导读
近日,MIT教授、「暂停大型AI实验」公开信的发起人之一Max Tegmark发表了题为「如何掌控 AI」的精彩演说,介绍了发展可控 AI 的重要意义,提出了通过「机械可解释性」实现可控 AI 的技术路线,同时也肯定了中国在 AI 安全领域的贡献,并呼吁全球同仁加入到 AI 治理的事业中来。
1. Yann LeCun 在他的演讲中提到,也许大语言模型缺乏世界模型。我听到很多人这么说,但我认为并非如此。
2. 中国确实得天独厚,在人工智能的安全和明智治理方面会做出贡献。
3. 当我们认真对待 AI 安全问题,东西方之间的关系可能会有所改善。

Max Tegmark
宇宙学家,现任麻省理工学院物理学终身教授、基础问题研究所科学主任;生命未来研究所创始人之一。代表作《Life 3.0》、《Life 3.0 Our Mathematical Universe》等。
如何才能掌控人工智能?

我喜欢人工智能,对它给我们带来的巨大机遇感到非常兴奋。人工智能可以做很多很棒的事情,不仅可以帮助中国,还可以帮助世界。
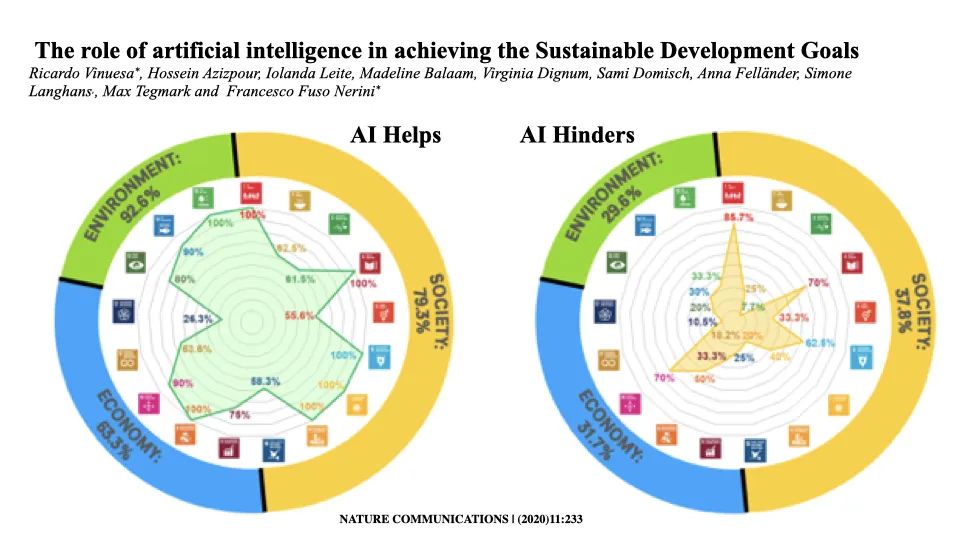
几乎所有国家都认同联合国的可持续发展目标。我们最新的研究表明:如果人工智能被正确使用,并加以控制,它可以帮助我们更快、更好地实现几乎所有这些目标,甚至超越这些目标。
如果我们能掌控这些技术,它们可以帮助我们治愈所有疾病,帮助地球上每个人过上健康、富裕和鼓舞人心的生活。众所周知,很多人对「控制AI」忧心忡忡。例如,几周前AI教父 Geoffory Hinton 的发言。
MC:我们距离拥有自我提升的意识的计算机很近吗?
Hinton:很可能是的。
MC:它可以发展得更快?
Hinton:是的,这是一个值得注意的问题,我们必须思考如何让它们处于掌控之下。
MC:我们可以做到吗?
Hinton:我不知道。我们还没有走到那一步,但我们可以试试。
MC:这有些令人担忧。
Hinton:是的。
再比如 OpenAI 的 CEO Sam Altman 在有关 ChatGPT 和 GPT-4 的访谈中提到:在最糟糕的情况下,人类会灭亡。

这些人都是 AI 领域的领袖。2023年5月20日,来自世界各地的一大批人工智能研究人员签署了一份声明,称「存在人工智能灭绝人类的危险」。图灵奖得主 Yann Lecun、Geoffery Hinton、Yoshua Bengio 都认为人工智能可以消灭人类。DeepMind CEO Demis Sassabis、OpenAI CEO Sam Altman 和许多国内知名研究人员也签署了这一协议。
为什么这么多人有这种担忧?为什么在当下的时间点引起了广泛讨论?

事实上,「AI 安全」是一个老生常谈的问题,它与人工智能的概念一样古老。Alan Turing、Norbert Wiener、Irving J Good、Stephen Hawking、Stuart Russell 等人也都曾有过这样的担心。
很明显,如果地球上最聪明的物种(即人类)不得不与另一个更聪明的智能体打交道,可能会失去对这些智能体的控制。人类已经造成了许多其他物种的灭绝,我们比它们更聪明,因此它们无法掌控人类。我们的目标与它们不同,我们需要它们的资源来完成我们的项目。它们无法阻止我们,因为我们更聪明。
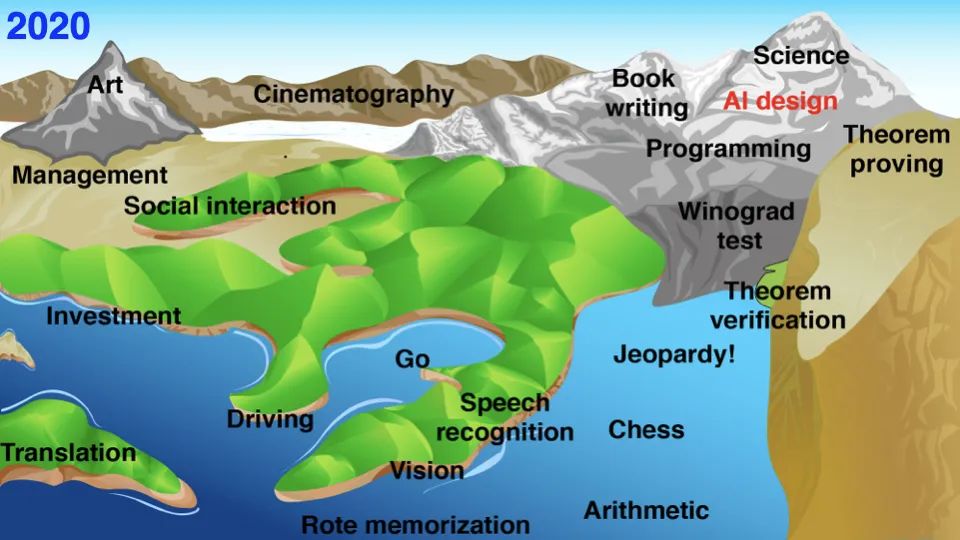
所以,就人工智能与人类而言,我们需要小心控制它们。在新时代,这一问题的紧迫性更为突出。三年前,我在中国展示了这张图片。该图介绍了一个任务图景,其中海拔代表每个任务对机器来说的难度。海平面代表了那时机器能做什么。
在过去的三年里,「海平面」上升了很多。看看短短三年发生了多大的变化。现在的 AI 可以通过「温诺格拉德测试」,可以出色地完成编程任务,甚至可以开始创作一些非常有趣的艺术品。还有许多人开始用大语言模型写书。

上次我在中国的时候,大多数研究人员认为需要 30-50 年实现强人工智能,还仍然有人认为我们几百年内都不会实现。但是,2023 年 4 月,微软发表了一篇论文《Sparks of Artificial General Intelligence》,称强人工智能已经萌芽,GPT-4 里已经有强人工智能的火花了,引发了广泛讨论。正如 Yoshua Bengio 所说:人工智能系统基本上已经达到了可以愚弄人类的程度,这意味着它们可以通过图灵测试。大型语言模型已经可以做到这一点。

这一现象也存在积极意义。当人们认真对待这一现象,东西方之间可能会有更好的关系。在此之前,人们只考虑人工智能可以带来力量,人们想的是竞争,尽可能抢占先机。一旦人们达成共识,认为 AI 可能会终结地球上所有人的文明,就会彻底改变超级大国和所有人的动机。如果人类灭绝了,无论美国人还是中国人都没有差别。谁先获得无法控制的超级智能并不重要,因为每个人都会在那一刻死去。
尽管这听起来很可怕,但这是第一次东方和西方都有同样的动机继续开发人工智能。我们希望得到收益,但不会让 AI 发展得太快,以至于失去对它们的控制。就像应对气候问题,这是我们可以共同为之努力的事情。
对齐人工智能
我们要控制人工智能,这样就可以得到好的结果,并确保它们为我们服务。
我们需要解决两个主要问题:(1)对齐。让独立的人工智能去做它的主人想让它做的事情。(2)多尺度对齐。让世界上所有的组织、公司、人们团结起来,使得人工智能向善。
如果我们只解决「对齐」问题,广泛使用非常强大的人工智能,就会出现这样的情况:一些恐怖分子想要接管世界,可以利用这项技术来做到这一点。
从技术方面说,我们要思考如何让计算机和人工智能结合起来,让它做你想让它做的事情。重点在于,如何更好地理解这些系统内部发生的事情,即机械可解释性 (Mechanistic Interpretability, MI)。在理解其工作原理后,就可以更加信任系统。这是一个相对年轻的较小众的研究领域,但非常有前途、令人兴奋。
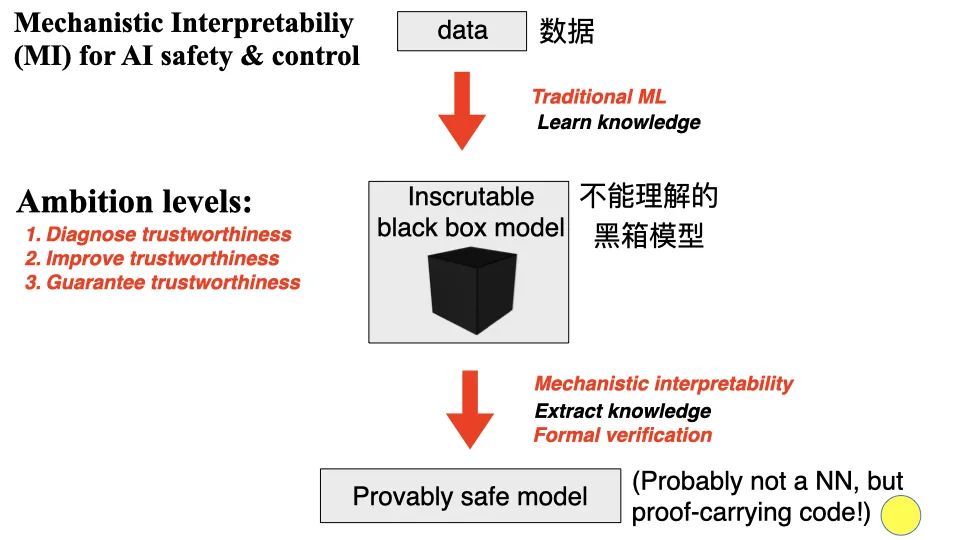
在机械可解释性范畴下,我们训练一个无法理解的黑盒神经网络来解释智能。我们想要知道机器是如何做到的,为何要这么做,为何想要这么做。
「解释」有三个级别的目标:
(1)诊断系统值得信赖的程度。例如,如果你在开车,即使你不明白它是如何工作的,你至少想知道你是否应该相信刹车。你相信当你踩下刹车时,车速会慢下来。
(2)提升可信程度。更好地理解机械,让它更值得信赖。
(3)保证可信度。从机器学习发现的黑盒中提取出所有的知识,提取出知识,在其它系统中重新实现,这样就可以证明它会做你想做的事情。
Stewart Russell 认为携带证明的代码(proof-carrying code)可以证明它会运行。携带证明的代码要求软件向它证明它将做正确的事情。只有软件能证明自身的安全性,才会运行。我们希望将其与机械可解释性结合起来,首先通过训练机器学习系统自动发现知识。然后使用其它人工智能技术提取知识并将其转换为某种形式的可证明代码。
LLM 在学习「量子」
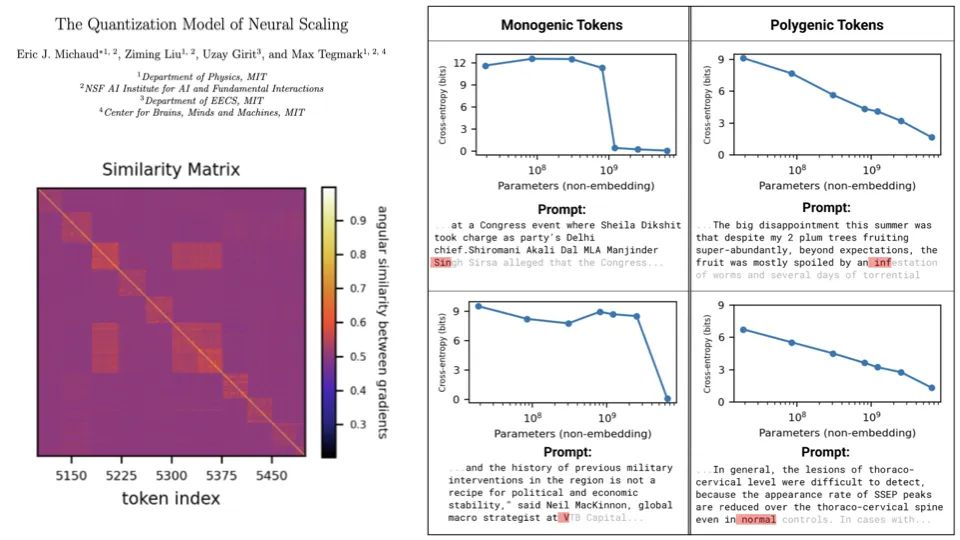
我们最近发表的论文指出,大语言模型中的知识近似由许多小量子(quanta)组成,我们称之为可以单独学习和研究的知识片段。我们对单个词例取梯度然后取所有梯度的点积然后将它们归一化,得到一个相似矩阵。然后我们做了一个谱聚类。这样一来,我们就能够自动识别出大语言模型正在学习的知识量子。
经过一段时间的训练,神经网络知道了一些事实。它能够预测某人的名字、工作单位。有很多这样的量子,小神经网络的梯度太大,永远无法学习。但是当参数量足够大时,它就能学习了,损失会趋向于 0。我们称之为「单基因标记」。

神经网络还有其它需要大量量子的技能。随着规模的扩大,它们的学习过程会越来越缓慢。如上图所示,这些知识的量子是自动发现的。大语言模型会读取这些量子,红色或粉红色始终是预测的下一个标记。大语言模型学习了编号列表。不管它是用数字、字母还是十六进制来表示,都是一样的道理。在右侧的图中,由于人们喜欢写长度大致相同的行。因此,它预测当一行写到相应的长度时,粉色换行和返回。

我们发现了各种各样的量子。有趣的是,大语言模型总是倾向于以相同的顺序学习量子。首先,它学习最有用的东西,然后是不太有用的东西。就想小孩一样,首先你要学会爬行。然后,你学会以同样的顺序走路。这种变化情况符合「放缩法则」。众所周知,损失以幂律一样的规律随着计算量、数据集的大小、参数的数量下降,这三者都可以同时解释。如果假设需要的这些量子的频率分布也是一个幂律,就像滑索一样,我们有一个公式来说明这些不同的尺度定律是如何相互联系的。

机械可解释性可以提取知识如何在模型中表示。东北大学 David Bau 教授最近发现了 GPT 是如何存储埃菲尔铁塔在巴黎的事实的,并计算出了其表征。他们通过在神经网络中编辑这些权重,让网络判断埃菲尔铁塔在罗马,而不是巴黎。所以当他们问埃菲尔铁塔在哪里时,系统开始解释关于罗马的事情。他们还发现,这种表征的储存方式是线性编码的。在 Transformer 中,将特定编码矩阵乘以嵌入编码巴黎的向量,得到的是带有很大系数的编码罗马的向量。

在过去的半年里,很多研究小组发现了存储不同种类的知识的方法。我们研究了算术信息是如何被表示出来的。对于抽象乘法表(普通的乘法,或其它群运算),你只是想预测像这样把两个元素结合在一起会发生什么。

如上图所示,将两张像素图像输入给网络,实现「加法,并对 59 取模」的操作。任何群运算都可以表示成一组矩阵乘法。我们训练一个编码器矩阵,以及解码器。训练时,在高维内部空间中表现出来神经网络的洞察力。所有的点都落在一个二维超平面上,并形成了圆形嵌入空间。这里的操作就像一个时钟,绕过一圈之后又重新开始。模型发现了这一点,它就能够泛化和并以前从未见过的例子。因为这个表征自动嵌入了这个运算满足交换律的和结合律。
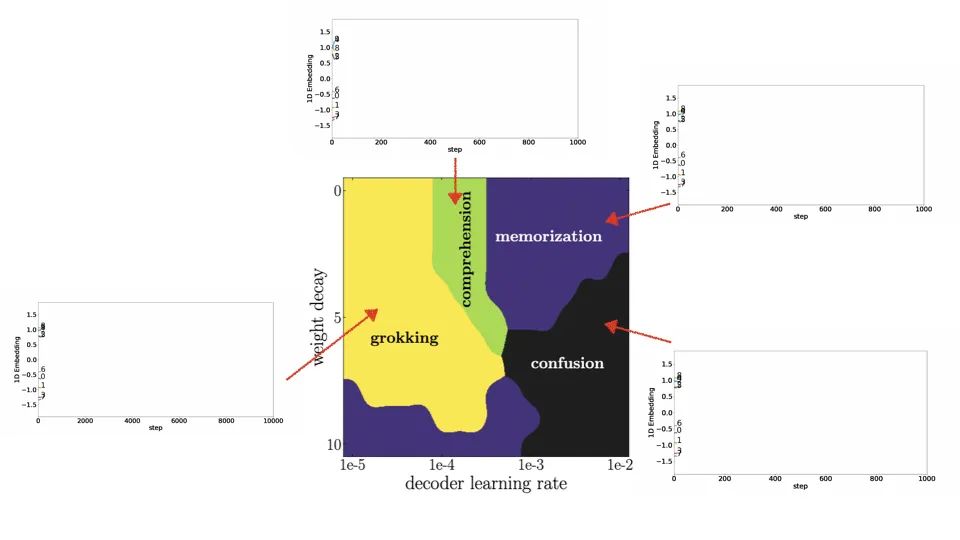
如果只做普通的加法而不做取模,你会发现它将开始在一条直线上表示所有的实体,而不是一个圆。如果过拟合,它会以一种随机愚蠢的方式表征,可以重复训练数据但永远不能泛化。Grokking(顿悟)是一个需要很长时间才能泛化的例子。如果在什么都学不到的情况下训练,模型总是很困惑,嵌入甚至不会改变。
提取模块化
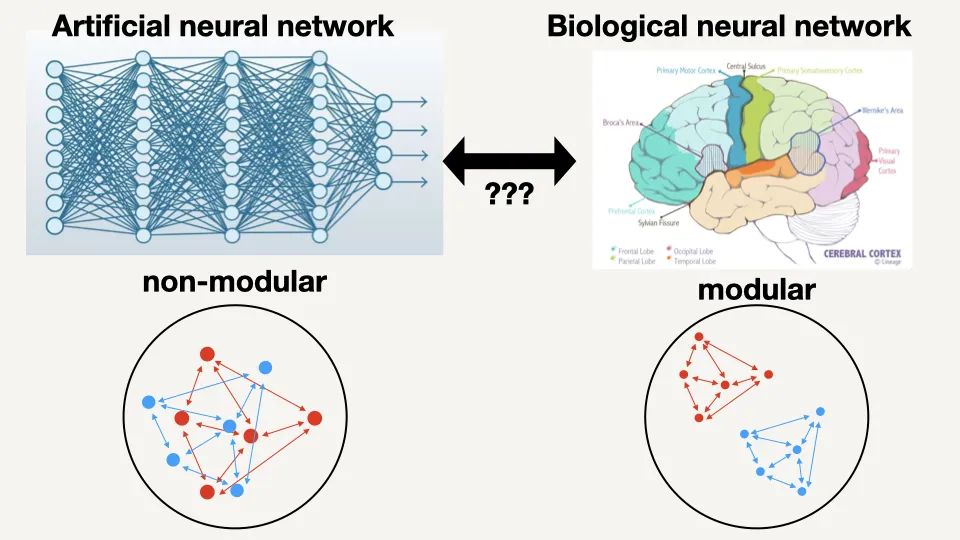
我们可以通过机器学习使解决方案变得更简单。神经网络有很多不同的方法来完成同样的任务。我们想要最简单的网络,但它通常会学习到更复杂的网络,因为复杂的网络比简单的要多。
人类的大脑则是非常模块化的。不同脑区完成不同的任务,需要大量交流的神经元靠得很近。这是因为在大脑中,发送长距离的信号开销很大,它会占用大脑更多的空间,消耗更多的能量,并造成时间延迟。在一个全连接的神经网络中。你可以在不改变损失函数的情况下改变层中所有神经元的顺序,也不改变任何常规的正则化。

我们向神经网络添加一个损失函数(一个类似于 L1范数的正则化项),再乘以神经元之间的距离,惩罚权重使其稀疏。我们将神经元嵌入到一个真实的二维或三维空间。
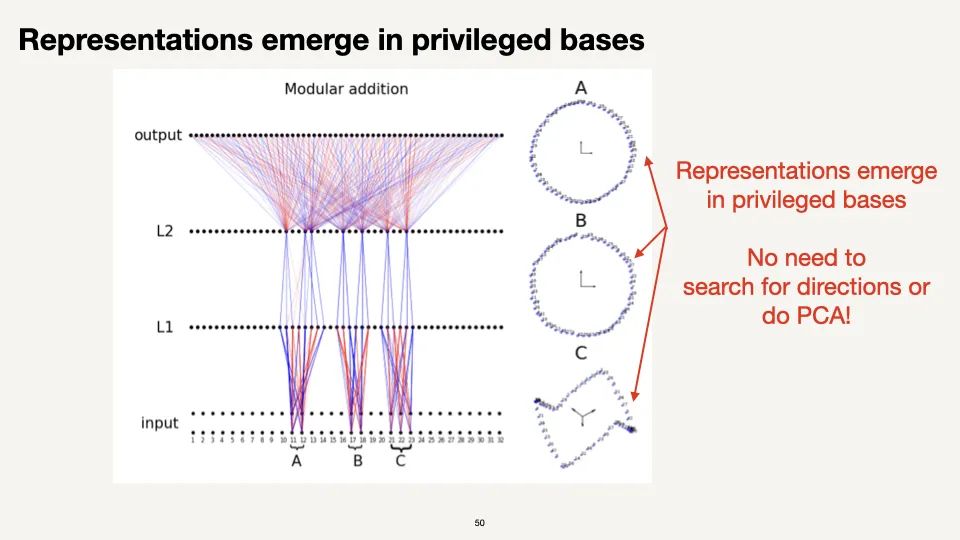
过了一段时间,神经网络不仅变得更加稀疏,而且开始出现一些特有的连接结构,形成了不同的模块。这与上文所述的量子有相似之处。有趣的是,这些模块显示出了上文所示形成「圆」的能力。还形成了像多数投票这样的纠错能力。
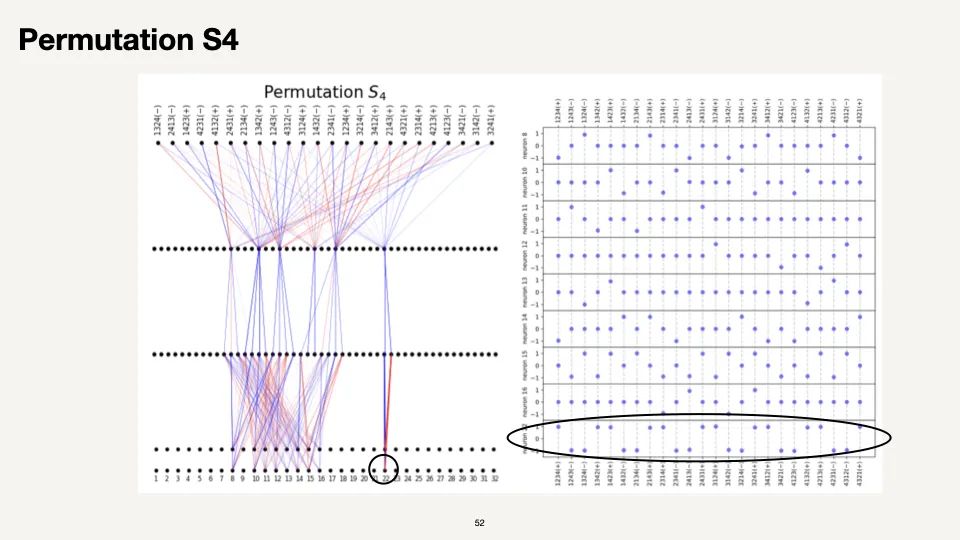
如上图所示,我们尝试用神经网络实现由 24 个元素组成的置换群。你可以把它想象成四面体的四个角的排列。这个群的 9 维表示对应于 3x3 矩阵,你可以旋转这个四面体并翻转它。你只需要 9 个神经元就能达到完美的准确度。此外,它还发现了群表示理论。
在训练神经网络预测简单的函数时,我们再次惩罚了长连接,将简化到人类更容易理解的程度。比如左边的方程,输出了两个不同的多项式。第一个多项式只依赖于 X2 和 X4,第二只与 X1 和 X3 有关。开始时,神经网络连接很「混乱」,最后网络实际上学会了把它简化成两个完全独立的神经网络。
如图(b)所示的网络还具有功能共享,可以完成类似的求平方操作。第三个网络可以将所有基础元素组合成一个神经元,即根号下的部分。如果我们能先训练网络简化它们自身,人类要弄清楚神经网络的工作机制就容易得多。
提取对称性

神经网络通常具有排列对称性,你可以链式地在一层中对神经元进行任何排列而不会增加损失。同时,去掉这种对称性,你可以得到更简单的网络。
假设有一个智能的前馈神经网络,你可以对数据进行任何连续的非线性变换。如果它在某些层上是可逆,你可以使用其它更多的层,使得去除掉那个变换的结果不变,但网络可能会更复杂。我们发现,可以所有不同的连续变换进行化简,这隐藏着一定的对称性。

我们把它应用到一个非常著名的黑洞物理问题上。当卡尔·史瓦兹柴尔德在 1915 年发现黑洞时,度规张量描述了时空的形状。分母要除以 R - 2M。当 R = 2M 时,会除 0。
17年后,Gulllstrand 和 Painleve 发现你可以不断地变换坐标系统。得到没有R - 2M的除法。只有在 R = 0 处才有奇点。他们花了17年才发现这一点。我们的自动化人工智能工具在一小时内发现了这一点。这种方法可以极大地简化这个著名的物理问题。

AlphaGo 等系统的出现让很多人认为我们永远不可能在围棋中打败 AI。但事实证明这是错误的。我们可以对这个围棋程序进行对抗性攻击。通过放置一个小陷阱,诱使电脑包围你的棋子。如果循环足够大,计算机不会注意到这一点,人类还是很有可能获胜。所以,不要相信那些被认为非常强大的人工智能系统,除非你能证明它。

Yann LeCun 在他的演讲中提到,也许大语言模型缺乏世界模型。我听到很多人这么说,但我认为并非如此。在如上图所示的论文中,预训练好的 Transformer 大语言模型被训练去玩奥赛罗的游戏:给定一系列动作,然后训练预测下一步动作。研究者没有告诉它任何游戏规则。研究者用机械可解释性发现这个 Transformer 自己建立了世界模型——8x8的二维世界。这样一来它更容易完成训练的任务。当你使用 GPT-4 时,它显然能够模仿不同的人。如果你开始以某种风格写作,它会试图继续保持这种风格。因此,大型语言模型可以建立外部的模型。
提取函数
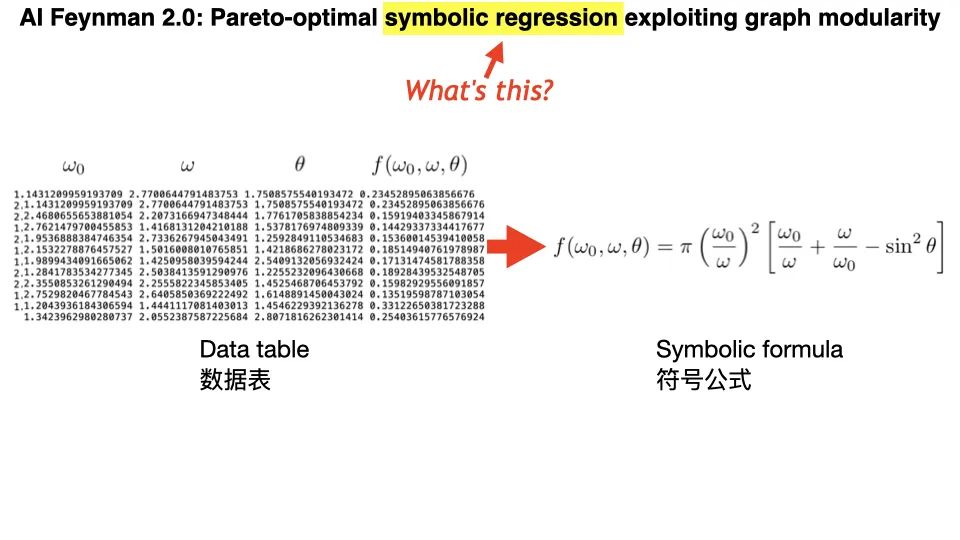
我们尝试用一个公式替代整个神经网络,从「符号回归」的角度解释神经网络。线性函数对应于简单的线性回归。任意的非线性函数,可能对应于 NP-难问题。
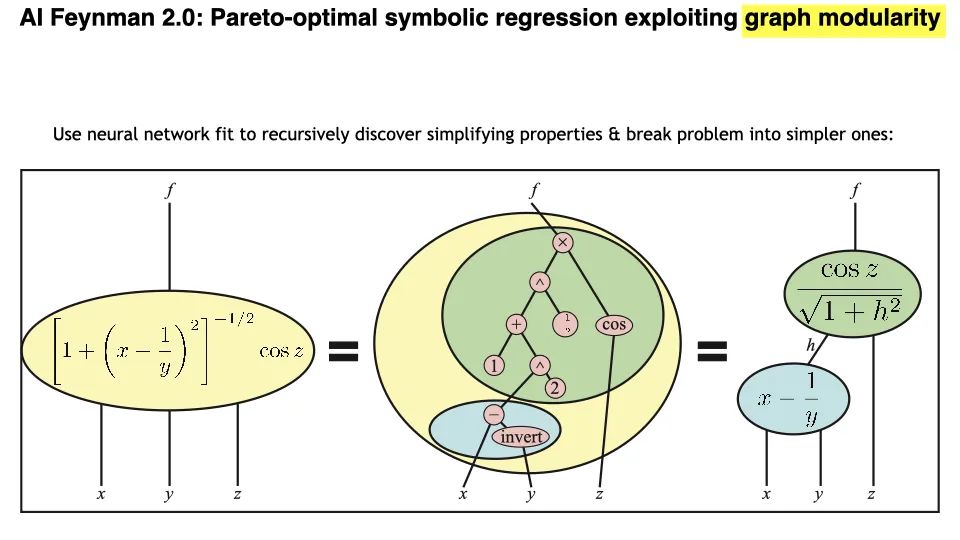
我们在科学和工程中所关心的绝大多数公式都是模块化的。这意味着一个有很多变量的函数可以写成有更少变量的函数的组合。如果先训练一个黑盒神经网络来拟合这个函数,然后通过研究黑盒的梯度并寻找某些代数性质,你可以发现非常复杂的模块性。这样你就可以把复杂的问题分解成许多更简单的问题,进而解决他们。

我们在各种物理课本上的大量方程上做了实验,神经网络在符号回归任务上得到了最先进的表现,黑箱学习的能力是不可思议的。有了发现知识和数据的神经网络,你就可以提取知识。
总之,机械可解释性是一个非常有前途的领域。如果有更多的人加入这个领域,我们就能取得非常迅速的进步,判断是否应该相信 AI,提升 AI 可信度,确保做出值得信赖的 AI。
事实上,我们有希望创造比我们更聪明的 AI,并确保他们是安全的。我们不需要自己证明,可以委托 AGI 或超级智能来证明。如果一台机器给了你一个非常长的证明,你可以通过简单的程序检查整个证明过程。
多尺度对齐
如果我们有这些服从控制机器的人,如何确保人们不会用自己的机器做坏事?正如 Yoshua Bengio 所说:
这令人非常兴奋,我们可以通过人工智能的社会积极应用带来益处。但我也担心强大的工具也会有负面的作用。社会还没有准备好处理这些问题。这就是为什么我们要慢下来,确保开发出更好的约束措施。

众所周知,我们联合全球 AI 学术界、工业界的领袖签署了「暂停大型 AI 实验」的公开信。需要澄清的是,它并不是说我们应该暂停一切人工智能研究。我们应该继续所有精彩的研究,只是说我们应该暂停开发比 GPT-4 更强大的系统。对一些公司来说,这只是暂时的停顿。原因是这些系统会让我们过快地失去对机器的控制,对于超级强大的系统我们仍不太了解。
暂停的目的只是为了让人工智能受到像生物技术一样的监管。在生物技术领域,新药的研发和上市具有严格的审查过程。
如果我们采取相关的约束措施,营造一个公平的竞争环境,确保我们所拥有的一切技术都是安全的,这反而并不会破坏创新。事实上,如果对危险事物的监管过于薄弱,往往会破坏创新。以核能为例,在福岛核事故之后,东西方的相关投资基本上都崩溃了。
我觉得中国确实有独特的机会,为人工智能的安全和明智治理做出贡献。超级智能等非常强大的人工智能的好处和风险当然应该由全人类分享,没有一个国家可以单独解决这个问题。中国确实处于独特的地位。因为中国是世界领先的科技强国。所以中国不仅可以帮助引导研究,让人工智能变得强大,还可以让它变得值得信赖,这就是我所说的。
中国有很强的的国际影响力,在激励和塑造人工智能监管方面,中国的声音真的非常重要。中国相对于西方的一个优势是——中国是现存最古老的文明之一。中国有高瞻远瞩的传统。上周,我很高兴看到中国的全球安全倡议明确谈到了防止人工智能风险。我非常欢迎这种中国的智慧和领导力,这样我们就可以通过控制人工智能来拥有一个美好的未来。
谢谢你,中国!
- 点击查看原文 观看大会回放 -

独家专访LAION创始人:高中生与科学家同酬,Discord上一呼百应

黄铁军:难以预测,无法闭幕 | 2023智源大会“AI安全与对齐论坛”