目录
集合介绍
为什么使用集合?
当我们想要保存一组数据时,可以使用到的变量类型有集合和数组。那么就像说一下数组的局限性:
- 数组一但类型确定,整个数组就只能放置此类型的数据,当然可以指定为类型为Object。
- 数组长度固定,当数据超出预先设定的大小时就会出错。有些集合类型虽然底层采用的也是数组,但集合对数组自动进行了管理,自动进行扩容,拷贝。
- 数组选择性少,无法根据数据使用情况选择合适的数据结构。数组就是一种
数组数据结构,数组数据结构的特点就是一块连续的地址空间,可以很快的根据序号计算出各个元素的内存地址,但如果在中间插入数据、删除数据就需要将后面的数据依次地移动,因此对于一些频繁发生中插入和中删除的数据就不能选用数组。而集合采用的类型可以有很多,例如:linkedList就是采用双向链表的方式。数组只有一种类型进行选择,而集合对于数据频繁发生删除和增加可以选择链表类型结构。
数组比较原始,而集合功能比较丰富,有的集合底层就是个数组,是在数组基础上的一些功能的增强。数组只是一种数据类型,而集合可以使用的数据类型更多,像链表、数组、哈希表、红黑树等
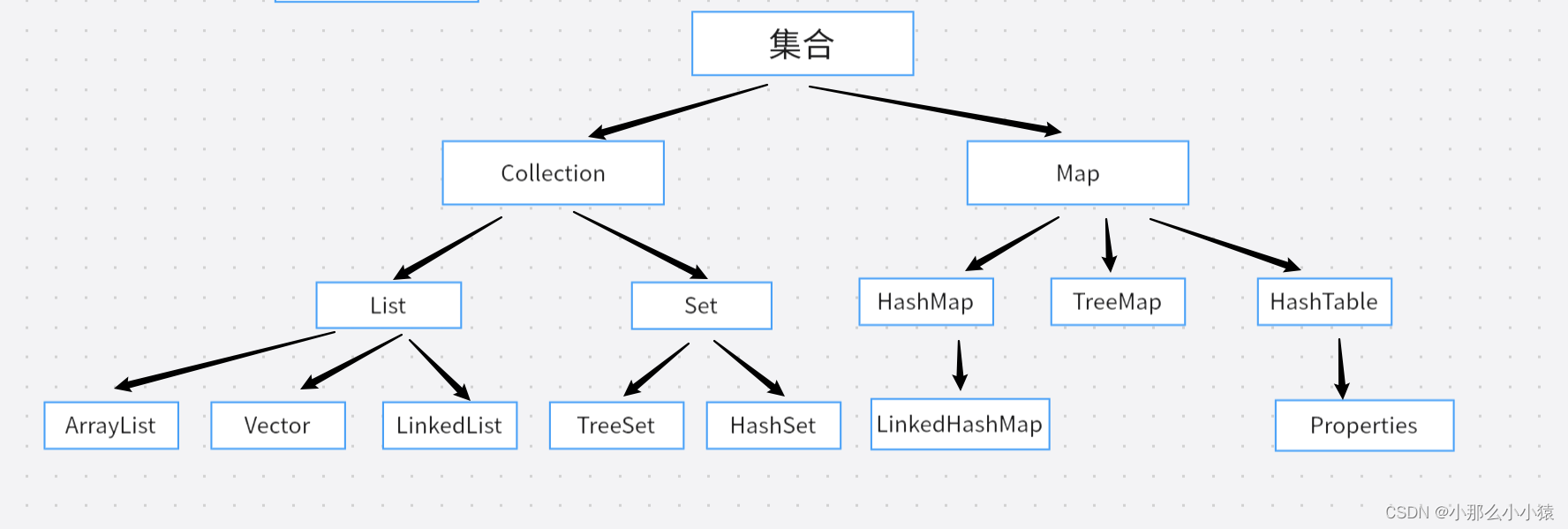
集合分为单列集合和双列集合,单个值为一组的就是单列集合,K_V为一组的就是双列集合。
单列集合又分为两个大类,一个List,一个是Set,双列集合只有Map(k_V键值对方式,K不可重复)一个大类
为什么每种集合的功能不一样呢?因为他们要么底层数据结构不同,要么扩容机制不同,要么安全机制不同等。
一个种类的集合按照需求不同分为了许多种,这里只介绍具常用到的几种类型。注意下面这个图只是进行一下分类而不是表示类和类的父子关系
在读源码时发现一个特点:源码中真的很喜欢在判断,循环时进行赋值
Map
HashMap
HashMap的构造方法

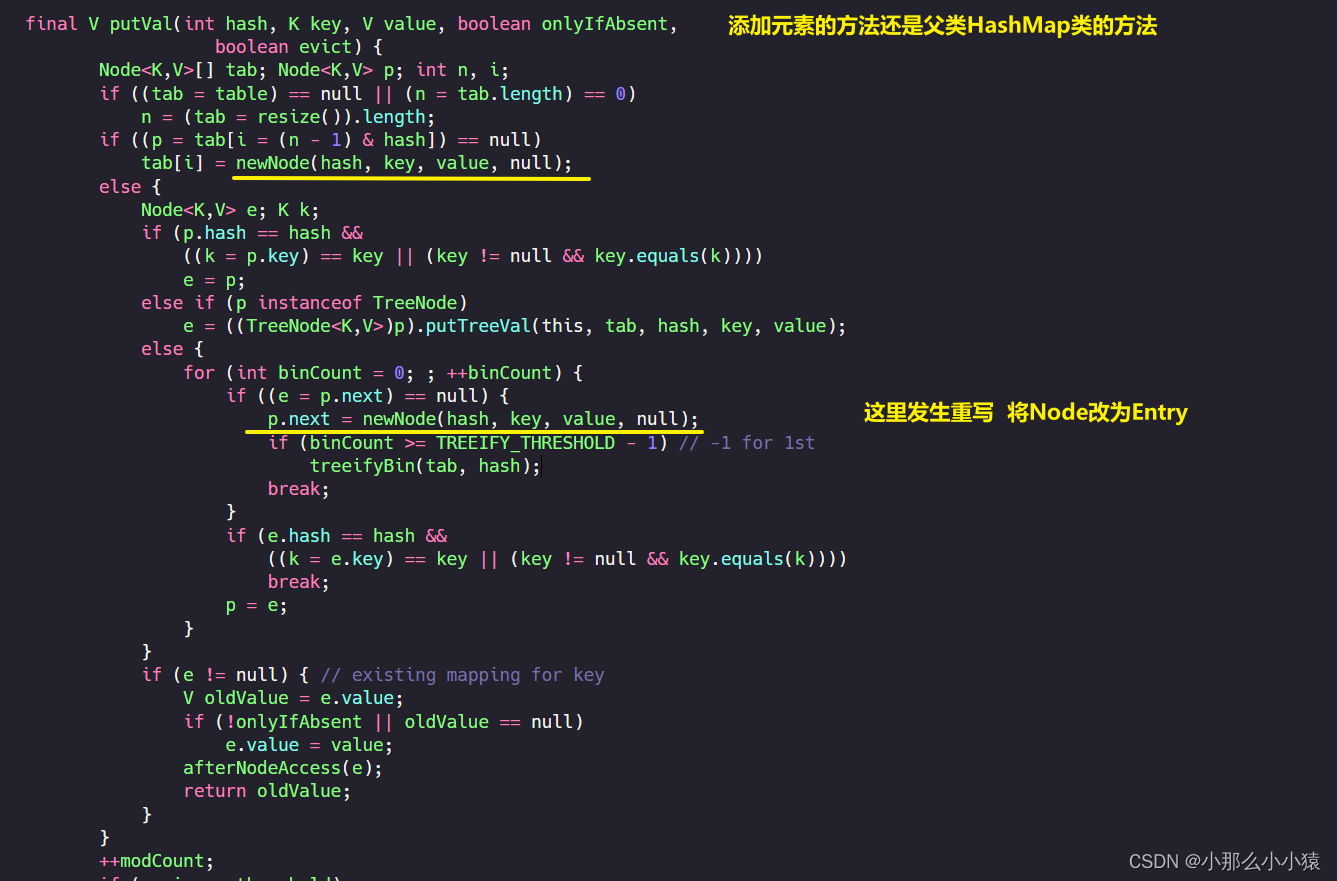
当添加一组K_V键值对时
先了解HashMao底层是怎样存储的
当放入一组key_value键值对时,先将key进行hash运算,然后根据hash运算结果除以底层Node<k_v>数组的长度计算出存储在Node<k_v>的位置,如果此位置已经有值,就向后存储,使得在Node<k_v>数组相同位置的节点形成一个单链表的结构。当链表数量超过8时,就对Node<k_v>数组进行扩容,如果已经扩容数组长度已经到64长度就将链表进行树化,转为红黑树。
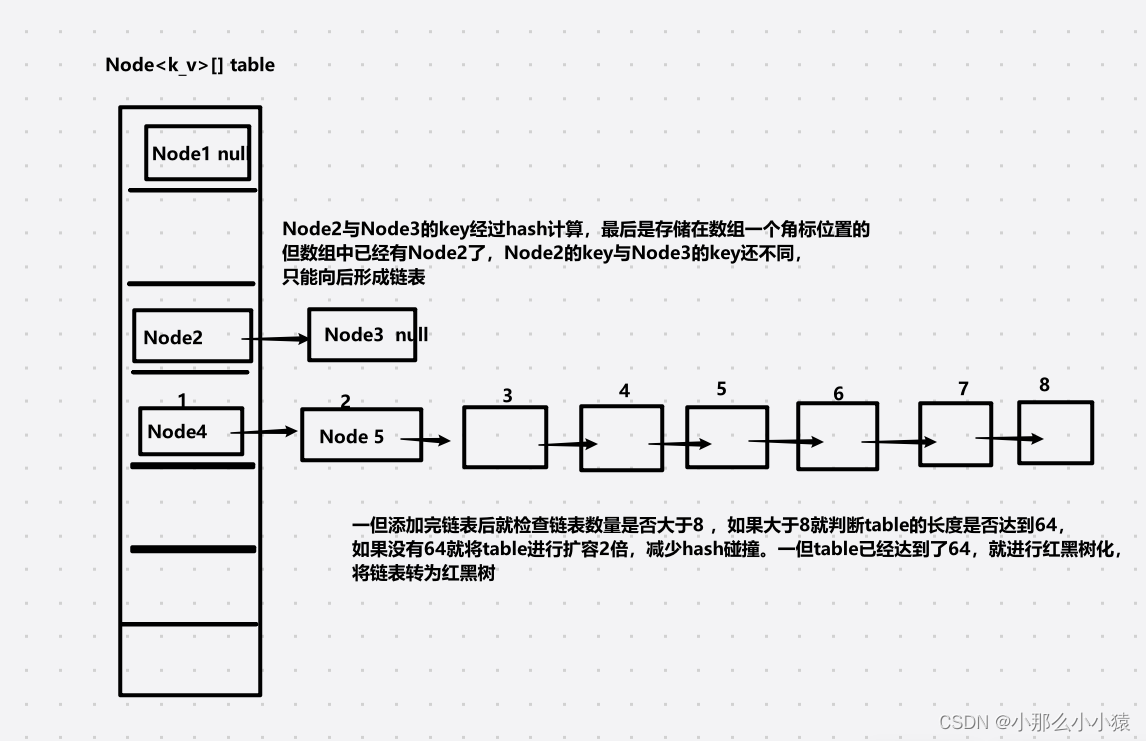
下面将详细介绍这一过程:
先将key判断是否为null,为null则值为0,不为null则获取它的hashCode右移16位

每一组k_v键值对底层都是存储在Node<k_v>中的,而Node<k_v>继承了Map.Entry<k_v>
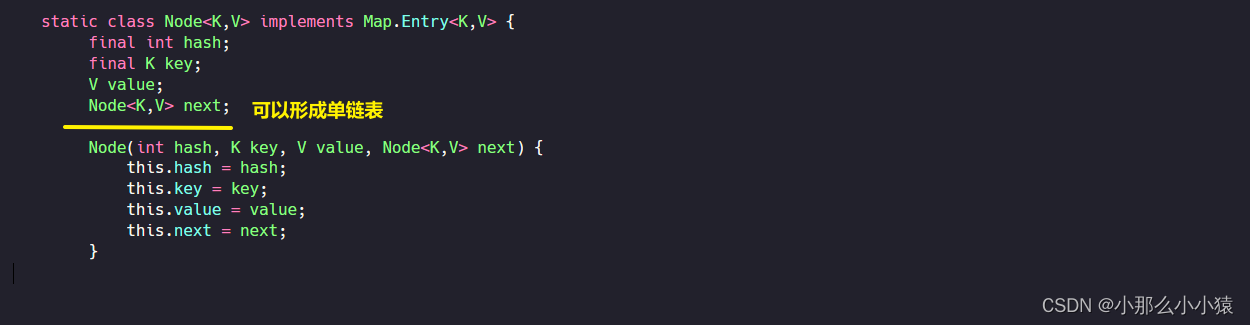
具体的存储过程
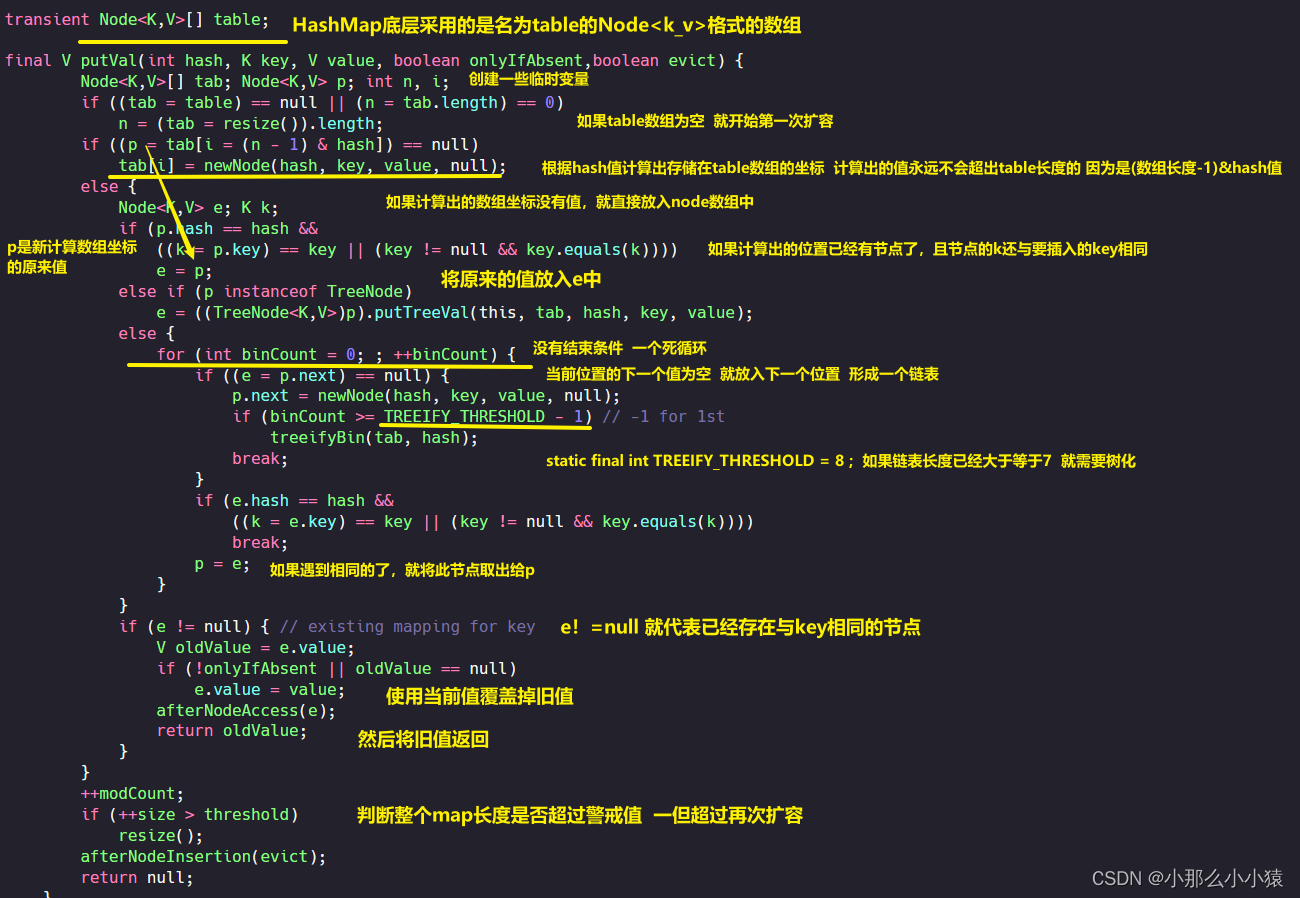
HashMap的底层是一个名为table的数组,当计算出的数组坐标已经有值时,就会以链表的形式向后存储。如果发现与自己hash值页相同的key,就将旧值取出然后使用新值覆盖掉。在此期间共发生两次扩容,一次是当table数组长度为0时,一个是当table数组长度(每次添加size就会++,所以算上了链表长度)达到警戒值时。那么扩容是怎样过程呢?这就需要查看resize()方法
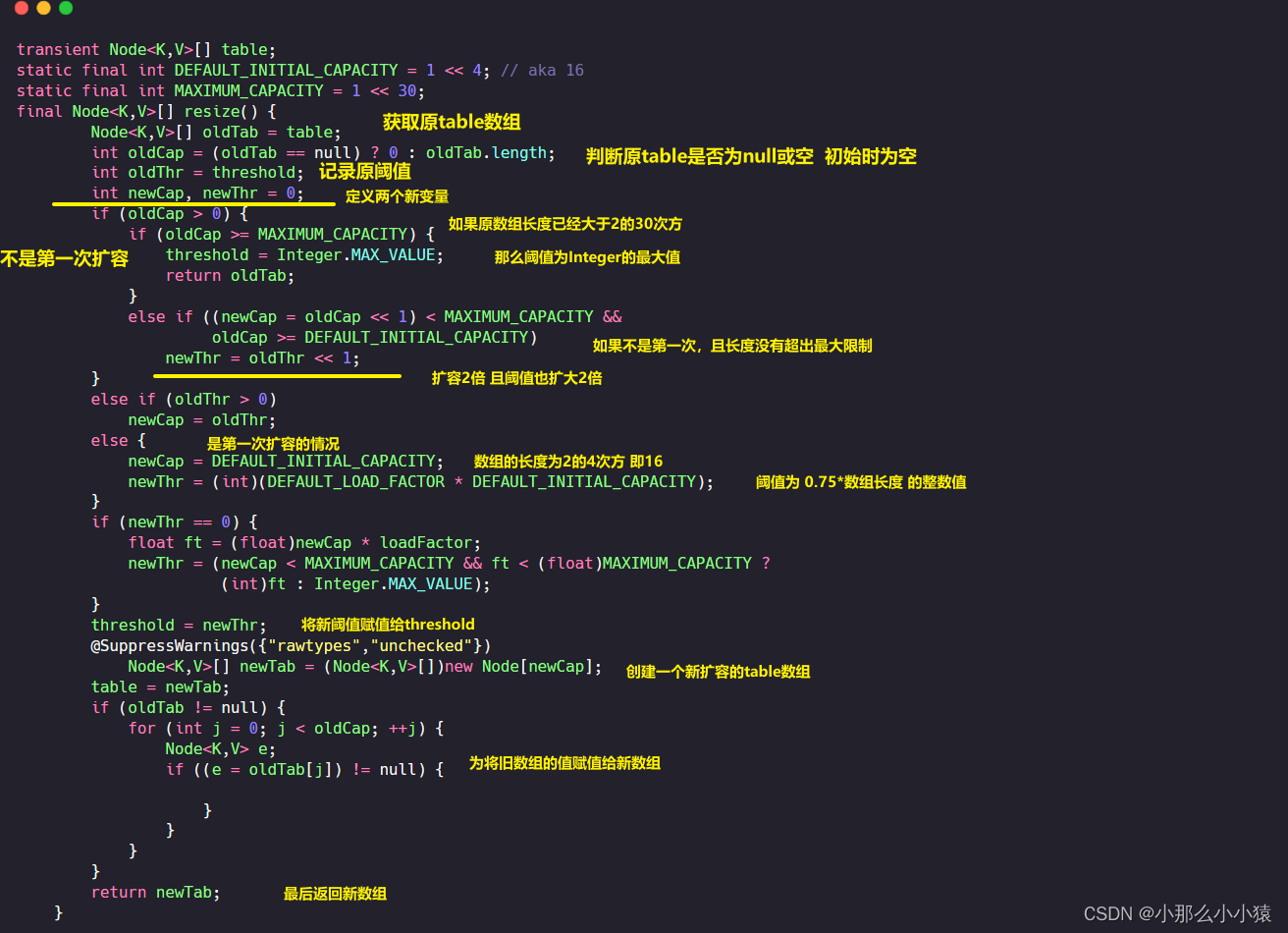
以上是当table表的总数超过阈值时或第一次向空table数组放入新值时对table数组的扩容,当单个链表的总数超过8并table数组小于64也会进行一次扩容

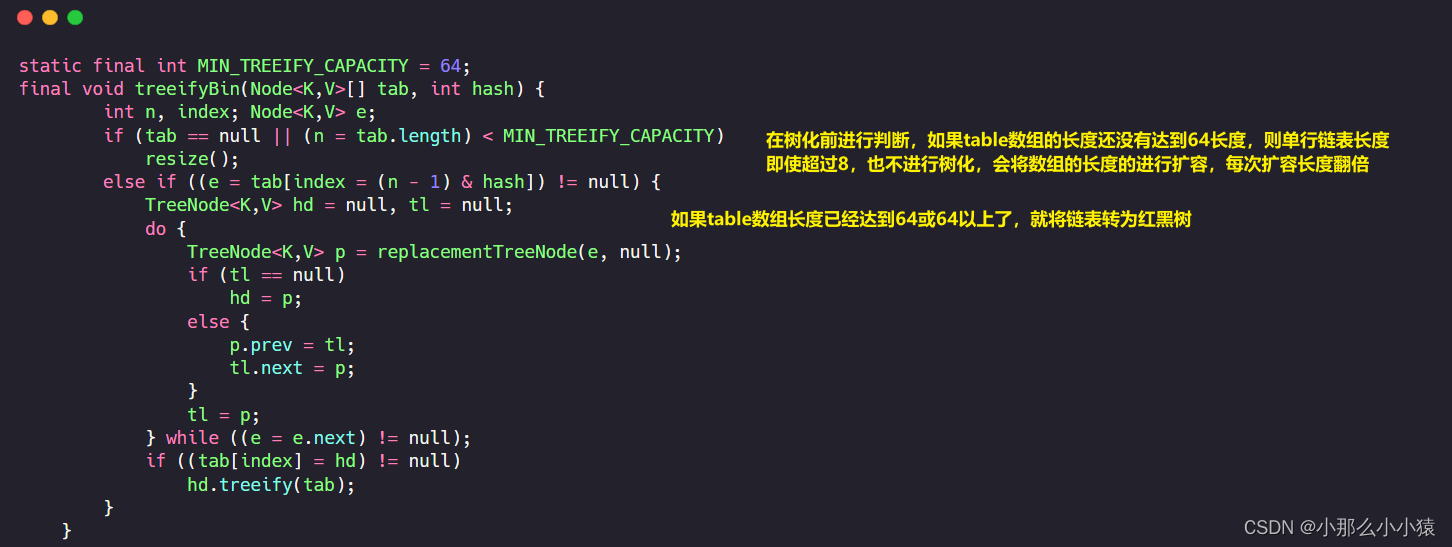
那么为什么HashMap要采用数组+链表+红黑树这种存储方式呢?数组的特点是查找快,长度有限,但使用hash来确定数组角标容易产生hash碰撞,这就不得不使用链表。在根据key查找value时,先对key进行hash计算,这样就可以快速的定位但数组的某个位置。但这个位置可能有多个节点,因此就需要沿着链表依次比对key。但当这个链表过长时,就会使得在链表上查找花费的时间过长。因此当链表数量达到8时,要么对数组进行扩容,减少hash碰撞的概率,要么将链表进行树化,提升key的查找效率。
hashMap是如何根据key来查找元素的呢?

思考:如果判断是否是要查找的节点的呢?
源码中已经给出,Hash值要相同(在添加节点时已经放入Node节点中),key要相同。HashMap的key不仅可以使用String类型,还可以使用对象。
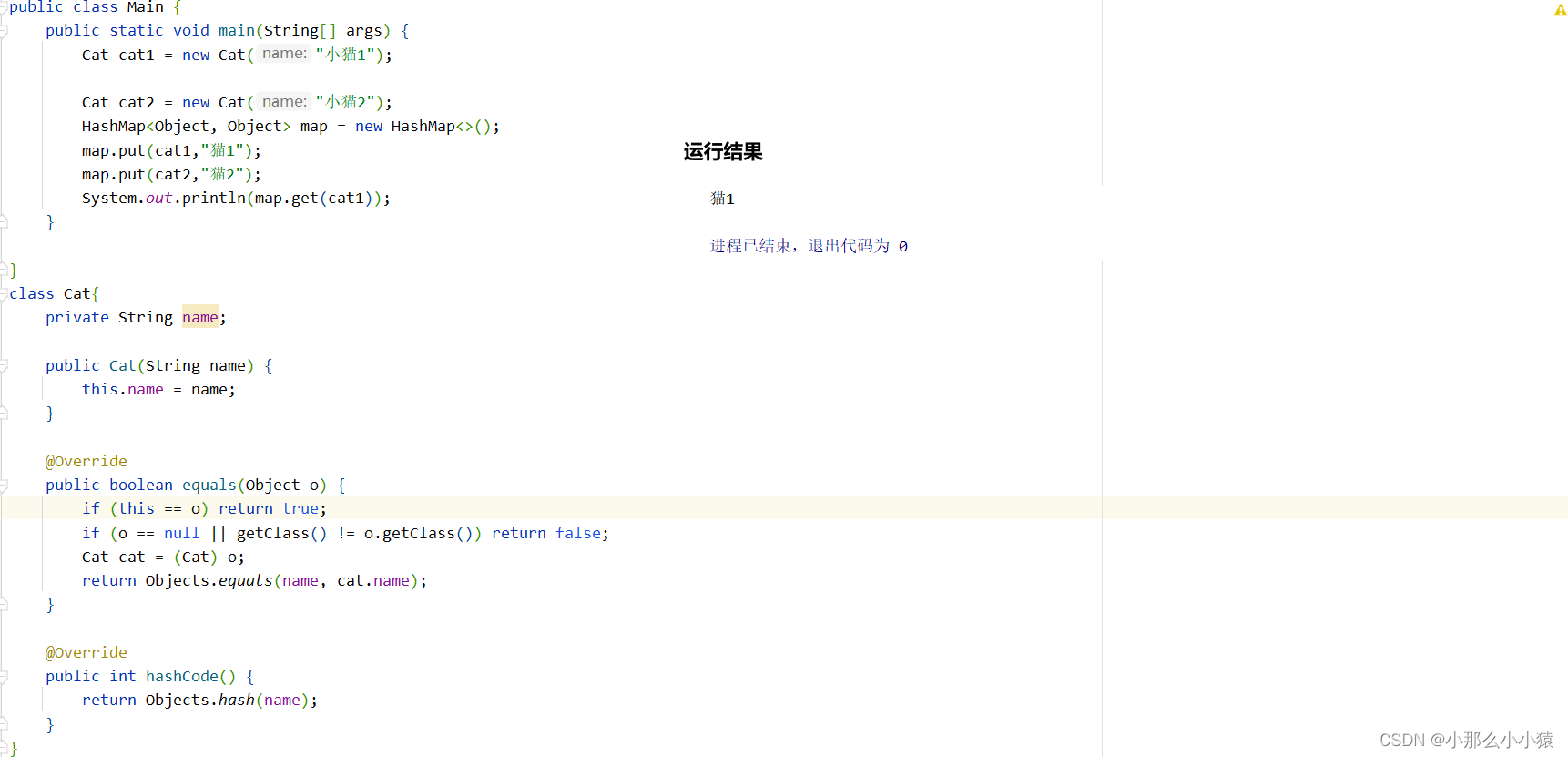
那么要想使得cat1对象能够覆盖掉cat2对象,或者是同一个类型的对象在map集合中只能有一个,或者只根据某个属性判断是否为同一个key,要怎么操作呢?
首先就要明白是如和判断key相同的,前面已经介绍过:hash值相同在比较key是否相同或相等。那么这就只需要重写每个类的HashCode和equals方法,使其能够按照我们的想法对判断是否为同一个key。

HashMap的几种遍历方式
为什么说HashMap的插入时和遍历时是无序的呢?因为HashMap再插入时,是根据计算key的Hash值来获取要插入的数组位置的,而不是按照先后顺序在数组中依次排列。在遍历时,是按照数组顺序进行遍历的,这就会导致虽然插入顺序不一样,但他们在数组中或者在链表中是相连的,使得遍历结果顺序相同。
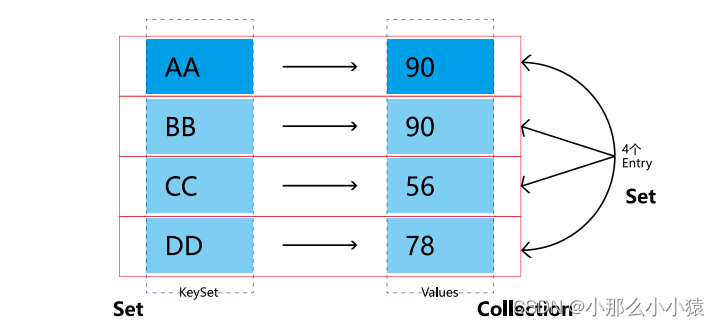
Map集合可以将key单独放在一起作为一个keySet,将Value值放在一个作为Values,每一组key_value为Entry。但注意的是在无论是调用keySet()方法或Values()方法时,返回的值也是通过遍历Map获得的,不是又将key或Value再单独存一份。
例如:keySet源码
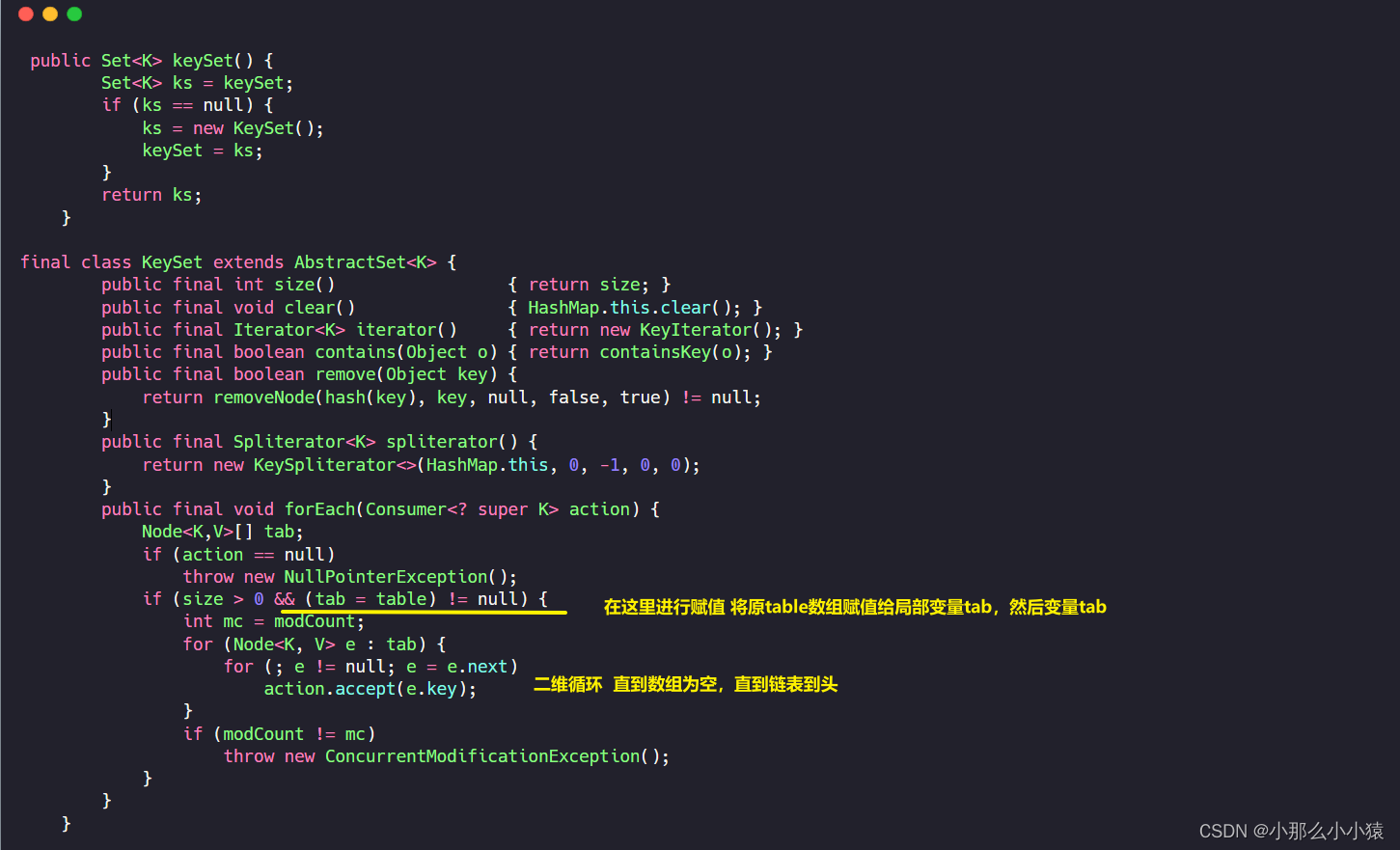
从这个源码中,可以知道KeySet可以为一个Set集合也可以为一个对象,有size(),Clear()方法等。
使用KeySet()获取Keys,在通过Map查找key进行遍历


使用EntrySet()获取或者组k_v值



LinkedHashMap
LinkedHashMap继承了HashMap类。将Node<k_v>这种单链表的基础上,多了个before, after指针,一个节点指向单向链表下一个节点的同时,还指向了它的上一个插入元素和下一个要插入的元素。


这样就使得map的插入能有先后顺序,能在原数组和链表的基础上,通过第一个插入的节点顺着链表能一直找到最后一个节点
插入规则还是HashMap的方法,只是将Node节点更换
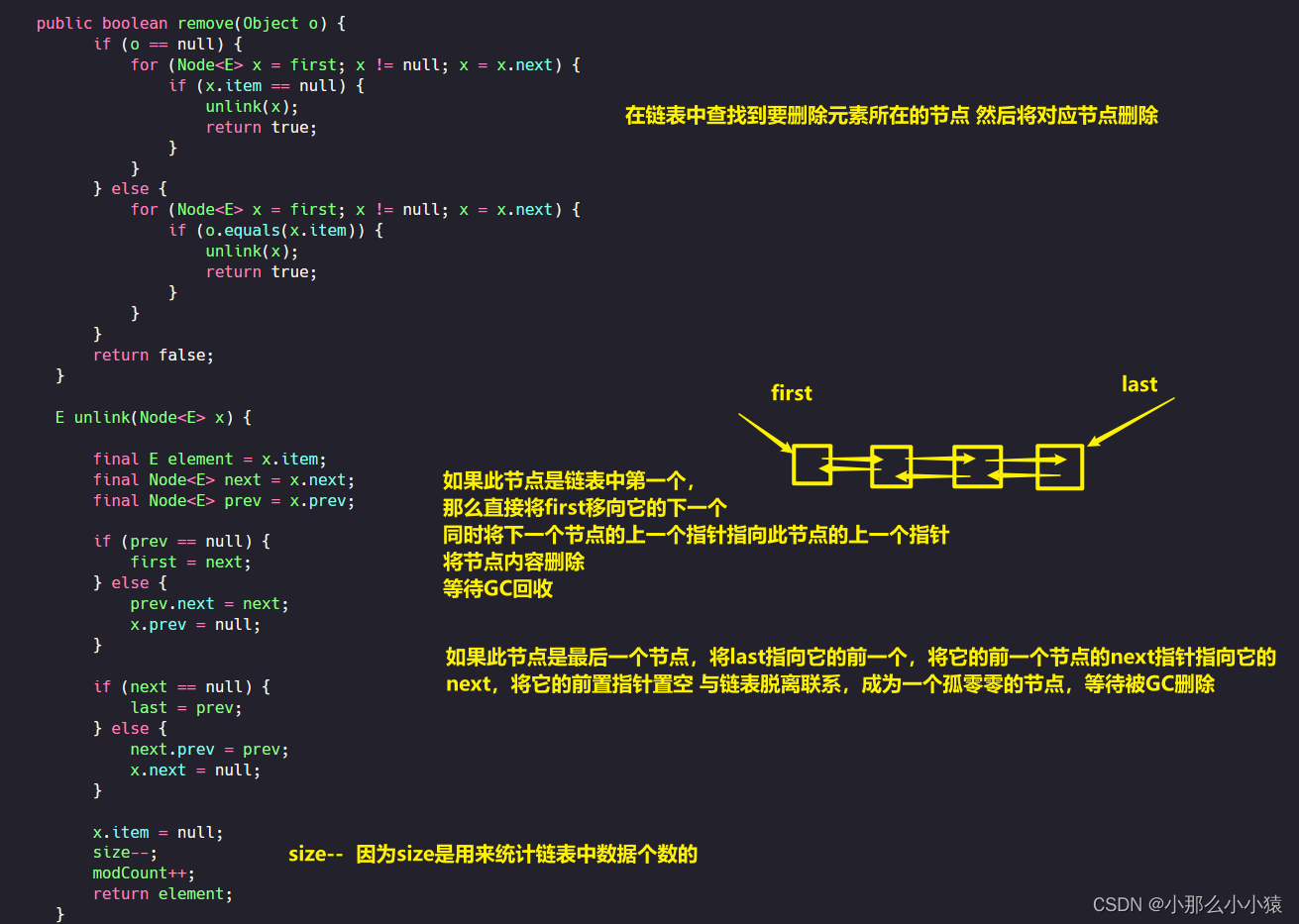
相同与Hashmap中维护着两条互不相干的结构,一个存储用的链表/树,一个是用来遍历的链表,由first指向头,last指向尾

在插入一个节点时,将原最后一个节点由新节点的before指针指向,同时将自己的节点赋值为tail,原最后一个节点的after指针指向最新插入的节点。这样在原HashMap的基础上,由插入顺序形成一个形成的单链表,使得插入有序
当LinkedHashMap执行keySet()时,原HashMap是直接遍历table,然后遍历链表,那么看看作为有序LinkedhashMap是如何进行遍历的呢?
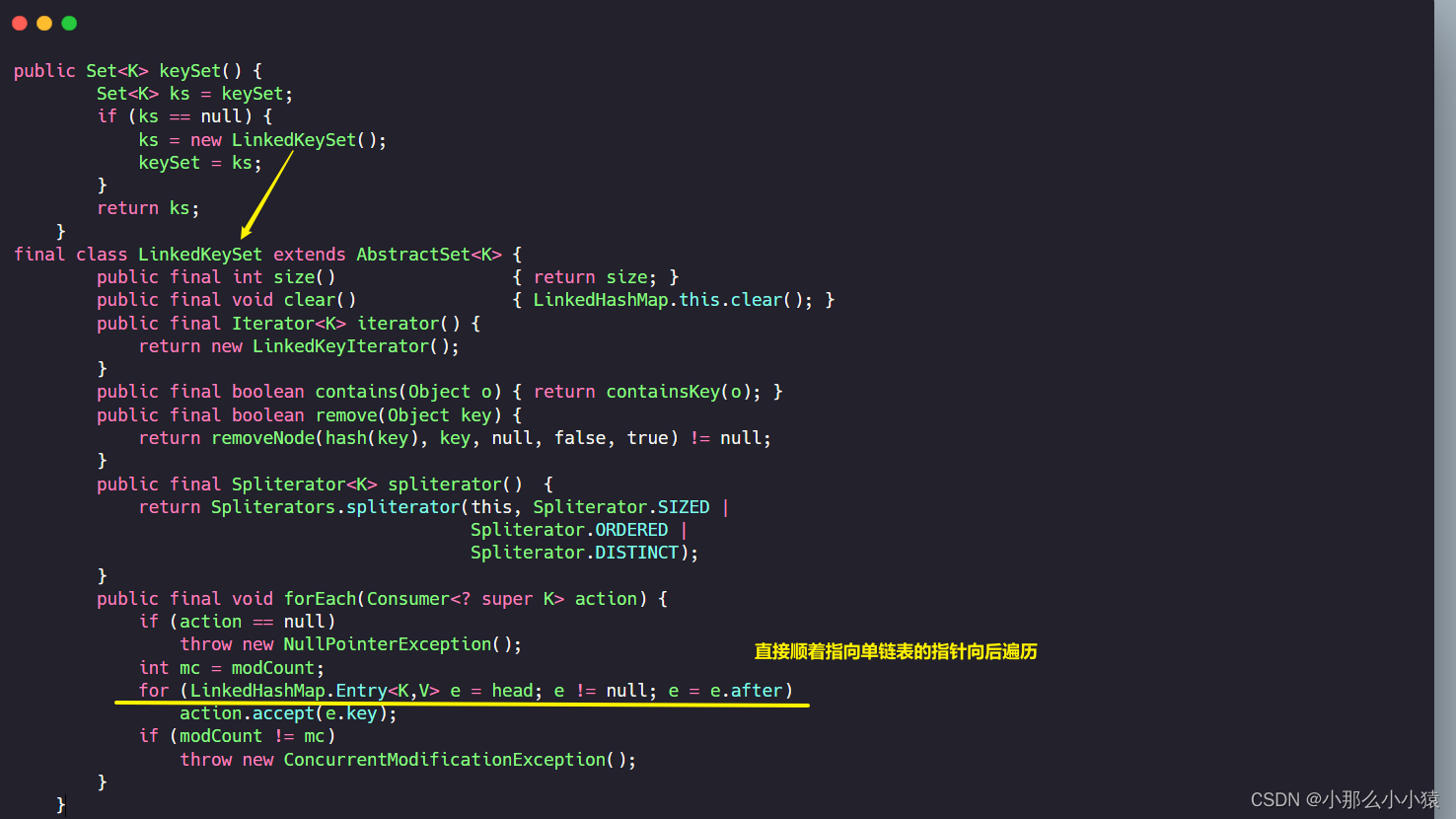
LinedHashMap与hashMap遍历对比
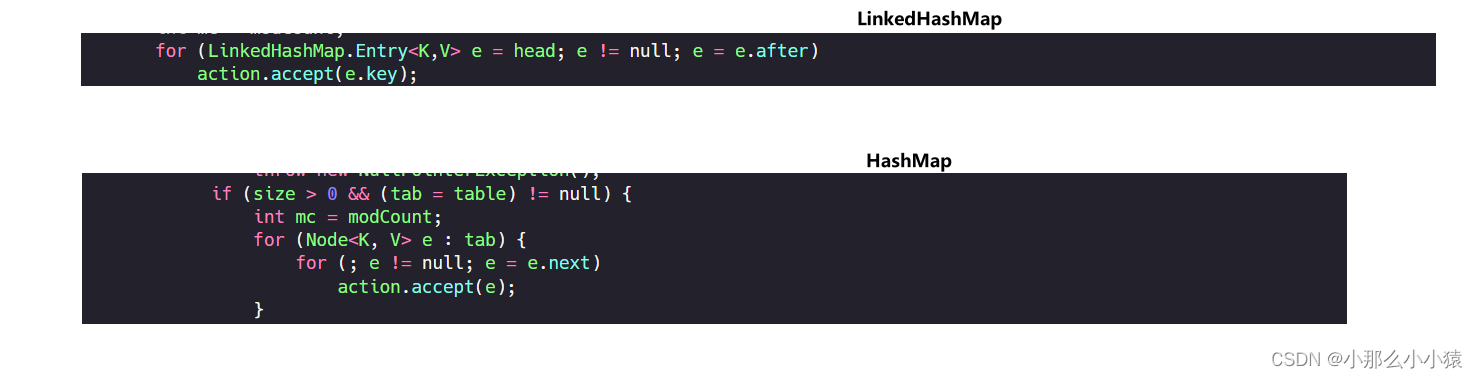
值的注意的是:LinkedHashMap与HashMap很像,LinedhashMap只是多个按照插入顺序形成的链表,两者在遍历方式外其余相差无几,二者都是不安全的
HashTable
Hashtable的构造时就已经对table数组完成初始化
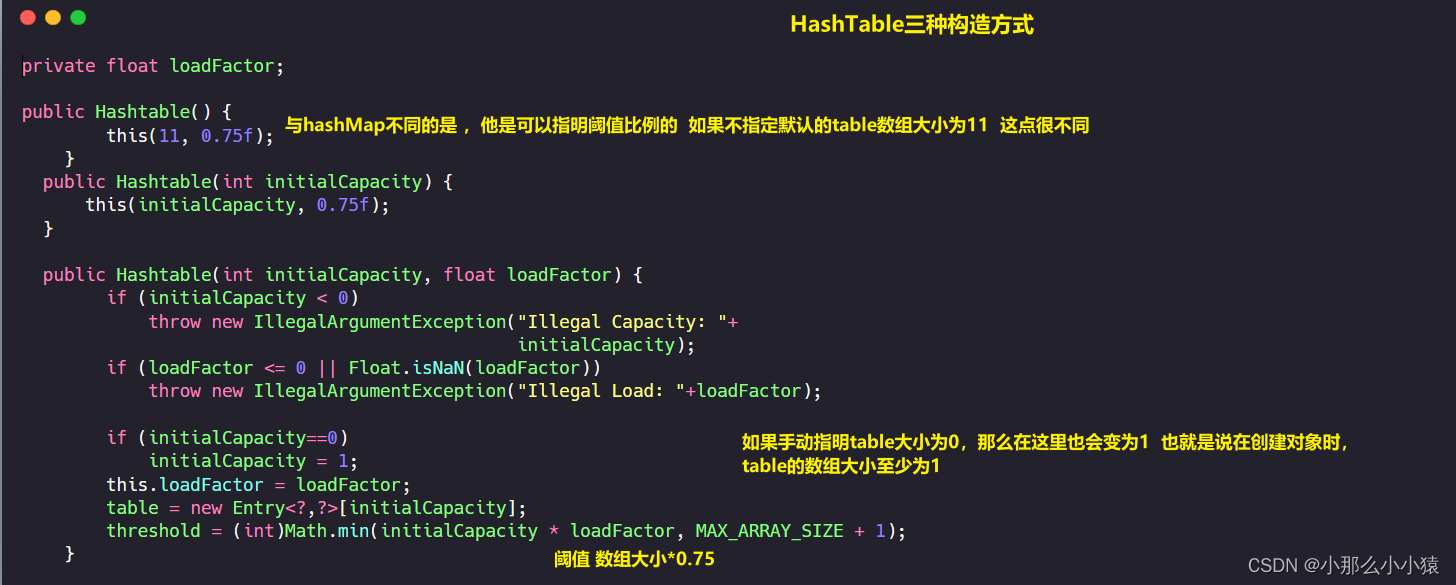
接下来让我们看一下HashTable的插入方式 HashTable的扩容机制与插入方式很特殊


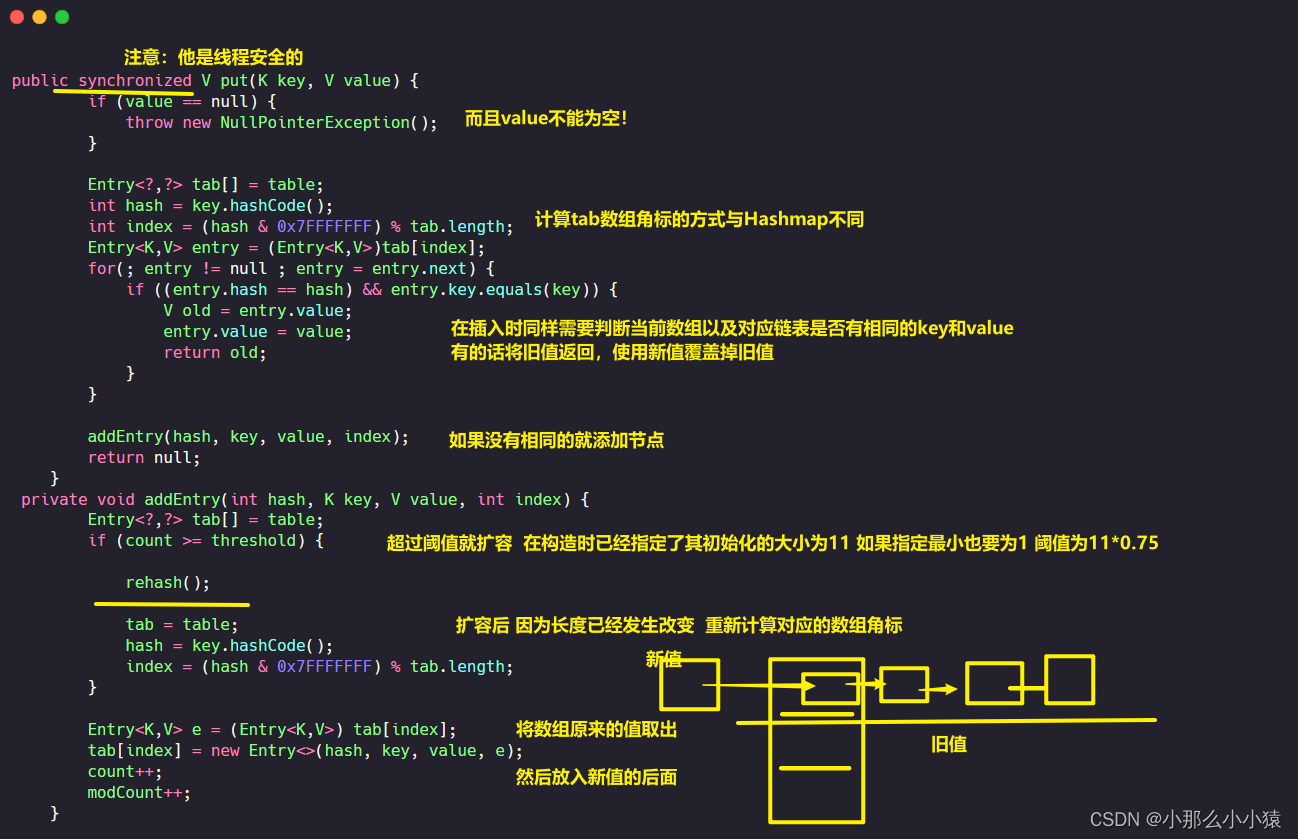
思考:Hashtable单纯在put数据时与HashMap有哪些不同呢?
- HashTable在构造时就指定table的初始大小,默认为11,手动指定最少为1
- HashTable计算存储数组角标是
(hash & 0x7FFFFFFF) % tab.length而hashMap是(n - 1) &key.hashCode()) ^ (h >>> 16)。 - HashTable是线程安全的,put方法有
synchronized修饰,HashMap就是线程不安全的 - HashTable插入数据时,是插入链表的前面,将此数组以前的空值也好,单个Entry也好,Entry链表也好,都放入插入节点的
next后面 - HashTable的
Value在插入时不能为空。 - Hashtable使用count记录节点数量,HashMap使用size记录
- 扩容时机于条件不同

相同部分:
- 阈值比例依旧是0.75,但Hashtable在构造时可以指定
上面源码中当count >= threshold是会进行 rehash()也就是扩容,那么接下来介绍一下扩容的源码
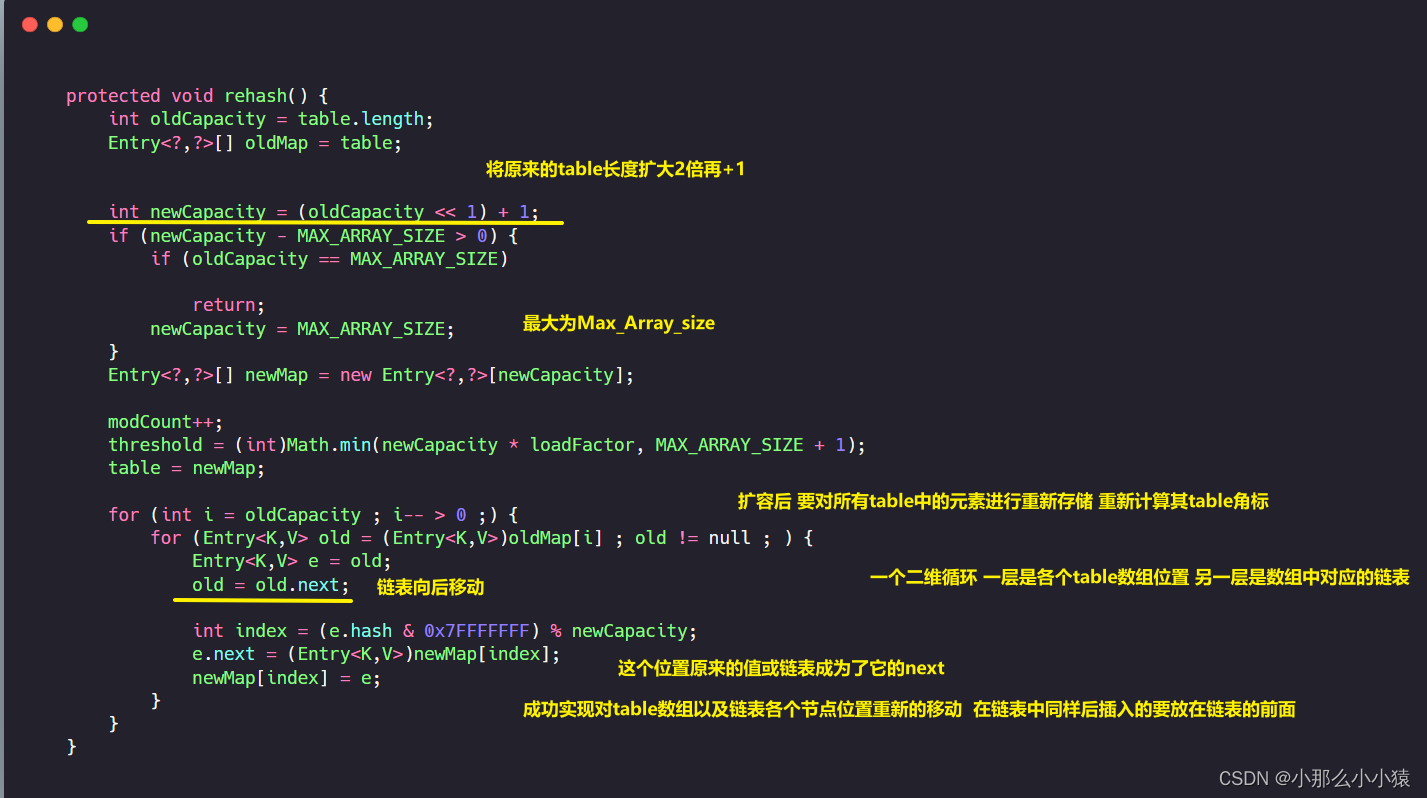
扩容方面与HashMap不同:
- Hashtable扩容需要对数据重新移动位置
- HashTable对链表的长度没有限制,没有
树这一说
Properties
Properties继承了HashTable,与Hashtable很像,更适合用来读取配置文件并将其转为hashTable
Collection
Collection是一个单向集合的接口,在接口中定义了很多方法为所有单向集合共有的功能。
List
ArrayList
ArrayList底层是一个名为elementData的数组,在创建ArrayList集合时,提供有参构造和无参构造
如果直接使用new ArrayList(),这种就是无参构造,在构造器的内部会为elementData数组赋值一个Object类型的空数组
无参构造创建ArrayList对象

在构造ArrayList时,传入Collection集合,就会在将此集合完成转换,并在此集合基础上进行操作。

在创建ArrayList对象时指定初始数组大小

在向数组中初始添加元素时,会将elementData数组扩容至10
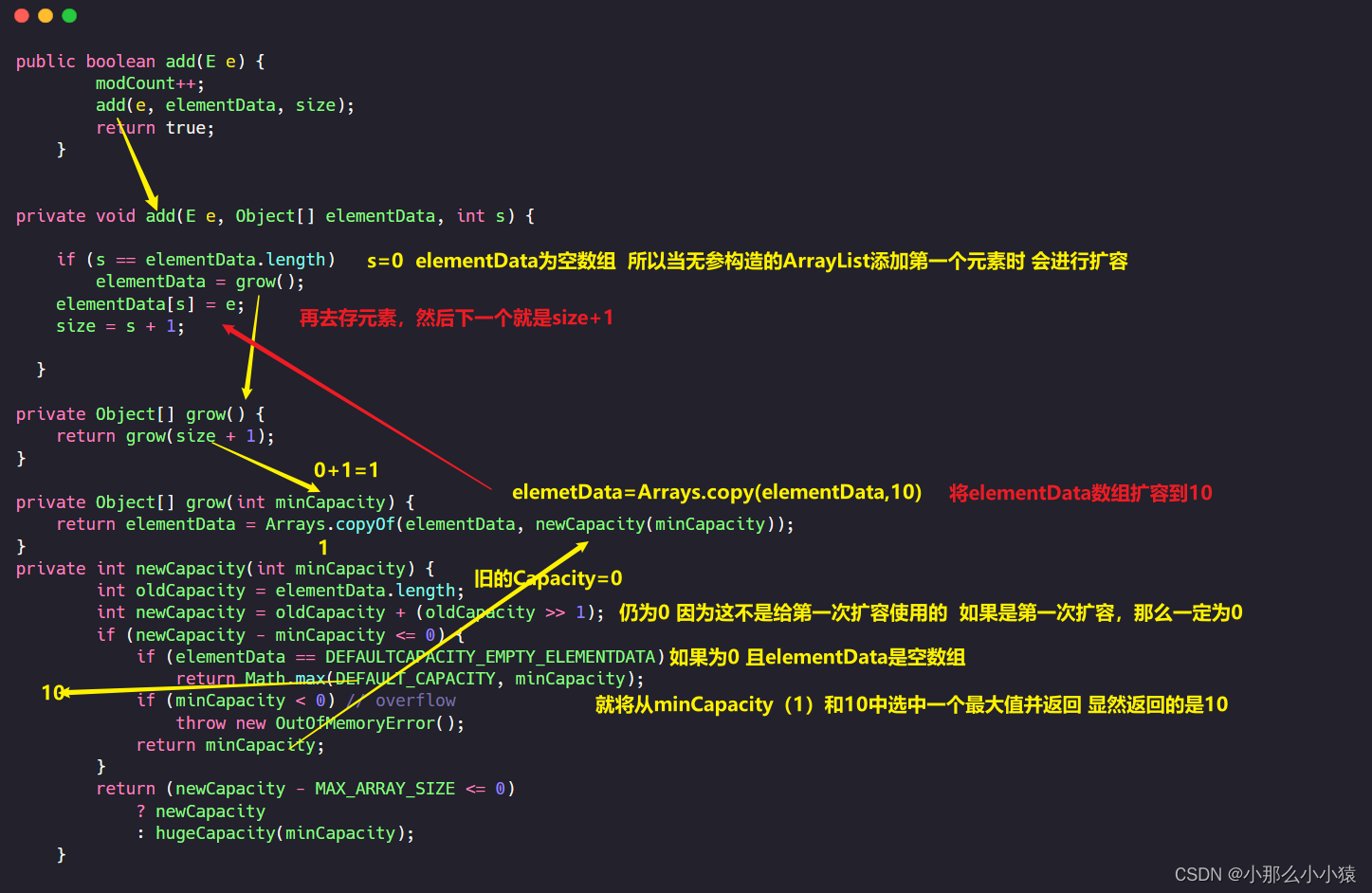
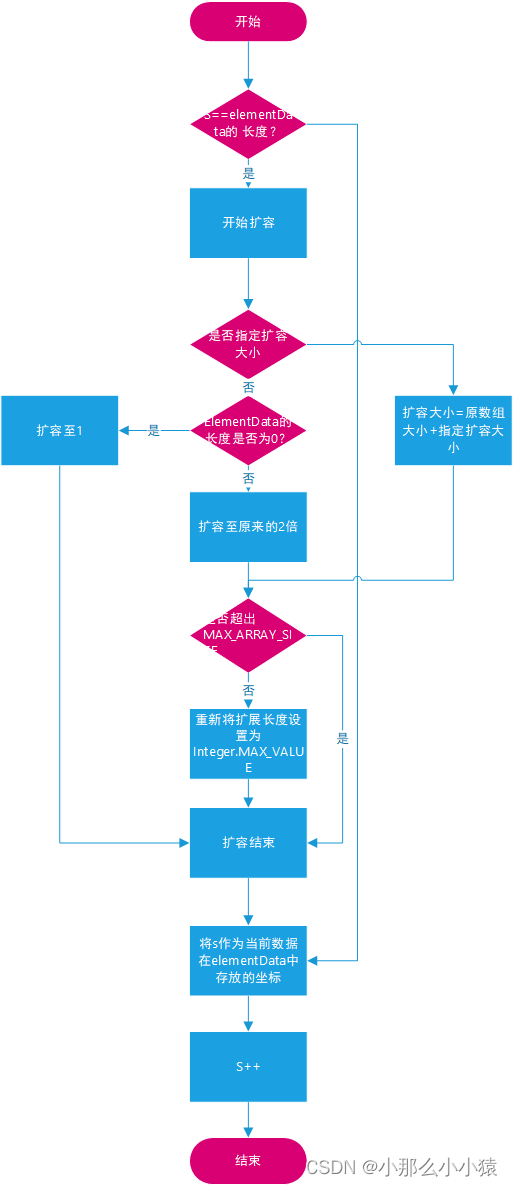
那么当扩容的数组容量用完了怎么办?1.5倍扩容
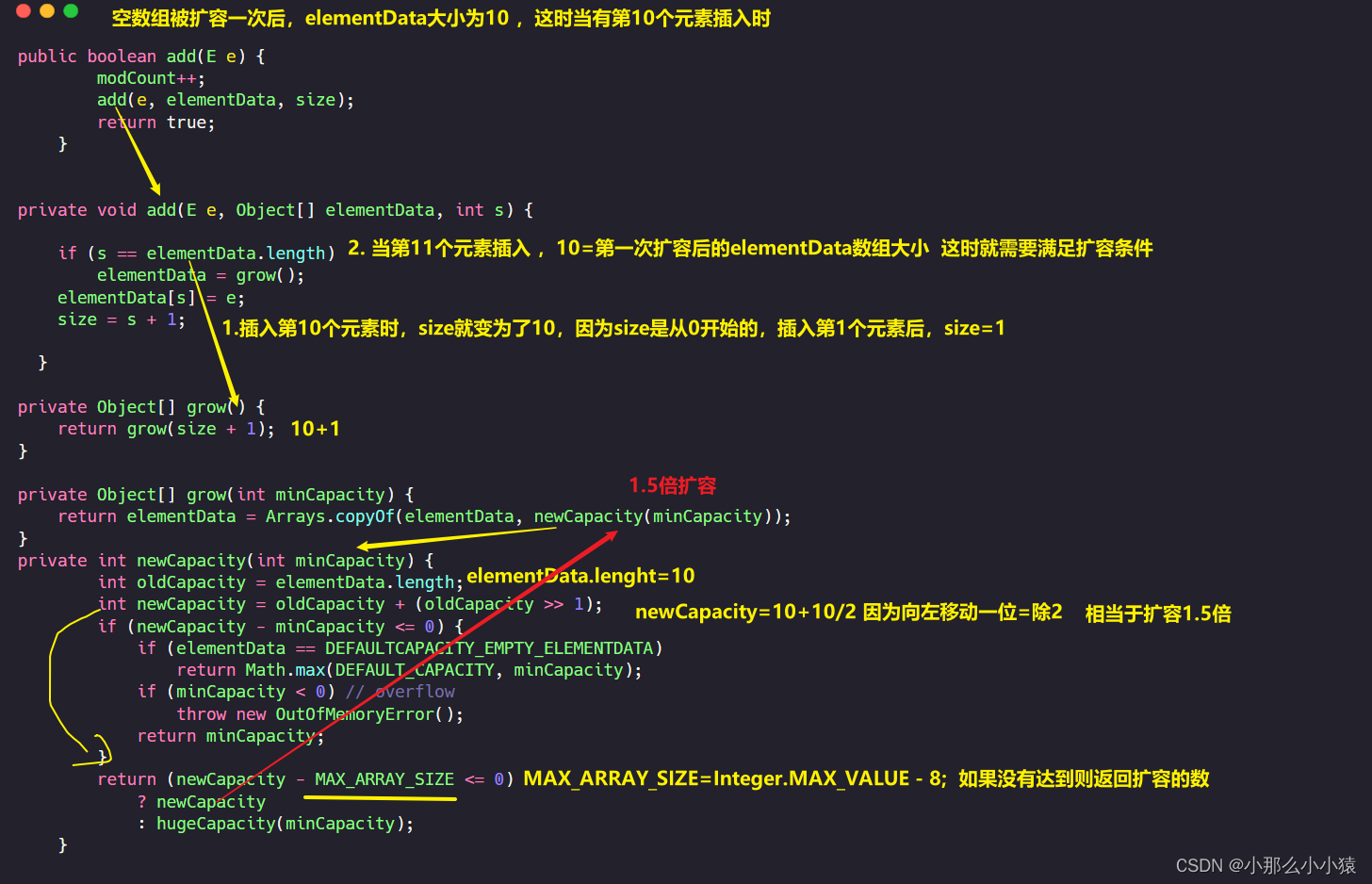
如果扩容后已经超出MAX_ARRAY_SIZE大小,那么就不在采用1.5倍的扩容方式,而是直接返回Integer.MAX_VALUE

总结ArrayList的扩容方式
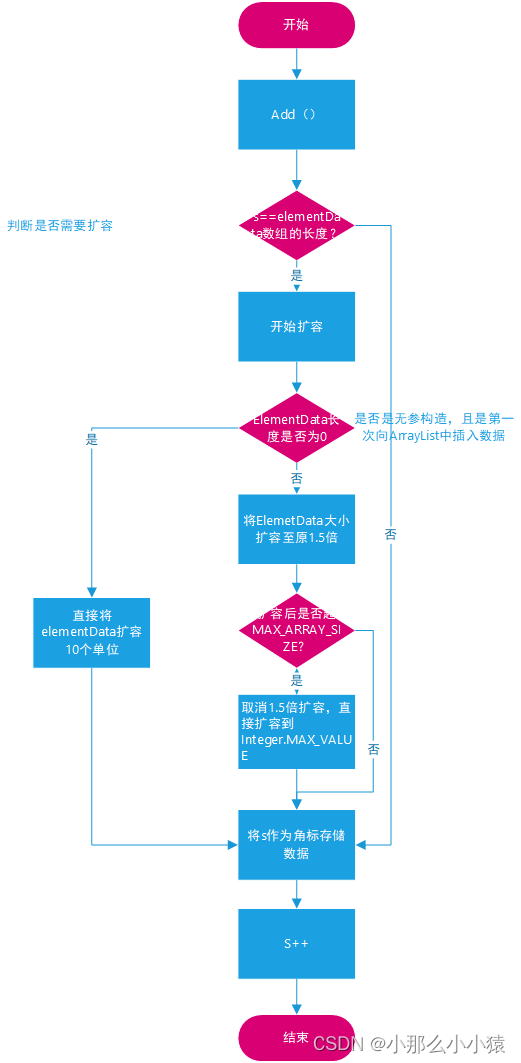
s就是数据要存储时数组的坐标,如果s已经与数组大小相等就代表已经没有地方去存储新的数据了,初始时,s=0,elementData的长度为0,已经无法存储数据,需要扩容,扩容后,elementData[s]=当前数据,然后s++。当数组中添加完最后一个元素,s++=10时,就代表下一个元素是第11个数据,此时s=elementData.length,就需要再次扩容了。
Vector
无参创建Vector对象
Vector的底层也是采用的名为elementData的数组,对于数组的初始大小不像ArrayList那样:在添加元素时进行判断,判断是否是空数组扩容,如果是就扩容10个单位,Vector的如果是无参构造,在无参构造中就调用有参构造,将参数设置为10
 在创建对象时,就已经创建了创建了指定长度的Object型elementData数组,这点和上面的ArrayList很不相同
在创建对象时,就已经创建了创建了指定长度的Object型elementData数组,这点和上面的ArrayList很不相同
在向数组中初始添加元素时,与ArrayList不同的是,它是线程安全的。
在创建Vector时,可以指定每次扩容的大小,如果不指定,那么默认为在原数组大小基础上再加上同样大小
底层数组满了怎么办?2倍扩容
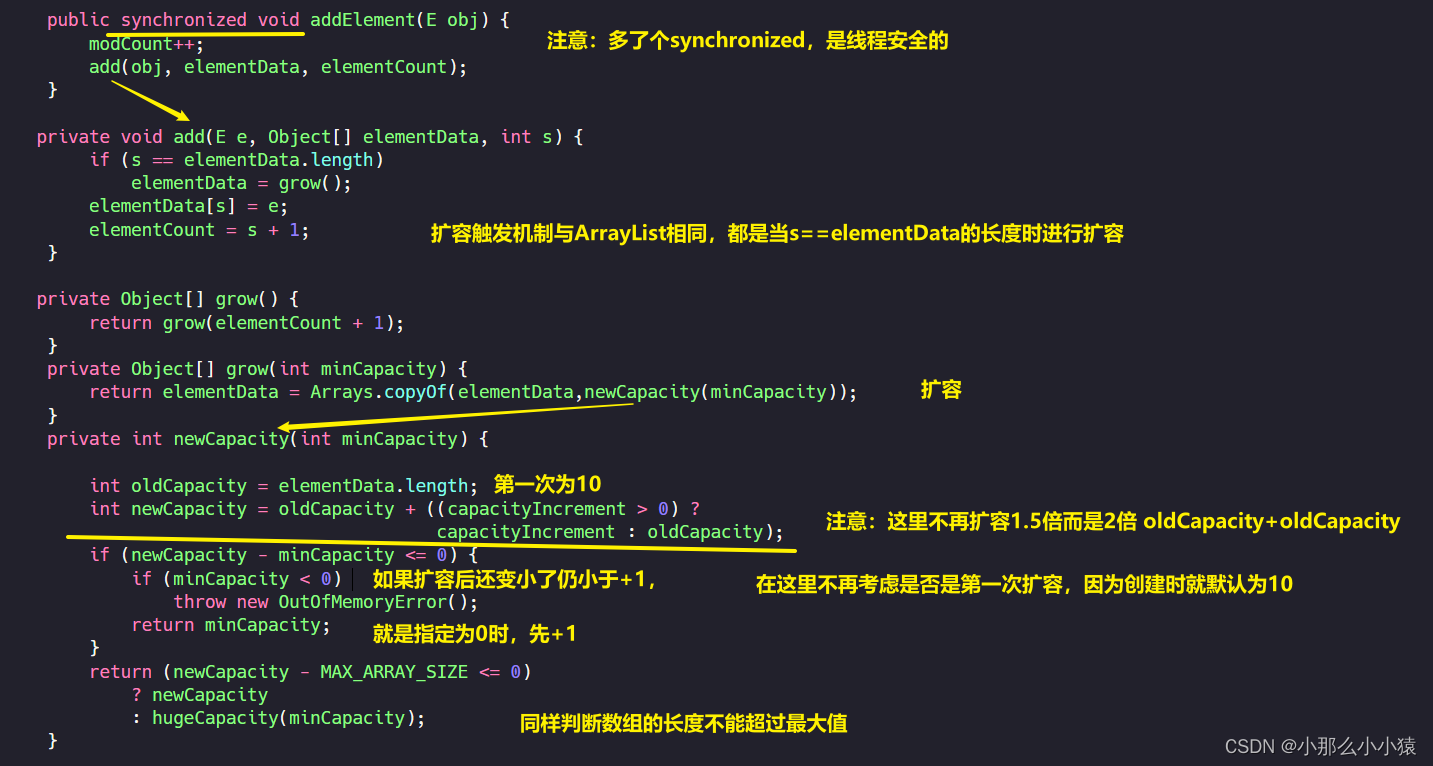
那么如果在构造Veactor时手动指定elementData大小为0时,怎么办?
如果觉得创建Vector时默认就指定10个大小长度有些不妥,可以在创建对象时手动指定长度为0,这样elementData的长度就为0。在添加元素时就行扩充

Vector与ArrayList不同之处
- Vector是线程安全的,在add()方法前添加了
synchronized,而ArrayList没有 - Vector在无参构造创建对象是就开辟了elementData数组的大小,而ArrayList在无参构造创建对象时elementData数组的大小为空,只有在添加元素时才会进行初始化
- Vector可以指定每次扩容大小,在有参构造的第一个参数指定elementData大小,第二个参数就是执行每次扩容大小。而ArrayList不能够指定,每次大小固定。
- Vector若不指定每次扩容大小,则扩容时是
新数组长度=原数组长度+原数组长度相当于是2倍,而ArrayList是新数组长度=原数组长度+0.5原数组长度相当于是1.5倍 - ArrayList在构造时,可以赋值为一个集合的数据
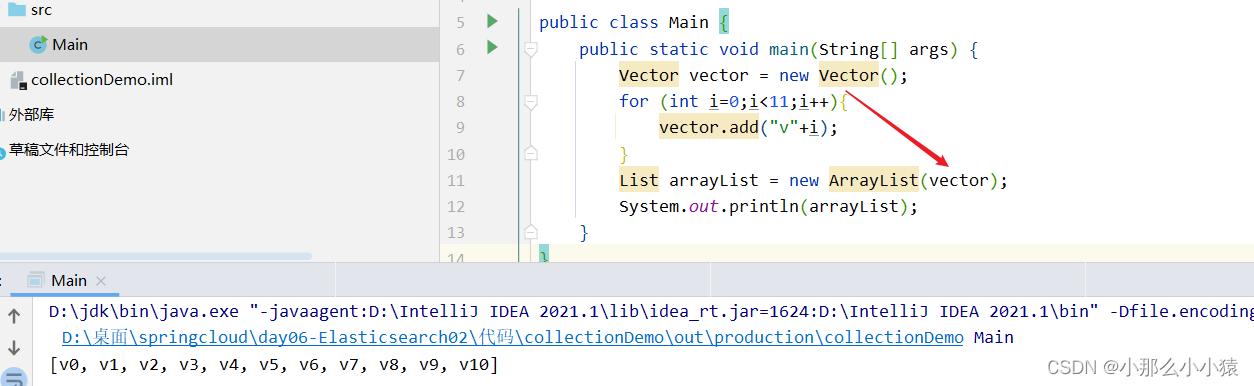
Vector与ArrayList的相同之处
- 底层都采用名为
elementData的数组 - 触发扩容机制相同,都是当s==elementData.length时,调用扩容方法。扩容后将s作为新数据的数组的脚标,然后s++

Vector适用场景:
如果对线程安全有要求,就使用Vector,如果想要手动指定每次扩容大小,就使用Vector。
总结:
LinkedList
LinkdList底层采用的是双向链表,以上两个都是数组。链表和数组的不同就是,链表十分的灵活,添加元素只需要创建单个节点,然后将指针指向它即可,而数组需要提前开辟一段空间,这就使得LinkedList的构造方法与ArrayList、Vector都不相同,它不需要开辟空间。
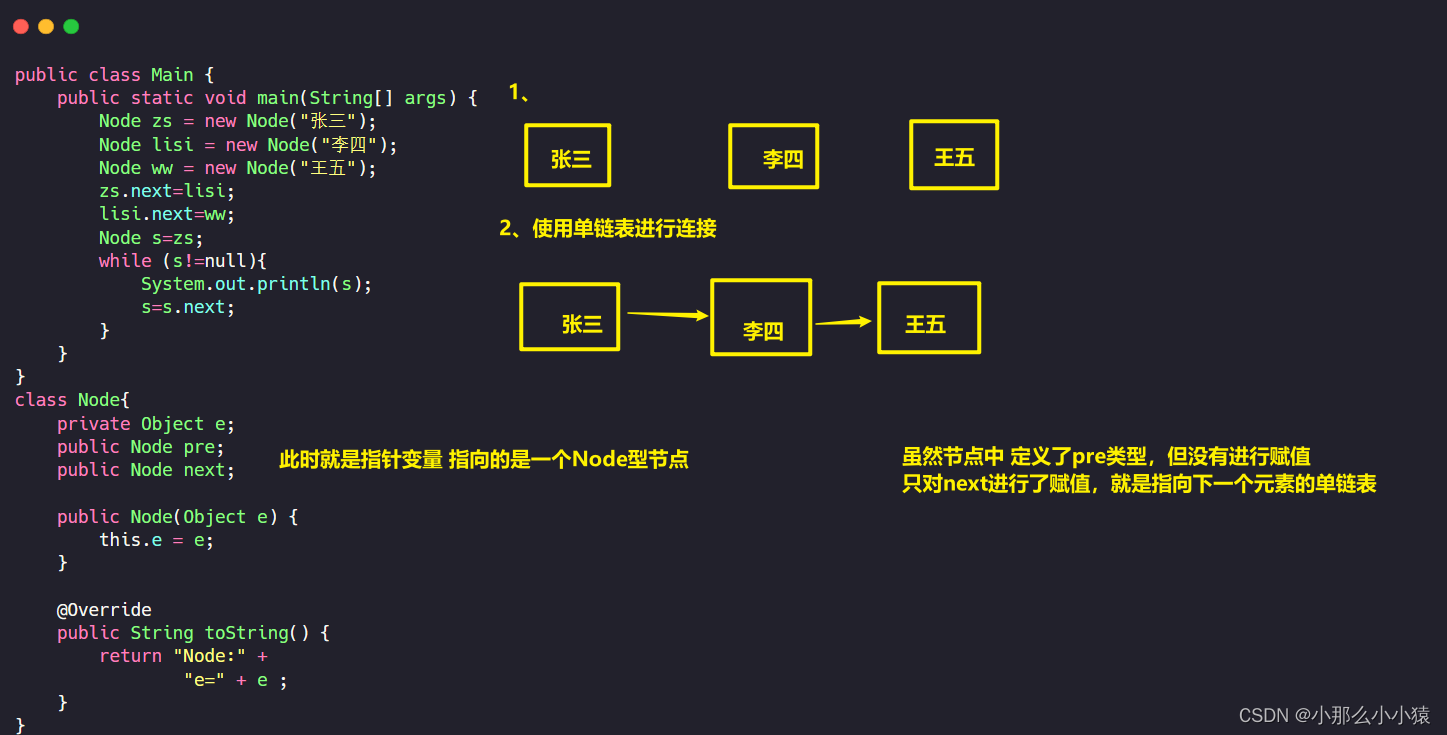
值的注意的是:虽然java中没有指针的概念,但指针是真实存在的。例如:String a=new String(“test”),a指向的就是堆空间中的String对象地址。
这里使用Java来写一个简单的单向链表
LinkedList的构造方法

但当向LinkedList中添加数据时
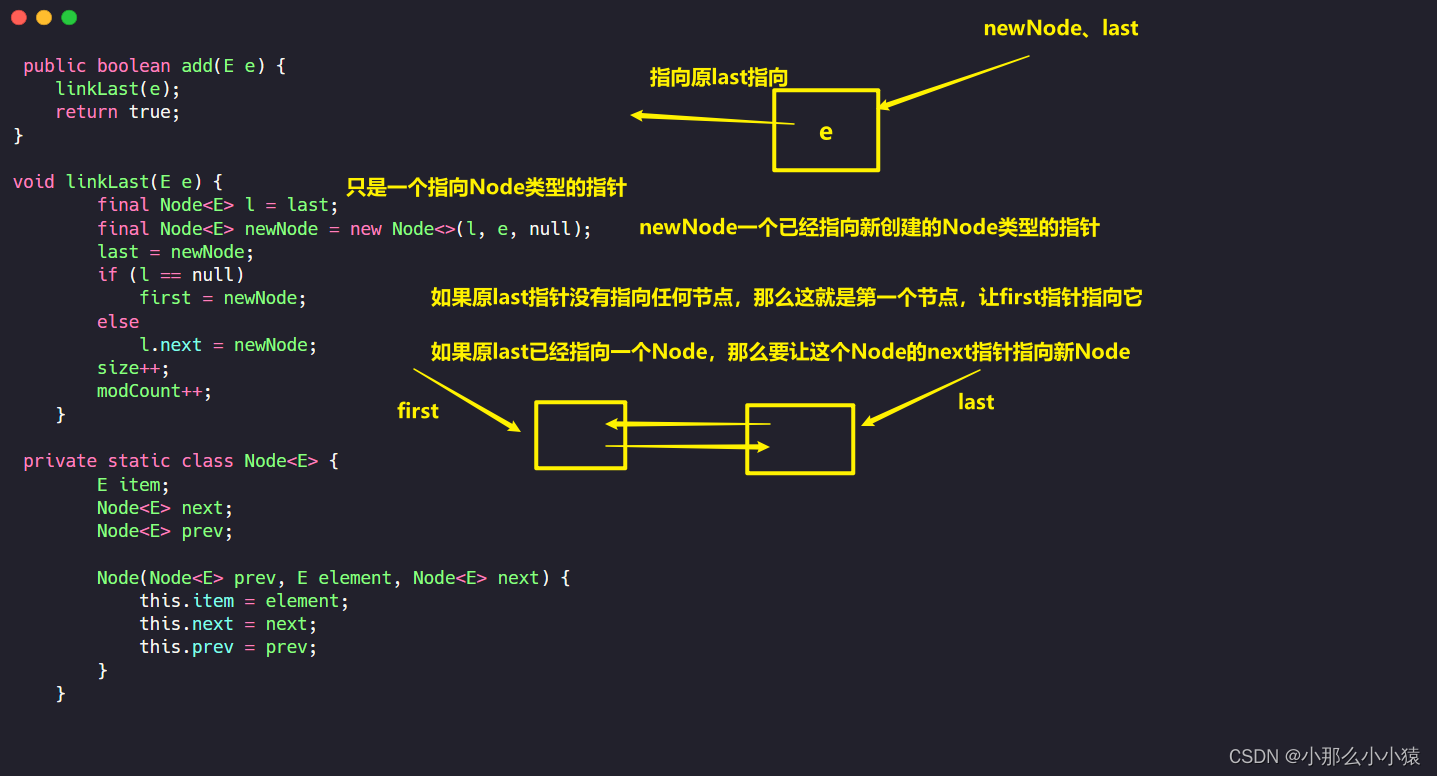
将原来last执向的节点记录下来,然后将last指向新添加的节点。判断此节点是否是第一个节点,就要看原last指向节点是否为空,如果原last指向节点为空,那么此节点就是第一个节点,将执行第一个节点的first执行它。如果原last指向的节点不为空,那么代表新添加的节点前还有节点,因为在创建新节点时,已经将新节点的pred指针指向last指向的位置了,但对于上一个节点,还没有将next指向新添加的节点。
那么双向链表在移除元素时是怎样进行操作的?
Set
HashSet
HashSet的本质就是一个HashMap,HashSet中的每个值都对应HashMap的key,并且它的value设置为空对象
这也就解释了HashSet的两大特性:
- 不重复:因为HashMap的key不允许重复
- 无序:说是无序准确来说是没有按照插入顺序,因为HashMap底层根据Hash值计算出数据在table数组(Node类型)中位置的,而不是按照插入顺序。
接下来介绍一下HashSet的源码,但因为前面已经介绍过HashMap,所以相同的部分这里不再赘述
HashSet的构造 HashSet的构造有很多,这里只介绍一下无参构造,有参构造要么是在指定阈值比例,要么就是table的初始化大小

当添加数据时add()

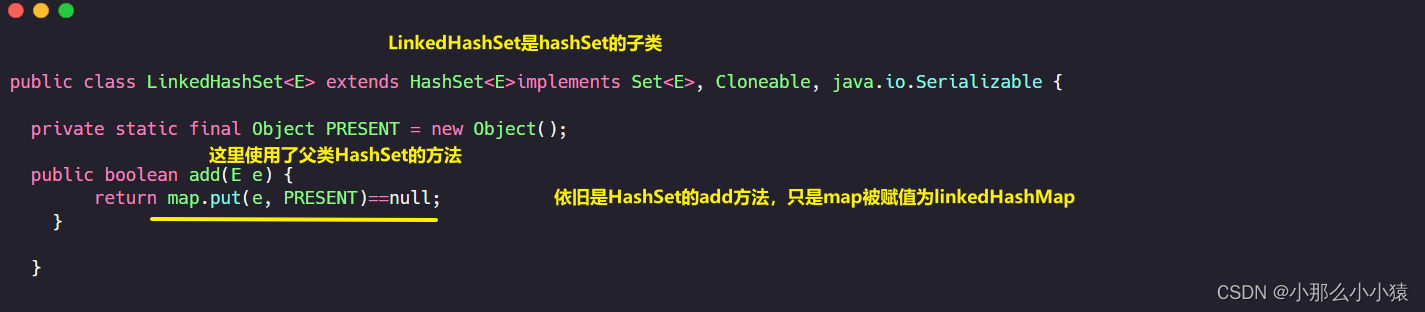
LinkedHashSet
LinkedHashSet同样底层是LinkedHashMap,那么LinkedhashMap相较于HashMap有什么特点呢?最大的特点就是单独维护一条链表使得HashMap的可以按照插入顺序进行输出。所以LinkedhashSet与HashSet最大的不同也是,LinkedHashMap是有序的,但Key依然不可重复

当添加一个元素时
TreeSet
TreeSet的底层使用的TreeMap,TreeMap的最大特点就是底层是一个红黑树,可以对插入key进行排序,当然要想自定义可以传入Comparator方法

TreeSet同样将值作为TreeMap的key,可以对Set中的值进行排序。
