在传统的数据结构的实现中,分为侵入式容器和非侵入式容器两种
侵入式容器
这也是教材喜欢使用的数据结构的实现方式 ,将数据结构放入类中,所以先讲这个
非侵入式容器:
struct ListNode {
ListNode *prev, *next;
int value;
};这时候如果要用模板实现的话就是:
template <typename T>
struct ListNode {
ListNode *prev, *next;
T value;
};可以看见数据都是放在类中,这也是平常在教学中常用的数据结构组织方式
非侵入式容器
C++标准的STL库中实现的容器,甚至于Redis中实现的容器都是非侵入式容器
关于在linux的kernel/inclue/linux/types.h源码中链表的实现:
struct list_head {
struct list_head *next, *prev;
};看一看这个数据结构表示中,只在里面存储了数据类型的前驱节点和后驱节点
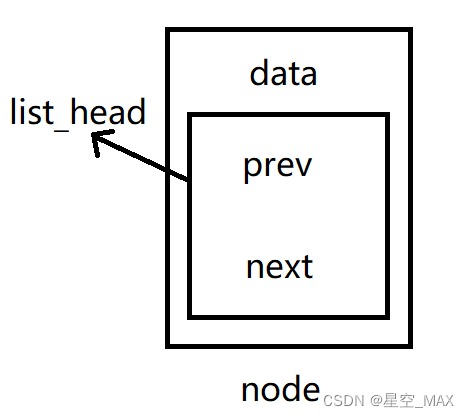
这时候,如果想要存储数据,需要创建指定的数据结构
Struct node{
int sum;
list_head list;
}这时候的数据结构示意图如下:

关于Ridis的adlist.h源码中:
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;在value中通过一个指针指向存储数据结构的区域
这时候,可以实现一个数据结构比如说struct
struct A{
int data;
}这时候需要用指针读到这个数据结构:
listNode *Node;
int v =(int*)Node->value;非侵入式容器总结和优势
可有看到再以上的非侵入式容器中数据没有直接放入类中,这样存储有什么好处呢?
这样存储数据类型有着非常的灵活性,解耦了容器和数据
比如说把
typedef struct listNode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;放入h文件中
把
struct A{
int data;
}放入cpp文件后
每次编译的时候,h文件需要全部复制到cpp文件中
这时候,如果修改类存储的数据结构的时候,放如果使用侵入式的方法,就会发现,h中改动一下,就要重新编译好久,单数放在cpp中,就会使得编译的流程大大减少
另一方面:
非入侵式容器不需要使用模板泛型编程,但是这不意味着彻底抛弃模板,在boost库的intrusive中就需要使用typename
侵入式容器总结和优势
在非侵入式容器中,每回寻找数据需要指针再次定位,但在现在的电脑上,这点性能开销简直可以忽略不记
创建需要在两个空间上new两次,其实也影响不大
其实它最不好地方在于在松散的内存布局对于cache line及其不友好
那么侵入式容器的优势就出来了,可以使得内存紧密排列,从而提高chache的命中率
另外重要的一点就是:
在STL的容器都是使用allocator分配器,如果使用侵入式容器,由于调用关系数据只能分配在堆上面
但是如果使用了侵入式容器的话,数据可以分配在栈上面,例如使用plancement new
在EASTL库中(由于游戏的特殊性,一般游戏需要构建自己的内存池,所以EASTL这套EA开发的高性能库成了不烧游戏开发的选择),就提供了intrusive容器的使用
扩展:从容器到侵入式和非侵入式框架设计
侵入式框架:引入了框架,对现有的类的结构有影响,需要实现框架某些接口或者基础某些特定的类。
非侵入式框架:引入了框架,对现有的类结构没有影响,不需要实现框架某些接口或者特定的类。
现在sprinresprinredis的框架设计倾向于非侵入式框架,这源于代码设计高内聚,低耦合原则
就拿spring举例吧,在java常用的spring框架中,就是常用的非侵入式框架设计,利用反射和动态调节涌来实例化对象,代码中没有与spring耦合交叉的类,这时候完全可以换一套框架,但是对原来的代码没影响,这么说当然夸张了,有一点侵入还是有的