一、Linux 存储堆栈图
当使用 read() 和 write() 系统调用向内核提交读写 I/O 请求操作时需要经历的步骤:
1)首先,请求经过虚拟文件系统,虚拟文件系统提供了统一的文件和文件系统的相关接口,屏蔽了不同文件系统的差异和操作细节;
2)其次,适配当前磁盘分区的文件系统,常见文件系统有 ext2/3/4、FATfs、sysfs、debugfs 等;
3)再次,内核将 I/O 请求交给 I/O 调度层进行排序和合并处理。经过 I/O 调度层加工处理后,将 I/O 请求发送给块设备驱动进行最终的 I/O 操作;
4)最后,通过总线协议对数据进行下盘或者读取操作。
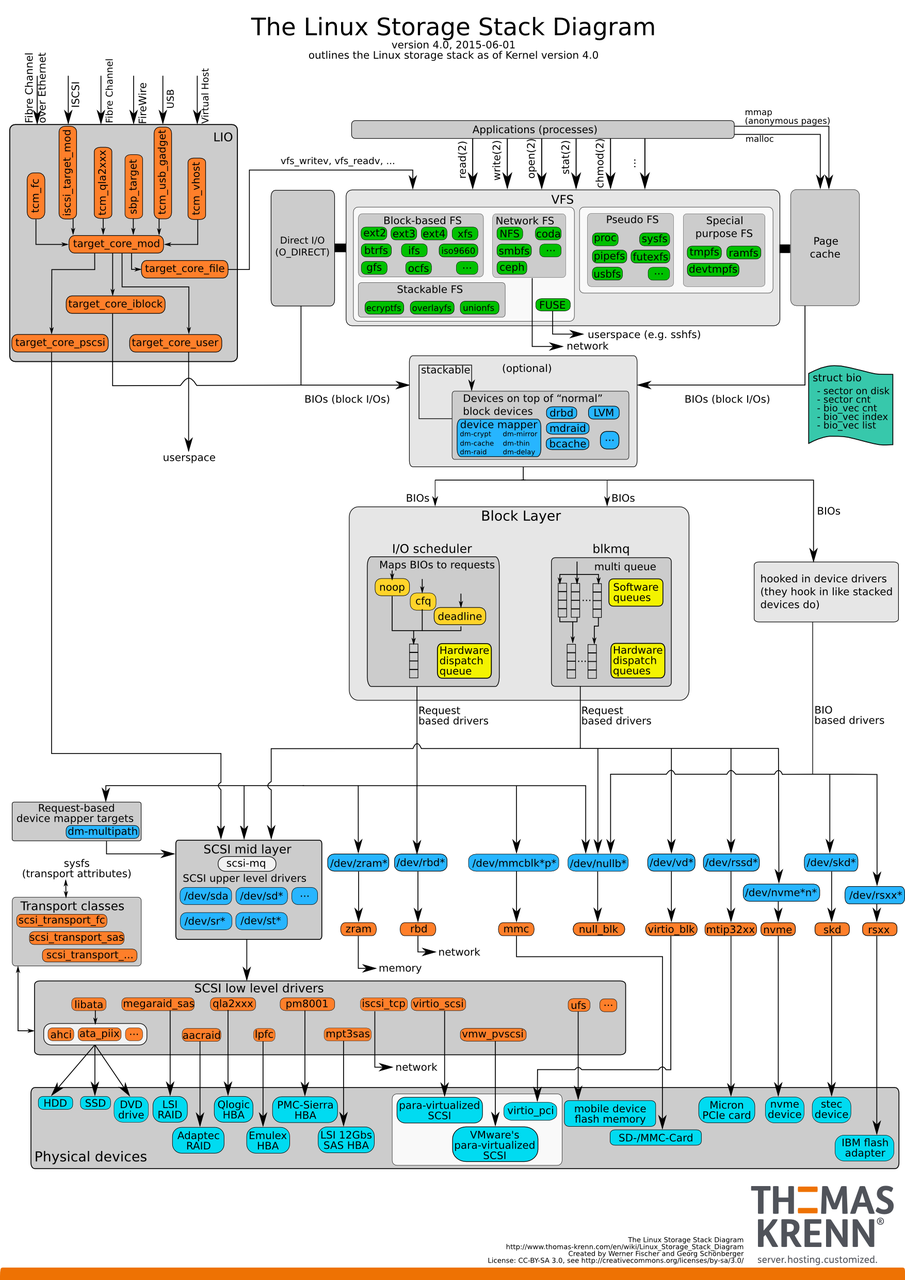
二、系统调用函数与存储介质交换
SQL 查询执行过程:
-
客户端发送一条查询给服务器
-
服务器优先检查查询缓存,如果命中了缓存,则立刻返回缓存中的结果,否则进入下一阶段
-
服务器端进行 SQL 解析、预处理,再由优化器生成对应的执行计划
-
根据优化器生成的执行计划,再调用存储引擎的 API 来执行查询
-
最后将结果返回给客户端

三、操作系统关于优化存储堆栈的参数
1) dirty_background_ratio:内存可以填充“脏数据”的百分比
这些“脏数据”后续将写入磁盘,后台进程会清理脏数据。比如现有 32G 内存,那么有 3.2G 的内存可以待着内存中,假设超过 3.2G 就会有后来进程来刷盘;
2) dirty_ratio 是绝对的脏数据限制,内存里的脏数据百分比不能超过这个值
如果脏数据超过这个数量,新的 IO 请求将会被阻挡,直到脏数据被写进磁盘。这是造成 IO 卡顿的重要原因,但也是保证内存中不会存在过量脏数据的保护机制;
3) dirty_expire_centisecs 指定脏数据能存活的时间
默认数值是 30 秒。当后台进程在刷盘时,它会检查是否有数据超时,如果超时就会触发刷盘操作,尽量规避数据在内存中储存过久后的丢失风险。

四、IO 优化在 KaiwuDB 中的应用实践
1) 通过观察 CPU 使用情况并借助火焰图,发现 KaiwuDB 内核程序进程内的性能瓶颈点,包括但不限于:
a. 进程服务压力与后台服务处理能力不匹配;
b. 操作系统参数设置不匹配导致 CPU 占用低;
2) 通过 iostat 和 vmstat 观察磁盘性能工具,发现进程写入速度与后台处理速度、磁盘处理速度不匹配,需要进行参数调优;
3) 借助 KaiwuDB 内部的日志及性能统计工具(Trace 功能模块和监控工具 KAP),发现某些应用及服务的性能瓶颈,调整优化进程程序逻辑。