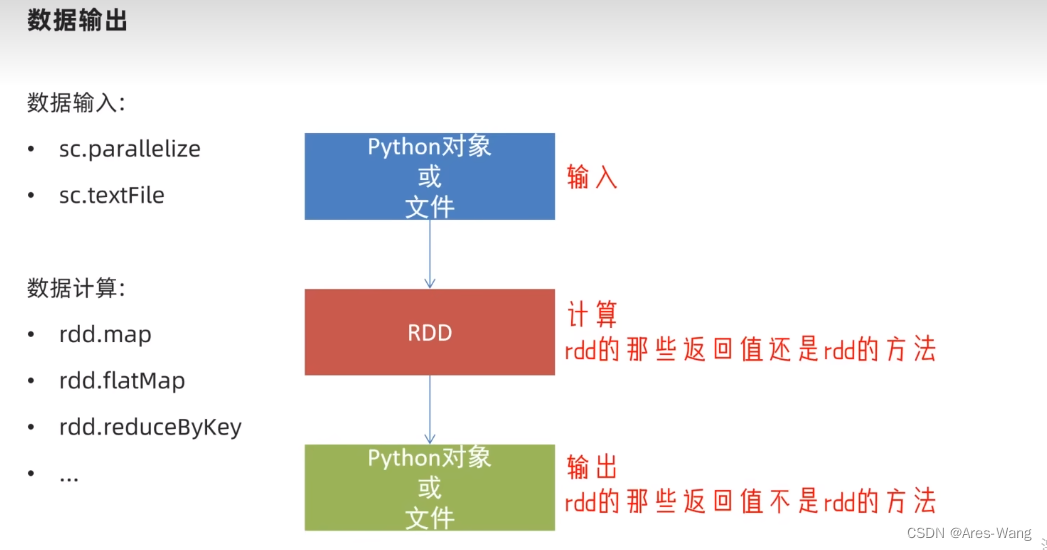
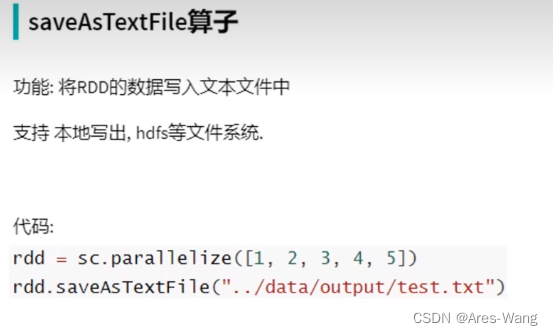
# rdd对象 通过sparkcontext的parallelize方法 把python数据容器(list、tuple、set、dict、str)转换为RDD对象
rdd = sc.parallelize(数据容器对象)
# 读取文件 转换成rdd对象
rdd = sc.textFile(文件路径)
# 输出RDD对象
# print(rdd) 不会打印输出, print打印只能打印python对象 rdd.collect() 把rdd 转换成python对象
print(rdd.collect())
# 停车SparkContenxt对象的运行(停车Pyspark程序)
sc.stop()
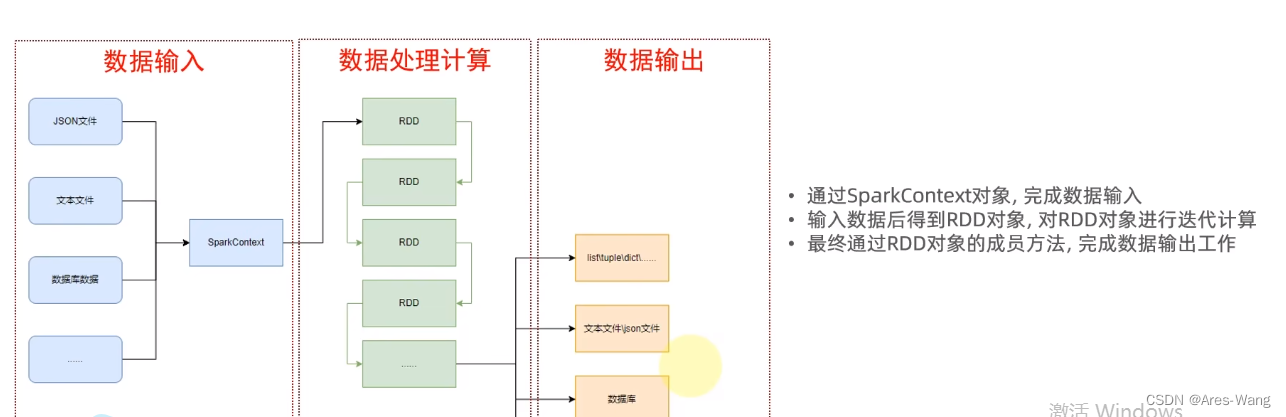
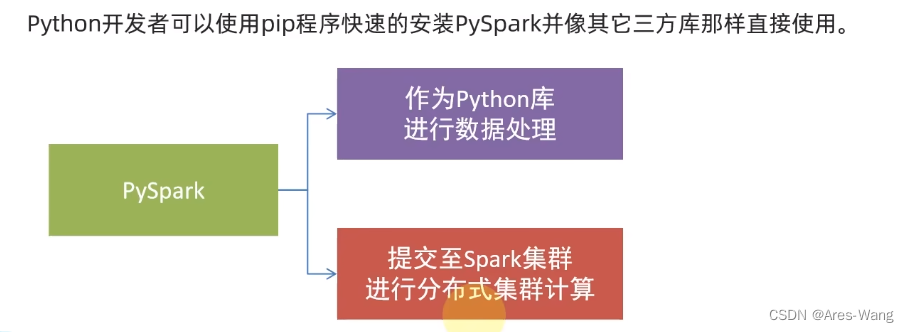
spark 数据处理

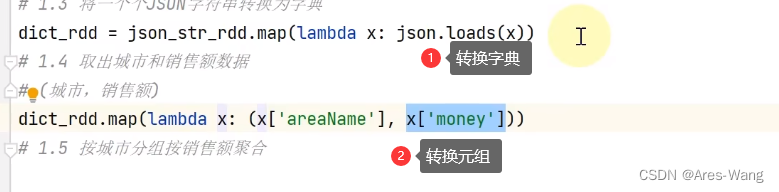
map、flatmap
flatmap跟map一样效果,只是flatmap 对结果多一个解除嵌套。
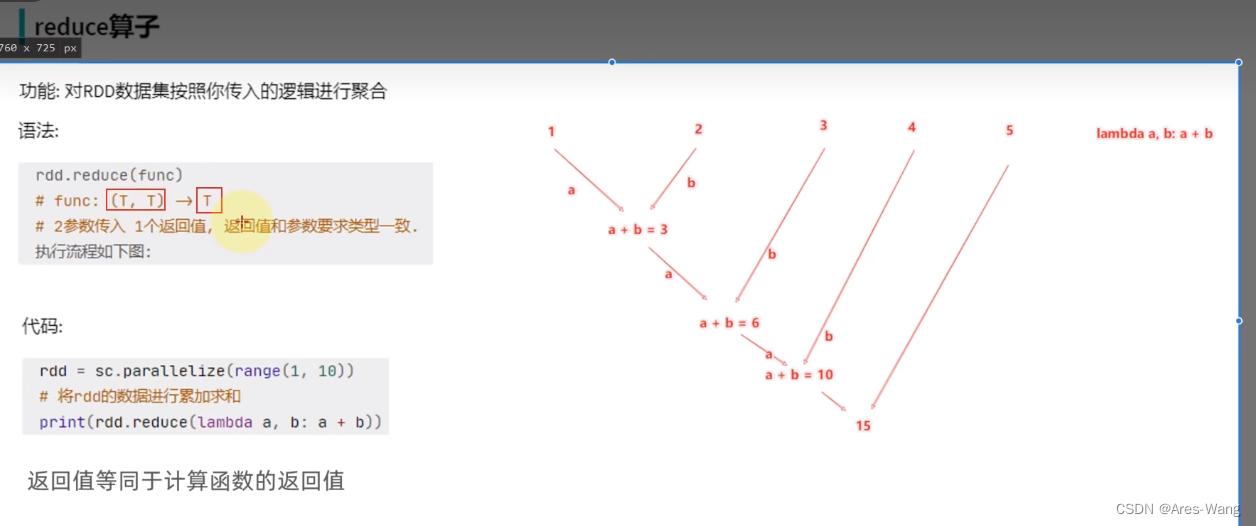
reduceBykey
二元元组又称KV元组 元组 只有两个元素。 ((‘a’,1),(‘b’,2))
按key就行分组,且每组,value,会聚会计算,即两辆计算
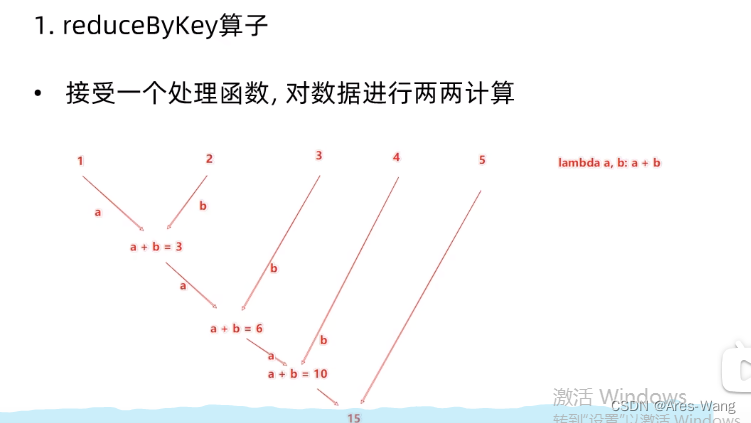
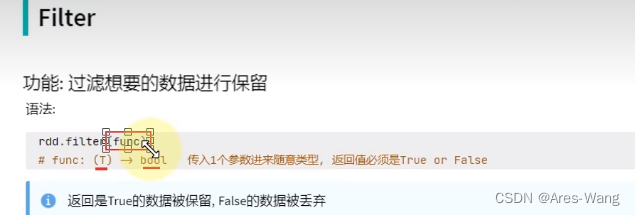
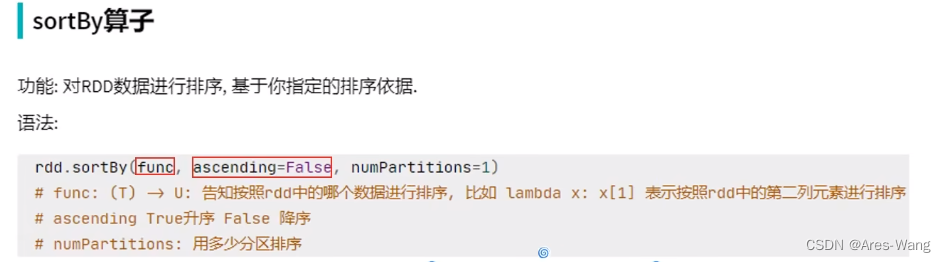
输出数据